 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human 3D Avatar Modeling with Implicit Neural Representation: A Brief Survey
Jun 06, 2023
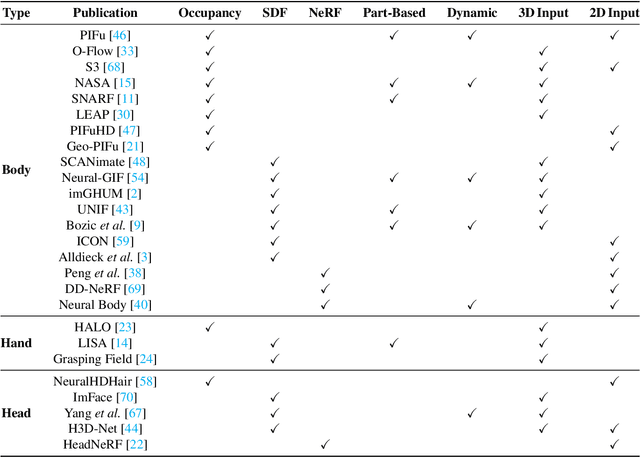
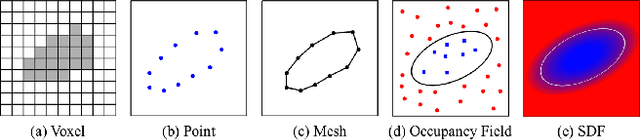
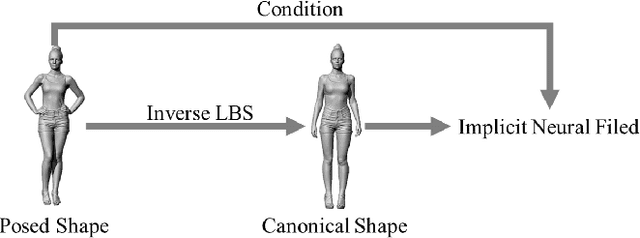
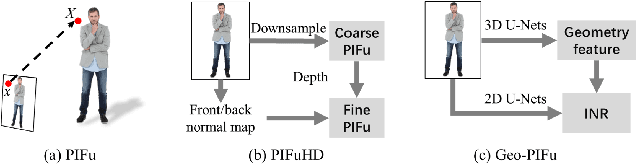
A human 3D avatar is one of the important elements in the metaverse, and the modeling effect directly affects people's visual experience. However, the human body has a complex topology and diverse details, so it is often expensive, time-consuming, and laborious to build a satisfactory model. Recent studies have proposed a novel method, implicit neural representation, which is a continuous representation method and can describe objects with arbitrary topology at arbitrary resolution. Researchers have applied implicit neural representation to human 3D avatar modeling and obtained more excellent results than traditional methods. This paper comprehensively reviews the application of implicit neural representation in human body modeling. First, we introduce three implicit representations of occupancy field, SDF, and NeRF, and make a classification of the literature investigated in this paper. Then the application of implicit modeling methods in the body, hand, and head are compared and analyzed respectively. Finally, we point out the shortcomings of current work and provide available suggestions for researchers.
Learning Human Mesh Recovery in 3D Scenes
Jun 06, 2023
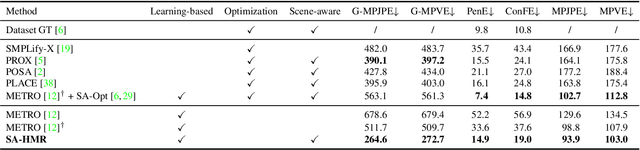
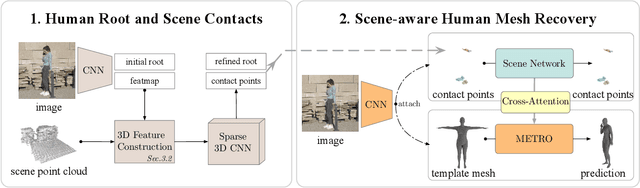
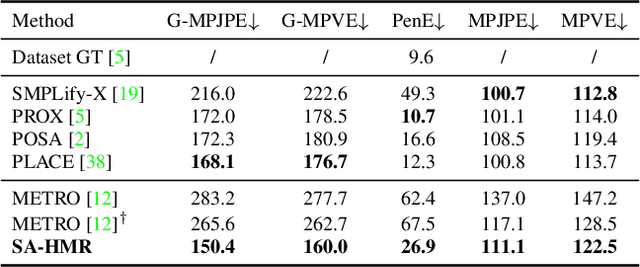
We present a novel method for recovering the absolute pose and shape of a human in a pre-scanned scene given a single image. Unlike previous methods that perform sceneaware mesh optimization, we propose to first estimate absolute position and dense scene contacts with a sparse 3D CNN, and later enhance a pretrained human mesh recovery network by cross-attention with the derived 3D scene cues. Joint learning on images and scene geometry enables our method to reduce the ambiguity caused by depth and occlusion, resulting in more reasonable global postures and contacts. Encoding scene-aware cues in the network also allows the proposed method to be optimization-free, and opens up the opportunity for real-time applications. The experiments show that the proposed network is capable of recovering accurate and physically-plausible meshes by a single forward pass and outperforms state-of-the-art methods in terms of both accuracy and speed.
TestLab: An Intelligent Automated Software Testing Framework
Jun 06, 2023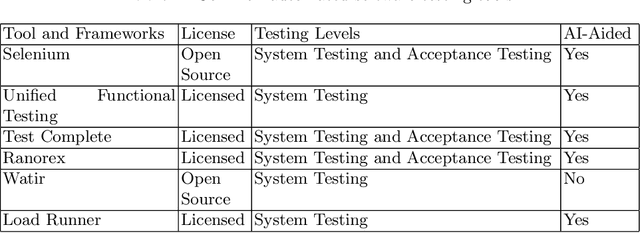

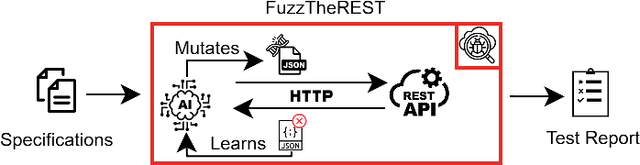

The prevalence of software systems has become an integral part of modern-day living. Software usage has increased significantly, leading to its growth in both size and complexity. Consequently, software development is becoming a more time-consuming process. In an attempt to accelerate the development cycle, the testing phase is often neglected, leading to the deployment of flawed systems that can have significant implications on the users daily activities. This work presents TestLab, an intelligent automated software testing framework that attempts to gather a set of testing methods and automate them using Artificial Intelligence to allow continuous testing of software systems at multiple levels from different scopes, ranging from developers to end-users. The tool consists of three modules, each serving a distinct purpose. The first two modules aim to identify vulnerabilities from different perspectives, while the third module enhances traditional automated software testing by automatically generating test cases through source code analysis.
Spherical Fourier Neural Operators: Learning Stable Dynamics on the Sphere
Jun 06, 2023
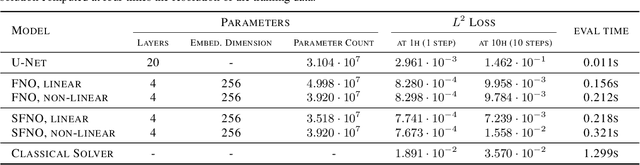
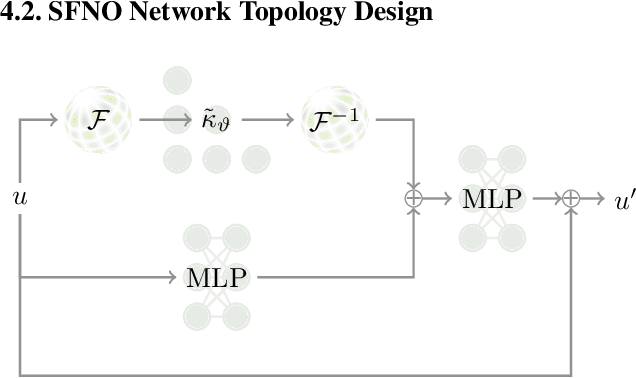
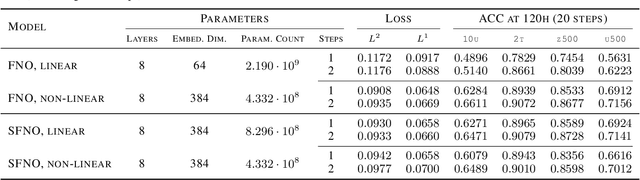
Fourier Neural Operators (FNOs) have proven to be an efficient and effective method for resolution-independent operator learning in a broad variety of application areas across scientific machine learning. A key reason for their success is their ability to accurately model long-range dependencies in spatio-temporal data by learning global convolutions in a computationally efficient manner. To this end, FNOs rely on the discrete Fourier transform (DFT), however, DFTs cause visual and spectral artifacts as well as pronounced dissipation when learning operators in spherical coordinates since they incorrectly assume a flat geometry. To overcome this limitation, we generalize FNOs on the sphere, introducing Spherical FNOs (SFNOs) for learning operators on spherical geometries. We apply SFNOs to forecasting atmospheric dynamics, and demonstrate stable auto\-regressive rollouts for a year of simulated time (1,460 steps), while retaining physically plausible dynamics. The SFNO has important implications for machine learning-based simulation of climate dynamics that could eventually help accelerate our response to climate change.
SciLit: A Platform for Joint Scientific Literature Discovery, Summarization and Citation Generation
Jun 06, 2023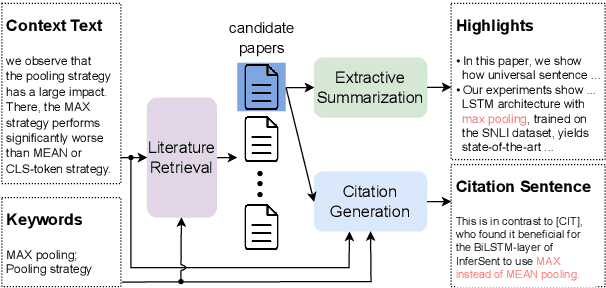

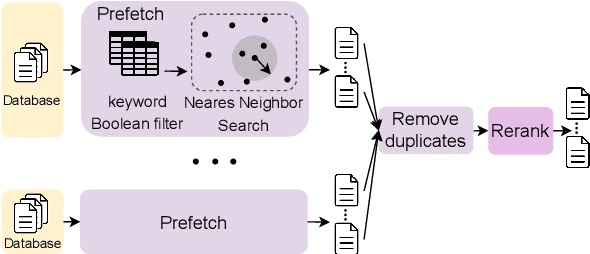
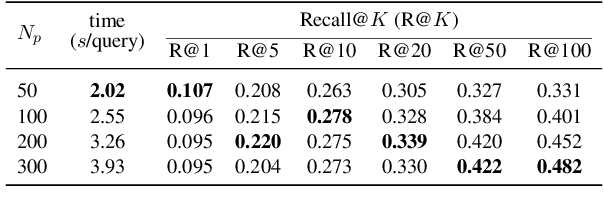
Scientific writing involves retrieving, summarizing, and citing relevant papers, which can be time-consuming processes in large and rapidly evolving fields. By making these processes inter-operable, natural language processing (NLP) provides opportunities for creating end-to-end assistive writing tools. We propose SciLit, a pipeline that automatically recommends relevant papers, extracts highlights, and suggests a reference sentence as a citation of a paper, taking into consideration the user-provided context and keywords. SciLit efficiently recommends papers from large databases of hundreds of millions of papers using a two-stage pre-fetching and re-ranking literature search system that flexibly deals with addition and removal of a paper database. We provide a convenient user interface that displays the recommended papers as extractive summaries and that offers abstractively-generated citing sentences which are aligned with the provided context and which mention the chosen keyword(s). Our assistive tool for literature discovery and scientific writing is available at https://scilit.vercel.app
Turning large language models into cognitive models
Jun 06, 2023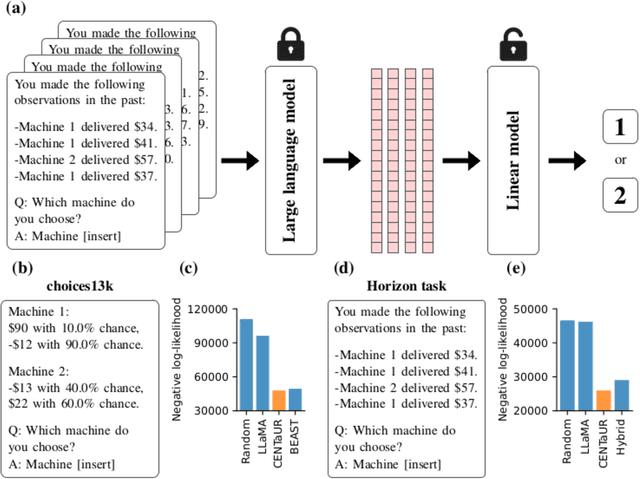
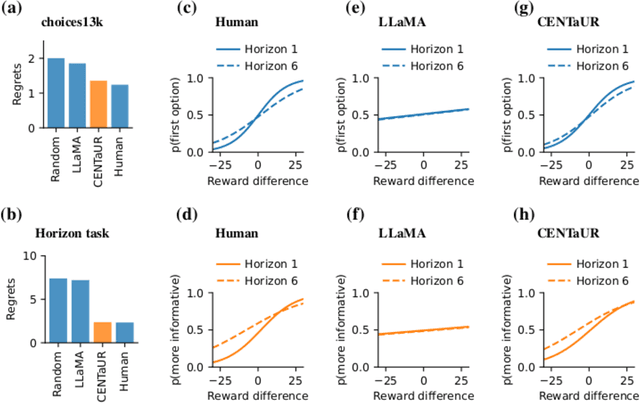
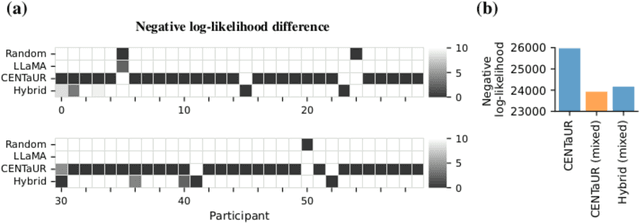
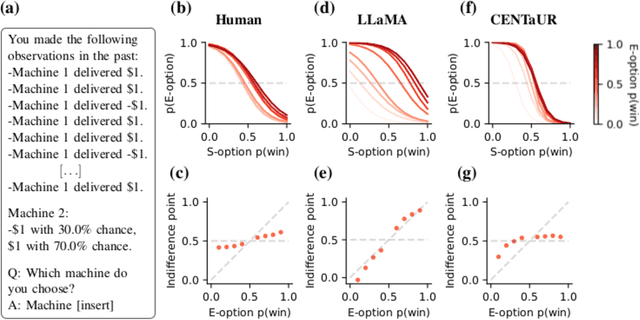
Large language models are powerful systems that excel at many tasks, ranging from translation to mathematical reasoning. Yet, at the same time, these models often show unhuman-like characteristics. In the present paper, we address this gap and ask whether large language models can be turned into cognitive models. We find that -- after finetuning them on data from psychological experiments -- these models offer accurate representations of human behavior, even outperforming traditional cognitive models in two decision-making domains. In addition, we show that their representations contain the information necessary to model behavior on the level of individual subjects. Finally, we demonstrate that finetuning on multiple tasks enables large language models to predict human behavior in a previously unseen task. Taken together, these results suggest that large, pre-trained models can be adapted to become generalist cognitive models, thereby opening up new research directions that could transform cognitive psychology and the behavioral sciences as a whole.
A Novel Implementation Methodology for Error Correction Codes on a Neuromorphic Architecture
Jun 06, 2023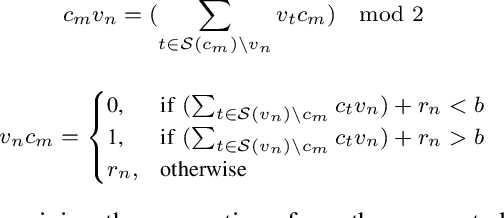
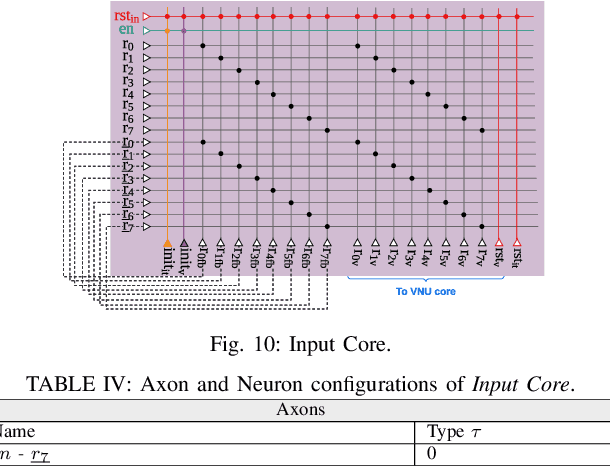
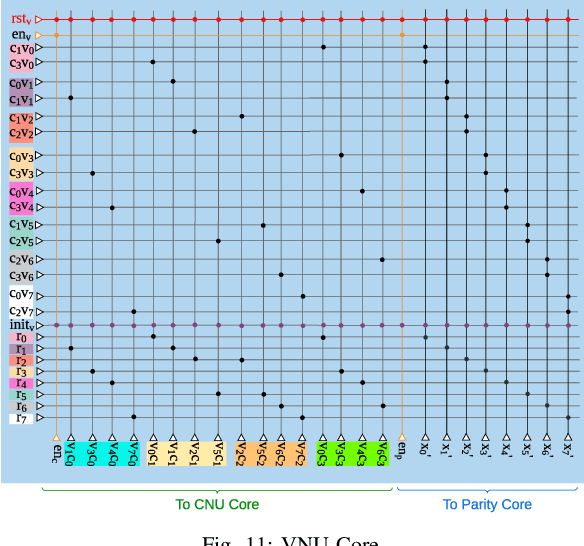
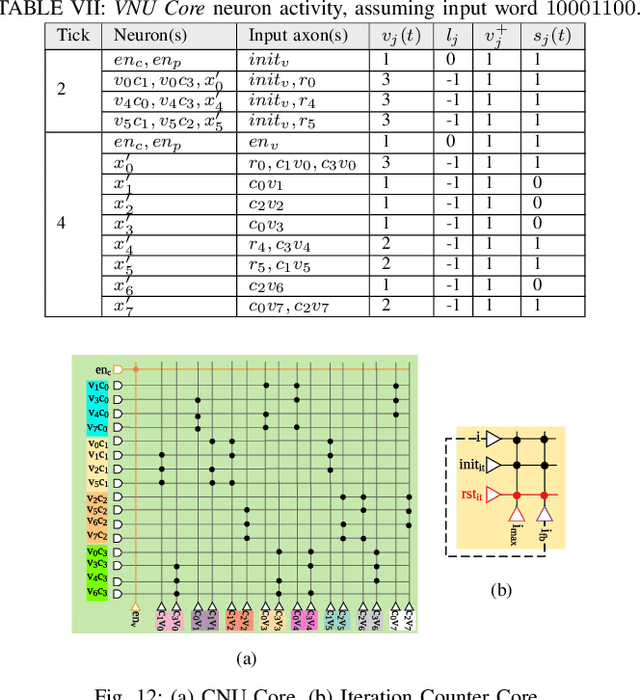
The Internet of Things infrastructure connects a massive number of edge devices with an increasing demand for intelligent sensing and inferencing capability. Such data-sensitive functions necessitate energy-efficient and programmable implementations of Error Correction Codes (ECC) and decoders. The algorithmic flow of ECCs with concurrent accumulation and comparison types of operations are innately exploitable by neuromorphic architectures for energy efficient execution -- an area that is relatively unexplored outside of machine learning applications. For the first time, we propose a methodology to map the hard-decision class of decoder algorithms on a neuromorphic architecture. We present the implementation of the Gallager B (GaB) decoding algorithm on a TrueNorth-inspired architecture that is emulated on the Xilinx Zynq ZCU102 MPSoC. Over this reference implementation, we propose architectural modifications at the neuron block level that result in a reduction of energy consumption by 31% with a negligible increase in resource usage while achieving the same error correction performance.
Bridging the Gap Between Multi-Step and One-Shot Trajectory Prediction via Self-Supervision
Jun 06, 2023
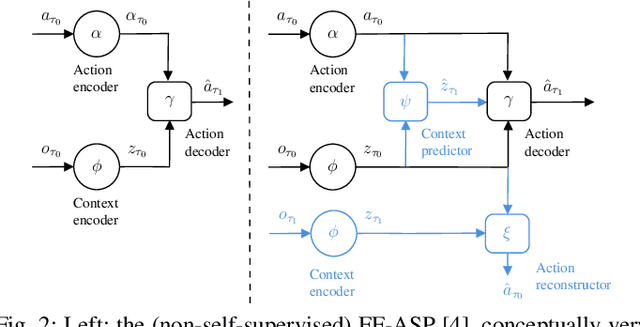
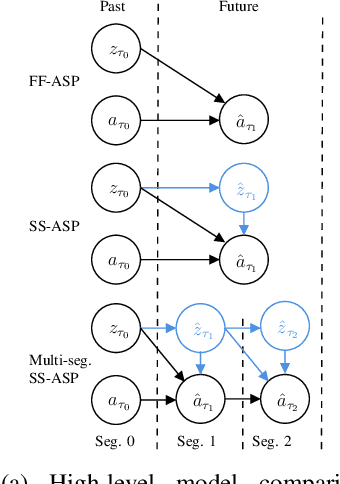
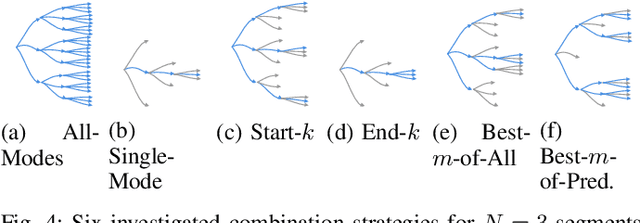
Accurate vehicle trajectory prediction is an unsolved problem in autonomous driving with various open research questions. State-of-the-art approaches regress trajectories either in a one-shot or step-wise manner. Although one-shot approaches are usually preferred for their simplicity, they relinquish powerful self-supervision schemes that can be constructed by chaining multiple time-steps. We address this issue by proposing a middle-ground where multiple trajectory segments are chained together. Our proposed Multi-Branch Self-Supervised Predictor receives additional training on new predictions starting at intermediate future segments. In addition, the model 'imagines' the latent context and 'predicts the past' while combining multi-modal trajectories in a tree-like manner. We deliberately keep aspects such as interaction and environment modeling simplistic and nevertheless achieve competitive results on the INTERACTION dataset. Furthermore, we investigate the sparsely explored uncertainty estimation of deterministic predictors. We find positive correlations between the prediction error and two proposed metrics, which might pave way for determining prediction confidence.
Exploring Model Dynamics for Accumulative Poisoning Discovery
Jun 06, 2023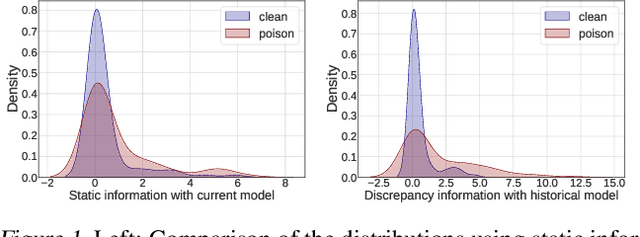
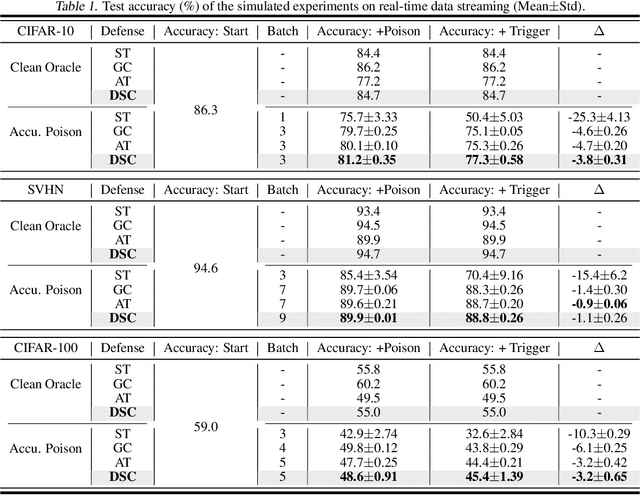
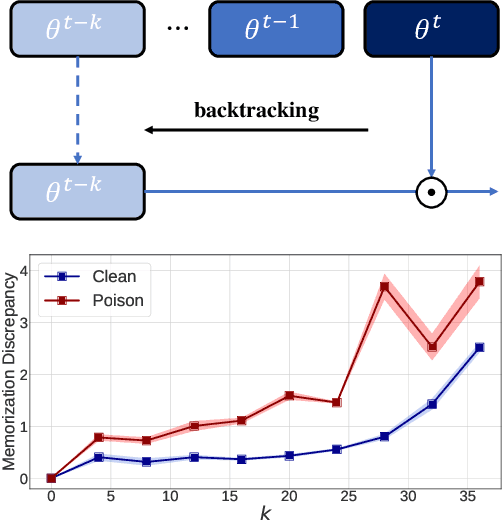
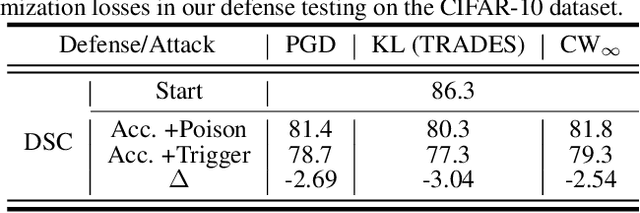
Adversarial poisoning attacks pose huge threats to various machine learning applications. Especially, the recent accumulative poisoning attacks show that it is possible to achieve irreparable harm on models via a sequence of imperceptible attacks followed by a trigger batch. Due to the limited data-level discrepancy in real-time data streaming, current defensive methods are indiscriminate in handling the poison and clean samples. In this paper, we dive into the perspective of model dynamics and propose a novel information measure, namely, Memorization Discrepancy, to explore the defense via the model-level information. By implicitly transferring the changes in the data manipulation to that in the model outputs, Memorization Discrepancy can discover the imperceptible poison samples based on their distinct dynamics from the clean samples. We thoroughly explore its properties and propose Discrepancy-aware Sample Correction (DSC) to defend against accumulative poisoning attacks. Extensive experiments comprehensively characterized Memorization Discrepancy and verified its effectiveness. The code is publicly available at: https://github.com/tmlr-group/Memorization-Discrepancy.
Energy-Based Models for Cross-Modal Localization using Convolutional Transformers
Jun 06, 2023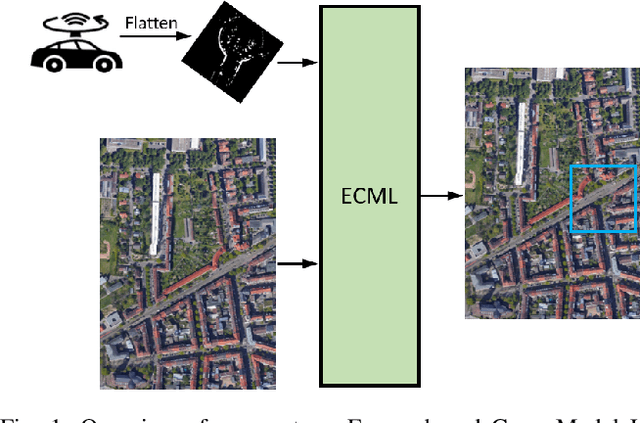
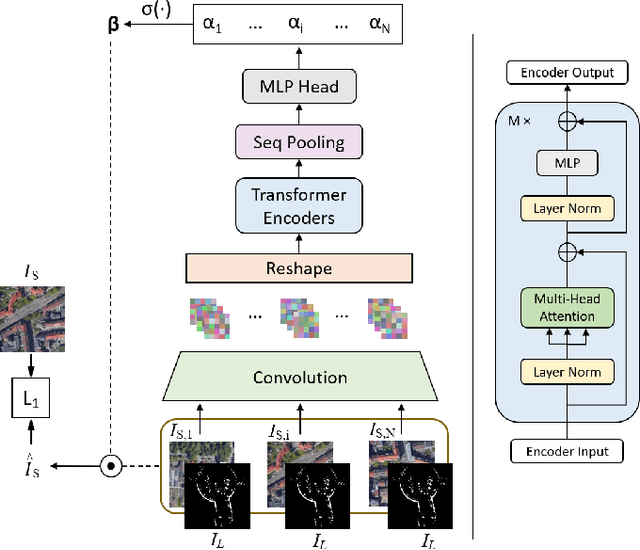
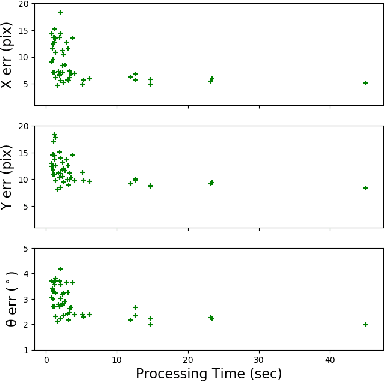
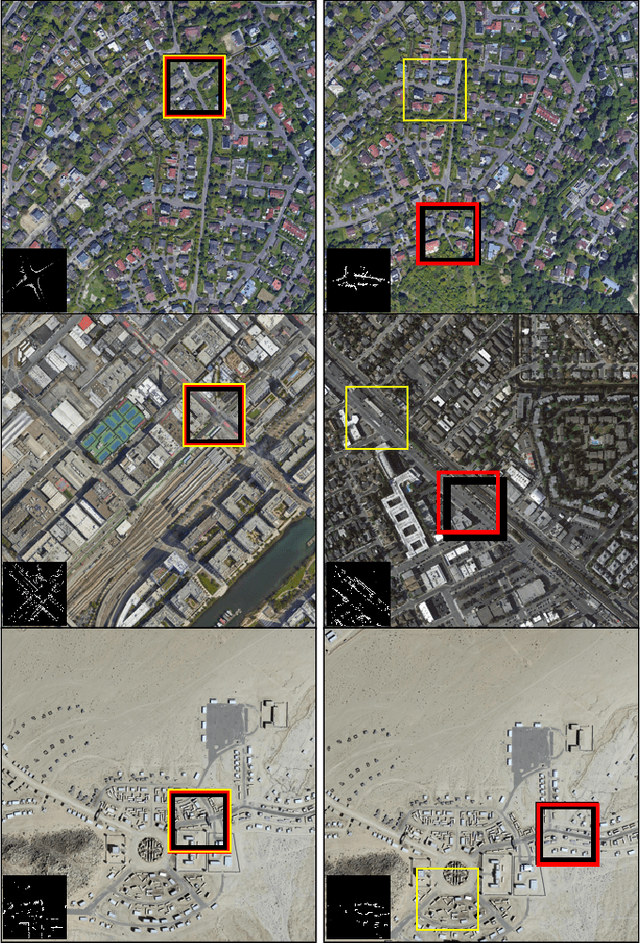
We present a novel framework using Energy-Based Models (EBMs) for localizing a ground vehicle mounted with a range sensor against satellite imagery in the absence of GPS. Lidar sensors have become ubiquitous on autonomous vehicles for describing its surrounding environment. Map priors are typically built using the same sensor modality for localization purposes. However, these map building endeavors using range sensors are often expensive and time-consuming. Alternatively, we leverage the use of satellite images as map priors, which are widely available, easily accessible, and provide comprehensive coverage. We propose a method using convolutional transformers that performs accurate metric-level localization in a cross-modal manner, which is challenging due to the drastic difference in appearance between the sparse range sensor readings and the rich satellite imagery. We train our model end-to-end and demonstrate our approach achieving higher accuracy than the state-of-the-art on KITTI, Pandaset, and a custom dataset.