 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Training neural operators to preserve invariant measures of chaotic attractors
Jun 01, 2023
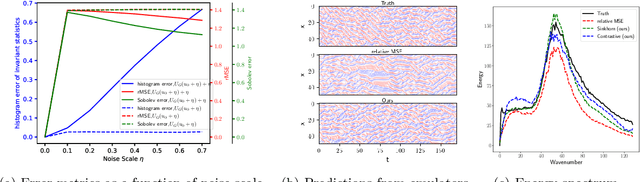
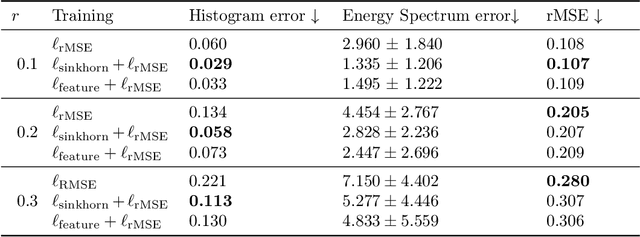
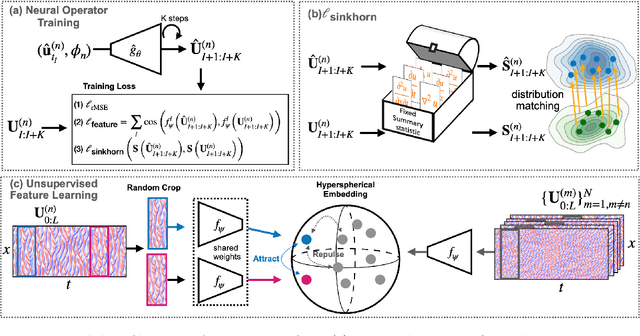

Chaotic systems make long-horizon forecasts difficult because small perturbations in initial conditions cause trajectories to diverge at an exponential rate. In this setting, neural operators trained to minimize squared error losses, while capable of accurate short-term forecasts, often fail to reproduce statistical or structural properties of the dynamics over longer time horizons and can yield degenerate results. In this paper, we propose an alternative framework designed to preserve invariant measures of chaotic attractors that characterize the time-invariant statistical properties of the dynamics. Specifically, in the multi-environment setting (where each sample trajectory is governed by slightly different dynamics), we consider two novel approaches to training with noisy data. First, we propose a loss based on the optimal transport distance between the observed dynamics and the neural operator outputs. This approach requires expert knowledge of the underlying physics to determine what statistical features should be included in the optimal transport loss. Second, we show that a contrastive learning framework, which does not require any specialized prior knowledge, can preserve statistical properties of the dynamics nearly as well as the optimal transport approach. On a variety of chaotic systems, our method is shown empirically to preserve invariant measures of chaotic attractors.
Analysis of ChatGPT on Source Code
Jun 06, 2023
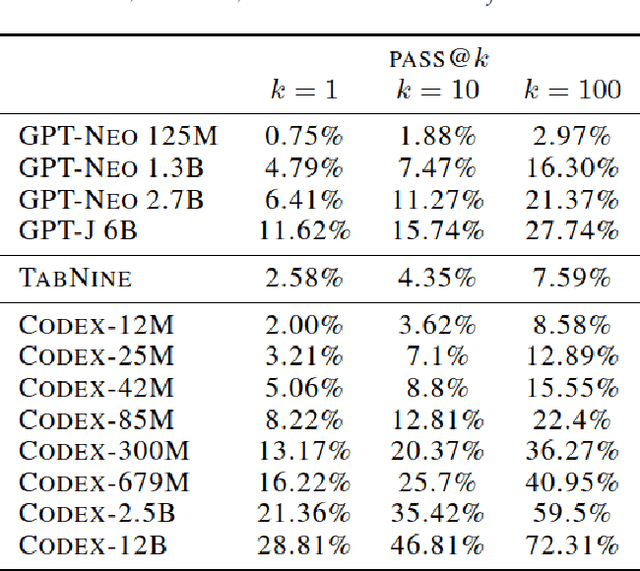
This paper explores the use of Large Language Models (LLMs) and in particular ChatGPT in programming, source code analysis, and code generation. LLMs and ChatGPT are built using machine learning and artificial intelligence techniques, and they offer several benefits to developers and programmers. While these models can save time and provide highly accurate results, they are not yet advanced enough to replace human programmers entirely. The paper investigates the potential applications of LLMs and ChatGPT in various areas, such as code creation, code documentation, bug detection, refactoring, and more. The paper also suggests that the usage of LLMs and ChatGPT is expected to increase in the future as they offer unparalleled benefits to the programming community.
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?
Jun 06, 2023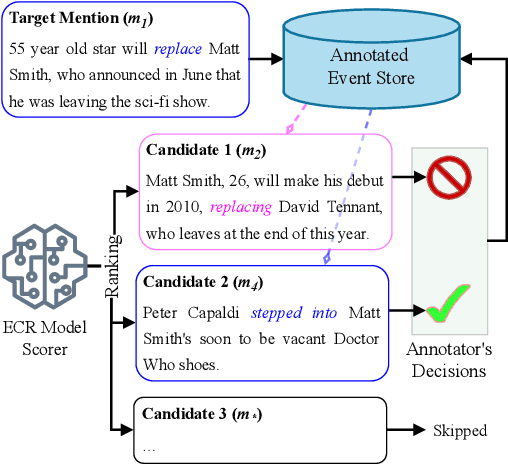
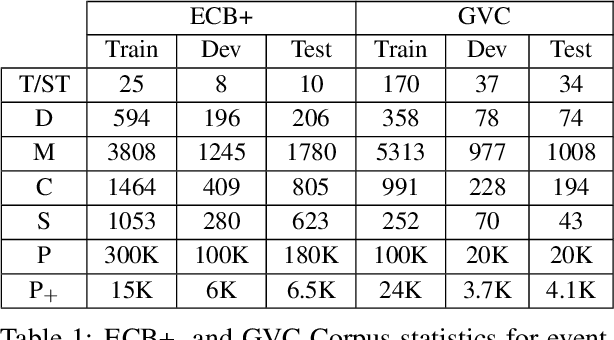
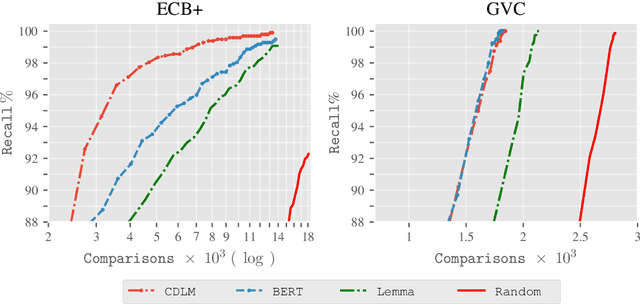
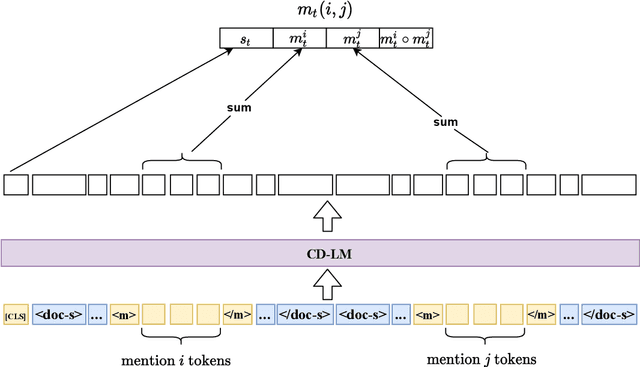
Annotating cross-document event coreference links is a time-consuming and cognitively demanding task that can compromise annotation quality and efficiency. To address this, we propose a model-in-the-loop annotation approach for event coreference resolution, where a machine learning model suggests likely corefering event pairs only. We evaluate the effectiveness of this approach by first simulating the annotation process and then, using a novel annotator-centric Recall-Annotation effort trade-off metric, we compare the results of various underlying models and datasets. We finally present a method for obtaining 97\% recall while substantially reducing the workload required by a fully manual annotation process. Code and data can be found at https://github.com/ahmeshaf/model_in_coref
Brain Tumor Recurrence vs. Radiation Necrosis Classification and Patient Survivability Prediction
Jun 05, 2023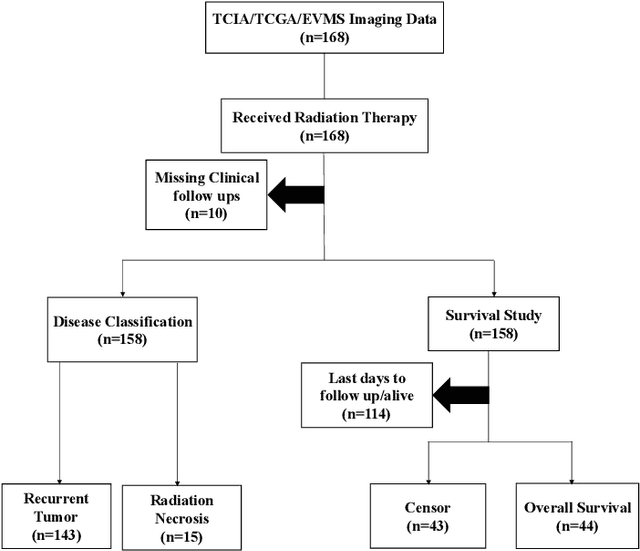
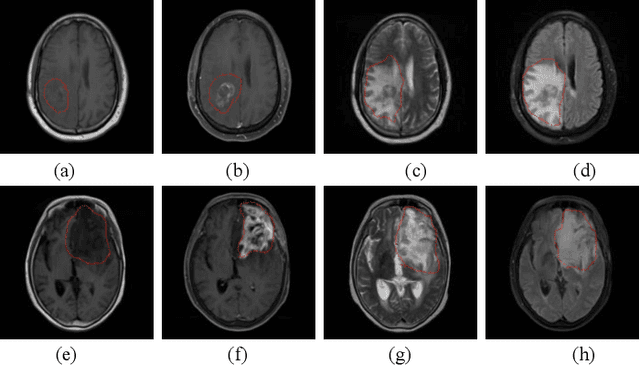
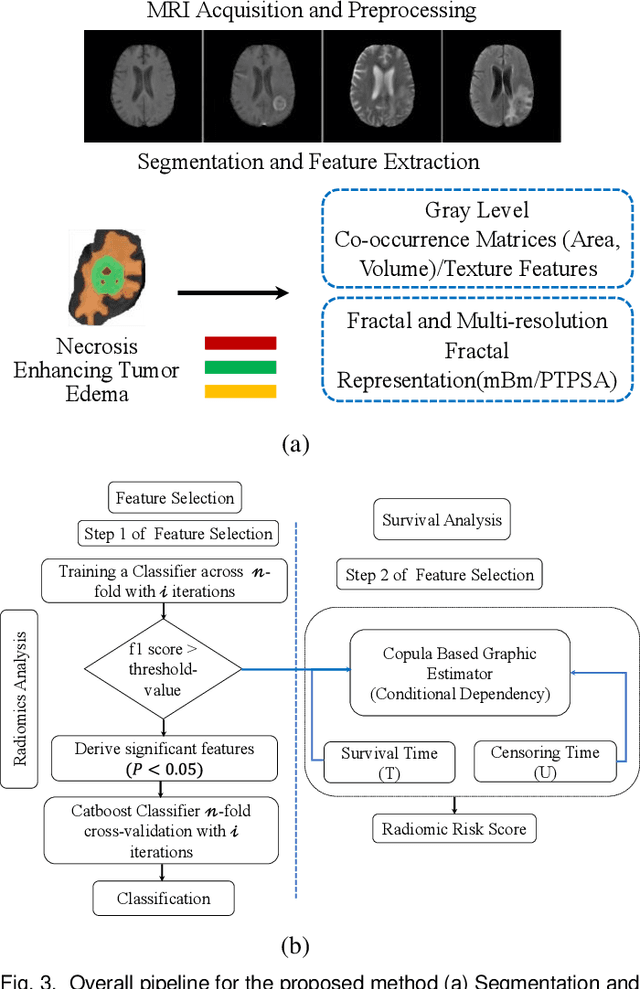
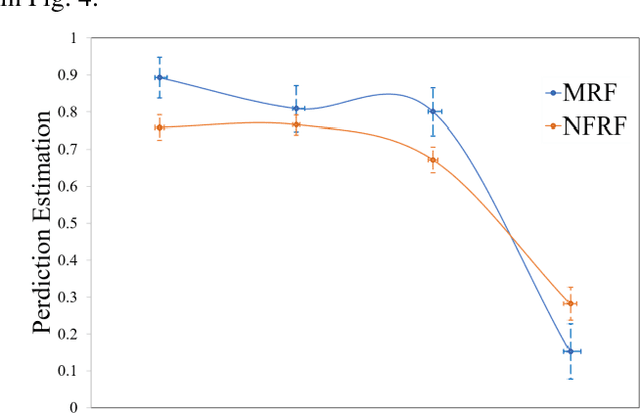
GBM (Glioblastoma multiforme) is the most aggressive type of brain tumor in adults that has a short survival rate even after aggressive treatment with surgery and radiation therapy. The changes on magnetic resonance imaging (MRI) for patients with GBM after radiotherapy are indicative of either radiation-induced necrosis (RN) or recurrent brain tumor (rBT). Screening for rBT and RN at an early stage is crucial for facilitating faster treatment and better outcomes for the patients. Differentiating rBT from RN is challenging as both may present with similar radiological and clinical characteristics on MRI. Moreover, learning-based rBT versus RN classification using MRI may suffer from class imbalance due to lack of patient data. While synthetic data generation using generative models has shown promise to address class imbalance, the underlying data representation may be different in synthetic or augmented data. This study proposes computational modeling with statistically rigorous repeated random sub-sampling to balance the subset sample size for rBT and RN classification. The proposed pipeline includes multiresolution radiomic feature (MRF) extraction followed by feature selection with statistical significance testing (p<0.05). The five-fold cross validation results show the proposed model with MRF features classifies rBT from RN with an area under the curve (AUC) of 0.8920+-.055. Moreover, considering the dependence between survival time and censor time (where patients are not followed up until death), we demonstrate the feasibility of using MRF radiomic features as a non-invasive biomarker to identify patients who are at higher risk of recurrence or radiation necrosis. The cross-validated results show that the MRF model provides the best overall performance with an AUC of 0.770+-.032.
Bayesian Learning of Optimal Policies in Markov Decision Processes with Countably Infinite State-Space
Jun 05, 2023

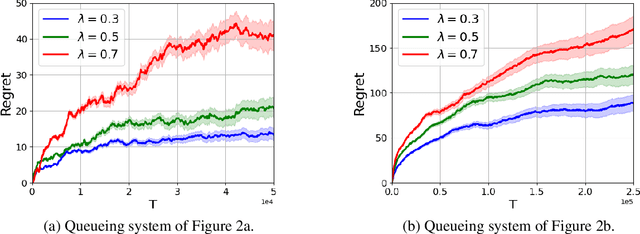
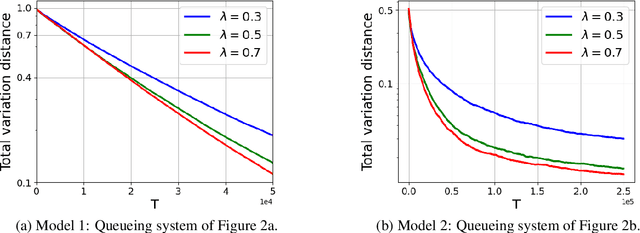
Models of many real-life applications, such as queuing models of communication networks or computing systems, have a countably infinite state-space. Algorithmic and learning procedures that have been developed to produce optimal policies mainly focus on finite state settings, and do not directly apply to these models. To overcome this lacuna, in this work we study the problem of optimal control of a family of discrete-time countable state-space Markov Decision Processes (MDPs) governed by an unknown parameter $\theta\in\Theta$, and defined on a countably-infinite state space $\mathcal X=\mathbb{Z}_+^d$, with finite action space $\mathcal A$, and an unbounded cost function. We take a Bayesian perspective with the random unknown parameter $\boldsymbol{\theta}^*$ generated via a given fixed prior distribution on $\Theta$. To optimally control the unknown MDP, we propose an algorithm based on Thompson sampling with dynamically-sized episodes: at the beginning of each episode, the posterior distribution formed via Bayes' rule is used to produce a parameter estimate, which then decides the policy applied during the episode. To ensure the stability of the Markov chain obtained by following the policy chosen for each parameter, we impose ergodicity assumptions. From this condition and using the solution of the average cost Bellman equation, we establish an $\tilde O(\sqrt{|\mathcal A|T})$ upper bound on the Bayesian regret of our algorithm, where $T$ is the time-horizon. Finally, to elucidate the applicability of our algorithm, we consider two different queuing models with unknown dynamics, and show that our algorithm can be applied to develop approximately optimal control algorithms.
Continually Improving Extractive QA via Human Feedback
May 21, 2023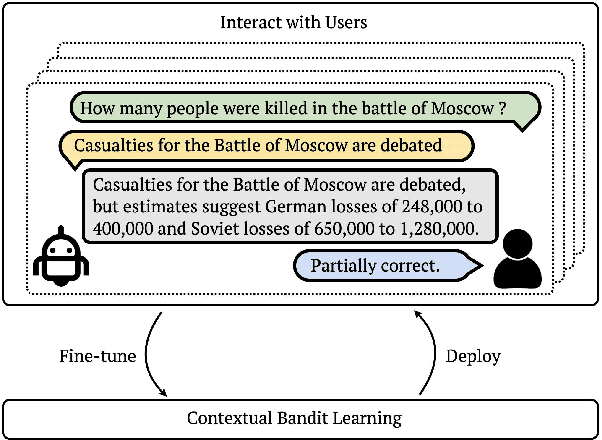

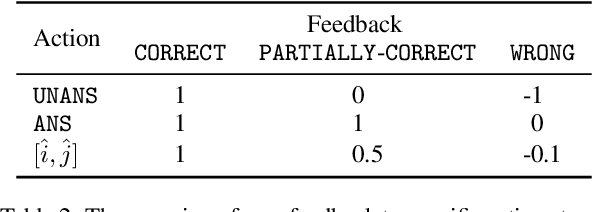
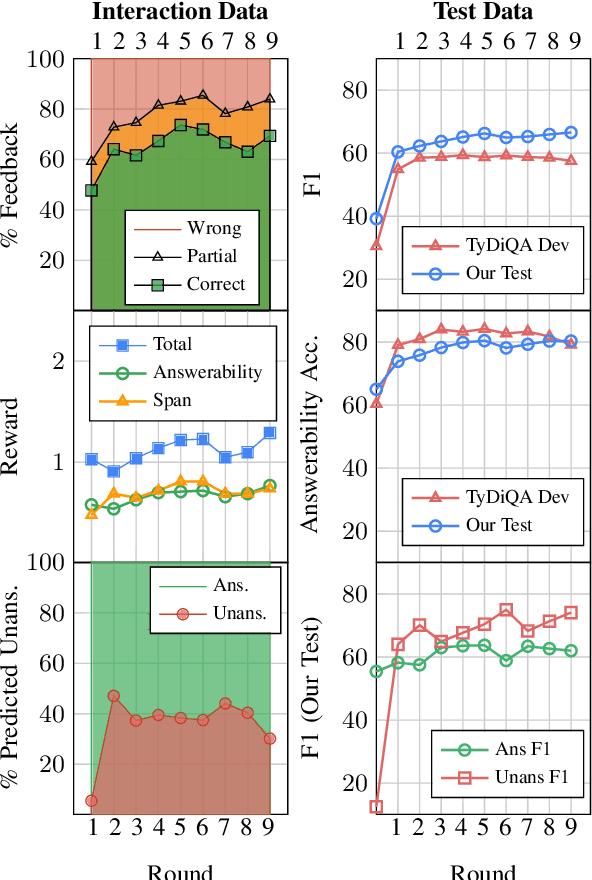
We study continually improving an extractive question answering (QA) system via human user feedback. We design and deploy an iterative approach, where information-seeking users ask questions, receive model-predicted answers, and provide feedback. We conduct experiments involving thousands of user interactions under diverse setups to broaden the understanding of learning from feedback over time. Our experiments show effective improvement from user feedback of extractive QA models over time across different data regimes, including significant potential for domain adaptation.
Multi-Robot Path Planning Combining Heuristics and Multi-Agent Reinforcement Learning
Jun 02, 2023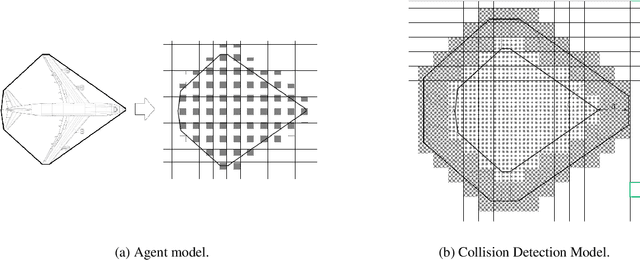
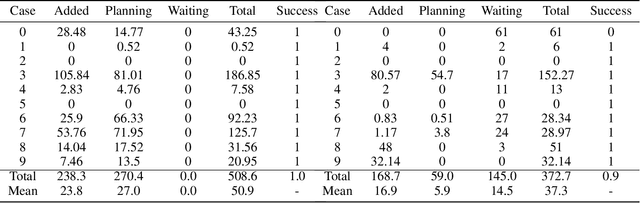
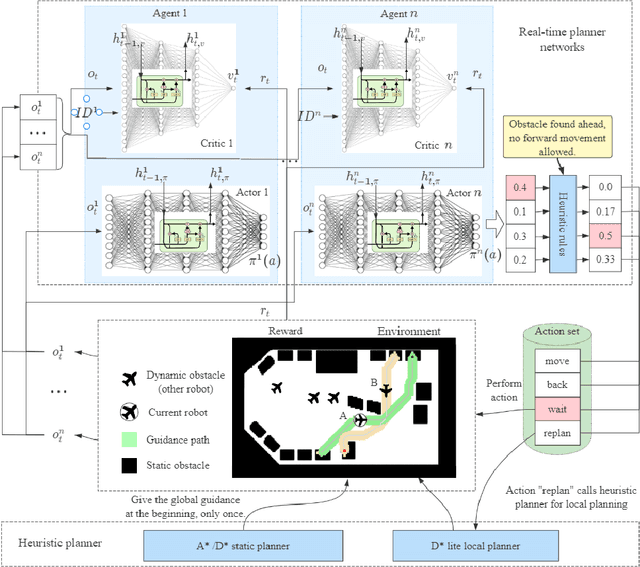
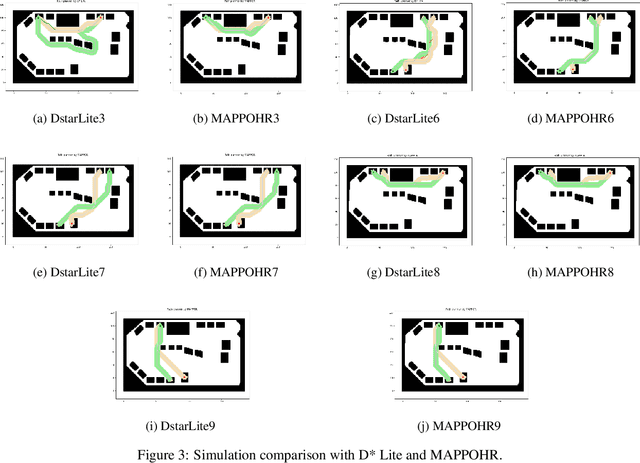
Multi-robot path finding in dynamic environments is a highly challenging classic problem. In the movement process, robots need to avoid collisions with other moving robots while minimizing their travel distance. Previous methods for this problem either continuously replan paths using heuristic search methods to avoid conflicts or choose appropriate collision avoidance strategies based on learning approaches. The former may result in long travel distances due to frequent replanning, while the latter may have low learning efficiency due to low sample exploration and utilization, and causing high training costs for the model. To address these issues, we propose a path planning method, MAPPOHR, which combines heuristic search, empirical rules, and multi-agent reinforcement learning. The method consists of two layers: a real-time planner based on the multi-agent reinforcement learning algorithm, MAPPO, which embeds empirical rules in the action output layer and reward functions, and a heuristic search planner used to create a global guiding path. During movement, the heuristic search planner replans new paths based on the instructions of the real-time planner. We tested our method in 10 different conflict scenarios. The experiments show that the planning performance of MAPPOHR is better than that of existing learning and heuristic methods. Due to the utilization of empirical knowledge and heuristic search, the learning efficiency of MAPPOHR is higher than that of existing learning methods.
Precise and Generalized Robustness Certification for Neural Networks
Jun 11, 2023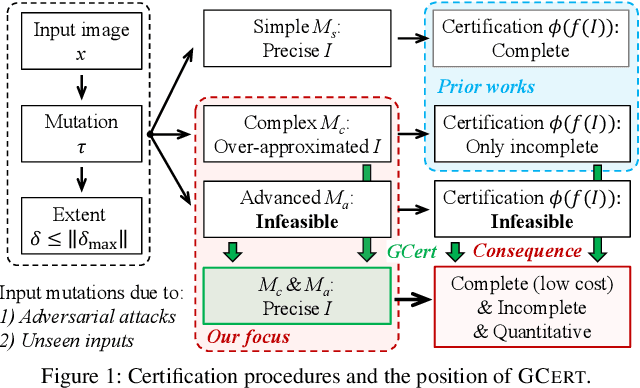
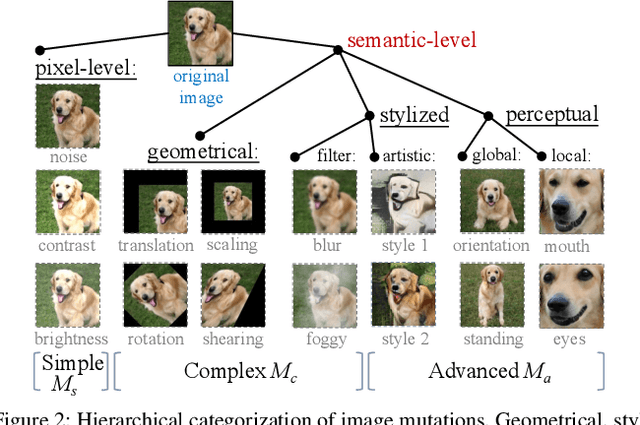
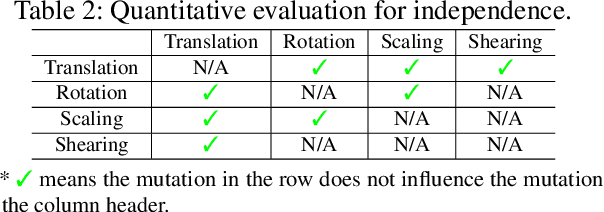
The objective of neural network (NN) robustness certification is to determine if a NN changes its predictions when mutations are made to its inputs. While most certification research studies pixel-level or a few geometrical-level and blurring operations over images, this paper proposes a novel framework, GCERT, which certifies NN robustness under a precise and unified form of diverse semantic-level image mutations. We formulate a comprehensive set of semantic-level image mutations uniformly as certain directions in the latent space of generative models. We identify two key properties, independence and continuity, that convert the latent space into a precise and analysis-friendly input space representation for certification. GCERT can be smoothly integrated with de facto complete, incomplete, or quantitative certification frameworks. With its precise input space representation, GCERT enables for the first time complete NN robustness certification with moderate cost under diverse semantic-level input mutations, such as weather-filter, style transfer, and perceptual changes (e.g., opening/closing eyes). We show that GCERT enables certifying NN robustness under various common and security-sensitive scenarios like autonomous driving.
Simultaneous Temperature and Acoustic Sensing with Coherent Correlation OTDR
May 26, 2023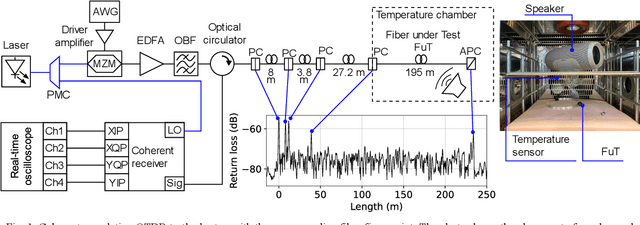
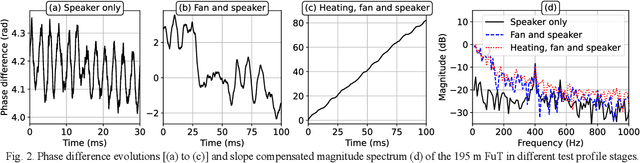
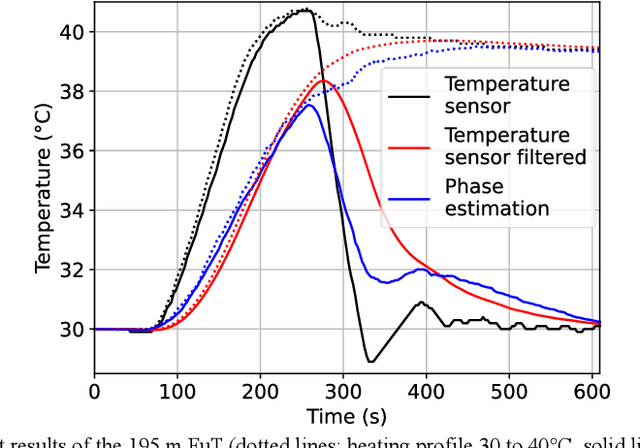
Superimposed temperature variations and dynamic strain applied through a 400 Hz acoustic signal on a 195 m single-mode fiber section are successfully measured using a coherent correlation optical time domain reflectometry as an interrogator.
* This work was partially funded by the German Federal Ministry of Education and Research in the framework of the RUBIN project Quantifisens (Project ID 03RU1U071D)
Optimal Sampling Designs for Multi-dimensional Streaming Time Series with Application to Power Grid Sensor Data
Mar 14, 2023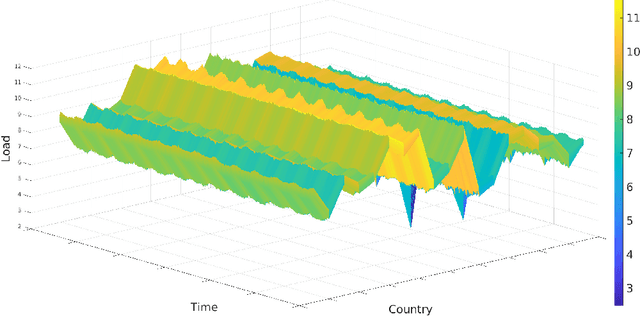
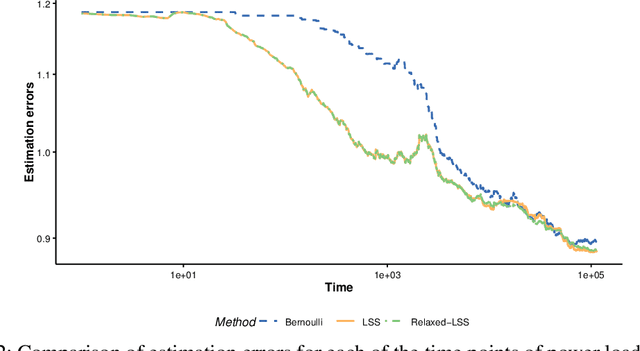
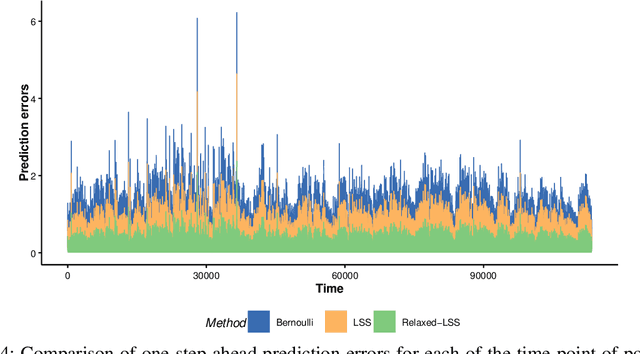
The Internet of Things (IoT) system generates massive high-speed temporally correlated streaming data and is often connected with online inference tasks under computational or energy constraints. Online analysis of these streaming time series data often faces a trade-off between statistical efficiency and computational cost. One important approach to balance this trade-off is sampling, where only a small portion of the sample is selected for the model fitting and update. Motivated by the demands of dynamic relationship analysis of IoT system, we study the data-dependent sample selection and online inference problem for a multi-dimensional streaming time series, aiming to provide low-cost real-time analysis of high-speed power grid electricity consumption data. Inspired by D-optimality criterion in design of experiments, we propose a class of online data reduction methods that achieve an optimal sampling criterion and improve the computational efficiency of the online analysis. We show that the optimal solution amounts to a strategy that is a mixture of Bernoulli sampling and leverage score sampling. The leverage score sampling involves auxiliary estimations that have a computational advantage over recursive least squares updates. Theoretical properties of the auxiliary estimations involved are also discussed. When applied to European power grid consumption data, the proposed leverage score based sampling methods outperform the benchmark sampling method in online estimation and prediction. The general applicability of the sampling-assisted online estimation method is assessed via simulation studies.