 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A metric to compare the anatomy variation between image time series
Feb 23, 2023
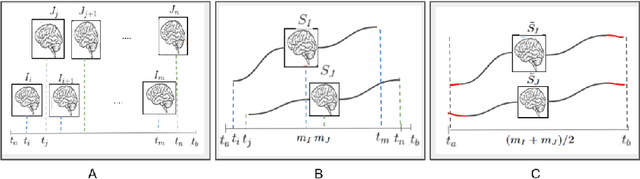
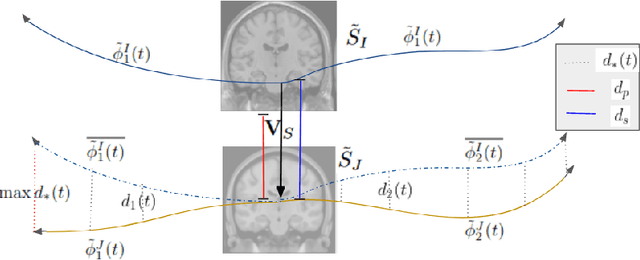
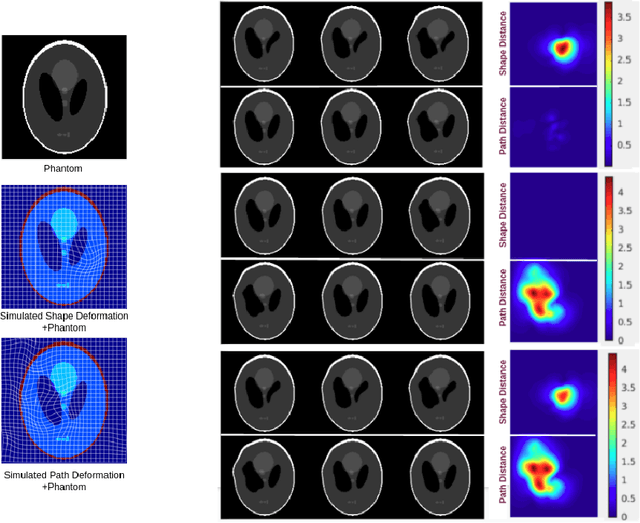
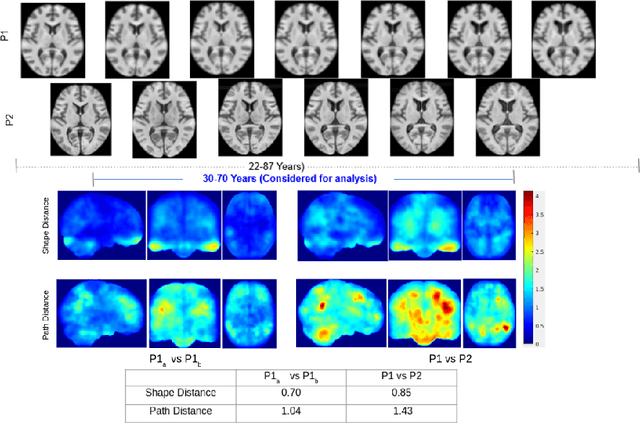
Biological processes like growth, aging, and disease progression are generally studied with follow-up scans taken at different time points, i.e., with image time series (TS) based analysis. Comparison between TS representing a biological process of two individuals/populations is of interest. A metric to quantify the difference between TS is desirable for such a comparison. The two TS represent the evolution of two different subject/population average anatomies through two paths. A method to untangle and quantify the path and inter-subject anatomy(shape) difference between the TS is presented in this paper. The proposed metric is a generalized version of Fr\'echet distance designed to compare curves. The proposed method is evaluated with simulated and adult and fetal neuro templates. Results show that the metric is able to separate and quantify the path and shape differences between TS.
Automatic Design Method of Building Pipeline Layout Based on Deep Reinforcement Learning
May 18, 2023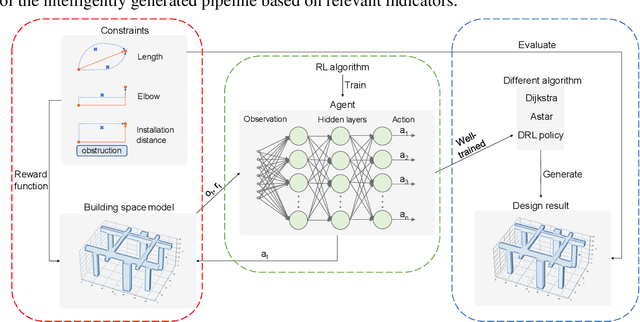
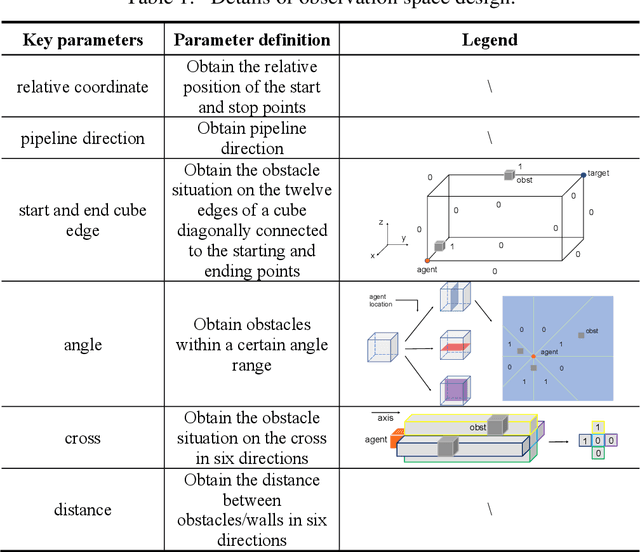
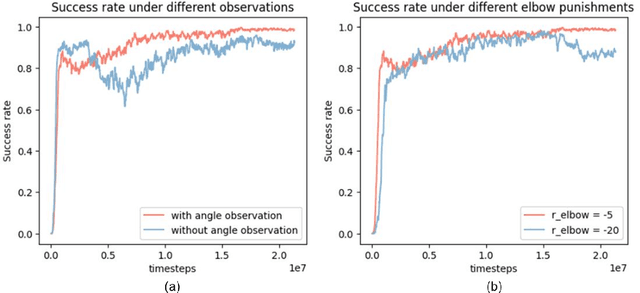
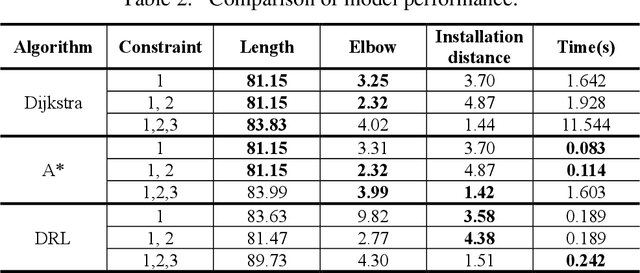
The layout design of pipelines is a critical task in the construction industry. Currently, pipeline layout is designed manually by engineers, which is time-consuming and laborious. Automating and streamlining this process can reduce the burden on engineers and save time. In this paper, we propose a method for generating three-dimensional layout of pipelines based on deep reinforcement learning (DRL). Firstly, we abstract the geometric features of space to establish a training environment and define reward functions based on three constraints: pipeline length, elbow, and installation distance. Next, we collect data through interactions between the agent and the environment and train the DRL model. Finally, we use the well-trained DRL model to automatically design a single pipeline. Our results demonstrate that DRL models can complete the pipeline layout task in space in a much shorter time than traditional algorithms while ensuring high-quality layout outcomes.
Findings of the VarDial Evaluation Campaign 2023
May 31, 2023

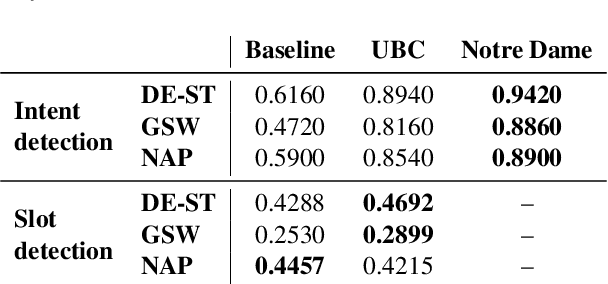

This report presents the results of the shared tasks organized as part of the VarDial Evaluation Campaign 2023. The campaign is part of the tenth workshop on Natural Language Processing (NLP) for Similar Languages, Varieties and Dialects (VarDial), co-located with EACL 2023. Three separate shared tasks were included this year: Slot and intent detection for low-resource language varieties (SID4LR), Discriminating Between Similar Languages -- True Labels (DSL-TL), and Discriminating Between Similar Languages -- Speech (DSL-S). All three tasks were organized for the first time this year.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023
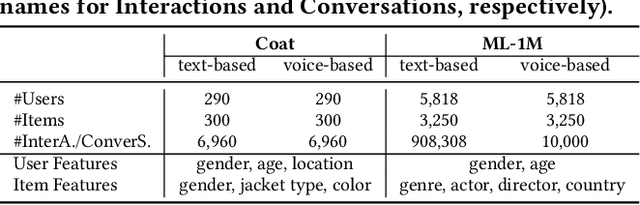
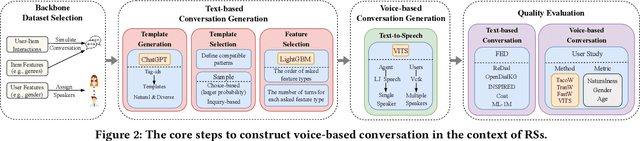
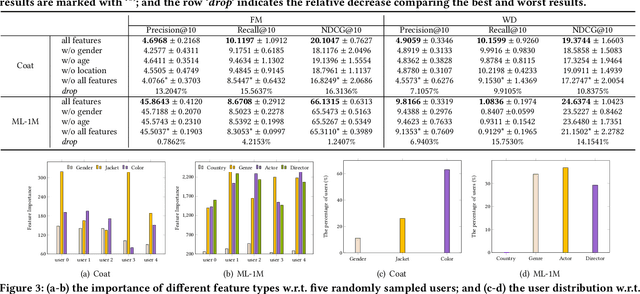
Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.
RADIUS: Risk-Aware, Real-Time, Reachability-Based Motion Planning
Feb 15, 2023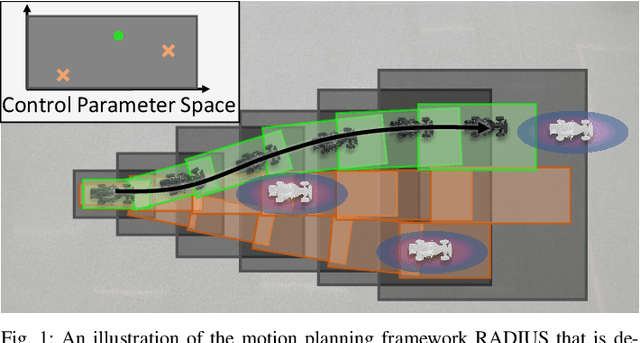
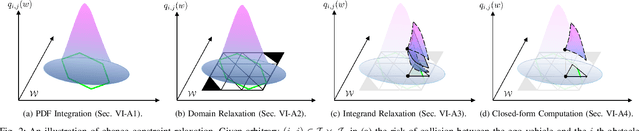
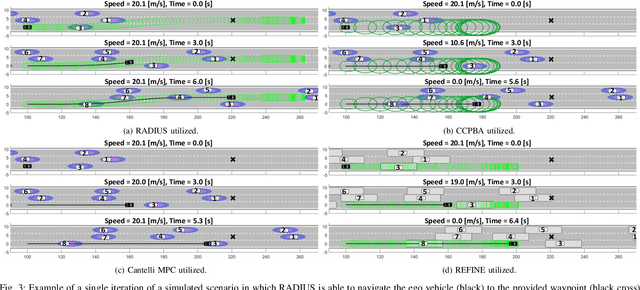
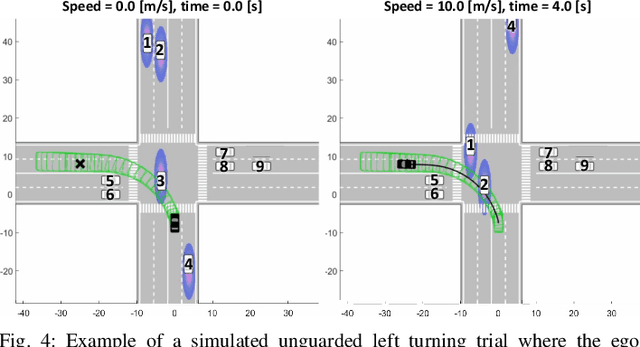
Deterministic methods for motion planning guarantee safety amidst uncertainty in obstacle locations by trying to restrict the robot from operating in any possible location that an obstacle could be in. Unfortunately, this can result in overly conservative behavior. Chance-constrained optimization can be applied to improve the performance of motion planning algorithms by allowing for a user-specified amount of bounded constraint violation. However, state-of-the-art methods rely either on moment-based inequalities, which can be overly conservative, or make it difficult to satisfy assumptions about the class of probability distributions used to model uncertainty. To address these challenges, this work proposes a real-time, risk-aware reachability based motion planning framework called RADIUS. The method first generates a reachable set of parameterized trajectories for the robot offline. At run time, RADIUS computes a closed-form over-approximation of the risk of a collision with an obstacle. This is done without restricting the probability distribution used to model uncertainty to a simple class (e.g., Gaussian). Then, RADIUS performs real-time optimization to construct a trajectory that can be followed by the robot in a manner that is certified to have a risk of collision that is less than or equal to a user-specified threshold. The proposed algorithm is compared to several state-of-the-art chance-constrained and deterministic methods in simulation, and is shown to consistently outperform them in a variety of driving scenarios. A demonstration of the proposed framework on hardware is also provided.
SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling
Feb 03, 2023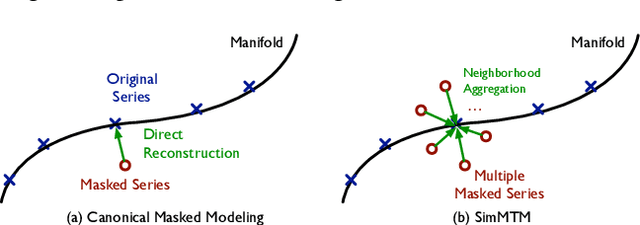
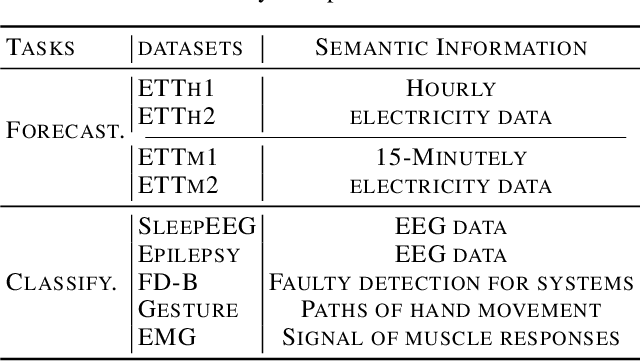
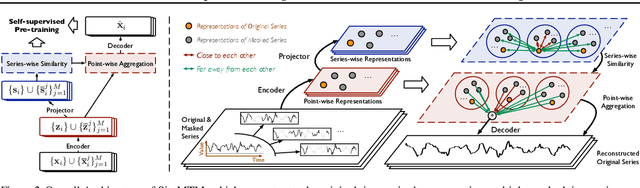
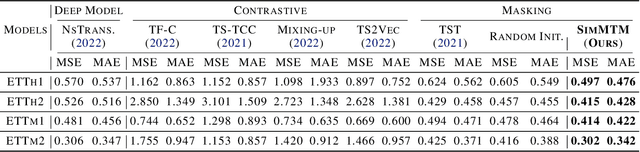
Time series analysis is widely used in extensive areas. Recently, to reduce labeling expenses and benefit various tasks, self-supervised pre-training has attracted immense interest. One mainstream paradigm is masked modeling, which successfully pre-trains deep models by learning to reconstruct the masked content based on the unmasked part. However, since the semantic information of time series is mainly contained in temporal variations, the standard way of randomly masking a portion of time points will ruin vital temporal variations of time series seriously, making the reconstruction task too difficult to guide representation learning. We thus present SimMTM, a Simple pre-training framework for Masked Time-series Modeling. By relating masked modeling to manifold learning, SimMTM proposes to recover masked time points by the weighted aggregation of multiple neighbors outside the manifold, which eases the reconstruction task by assembling ruined but complementary temporal variations from multiple masked series. SimMTM further learns to uncover the local structure of the manifold helpful for masked modeling. Experimentally, SimMTM achieves state-of-the-art fine-tuning performance in two canonical time series analysis tasks: forecasting and classification, covering both in- and cross-domain settings.
Combining a Meta-Policy and Monte-Carlo Planning for Scalable Type-Based Reasoning in Partially Observable Environments
Jun 09, 2023The design of autonomous agents that can interact effectively with other agents without prior coordination is a core problem in multi-agent systems. Type-based reasoning methods achieve this by maintaining a belief over a set of potential behaviours for the other agents. However, current methods are limited in that they assume full observability of the state and actions of the other agent or do not scale efficiently to larger problems with longer planning horizons. Addressing these limitations, we propose Partially Observable Type-based Meta Monte-Carlo Planning (POTMMCP) - an online Monte-Carlo Tree Search based planning method for type-based reasoning in large partially observable environments. POTMMCP incorporates a novel meta-policy for guiding search and evaluating beliefs, allowing it to search more effectively to longer horizons using less planning time. We show that our method converges to the optimal solution in the limit and empirically demonstrate that it effectively adapts online to diverse sets of other agents across a range of environments. Comparisons with the state-of-the art method on problems with up to $10^{14}$ states and $10^8$ observations indicate that POTMMCP is able to compute better solutions significantly faster.
Unsupervised Cross-Domain Soft Sensor Modelling via Deep Physics-Inspired Particle Flow Bayes
Jun 09, 2023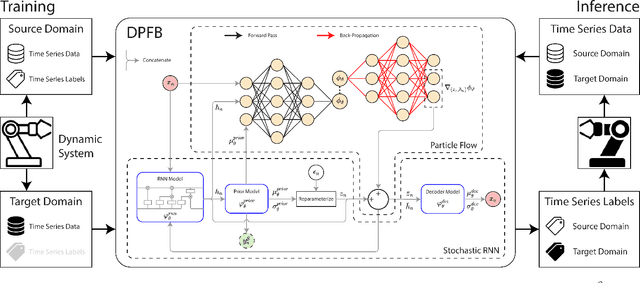
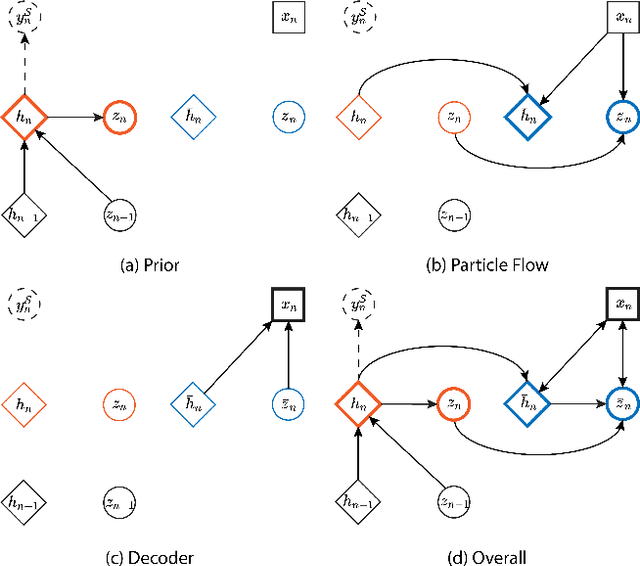
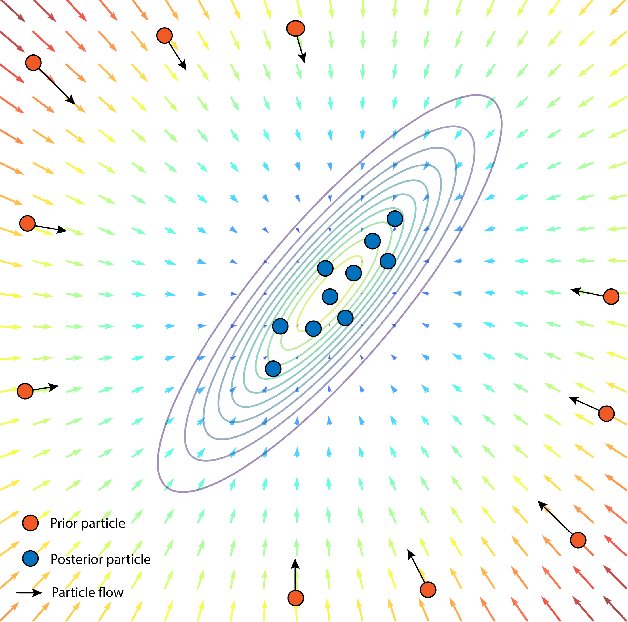
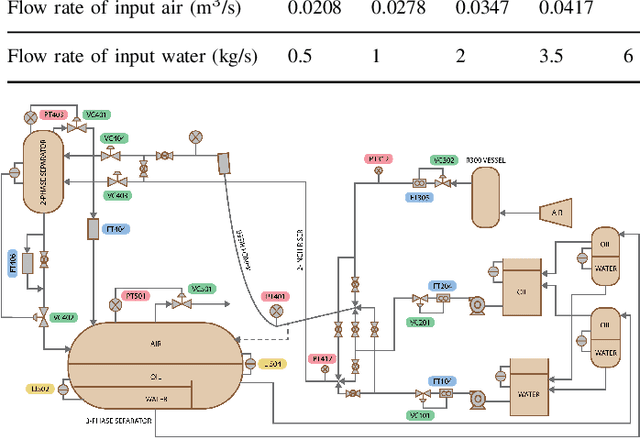
Data-driven soft sensors are essential for achieving accurate perception through reliable state inference. However, developing representative soft sensor models is challenged by issues such as missing labels, domain adaptability, and temporal coherence in data. To address these challenges, we propose a deep Particle Flow Bayes (DPFB) framework for cross-domain soft sensor modeling in the absence of target state labels. In particular, a sequential Bayes objective is first formulated to perform the maximum likelihood estimation underlying the cross-domain soft sensing problem. At the core of the framework, we incorporate a physics-inspired particle flow that optimizes the sequential Bayes objective to perform an exact Bayes update of the model extracted latent and hidden features. As a result, these contributions enable the proposed framework to learn a rich approximate posterior feature representation capable of characterizing complex cross-domain system dynamics and performing effective time series unsupervised domain adaptation (UDA). Finally, we validate the framework on a complex industrial multiphase flow process system with complex dynamics and multiple operating conditions. The results demonstrate that the DPFB framework achieves superior cross-domain soft sensing performance, outperforming state-of-the-art deep UDA and normalizing flow approaches.
Forecasting Electric Vehicle Charging Station Occupancy: Smarter Mobility Data Challenge
Jun 09, 2023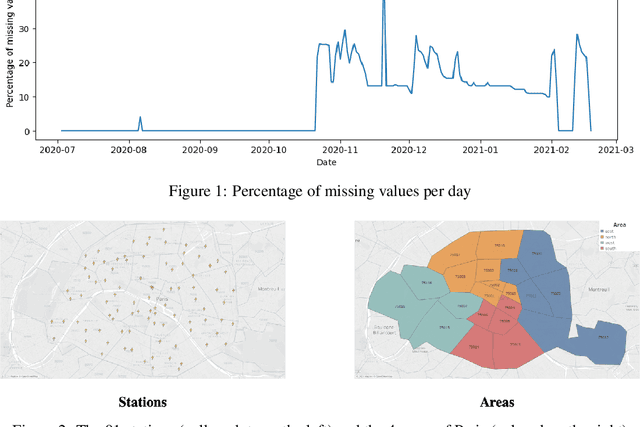


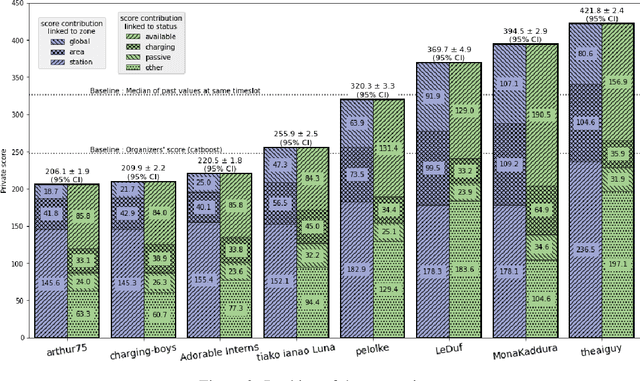
The transport sector is a major contributor to greenhouse gas emissions in Europe. Shifting to electric vehicles (EVs) powered by a low-carbon energy mix would reduce carbon emissions. However, to support the development of electric mobility, a better understanding of EV charging behaviours and more accurate forecasting models are needed. To fill that gap, the Smarter Mobility Data Challenge has focused on the development of forecasting models to predict EV charging station occupancy. This challenge involved analysing a dataset of 91 charging stations across four geographical areas over seven months in 2020-2021. The forecasts were evaluated at three levels of aggregation (individual stations, areas and global) to capture the inherent hierarchical structure of the data. The results highlight the potential of hierarchical forecasting approaches to accurately predict EV charging station occupancy, providing valuable insights for energy providers and EV users alike. This open dataset addresses many real-world challenges associated with time series, such as missing values, non-stationarity and spatio-temporal correlations. Access to the dataset, code and benchmarks are available at https://gitlab.com/smarter-mobility-data-challenge/tutorials to foster future research.
Two-level histograms for dealing with outliers and heavy tail distributions
Jun 09, 2023
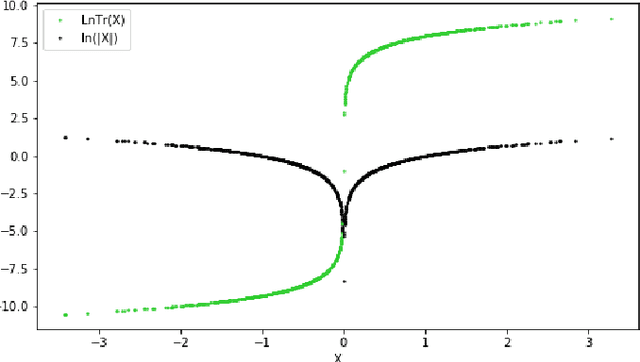
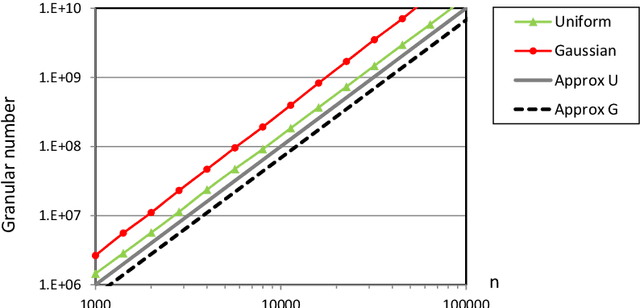
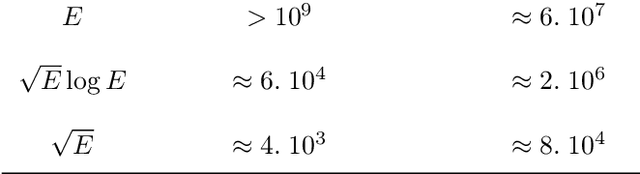
Histograms are among the most popular methods used in exploratory analysis to summarize univariate distributions. In particular, irregular histograms are good non-parametric density estimators that require very few parameters: the number of bins with their lengths and frequencies. Many approaches have been proposed in the literature to infer these parameters, either assuming hypotheses about the underlying data distributions or exploiting a model selection approach. In this paper, we focus on the G-Enum histogram method, which exploits the Minimum Description Length (MDL) principle to build histograms without any user parameter and achieves state-of-the art performance w.r.t accuracy; parsimony and computation time. We investigate on the limits of this method in the case of outliers or heavy-tailed distributions. We suggest a two-level heuristic to deal with such cases. The first level exploits a logarithmic transformation of the data to split the data set into a list of data subsets with a controlled range of values. The second level builds a sub-histogram for each data subset and aggregates them to obtain a complete histogram. Extensive experiments show the benefits of the approach.