 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Efficient Membership Inference Attack for the Diffusion Model by Proximal Initialization
May 26, 2023
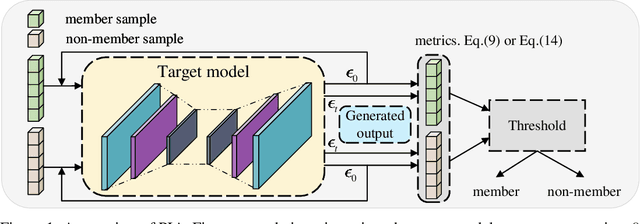
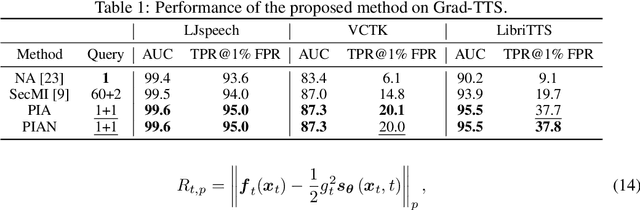
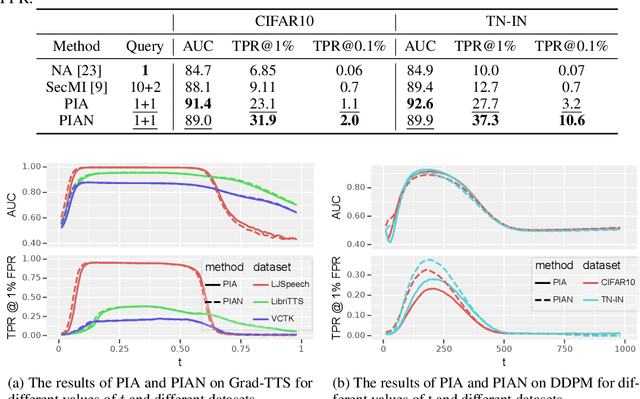
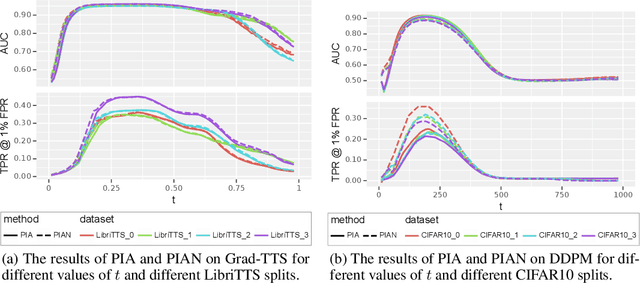
Recently, diffusion models have achieved remarkable success in generating tasks, including image and audio generation. However, like other generative models, diffusion models are prone to privacy issues. In this paper, we propose an efficient query-based membership inference attack (MIA), namely Proximal Initialization Attack (PIA), which utilizes groundtruth trajectory obtained by $\epsilon$ initialized in $t=0$ and predicted point to infer memberships. Experimental results indicate that the proposed method can achieve competitive performance with only two queries on both discrete-time and continuous-time diffusion models. Moreover, previous works on the privacy of diffusion models have focused on vision tasks without considering audio tasks. Therefore, we also explore the robustness of diffusion models to MIA in the text-to-speech (TTS) task, which is an audio generation task. To the best of our knowledge, this work is the first to study the robustness of diffusion models to MIA in the TTS task. Experimental results indicate that models with mel-spectrogram (image-like) output are vulnerable to MIA, while models with audio output are relatively robust to MIA. {Code is available at \url{https://github.com/kong13661/PIA}}.
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation
Jun 01, 2023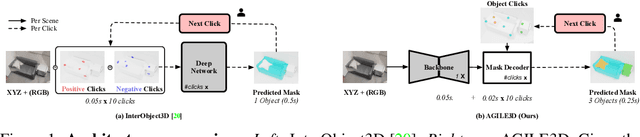
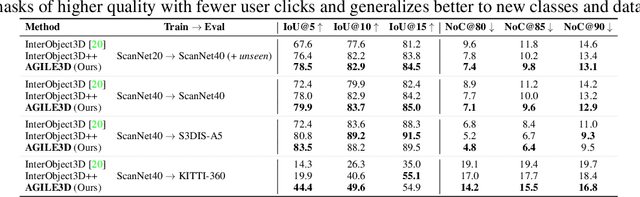
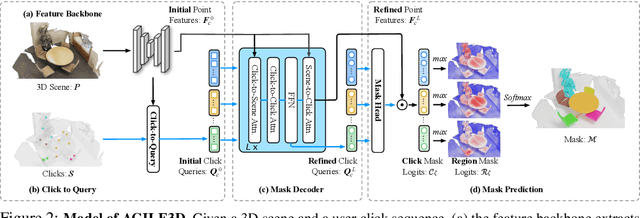
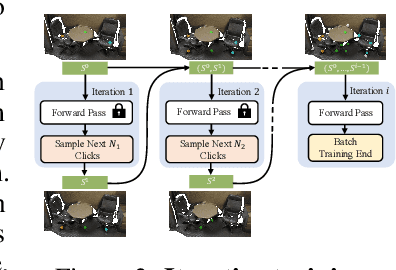
During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. From a machine learning perspective the goal is to design the model and the feedback mechanism in a way that minimizes the required user input. The current best practice segments objects one at a time, and asks the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks to indicate regions wrongly assigned to the object (foreground). Sequentially visiting objects is wasteful, since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects, moreover a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. We encode the point cloud into a latent feature representation, and view user clicks as queries and employ cross-attention to represent contextual relations between different click locations as well as between clicks and the 3D point cloud features. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different point cloud datasets, AGILE3D sets a new state of the art, moreover, we also verify its practicality in real-world setups with a real user study.
Neuromorphic Bayesian Optimization in Lava
May 18, 2023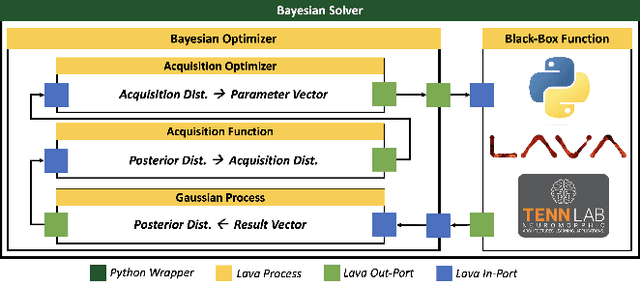

The ever-increasing demands of computationally expensive and high-dimensional problems require novel optimization methods to find near-optimal solutions in a reasonable amount of time. Bayesian Optimization (BO) stands as one of the best methodologies for learning the underlying relationships within multi-variate problems. This allows users to optimize time consuming and computationally expensive black-box functions in feasible time frames. Existing BO implementations use traditional von-Neumann architectures, in which data and memory are separate. In this work, we introduce Lava Bayesian Optimization (LavaBO) as a contribution to the open-source Lava Software Framework. LavaBO is the first step towards developing a BO system compatible with heterogeneous, fine-grained parallel, in-memory neuromorphic computing architectures (e.g., Intel's Loihi platform). We evaluate the algorithmic performance of the LavaBO system on multiple problems such as training state-of-the-art spiking neural network through back-propagation and evolutionary learning. Compared to traditional algorithms (such as grid and random search), we highlight the ability of LavaBO to explore the parameter search space with fewer expensive function evaluations, while discovering the optimal solutions.
Deep Learning for Time Series Classification and Extrinsic Regression: A Current Survey
Feb 06, 2023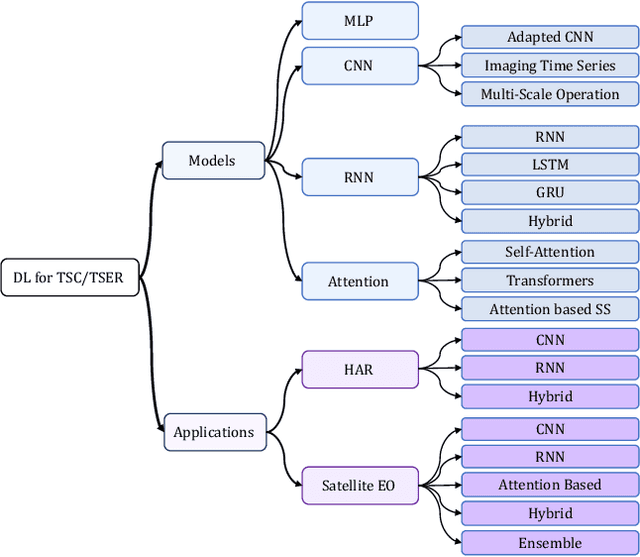
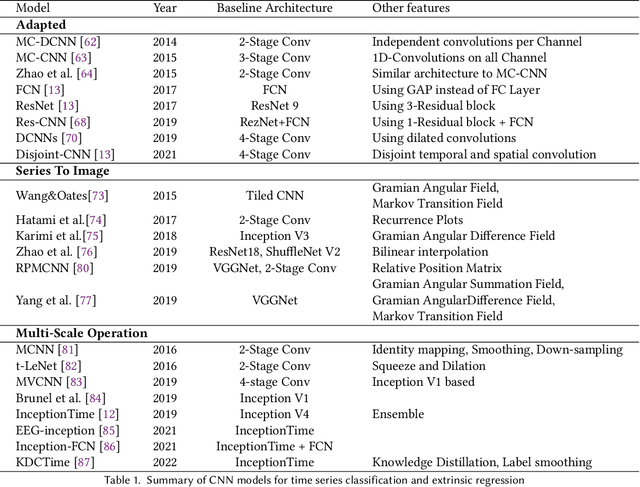
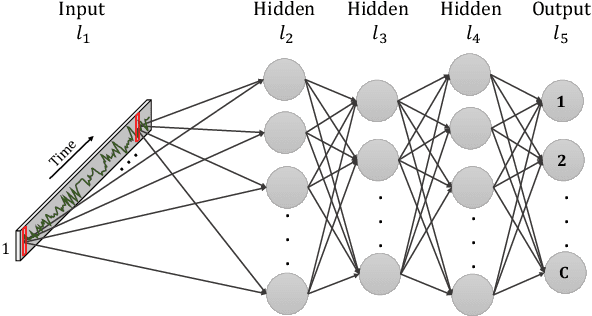
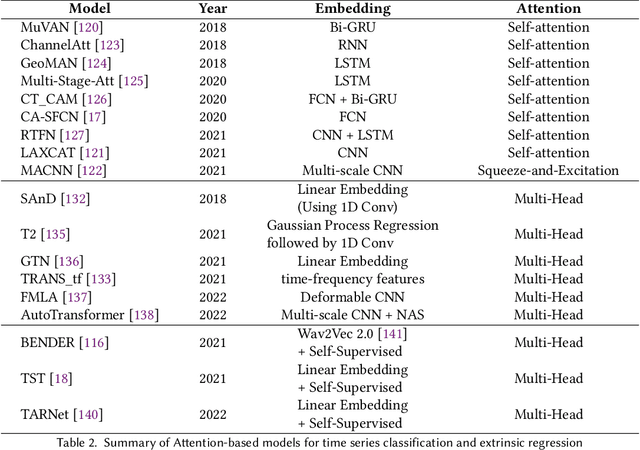
Time Series Classification and Extrinsic Regression are important and challenging machine learning tasks. Deep learning has revolutionized natural language processing and computer vision and holds great promise in other fields such as time series analysis where the relevant features must often be abstracted from the raw data but are not known a priori. This paper surveys the current state of the art in the fast-moving field of deep learning for time series classification and extrinsic regression. We review different network architectures and training methods used for these tasks and discuss the challenges and opportunities when applying deep learning to time series data. We also summarize two critical applications of time series classification and extrinsic regression, human activity recognition and satellite earth observation.
Creating Disasters: Recession Forecasting with GAN-Generated Synthetic Time Series Data
Feb 21, 2023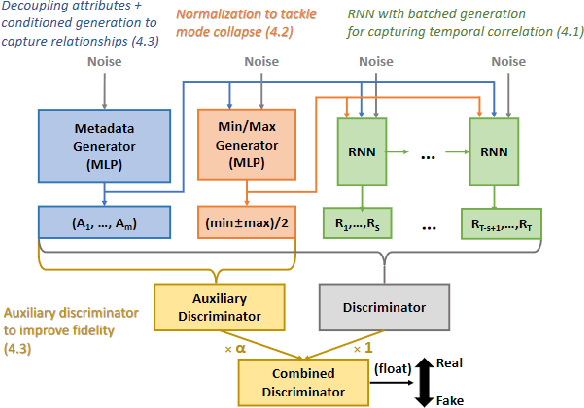
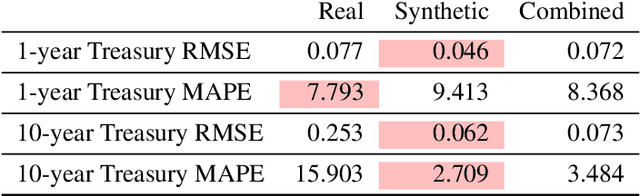
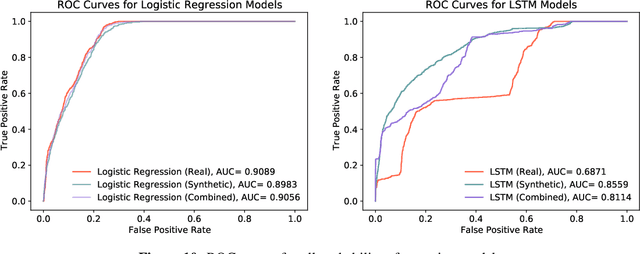
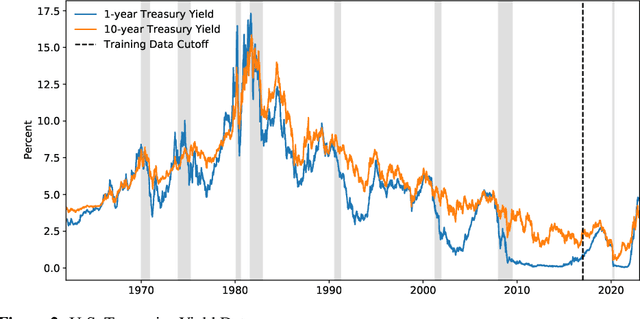
A common problem when forecasting rare events, such as recessions, is limited data availability. Recent advancements in deep learning and generative adversarial networks (GANs) make it possible to produce high-fidelity synthetic data in large quantities. This paper uses a model called DoppelGANger, a GAN tailored to producing synthetic time series data, to generate synthetic Treasury yield time series and associated recession indicators. It is then shown that short-range forecasting performance for Treasury yields is improved for models trained on synthetic data relative to models trained only on real data. Finally, synthetic recession conditions are produced and used to train classification models to predict the probability of a future recession. It is shown that training models on synthetic recessions can improve a model's ability to predict future recessions over a model trained only on real data.
Replicability in Reinforcement Learning
May 31, 2023
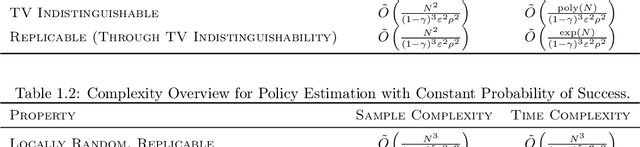
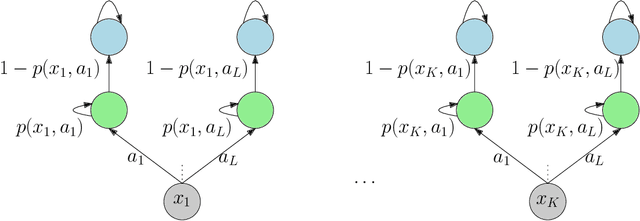
We initiate the mathematical study of replicability as an algorithmic property in the context of reinforcement learning (RL). We focus on the fundamental setting of discounted tabular MDPs with access to a generative model. Inspired by Impagliazzo et al. [2022], we say that an RL algorithm is replicable if, with high probability, it outputs the exact same policy after two executions on i.i.d. samples drawn from the generator when its internal randomness is the same. We first provide an efficient $\rho$-replicable algorithm for $(\varepsilon, \delta)$-optimal policy estimation with sample and time complexity $\widetilde O\left(\frac{N^3\cdot\log(1/\delta)}{(1-\gamma)^5\cdot\varepsilon^2\cdot\rho^2}\right)$, where $N$ is the number of state-action pairs. Next, for the subclass of deterministic algorithms, we provide a lower bound of order $\Omega\left(\frac{N^3}{(1-\gamma)^3\cdot\varepsilon^2\cdot\rho^2}\right)$. Then, we study a relaxed version of replicability proposed by Kalavasis et al. [2023] called TV indistinguishability. We design a computationally efficient TV indistinguishable algorithm for policy estimation whose sample complexity is $\widetilde O\left(\frac{N^2\cdot\log(1/\delta)}{(1-\gamma)^5\cdot\varepsilon^2\cdot\rho^2}\right)$. At the cost of $\exp(N)$ running time, we transform these TV indistinguishable algorithms to $\rho$-replicable ones without increasing their sample complexity. Finally, we introduce the notion of approximate-replicability where we only require that two outputted policies are close under an appropriate statistical divergence (e.g., Renyi) and show an improved sample complexity of $\widetilde O\left(\frac{N\cdot\log(1/\delta)}{(1-\gamma)^5\cdot\varepsilon^2\cdot\rho^2}\right)$.
Exploration on HuBERT with Multiple Resolutions
Jun 01, 2023

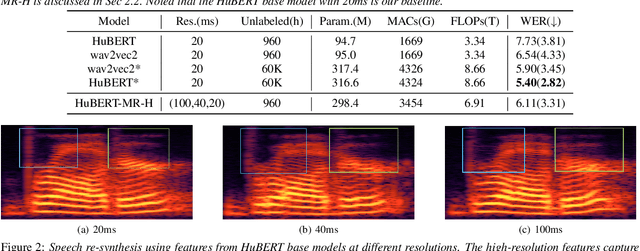
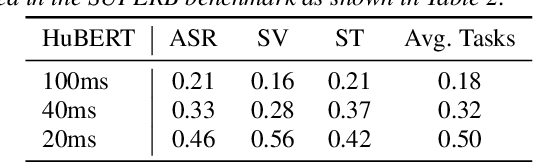
Hidden-unit BERT (HuBERT) is a widely-used self-supervised learning (SSL) model in speech processing. However, we argue that its fixed 20ms resolution for hidden representations would not be optimal for various speech-processing tasks since their attributes (e.g., speaker characteristics and semantics) are based on different time scales. To address this limitation, we propose utilizing HuBERT representations at multiple resolutions for downstream tasks. We explore two approaches, namely the parallel and hierarchical approaches, for integrating HuBERT features with different resolutions. Through experiments, we demonstrate that HuBERT with multiple resolutions outperforms the original model. This highlights the potential of utilizing multiple resolutions in SSL models like HuBERT to capture diverse information from speech signals.
Combining Particle and Tensor-network Methods for Partial Differential Equations via Sketching
Jun 01, 2023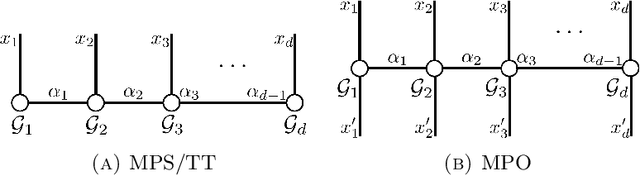

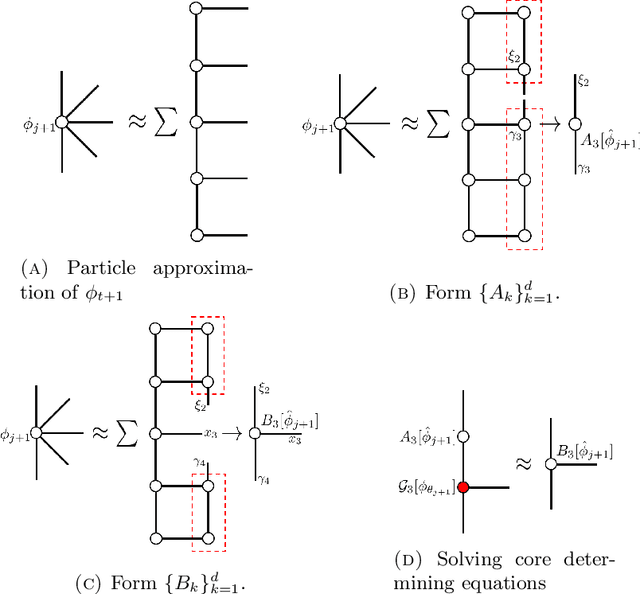

In this paper, we propose a general framework for solving high-dimensional partial differential equations with tensor networks. Our approach offers a comprehensive solution methodology, wherein we employ a combination of particle simulations to update the solution and re-estimations of the new solution as a tensor-network using a recently proposed tensor train sketching technique. Our method can also be interpreted as an alternative approach for performing particle number control by assuming the particles originate from an underlying tensor network. We demonstrate the versatility and flexibility of our approach by applying it to two specific scenarios: simulating the Fokker-Planck equation through Langevin dynamics and quantum imaginary time evolution via auxiliary-field quantum Monte Carlo.
Multi-Dataset Co-Training with Sharpness-Aware Optimization for Audio Anti-spoofing
Jun 01, 2023
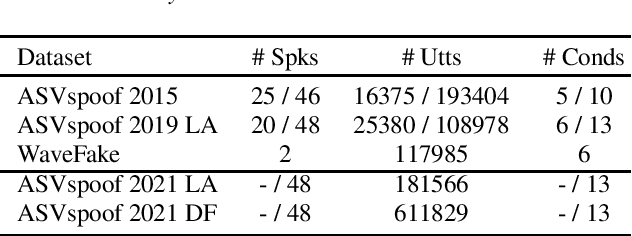
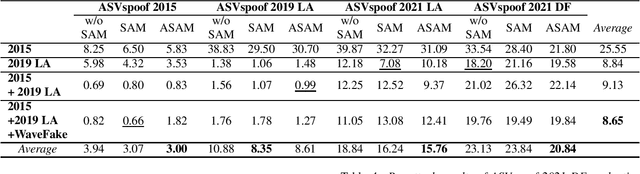
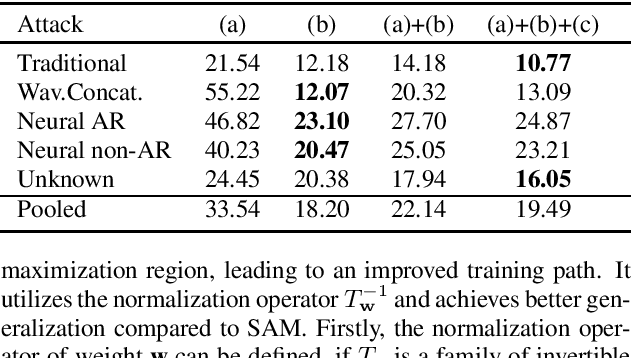
Audio anti-spoofing for automatic speaker verification aims to safeguard users' identities from spoofing attacks. Although state-of-the-art spoofing countermeasure(CM) models perform well on specific datasets, they lack generalization when evaluated with different datasets. To address this limitation, previous studies have explored large pre-trained models, which require significant resources and time. We aim to develop a compact but well-generalizing CM model that can compete with large pre-trained models. Our approach involves multi-dataset co-training and sharpness-aware minimization, which has not been investigated in this domain. Extensive experiments reveal that proposed method yield competitive results across various datasets while utilizing 4,000 times less parameters than the large pre-trained models.
Faster Robust Tensor Power Method for Arbitrary Order
Jun 01, 2023Tensor decomposition is a fundamental method used in various areas to deal with high-dimensional data. \emph{Tensor power method} (TPM) is one of the widely-used techniques in the decomposition of tensors. This paper presents a novel tensor power method for decomposing arbitrary order tensors, which overcomes limitations of existing approaches that are often restricted to lower-order (less than $3$) tensors or require strong assumptions about the underlying data structure. We apply sketching method, and we are able to achieve the running time of $\widetilde{O}(n^{p-1})$, on the power $p$ and dimension $n$ tensor. We provide a detailed analysis for any $p$-th order tensor, which is never given in previous works.