 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 18, 2024
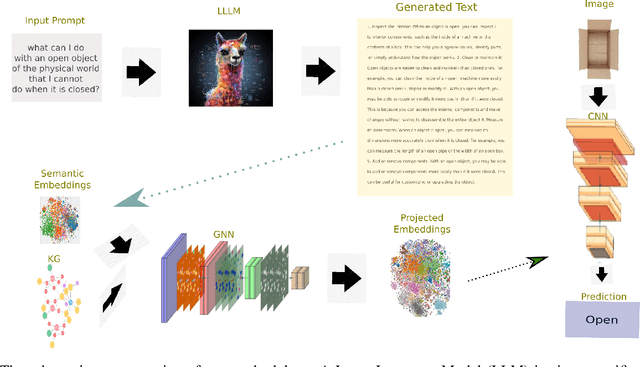


Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Learning-Based Design of Off-Policy Gaussian Controllers: Integrating Model Predictive Control and Gaussian Process Regression
Mar 16, 2024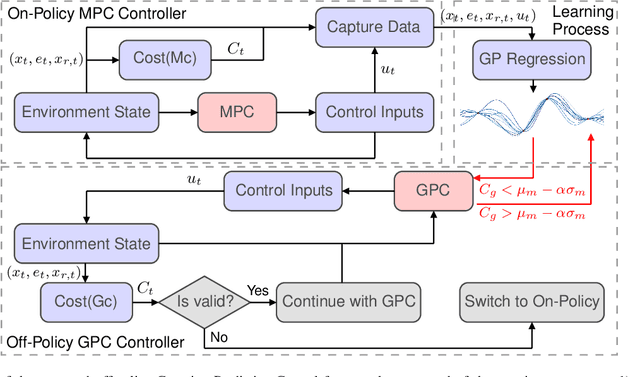

This paper presents an off-policy Gaussian Predictive Control (GPC) framework aimed at solving optimal control problems with a smaller computational footprint, thereby facilitating real-time applicability while ensuring critical safety considerations. The proposed controller imitates classical control methodologies by modeling the optimization process through a Gaussian process and employs Gaussian Process Regression to learn from the Model Predictive Control (MPC) algorithm. Notably, the Gaussian Process setup does not incorporate a built-in model, enhancing its applicability to a broad range of control problems. We applied this framework experimentally to a differential drive mobile robot, tasking it with trajectory tracking and obstacle avoidance. Leveraging the off-policy aspect, the controller demonstrated adaptability to diverse trajectories and obstacle behaviors. Simulation experiments confirmed the effectiveness of the proposed GPC method, emphasizing its ability to learn the dynamics of optimal control strategies. Consequently, our findings highlight the significant potential of off-policy Gaussian Predictive Control in achieving real-time optimal control for handling of robotic systems in safety-critical scenarios.
Independent RL for Cooperative-Competitive Agents: A Mean-Field Perspective
Mar 17, 2024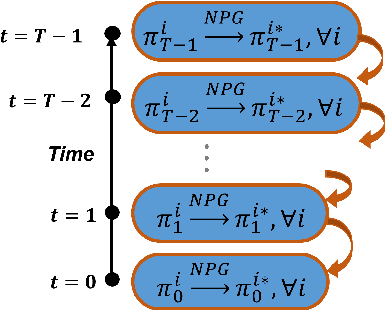
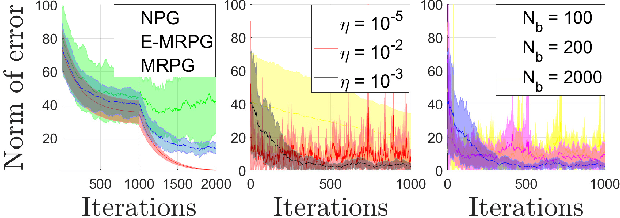
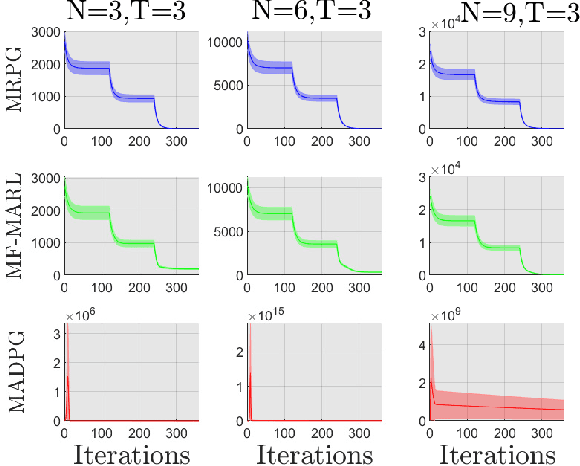
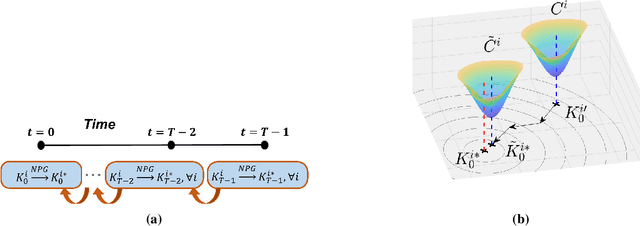
We address in this paper Reinforcement Learning (RL) among agents that are grouped into teams such that there is cooperation within each team but general-sum (non-zero sum) competition across different teams. To develop an RL method that provably achieves a Nash equilibrium, we focus on a linear-quadratic structure. Moreover, to tackle the non-stationarity induced by multi-agent interactions in the finite population setting, we consider the case where the number of agents within each team is infinite, i.e., the mean-field setting. This results in a General-Sum LQ Mean-Field Type Game (GS-MFTGs). We characterize the Nash equilibrium (NE) of the GS-MFTG, under a standard invertibility condition. This MFTG NE is then shown to be $\mathcal{O}(1/M)$-NE for the finite population game where $M$ is a lower bound on the number of agents in each team. These structural results motivate an algorithm called Multi-player Receding-horizon Natural Policy Gradient (MRPG), where each team minimizes its cumulative cost independently in a receding-horizon manner. Despite the non-convexity of the problem, we establish that the resulting algorithm converges to a global NE through a novel problem decomposition into sub-problems using backward recursive discrete-time Hamilton-Jacobi-Isaacs (HJI) equations, in which independent natural policy gradient is shown to exhibit linear convergence under time-independent diagonal dominance. Experiments illuminate the merits of this approach in practice.
Real-time Surgical Instrument Segmentation in Video Using Point Tracking and Segment Anything
Mar 12, 2024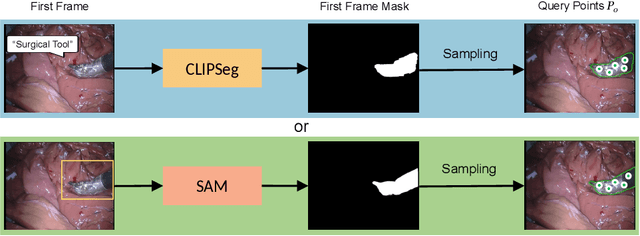
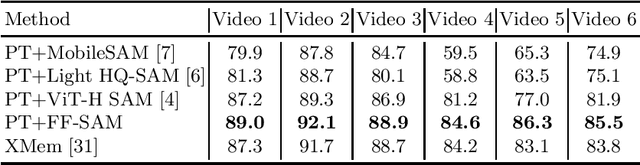
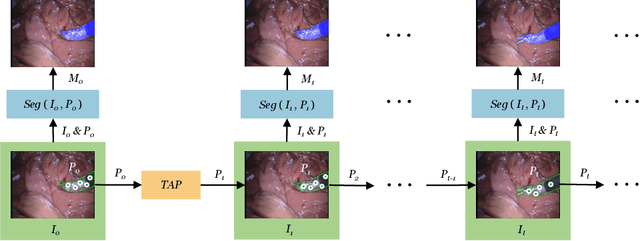
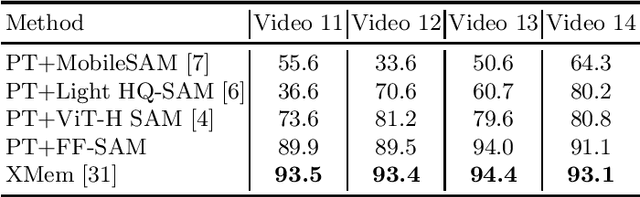
The Segment Anything Model (SAM) is a powerful vision foundation model that is revolutionizing the traditional paradigm of segmentation. Despite this, a reliance on prompting each frame and large computational cost limit its usage in robotically assisted surgery. Applications, such as augmented reality guidance, require little user intervention along with efficient inference to be usable clinically. In this study, we address these limitations by adopting lightweight SAM variants to meet the speed requirement and employing fine-tuning techniques to enhance their generalization in surgical scenes. Recent advancements in Tracking Any Point (TAP) have shown promising results in both accuracy and efficiency, particularly when points are occluded or leave the field of view. Inspired by this progress, we present a novel framework that combines an online point tracker with a lightweight SAM model that is fine-tuned for surgical instrument segmentation. Sparse points within the region of interest are tracked and used to prompt SAM throughout the video sequence, providing temporal consistency. The quantitative results surpass the state-of-the-art semi-supervised video object segmentation method on the EndoVis 2015 dataset, with an over 25 FPS inference speed running on a single GeForce RTX 4060 GPU.
Tensor Decomposition-based Time Varying Channel Estimation for mmWave MIMO-OFDM Systems
Mar 05, 2024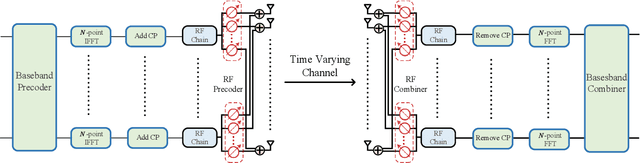
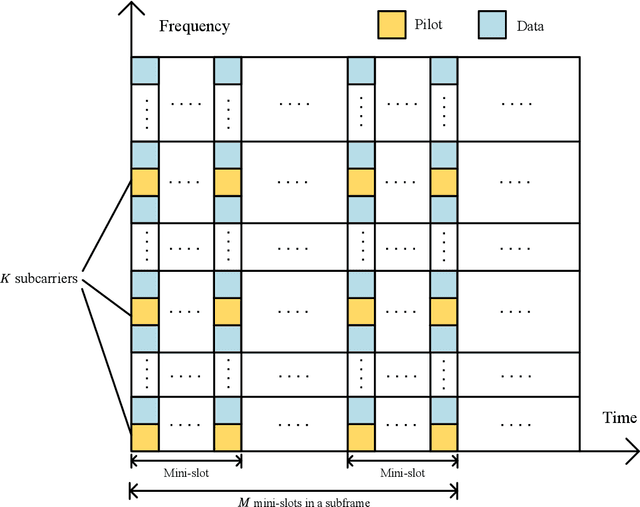
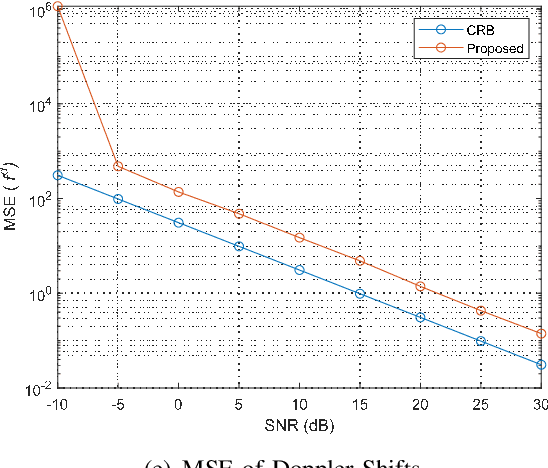
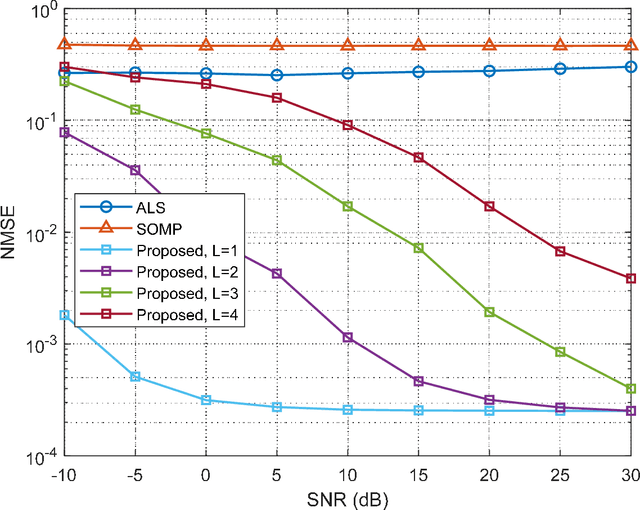
In this paper, we consider the time-varying channel estimation in millimeter wave (mmWave) multiple-input multiple-output MIMO systems with hybrid beamforming architectures. Different from the existing contributions that considered single-carrier mmWave systems with high mobility, the wideband orthogonal frequency division multiplexing (OFDM) system is considered in this work. To solve the channel estimation problem under channel double selectivity, we propose a pilot transmission scheme based on 5G OFDM, and the received signals are formed as a fourth-order tensor, which fits the low-rank CANDECOMP/PARAFAC (CP) model. By further exploring the Vandermonde structure of factor matrix, a tensor-subspace decomposition based channel estimation method is proposed to solve the CP decomposition, where the uniqueness condition is analyzed. Based on the decomposed factor matrices, the channel parameters, including angles of arrival/departure, delays, channel gains and Doppler shifts are estimated, and the Cram\'{e}r-Rao bound (CRB) results are derived as performance metrics. Simulation results demonstrate the superior performance of the proposed method over other benchmarks. Furthermore, the channel estimation methods are tested based on the channel parameters generated by Wireless InSites, and simulation results show the effectiveness of the proposed method in practical scenarios.
FaceXFormer: A Unified Transformer for Facial Analysis
Mar 19, 2024
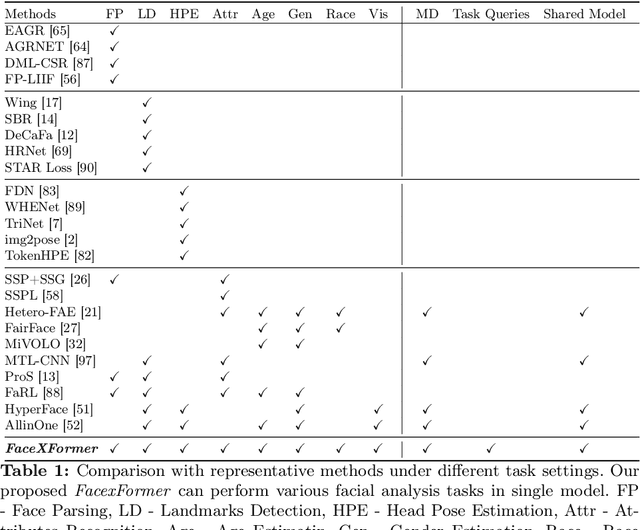
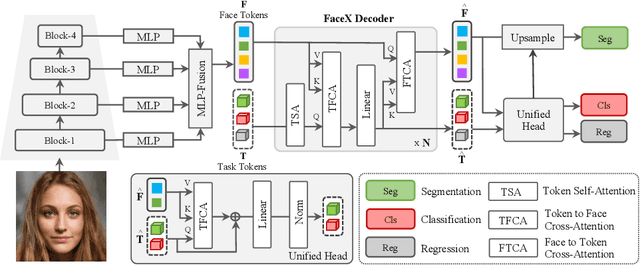
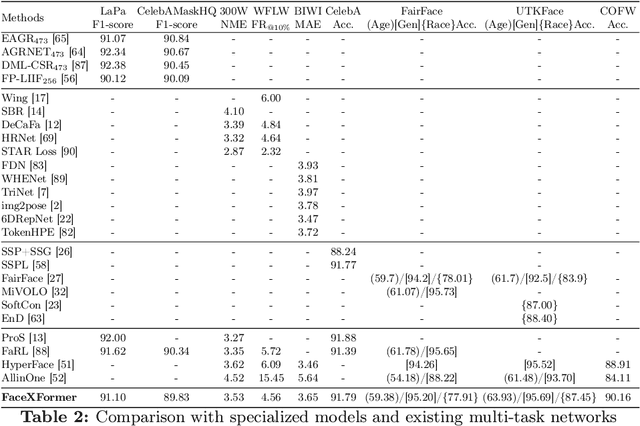
In this work, we introduce FaceXformer, an end-to-end unified transformer model for a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility. Conventional methods in face analysis have often relied on task-specific designs and preprocessing techniques, which limit their approach to a unified architecture. Unlike these conventional methods, our FaceXformer leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework. Moreover, we propose a parameter-efficient decoder, FaceX, which jointly processes face and task tokens, thereby learning generalized and robust face representations across different tasks. To the best of our knowledge, this is the first work to propose a single model capable of handling all these facial analysis tasks using transformers. We conducted a comprehensive analysis of effective backbones for unified face task processing and evaluated different task queries and the synergy between them. We conduct experiments against state-of-the-art specialized models and previous multi-task models in both intra-dataset and cross-dataset evaluations across multiple benchmarks. Additionally, our model effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight different tasks, all while maintaining the real-time performance of 37 FPS.
ExACT: Language-guided Conceptual Reasoning and Uncertainty Estimation for Event-based Action Recognition and More
Mar 19, 2024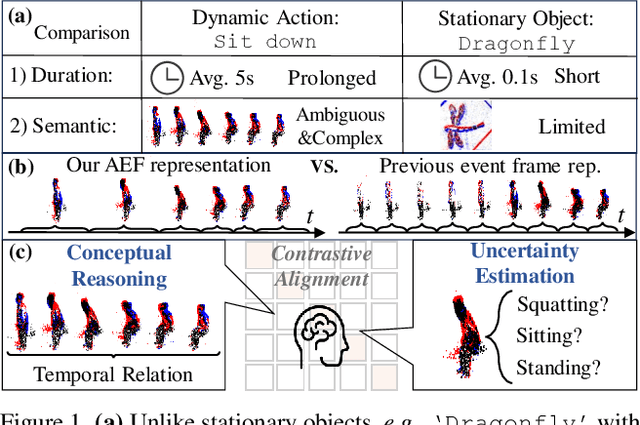
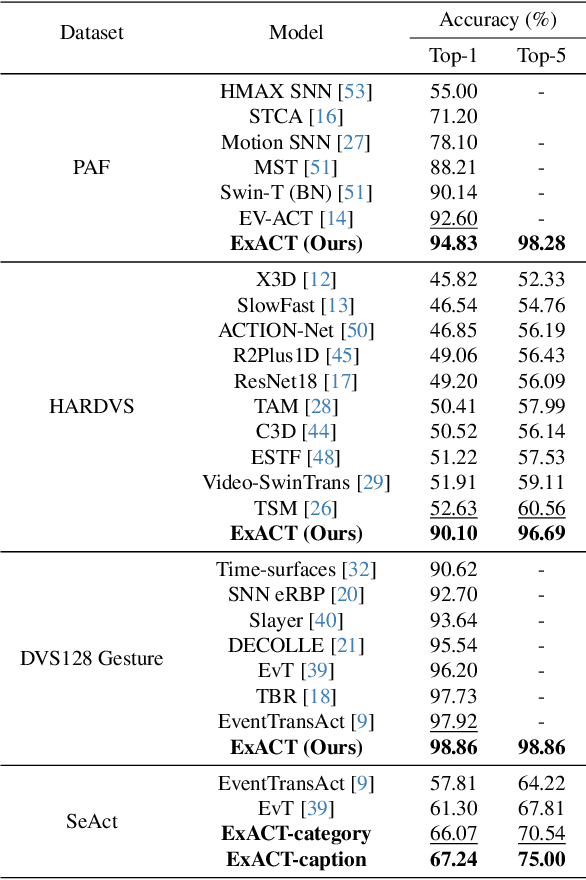
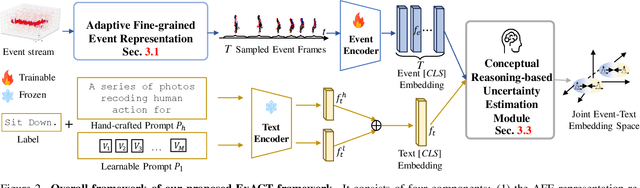
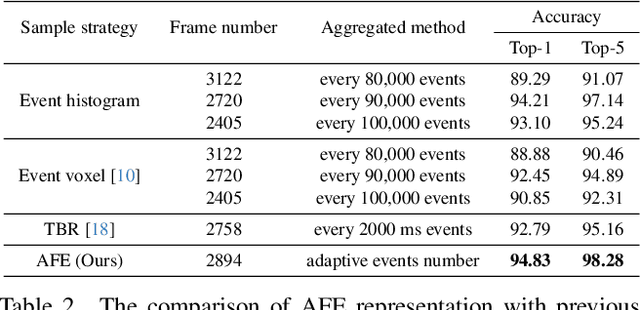
Event cameras have recently been shown beneficial for practical vision tasks, such as action recognition, thanks to their high temporal resolution, power efficiency, and reduced privacy concerns. However, current research is hindered by 1) the difficulty in processing events because of their prolonged duration and dynamic actions with complex and ambiguous semantics and 2) the redundant action depiction of the event frame representation with fixed stacks. We find language naturally conveys abundant semantic information, rendering it stunningly superior in reducing semantic uncertainty. In light of this, we propose ExACT, a novel approach that, for the first time, tackles event-based action recognition from a cross-modal conceptualizing perspective. Our ExACT brings two technical contributions. Firstly, we propose an adaptive fine-grained event (AFE) representation to adaptively filter out the repeated events for the stationary objects while preserving dynamic ones. This subtly enhances the performance of ExACT without extra computational cost. Then, we propose a conceptual reasoning-based uncertainty estimation module, which simulates the recognition process to enrich the semantic representation. In particular, conceptual reasoning builds the temporal relation based on the action semantics, and uncertainty estimation tackles the semantic uncertainty of actions based on the distributional representation. Experiments show that our ExACT achieves superior recognition accuracy of 94.83%(+2.23%), 90.10%(+37.47%) and 67.24% on PAF, HARDVS and our SeAct datasets respectively.
Approximation of RKHS Functionals by Neural Networks
Mar 18, 2024Motivated by the abundance of functional data such as time series and images, there has been a growing interest in integrating such data into neural networks and learning maps from function spaces to R (i.e., functionals). In this paper, we study the approximation of functionals on reproducing kernel Hilbert spaces (RKHS's) using neural networks. We establish the universality of the approximation of functionals on the RKHS's. Specifically, we derive explicit error bounds for those induced by inverse multiquadric, Gaussian, and Sobolev kernels. Moreover, we apply our findings to functional regression, proving that neural networks can accurately approximate the regression maps in generalized functional linear models. Existing works on functional learning require integration-type basis function expansions with a set of pre-specified basis functions. By leveraging the interpolating orthogonal projections in RKHS's, our proposed network is much simpler in that we use point evaluations to replace basis function expansions.
Reinforcement Learning from Delayed Observations via World Models
Mar 18, 2024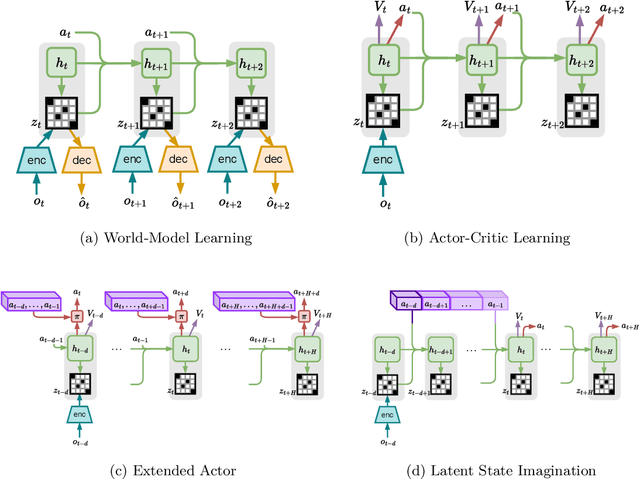
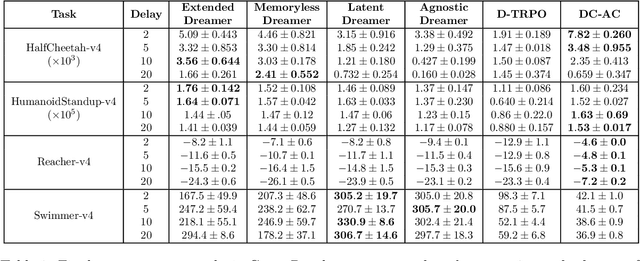
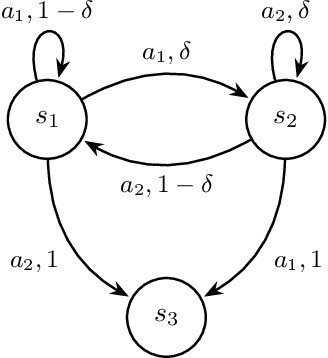
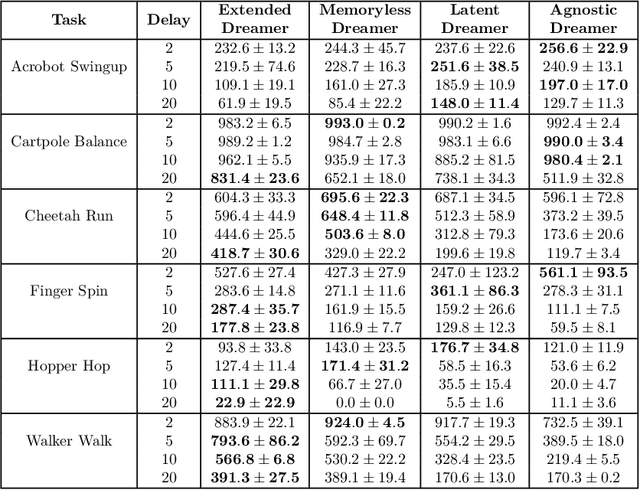
In standard Reinforcement Learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of RL algorithms. In this paper, we focus on addressing observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or even degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to %30. Moreover, we evaluate our methods on visual input based delayed environment, for the first time showcasing delay-aware reinforcement learning on visual observations.
Ricci flow-based brain surface covariance descriptors for diagnosing Alzheimer's disease
Mar 18, 2024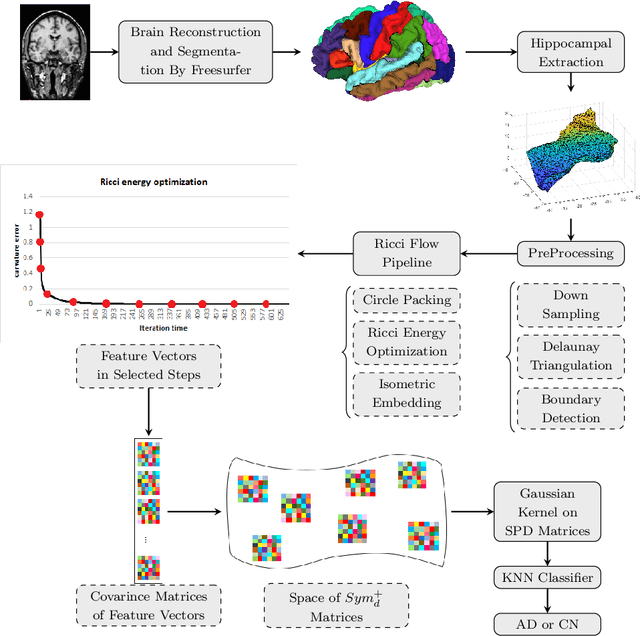
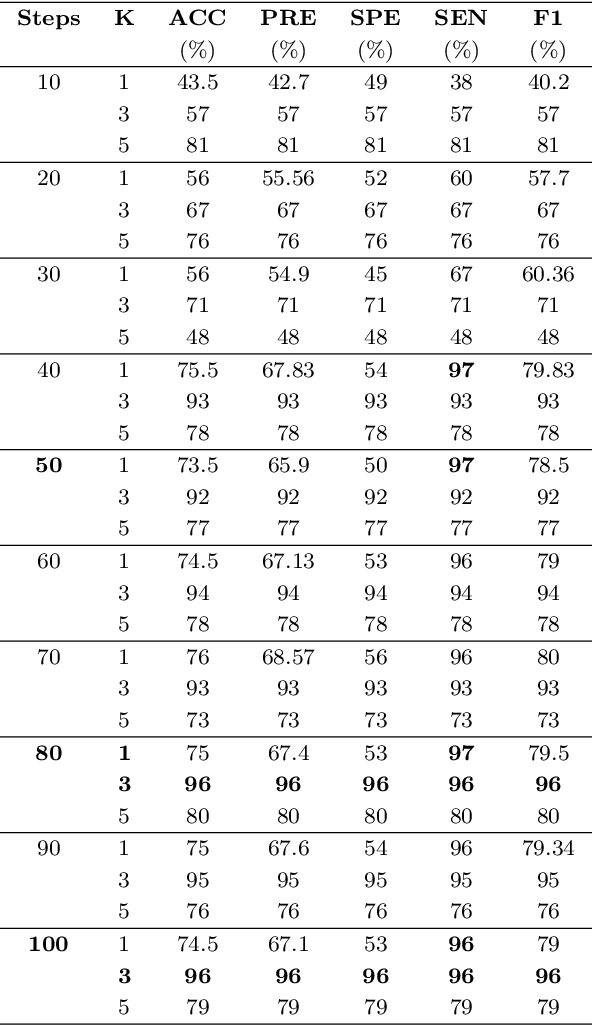
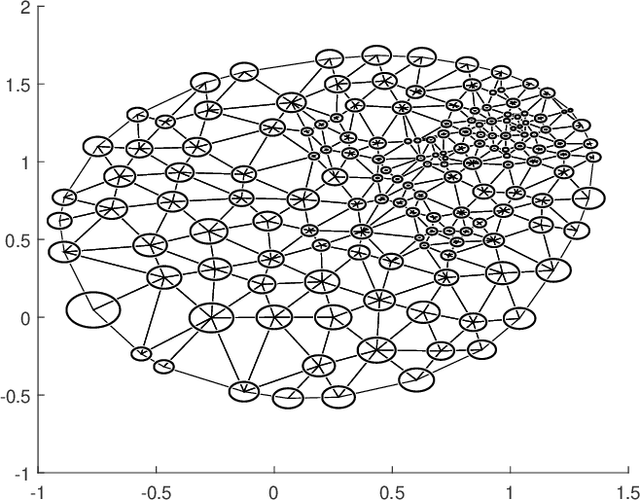

Automated feature extraction from MRI brain scans and diagnosis of Alzheimer's disease are ongoing challenges. With advances in 3D imaging technology, 3D data acquisition is becoming more viable and efficient than its 2D counterpart. Rather than using feature-based vectors, in this paper, for the first time, we suggest a pipeline to extract novel covariance-based descriptors from the cortical surface using the Ricci energy optimization. The covariance descriptors are components of the nonlinear manifold of symmetric positive-definite matrices, thus we focus on using the Gaussian radial basis function to apply manifold-based classification to the 3D shape problem. Applying this novel signature to the analysis of abnormal cortical brain morphometry allows for diagnosing Alzheimer's disease. Experimental studies performed on about two hundred 3D MRI brain models, gathered from Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate the effectiveness of our descriptors in achieving remarkable classification accuracy.