 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Questioning the Survey Responses of Large Language Models
Jun 13, 2023
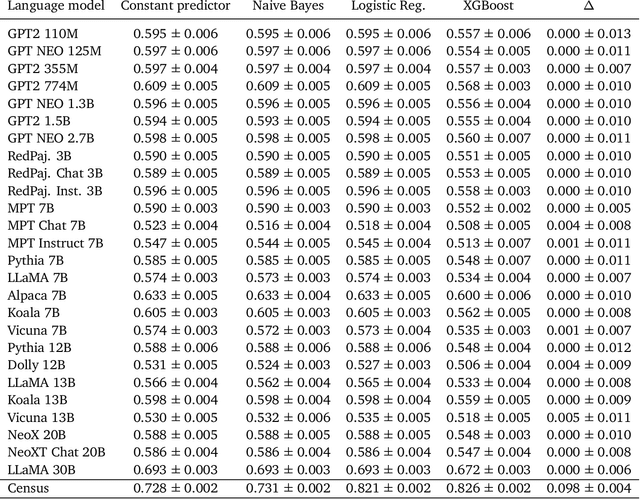
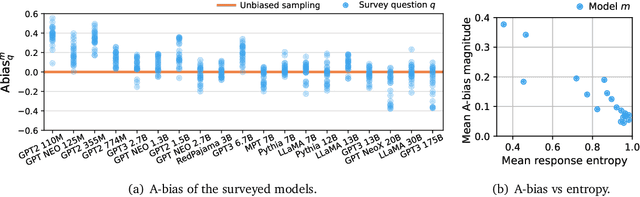
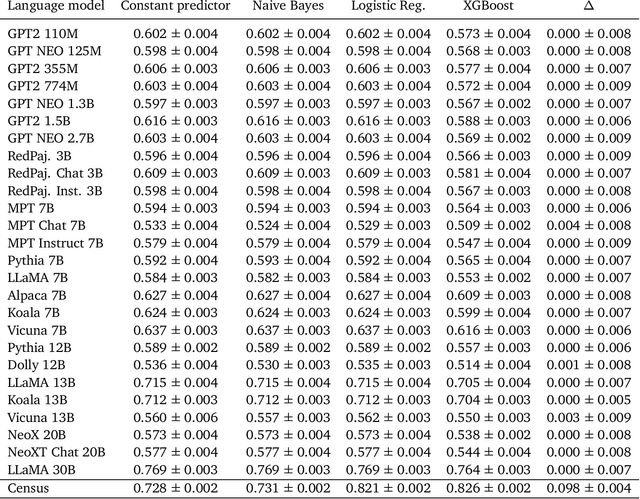
As large language models increase in capability, researchers have started to conduct surveys of all kinds on these models with varying scientific motivations. In this work, we examine what we can learn from a model's survey responses on the basis of the well-established American Community Survey (ACS) by the U.S. Census Bureau. Evaluating more than a dozen different models, varying in size from a few hundred million to ten billion parameters, hundreds of thousands of times each on questions from the ACS, we systematically establish two dominant patterns. First, smaller models have a significant position and labeling bias, for example, towards survey responses labeled with the letter "A". This A-bias diminishes, albeit slowly, as model size increases. Second, when adjusting for this labeling bias through randomized answer ordering, models still do not trend toward US population statistics or those of any cognizable population. Rather, models across the board trend toward uniformly random aggregate statistics over survey responses. This pattern is robust to various different ways of prompting the model, including what is the de-facto standard. Our findings demonstrate that aggregate statistics of a language model's survey responses lack the signals found in human populations. This absence of statistical signal cautions about the use of survey responses from large language models at present time.
RescueSpeech: A German Corpus for Speech Recognition in Search and Rescue Domain
Jun 06, 2023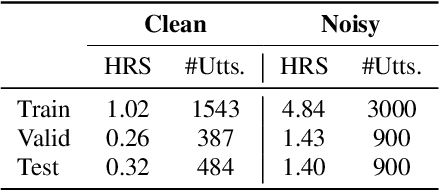
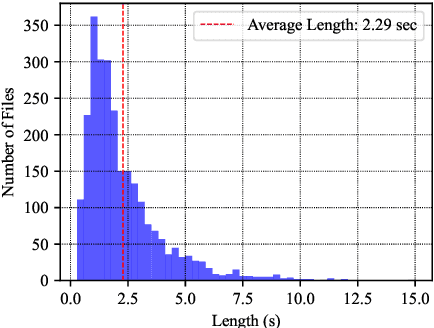
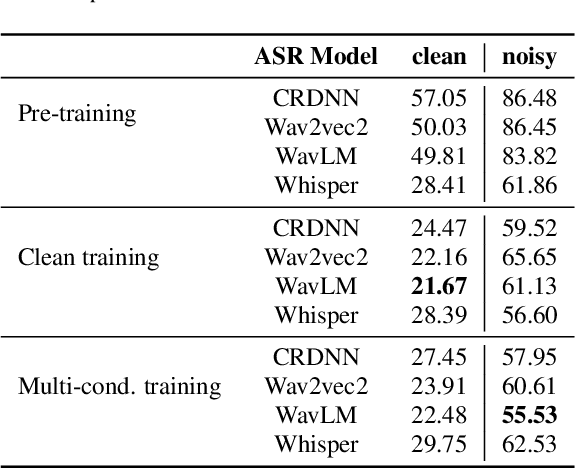
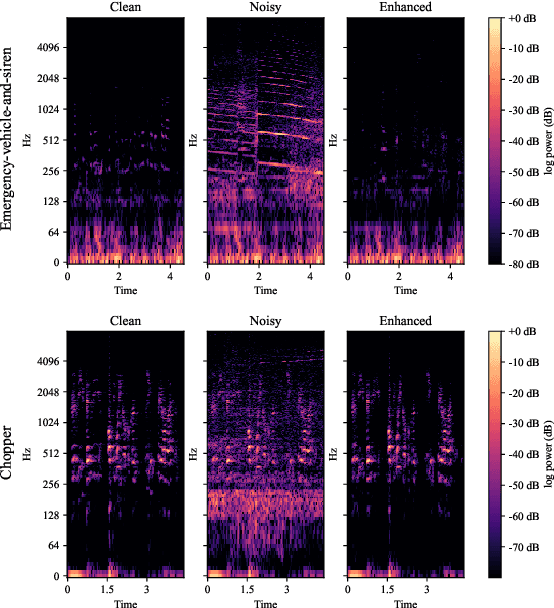
Despite recent advancements in speech recognition, there are still difficulties in accurately transcribing conversational and emotional speech in noisy and reverberant acoustic environments. This poses a particular challenge in the search and rescue (SAR) domain, where transcribing conversations among rescue team members is crucial to support real-time decision-making. The scarcity of speech data and associated background noise in SAR scenarios make it difficult to deploy robust speech recognition systems. To address this issue, we have created and made publicly available a German speech dataset called RescueSpeech. This dataset includes real speech recordings from simulated rescue exercises. Additionally, we have released competitive training recipes and pre-trained models. Our study indicates that the current level of performance achieved by state-of-the-art methods is still far from being acceptable.
Time-Varying Graph Mode Decomposition
Jan 09, 2023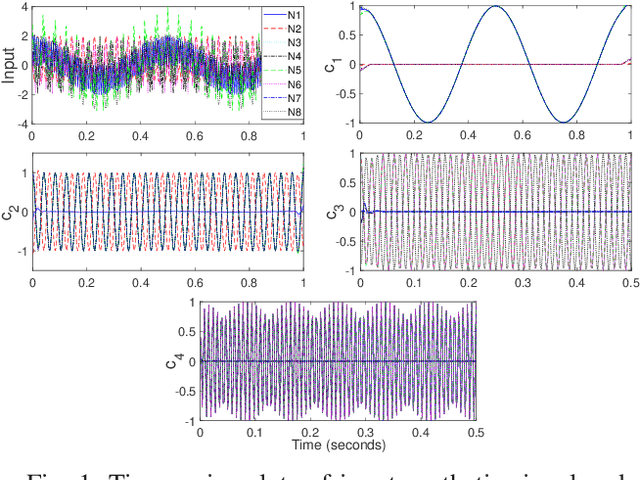
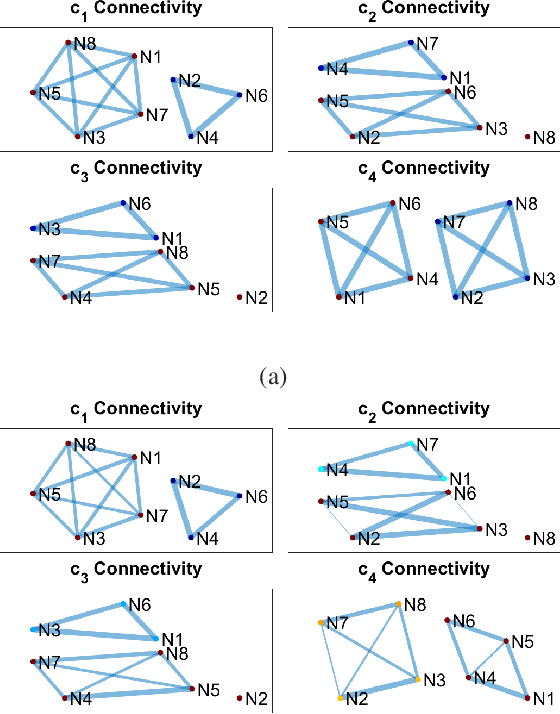
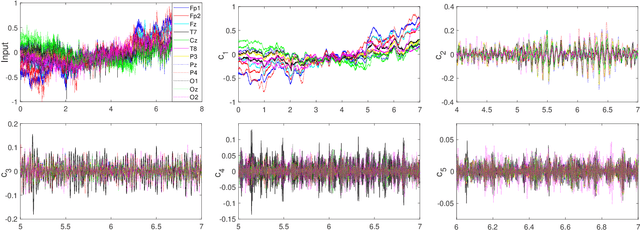
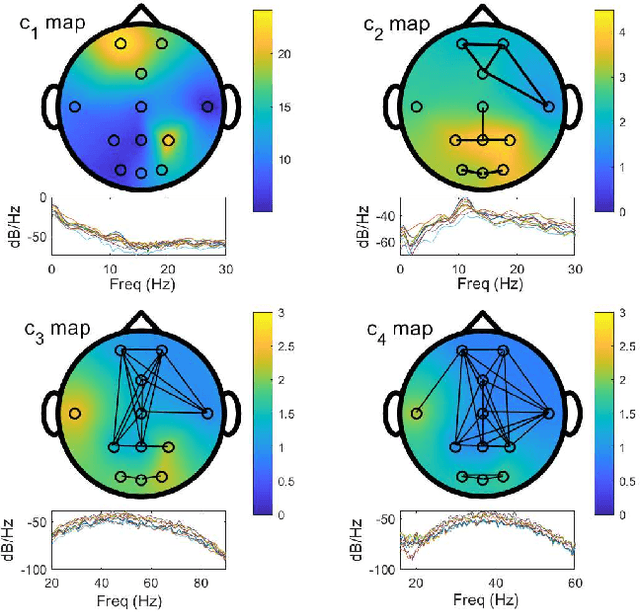
Time-varying graph signals are alternative representation of multivariate (or multichannel) signals in which a single time-series is associated with each of the nodes or vertex of a graph. Aided by the graph-theoretic tools, time-varying graph models have the ability to capture the underlying structure of the data associated with multiple nodes of a graph -- a feat that is hard to accomplish using standard signal processing approaches. The aim of this contribution is to propose a method for the decomposition of time-varying graph signals into a set of graph modes. The graph modes can be interpreted in terms of their temporal, spectral and topological characteristics. From the temporal (spectral) viewpoint, the graph modes represent the finite number of oscillatory signal components (output of multiple band-pass filters whose center frequencies and bandwidths are learned in a fully data-driven manner), similar in properties to those obtained from the empirical mode decomposition and related approaches. From the topological perspective, the graph modes quantify the functional connectivity of the graph vertices at multiple scales based on their signal content. In order to estimate the graph modes, a variational optimization formulation is designed that includes necessary temporal, spectral and topological requirements relevant to the graph modes. An efficient method to solve that problem is developed which is based on the alternating direction method of multipliers (ADMM) and the primal-dual optimization approach. Finally, the ability of the method to enable a joint analysis of the temporal and topological characteristics of time-varying graph signals, at multiple frequency bands/scales, is demonstrated on a series of synthetic and real time-varying graph data sets.
Optimal Rates for Bandit Nonstochastic Control
May 24, 2023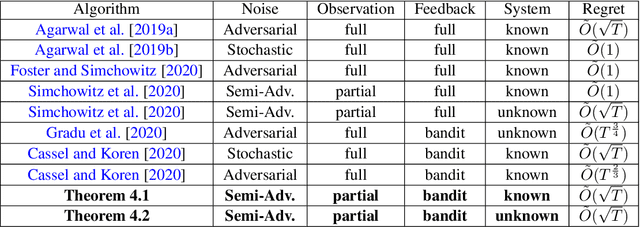
Linear Quadratic Regulator (LQR) and Linear Quadratic Gaussian (LQG) control are foundational and extensively researched problems in optimal control. We investigate LQR and LQG problems with semi-adversarial perturbations and time-varying adversarial bandit loss functions. The best-known sublinear regret algorithm of~\cite{gradu2020non} has a $T^{\frac{3}{4}}$ time horizon dependence, and its authors posed an open question about whether a tight rate of $\sqrt{T}$ could be achieved. We answer in the affirmative, giving an algorithm for bandit LQR and LQG which attains optimal regret (up to logarithmic factors) for both known and unknown systems. A central component of our method is a new scheme for bandit convex optimization with memory, which is of independent interest.
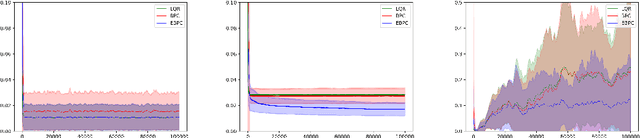
TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
Feb 18, 2023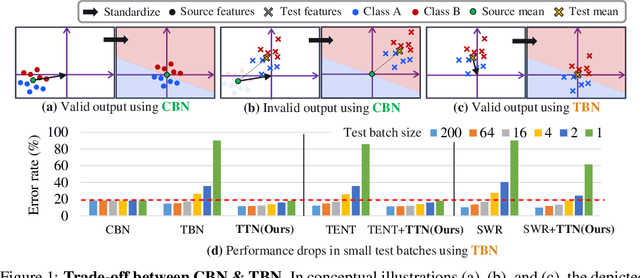
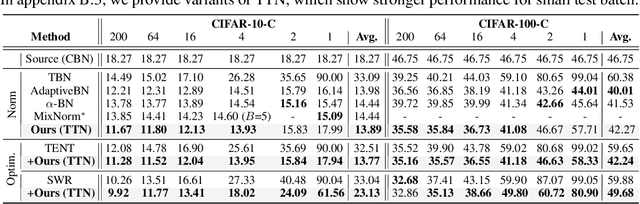
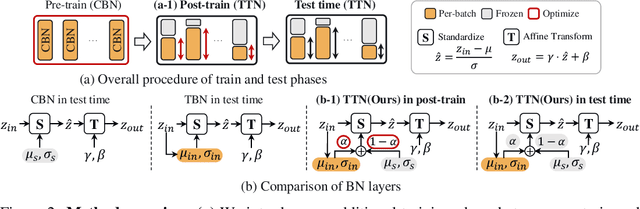
This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
RNN-Based GNSS Positioning using Satellite Measurement Features and Pseudorange Residuals
Jun 08, 2023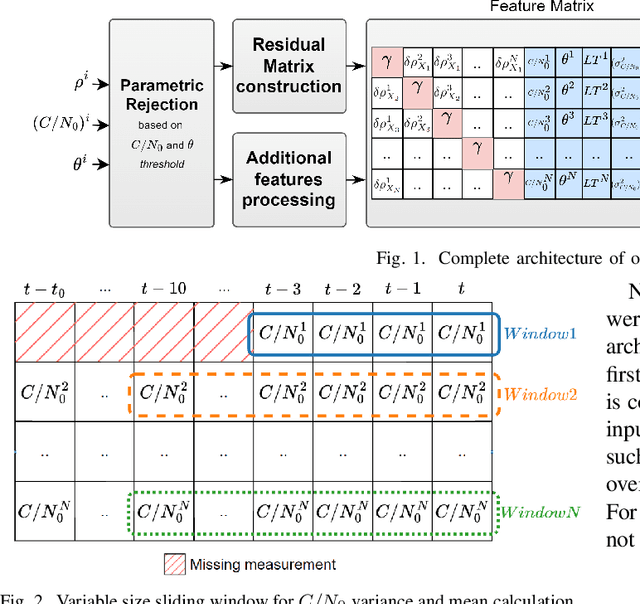

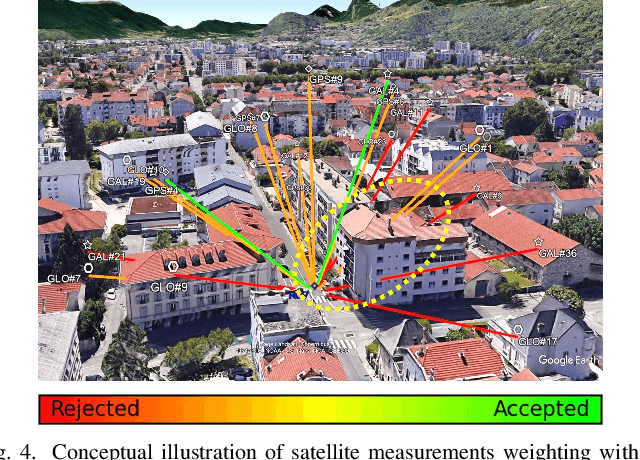
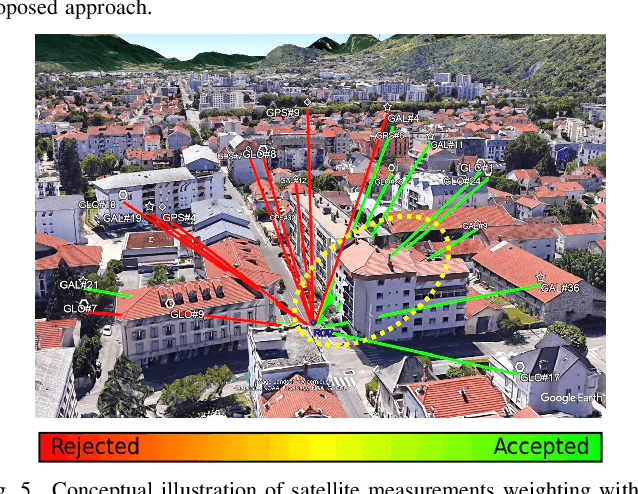
In the Global Navigation Satellite System (GNSS) context, the growing number of available satellites has lead to many challenges when it comes to choosing the most accurate pseudorange contributions, given the strong impact of biased measurements on positioning accuracy, particularly in single-epoch scenarios. This work leverages the potential of machine learning in predicting link-wise measurement quality factors and, hence, optimize measurement weighting. For this purpose, we use a customized matrix composed of heterogeneous features such as conditional pseudorange residuals and per-link satellite metrics (e.g., carrier-to-noise power density ratio and its empirical statistics, satellite elevation, carrier phase lock time). This matrix is then fed as an input to a recurrent neural network (RNN) (i.e., a long-short term memory (LSTM) network). Our experimental results on real data, obtained from extensive field measurements, demonstrate the high potential of our proposed solution being able to outperform traditional measurements weighting and selection strategies from state-of-the-art.
Tracking Everything Everywhere All at Once
Jun 08, 2023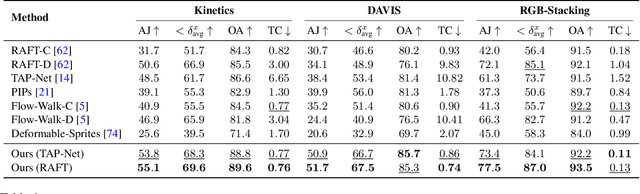
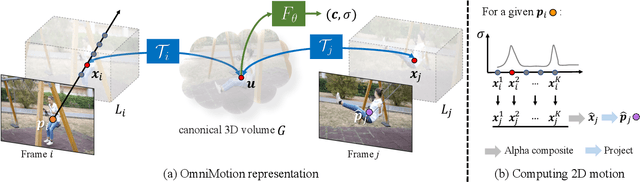
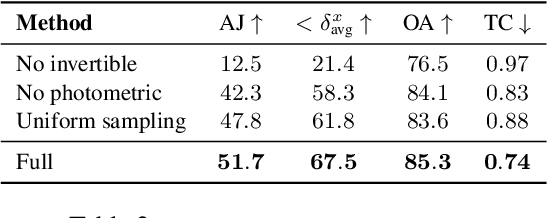

We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusions and maintain global consistency of estimated motion trajectories. We propose a complete and globally consistent motion representation, dubbed OmniMotion, that allows for accurate, full-length motion estimation of every pixel in a video. OmniMotion represents a video using a quasi-3D canonical volume and performs pixel-wise tracking via bijections between local and canonical space. This representation allows us to ensure global consistency, track through occlusions, and model any combination of camera and object motion. Extensive evaluations on the TAP-Vid benchmark and real-world footage show that our approach outperforms prior state-of-the-art methods by a large margin both quantitatively and qualitatively. See our project page for more results: http://omnimotion.github.io/
The Viability of Domain Constrained Coalition Formation for Robotic Collectives
Jun 08, 2023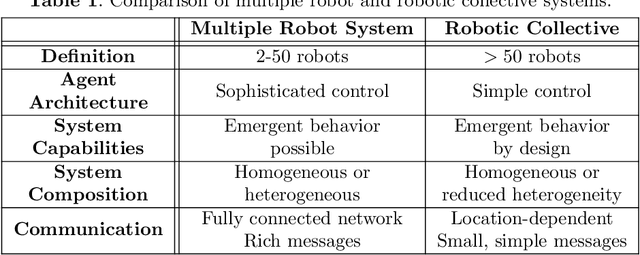
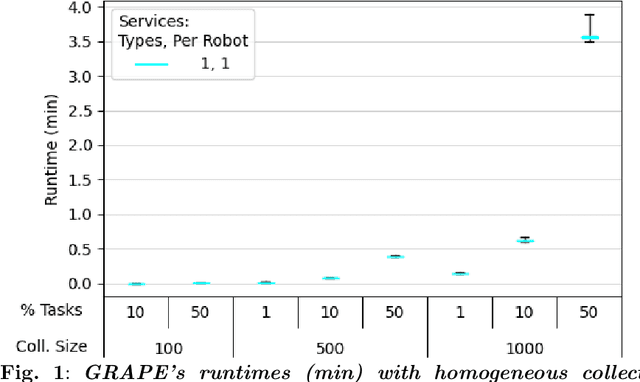

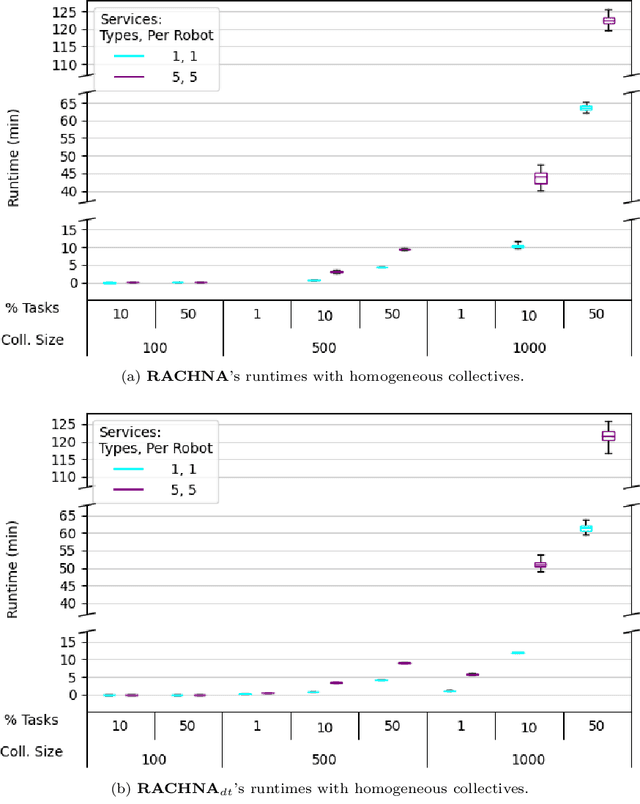
Applications, such as military and disaster response, can benefit from robotic collectives' ability to perform multiple cooperative tasks (e.g., surveillance, damage assessments) efficiently across a large spatial area. Coalition formation algorithms can potentially facilitate collective robots' assignment to appropriate task teams; however, most coalition formation algorithms were designed for smaller multiple robot systems (i.e., 2-50 robots). Collectives' scale and domain-relevant constraints (i.e., distribution, near real-time, minimal communication) make coalition formation more challenging. This manuscript identifies the challenges inherent to designing coalition formation algorithms for very large collectives (e.g., 1000 robots). A survey of multiple robot coalition formation algorithms finds that most are unable to transfer directly to collectives, due to the identified system differences; however, auctions and hedonic games may be the most transferable. A simulation-based evaluation of three auction and hedonic game algorithms, applied to homogeneous and heterogeneous collectives, demonstrates that there are collective compositions for which no existing algorithm is viable; however, the experimental results and literature survey suggest paths forward.
Improving Language Model Integration for Neural Machine Translation
Jun 08, 2023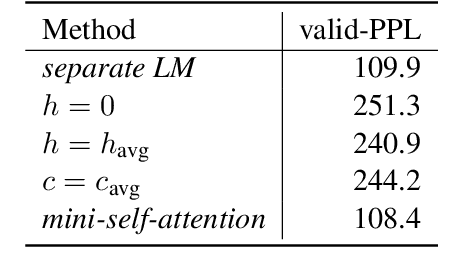
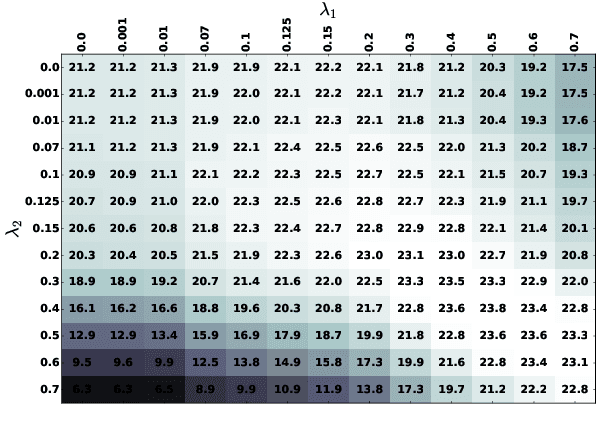
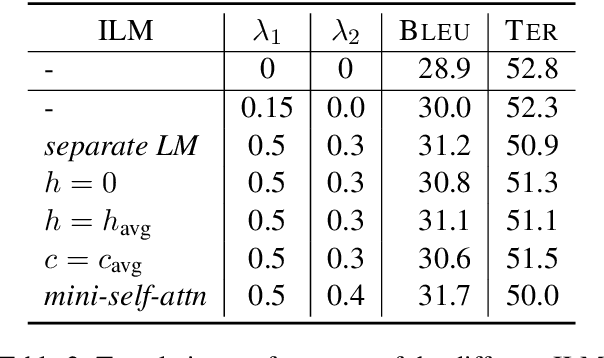
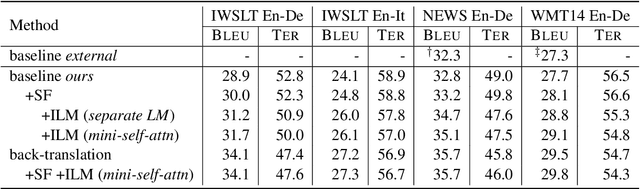
The integration of language models for neural machine translation has been extensively studied in the past. It has been shown that an external language model, trained on additional target-side monolingual data, can help improve translation quality. However, there has always been the assumption that the translation model also learns an implicit target-side language model during training, which interferes with the external language model at decoding time. Recently, some works on automatic speech recognition have demonstrated that, if the implicit language model is neutralized in decoding, further improvements can be gained when integrating an external language model. In this work, we transfer this concept to the task of machine translation and compare with the most prominent way of including additional monolingual data - namely back-translation. We find that accounting for the implicit language model significantly boosts the performance of language model fusion, although this approach is still outperformed by back-translation.
Leveraging characteristics of the output probability distribution for identifying adversarial audio examples
May 26, 2023

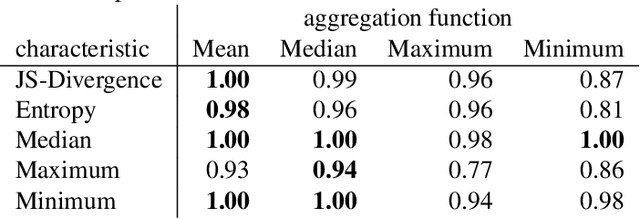
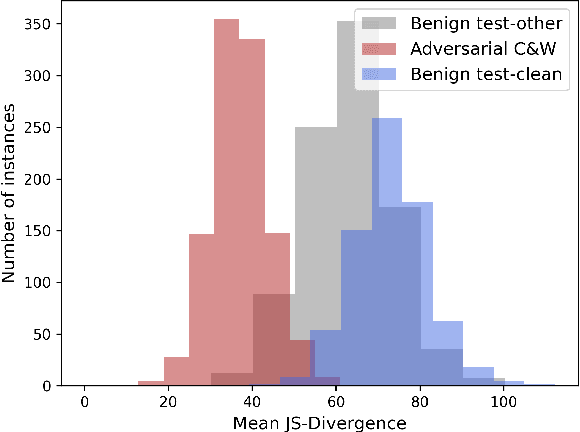
Adversarial attacks represent a security threat to machine learning based automatic speech recognition (ASR) systems. To prevent such attacks we propose an adversarial example detection strategy applicable to any ASR system that predicts a probability distribution over output tokens in each time step. We measure a set of characteristics of this distribution: the median, maximum, and minimum over the output probabilities, the entropy, and the Jensen-Shannon divergence of the distributions of subsequent time steps. Then, we fit a Gaussian distribution to the characteristics observed for benign data. By computing the likelihood of incoming new audio we can distinguish malicious inputs from samples from clean data with an area under the receiving operator characteristic (AUROC) higher than 0.99, which drops to 0.98 for less-quality audio. To assess the robustness of our method we build adaptive attacks. This reduces the AUROC to 0.96 but results in more noisy adversarial clips.