 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Knowledge Distillation for Surgical Phase Recognition
Jun 15, 2023
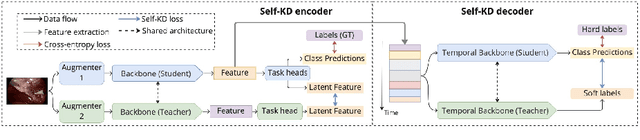
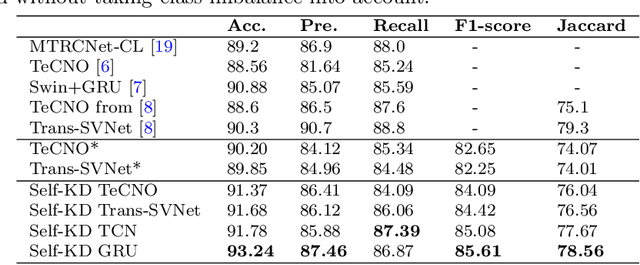
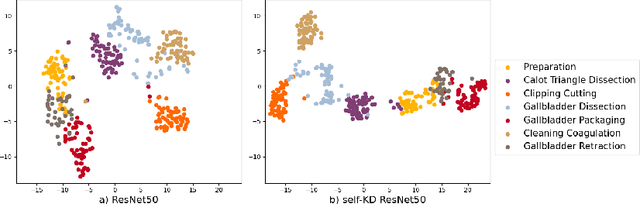
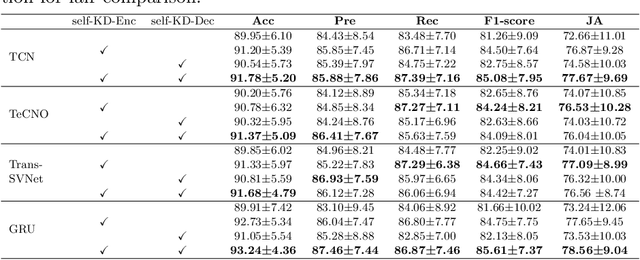
Purpose: Advances in surgical phase recognition are generally led by training deeper networks. Rather than going further with a more complex solution, we believe that current models can be exploited better. We propose a self-knowledge distillation framework that can be integrated into current state-of-the-art (SOTA) models without requiring any extra complexity to the models or annotations. Methods: Knowledge distillation is a framework for network regularization where knowledge is distilled from a teacher network to a student network. In self-knowledge distillation, the student model becomes the teacher such that the network learns from itself. Most phase recognition models follow an encoder-decoder framework. Our framework utilizes self-knowledge distillation in both stages. The teacher model guides the training process of the student model to extract enhanced feature representations from the encoder and build a more robust temporal decoder to tackle the over-segmentation problem. Results: We validate our proposed framework on the public dataset Cholec80. Our framework is embedded on top of four popular SOTA approaches and consistently improves their performance. Specifically, our best GRU model boosts performance by +3.33% accuracy and +3.95% F1-score over the same baseline model. Conclusion: We embed a self-knowledge distillation framework for the first time in the surgical phase recognition training pipeline. Experimental results demonstrate that our simple yet powerful framework can improve performance of existing phase recognition models. Moreover, our extensive experiments show that even with 75% of the training set we still achieve performance on par with the same baseline model trained on the full set.
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design
Jun 15, 2023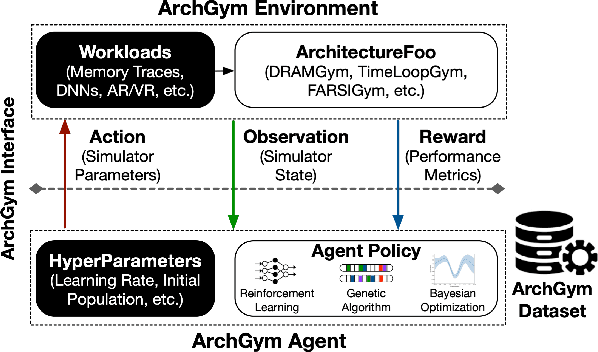
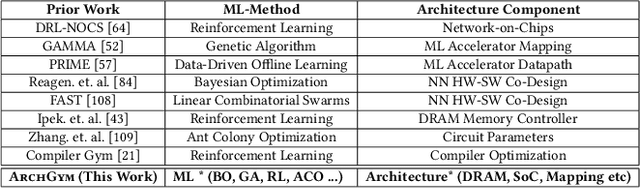
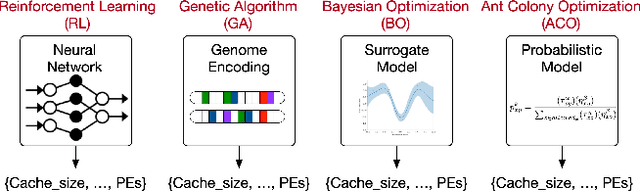

Machine learning is a prevalent approach to tame the complexity of design space exploration for domain-specific architectures. Using ML for design space exploration poses challenges. First, it's not straightforward to identify the suitable algorithm from an increasing pool of ML methods. Second, assessing the trade-offs between performance and sample efficiency across these methods is inconclusive. Finally, lack of a holistic framework for fair, reproducible, and objective comparison across these methods hinders progress of adopting ML-aided architecture design space exploration and impedes creating repeatable artifacts. To mitigate these challenges, we introduce ArchGym, an open-source gym and easy-to-extend framework that connects diverse search algorithms to architecture simulators. To demonstrate utility, we evaluate ArchGym across multiple vanilla and domain-specific search algorithms in designing custom memory controller, deep neural network accelerators, and custom SoC for AR/VR workloads, encompassing over 21K experiments. Results suggest that with unlimited samples, ML algorithms are equally favorable to meet user-defined target specification if hyperparameters are tuned; no solution is necessarily better than another (e.g., reinforcement learning vs. Bayesian methods). We coin the term hyperparameter lottery to describe the chance for a search algorithm to find an optimal design provided meticulously selected hyperparameters. The ease of data collection and aggregation in ArchGym facilitates research in ML-aided architecture design space exploration. As a case study, we show this advantage by developing a proxy cost model with an RMSE of 0.61% that offers a 2,000-fold reduction in simulation time. Code and data for ArchGym is available at https://bit.ly/ArchGym.
Multimodal Pathology Image Search Between H&E Slides and Multiplexed Immunofluorescent Images
Jun 11, 2023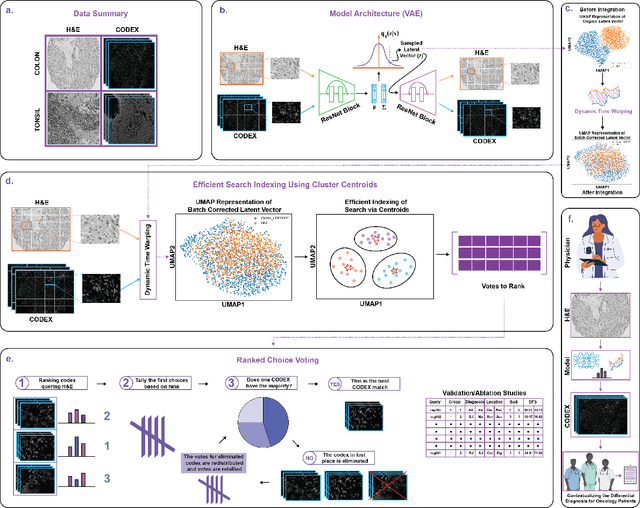
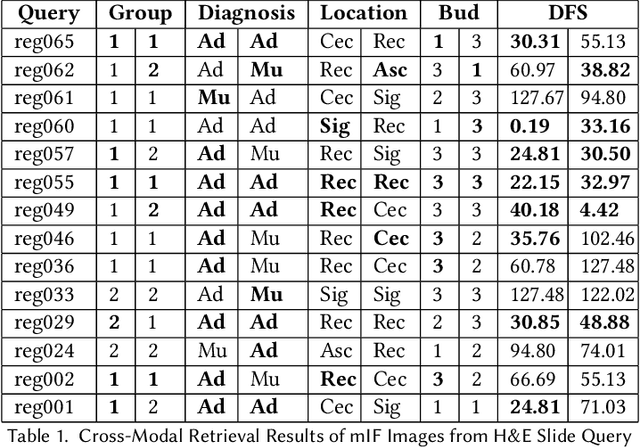
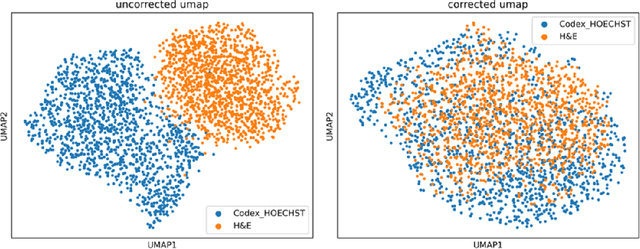
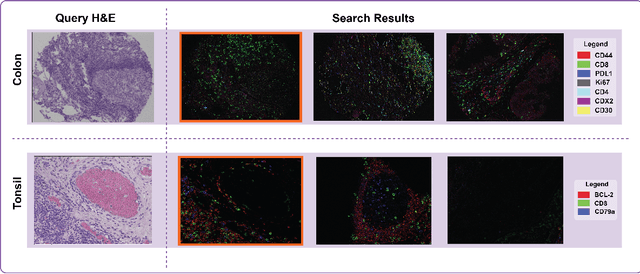
We present an approach for multimodal pathology image search, using dynamic time warping (DTW) on Variational Autoencoder (VAE) latent space that is fed into a ranked choice voting scheme to retrieve multiplexed immunofluorescent imaging (mIF) that is most similar to a query H&E slide. Through training the VAE and applying DTW, we align and compare mIF and H&E slides. Our method improves differential diagnosis and therapeutic decisions by integrating morphological H&E data with immunophenotyping from mIF, providing clinicians a rich perspective of disease states. This facilitates an understanding of the spatial relationships in tissue samples and could revolutionize the diagnostic process, enhancing precision and enabling personalized therapy selection. Our technique demonstrates feasibility using colorectal cancer and healthy tonsil samples. An exhaustive ablation study was conducted on a search engine designed to explore the correlation between multiplexed Immunofluorescence (mIF) and Hematoxylin and Eosin (H&E) staining, in order to validate its ability to map these distinct modalities into a unified vector space. Despite extreme class imbalance, the system demonstrated robustness and utility by returning similar results across various data features, which suggests potential for future use in multimodal histopathology data analysis.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
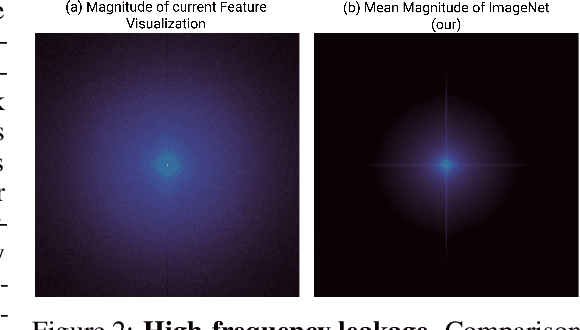
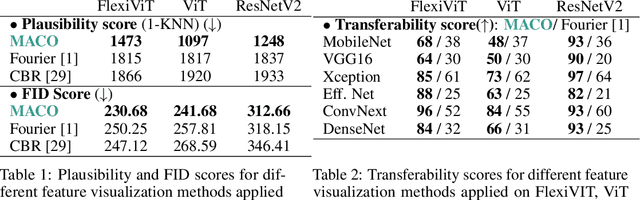
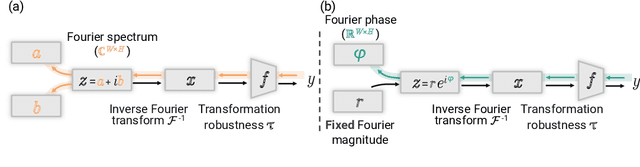
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
Generalizable Wireless Navigation through Physics-Informed Reinforcement Learning in Wireless Digital Twin
Jun 11, 2023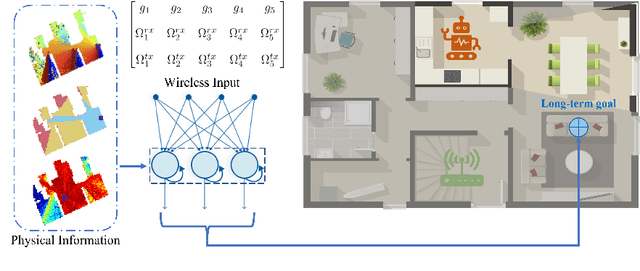
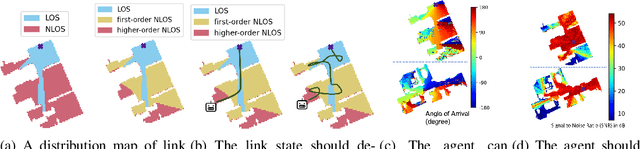
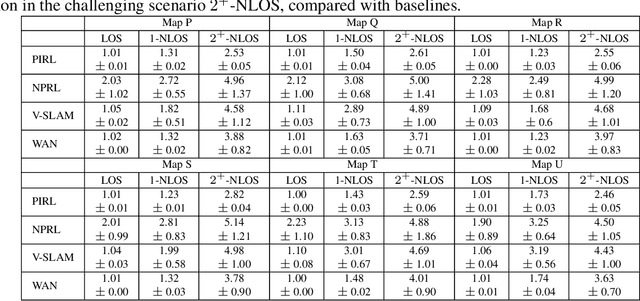
The growing focus on indoor robot navigation utilizing wireless signals has stemmed from the capability of these signals to capture high-resolution angular and temporal measurements. However, employing end-to-end generic reinforcement learning (RL) for wireless indoor navigation (WIN) in initially unknown environments remains a significant challenge, due to its limited generalization ability and poor sample efficiency. At the same time, purely model-based solutions, based on radio frequency propagation, are simple and generalizable, but unable to find optimal decisions in complex environments. This work proposes a novel physics-informed RL (PIRL) were a standard distance-to-target-based cost along with physics-informed terms on the optimal trajectory. The proposed PIRL is evaluated using a wireless digital twin (WDT) built upon simulations of a large class of indoor environments from the AI Habitat dataset augmented with electromagnetic radiation (EM) simulation for wireless signals. It is shown that the PIRL significantly outperforms both standard RL and purely physics-based solutions in terms of generalizability and performance. Furthermore, the resulting PIRL policy is explainable in that it is empirically consistent with the physics heuristic.
Meta-SAGE: Scale Meta-Learning Scheduled Adaptation with Guided Exploration for Mitigating Scale Shift on Combinatorial Optimization
Jun 07, 2023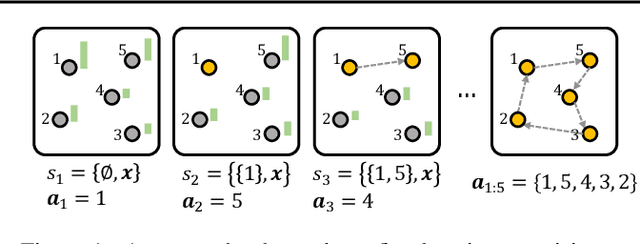
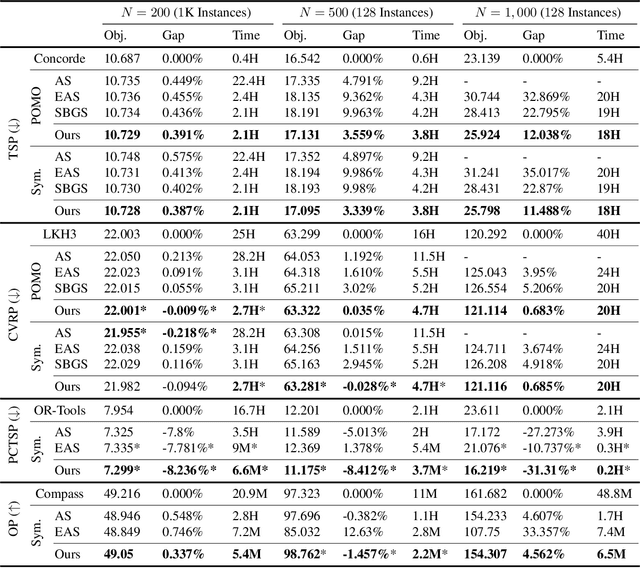
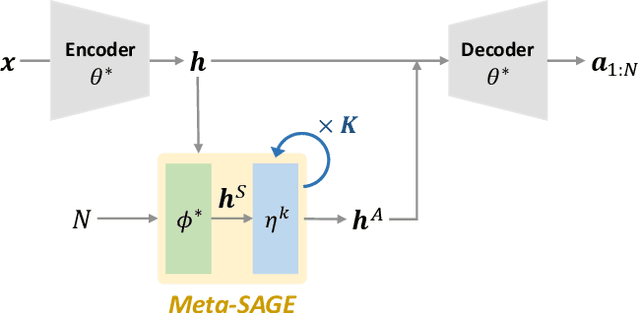
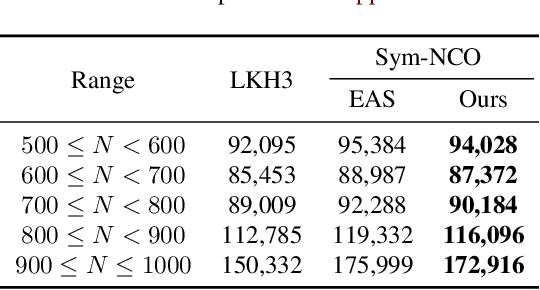
This paper proposes Meta-SAGE, a novel approach for improving the scalability of deep reinforcement learning models for combinatorial optimization (CO) tasks. Our method adapts pre-trained models to larger-scale problems in test time by suggesting two components: a scale meta-learner (SML) and scheduled adaptation with guided exploration (SAGE). First, SML transforms the context embedding for subsequent adaptation of SAGE based on scale information. Then, SAGE adjusts the model parameters dedicated to the context embedding for a specific instance. SAGE introduces locality bias, which encourages selecting nearby locations to determine the next location. The locality bias gradually decays as the model is adapted to the target instance. Results show that Meta-SAGE outperforms previous adaptation methods and significantly improves scalability in representative CO tasks. Our source code is available at https://github.com/kaist-silab/meta-sage
UCTB: An Urban Computing Tool Box for Spatiotemporal Crowd Flow Prediction
Jun 07, 2023
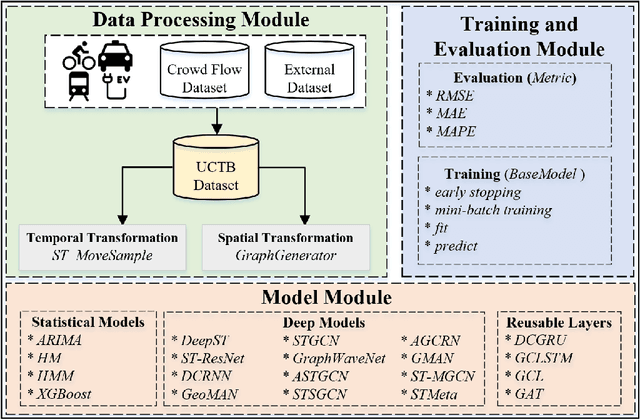


Spatiotemporal crowd flow prediction is one of the key technologies in smart cities. Currently, there are two major pain points that plague related research and practitioners. Firstly, crowd flow is related to multiple domain knowledge factors; however, due to the diversity of application scenarios, it is difficult for subsequent work to make reasonable and comprehensive use of domain knowledge. Secondly, with the development of deep learning technology, the implementation of relevant techniques has become increasingly complex; reproducing advanced models has become a time-consuming and increasingly cumbersome task. To address these issues, we design and implement a spatiotemporal crowd flow prediction toolbox called UCTB (Urban Computing Tool Box), which integrates multiple spatiotemporal domain knowledge and state-of-the-art models simultaneously. The relevant code and supporting documents have been open-sourced at https://github.com/uctb/UCTB.
Are training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023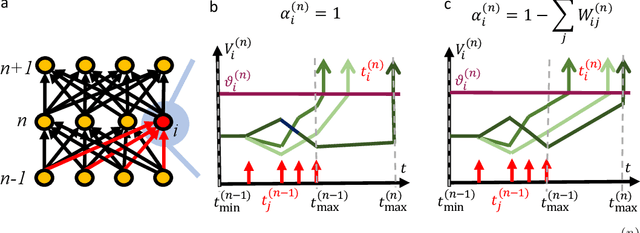


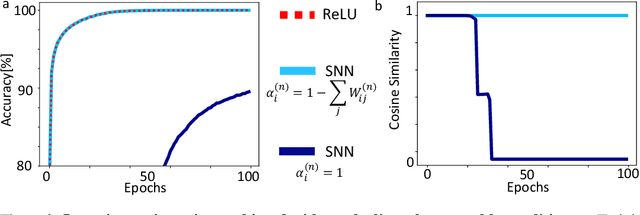
Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
Feeding control and water quality monitoring in aquaculture systems: Opportunities and challenges
Jun 14, 2023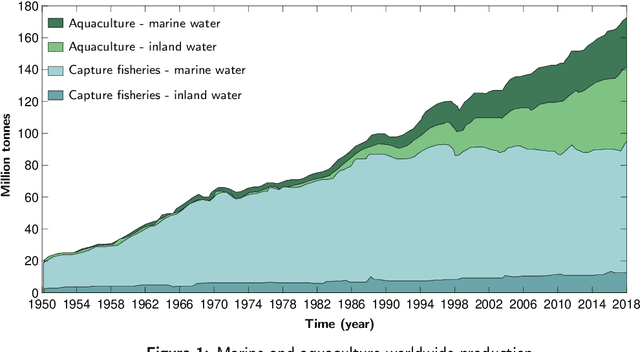

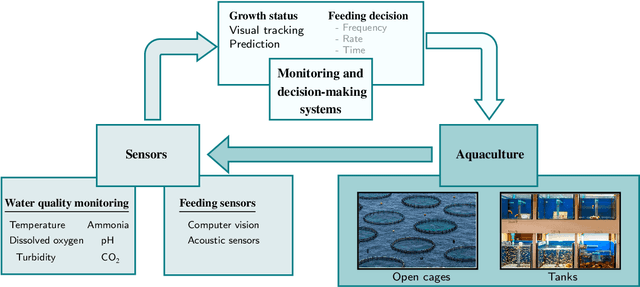
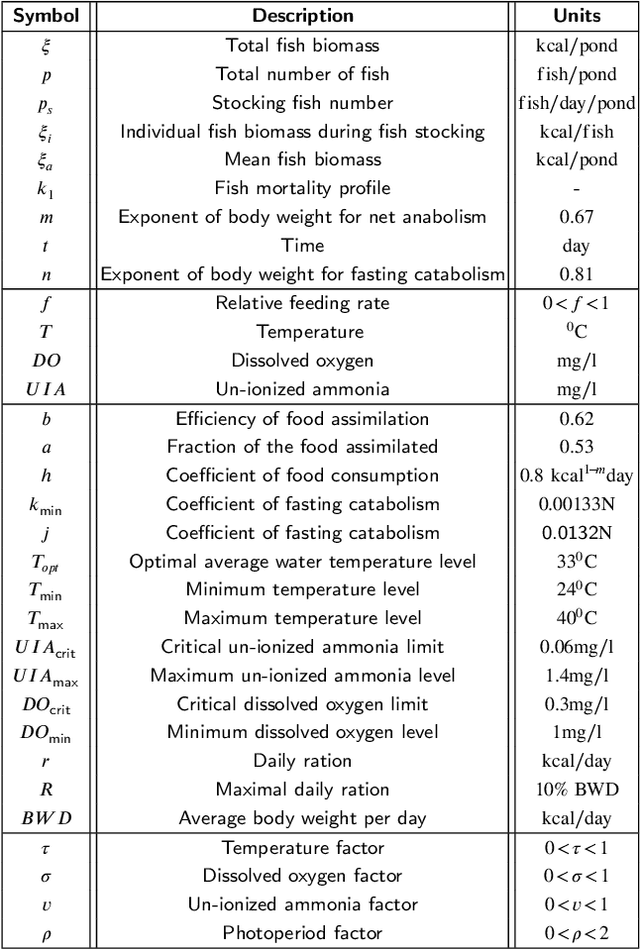
Aquaculture systems can benefit from the recent development of advanced control strategies to reduce operating costs and fish loss and increase growth production efficiency, resulting in fish welfare and health. Monitoring the water quality and controlling feeding are fundamental elements of balancing fish productivity and shaping the fish growth process. Currently, most fish-feeding processes are conducted manually in different phases and rely on time-consuming and challenging artificial discrimination. The feeding control approach influences fish growth and breeding through the feed conversion rate; hence, controlling these feeding parameters is crucial for enhancing fish welfare and minimizing general fishery costs. The high concentration of environmental factors, such as a high ammonia concentration and pH, affect the water quality and fish survival. Therefore, there is a critical need to develop control strategies to determine optimal, efficient, and reliable feeding processes and monitor water quality. This paper reviews the main control design techniques for fish growth in aquaculture systems, namely algorithms that optimize the feeding and water quality of a dynamic fish growth process. Specifically, we review model-based control approaches and model-free reinforcement learning strategies to optimize the growth and survival of the fish or track a desired reference live-weight growth trajectory. The model-free framework uses an approximate fish growth dynamic model and does not satisfy constraints. We discuss how model-based approaches can support a reinforcement learning framework to efficiently handle constraint satisfaction and find better trajectories and policies from value-based reinforcement learning.
Retrieval-Enhanced Contrastive Vision-Text Models
Jun 12, 2023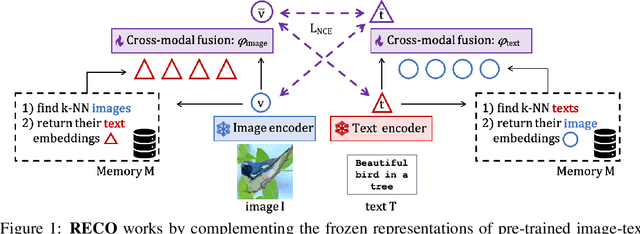
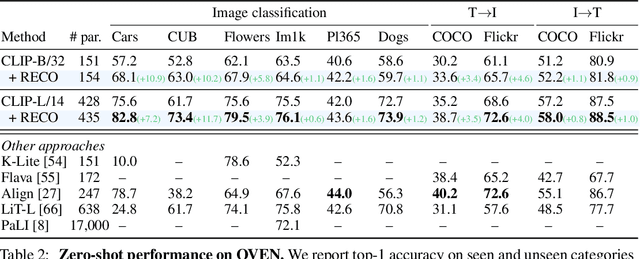
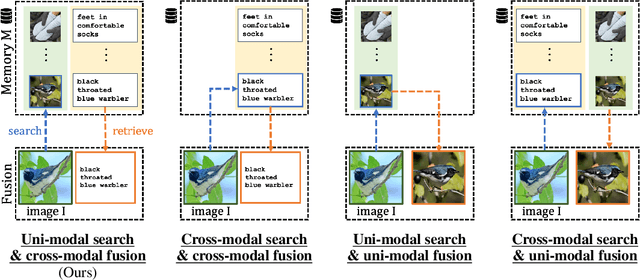
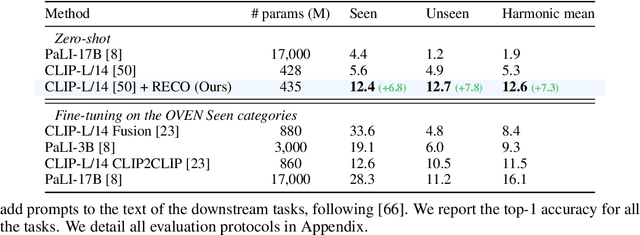
Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.