 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Taught by the Internet, Exploring Bias in OpenAIs GPT3
Jun 04, 2023
This research delves into the current literature on bias in Natural Language Processing Models and the techniques proposed to mitigate the problem of bias, including why it is important to tackle bias in the first place. Additionally, these techniques are further analysed in the light of newly developed models that tower in size over past editions. To achieve those aims, the authors of this paper conducted their research on GPT3 by OpenAI, the largest NLP model available to consumers today. With 175 billion parameters in contrast to BERTs 340 million, GPT3 is the perfect model to test the common pitfalls of NLP models. Tests were conducted through the development of an Applicant Tracking System using GPT3. For the sake of feasibility and time constraints, the tests primarily focused on gender bias, rather than all or multiple types of bias. Finally, current mitigation techniques are considered and tested to measure their degree of functionality.
Onsite Job Scheduling by Adaptive Genetic Algorithm
Jun 04, 2023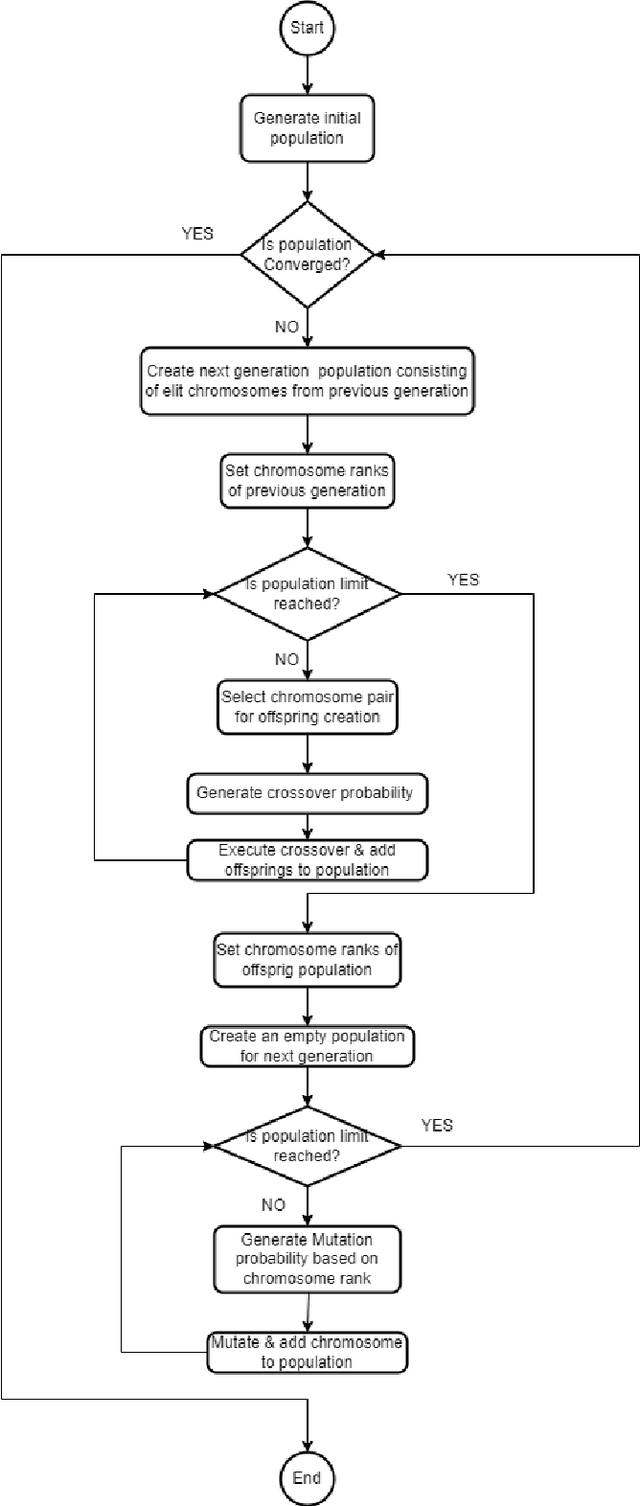
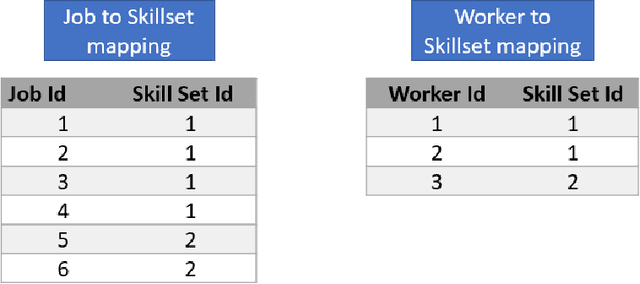
Onsite Job Scheduling is a specialized variant of Vehicle Routing Problem (VRP) with multiple depots. The objective of this problem is to execute jobs requested by customers, belonging to different geographic locations by a limited number of technicians, with minimum travel and overtime of technicians. Each job is expected to be completed within a specified time limit according to the service level agreement with customers. Each technician is assumed to start from a base location, serve several customers and return to the starting place. Technicians are allotted jobs based on their skill sets, expertise levels of each skill and availability slots. Although there are considerable number of literatures on VRP we do not see any explicit work related to Onsite Job Scheduling. In this paper we have proposed an Adaptive Genetic Algorithm to solve the scheduling problem. We found an optimized travel route for a substantial number of jobs and technicians, minimizing travel distance, overtime duration as well as meeting constraints related to SLA.
A data-driven rutting depth short-time prediction model with metaheuristic optimization for asphalt pavements based on RIOHTrack
May 11, 2023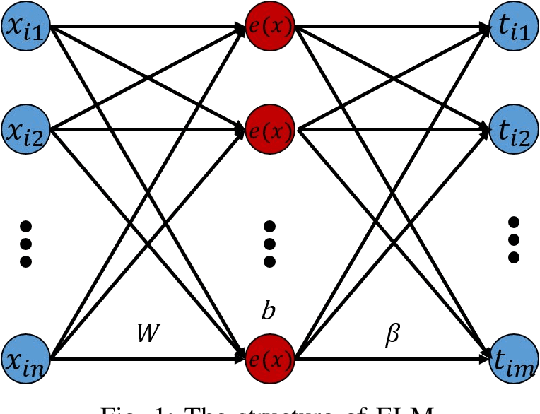
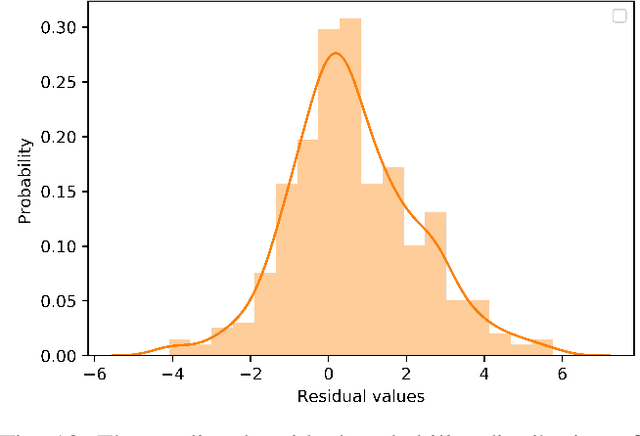
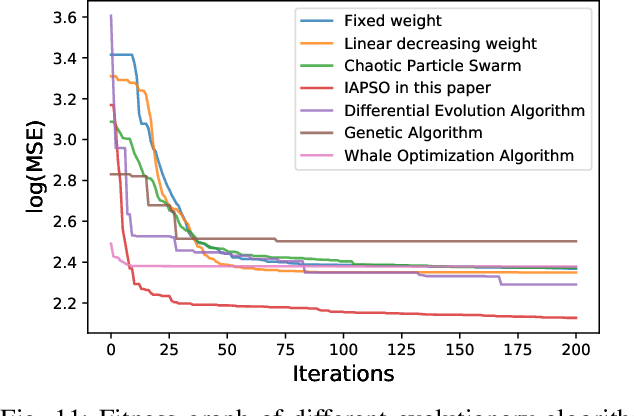
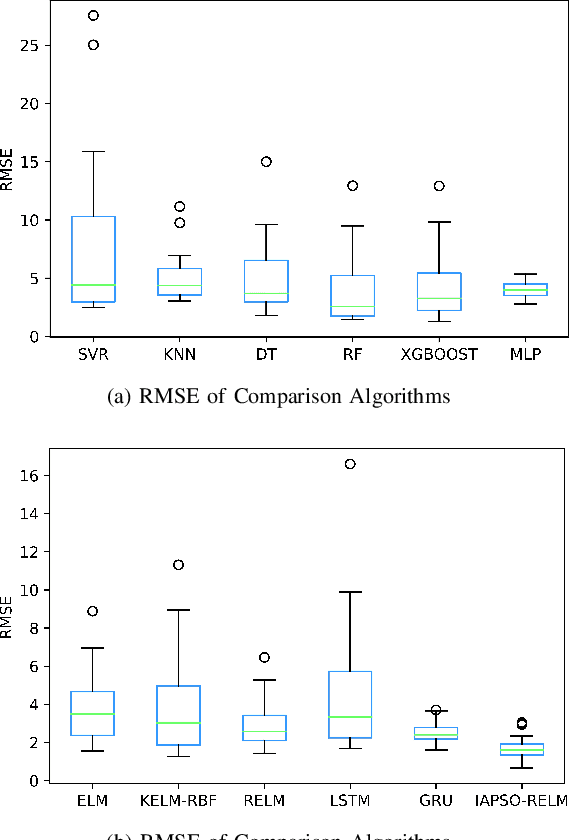
Rutting of asphalt pavements is a crucial design criterion in various pavement design guides. A good road transportation base can provide security for the transportation of oil and gas in road transportation. This study attempts to develop a robust artificial intelligence model to estimate different asphalt pavements' rutting depth clips, temperature, and load axes as primary characteristics. The experiment data were obtained from 19 asphalt pavements with different crude oil sources on a 2.038 km long full-scale field accelerated pavement test track (RIOHTrack, Road Track Institute) in Tongzhou, Beijing. In addition, this paper also proposes to build complex networks with different pavement rutting depths through complex network methods and the Louvain algorithm for community detection. The most critical structural elements can be selected from different asphalt pavement rutting data, and similar structural elements can be found. An extreme learning machine algorithm with residual correction (RELM) is designed and optimized using an independent adaptive particle swarm algorithm. The experimental results of the proposed method are compared with several classical machine learning algorithms, with predictions of Average Root Mean Squared Error, Average Mean Absolute Error, and Average Mean Absolute Percentage Error for 19 asphalt pavements reaching 1.742, 1.363, and 1.94\% respectively. The experiments demonstrate that the RELM algorithm has an advantage over classical machine learning methods in dealing with non-linear problems in road engineering. Notably, the method ensures the adaptation of the simulated environment to different levels of abstraction through the cognitive analysis of the production environment parameters.
On the robust learning mixtures of linear regressions
May 23, 2023In this note, we consider the problem of robust learning mixtures of linear regressions. We connect mixtures of linear regressions and mixtures of Gaussians with a simple thresholding, so that a quasi-polynomial time algorithm can be obtained under some mild separation condition. This algorithm has significantly better robustness than the previous result.
AdANNS: A Framework for Adaptive Semantic Search
May 30, 2023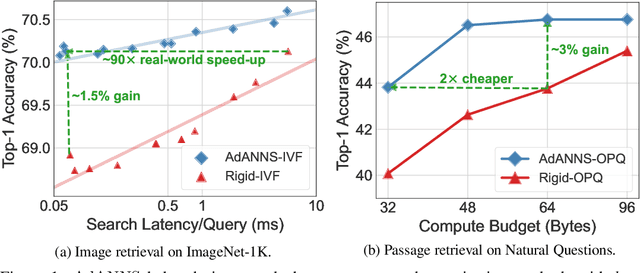
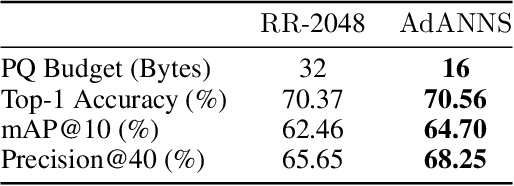
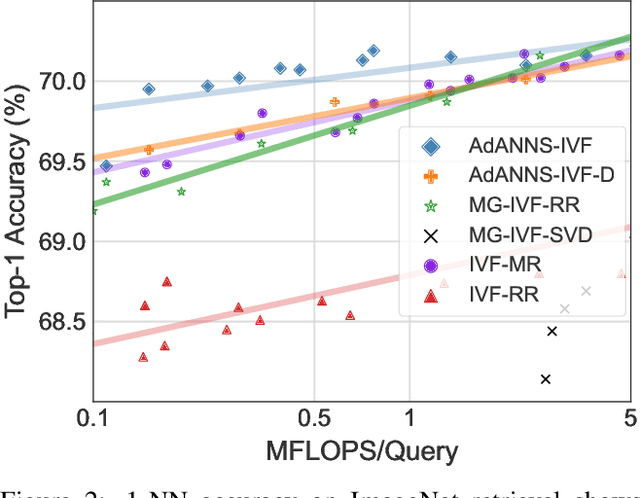

Web-scale search systems learn an encoder to embed a given query which is then hooked into an approximate nearest neighbor search (ANNS) pipeline to retrieve similar data points. To accurately capture tail queries and data points, learned representations typically are rigid, high-dimensional vectors that are generally used as-is in the entire ANNS pipeline and can lead to computationally expensive retrieval. In this paper, we argue that instead of rigid representations, different stages of ANNS can leverage adaptive representations of varying capacities to achieve significantly better accuracy-compute trade-offs, i.e., stages of ANNS that can get away with more approximate computation should use a lower-capacity representation of the same data point. To this end, we introduce AdANNS, a novel ANNS design framework that explicitly leverages the flexibility of Matryoshka Representations. We demonstrate state-of-the-art accuracy-compute trade-offs using novel AdANNS-based key ANNS building blocks like search data structures (AdANNS-IVF) and quantization (AdANNS-OPQ). For example on ImageNet retrieval, AdANNS-IVF is up to 1.5% more accurate than the rigid representations-based IVF at the same compute budget; and matches accuracy while being up to 90x faster in wall-clock time. For Natural Questions, 32-byte AdANNS-OPQ matches the accuracy of the 64-byte OPQ baseline constructed using rigid representations -- same accuracy at half the cost! We further show that the gains from AdANNS translate to modern-day composite ANNS indices that combine search structures and quantization. Finally, we demonstrate that AdANNS can enable inference-time adaptivity for compute-aware search on ANNS indices built non-adaptively on matryoshka representations. Code is open-sourced at https://github.com/RAIVNLab/AdANNS.
Multi-objective Anti-swing Trajectory Planning of Double-pendulum Tower Crane Operations using Opposition-based Evolutionary Algorithm
May 30, 2023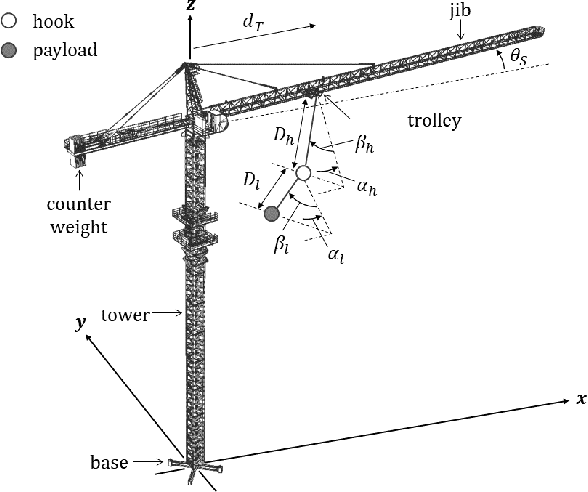
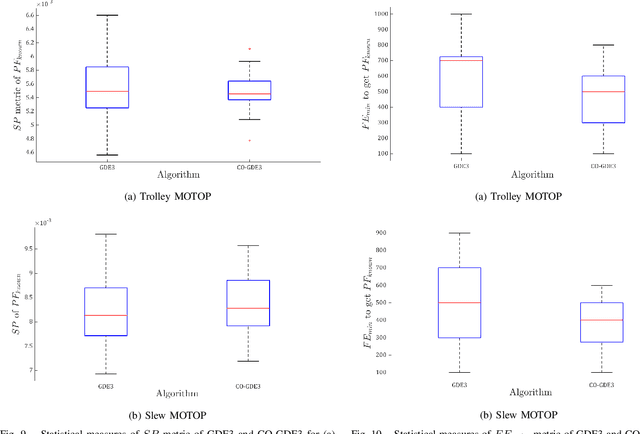
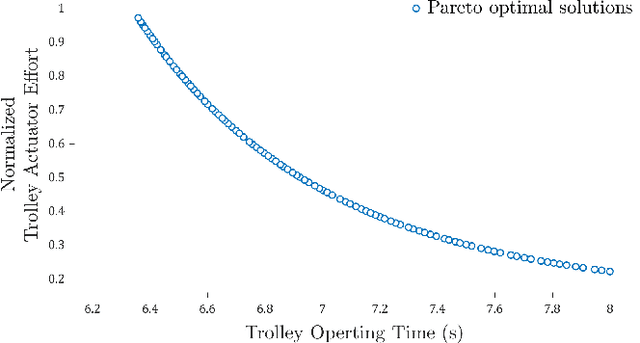
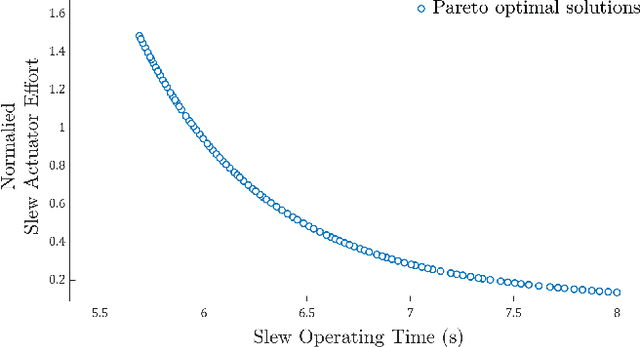
Underactuated tower crane lifting requires time-energy optimal trajectories for the trolley/slew operations and reduction of the unactuated swings resulting from the trolley/jib motion. In scenarios involving non-negligible hook mass or long rig-cable, the hook-payload unit exhibits double-pendulum behaviour, making the problem highly challenging. This article introduces an offline multi-objective anti-swing trajectory planning module for a Computer-Aided Lift Planning (CALP) system of autonomous double-pendulum tower cranes, addressing all the transient state constraints. A set of auxiliary outputs are selected by methodically analyzing the payload swing dynamics and are used to prove the differential flatness property of the crane operations. The flat outputs are parameterized via suitable B\'{e}zier curves to formulate the multi-objective trajectory optimization problems in the flat output space. A novel multi-objective evolutionary algorithm called Collective Oppositional Generalized Differential Evolution 3 (CO-GDE3) is employed as the optimizer. To obtain faster convergence and better consistency in getting a wide range of good solutions, a new population initialization strategy is integrated into the conventional GDE3. The computationally efficient initialization method incorporates various concepts of computational opposition. Statistical comparisons based on trolley and slew operations verify the superiority of convergence and reliability of CO-GDE3 over the standard GDE3. Trolley and slew operations of a collision-free lifting path computed via the path planner of the CALP system are selected for a simulation study. The simulated trajectories demonstrate that the proposed planner can produce time-energy optimal solutions, keeping all the state variables within their respective limits and restricting the hook and payload swings.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023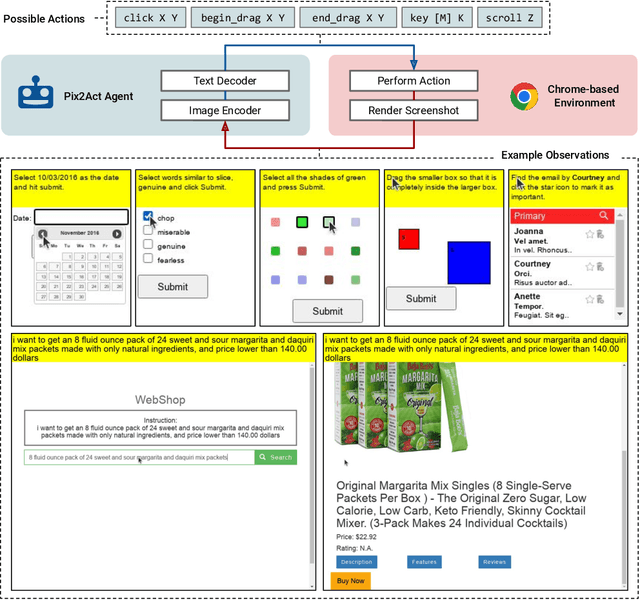
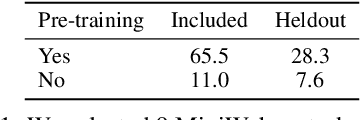
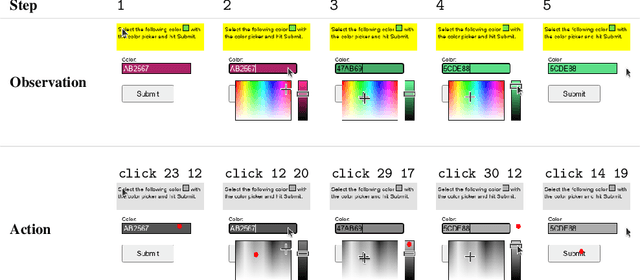
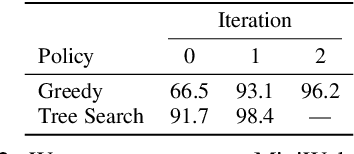
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
Multi-granulariy Time-based Transformer for Knowledge Tracing
Apr 11, 2023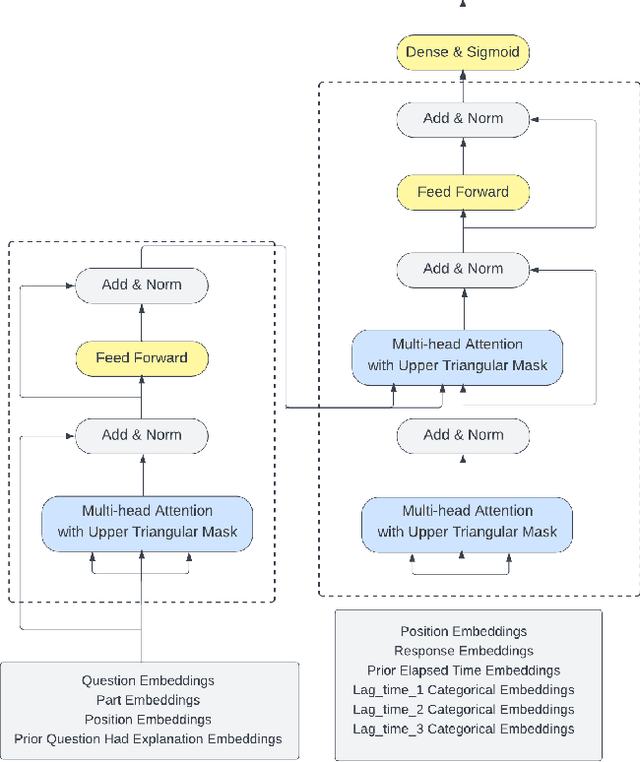

In this paper, we present a transformer architecture for predicting student performance on standardized tests. Specifically, we leverage students historical data, including their past test scores, study habits, and other relevant information, to create a personalized model for each student. We then use these models to predict their future performance on a given test. Applying this model to the RIIID dataset, we demonstrate that using multiple granularities for temporal features as the decoder input significantly improve model performance. Our results also show the effectiveness of our approach, with substantial improvements over the LightGBM method. Our work contributes to the growing field of AI in education, providing a scalable and accurate tool for predicting student outcomes.
SEIP: Simulation-based Design and Evaluation of Infrastructure-based Collective Perception
May 29, 2023
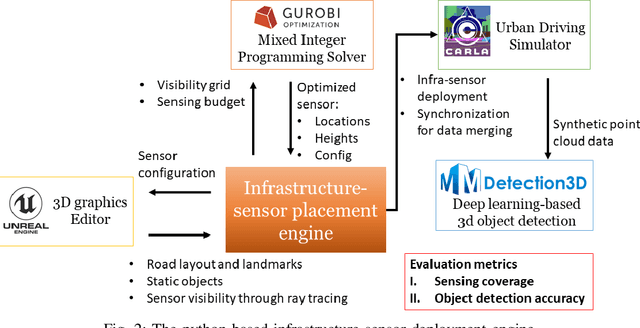

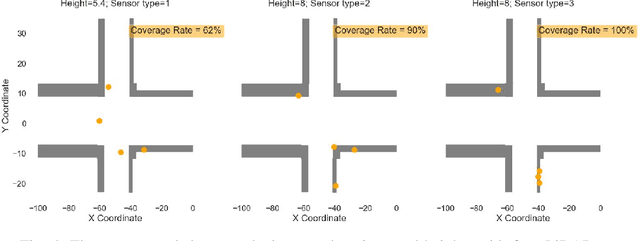
Infrastructure-based collective perception, which entails the real-time sharing and merging of sensing data from different roadside sensors for object detection, has shown promise in preventing occlusions for traffic safety and efficiency. However, its adoption has been hindered by the lack of guidance for roadside sensor placement and high costs for ex-post evaluation. For infrastructure projects with limited budgets, the ex-ante evaluation for optimizing the configurations and placements of infrastructure sensors is crucial to minimize occlusion risks at a low cost. This paper presents algorithms and simulation tools to support the ex-ante evaluation of the cost-performance tradeoff in infrastructure sensor deployment for collective perception. More specifically, the deployment of infrastructure sensors is framed as an integer programming problem that can be efficiently solved in polynomial time, achieving near-optimal results with the use of certain heuristic algorithms. The solutions provide guidance on deciding sensor locations, installation heights, and configurations to achieve the balance between procurement cost, physical constraints for installation, and sensing coverage. Additionally, we implement the proposed algorithms in a simulation engine. This allows us to evaluate the effectiveness of each sensor deployment solution through the lens of object detection. The application of the proposed methods was illustrated through a case study on traffic monitoring by using infrastructure LiDARs. Preliminary findings indicate that when working with a tight sensing budget, it is possible that the incremental benefit derived from integrating additional low-resolution LiDARs could surpass that of incorporating more high-resolution ones. The results reinforce the necessity of investigating the cost-performance tradeoff.
Physics-Guided Graph Neural Networks for Real-time AC/DC Power Flow Analysis
Apr 29, 2023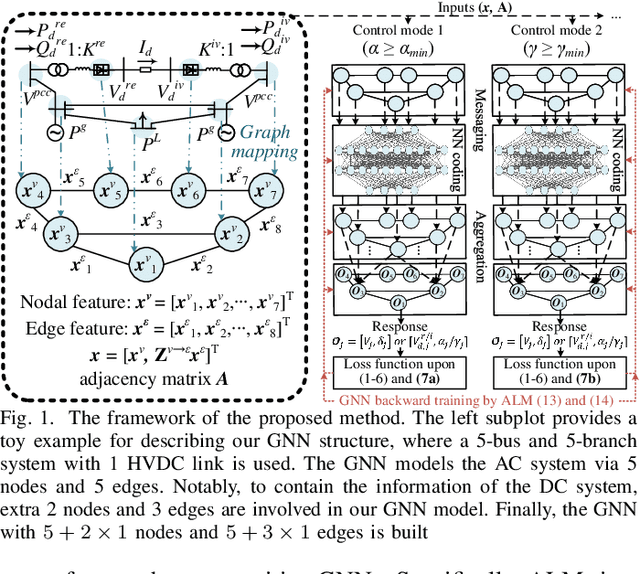
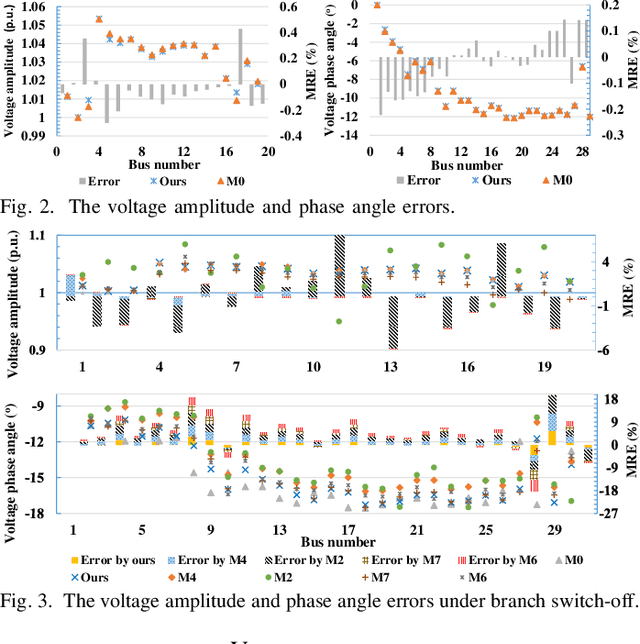
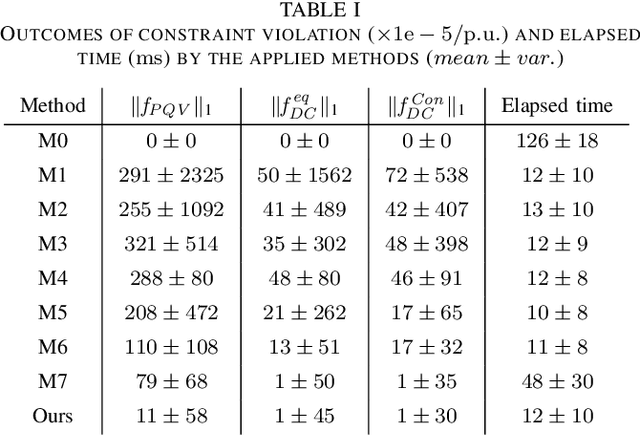
The increasing scale of alternating current and direct current (AC/DC) hybrid systems necessitates a faster power flow analysis tool than ever. This letter thus proposes a specific physics-guided graph neural network (PG-GNN). The tailored graph modelling of AC and DC grids is firstly advanced to enhance the topology adaptability of the PG-GNN. To eschew unreliable experience emulation from data, AC/DC physics are embedded in the PG-GNN using duality. Augmented Lagrangian method-based learning scheme is then presented to help the PG-GNN better learn nonconvex patterns in an unsupervised label-free manner. Multi-PG-GNN is finally conducted to master varied DC control modes. Case study shows that, relative to the other 7 data-driven rivals, only the proposed method matches the performance of the model-based benchmark, also beats it in computational efficiency beyond 10 times.