 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?
Jun 06, 2023
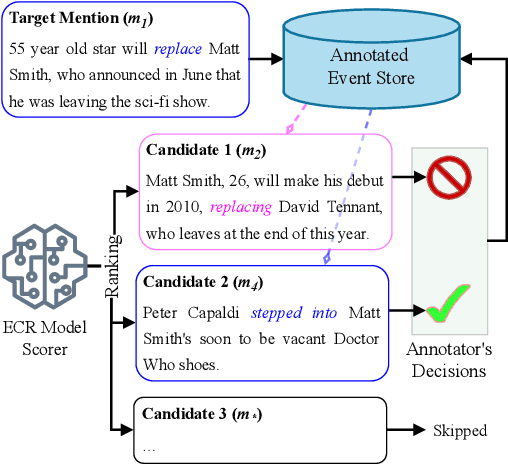
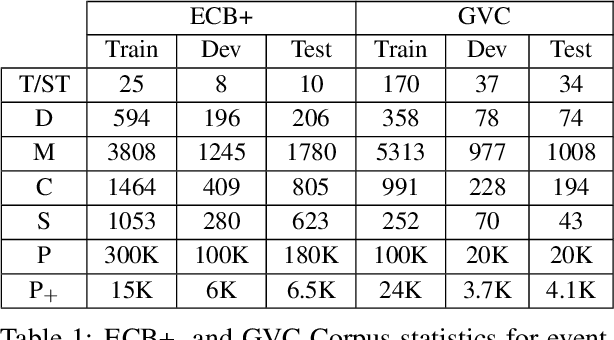
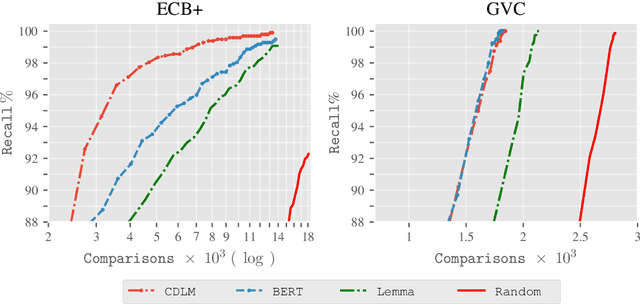
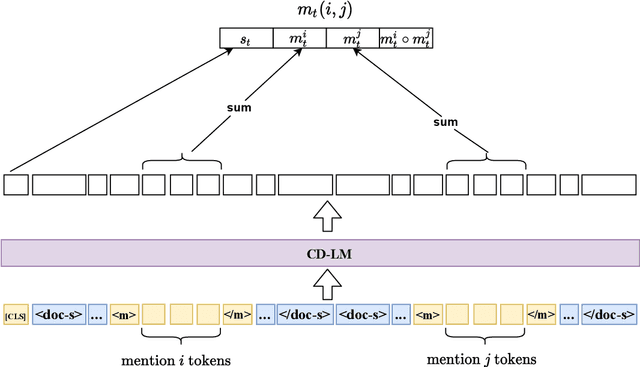
Annotating cross-document event coreference links is a time-consuming and cognitively demanding task that can compromise annotation quality and efficiency. To address this, we propose a model-in-the-loop annotation approach for event coreference resolution, where a machine learning model suggests likely corefering event pairs only. We evaluate the effectiveness of this approach by first simulating the annotation process and then, using a novel annotator-centric Recall-Annotation effort trade-off metric, we compare the results of various underlying models and datasets. We finally present a method for obtaining 97\% recall while substantially reducing the workload required by a fully manual annotation process. Code and data can be found at https://github.com/ahmeshaf/model_in_coref
Communication-minimizing Asynchronous Tensor Parallelism
May 22, 2023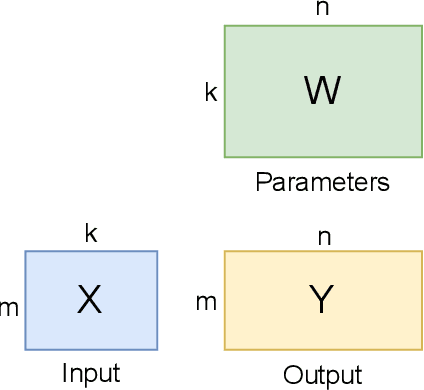
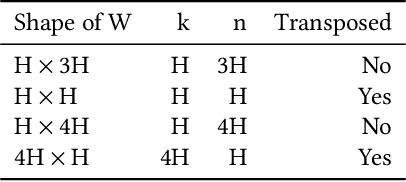
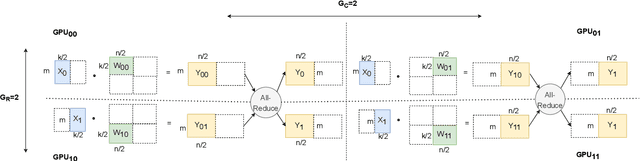
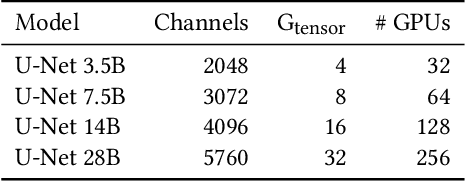
As state-of-the-art neural networks scale to billions of parameters, designing parallel algorithms that can train these networks efficiently on multi-GPU clusters has become critical. This paper presents Tensor3D, a novel three-dimensional (3D) approach to parallelize tensor computations, that strives to minimize the idle time incurred due to communication in parallel training of large multi-billion parameter models. First, we introduce an intelligent distribution of neural network parameters across GPUs that eliminates communication required for satisfying data dependencies of individual layers. Then, we propose a novel overdecomposition of the parallel training process, using which we achieve significant overlap of communication with computation, thereby reducing GPU idle time. Finally, we present a communication model, which helps users identify communication optimal decompositions of available hardware resources for a given neural network. For a 28B parameter CNN on 256 A100 GPUs, Tensor3D improves the training time by nearly 60% as compared to Megatron-LM.
Brain Tumor Recurrence vs. Radiation Necrosis Classification and Patient Survivability Prediction
Jun 05, 2023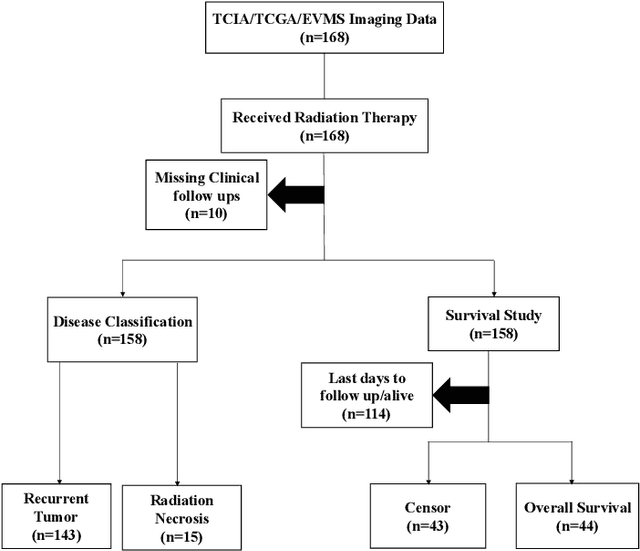
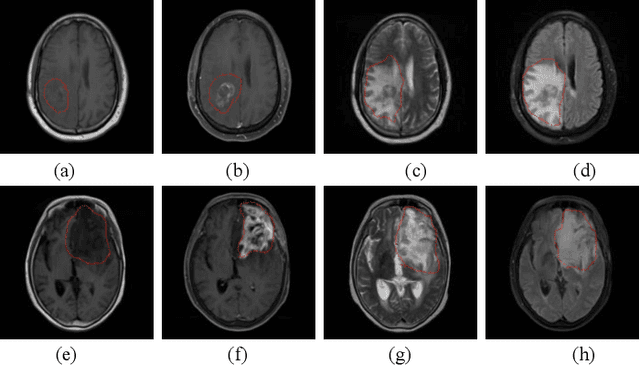
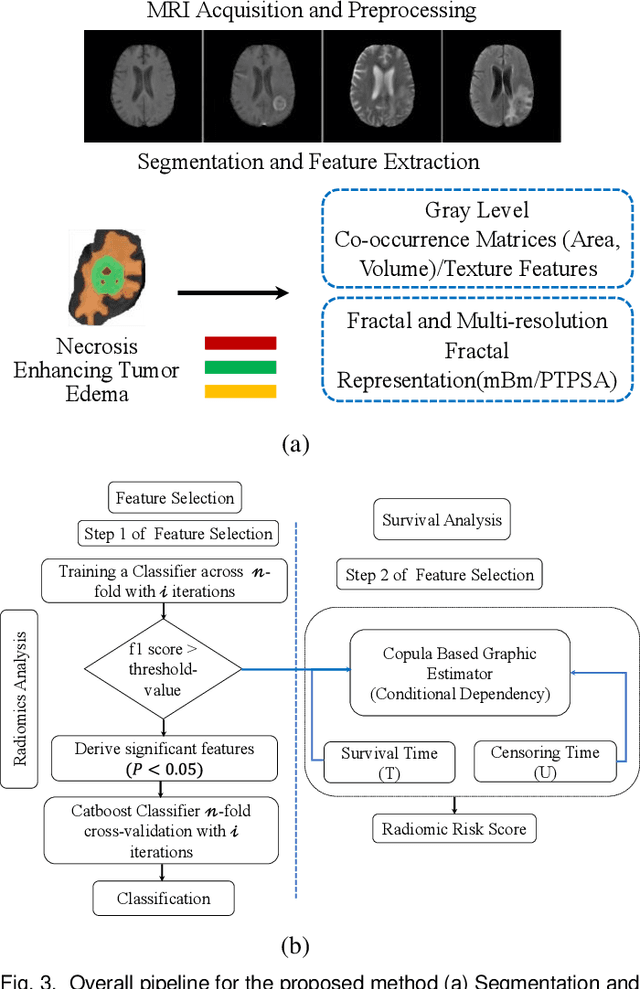
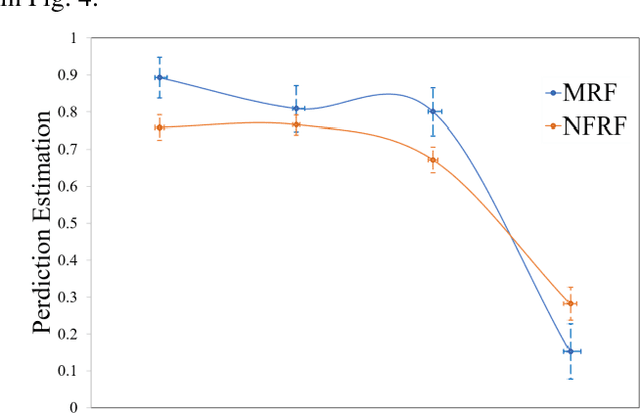
GBM (Glioblastoma multiforme) is the most aggressive type of brain tumor in adults that has a short survival rate even after aggressive treatment with surgery and radiation therapy. The changes on magnetic resonance imaging (MRI) for patients with GBM after radiotherapy are indicative of either radiation-induced necrosis (RN) or recurrent brain tumor (rBT). Screening for rBT and RN at an early stage is crucial for facilitating faster treatment and better outcomes for the patients. Differentiating rBT from RN is challenging as both may present with similar radiological and clinical characteristics on MRI. Moreover, learning-based rBT versus RN classification using MRI may suffer from class imbalance due to lack of patient data. While synthetic data generation using generative models has shown promise to address class imbalance, the underlying data representation may be different in synthetic or augmented data. This study proposes computational modeling with statistically rigorous repeated random sub-sampling to balance the subset sample size for rBT and RN classification. The proposed pipeline includes multiresolution radiomic feature (MRF) extraction followed by feature selection with statistical significance testing (p<0.05). The five-fold cross validation results show the proposed model with MRF features classifies rBT from RN with an area under the curve (AUC) of 0.8920+-.055. Moreover, considering the dependence between survival time and censor time (where patients are not followed up until death), we demonstrate the feasibility of using MRF radiomic features as a non-invasive biomarker to identify patients who are at higher risk of recurrence or radiation necrosis. The cross-validated results show that the MRF model provides the best overall performance with an AUC of 0.770+-.032.
Bayesian Learning of Optimal Policies in Markov Decision Processes with Countably Infinite State-Space
Jun 05, 2023

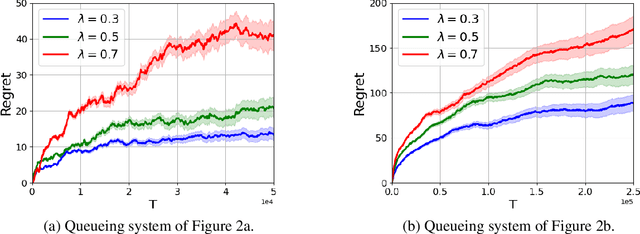
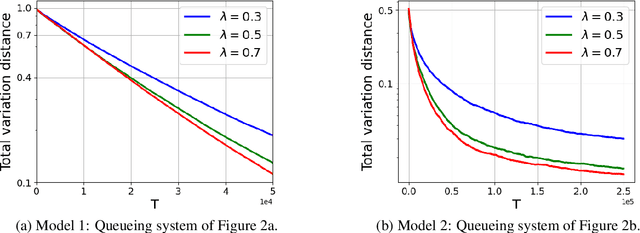
Models of many real-life applications, such as queuing models of communication networks or computing systems, have a countably infinite state-space. Algorithmic and learning procedures that have been developed to produce optimal policies mainly focus on finite state settings, and do not directly apply to these models. To overcome this lacuna, in this work we study the problem of optimal control of a family of discrete-time countable state-space Markov Decision Processes (MDPs) governed by an unknown parameter $\theta\in\Theta$, and defined on a countably-infinite state space $\mathcal X=\mathbb{Z}_+^d$, with finite action space $\mathcal A$, and an unbounded cost function. We take a Bayesian perspective with the random unknown parameter $\boldsymbol{\theta}^*$ generated via a given fixed prior distribution on $\Theta$. To optimally control the unknown MDP, we propose an algorithm based on Thompson sampling with dynamically-sized episodes: at the beginning of each episode, the posterior distribution formed via Bayes' rule is used to produce a parameter estimate, which then decides the policy applied during the episode. To ensure the stability of the Markov chain obtained by following the policy chosen for each parameter, we impose ergodicity assumptions. From this condition and using the solution of the average cost Bellman equation, we establish an $\tilde O(\sqrt{|\mathcal A|T})$ upper bound on the Bayesian regret of our algorithm, where $T$ is the time-horizon. Finally, to elucidate the applicability of our algorithm, we consider two different queuing models with unknown dynamics, and show that our algorithm can be applied to develop approximately optimal control algorithms.
Mask and Restore: Blind Backdoor Defense at Test Time with Masked Autoencoder
Mar 27, 2023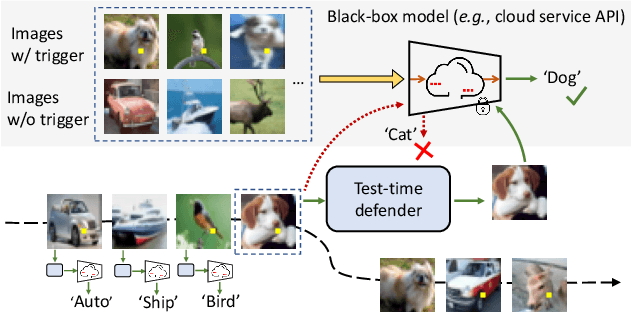
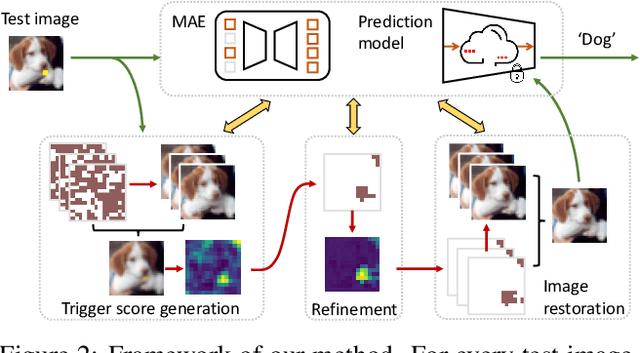
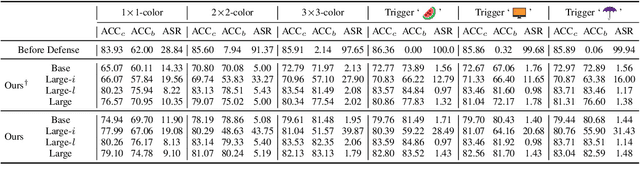
Deep neural networks are vulnerable to backdoor attacks, where an adversary maliciously manipulates the model behavior through overlaying images with special triggers. Existing backdoor defense methods often require accessing a few validation data and model parameters, which are impractical in many real-world applications, e.g., when the model is provided as a cloud service. In this paper, we address the practical task of blind backdoor defense at test time, in particular for black-box models. The true label of every test image needs to be recovered on the fly from the hard label predictions of a suspicious model. The heuristic trigger search in image space, however, is not scalable to complex triggers or high image resolution. We circumvent such barrier by leveraging generic image generation models, and propose a framework of Blind Defense with Masked AutoEncoder (BDMAE). It uses the image structural similarity and label consistency between the test image and MAE restorations to detect possible triggers. The detection result is refined by considering the topology of triggers. We obtain a purified test image from restorations for making prediction. Our approach is blind to the model architectures, trigger patterns or image benignity. Extensive experiments on multiple datasets with different backdoor attacks validate its effectiveness and generalizability. Code is available at https://github.com/tsun/BDMAE.
SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
Mar 27, 2023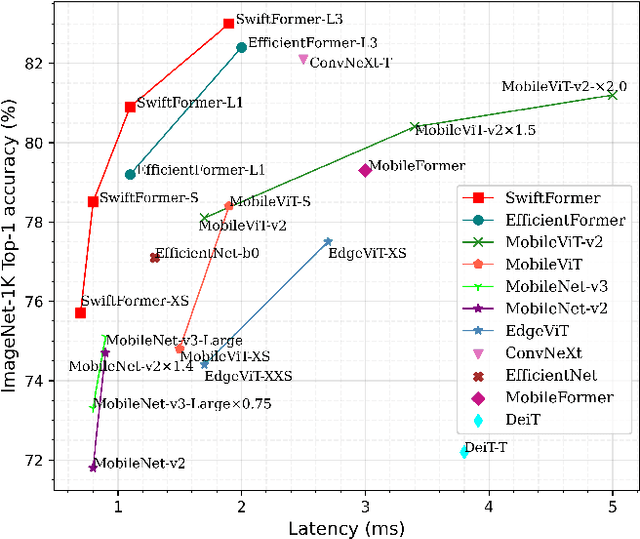

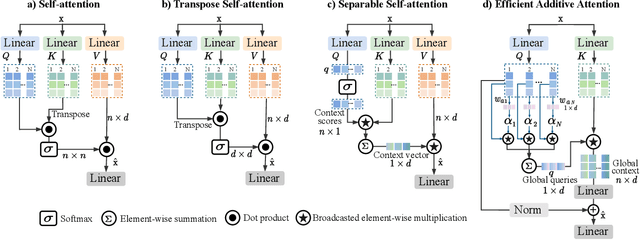
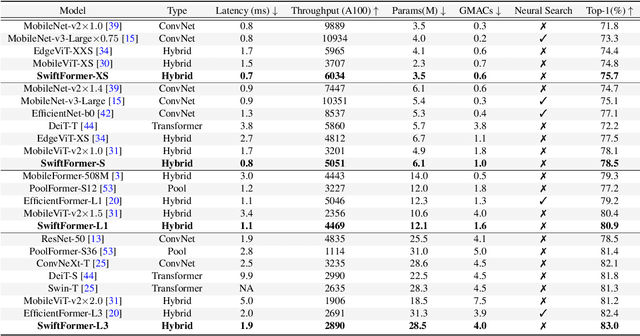
Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2. Code: https://github.com/Amshaker/SwiftFormer
Precise and Generalized Robustness Certification for Neural Networks
Jun 11, 2023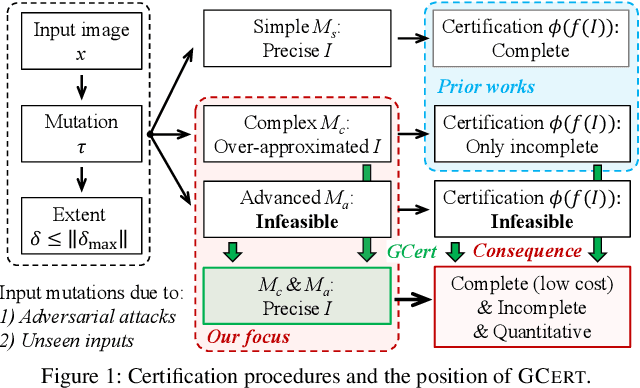
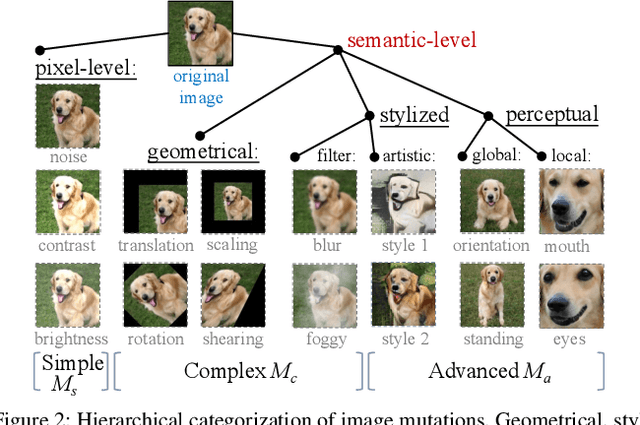
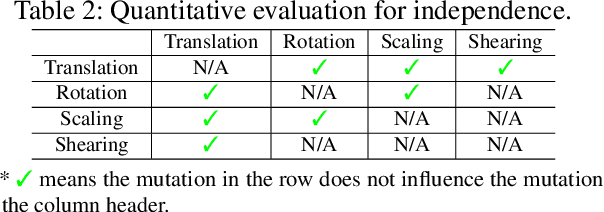
The objective of neural network (NN) robustness certification is to determine if a NN changes its predictions when mutations are made to its inputs. While most certification research studies pixel-level or a few geometrical-level and blurring operations over images, this paper proposes a novel framework, GCERT, which certifies NN robustness under a precise and unified form of diverse semantic-level image mutations. We formulate a comprehensive set of semantic-level image mutations uniformly as certain directions in the latent space of generative models. We identify two key properties, independence and continuity, that convert the latent space into a precise and analysis-friendly input space representation for certification. GCERT can be smoothly integrated with de facto complete, incomplete, or quantitative certification frameworks. With its precise input space representation, GCERT enables for the first time complete NN robustness certification with moderate cost under diverse semantic-level input mutations, such as weather-filter, style transfer, and perceptual changes (e.g., opening/closing eyes). We show that GCERT enables certifying NN robustness under various common and security-sensitive scenarios like autonomous driving.
Training neural operators to preserve invariant measures of chaotic attractors
Jun 01, 2023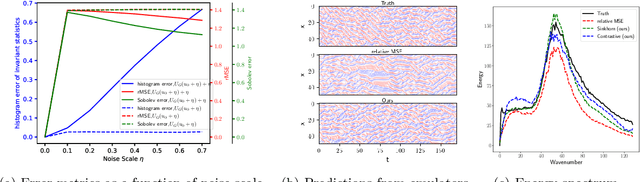
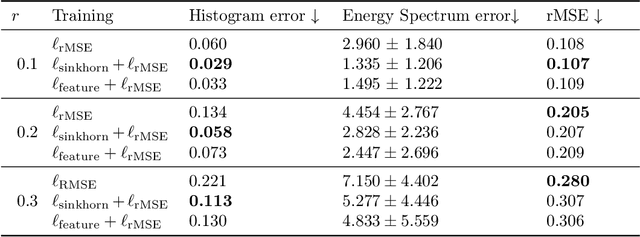
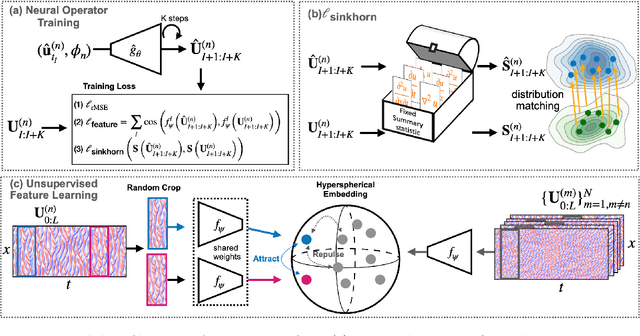

Chaotic systems make long-horizon forecasts difficult because small perturbations in initial conditions cause trajectories to diverge at an exponential rate. In this setting, neural operators trained to minimize squared error losses, while capable of accurate short-term forecasts, often fail to reproduce statistical or structural properties of the dynamics over longer time horizons and can yield degenerate results. In this paper, we propose an alternative framework designed to preserve invariant measures of chaotic attractors that characterize the time-invariant statistical properties of the dynamics. Specifically, in the multi-environment setting (where each sample trajectory is governed by slightly different dynamics), we consider two novel approaches to training with noisy data. First, we propose a loss based on the optimal transport distance between the observed dynamics and the neural operator outputs. This approach requires expert knowledge of the underlying physics to determine what statistical features should be included in the optimal transport loss. Second, we show that a contrastive learning framework, which does not require any specialized prior knowledge, can preserve statistical properties of the dynamics nearly as well as the optimal transport approach. On a variety of chaotic systems, our method is shown empirically to preserve invariant measures of chaotic attractors.
Multi-Robot Path Planning Combining Heuristics and Multi-Agent Reinforcement Learning
Jun 02, 2023
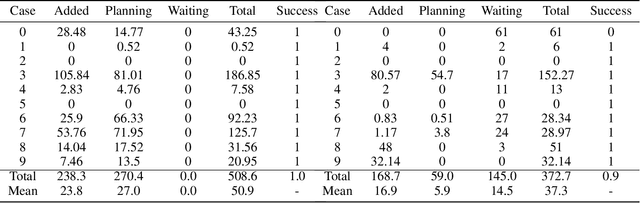
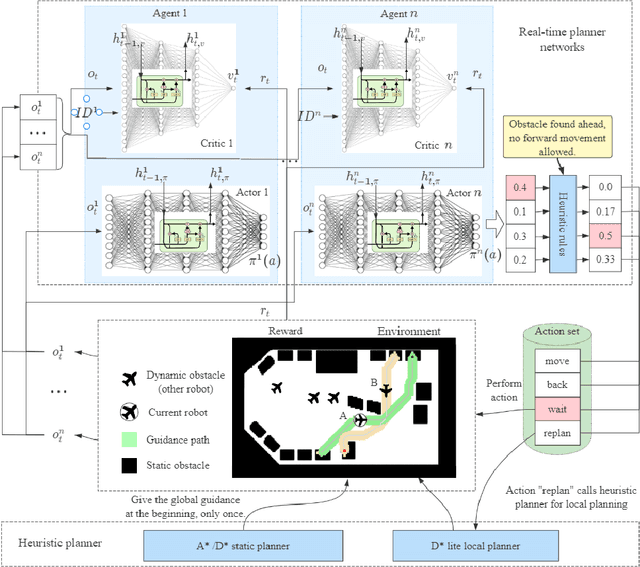
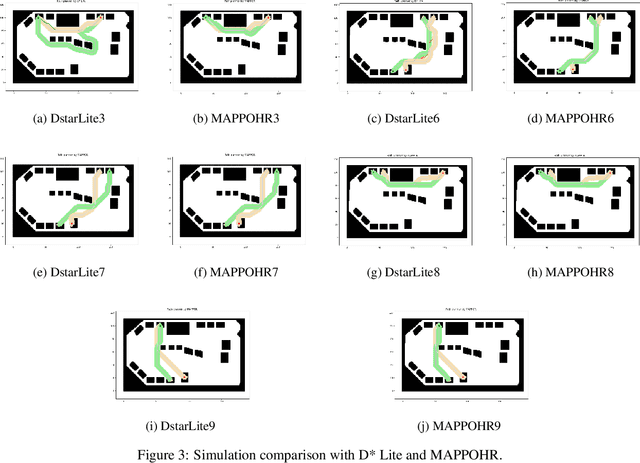
Multi-robot path finding in dynamic environments is a highly challenging classic problem. In the movement process, robots need to avoid collisions with other moving robots while minimizing their travel distance. Previous methods for this problem either continuously replan paths using heuristic search methods to avoid conflicts or choose appropriate collision avoidance strategies based on learning approaches. The former may result in long travel distances due to frequent replanning, while the latter may have low learning efficiency due to low sample exploration and utilization, and causing high training costs for the model. To address these issues, we propose a path planning method, MAPPOHR, which combines heuristic search, empirical rules, and multi-agent reinforcement learning. The method consists of two layers: a real-time planner based on the multi-agent reinforcement learning algorithm, MAPPO, which embeds empirical rules in the action output layer and reward functions, and a heuristic search planner used to create a global guiding path. During movement, the heuristic search planner replans new paths based on the instructions of the real-time planner. We tested our method in 10 different conflict scenarios. The experiments show that the planning performance of MAPPOHR is better than that of existing learning and heuristic methods. Due to the utilization of empirical knowledge and heuristic search, the learning efficiency of MAPPOHR is higher than that of existing learning methods.
Adaptive learning of effective dynamics: Adaptive real-time, online modeling for complex systems
Apr 04, 2023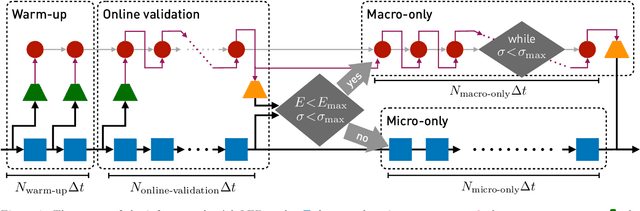

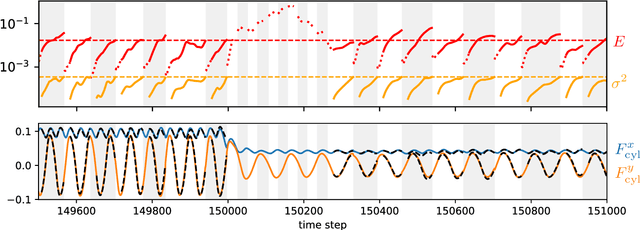
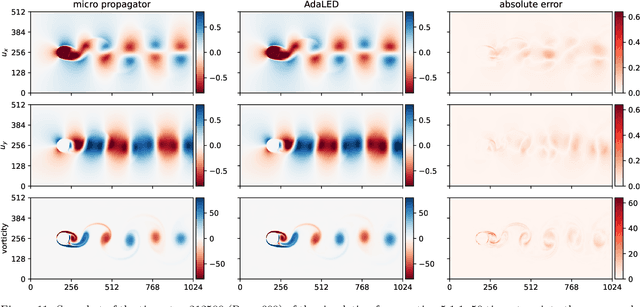
Predictive simulations are essential for applications ranging from weather forecasting to material design. The veracity of these simulations hinges on their capacity to capture the effective system dynamics. Massively parallel simulations predict the systems dynamics by resolving all spatiotemporal scales, often at a cost that prevents experimentation. On the other hand, reduced order models are fast but often limited by the linearization of the system dynamics and the adopted heuristic closures. We propose a novel systematic framework that bridges large scale simulations and reduced order models to extract and forecast adaptively the effective dynamics (AdaLED) of multiscale systems. AdaLED employs an autoencoder to identify reduced-order representations of the system dynamics and an ensemble of probabilistic recurrent neural networks (RNNs) as the latent time-stepper. The framework alternates between the computational solver and the surrogate, accelerating learned dynamics while leaving yet-to-be-learned dynamics regimes to the original solver. AdaLED continuously adapts the surrogate to the new dynamics through online training. The transitions between the surrogate and the computational solver are determined by monitoring the prediction accuracy and uncertainty of the surrogate. The effectiveness of AdaLED is demonstrated on three different systems - a Van der Pol oscillator, a 2D reaction-diffusion equation, and a 2D Navier-Stokes flow past a cylinder for varying Reynolds numbers (400 up to 1200), showcasing its ability to learn effective dynamics online, detect unseen dynamics regimes, and provide net speed-ups. To the best of our knowledge, AdaLED is the first framework that couples a surrogate model with a computational solver to achieve online adaptive learning of effective dynamics. It constitutes a potent tool for applications requiring many expensive simulations.