 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Addressing Source Scale Bias via Image Warping for Domain Adaptation
Mar 19, 2024

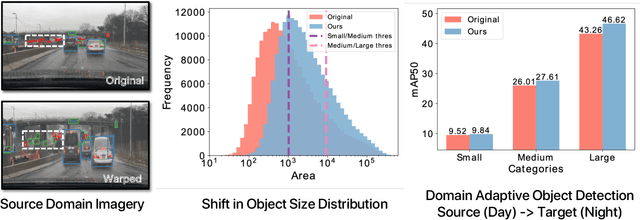

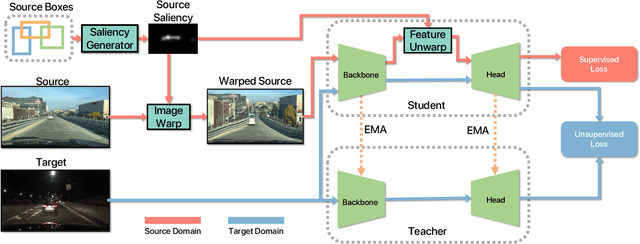
In visual recognition, scale bias is a key challenge due to the imbalance of object and image size distribution inherent in real scene datasets. Conventional solutions involve injecting scale invariance priors, oversampling the dataset at different scales during training, or adjusting scale at inference. While these strategies mitigate scale bias to some extent, their ability to adapt across diverse datasets is limited. Besides, they increase computational load during training and latency during inference. In this work, we use adaptive attentional processing -- oversampling salient object regions by warping images in-place during training. Discovering that shifting the source scale distribution improves backbone features, we developed a instance-level warping guidance aimed at object region sampling to mitigate source scale bias in domain adaptation. Our approach improves adaptation across geographies, lighting and weather conditions, is agnostic to the task, domain adaptation algorithm, saliency guidance, and underlying model architecture. Highlights include +6.1 mAP50 for BDD100K Clear $\rightarrow$ DENSE Foggy, +3.7 mAP50 for BDD100K Day $\rightarrow$ Night, +3.0 mAP50 for BDD100K Clear $\rightarrow$ Rainy, and +6.3 mIoU for Cityscapes $\rightarrow$ ACDC. Our approach adds minimal memory during training and has no additional latency at inference time. Please see Appendix for more results and analysis.
Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
Mar 19, 2024

Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
GraphERE: Jointly Multiple Event-Event Relation Extraction via Graph-Enhanced Event Embeddings
Mar 19, 2024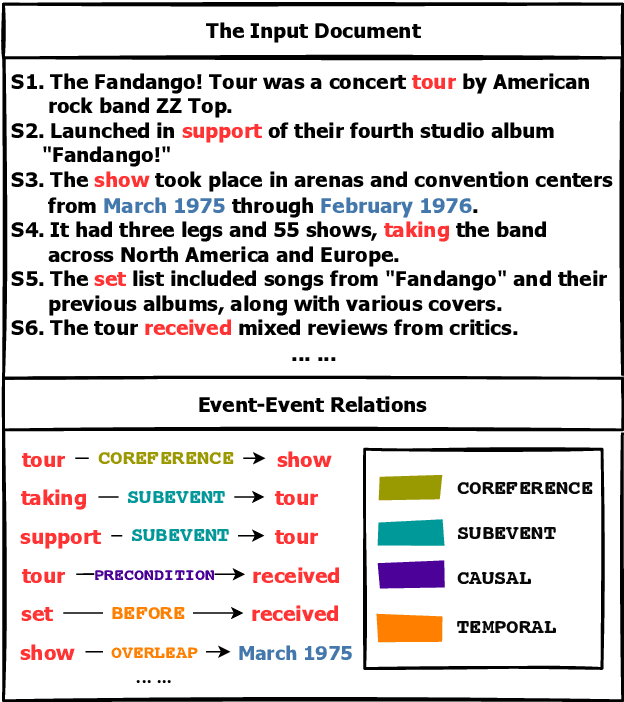
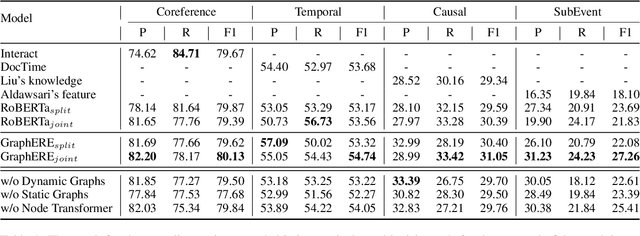
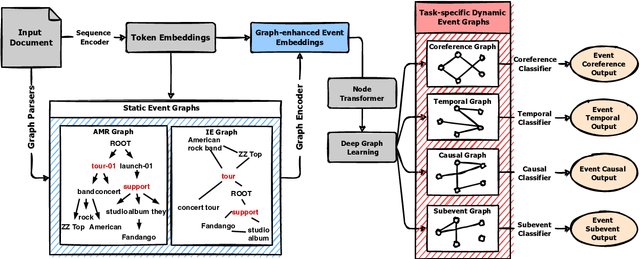
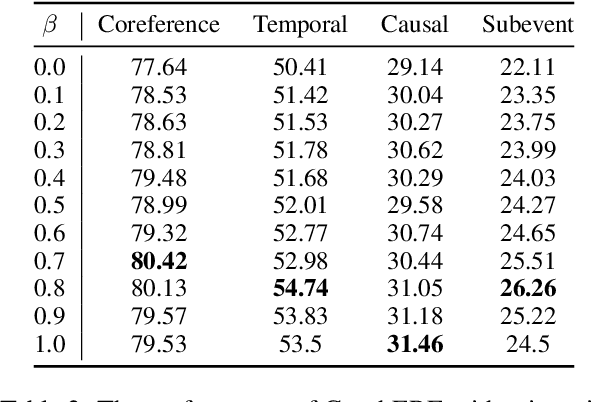
Events describe the state changes of entities. In a document, multiple events are connected by various relations (e.g., Coreference, Temporal, Causal, and Subevent). Therefore, obtaining the connections between events through Event-Event Relation Extraction (ERE) is critical to understand natural language. There are two main problems in the current ERE works: a. Only embeddings of the event triggers are used for event feature representation, ignoring event arguments (e.g., time, place, person, etc.) and their structure within the event. b. The interconnection between relations (e.g., temporal and causal relations usually interact with each other ) is ignored. To solve the above problems, this paper proposes a jointly multiple ERE framework called GraphERE based on Graph-enhanced Event Embeddings. First, we enrich the event embeddings with event argument and structure features by using static AMR graphs and IE graphs; Then, to jointly extract multiple event relations, we use Node Transformer and construct Task-specific Dynamic Event Graphs for each type of relation. Finally, we used a multi-task learning strategy to train the whole framework. Experimental results on the latest MAVEN-ERE dataset validate that GraphERE significantly outperforms existing methods. Further analyses indicate the effectiveness of the graph-enhanced event embeddings and the joint extraction strategy.
Diagrammatic Instructions to Specify Spatial Objectives and Constraints with Applications to Mobile Base Placement
Mar 19, 2024
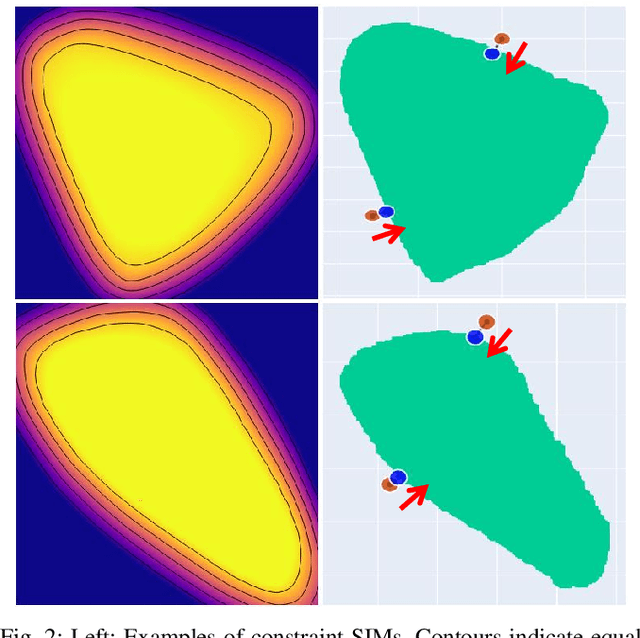
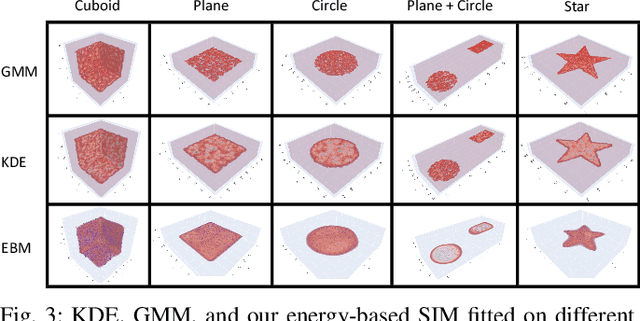

This paper introduces Spatial Diagrammatic Instructions (SDIs), an approach for human operators to specify objectives and constraints that are related to spatial regions in the working environment. Human operators are enabled to sketch out regions directly on camera images that correspond to the objectives and constraints. These sketches are projected to 3D spatial coordinates, and continuous Spatial Instruction Maps (SIMs) are learned upon them. These maps can then be integrated into optimization problems for tasks of robots. In particular, we demonstrate how Spatial Diagrammatic Instructions can be applied to solve the Base Placement Problem of mobile manipulators, which concerns the best place to put the manipulator to facilitate a certain task. Human operators can specify, via sketch, spatial regions of interest for a manipulation task and permissible regions for the mobile manipulator to be at. Then, an optimization problem that maximizes the manipulator's reachability, or coverage, over the designated regions of interest while remaining in the permissible regions is solved. We provide extensive empirical evaluations, and show that our formulation of Spatial Instruction Maps provides accurate representations of user-specified diagrammatic instructions. Furthermore, we demonstrate that our diagrammatic approach to the Mobile Base Placement Problem enables higher quality solutions and faster run-time.
Do Generated Data Always Help Contrastive Learning?
Mar 19, 2024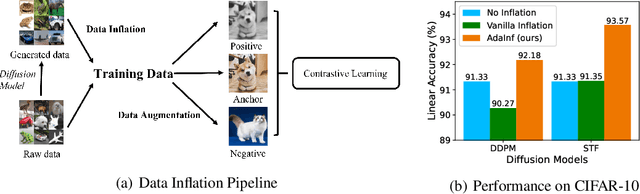

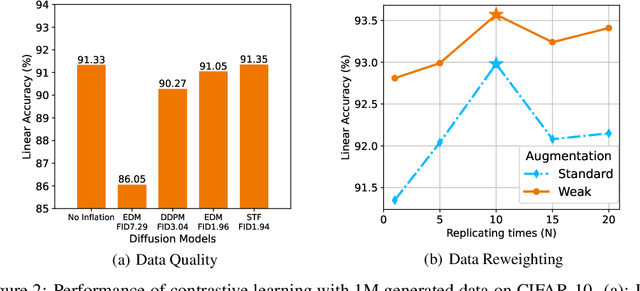

Contrastive Learning (CL) has emerged as one of the most successful paradigms for unsupervised visual representation learning, yet it often depends on intensive manual data augmentations. With the rise of generative models, especially diffusion models, the ability to generate realistic images close to the real data distribution has been well recognized. These generated high-equality images have been successfully applied to enhance contrastive representation learning, a technique termed ``data inflation''. However, we find that the generated data (even from a good diffusion model like DDPM) may sometimes even harm contrastive learning. We investigate the causes behind this failure from the perspective of both data inflation and data augmentation. For the first time, we reveal the complementary roles that stronger data inflation should be accompanied by weaker augmentations, and vice versa. We also provide rigorous theoretical explanations for these phenomena via deriving its generalization bounds under data inflation. Drawing from these insights, we propose Adaptive Inflation (AdaInf), a purely data-centric strategy without introducing any extra computation cost. On benchmark datasets, AdaInf can bring significant improvements for various contrastive learning methods. Notably, without using external data, AdaInf obtains 94.70% linear accuracy on CIFAR-10 with SimCLR, setting a new record that surpasses many sophisticated methods. Code is available at https://github.com/PKU-ML/adainf.
Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
Mar 19, 2024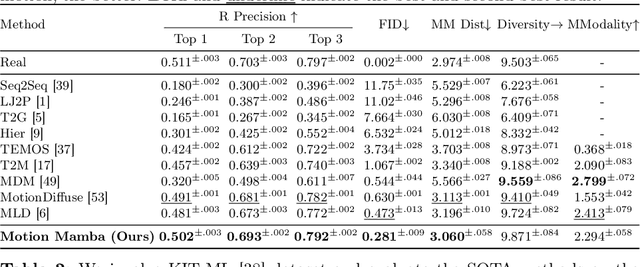
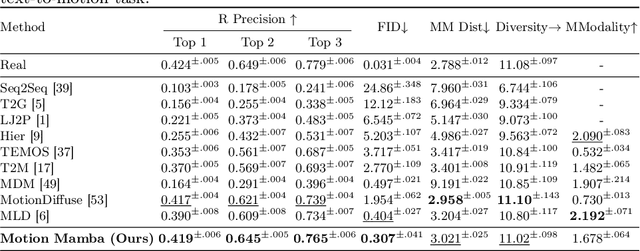
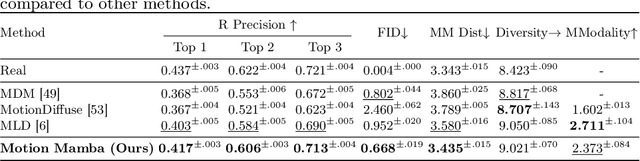
Human motion generation stands as a significant pursuit in generative computer vision, while achieving long-sequence and efficient motion generation remains challenging. Recent advancements in state space models (SSMs), notably Mamba, have showcased considerable promise in long sequence modeling with an efficient hardware-aware design, which appears to be a promising direction to build motion generation model upon it. Nevertheless, adapting SSMs to motion generation faces hurdles since the lack of a specialized design architecture to model motion sequence. To address these challenges, we propose Motion Mamba, a simple and efficient approach that presents the pioneering motion generation model utilized SSMs. Specifically, we design a Hierarchical Temporal Mamba (HTM) block to process temporal data by ensemble varying numbers of isolated SSM modules across a symmetric U-Net architecture aimed at preserving motion consistency between frames. We also design a Bidirectional Spatial Mamba (BSM) block to bidirectionally process latent poses, to enhance accurate motion generation within a temporal frame. Our proposed method achieves up to 50% FID improvement and up to 4 times faster on the HumanML3D and KIT-ML datasets compared to the previous best diffusion-based method, which demonstrates strong capabilities of high-quality long sequence motion modeling and real-time human motion generation. See project website https://steve-zeyu-zhang.github.io/MotionMamba/
Non-negative matrix underapproximation as optimal frequency band selector
Mar 19, 2024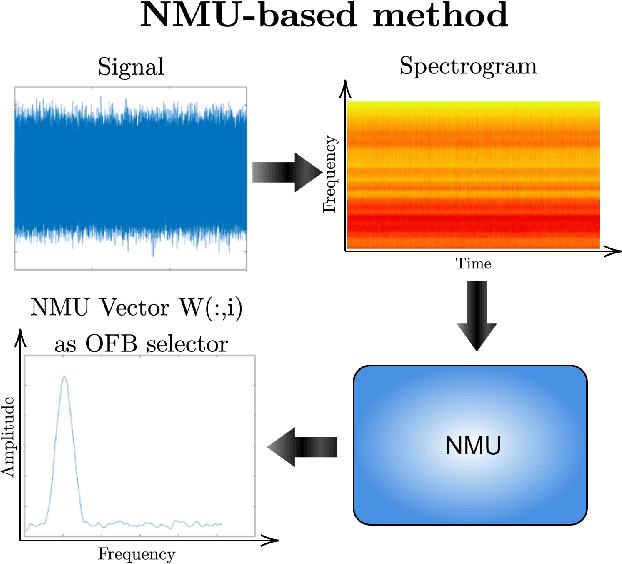
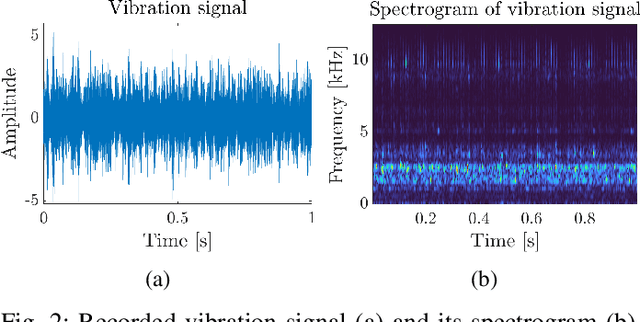
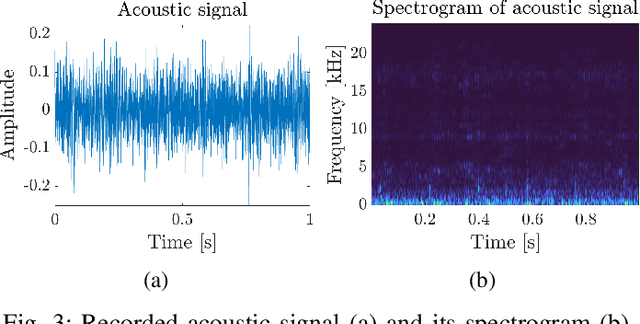
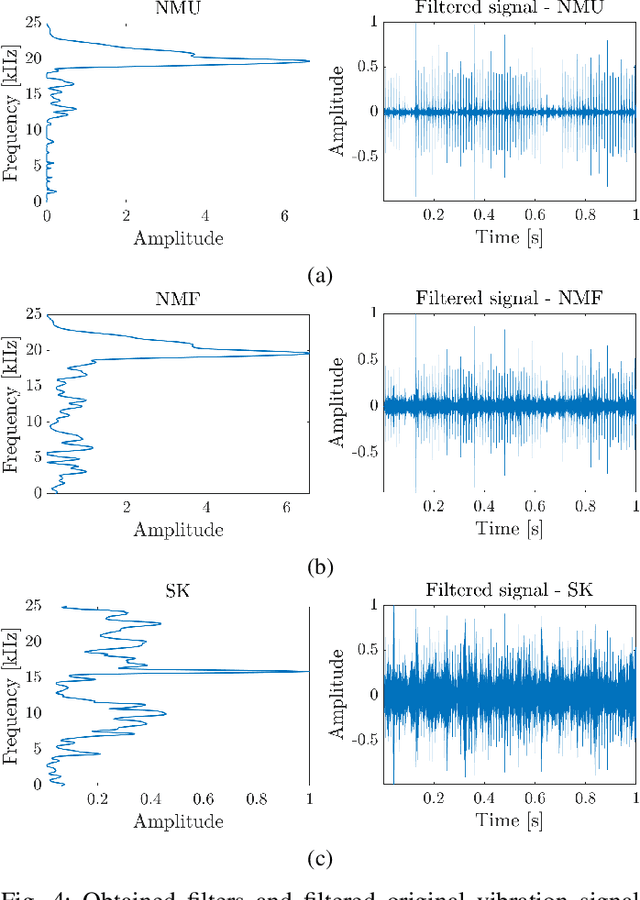
Time-frequency representation (TFR) is often used for non-stationary signal analysis. The most intuitive and interpretable TFR is the spectrogram. Recently, a concept of non-negative matrix factorization (NMF) has been successfully applied to local damage detection in rolling elements of bearings via spectrogram factorization. NMF applied to the spectrogram allows one to find an informative frequency band, which could be further used as a filter characteristic. However, the obtained filter characteristics mostly detect the informative frequency band, which also encompasses a lot of noise. In the case where noise is more problematic, as is the case for acoustic signals from industrial machines, the NMF hardly detects the damage. To solve this problem and obtain more selective filters, which are more robust to noise, we propose the non-negative matrix under-approximation (NMU) as an informative frequency band selector. Due to the more sparse parts-based representation of the NMU compared to NMF, NMU provides more selective filter characteristics, which neglect the non-informative frequency bands related to the noise. In practice, it means that NMU gives a better signal-to-noise ratio for the filtered signal. The efficiency of the proposed approach has been validated on the vibration signal from the test rig and the acoustic signal from an idler.
Most Likely Sequence Generation for $n$-Grams, Transformers, HMMs, and Markov Chains, by Using Rollout Algorithms
Mar 19, 2024In this paper we consider a transformer with an $n$-gram structure, such as the one underlying ChatGPT. The transformer provides next word probabilities, which can be used to generate word sequences. We consider methods for computing word sequences that are highly likely, based on these probabilities. Computing the optimal (i.e., most likely) word sequence starting with a given initial state is an intractable problem, so we propose methods to compute highly likely sequences of $N$ words in time that is a low order polynomial in $N$ and in the vocabulary size of the $n$-gram. These methods are based on the rollout approach from approximate dynamic programming, a form of single policy iteration, which can improve the performance of any given heuristic policy. In our case we use a greedy heuristic that generates as next word one that has the highest probability. We show with analysis, examples, and computational experimentation that our methods are capable of generating highly likely sequences with a modest increase in computation over the greedy heuristic. While our analysis and experiments are focused on Markov chains of the type arising in transformer and ChatGPT-like models, our methods apply to general finite-state Markov chains, and related inference applications of Hidden Markov Models (HMM), where Viterbi decoding is used extensively.
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024
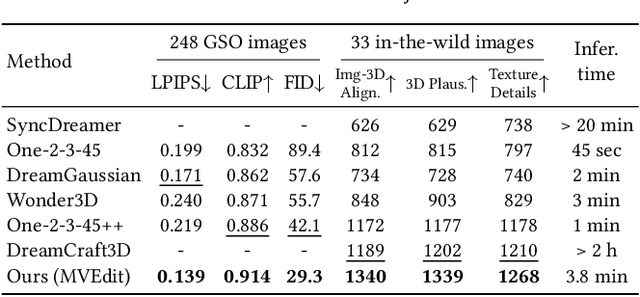
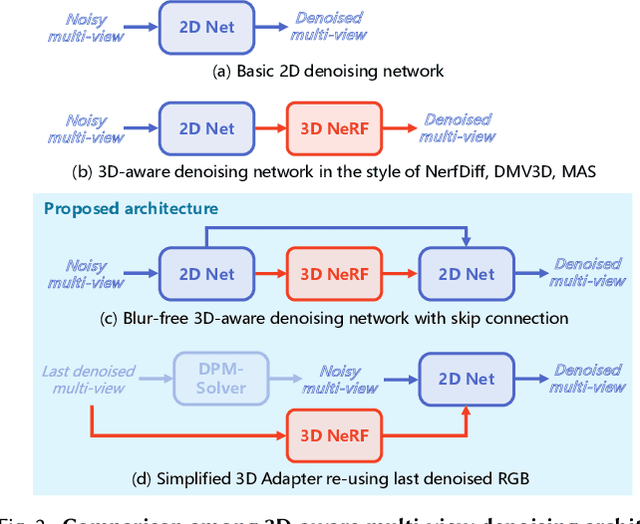
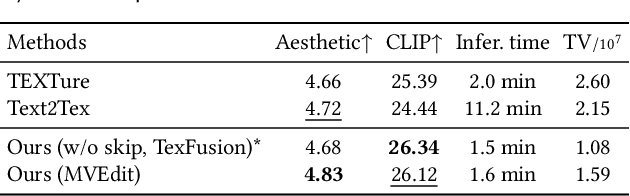
Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
BAGS: Building Animatable Gaussian Splatting from a Monocular Video with Diffusion Priors
Mar 18, 2024
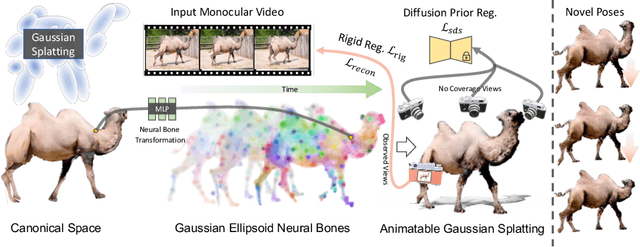


Animatable 3D reconstruction has significant applications across various fields, primarily relying on artists' handcraft creation. Recently, some studies have successfully constructed animatable 3D models from monocular videos. However, these approaches require sufficient view coverage of the object within the input video and typically necessitate significant time and computational costs for training and rendering. This limitation restricts the practical applications. In this work, we propose a method to build animatable 3D Gaussian Splatting from monocular video with diffusion priors. The 3D Gaussian representations significantly accelerate the training and rendering process, and the diffusion priors allow the method to learn 3D models with limited viewpoints. We also present the rigid regularization to enhance the utilization of the priors. We perform an extensive evaluation across various real-world videos, demonstrating its superior performance compared to the current state-of-the-art methods.