 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
To Collide or Not To Collide -- Exploiting Passive Deformable Quadrotors for Contact-Rich Tasks
May 26, 2023

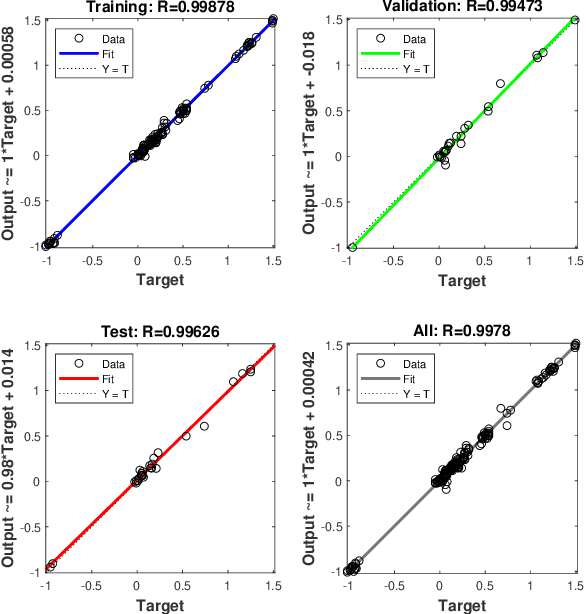
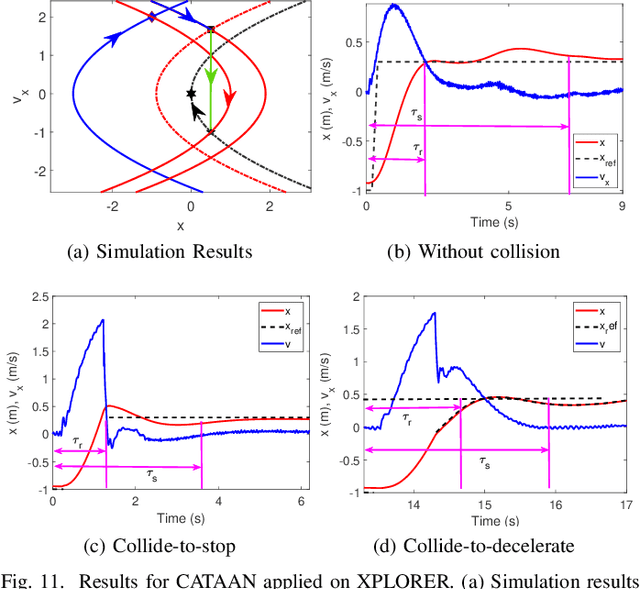
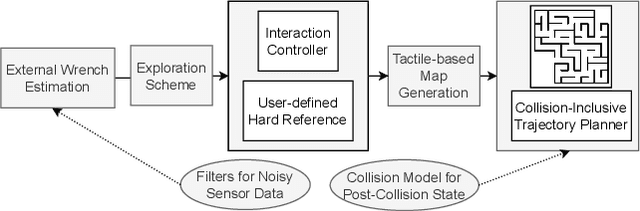
With an increase in aerial vehicle applications, passive deformable quadrotors are getting significant attention in the research community due to their potential to perform physical interaction tasks. Such quadrotors are capable of undergoing collisions, both planned and unplanned, which are harnessed to induce deformation and retain stability by dissipating collision energies. In this article, we utilize one such passive deforming quadrotor, XPLORER, to complete various contact-rich tasks by exploiting its compliant chassis via various impact-aware planning and control algorithms. At the core of these algorithms is a novel external wrench estimation technique developed specifically for the unique multi-linked structure of XPLORER's chassis. The external wrench information is then employed for designing interaction controllers to obtain three additional flight modes: static-wrench application, disturbance rejection and yielding to the disturbance. These modes are then incorporated into a novel online exploration scheme to enable navigation in unknown flight spaces with only tactile feedback and generate a map of the environment without requiring additional sensors. Experiments show the efficacy of this scheme to generate maps of the previously unexplored flight space with an accuracy of 96.72%. Finally, we develop a novel collision-aware trajectory planner (CATAAN) to generate minimum time maneuvers for waypoint tracking by integrating collision-induced state jumps for both elastic and inelastic cases. We experimentally validate that minimum time trajectories can be obtained with CATAAN leading to a 40.38% reduction of settling time accompanied by improved tracking performance of a root mean squared error in position within 0.5cm as compared to 3cm of conventional methods.
RNN-Based GNSS Positioning using Satellite Measurement Features and Pseudorange Residuals
Jun 08, 2023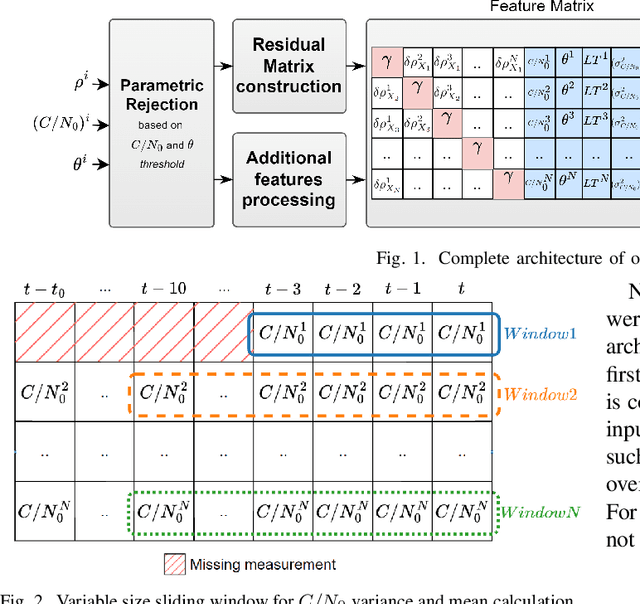

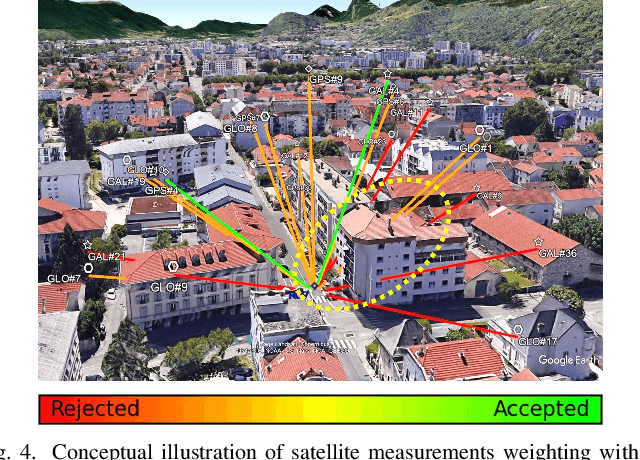
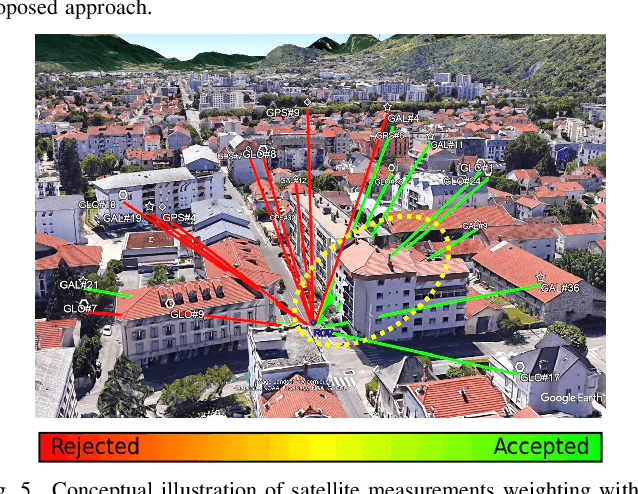
In the Global Navigation Satellite System (GNSS) context, the growing number of available satellites has lead to many challenges when it comes to choosing the most accurate pseudorange contributions, given the strong impact of biased measurements on positioning accuracy, particularly in single-epoch scenarios. This work leverages the potential of machine learning in predicting link-wise measurement quality factors and, hence, optimize measurement weighting. For this purpose, we use a customized matrix composed of heterogeneous features such as conditional pseudorange residuals and per-link satellite metrics (e.g., carrier-to-noise power density ratio and its empirical statistics, satellite elevation, carrier phase lock time). This matrix is then fed as an input to a recurrent neural network (RNN) (i.e., a long-short term memory (LSTM) network). Our experimental results on real data, obtained from extensive field measurements, demonstrate the high potential of our proposed solution being able to outperform traditional measurements weighting and selection strategies from state-of-the-art.
Tracking Everything Everywhere All at Once
Jun 08, 2023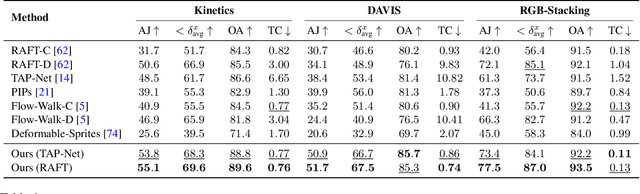
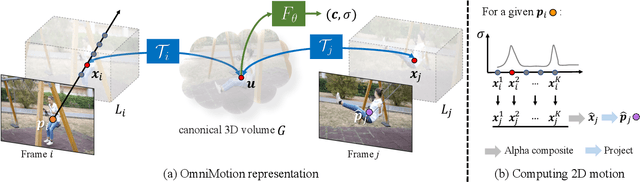

We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusions and maintain global consistency of estimated motion trajectories. We propose a complete and globally consistent motion representation, dubbed OmniMotion, that allows for accurate, full-length motion estimation of every pixel in a video. OmniMotion represents a video using a quasi-3D canonical volume and performs pixel-wise tracking via bijections between local and canonical space. This representation allows us to ensure global consistency, track through occlusions, and model any combination of camera and object motion. Extensive evaluations on the TAP-Vid benchmark and real-world footage show that our approach outperforms prior state-of-the-art methods by a large margin both quantitatively and qualitatively. See our project page for more results: http://omnimotion.github.io/
The Viability of Domain Constrained Coalition Formation for Robotic Collectives
Jun 08, 2023
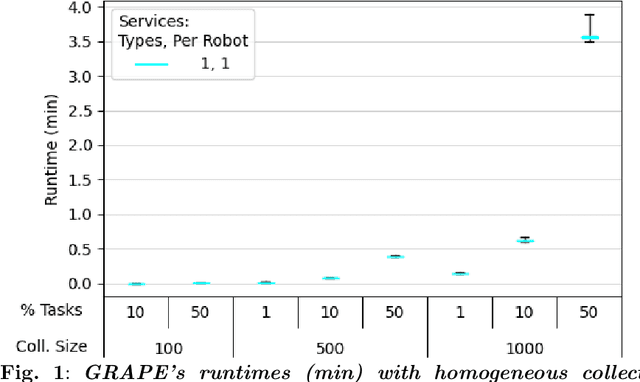

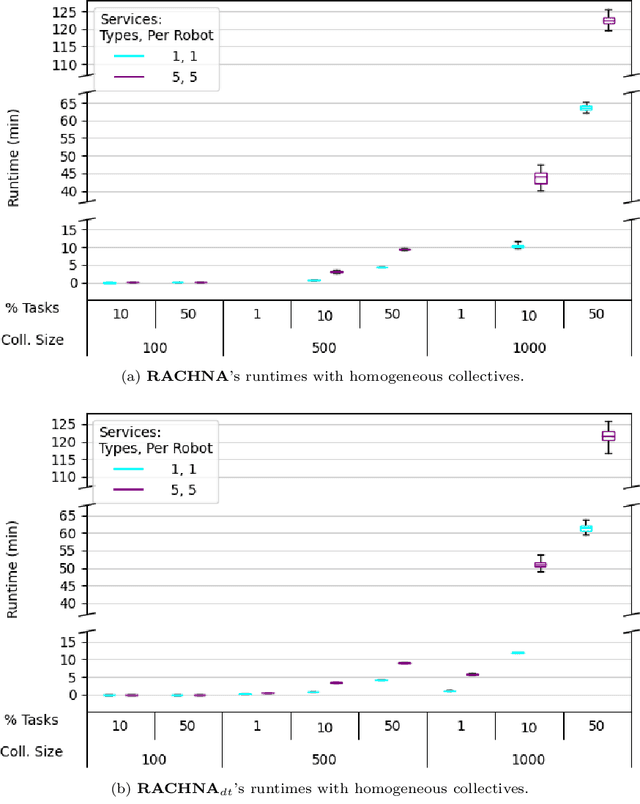
Applications, such as military and disaster response, can benefit from robotic collectives' ability to perform multiple cooperative tasks (e.g., surveillance, damage assessments) efficiently across a large spatial area. Coalition formation algorithms can potentially facilitate collective robots' assignment to appropriate task teams; however, most coalition formation algorithms were designed for smaller multiple robot systems (i.e., 2-50 robots). Collectives' scale and domain-relevant constraints (i.e., distribution, near real-time, minimal communication) make coalition formation more challenging. This manuscript identifies the challenges inherent to designing coalition formation algorithms for very large collectives (e.g., 1000 robots). A survey of multiple robot coalition formation algorithms finds that most are unable to transfer directly to collectives, due to the identified system differences; however, auctions and hedonic games may be the most transferable. A simulation-based evaluation of three auction and hedonic game algorithms, applied to homogeneous and heterogeneous collectives, demonstrates that there are collective compositions for which no existing algorithm is viable; however, the experimental results and literature survey suggest paths forward.
Improving Language Model Integration for Neural Machine Translation
Jun 08, 2023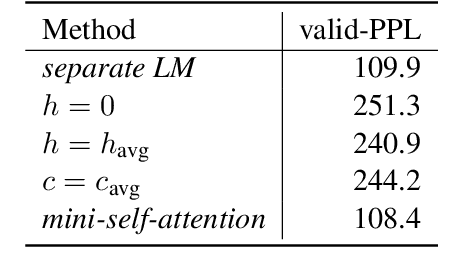
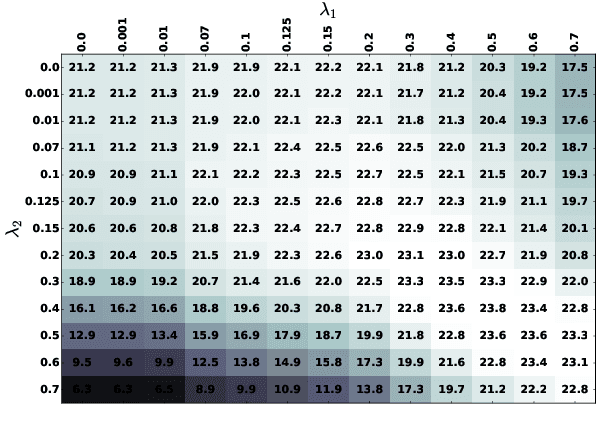
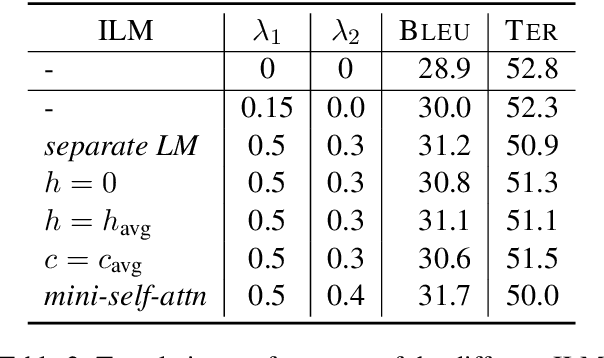
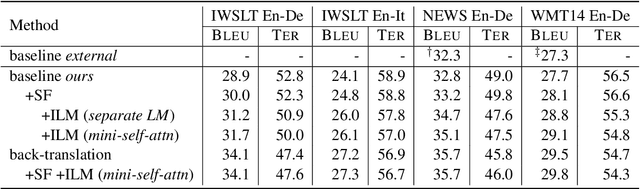
The integration of language models for neural machine translation has been extensively studied in the past. It has been shown that an external language model, trained on additional target-side monolingual data, can help improve translation quality. However, there has always been the assumption that the translation model also learns an implicit target-side language model during training, which interferes with the external language model at decoding time. Recently, some works on automatic speech recognition have demonstrated that, if the implicit language model is neutralized in decoding, further improvements can be gained when integrating an external language model. In this work, we transfer this concept to the task of machine translation and compare with the most prominent way of including additional monolingual data - namely back-translation. We find that accounting for the implicit language model significantly boosts the performance of language model fusion, although this approach is still outperformed by back-translation.
Data Quality in Imitation Learning
Jun 04, 2023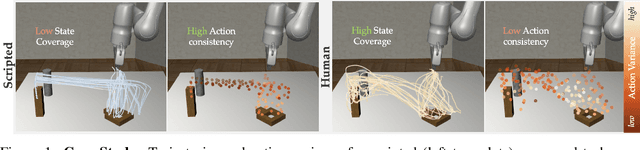
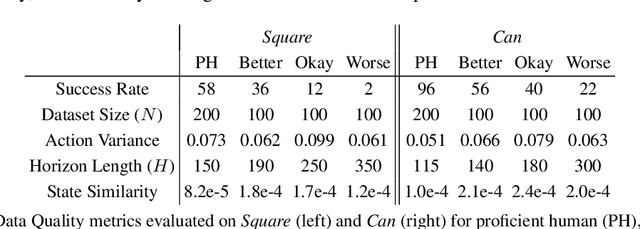
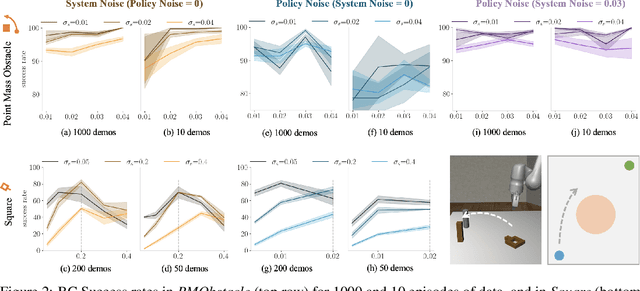
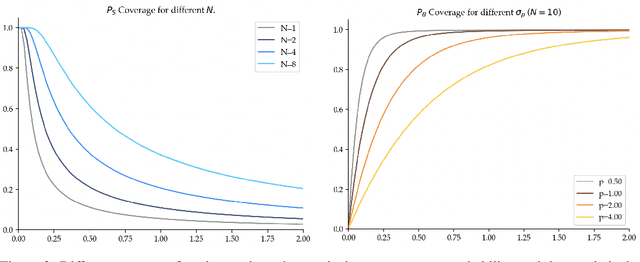
In supervised learning, the question of data quality and curation has been over-shadowed in recent years by increasingly more powerful and expressive models that can ingest internet-scale data. However, in offline learning for robotics, we simply lack internet scale data, and so high quality datasets are a necessity. This is especially true in imitation learning (IL), a sample efficient paradigm for robot learning using expert demonstrations. Policies learned through IL suffer from state distribution shift at test time due to compounding errors in action prediction, which leads to unseen states that the policy cannot recover from. Instead of designing new algorithms to address distribution shift, an alternative perspective is to develop new ways of assessing and curating datasets. There is growing evidence that the same IL algorithms can have substantially different performance across different datasets. This calls for a formalism for defining metrics of "data quality" that can further be leveraged for data curation. In this work, we take the first step toward formalizing data quality for imitation learning through the lens of distribution shift: a high quality dataset encourages the policy to stay in distribution at test time. We propose two fundamental properties that shape the quality of a dataset: i) action divergence: the mismatch between the expert and learned policy at certain states; and ii) transition diversity: the noise present in the system for a given state and action. We investigate the combined effect of these two key properties in imitation learning theoretically, and we empirically analyze models trained on a variety of different data sources. We show that state diversity is not always beneficial, and we demonstrate how action divergence and transition diversity interact in practice.
QFA2SR: Query-Free Adversarial Transfer Attacks to Speaker Recognition Systems
May 23, 2023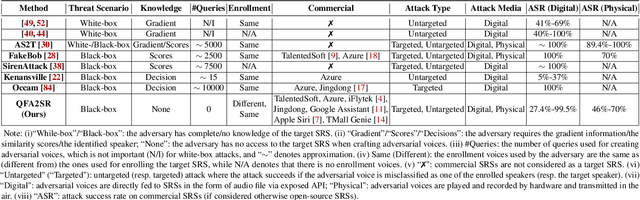
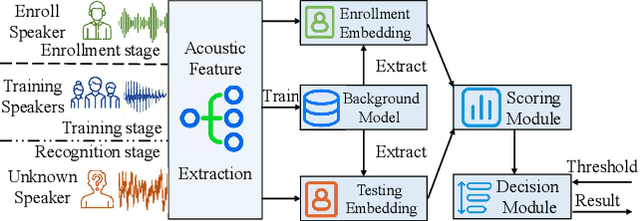
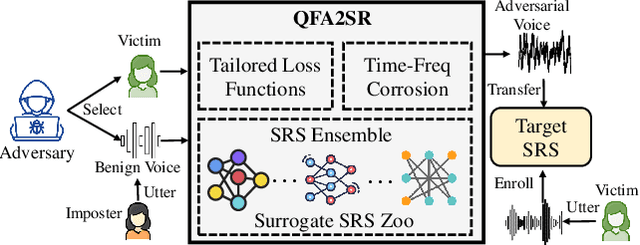
Current adversarial attacks against speaker recognition systems (SRSs) require either white-box access or heavy black-box queries to the target SRS, thus still falling behind practical attacks against proprietary commercial APIs and voice-controlled devices. To fill this gap, we propose QFA2SR, an effective and imperceptible query-free black-box attack, by leveraging the transferability of adversarial voices. To improve transferability, we present three novel methods, tailored loss functions, SRS ensemble, and time-freq corrosion. The first one tailors loss functions to different attack scenarios. The latter two augment surrogate SRSs in two different ways. SRS ensemble combines diverse surrogate SRSs with new strategies, amenable to the unique scoring characteristics of SRSs. Time-freq corrosion augments surrogate SRSs by incorporating well-designed time-/frequency-domain modification functions, which simulate and approximate the decision boundary of the target SRS and distortions introduced during over-the-air attacks. QFA2SR boosts the targeted transferability by 20.9%-70.7% on four popular commercial APIs (Microsoft Azure, iFlytek, Jingdong, and TalentedSoft), significantly outperforming existing attacks in query-free setting, with negligible effect on the imperceptibility. QFA2SR is also highly effective when launched over the air against three wide-spread voice assistants (Google Assistant, Apple Siri, and TMall Genie) with 60%, 46%, and 70% targeted transferability, respectively.
Trend-Based SAC Beam Control Method with Zero-Shot in Superconducting Linear Accelerator
May 23, 2023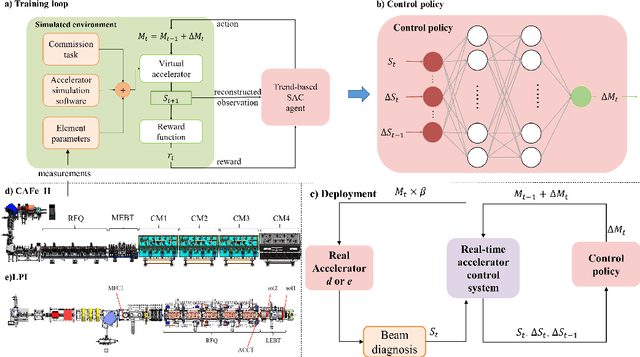

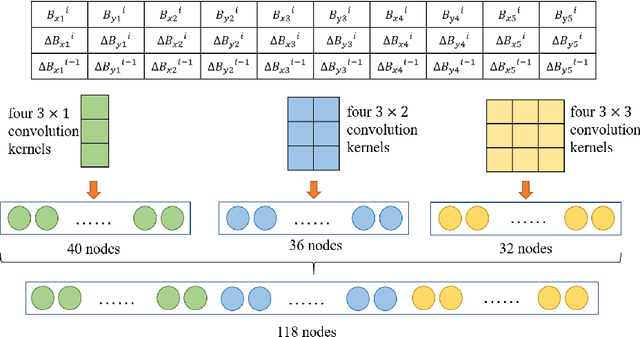
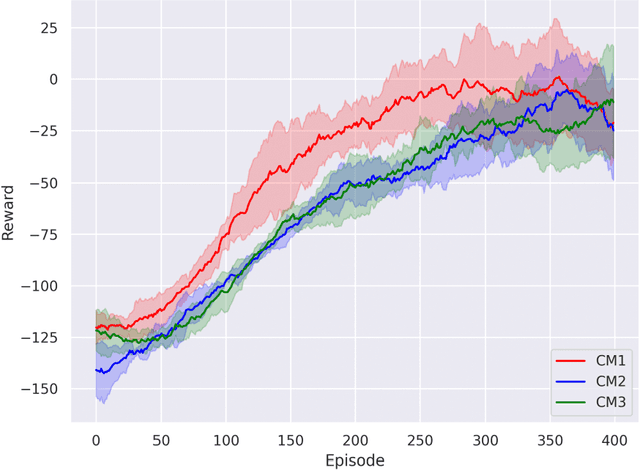
The superconducting linear accelerator is a highly flexiable facility for modern scientific discoveries, necessitating weekly reconfiguration and tuning. Accordingly, minimizing setup time proves essential in affording users with ample experimental time. We propose a trend-based soft actor-critic(TBSAC) beam control method with strong robustness, allowing the agents to be trained in a simulated environment and applied to the real accelerator directly with zero-shot. To validate the effectiveness of our method, two different typical beam control tasks were performed on China Accelerator Facility for Superheavy Elements (CAFe II) and a light particle injector(LPI) respectively. The orbit correction tasks were performed in three cryomodules in CAFe II seperately, the time required for tuning has been reduced to one-tenth of that needed by human experts, and the RMS values of the corrected orbit were all less than 1mm. The other transmission efficiency optimization task was conducted in the LPI, our agent successfully optimized the transmission efficiency of radio-frequency quadrupole(RFQ) to over $85\%$ within 2 minutes. The outcomes of these two experiments offer substantiation that our proposed TBSAC approach can efficiently and effectively accomplish beam commissioning tasks while upholding the same standard as skilled human experts. As such, our method exhibits potential for future applications in other accelerator commissioning fields.
Streaming Object Detection on Fisheye Cameras for Automatic Parking
May 24, 2023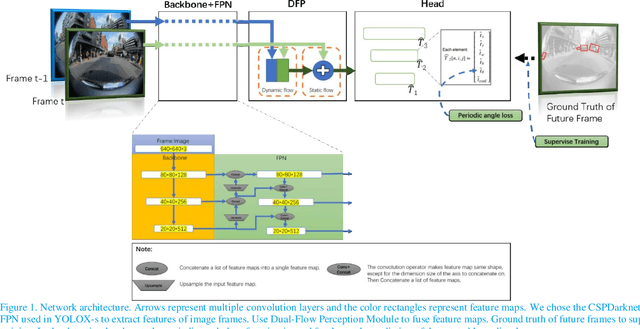
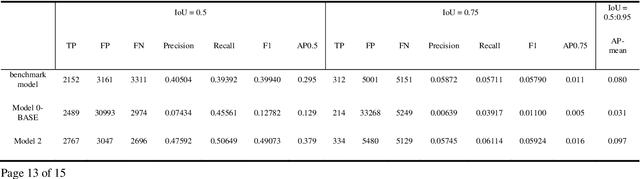
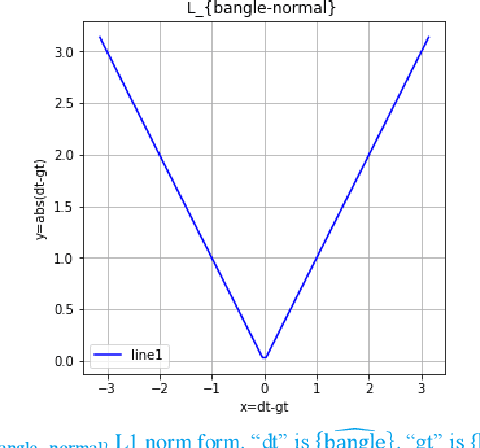

Fisheye cameras are widely employed in automatic parking, and the video stream object detection (VSOD) of the fisheye camera is a fundamental perception function to ensure the safe operation of vehicles. In past research work, the difference between the output of the deep learning model and the actual situation at the current moment due to the existence of delay of the perception system is generally ignored. But the environment will inevitably change within the delay time which may cause a potential safety hazard. In this paper, we propose a real-time detection framework equipped with a dual-flow perception module (dynamic and static flows) that can predict the future and alleviate the time-lag problem. Meanwhile, we use a new scheme to evaluate latency and accuracy. The standard bounding box is unsuitable for the object in fisheye camera images due to the strong radial distortion of the fisheye camera and the primary detection objects of parking perception are vehicles and pedestrians, so we adopt the rotate bounding box and propose a new periodic angle loss function to regress the angle of the box, which is the simple and accurate representation method of objects. The instance segmentation ground truth is used to supervise the training. Experiments demonstrate the effectiveness of our approach. Code is released at: https://gitee.com/hiyanyx/fisheye-streaming-perception.
Hierarchical Multi-Instance Multi-Label Learning for Detecting Propaganda Techniques
May 30, 2023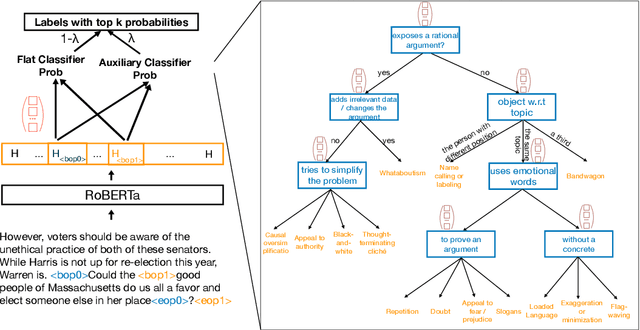

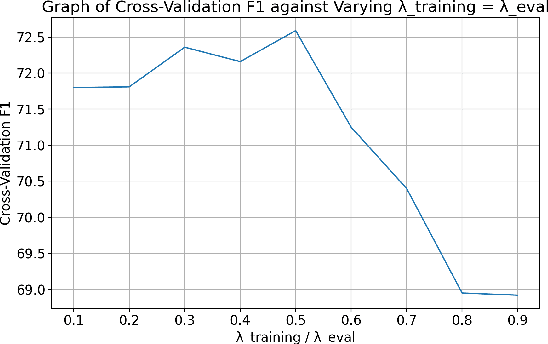
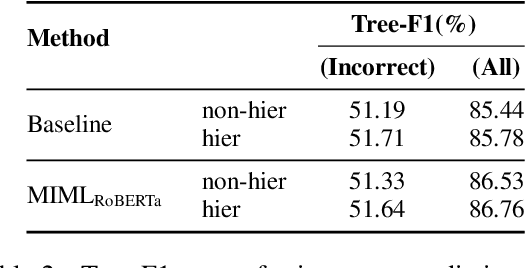
Since the introduction of the SemEval 2020 Task 11 (Martino et al., 2020a), several approaches have been proposed in the literature for classifying propaganda based on the rhetorical techniques used to influence readers. These methods, however, classify one span at a time, ignoring dependencies from the labels of other spans within the same context. In this paper, we approach propaganda technique classification as a Multi-Instance Multi-Label (MIML) learning problem (Zhou et al., 2012) and propose a simple RoBERTa-based model (Zhuang et al., 2021) for classifying all spans in an article simultaneously. Further, we note that, due to the annotation process where annotators classified the spans by following a decision tree, there is an inherent hierarchical relationship among the different techniques, which existing approaches ignore. We incorporate these hierarchical label dependencies by adding an auxiliary classifier for each node in the decision tree to the training objective and ensembling the predictions from the original and auxiliary classifiers at test time. Overall, our model leads to an absolute improvement of 2.47% micro-F1 over the model from the shared task winning team in a cross-validation setup and is the best performing non-ensemble model on the shared task leaderboard.