 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Expressivity of Graph Neural Networks using Localization
May 31, 2023
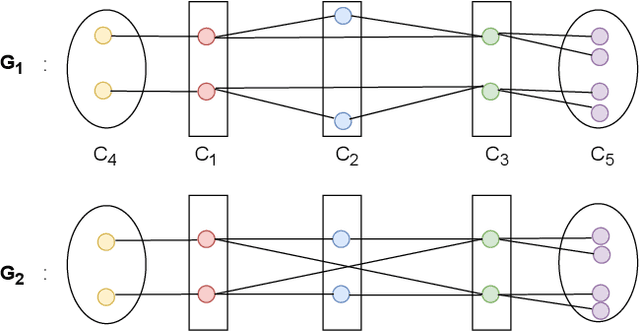


In this paper, we propose localized versions of Weisfeiler-Leman (WL) algorithms in an effort to both increase the expressivity, as well as decrease the computational overhead. We focus on the specific problem of subgraph counting and give localized versions of $k-$WL for any $k$. We analyze the power of Local $k-$WL and prove that it is more expressive than $k-$WL and at most as expressive as $(k+1)-$WL. We give a characterization of patterns whose count as a subgraph and induced subgraph are invariant if two graphs are Local $k-$WL equivalent. We also introduce two variants of $k-$WL: Layer $k-$WL and recursive $k-$WL. These methods are more time and space efficient than applying $k-$WL on the whole graph. We also propose a fragmentation technique that guarantees the exact count of all induced subgraphs of size at most 4 using just $1-$WL. The same idea can be extended further for larger patterns using $k>1$. We also compare the expressive power of Local $k-$WL with other GNN hierarchies and show that given a bound on the time-complexity, our methods are more expressive than the ones mentioned in Papp and Wattenhofer[2022a].
Empowering Business Transformation: The Positive Impact and Ethical Considerations of Generative AI in Software Product Management -- A Systematic Literature Review
Jun 05, 2023
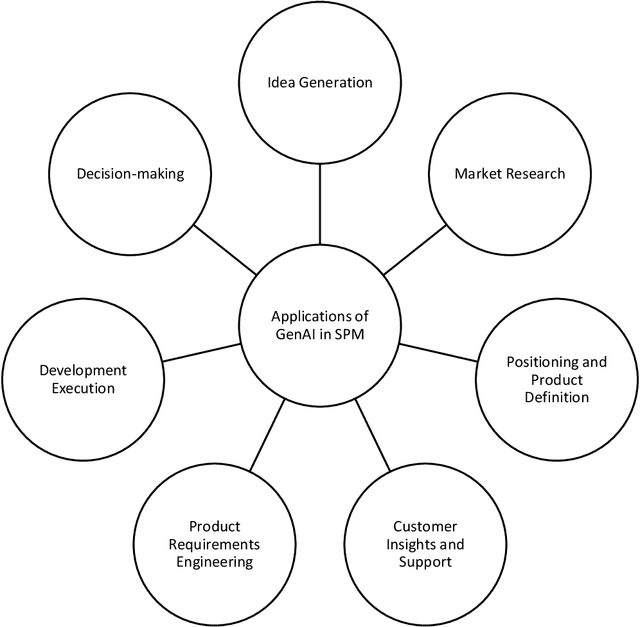
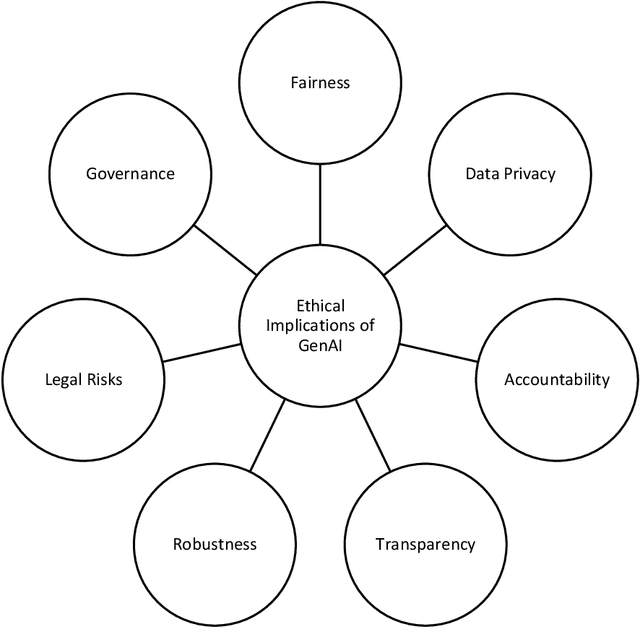
Generative Artificial Intelligence (GAI) has made outstanding strides in recent years, with a good-sized impact on software product management. Drawing on pertinent articles from 2016 to 2023, this systematic literature evaluation reveals generative AI's potential applications, benefits, and constraints in this area. The study shows that technology can assist in idea generation, market research, customer insights, product requirements engineering, and product development. It can help reduce development time and costs through automatic code generation, customer feedback analysis, and more. However, the technology's accuracy, reliability, and ethical consideration persist. Ultimately, generative AI's practical application can significantly improve software product management activities, leading to more efficient use of resources, better product outcomes, and improved end-user experiences.
MCTS: A Multi-Reference Chinese Text Simplification Dataset
Jun 05, 2023
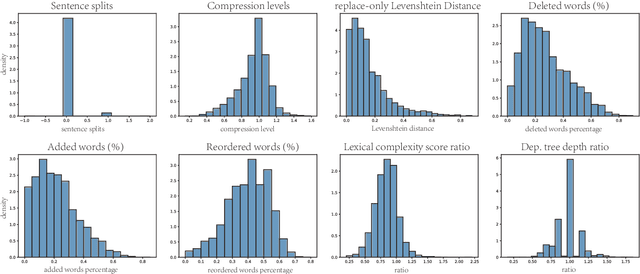
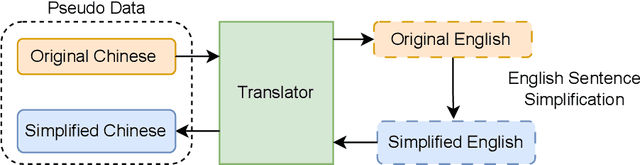

Text simplification aims to make the text easier to understand by applying rewriting transformations. There has been very little research on Chinese text simplification for a long time. The lack of generic evaluation data is an essential reason for this phenomenon. In this paper, we introduce MCTS, a multi-reference Chinese text simplification dataset. We describe the annotation process of the dataset and provide a detailed analysis of it. Furthermore, we evaluate the performance of some unsupervised methods and advanced large language models. We hope to build a basic understanding of Chinese text simplification through the foundational work and provide references for future research. We release our data at https://github.com/blcuicall/mcts.
Efficient Deep Learning of Robust Policies from MPC using Imitation and Tube-Guided Data Augmentation
Jun 01, 2023
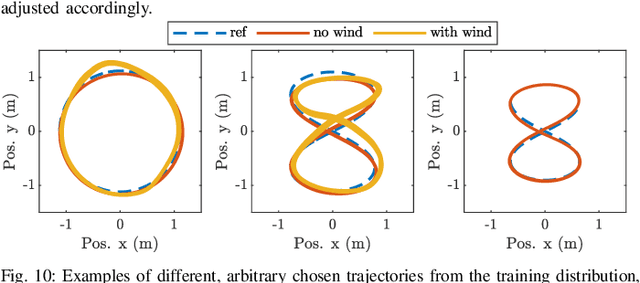
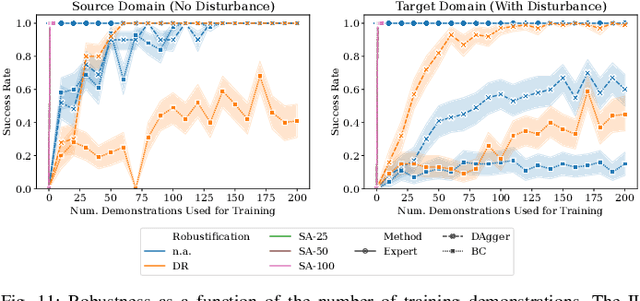
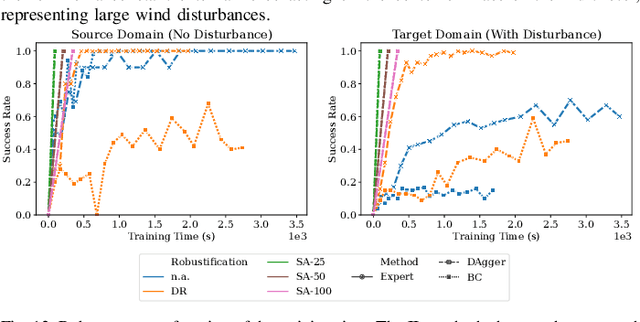
Imitation Learning (IL) has been increasingly employed to generate computationally efficient policies from task-relevant demonstrations provided by Model Predictive Control (MPC). However, commonly employed IL methods are often data- and computationally-inefficient, as they require a large number of MPC demonstrations, resulting in long training times, and they produce policies with limited robustness to disturbances not experienced during training. In this work, we propose an IL strategy to efficiently compress a computationally expensive MPC into a Deep Neural Network (DNN) policy that is robust to previously unseen disturbances. By using a robust variant of the MPC, called Robust Tube MPC (RTMPC), and leveraging properties from the controller, we introduce a computationally-efficient Data Aggregation (DA) method that enables a significant reduction of the number of MPC demonstrations and training time required to generate a robust policy. Our approach opens the possibility of zero-shot transfer of a policy trained from a single MPC demonstration collected in a nominal domain, such as a simulation or a robot in a lab/controlled environment, to a new domain with previously-unseen bounded model errors/perturbations. Numerical and experimental evaluations performed using linear and nonlinear MPC for agile flight on a multirotor show that our method outperforms strategies commonly employed in IL (such as DAgger and DR) in terms of demonstration-efficiency, training time, and robustness to perturbations unseen during training.
CRAP: Clutter Removal with Acquisitions Under Phase Noise
Jun 01, 2023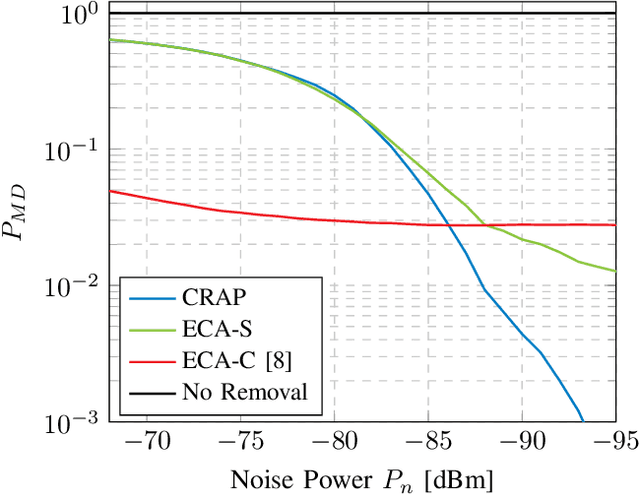
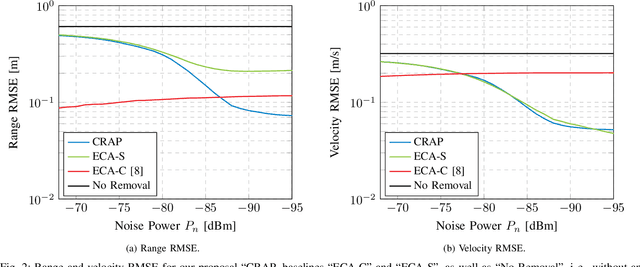
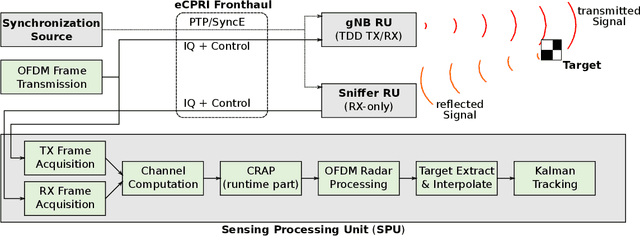

The emergence of Integrated Sensing and Communication (ISAC) in future 6G networks comes with a variety of challenges to be solved. One of those is clutter removal, which should be applied to remove the influence of unwanted components, scattered by the environment, in the acquired sensing signal. While legacy radar systems already implement different clutter removal algorithms, ISAC requires techniques that are tailored to the envisioned use cases and the specific challenges that communications deployments bring along, like phase noise due to clock errors between transmitter and receiver. To that end, in this work we introduce Clutter Removal with Acquisitions Under Phase Noise (CRAP). We propose to vectorize the time-frequency channel acquired in a radio frame in a high-dimensional space. In an offline clutter acquisition step, singular value decomposition is used to determine the major clutter components. At runtime, the clutter is then estimated and removed by a subspace projection of the acquired radio frame onto the clutter components. Simulation results prove that CRAP offers benefits over prior art techniques robust to phase noise. In particular, our proposal does not suppress zero Doppler information, thereby enabling the detection of slow targets. Moreover, we show CRAP's real-time applicability in a millimeter-wave ISAC proof of concept, where a pedestrian is tracked in a cluttered lab environment.
Time-uniform confidence bands for the CDF under nonstationarity
Feb 28, 2023
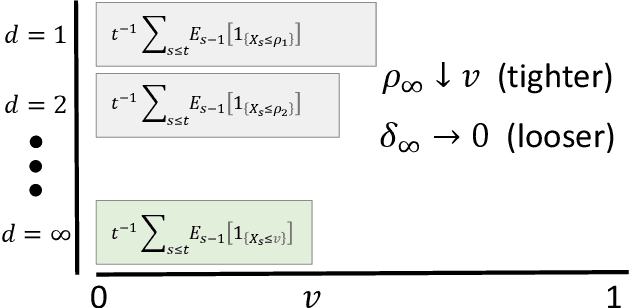
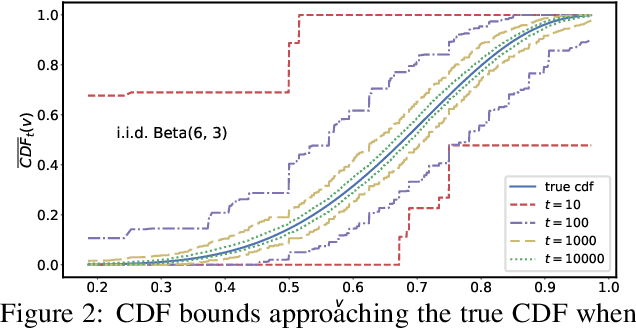
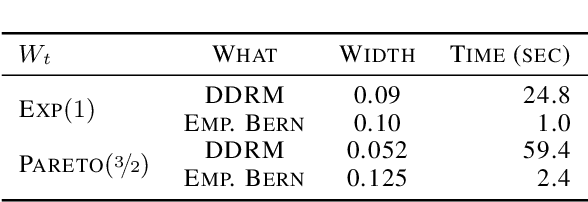
Estimation of the complete distribution of a random variable is a useful primitive for both manual and automated decision making. This problem has received extensive attention in the i.i.d. setting, but the arbitrary data dependent setting remains largely unaddressed. Consistent with known impossibility results, we present computationally felicitous time-uniform and value-uniform bounds on the CDF of the running averaged conditional distribution of a real-valued random variable which are always valid and sometimes trivial, along with an instance-dependent convergence guarantee. The importance-weighted extension is appropriate for estimating complete counterfactual distributions of rewards given controlled experimentation data exhaust, e.g., from an A/B test or a contextual bandit.
Spatially Resolved Gene Expression Prediction from H&E Histology Images via Bi-modal Contrastive Learning
Jun 02, 2023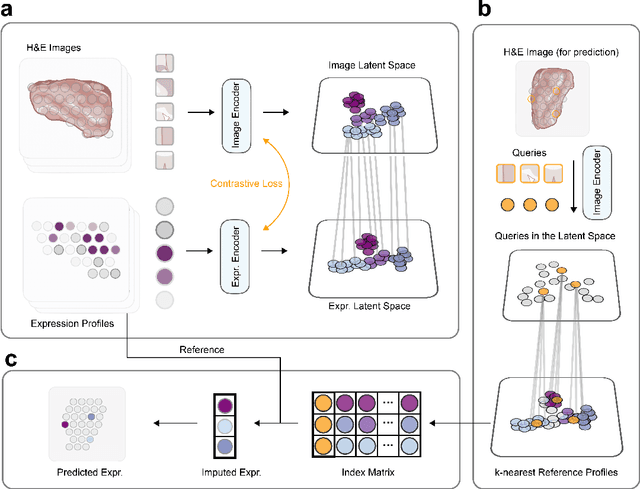
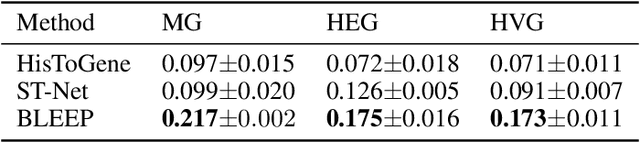
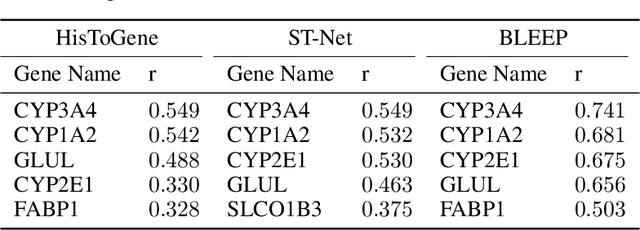
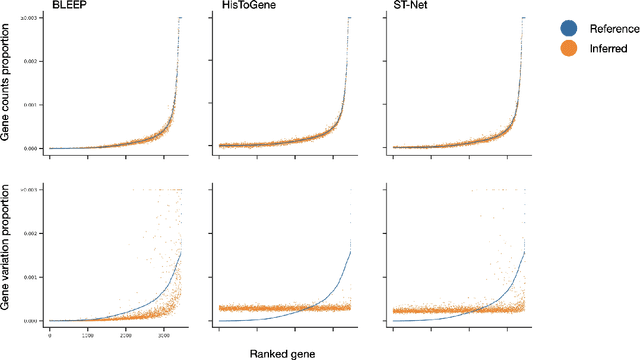
Histology imaging is an important tool in medical diagnosis and research, enabling the examination of tissue structure and composition at the microscopic level. Understanding the underlying molecular mechanisms of tissue architecture is critical in uncovering disease mechanisms and developing effective treatments. Gene expression profiling provides insight into the molecular processes underlying tissue architecture, but the process can be time-consuming and expensive. In this study, we present BLEEP (Bi-modaL Embedding for Expression Prediction), a bi-modal embedding framework capable of generating spatially resolved gene expression profiles of whole-slide Hematoxylin and eosin (H&E) stained histology images. BLEEP uses a contrastive learning framework to construct a low-dimensional joint embedding space from a reference dataset using paired image and expression profiles at micrometer resolution. With this framework, the gene expression of any query image patch can be imputed using the expression profiles from the reference dataset. We demonstrate BLEEP's effectiveness in gene expression prediction by benchmarking its performance on a human liver tissue dataset captured via the 10x Visium platform, where it achieves significant improvements over existing methods. Our results demonstrate the potential of BLEEP to provide insights into the molecular mechanisms underlying tissue architecture, with important implications in diagnosis and research of various diseases. The proposed framework can significantly reduce the time and cost associated with gene expression profiling, opening up new avenues for high-throughput analysis of histology images for both research and clinical applications.
GlyphNet: Homoglyph domains dataset and detection using attention-based Convolutional Neural Networks
Jun 17, 2023


Cyber attacks deceive machines into believing something that does not exist in the first place. However, there are some to which even humans fall prey. One such famous attack that attackers have used over the years to exploit the vulnerability of vision is known to be a Homoglyph attack. It employs a primary yet effective mechanism to create illegitimate domains that are hard to differentiate from legit ones. Moreover, as the difference is pretty indistinguishable for a user to notice, they cannot stop themselves from clicking on these homoglyph domain names. In many cases, that results in either information theft or malware attack on their systems. Existing approaches use simple, string-based comparison techniques applied in primary language-based tasks. Although they are impactful to some extent, they usually fail because they are not robust to different types of homoglyphs and are computationally not feasible because of their time requirement proportional to the string length. Similarly, neural network-based approaches are employed to determine real domain strings from fake ones. Nevertheless, the problem with both methods is that they require paired sequences of real and fake domain strings to work with, which is often not the case in the real world, as the attacker only sends the illegitimate or homoglyph domain to the vulnerable user. Therefore, existing approaches are not suitable for practical scenarios in the real world. In our work, we created GlyphNet, an image dataset that contains 4M domains, both real and homoglyphs. Additionally, we introduce a baseline method for a homoglyph attack detection system using an attention-based convolutional Neural Network. We show that our model can reach state-of-the-art accuracy in detecting homoglyph attacks with a 0.93 AUC on our dataset.
NBMOD: Find It and Grasp It in Noisy Background
Jun 17, 2023



Grasping objects is a fundamental yet important capability of robots, and many tasks such as sorting and picking rely on this skill. The prerequisite for stable grasping is the ability to correctly identify suitable grasping positions. However, finding appropriate grasping points is challenging due to the diverse shapes, varying density distributions, and significant differences between the barycenter of various objects. In the past few years, researchers have proposed many methods to address the above-mentioned issues and achieved very good results on publicly available datasets such as the Cornell dataset and the Jacquard dataset. The problem is that the backgrounds of Cornell and Jacquard datasets are relatively simple - typically just a whiteboard, while in real-world operational environments, the background could be complex and noisy. Moreover, in real-world scenarios, robots usually only need to grasp fixed types of objects. To address the aforementioned issues, we proposed a large-scale grasp detection dataset called NBMOD: Noisy Background Multi-Object Dataset for grasp detection, which consists of 31,500 RGB-D images of 20 different types of fruits. Accurate prediction of angles has always been a challenging problem in the detection task of oriented bounding boxes. This paper presents a Rotation Anchor Mechanism (RAM) to address this issue. Considering the high real-time requirement of robotic systems, we propose a series of lightweight architectures called RA-GraspNet (GraspNet with Rotation Anchor): RARA (network with Rotation Anchor and Region Attention), RAST (network with Rotation Anchor and Semi Transformer), and RAGT (network with Rotation Anchor and Global Transformer) to tackle this problem. Among them, the RAGT-3/3 model achieves an accuracy of 99% on the NBMOD dataset. The NBMOD and our code are available at https://github.com/kmittle/Grasp-Detection-NBMOD.
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Feb 23, 2023
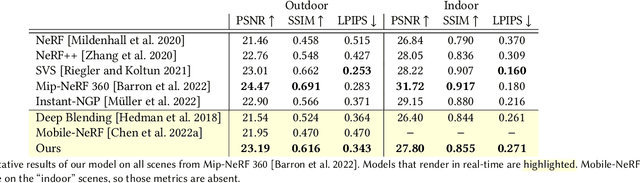
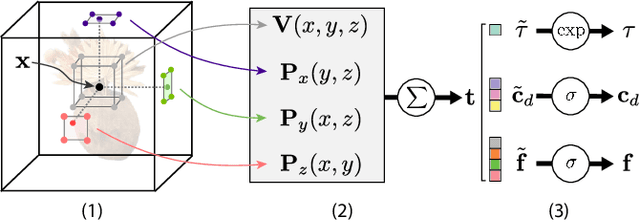
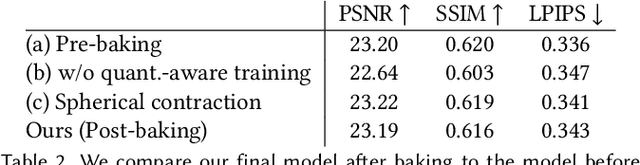
Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.