 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
Feb 18, 2023
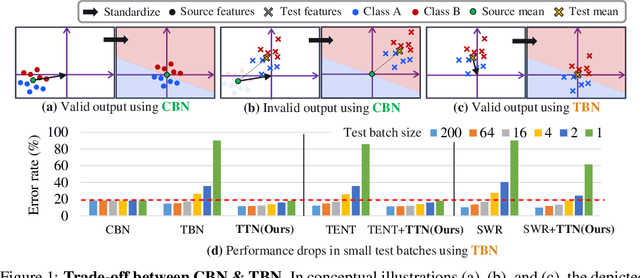
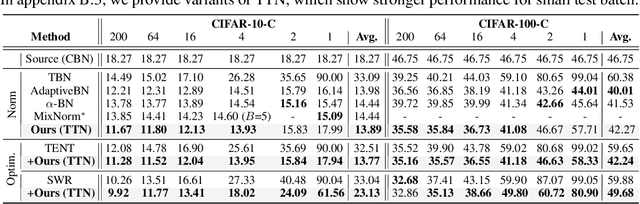
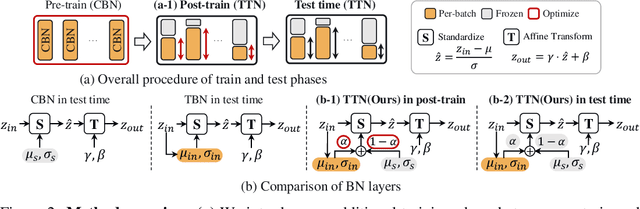
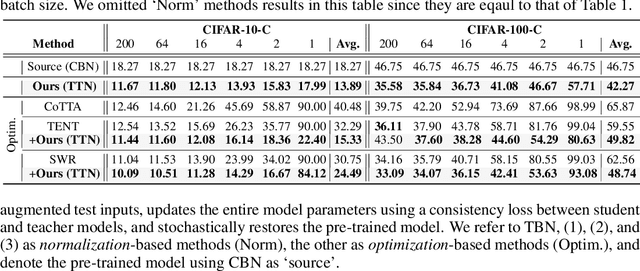
This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
Precise and Generalized Robustness Certification for Neural Networks
Jun 11, 2023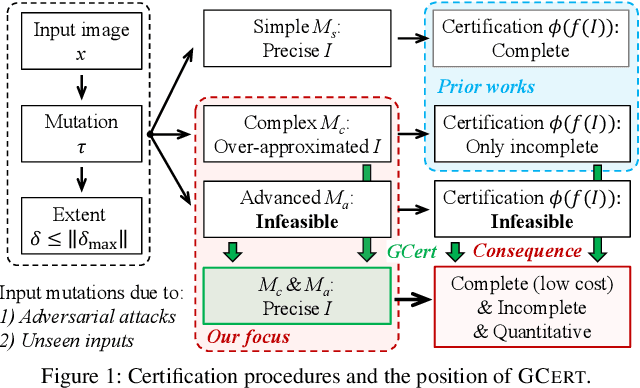
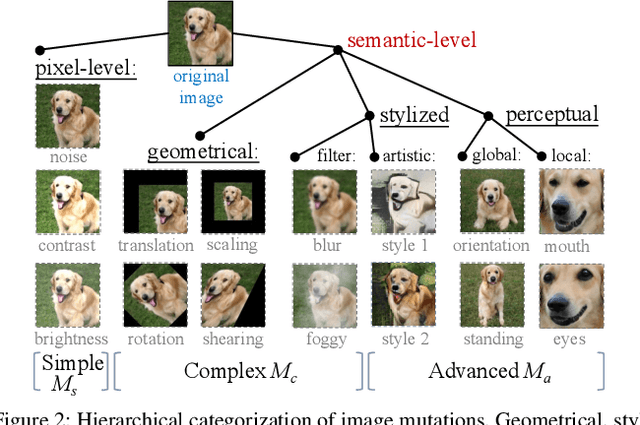
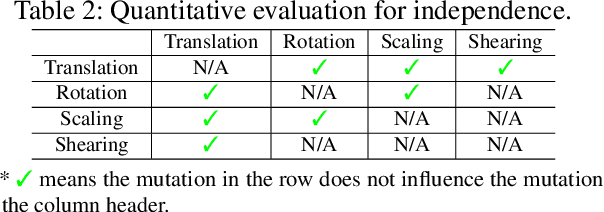
The objective of neural network (NN) robustness certification is to determine if a NN changes its predictions when mutations are made to its inputs. While most certification research studies pixel-level or a few geometrical-level and blurring operations over images, this paper proposes a novel framework, GCERT, which certifies NN robustness under a precise and unified form of diverse semantic-level image mutations. We formulate a comprehensive set of semantic-level image mutations uniformly as certain directions in the latent space of generative models. We identify two key properties, independence and continuity, that convert the latent space into a precise and analysis-friendly input space representation for certification. GCERT can be smoothly integrated with de facto complete, incomplete, or quantitative certification frameworks. With its precise input space representation, GCERT enables for the first time complete NN robustness certification with moderate cost under diverse semantic-level input mutations, such as weather-filter, style transfer, and perceptual changes (e.g., opening/closing eyes). We show that GCERT enables certifying NN robustness under various common and security-sensitive scenarios like autonomous driving.
Simultaneous Temperature and Acoustic Sensing with Coherent Correlation OTDR
May 26, 2023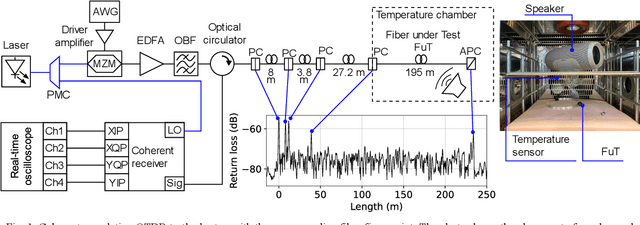
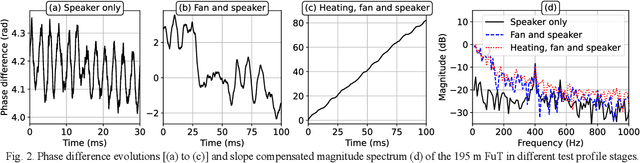
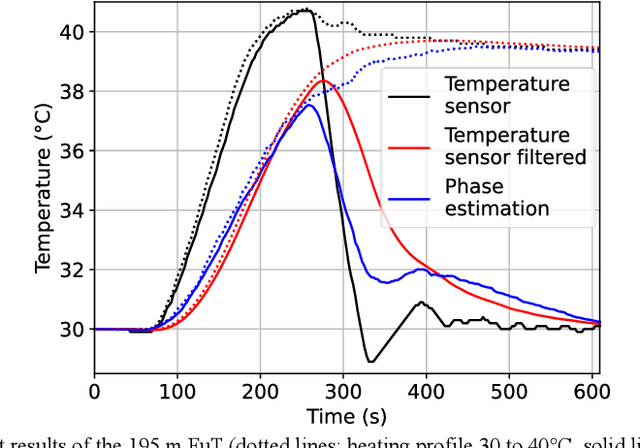
Superimposed temperature variations and dynamic strain applied through a 400 Hz acoustic signal on a 195 m single-mode fiber section are successfully measured using a coherent correlation optical time domain reflectometry as an interrogator.
* This work was partially funded by the German Federal Ministry of Education and Research in the framework of the RUBIN project Quantifisens (Project ID 03RU1U071D)
ConaCLIP: Exploring Distillation of Fully-Connected Knowledge Interaction Graph for Lightweight Text-Image Retrieval
May 28, 2023
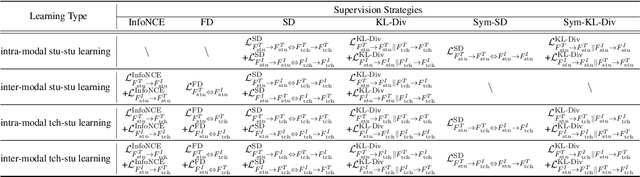
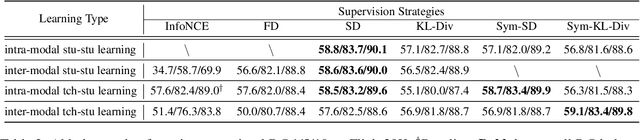
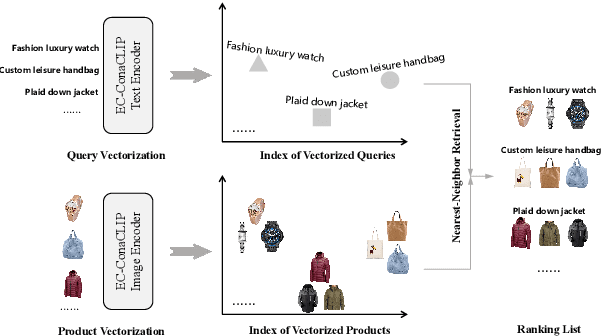
Large-scale pre-trained text-image models with dual-encoder architectures (such as CLIP) are typically adopted for various vision-language applications, including text-image retrieval. However,these models are still less practical on edge devices or for real-time situations, due to the substantial indexing and inference time and the large consumption of computational resources. Although knowledge distillation techniques have been widely utilized for uni-modal model compression, how to expand them to the situation when the numbers of modalities and teachers/students are doubled has been rarely studied. In this paper, we conduct comprehensive experiments on this topic and propose the fully-Connected knowledge interaction graph (Cona) technique for cross-modal pre-training distillation. Based on our findings, the resulting ConaCLIP achieves SOTA performances on the widely-used Flickr30K and MSCOCO benchmarks under the lightweight setting. An industry application of our method on an e-commercial platform further demonstrates the significant effectiveness of ConaCLIP.
HiddenSinger: High-Quality Singing Voice Synthesis via Neural Audio Codec and Latent Diffusion Models
Jun 12, 2023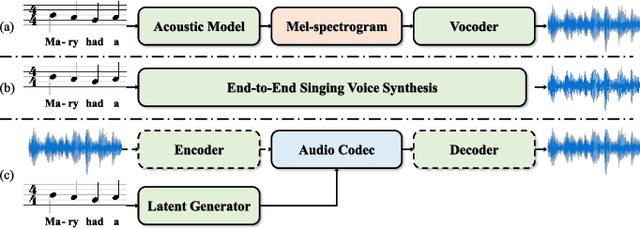
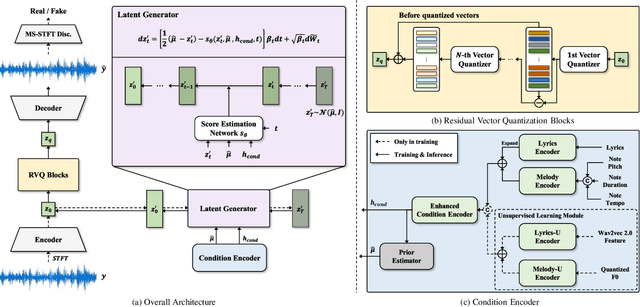
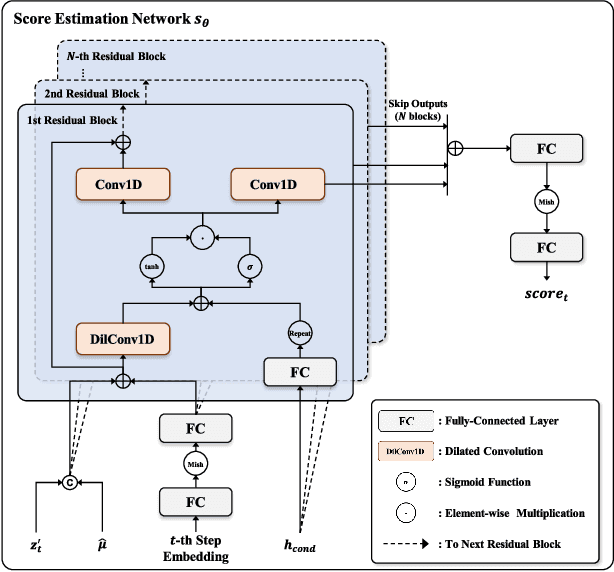
Recently, denoising diffusion models have demonstrated remarkable performance among generative models in various domains. However, in the speech domain, the application of diffusion models for synthesizing time-varying audio faces limitations in terms of complexity and controllability, as speech synthesis requires very high-dimensional samples with long-term acoustic features. To alleviate the challenges posed by model complexity in singing voice synthesis, we propose HiddenSinger, a high-quality singing voice synthesis system using a neural audio codec and latent diffusion models. To ensure high-fidelity audio, we introduce an audio autoencoder that can encode audio into an audio codec as a compressed representation and reconstruct the high-fidelity audio from the low-dimensional compressed latent vector. Subsequently, we use the latent diffusion models to sample a latent representation from a musical score. In addition, our proposed model is extended to an unsupervised singing voice learning framework, HiddenSinger-U, to train the model using an unlabeled singing voice dataset. Experimental results demonstrate that our model outperforms previous models in terms of audio quality. Furthermore, the HiddenSinger-U can synthesize high-quality singing voices of speakers trained solely on unlabeled data.
Diffusion Models for Black-Box Optimization
Jun 12, 2023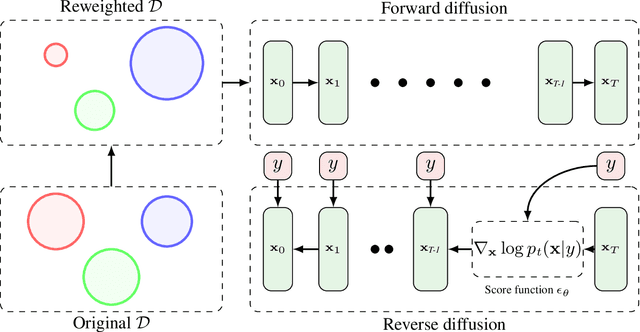
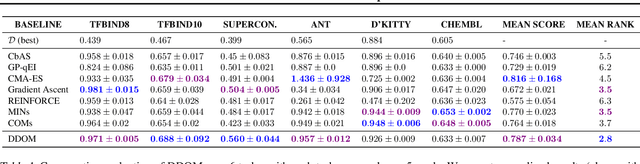
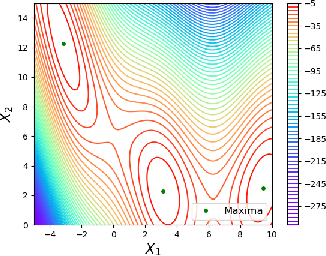

The goal of offline black-box optimization (BBO) is to optimize an expensive black-box function using a fixed dataset of function evaluations. Prior works consider forward approaches that learn surrogates to the black-box function and inverse approaches that directly map function values to corresponding points in the input domain of the black-box function. These approaches are limited by the quality of the offline dataset and the difficulty in learning one-to-many mappings in high dimensions, respectively. We propose Denoising Diffusion Optimization Models (DDOM), a new inverse approach for offline black-box optimization based on diffusion models. Given an offline dataset, DDOM learns a conditional generative model over the domain of the black-box function conditioned on the function values. We investigate several design choices in DDOM, such as re-weighting the dataset to focus on high function values and the use of classifier-free guidance at test-time to enable generalization to function values that can even exceed the dataset maxima. Empirically, we conduct experiments on the Design-Bench benchmark and show that DDOM achieves results competitive with state-of-the-art baselines.
Improving the performance of Learned Controllers in Behavior Trees using Value Function Estimates at Switching Boundaries
Jun 12, 2023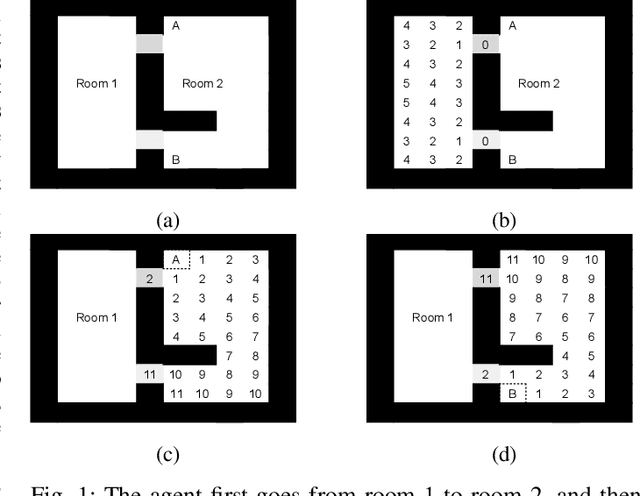

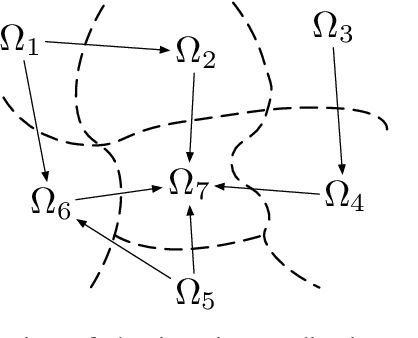
Behavior trees represent a modular way to create an overall controller from a set of sub-controllers solving different sub-problems. These sub-controllers can be created in different ways, such as classical model based control or reinforcement learning (RL). If each sub-controller satisfies the preconditions of the next sub-controller, the overall controller will achieve the overall goal. However, even if all sub-controllers are locally optimal in achieving the preconditions of the next, with respect to some performance metric such as completion time, the overall controller might be far from optimal with respect to the same performance metric. In this paper we show how the performance of the overall controller can be improved if we use approximations of value functions to inform the design of a sub-controller of the needs of the next one. We also show how, under certain assumptions, this leads to a globally optimal controller when the process is executed on all sub-controllers. Finally, this result also holds when some of the sub-controllers are already given, i.e., if we are constrained to use some existing sub-controllers the overall controller will be globally optimal given this constraint.
Ensemble-based Offline-to-Online Reinforcement Learning: From Pessimistic Learning to Optimistic Exploration
Jun 12, 2023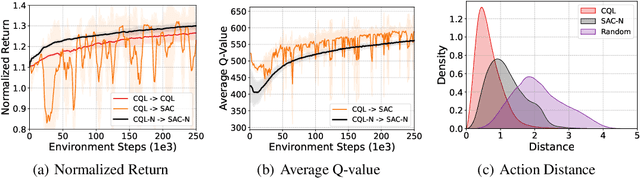

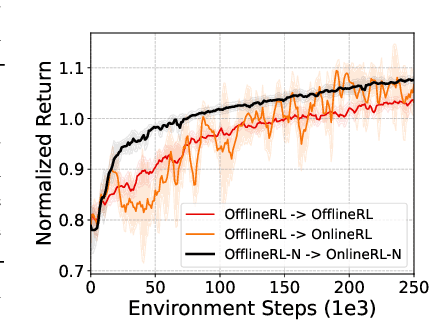
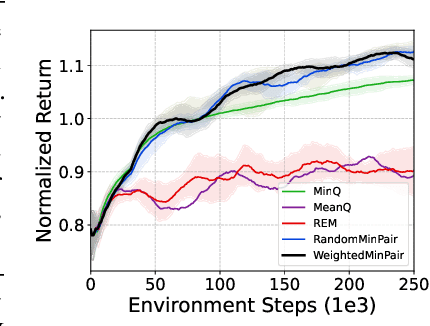
Offline reinforcement learning (RL) is a learning paradigm where an agent learns from a fixed dataset of experience. However, learning solely from a static dataset can limit the performance due to the lack of exploration. To overcome it, offline-to-online RL combines offline pre-training with online fine-tuning, which enables the agent to further refine its policy by interacting with the environment in real-time. Despite its benefits, existing offline-to-online RL methods suffer from performance degradation and slow improvement during the online phase. To tackle these challenges, we propose a novel framework called Ensemble-based Offline-to-Online (E2O) RL. By increasing the number of Q-networks, we seamlessly bridge offline pre-training and online fine-tuning without degrading performance. Moreover, to expedite online performance enhancement, we appropriately loosen the pessimism of Q-value estimation and incorporate ensemble-based exploration mechanisms into our framework. Experimental results demonstrate that E2O can substantially improve the training stability, learning efficiency, and final performance of existing offline RL methods during online fine-tuning on a range of locomotion and navigation tasks, significantly outperforming existing offline-to-online RL methods.
Supervised Deep Learning for Content-Aware Image Retargeting with Fourier Convolutions
Jun 12, 2023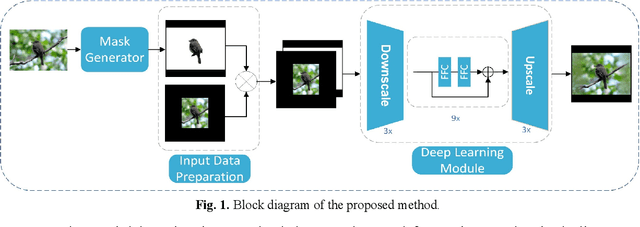


Image retargeting aims to alter the size of the image with attention to the contents. One of the main obstacles to training deep learning models for image retargeting is the need for a vast labeled dataset. Labeled datasets are unavailable for training deep learning models in the image retargeting tasks. As a result, we present a new supervised approach for training deep learning models. We use the original images as ground truth and create inputs for the model by resizing and cropping the original images. A second challenge is generating different image sizes in inference time. However, regular convolutional neural networks cannot generate images of different sizes than the input image. To address this issue, we introduced a new method for supervised learning. In our approach, a mask is generated to show the desired size and location of the object. Then the mask and the input image are fed to the network. Comparing image retargeting methods and our proposed method demonstrates the model's ability to produce high-quality retargeted images. Afterward, we compute the image quality assessment score for each output image based on different techniques and illustrate the effectiveness of our approach.
Making forecasting self-learning and adaptive -- Pilot forecasting rack
Jun 12, 2023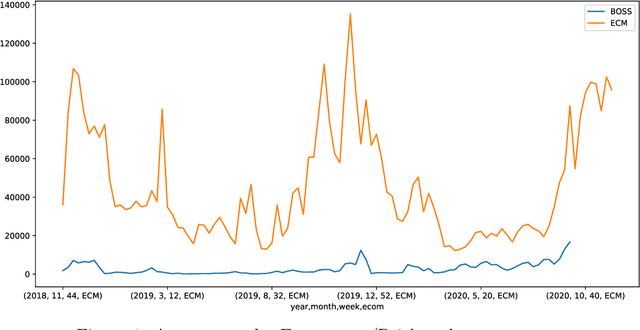
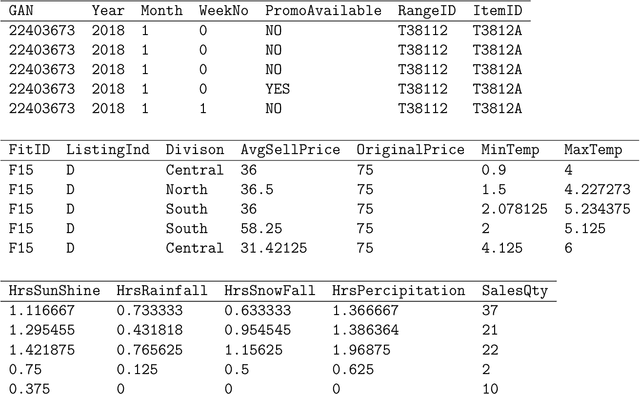
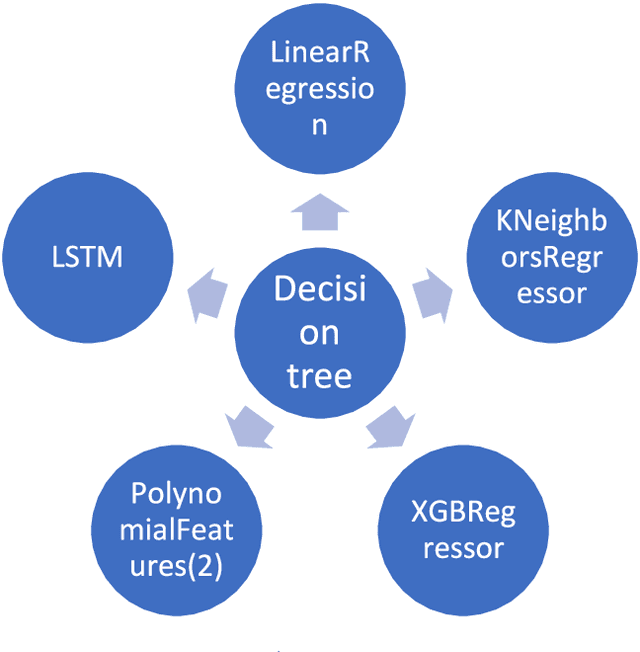

Retail sales and price projections are typically based on time series forecasting. For some product categories, the accuracy of demand forecasts achieved is low, negatively impacting inventory, transport, and replenishment planning. This paper presents our findings based on a proactive pilot exercise to explore ways to help retailers to improve forecast accuracy for such product categories. We evaluated opportunities for algorithmic interventions to improve forecast accuracy based on a sample product category, Knitwear. The Knitwear product category has a current demand forecast accuracy from non-AI models in the range of 60%. We explored how to improve the forecast accuracy using a rack approach. To generate forecasts, our decision model dynamically selects the best algorithm from an algorithm rack based on performance for a given state and context. Outcomes from our AI/ML forecasting model built using advanced feature engineering show an increase in the accuracy of demand forecast for Knitwear product category by 20%, taking the overall accuracy to 80%. Because our rack comprises algorithms that cater to a range of customer data sets, the forecasting model can be easily tailored for specific customer contexts.