 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enabling Intelligent Interactions between an Agent and an LLM: A Reinforcement Learning Approach
Jun 11, 2023
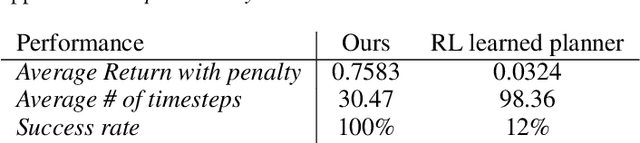
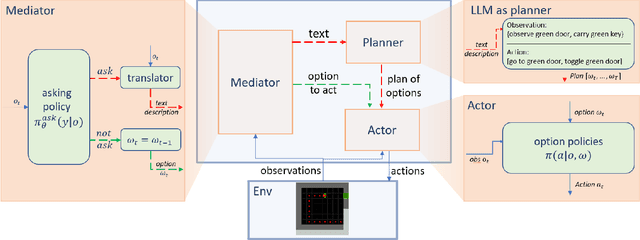
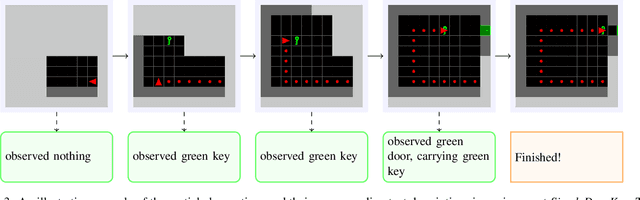
Large language models (LLMs) encode a vast amount of world knowledge acquired from massive text datasets. Recent studies have demonstrated that LLMs can assist an agent in solving complex sequential decision making tasks in embodied environments by providing high-level instructions. However, interacting with LLMs can be time-consuming, as in many practical scenarios, they require a significant amount of storage space that can only be deployed on remote cloud server nodes. Additionally, using commercial LLMs can be costly since they may charge based on usage frequency. In this paper, we explore how to enable intelligent cost-effective interactions between the agent and an LLM. We propose a reinforcement learning based mediator model that determines when it is necessary to consult LLMs for high-level instructions to accomplish a target task. Experiments on 4 MiniGrid environments that entail planning sub-goals demonstrate that our method can learn to solve target tasks with only a few necessary interactions with an LLM, significantly reducing interaction costs in testing environments, compared with baseline methods. Experimental results also suggest that by learning a mediator model to interact with the LLM, the agent's performance becomes more robust against partial observability of the environment. Our code is available at https://github.com/ZJLAB-AMMI/LLM4RL.
Toward Fair Facial Expression Recognition with Improved Distribution Alignment
Jun 11, 2023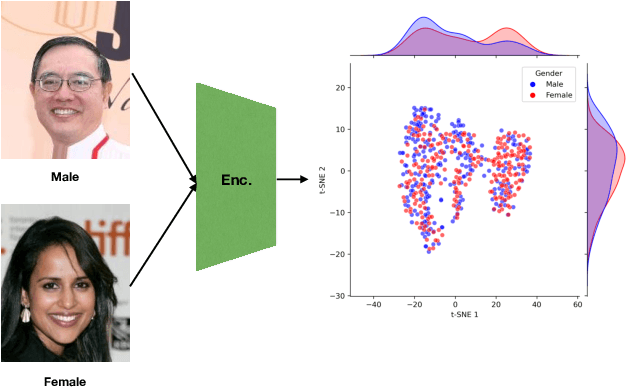
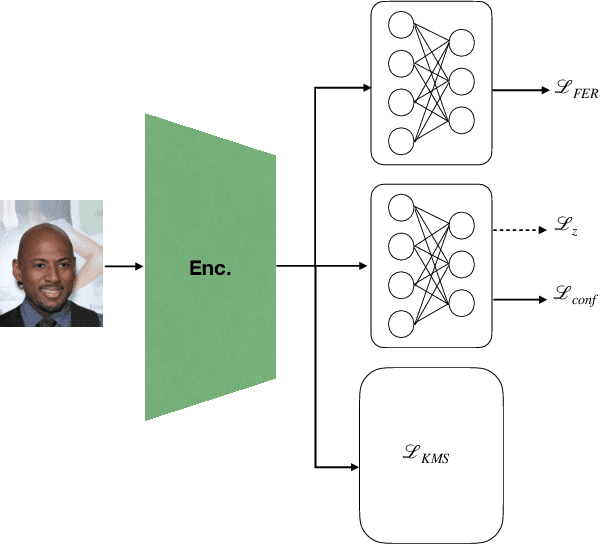
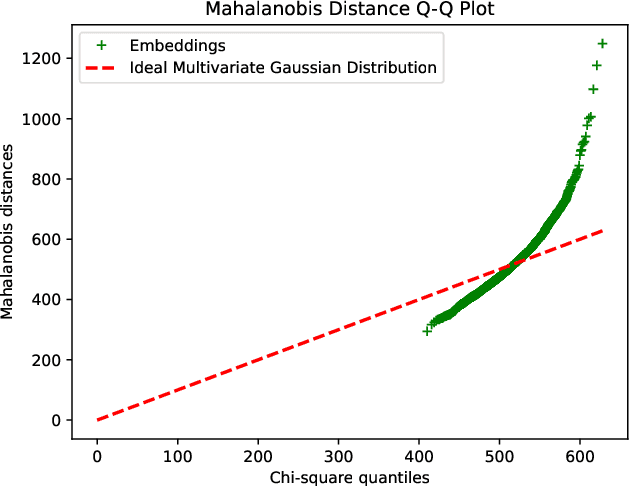
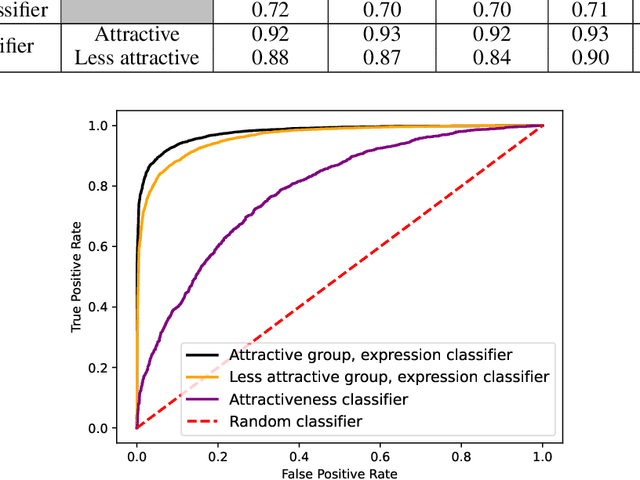
We present a novel approach to mitigate bias in facial expression recognition (FER) models. Our method aims to reduce sensitive attribute information such as gender, age, or race, in the embeddings produced by FER models. We employ a kernel mean shrinkage estimator to estimate the kernel mean of the distributions of the embeddings associated with different sensitive attribute groups, such as young and old, in the Hilbert space. Using this estimation, we calculate the maximum mean discrepancy (MMD) distance between the distributions and incorporate it in the classifier loss along with an adversarial loss, which is then minimized through the learning process to improve the distribution alignment. Our method makes sensitive attributes less recognizable for the model, which in turn promotes fairness. Additionally, for the first time, we analyze the notion of attractiveness as an important sensitive attribute in FER models and demonstrate that FER models can indeed exhibit biases towards more attractive faces. To prove the efficacy of our model in reducing bias regarding different sensitive attributes (including the newly proposed attractiveness attribute), we perform several experiments on two widely used datasets, CelebA and RAF-DB. The results in terms of both accuracy and fairness measures outperform the state-of-the-art in most cases, demonstrating the effectiveness of the proposed method.
Random-Access Neural Compression of Material Textures
May 26, 2023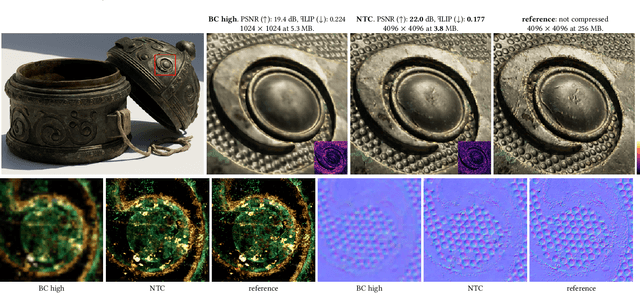

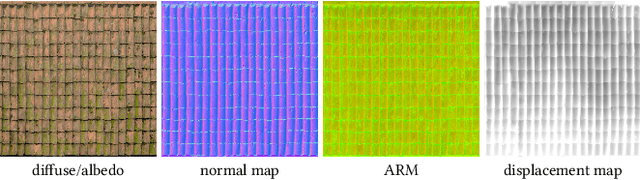

The continuous advancement of photorealism in rendering is accompanied by a growth in texture data and, consequently, increasing storage and memory demands. To address this issue, we propose a novel neural compression technique specifically designed for material textures. We unlock two more levels of detail, i.e., 16x more texels, using low bitrate compression, with image quality that is better than advanced image compression techniques, such as AVIF and JPEG XL. At the same time, our method allows on-demand, real-time decompression with random access similar to block texture compression on GPUs, enabling compression on disk and memory. The key idea behind our approach is compressing multiple material textures and their mipmap chains together, and using a small neural network, that is optimized for each material, to decompress them. Finally, we use a custom training implementation to achieve practical compression speeds, whose performance surpasses that of general frameworks, like PyTorch, by an order of magnitude.
On the Generalization Capacities of Neural Controlled Differential Equations
May 26, 2023We consider a supervised learning setup in which the goal is to predicts an outcome from a sample of irregularly sampled time series using Neural Controlled Differential Equations (Kidger, Morrill, et al. 2020). In our framework, the time series is a discretization of an unobserved continuous path, and the outcome depends on this path through a controlled differential equation with unknown vector field. Learning with discrete data thus induces a discretization bias, which we precisely quantify. Using theoretical results on the continuity of the flow of controlled differential equations, we show that the approximation bias is directly related to the approximation error of a Lipschitz function defining the generative model by a shallow neural network. By combining these result with recent work linking the Lipschitz constant of neural networks to their generalization capacities, we upper bound the generalization gap between the expected loss attained by the empirical risk minimizer and the expected loss of the true predictor.
Efficient Quantization-aware Training with Adaptive Coreset Selection
Jun 12, 2023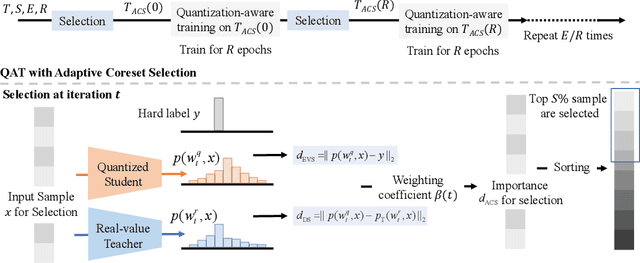
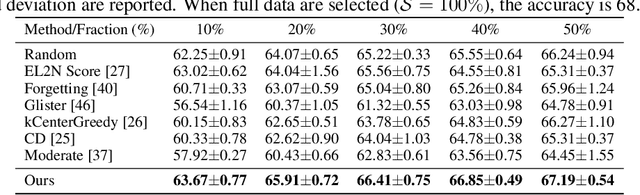
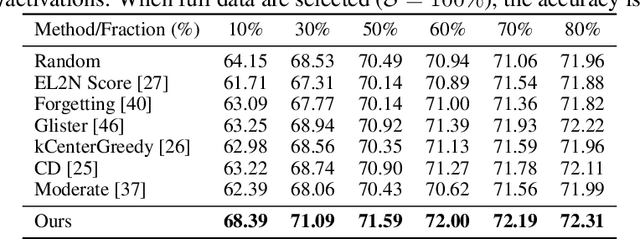
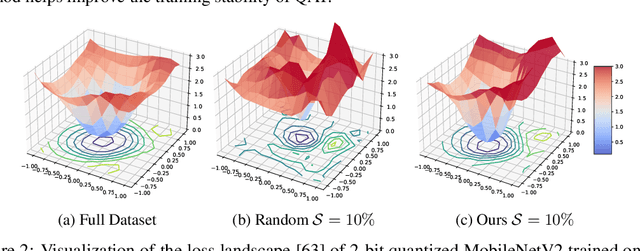
The expanding model size and computation of deep neural networks (DNNs) have increased the demand for efficient model deployment methods. Quantization-aware training (QAT) is a representative model compression method to leverage redundancy in weights and activations. However, most existing QAT methods require end-to-end training on the entire dataset, which suffers from long training time and high energy costs. Coreset selection, aiming to improve data efficiency utilizing the redundancy of training data, has also been widely used for efficient training. In this work, we propose a new angle through the coreset selection to improve the training efficiency of quantization-aware training. Based on the characteristics of QAT, we propose two metrics: error vector score and disagreement score, to quantify the importance of each sample during training. Guided by these two metrics of importance, we proposed a quantization-aware adaptive coreset selection (ACS) method to select the data for the current training epoch. We evaluate our method on various networks (ResNet-18, MobileNetV2), datasets(CIFAR-100, ImageNet-1K), and under different quantization settings. Compared with previous coreset selection methods, our method significantly improves QAT performance with different dataset fractions. Our method can achieve an accuracy of 68.39% of 4-bit quantized ResNet-18 on the ImageNet-1K dataset with only a 10% subset, which has an absolute gain of 4.24% compared to the baseline.
Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow
Jun 12, 2023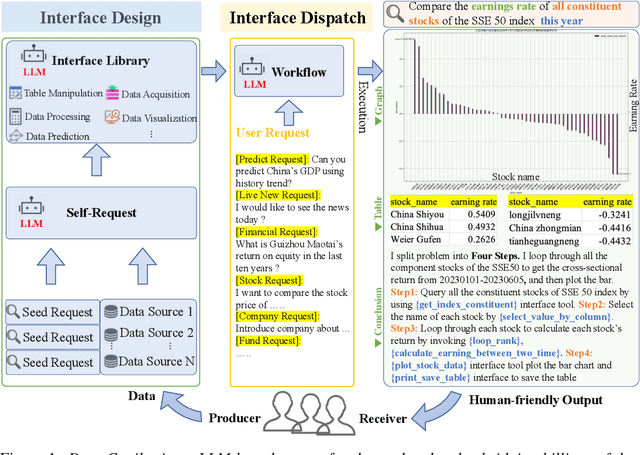
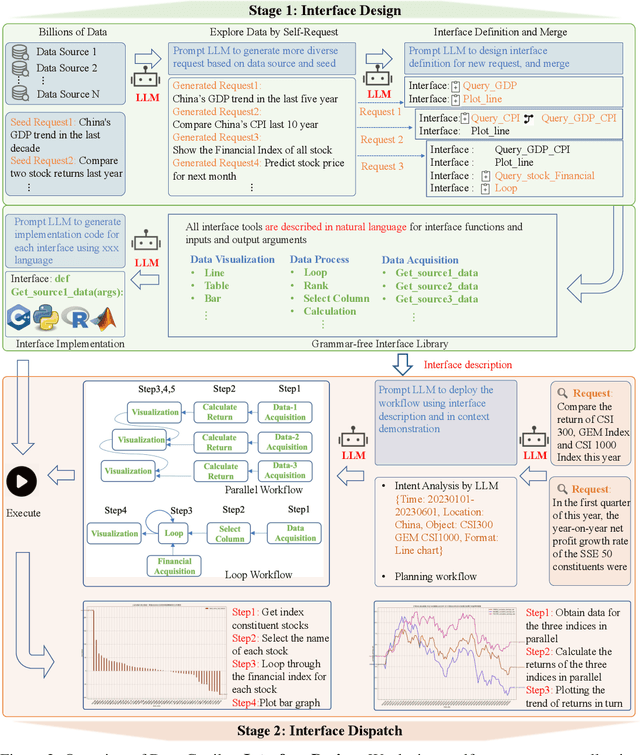
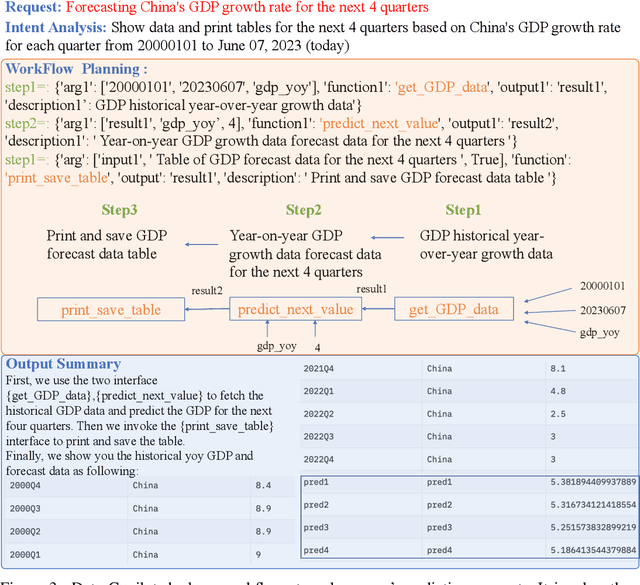
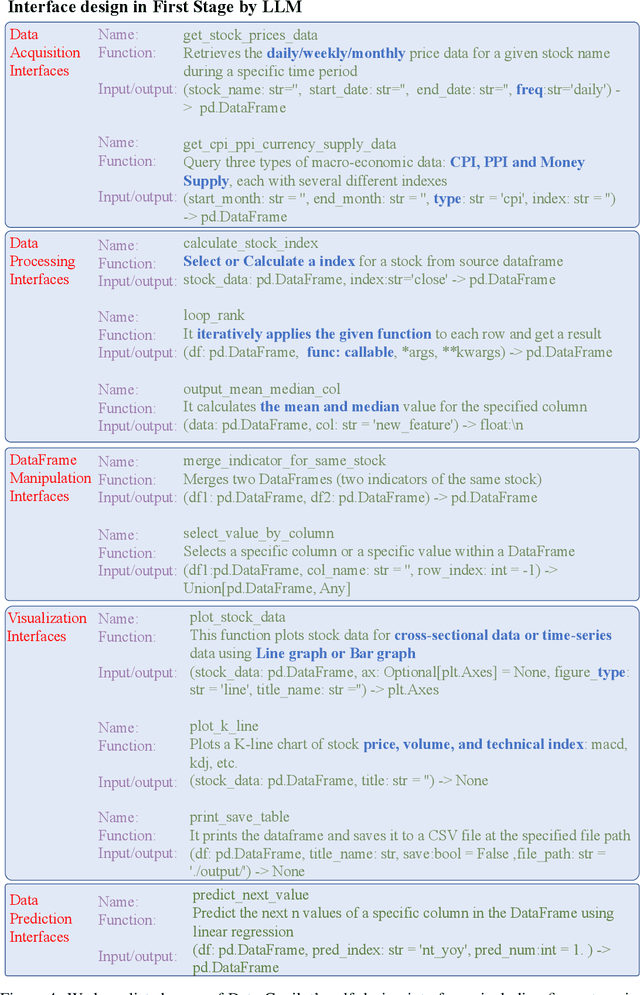
Various industries such as finance, meteorology, and energy generate vast amounts of heterogeneous data every day. There is a natural demand for humans to manage, process, and display data efficiently. However, it necessitates labor-intensive efforts and a high level of expertise for these data-related tasks. Considering that large language models (LLMs) have showcased promising capabilities in semantic understanding and reasoning, we advocate that the deployment of LLMs could autonomously manage and process massive amounts of data while displaying and interacting in a human-friendly manner. Based on this belief, we propose Data-Copilot, an LLM-based system that connects numerous data sources on one end and caters to diverse human demands on the other end. Acting like an experienced expert, Data-Copilot autonomously transforms raw data into visualization results that best match the user's intent. Specifically, Data-Copilot autonomously designs versatile interfaces (tools) for data management, processing, prediction, and visualization. In real-time response, it automatically deploys a concise workflow by invoking corresponding interfaces step by step for the user's request. The interface design and deployment processes are fully controlled by Data-Copilot itself, without human assistance. Besides, we create a Data-Copilot demo that links abundant data from different domains (stock, fund, company, economics, and live news) and accurately respond to diverse requests, serving as a reliable AI assistant.
Occlusion-Aware Path Planning for Collision Avoidance: Leveraging Potential Field Method with Responsibility-Sensitive Safety
Jun 12, 2023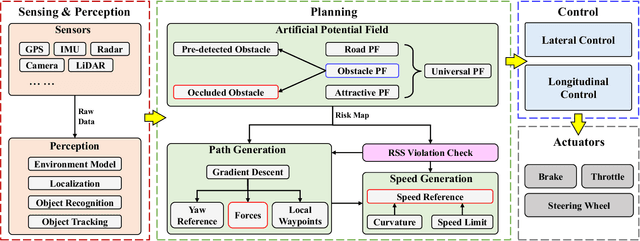
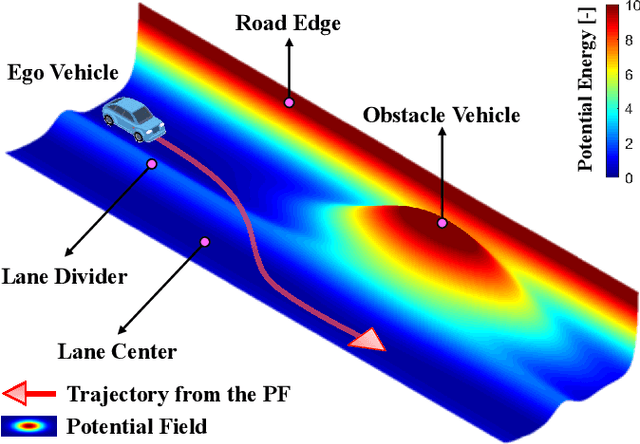
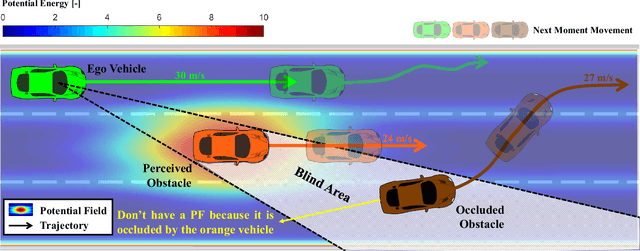
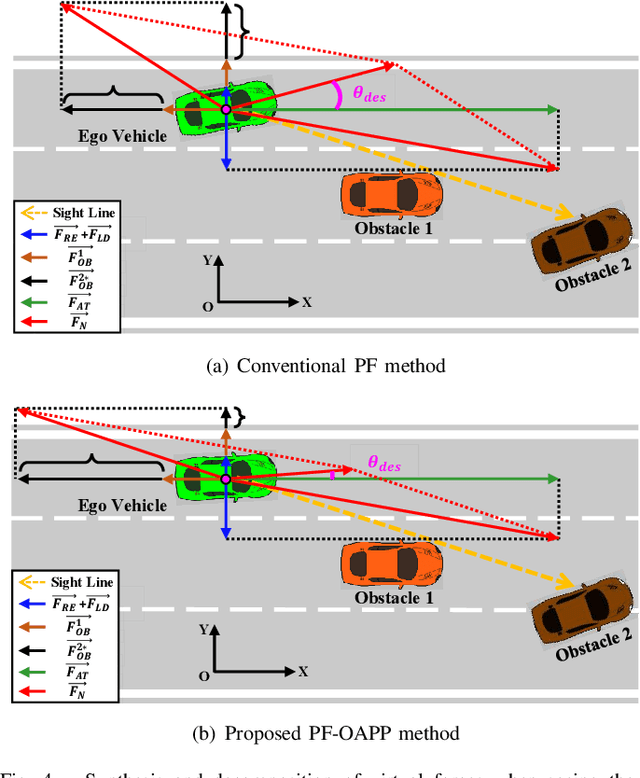
Collision avoidance (CA) has always been the foremost task for autonomous vehicles (AVs) under safety criteria. And path planning is directly responsible for generating a safe path to accomplish CA while satisfying other commands. Due to the real-time computation and simple structure, the potential field (PF) has emerged as one of the mainstream path-planning algorithms. However, the current PF is primarily simulated in ideal CA scenarios, assuming complete obstacle information while disregarding occlusion issues where obstacles can be partially or entirely hidden from the AV's sensors. During the occlusion period, the occluded obstacles do not possess a PF. Once the occlusion is over, these obstacles can generate an instantaneous virtual force that impacts the ego vehicle. Therefore, we propose an occlusion-aware path planning (OAPP) with the responsibility-sensitive safety (RSS)-based PF to tackle the occlusion problem for non-connected AVs. We first categorize the detected and occluded obstacles, and then we proceed to the RSS violation check. Finally, we can generate different virtual forces from the PF for occluded and non-occluded obstacles. We compare the proposed OAPP method with other PF-based path planning methods via MATLAB/Simulink. The simulation results indicate that the proposed method can eliminate instantaneous lateral oscillation or sway and produce a smoother path than conventional PF methods.
Inflated 3D Convolution-Transformer for Weakly-supervised Carotid Stenosis Grading with Ultrasound Videos
Jun 12, 2023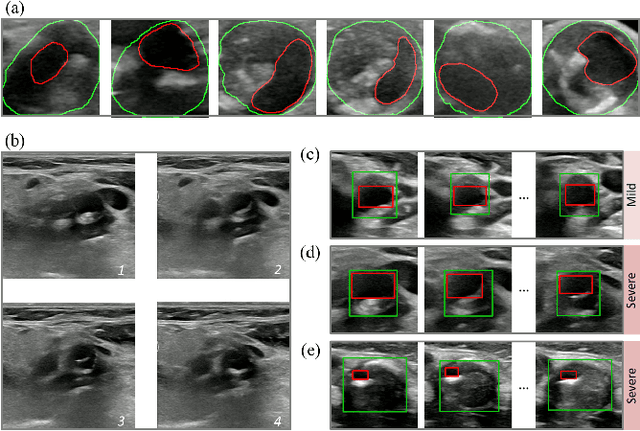
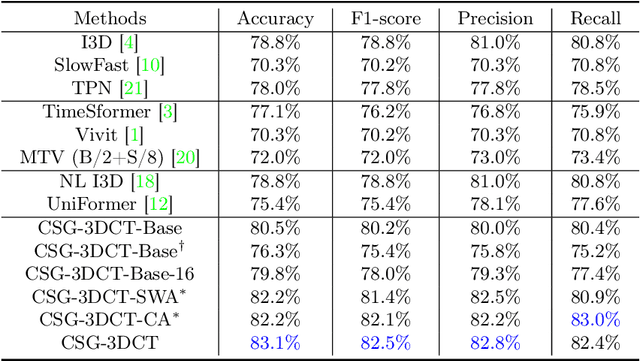
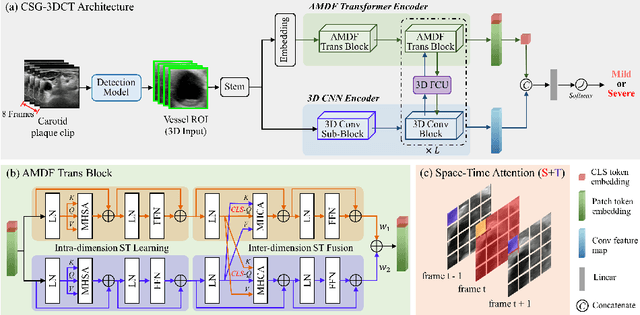
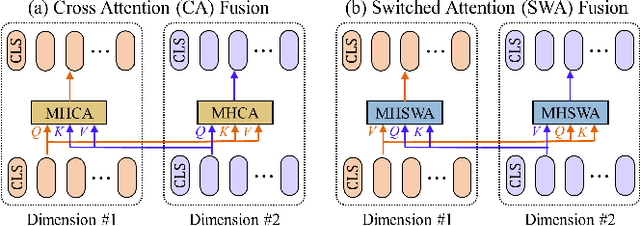
Localization of the narrowest position of the vessel and corresponding vessel and remnant vessel delineation in carotid ultrasound (US) are essential for carotid stenosis grading (CSG) in clinical practice. However, the pipeline is time-consuming and tough due to the ambiguous boundaries of plaque and temporal variation. To automatize this procedure, a large number of manual delineations are usually required, which is not only laborious but also not reliable given the annotation difficulty. In this study, we present the first video classification framework for automatic CSG. Our contribution is three-fold. First, to avoid the requirement of laborious and unreliable annotation, we propose a novel and effective video classification network for weakly-supervised CSG. Second, to ease the model training, we adopt an inflation strategy for the network, where pre-trained 2D convolution weights can be adapted into the 3D counterpart in our network for an effective warm start. Third, to enhance the feature discrimination of the video, we propose a novel attention-guided multi-dimension fusion (AMDF) transformer encoder to model and integrate global dependencies within and across spatial and temporal dimensions, where two lightweight cross-dimensional attention mechanisms are designed. Our approach is extensively validated on a large clinically collected carotid US video dataset, demonstrating state-of-the-art performance compared with strong competitors.
Understanding Model Complexity for temporal tabular and multi-variate time series, case study with Numerai data science tournament
Mar 14, 2023
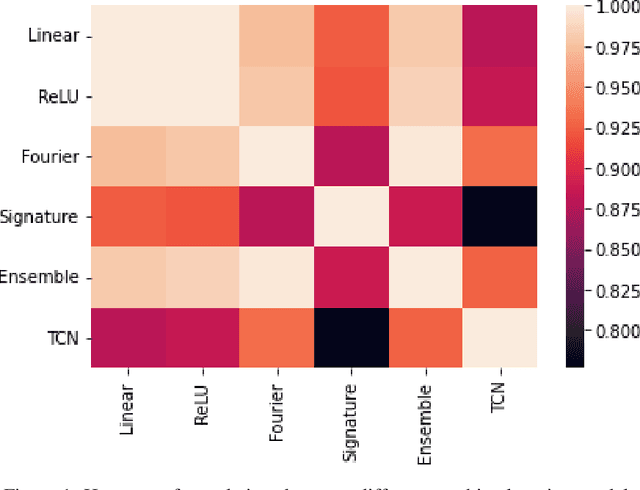

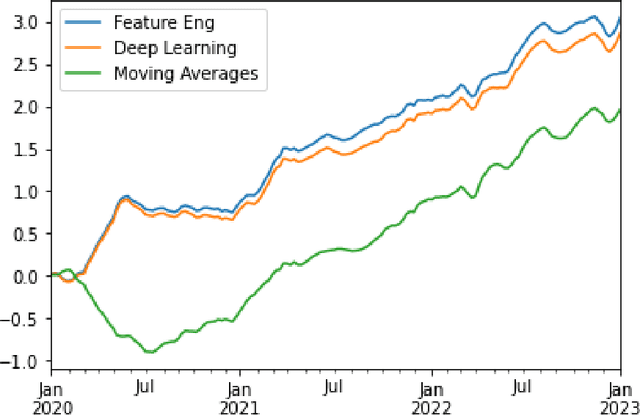
In this paper, we explore the use of different feature engineering and dimensionality reduction methods in multi-variate time-series modelling. Using a feature-target cross correlation time series dataset created from Numerai tournament, we demonstrate under over-parameterised regime, both the performance and predictions from different feature engineering methods converge to the same equilibrium, which can be characterised by the reproducing kernel Hilbert space. We suggest a new Ensemble method, which combines different random non-linear transforms followed by ridge regression for modelling high dimensional time-series. Compared to some commonly used deep learning models for sequence modelling, such as LSTM and transformers, our method is more robust (lower model variance over different random seeds and less sensitive to the choice of architecture) and more efficient. An additional advantage of our method is model simplicity as there is no need to use sophisticated deep learning frameworks such as PyTorch. The learned feature rankings are then applied to the temporal tabular prediction problem in the Numerai tournament, and the predictive power of feature rankings obtained from our method is better than the baseline prediction model based on moving averages
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Feb 23, 2023
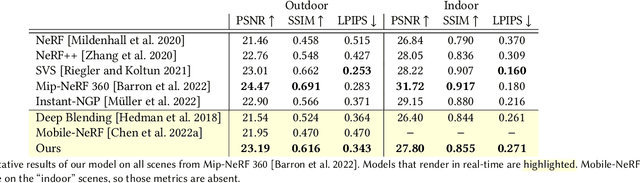
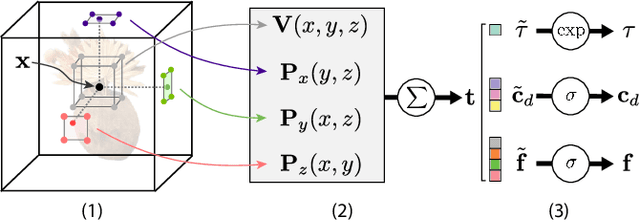
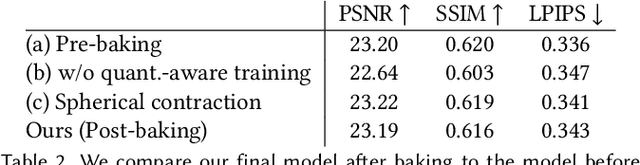
Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.