 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WaveDM: Wavelet-Based Diffusion Models for Image Restoration
May 23, 2023
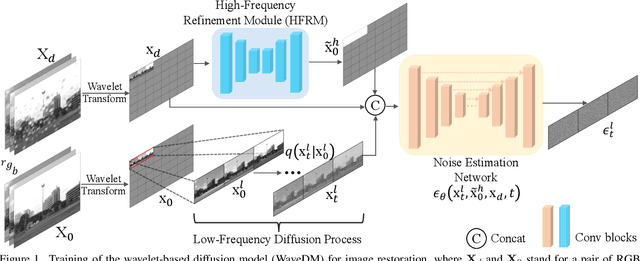
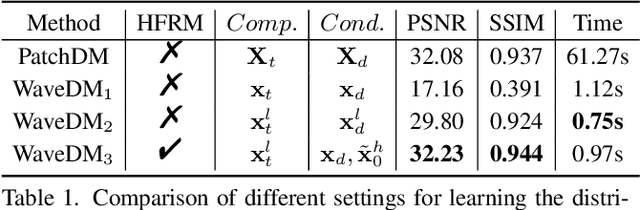
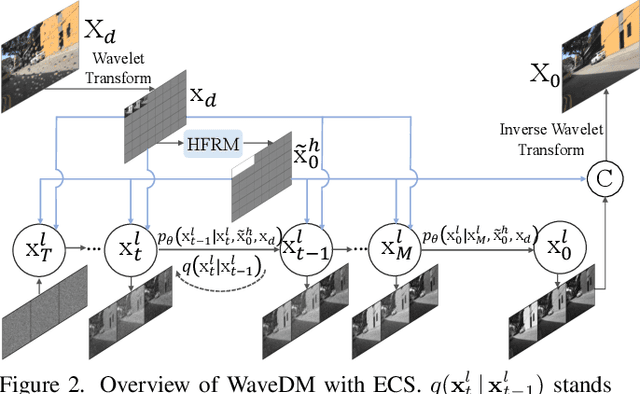
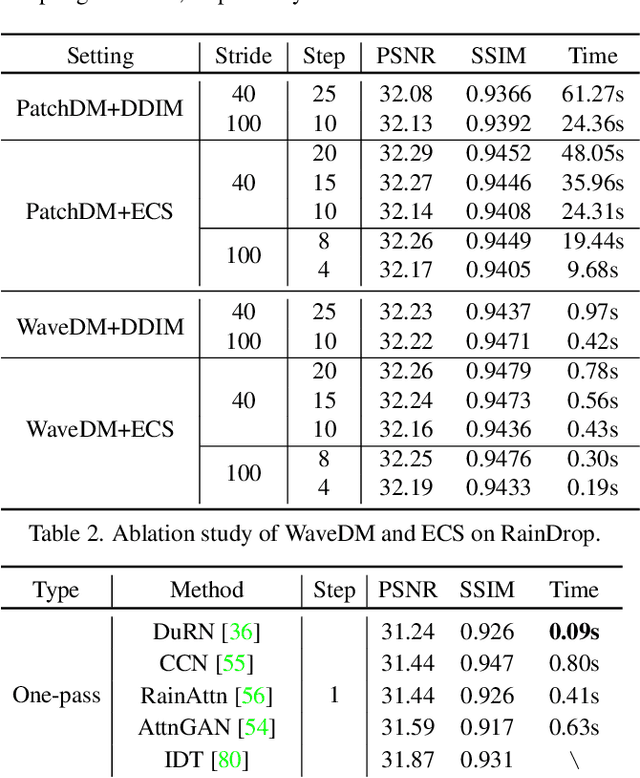
Latest diffusion-based methods for many image restoration tasks outperform traditional models, but they encounter the long-time inference problem. To tackle it, this paper proposes a Wavelet-Based Diffusion Model (WaveDM) with an Efficient Conditional Sampling (ECS) strategy. WaveDM learns the distribution of clean images in the wavelet domain conditioned on the wavelet spectrum of degraded images after wavelet transform, which is more time-saving in each step of sampling than modeling in the spatial domain. In addition, ECS follows the same procedure as the deterministic implicit sampling in the initial sampling period and then stops to predict clean images directly, which reduces the number of total sampling steps to around 5. Evaluations on four benchmark datasets including image raindrop removal, defocus deblurring, demoir\'eing, and denoising demonstrate that WaveDM achieves state-of-the-art performance with the efficiency that is comparable to traditional one-pass methods and over 100 times faster than existing image restoration methods using vanilla diffusion models.
EfficientSpeech: An On-Device Text to Speech Model
May 23, 2023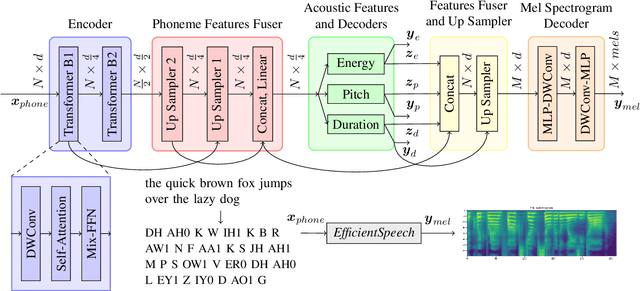
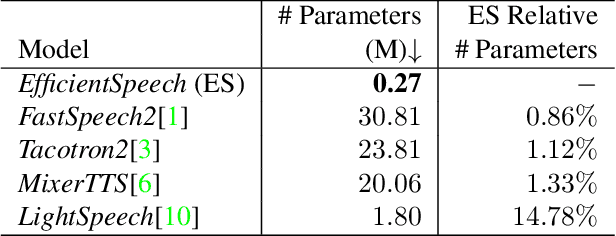
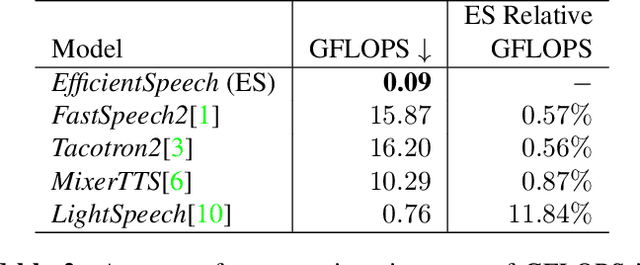
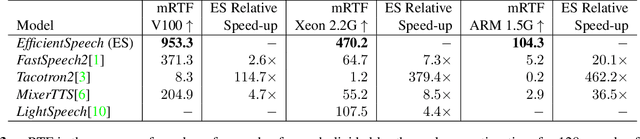
State of the art (SOTA) neural text to speech (TTS) models can generate natural-sounding synthetic voices. These models are characterized by large memory footprints and substantial number of operations due to the long-standing focus on speech quality with cloud inference in mind. Neural TTS models are generally not designed to perform standalone speech syntheses on resource-constrained and no Internet access edge devices. In this work, an efficient neural TTS called EfficientSpeech that synthesizes speech on an ARM CPU in real-time is proposed. EfficientSpeech uses a shallow non-autoregressive pyramid-structure transformer forming a U-Network. EfficientSpeech has 266k parameters and consumes 90 MFLOPS only or about 1% of the size and amount of computation in modern compact models such as Mixer-TTS. EfficientSpeech achieves an average mel generation real-time factor of 104.3 on an RPi4. Human evaluation shows only a slight degradation in audio quality as compared to FastSpeech2.
RLSS: Real-time, Decentralized, Cooperative, Networkless Multi-Robot Trajectory Planning using Linear Spatial Separations
Feb 24, 2023

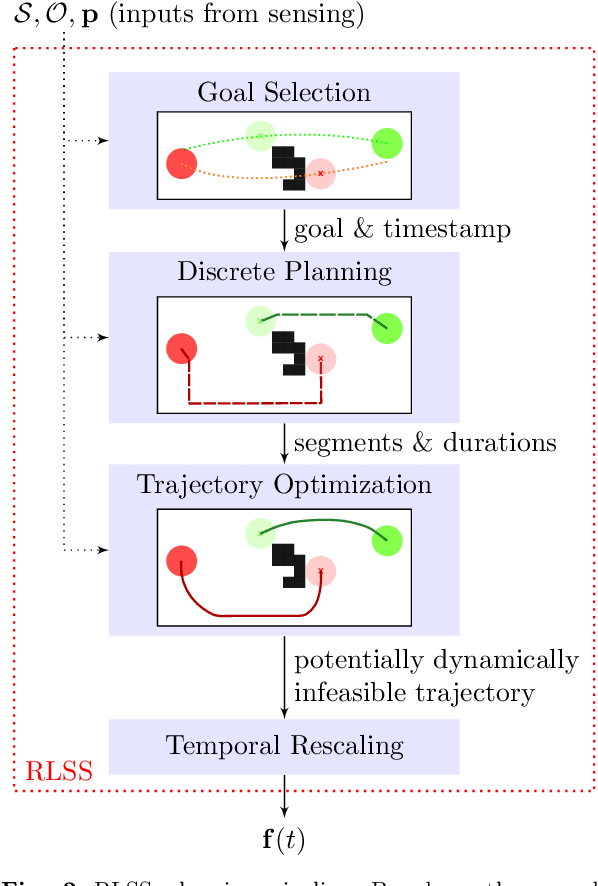

Trajectory planning for multiple robots in shared environments is a challenging problem especially when there is limited communication available or no central entity. In this article, we present Real-time planning using Linear Spatial Separations, or RLSS: a real-time decentralized trajectory planning algorithm for cooperative multi-robot teams in static environments. The algorithm requires relatively few robot capabilities, namely sensing the positions of robots and obstacles without higher-order derivatives and the ability of distinguishing robots from obstacles. There is no communication requirement and the robots' dynamic limits are taken into account. RLSS generates and solves convex quadratic optimization problems that are kinematically feasible and guarantees collision avoidance if the resulting problems are feasible. We demonstrate the algorithm's performance in real-time in simulations and on physical robots. We compare RLSS to two state-of-the-art planners and show empirically that RLSS does avoid deadlocks and collisions in forest-like and maze-like environments, significantly improving prior work, which result in collisions and deadlocks in such environments.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023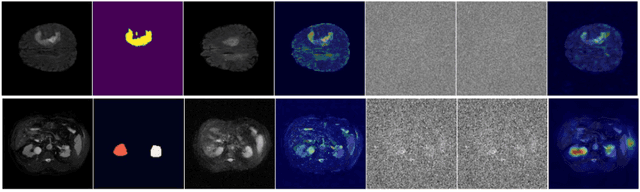
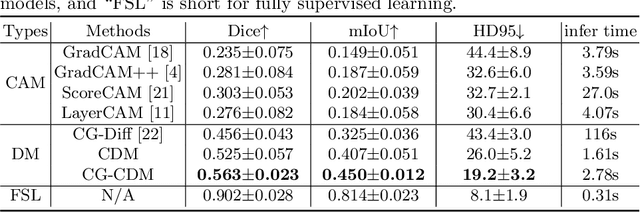
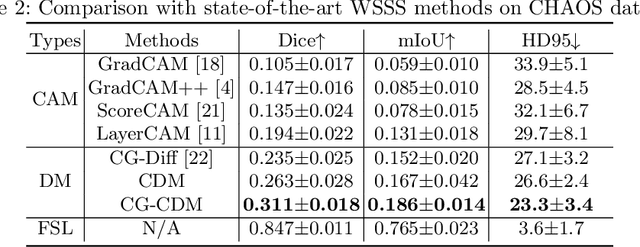

Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.
An Empirical Analysis of Parameter-Efficient Methods for Debiasing Pre-Trained Language Models
Jun 06, 2023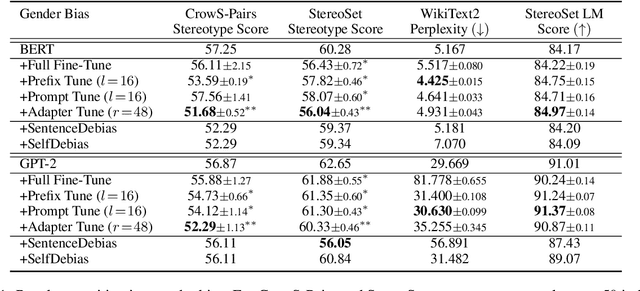
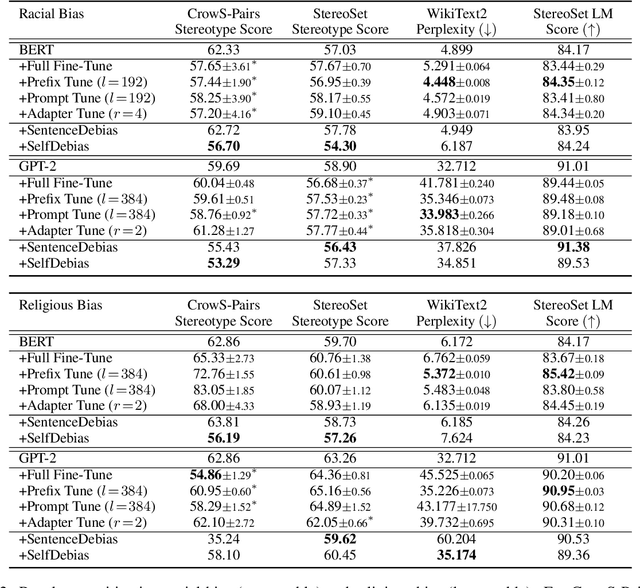
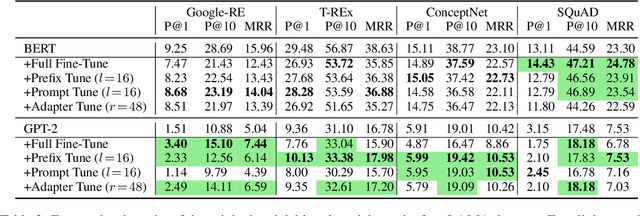
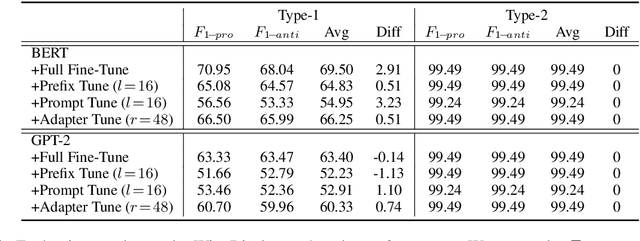
The increasingly large size of modern pretrained language models not only makes them inherit more human-like biases from the training corpora, but also makes it computationally expensive to mitigate such biases. In this paper, we investigate recent parameter-efficient methods in combination with counterfactual data augmentation (CDA) for bias mitigation. We conduct extensive experiments with prefix tuning, prompt tuning, and adapter tuning on different language models and bias types to evaluate their debiasing performance and abilities to preserve the internal knowledge of a pre-trained model. We find that the parameter-efficient methods (i) are effective in mitigating gender bias, where adapter tuning is consistently the most effective one and prompt tuning is more suitable for GPT-2 than BERT, (ii) are less effective when it comes to racial and religious bias, which may be attributed to the limitations of CDA, and (iii) can perform similarly to or sometimes better than full fine-tuning with improved time and memory efficiency, as well as maintain the internal knowledge in BERT and GPT-2, evaluated via fact retrieval and downstream fine-tuning.
Hiding in Plain Sight: Disguising Data Stealing Attacks in Federated Learning
Jun 06, 2023
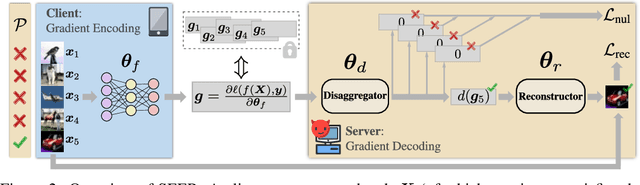
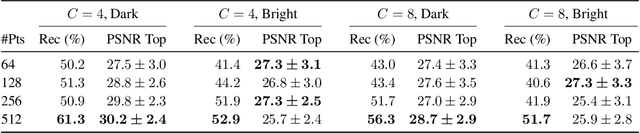

Malicious server (MS) attacks have enabled the scaling of data stealing in federated learning to large batch sizes and secure aggregation, settings previously considered private. However, many concerns regarding client-side detectability of MS attacks were raised, questioning their practicality once they are publicly known. In this work, for the first time, we thoroughly study the problem of client-side detectability.We demonstrate that most prior MS attacks, which fundamentally rely on one of two key principles, are detectable by principled client-side checks. Further, we formulate desiderata for practical MS attacks and propose SEER, a novel attack framework that satisfies all desiderata, while stealing user data from gradients of realistic networks, even for large batch sizes (up to 512 in our experiments) and under secure aggregation. The key insight of SEER is the use of a secret decoder, which is jointly trained with the shared model. Our work represents a promising first step towards more principled treatment of MS attacks, paving the way for realistic data stealing that can compromise user privacy in real-world deployments.
Model Spider: Learning to Rank Pre-Trained Models Efficiently
Jun 06, 2023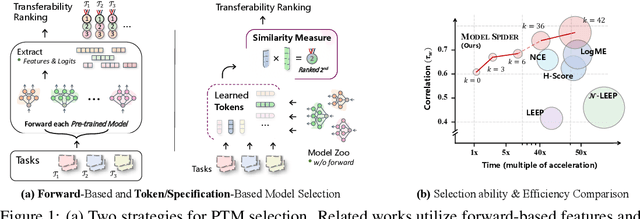
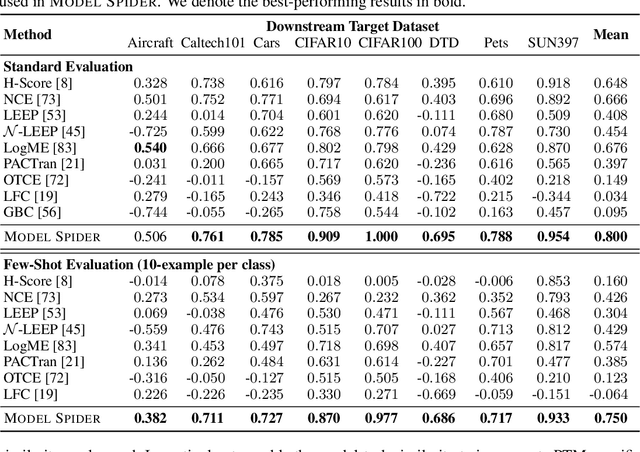
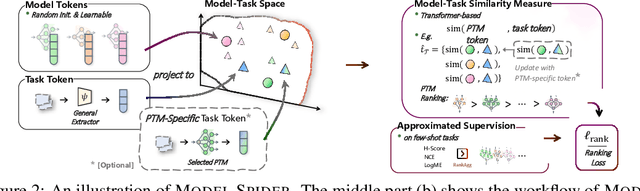
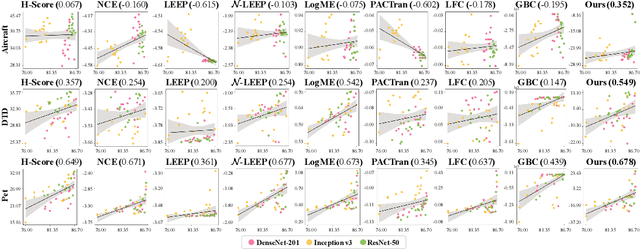
Figuring out which Pre-Trained Model (PTM) from a model zoo fits the target task is essential to take advantage of plentiful model resources. With the availability of numerous heterogeneous PTMs from diverse fields, efficiently selecting the most suitable PTM is challenging due to the time-consuming costs of carrying out forward or backward passes over all PTMs. In this paper, we propose Model Spider, which tokenizes both PTMs and tasks by summarizing their characteristics into vectors to enable efficient PTM selection. By leveraging the approximated performance of PTMs on a separate set of training tasks, Model Spider learns to construct tokens and measure the fitness score between a model-task pair via their tokens. The ability to rank relevant PTMs higher than others generalizes to new tasks. With the top-ranked PTM candidates, we further learn to enrich task tokens with their PTM-specific semantics to re-rank the PTMs for better selection. Model Spider balances efficiency and selection ability, making PTM selection like a spider preying on a web. Model Spider demonstrates promising performance in various configurations of model zoos.
Agents Explore the Environment Beyond Good Actions to Improve Their Model for Better Decisions
Jun 06, 2023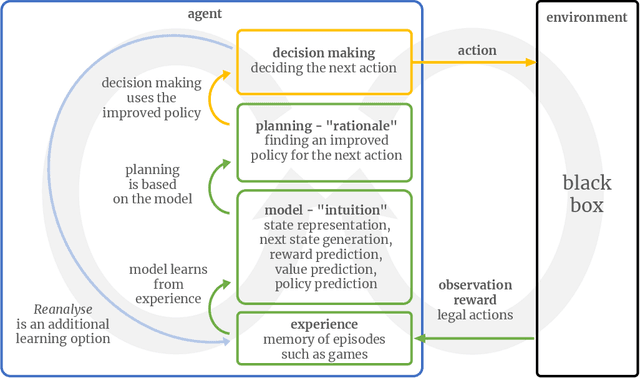


Improving the decision-making capabilities of agents is a key challenge on the road to artificial intelligence. To improve the planning skills needed to make good decisions, MuZero's agent combines prediction by a network model and planning by a tree search using the predictions. MuZero's learning process can fail when predictions are poor but planning requires them. We use this as an impetus to get the agent to explore parts of the decision tree in the environment that it otherwise would not explore. The agent achieves this, first by normal planning to come up with an improved policy. Second, it randomly deviates from this policy at the beginning of each training episode. And third, it switches back to the improved policy at a random time step to experience the rewards from the environment associated with the improved policy, which is the basis for learning the correct value expectation. The simple board game Tic-Tac-Toe is used to illustrate how this approach can improve the agent's decision-making ability. The source code, written entirely in Java, is available at https://github.com/enpasos/muzero.
VR.net: A Real-world Dataset for Virtual Reality Motion Sickness Research
Jun 06, 2023Researchers have used machine learning approaches to identify motion sickness in VR experience. These approaches demand an accurately-labeled, real-world, and diverse dataset for high accuracy and generalizability. As a starting point to address this need, we introduce `VR.net', a dataset offering approximately 12-hour gameplay videos from ten real-world games in 10 diverse genres. For each video frame, a rich set of motion sickness-related labels, such as camera/object movement, depth field, and motion flow, are accurately assigned. Building such a dataset is challenging since manual labeling would require an infeasible amount of time. Instead, we utilize a tool to automatically and precisely extract ground truth data from 3D engines' rendering pipelines without accessing VR games' source code. We illustrate the utility of VR.net through several applications, such as risk factor detection and sickness level prediction. We continuously expand VR.net and envision its next version offering 10X more data than the current form. We believe that the scale, accuracy, and diversity of VR.net can offer unparalleled opportunities for VR motion sickness research and beyond.
GSHOT: Few-shot Generative Modeling of Labeled Graphs
Jun 06, 2023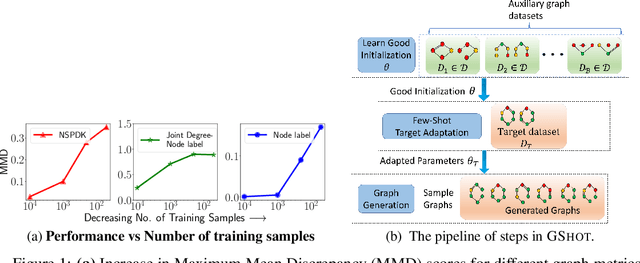
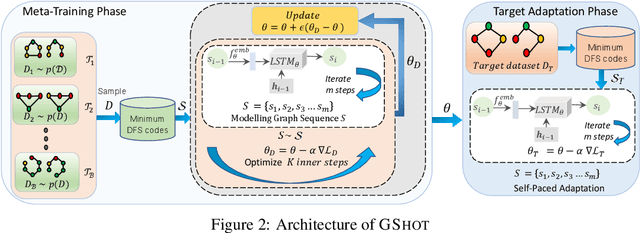
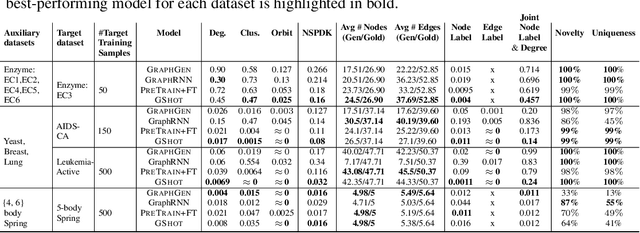
Deep graph generative modeling has gained enormous attraction in recent years due to its impressive ability to directly learn the underlying hidden graph distribution. Despite their initial success, these techniques, like much of the existing deep generative methods, require a large number of training samples to learn a good model. Unfortunately, large number of training samples may not always be available in scenarios such as drug discovery for rare diseases. At the same time, recent advances in few-shot learning have opened door to applications where available training data is limited. In this work, we introduce the hitherto unexplored paradigm of few-shot graph generative modeling. Towards this, we develop GSHOT, a meta-learning based framework for few-shot labeled graph generative modeling. GSHOT learns to transfer meta-knowledge from similar auxiliary graph datasets. Utilizing these prior experiences, GSHOT quickly adapts to an unseen graph dataset through self-paced fine-tuning. Through extensive experiments on datasets from diverse domains having limited training samples, we establish that GSHOT generates graphs of superior fidelity compared to existing baselines.