 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling Trust and Reliance with Wait Time in a Human-Robot Interaction
Feb 16, 2023
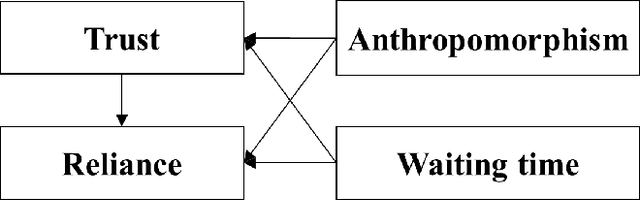
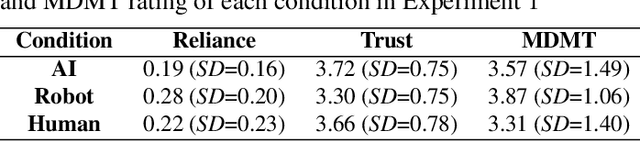

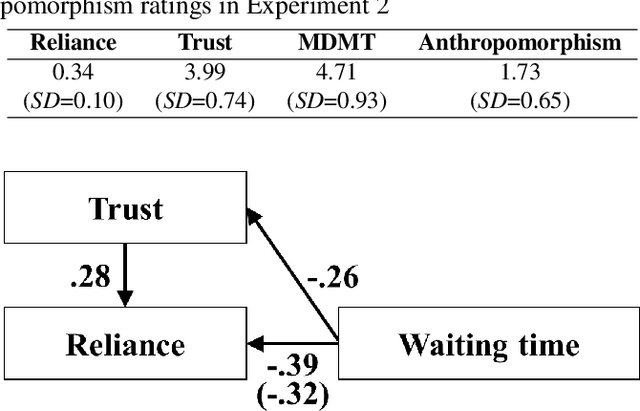
This study investigated how wait time influences trust in and reliance on a robot. Experiment 1 was conducted as an online experiment manipulating the wait time for the task partner's action from 1 to 20 seconds and the anthropomorphism of the partner. As a result, the anthropomorphism influenced trust in the partner and did not influence reliance on the partner. However, the wait time negatively influenced trust in and reliance on the partner. Moreover, a mediation effect of trust from the wait time on reliance on the partner was confirmed. Experiment 2 was conducted to confirm the effects of wait time on trust and reliance in a human-robot face-to-face situation. As a result, the same effects of wait time found in Experiment 1 were confirmed. This study revealed that wait time is a strong and controllable factor that influences trust in and reliance on a robot.
On Diffusion Modeling for Anomaly Detection
May 29, 2023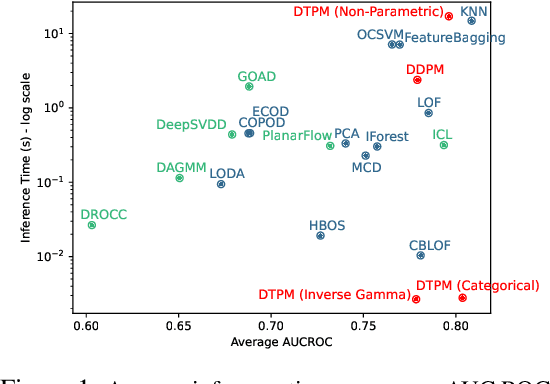
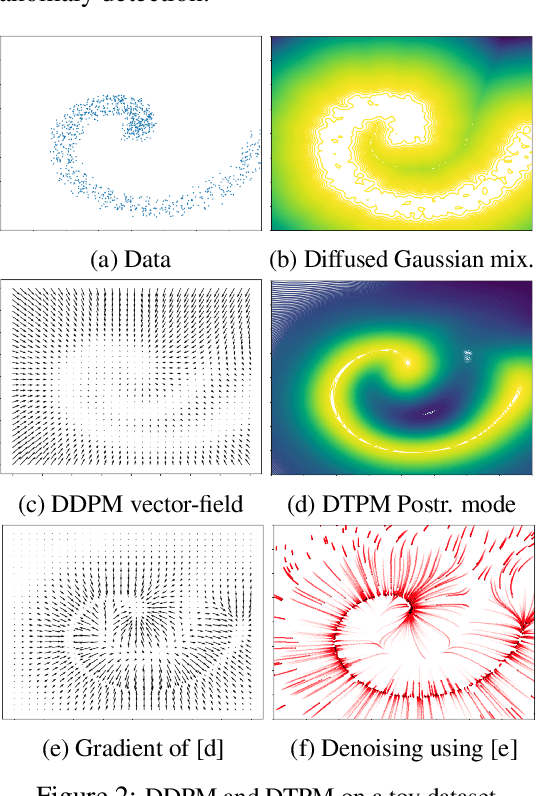
Known for their impressive performance in generative modeling, diffusion models are attractive candidates for density-based anomaly detection. This paper investigates different variations of diffusion modeling for unsupervised and semi-supervised anomaly detection. In particular, we find that Denoising Diffusion Probability Models (DDPM) are performant on anomaly detection benchmarks yet computationally expensive. By simplifying DDPM in application to anomaly detection, we are naturally led to an alternative approach called Diffusion Time Probabilistic Model (DTPM). DTPM estimates the posterior distribution over diffusion time for a given input, enabling the identification of anomalies due to their higher posterior density at larger timesteps. We derive an analytical form for this posterior density and leverage a deep neural network to improve inference efficiency. Through empirical evaluations on the ADBench benchmark, we demonstrate that all diffusion-based anomaly detection methods perform competitively. Notably, DTPM achieves orders of magnitude faster inference time than DDPM, while outperforming it on this benchmark. These results establish diffusion-based anomaly detection as an interpretable and scalable alternative to traditional methods and recent deep-learning techniques.
BOOT: Data-free Distillation of Denoising Diffusion Models with Bootstrapping
Jun 08, 2023
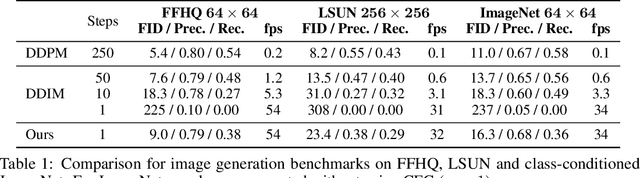
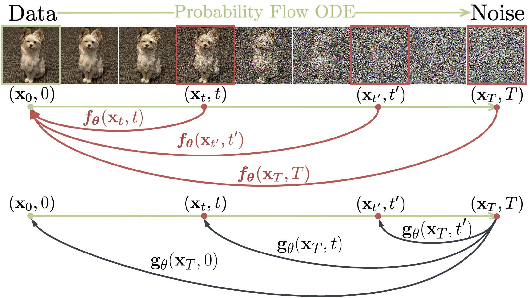
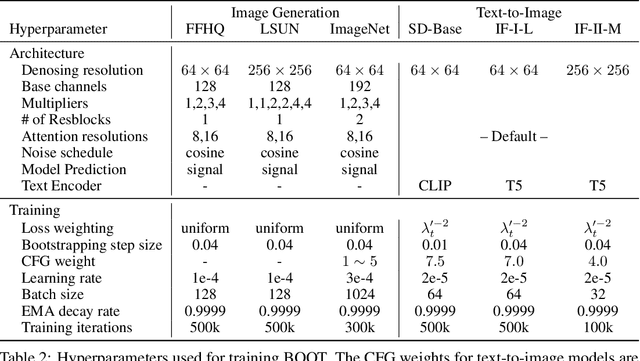
Diffusion models have demonstrated excellent potential for generating diverse images. However, their performance often suffers from slow generation due to iterative denoising. Knowledge distillation has been recently proposed as a remedy that can reduce the number of inference steps to one or a few without significant quality degradation. However, existing distillation methods either require significant amounts of offline computation for generating synthetic training data from the teacher model or need to perform expensive online learning with the help of real data. In this work, we present a novel technique called BOOT, that overcomes these limitations with an efficient data-free distillation algorithm. The core idea is to learn a time-conditioned model that predicts the output of a pre-trained diffusion model teacher given any time step. Such a model can be efficiently trained based on bootstrapping from two consecutive sampled steps. Furthermore, our method can be easily adapted to large-scale text-to-image diffusion models, which are challenging for conventional methods given the fact that the training sets are often large and difficult to access. We demonstrate the effectiveness of our approach on several benchmark datasets in the DDIM setting, achieving comparable generation quality while being orders of magnitude faster than the diffusion teacher. The text-to-image results show that the proposed approach is able to handle highly complex distributions, shedding light on more efficient generative modeling.
JABBERWOCK: A Tool for WebAssembly Dataset Generation and Its Application to Malicious Website Detection
Jun 09, 2023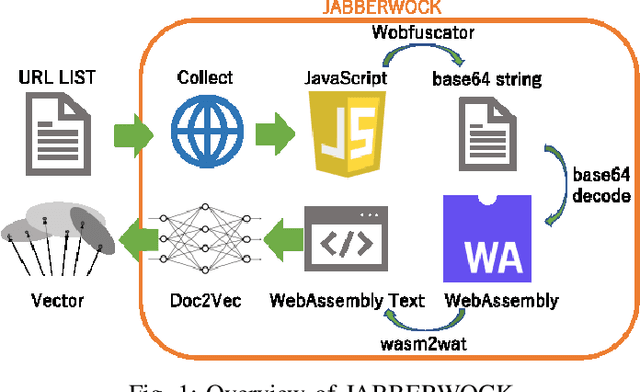
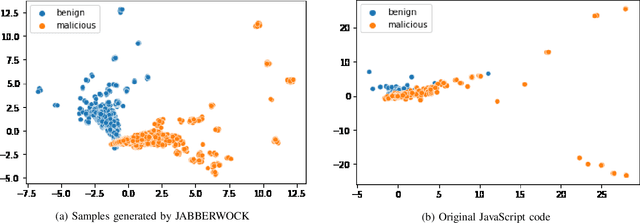
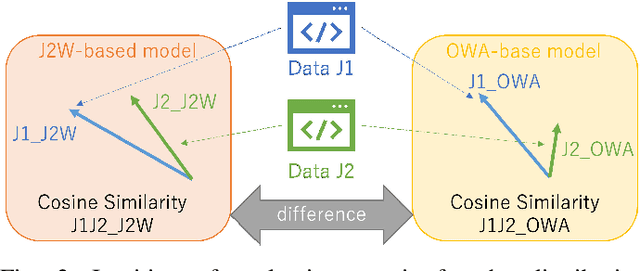
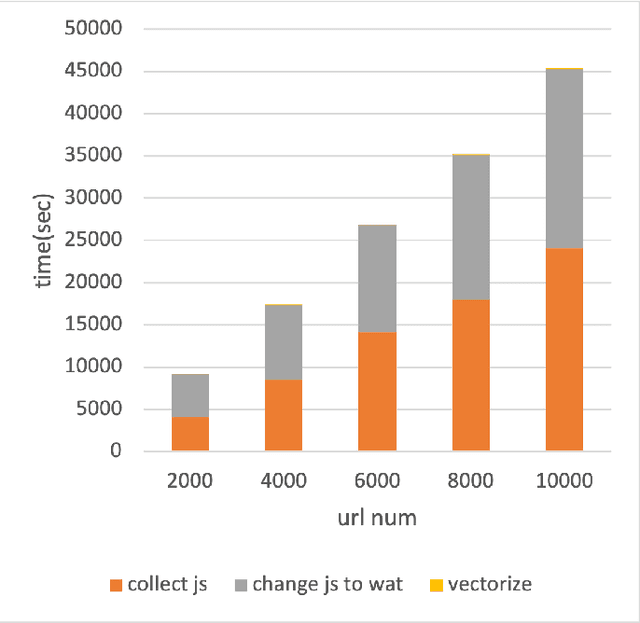
Machine learning is often used for malicious website detection, but an approach incorporating WebAssembly as a feature has not been explored due to a limited number of samples, to the best of our knowledge. In this paper, we propose JABBERWOCK (JAvascript-Based Binary EncodeR by WebAssembly Optimization paCKer), a tool to generate WebAssembly datasets in a pseudo fashion via JavaScript. Loosely speaking, JABBERWOCK automatically gathers JavaScript code in the real world, convert them into WebAssembly, and then outputs vectors of the WebAssembly as samples for malicious website detection. We also conduct experimental evaluations of JABBERWOCK in terms of the processing time for dataset generation, comparison of the generated samples with actual WebAssembly samples gathered from the Internet, and an application for malicious website detection. Regarding the processing time, we show that JABBERWOCK can construct a dataset in 4.5 seconds per sample for any number of samples. Next, comparing 10,000 samples output by JABBERWOCK with 168 gathered WebAssembly samples, we believe that the generated samples by JABBERWOCK are similar to those in the real world. We then show that JABBERWOCK can provide malicious website detection with 99\% F1-score because JABBERWOCK makes a gap between benign and malicious samples as the reason for the above high score. We also confirm that JABBERWOCK can be combined with an existing malicious website detection tool to improve F1-scores. JABBERWOCK is publicly available via GitHub (https://github.com/c-chocolate/Jabberwock).
4DSR-GCN: 4D Video Point Cloud Upsampling using Graph Convolutional Networks
Jun 01, 2023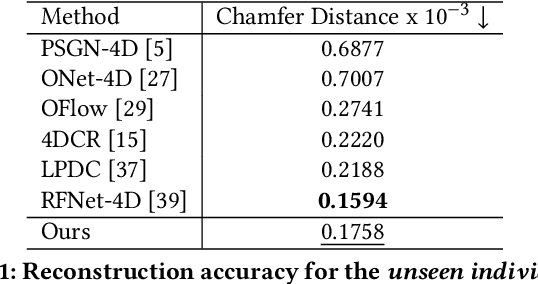

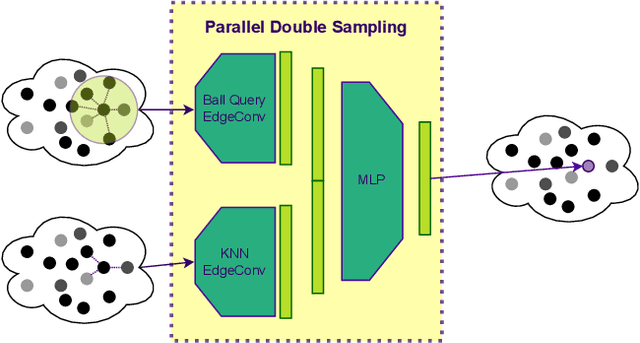
Time varying sequences of 3D point clouds, or 4D point clouds, are now being acquired at an increasing pace in several applications (e.g., LiDAR in autonomous or assisted driving). In many cases, such volume of data is transmitted, thus requiring that proper compression tools are applied to either reduce the resolution or the bandwidth. In this paper, we propose a new solution for upscaling and restoration of time-varying 3D video point clouds after they have been heavily compressed. In consideration of recent growing relevance of 3D applications, %We focused on a model allowing user-side upscaling and artifact removal for 3D video point clouds, a real-time stream of which would require . Our model consists of a specifically designed Graph Convolutional Network (GCN) that combines Dynamic Edge Convolution and Graph Attention Networks for feature aggregation in a Generative Adversarial setting. By taking inspiration PointNet++, We present a different way to sample dense point clouds with the intent to make these modules work in synergy to provide each node enough features about its neighbourhood in order to later on generate new vertices. Compared to other solutions in the literature that address the same task, our proposed model is capable of obtaining comparable results in terms of quality of the reconstruction, while using a substantially lower number of parameters (about 300KB), making our solution deployable in edge computing devices such as LiDAR.
Label- and slide-free tissue histology using 3D epi-mode quantitative phase imaging and virtual H&E staining
Jun 01, 2023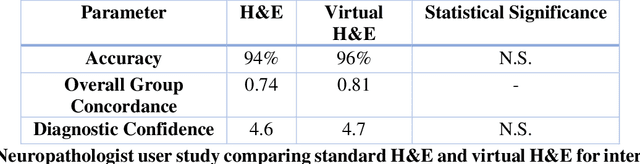
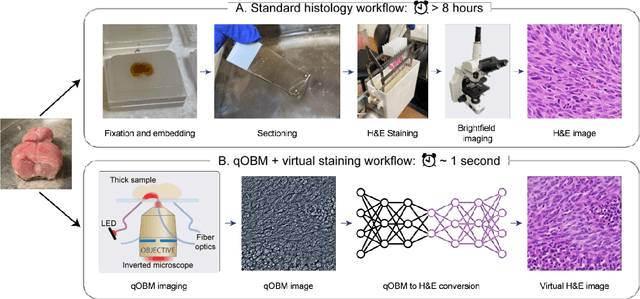
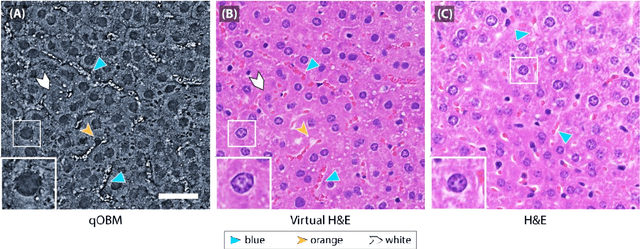

Histological staining of tissue biopsies, especially hematoxylin and eosin (H&E) staining, serves as the benchmark for disease diagnosis and comprehensive clinical assessment of tissue. However, the process is laborious and time-consuming, often limiting its usage in crucial applications such as surgical margin assessment. To address these challenges, we combine an emerging 3D quantitative phase imaging technology, termed quantitative oblique back illumination microscopy (qOBM), with an unsupervised generative adversarial network pipeline to map qOBM phase images of unaltered thick tissues (i.e., label- and slide-free) to virtually stained H&E-like (vH&E) images. We demonstrate that the approach achieves high-fidelity conversions to H&E with subcellular detail using fresh tissue specimens from mouse liver, rat gliosarcoma, and human gliomas. We also show that the framework directly enables additional capabilities such as H&E-like contrast for volumetric imaging. The quality and fidelity of the vH&E images are validated using both a neural network classifier trained on real H&E images and tested on virtual H&E images, and a user study with neuropathologists. Given its simple and low-cost embodiment and ability to provide real-time feedback in vivo, this deep learning-enabled qOBM approach could enable new workflows for histopathology with the potential to significantly save time, labor, and costs in cancer screening, detection, treatment guidance, and more.
Runtime Analysis of Quality Diversity Algorithms
May 30, 2023Quality diversity~(QD) is a branch of evolutionary computation that gained increasing interest in recent years. The Map-Elites QD approach defines a feature space, i.e., a partition of the search space, and stores the best solution for each cell of this space. We study a simple QD algorithm in the context of pseudo-Boolean optimisation on the ``number of ones'' feature space, where the $i$th cell stores the best solution amongst those with a number of ones in $[(i-1)k, ik-1]$. Here $k$ is a granularity parameter $1 \leq k \leq n+1$. We give a tight bound on the expected time until all cells are covered for arbitrary fitness functions and for all $k$ and analyse the expected optimisation time of QD on \textsc{OneMax} and other problems whose structure aligns favourably with the feature space. On combinatorial problems we show that QD finds a ${(1-1/e)}$-approximation when maximising any monotone sub-modular function with a single uniform cardinality constraint efficiently. Defining the feature space as the number of connected components of a connected graph, we show that QD finds a minimum spanning tree in expected polynomial time.
Local track irregularity identification based on multi-sensor time-frequency features of high-speed railway bridge accelerations
Mar 28, 2023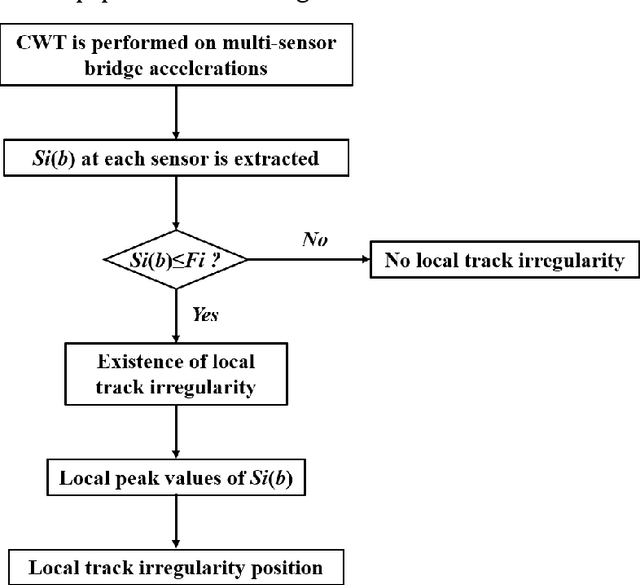

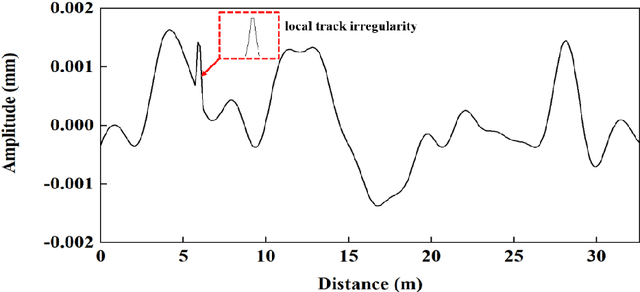
Shortwave track diseases are generally reflected in the form of local track irregularity. Such diseases will greatly impact the train-track-bridge interaction (TTBI) dynamic system, seriously affecting train safety. Therefore, a method is proposed to detect and localize local track irregularities based on multis-sensor time-frequency features of high-speed railway bridge accelerations. Continuous wavelet transform (CWT) is used to analyze the multi-sensor accelerations of railway bridges. Moreover, time-frequency features based on the sum of wavelet coefficients are proposed, considering the influence of the distance from the measurement points to the local irregularity on the recognition accuracy. Then, the multi-domain features are utilized to recognize deteriorated railway locations. A simply-supported high-speed railway bridge traversed by a railway train is adopted as a numerical simulation. Comparative studies are conducted to investigate the influence of vehicle speeds and the location of local track irregularity on the algorithm. Numerical simulation results show that the proposed algorithm can detect and locate local track irregularity accurately and is robust to vehicle speeds.
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing
Jun 22, 2023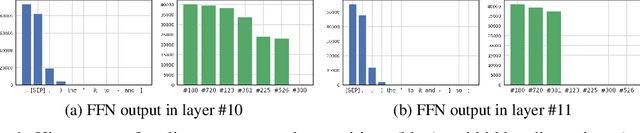
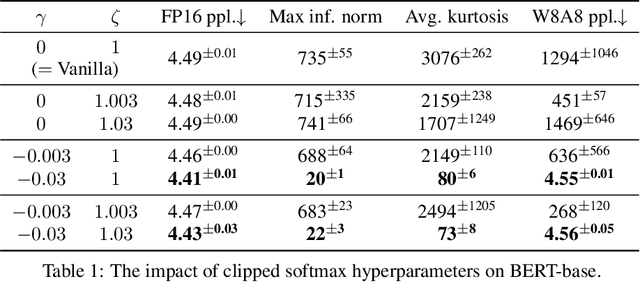
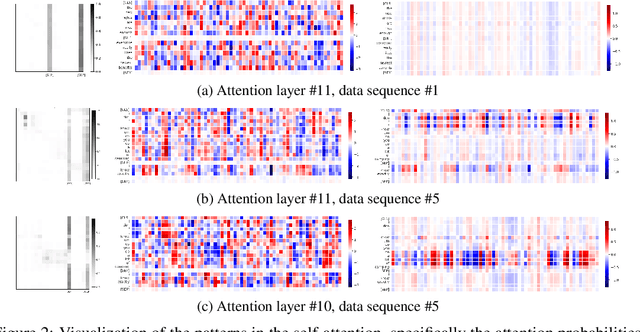
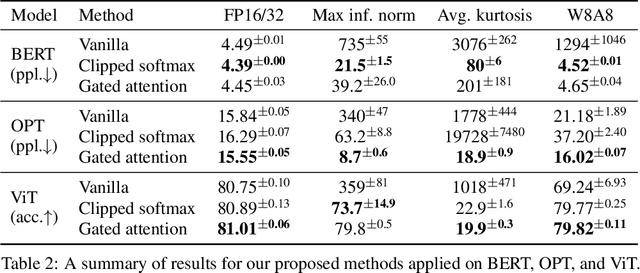
Transformer models have been widely adopted in various domains over the last years, and especially large language models have advanced the field of AI significantly. Due to their size, the capability of these networks has increased tremendously, but this has come at the cost of a significant increase in necessary compute. Quantization is one of the most effective ways to reduce the computational time and memory consumption of neural networks. Many studies have shown, however, that modern transformer models tend to learn strong outliers in their activations, making them difficult to quantize. To retain acceptable performance, the existence of these outliers requires activations to be in higher bitwidth or the use of different numeric formats, extra fine-tuning, or other workarounds. We show that strong outliers are related to very specific behavior of attention heads that try to learn a "no-op" or just a partial update of the residual. To achieve the exact zeros needed in the attention matrix for a no-update, the input to the softmax is pushed to be larger and larger during training, causing outliers in other parts of the network. Based on these observations, we propose two simple (independent) modifications to the attention mechanism - clipped softmax and gated attention. We empirically show that models pre-trained using our methods learn significantly smaller outliers while maintaining and sometimes even improving the floating-point task performance. This enables us to quantize transformers to full INT8 quantization of the activations without any additional effort. We demonstrate the effectiveness of our methods on both language models (BERT, OPT) and vision transformers.
Exploiting Intrinsic Stochasticity of Real-Time Simulation to Facilitate Robust Reinforcement Learning for Robot Manipulation
Apr 12, 2023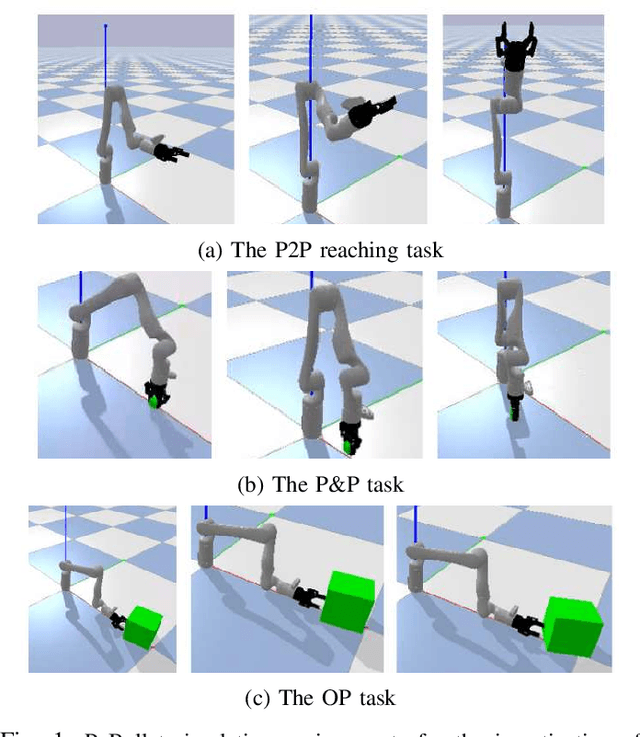

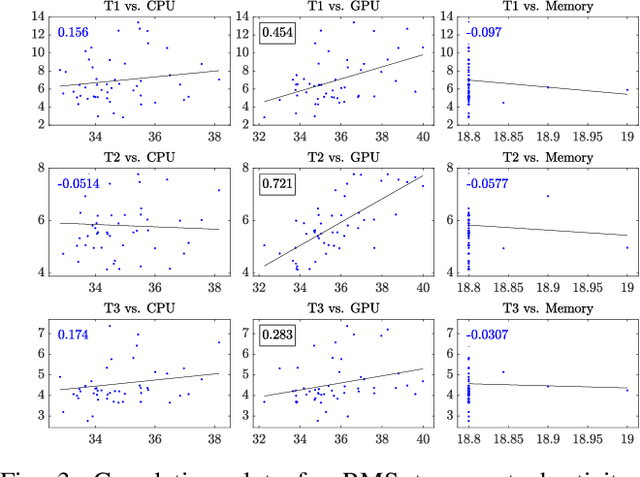
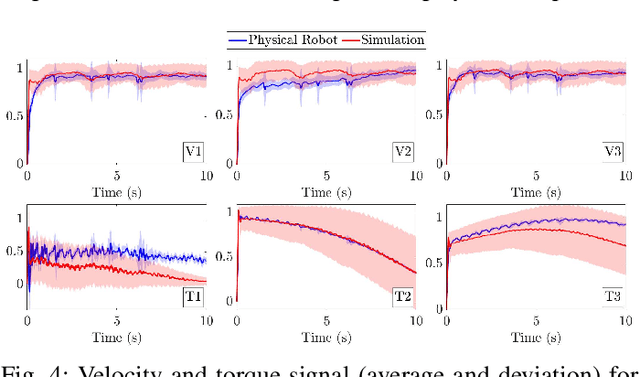
Simulation is essential to reinforcement learning (RL) before implementation in the real world, especially for safety-critical applications like robot manipulation. Conventionally, RL agents are sensitive to the discrepancies between the simulation and the real world, known as the sim-to-real gap. The application of domain randomization, a technique used to fill this gap, is limited to the imposition of heuristic-randomized models. We investigate the properties of intrinsic stochasticity of real-time simulation (RT-IS) of off-the-shelf simulation software and its potential to improve the robustness of RL methods and the performance of domain randomization. Firstly, we conduct analytical studies to measure the correlation of RT-IS with the occupation of the computer hardware and validate its comparability with the natural stochasticity of a physical robot. Then, we apply the RT-IS feature in the training of an RL agent. The simulation and physical experiment results verify the feasibility and applicability of RT-IS to robust RL agent design for robot manipulation tasks. The RT-IS-powered robust RL agent outperforms conventional RL agents on robots with modeling uncertainties. It requires fewer heuristic randomization and achieves better generalizability than the conventional domain-randomization-powered agents. Our findings provide a new perspective on the sim-to-real problem in practical applications like robot manipulation tasks.