 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ReactGenie: An Object-Oriented State Abstraction for Complex Multimodal Interactions Using Large Language Models
Jun 16, 2023
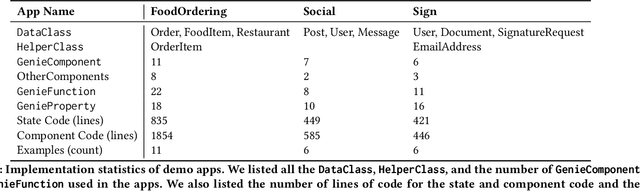
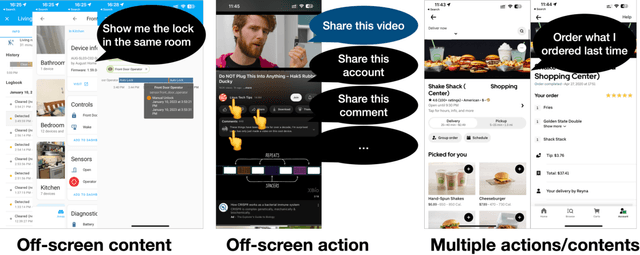

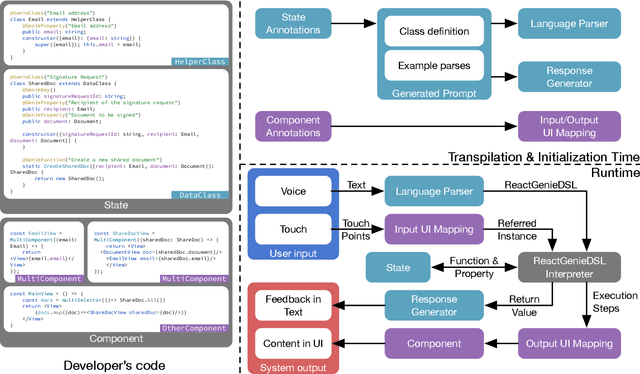
Multimodal interactions have been shown to be more flexible, efficient, and adaptable for diverse users and tasks than traditional graphical interfaces. However, existing multimodal development frameworks either do not handle the complexity and compositionality of multimodal commands well or require developers to write a substantial amount of code to support these multimodal interactions. In this paper, we present ReactGenie, a programming framework that uses a shared object-oriented state abstraction to support building complex multimodal mobile applications. Having different modalities share the same state abstraction allows developers using ReactGenie to seamlessly integrate and compose these modalities to deliver multimodal interaction. ReactGenie is a natural extension to the existing workflow of building a graphical app, like the workflow with React-Redux. Developers only have to add a few annotations and examples to indicate how natural language is mapped to the user-accessible functions in the program. ReactGenie automatically handles the complex problem of understanding natural language by generating a parser that leverages large language models. We evaluated the ReactGenie framework by using it to build three demo apps. We evaluated the accuracy of the language parser using elicited commands from crowd workers and evaluated the usability of the generated multimodal app with 16 participants. Our results show that ReactGenie can be used to build versatile multimodal applications with highly accurate language parsers, and the multimodal app can lower users' cognitive load and task completion time.
CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
Jun 16, 2023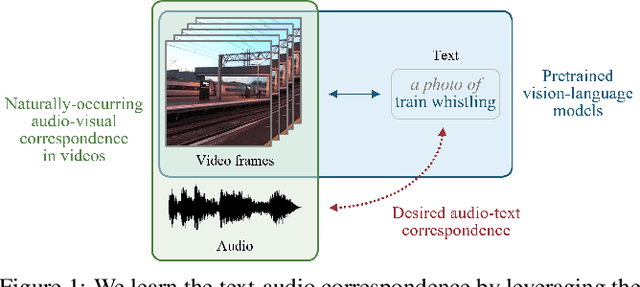
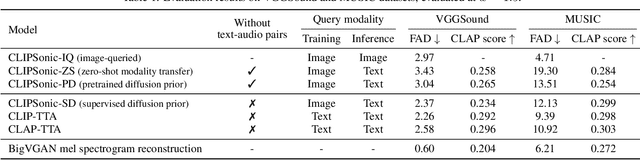
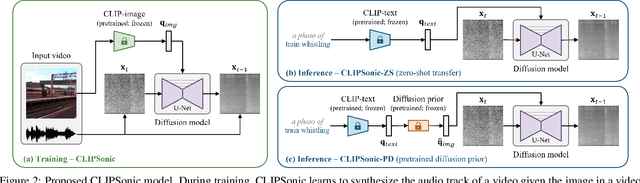
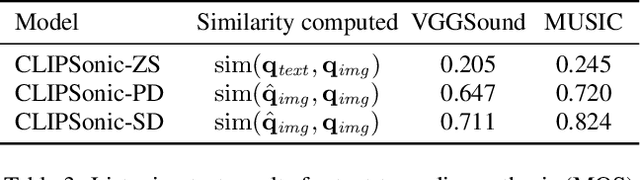
Recent work has studied text-to-audio synthesis using large amounts of paired text-audio data. However, audio recordings with high-quality text annotations can be difficult to acquire. In this work, we approach text-to-audio synthesis using unlabeled videos and pretrained language-vision models. We propose to learn the desired text-audio correspondence by leveraging the visual modality as a bridge. We train a conditional diffusion model to generate the audio track of a video, given a video frame encoded by a pretrained contrastive language-image pretraining (CLIP) model. At test time, we first explore performing a zero-shot modality transfer and condition the diffusion model with a CLIP-encoded text query. However, we observe a noticeable performance drop with respect to image queries. To close this gap, we further adopt a pretrained diffusion prior model to generate a CLIP image embedding given a CLIP text embedding. Our results show the effectiveness of the proposed method, and that the pretrained diffusion prior can reduce the modality transfer gap. While we focus on text-to-audio synthesis, the proposed model can also generate audio from image queries, and it shows competitive performance against a state-of-the-art image-to-audio synthesis model in a subjective listening test. This study offers a new direction of approaching text-to-audio synthesis that leverages the naturally-occurring audio-visual correspondence in videos and the power of pretrained language-vision models.
When Hyperspectral Image Classification Meets Diffusion Models: An Unsupervised Feature Learning Framework
Jun 15, 2023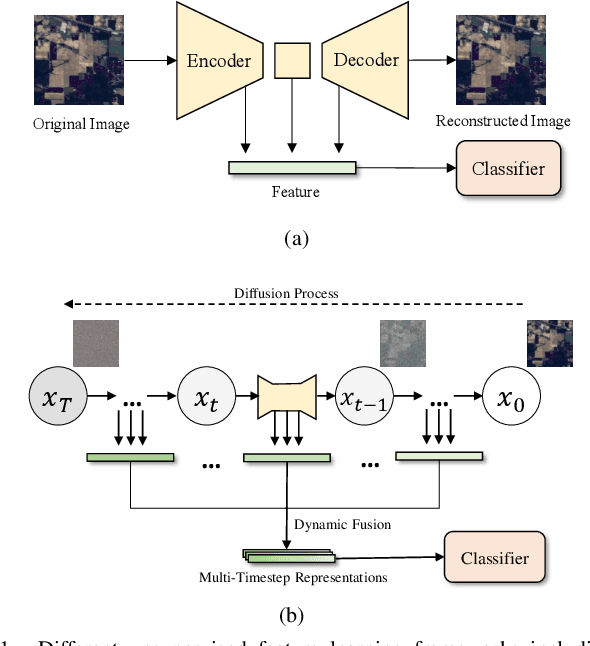
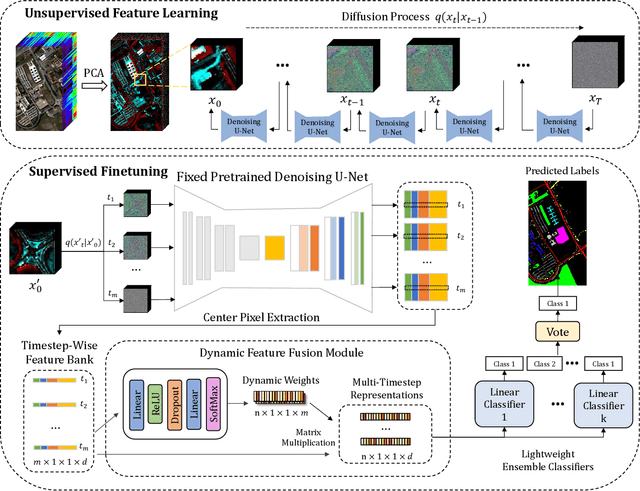
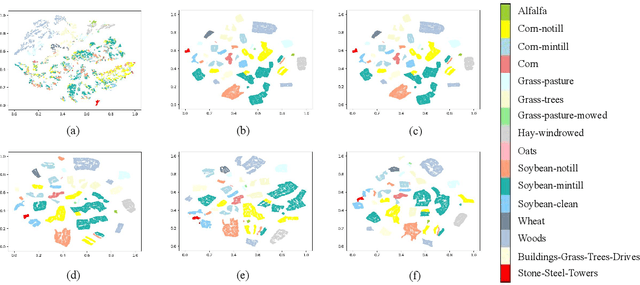
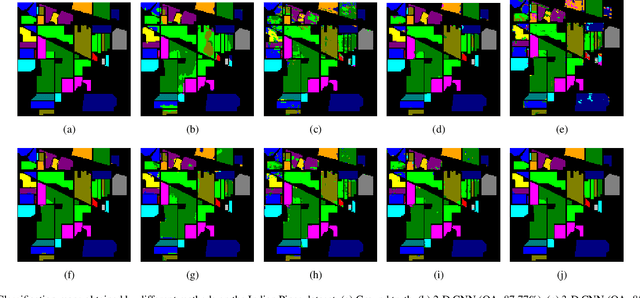
Learning effective spectral-spatial features is important for the hyperspectral image (HSI) classification task, but the majority of existing HSI classification methods still suffer from modeling complex spectral-spatial relations and characterizing low-level details and high-level semantics comprehensively. As a new class of record-breaking generative models, diffusion models are capable of modeling complex relations for understanding inputs well as learning both high-level and low-level visual features. Meanwhile, diffusion models can capture more abundant features by taking advantage of the extra and unique dimension of timestep t. In view of these, we propose an unsupervised spectral-spatial feature learning framework based on the diffusion model for HSI classification for the first time, named Diff-HSI. Specifically, we first pretrain the diffusion model with unlabeled HSI patches for unsupervised feature learning, and then exploit intermediate hierarchical features from different timesteps for classification. For better using the abundant timestep-wise features, we design a timestep-wise feature bank and a dynamic feature fusion module to construct timestep-wise features, adaptively learning informative multi-timestep representations. Finally, an ensemble of linear classifiers is applied to perform HSI classification. Extensive experiments are conducted on three public HSI datasets, and our results demonstrate that Diff-HSI outperforms state-of-the-art supervised and unsupervised methods for HSI classification.
ReLoop2: Building Self-Adaptive Recommendation Models via Responsive Error Compensation Loop
Jun 15, 2023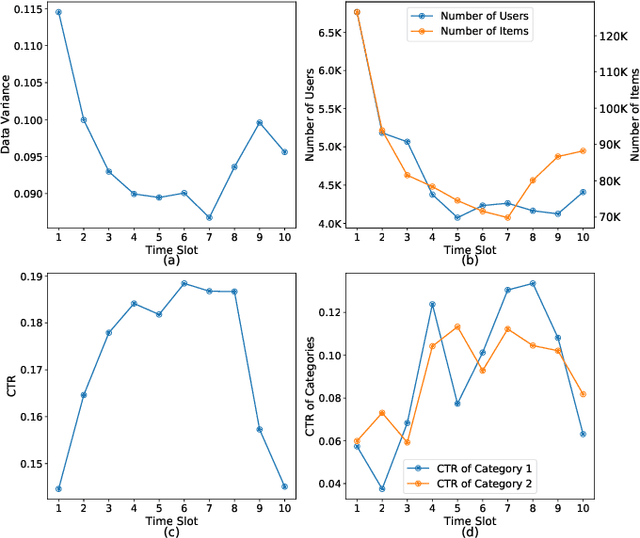
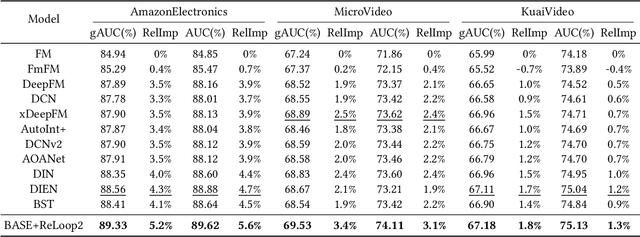
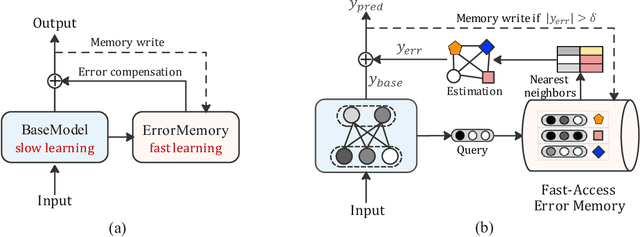
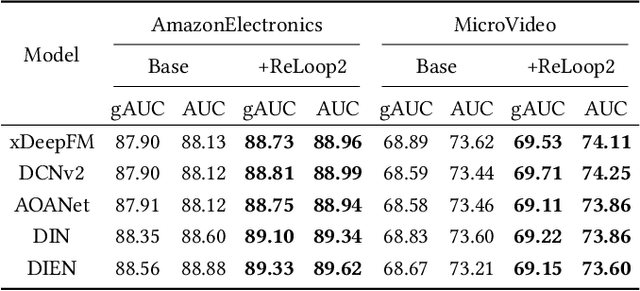
Industrial recommender systems face the challenge of operating in non-stationary environments, where data distribution shifts arise from evolving user behaviors over time. To tackle this challenge, a common approach is to periodically re-train or incrementally update deployed deep models with newly observed data, resulting in a continual training process. However, the conventional learning paradigm of neural networks relies on iterative gradient-based updates with a small learning rate, making it slow for large recommendation models to adapt. In this paper, we introduce ReLoop2, a self-correcting learning loop that facilitates fast model adaptation in online recommender systems through responsive error compensation. Inspired by the slow-fast complementary learning system observed in human brains, we propose an error memory module that directly stores error samples from incoming data streams. These stored samples are subsequently leveraged to compensate for model prediction errors during testing, particularly under distribution shifts. The error memory module is designed with fast access capabilities and undergoes continual refreshing with newly observed data samples during the model serving phase to support fast model adaptation. We evaluate the effectiveness of ReLoop2 on three open benchmark datasets as well as a real-world production dataset. The results demonstrate the potential of ReLoop2 in enhancing the responsiveness and adaptiveness of recommender systems operating in non-stationary environments.
Fix Fairness, Don't Ruin Accuracy: Performance Aware Fairness Repair using AutoML
Jun 15, 2023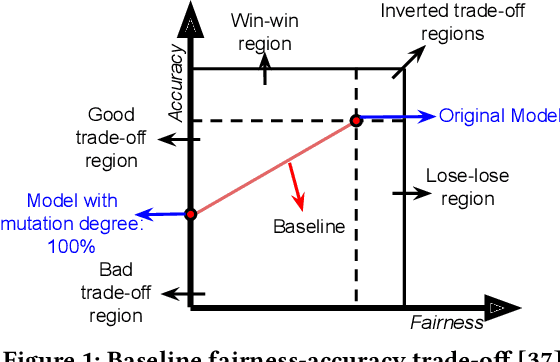
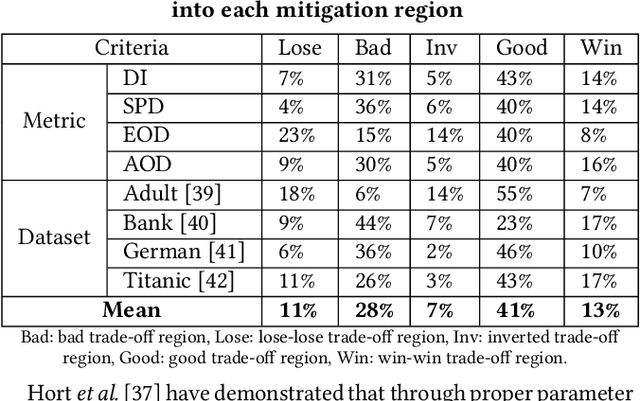
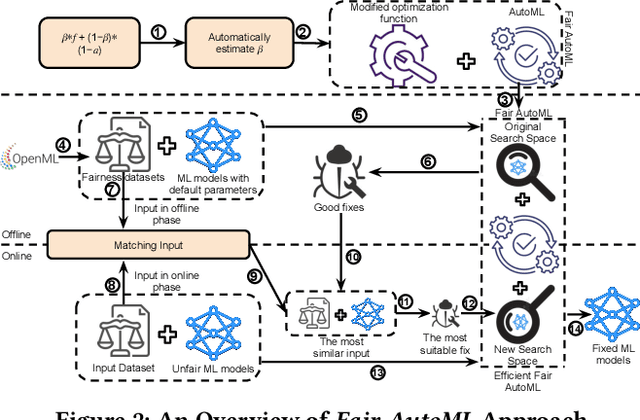
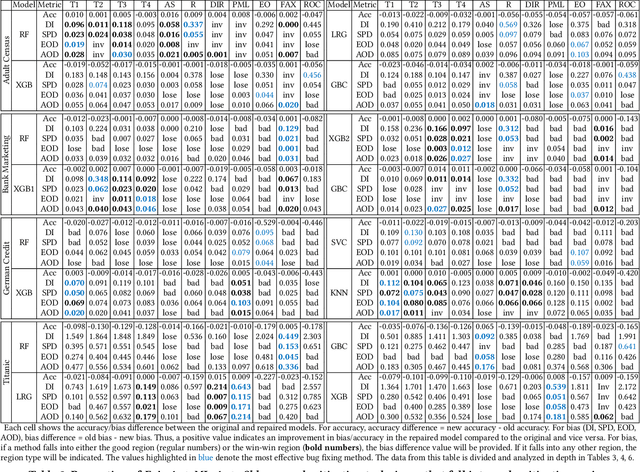
Machine learning (ML) is increasingly being used in critical decision-making software, but incidents have raised questions about the fairness of ML predictions. To address this issue, new tools and methods are needed to mitigate bias in ML-based software. Previous studies have proposed bias mitigation algorithms that only work in specific situations and often result in a loss of accuracy. Our proposed solution is a novel approach that utilizes automated machine learning (AutoML) techniques to mitigate bias. Our approach includes two key innovations: a novel optimization function and a fairness-aware search space. By improving the default optimization function of AutoML and incorporating fairness objectives, we are able to mitigate bias with little to no loss of accuracy. Additionally, we propose a fairness-aware search space pruning method for AutoML to reduce computational cost and repair time. Our approach, built on the state-of-the-art Auto-Sklearn tool, is designed to reduce bias in real-world scenarios. In order to demonstrate the effectiveness of our approach, we evaluated our approach on four fairness problems and 16 different ML models, and our results show a significant improvement over the baseline and existing bias mitigation techniques. Our approach, Fair-AutoML, successfully repaired 60 out of 64 buggy cases, while existing bias mitigation techniques only repaired up to 44 out of 64 cases.
SplatFlow: Learning Multi-frame Optical Flow via Splatting
Jun 15, 2023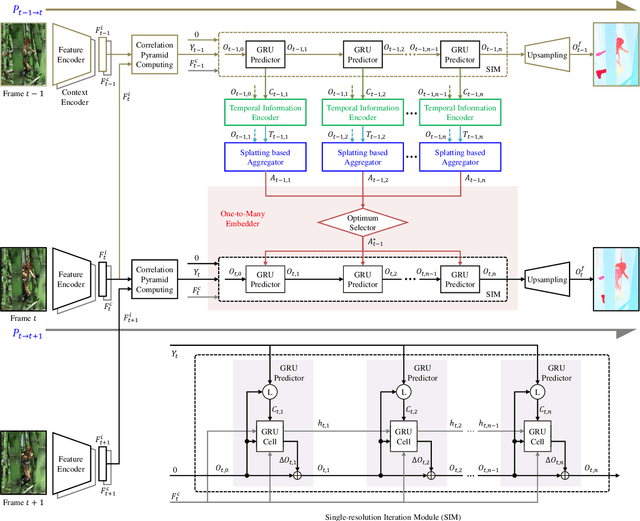
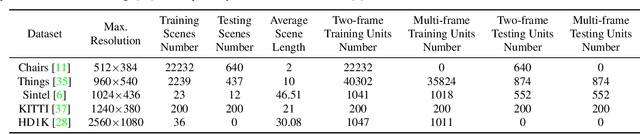
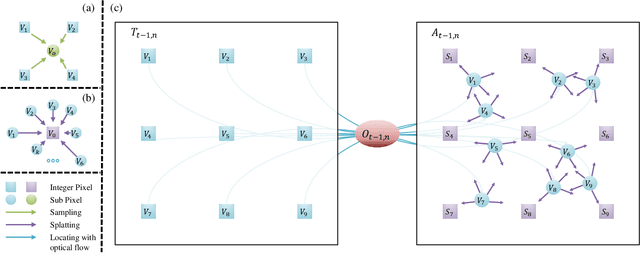
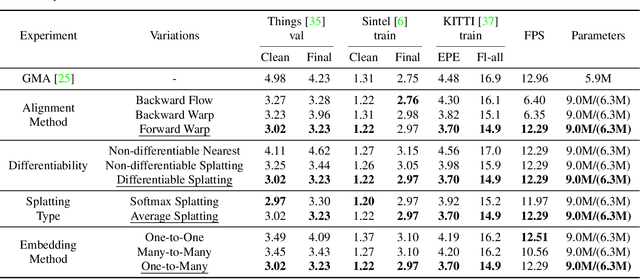
Occlusion problem remains a key challenge in Optical Flow Estimation (OFE) despite the recent significant progress brought by deep learning in the field. Most existing deep learning OFE methods, especially those based on two frames, cannot properly handle occlusions, in part because there is no significant feature similarity in occluded regions. The multi-frame settings have the potential to mitigate the occlusion issue in OFE. However, the problem of Multi-frame OFE (MOFE) remains underexplored, and the limited works are specially designed for pyramid backbones and obtain the aligned temporal information by time-consuming backward flow calculation or non-differentiable forward warping transformation. To address these shortcomings, we propose an efficient MOFE framework named SplatFlow, which is realized by introducing the differentiable splatting transformation to align the temporal information, designing a One-to-Many embedding method to densely guide the current frame's estimation, and further remodelling the existing two-frame backbones. The proposed SplatFlow is very efficient yet more accurate as it is able to handle occlusions properly. Extensive experimental evaluations show that our SplatFlow substantially outperforms all published methods on KITTI2015 and Sintel benchmarks. Especially on Sintel benchmark, SplatFlow achieves errors of 1.12 (clean pass) and 2.07 (final pass), with surprisingly significant 19.4% and 16.2% error reductions from the previous best results submitted, respectively. Code is available at https://github.com/wwsource/SplatFlow.
Prevention of cyberattacks in WSN and packet drop by CI framework and information processing protocol using AI and Big Data
Jun 15, 2023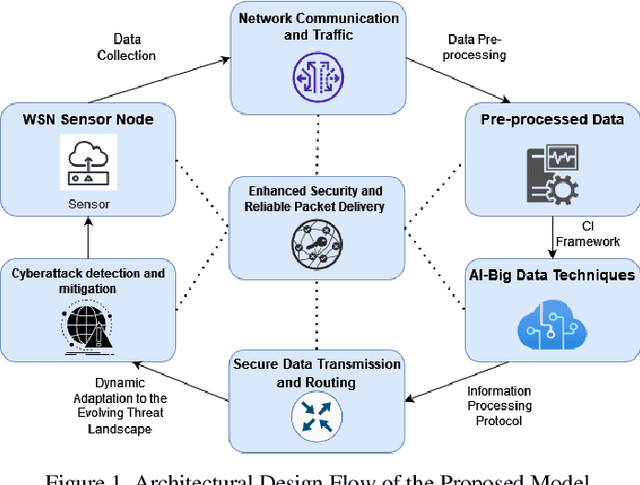
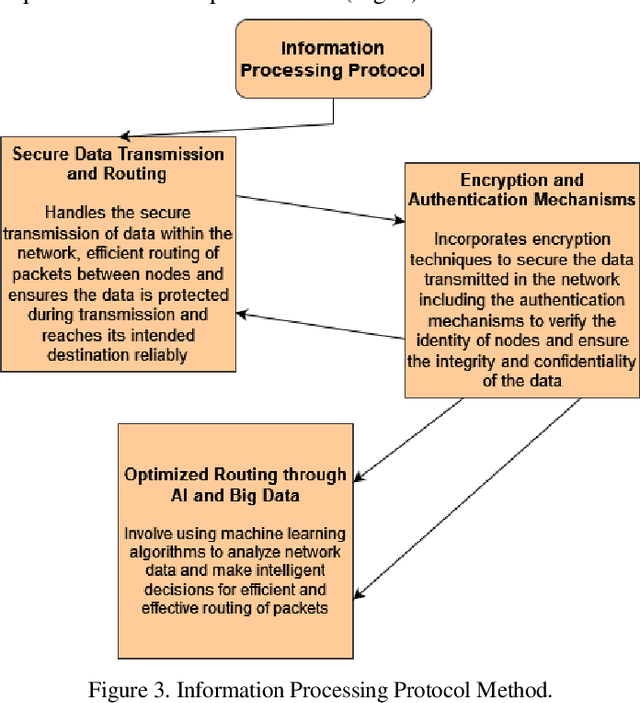
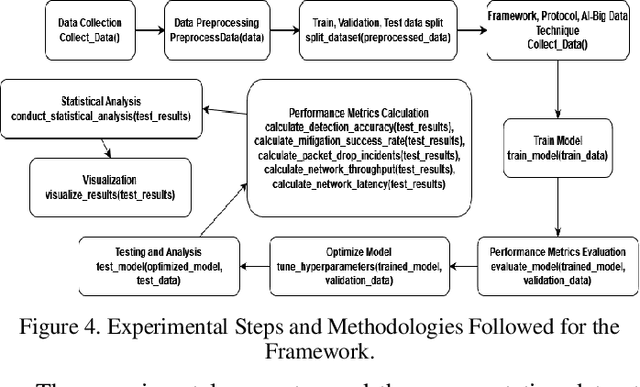
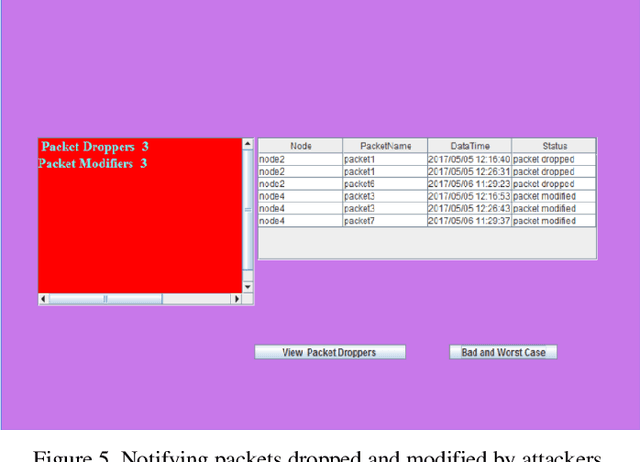
As the reliance on wireless sensor networks (WSNs) rises in numerous sectors, cyberattack prevention and data transmission integrity become essential problems. This study provides a complete framework to handle these difficulties by integrating a cognitive intelligence (CI) framework, an information processing protocol, and sophisticated artificial intelligence (AI) and big data analytics approaches. The CI architecture is intended to improve WSN security by dynamically reacting to an evolving threat scenario. It employs artificial intelligence algorithms to continuously monitor and analyze network behavior, identifying and mitigating any intrusions in real time. Anomaly detection algorithms are also included in the framework to identify packet drop instances caused by attacks or network congestion. To support the CI architecture, an information processing protocol focusing on efficient and secure data transfer within the WSN is introduced. To protect data integrity and prevent unwanted access, this protocol includes encryption and authentication techniques. Furthermore, it enhances the routing process with the use of AI and big data approaches, providing reliable and timely packet delivery. Extensive simulations and tests are carried out to assess the efficiency of the suggested framework. The findings show that it is capable of detecting and preventing several forms of assaults, including as denial-of-service (DoS) attacks, node compromise, and data tampering. Furthermore, the framework is highly resilient to packet drop occurrences, which improves the WSN's overall reliability and performance
Battery Capacity Knee Identification Using Unsupervised Time Series Segmentation
Apr 23, 2023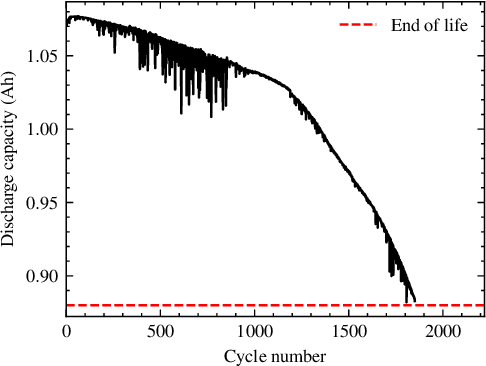
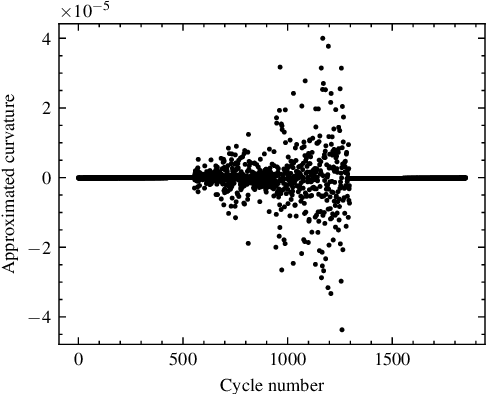
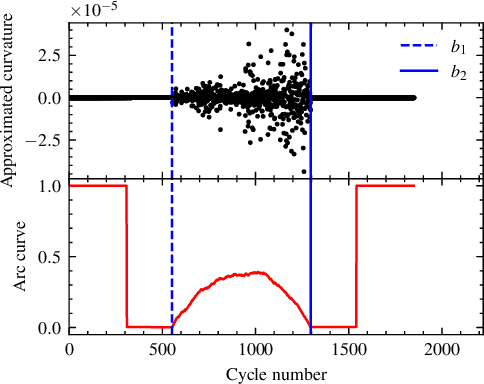
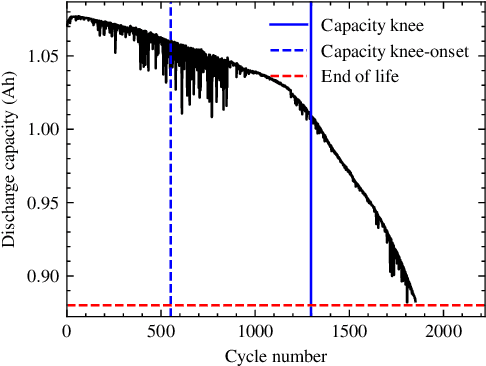
Capacity knees have been observed in experimental tests of commercial lithium-ion cells of various chemistry types under different operating conditions. Their occurrence can have a significant impact on safety and profitability in battery applications. To address concerns arising from possible knee occurrence in battery applications, this work proposes an algorithm to identify capacity knees as well as their onset from capacity fade curves. The proposed capacity knee identification algorithm is validated on both synthetic degradation data and experimental degradation data of two different battery chemistries, and is also benchmarked to the state-of-the-art knee identification algorithm in the literature. The results demonstrate that our proposed capacity knee identification algorithm could successfully identify capacity knees when the state-of-the-art knee identification algorithm failed. The results can contribute to a better understanding of capacity knees and the proposed capacity knee identification algorithm can be used to, for example, systematically evaluate the knee prediction performance of both model-based methods, and data-driven methods and facilitate better classification of retired automotive batteries from safety and profitability perspectives.
InterviewBot: Real-Time End-to-End Dialogue System to Interview Students for College Admission
Mar 27, 2023
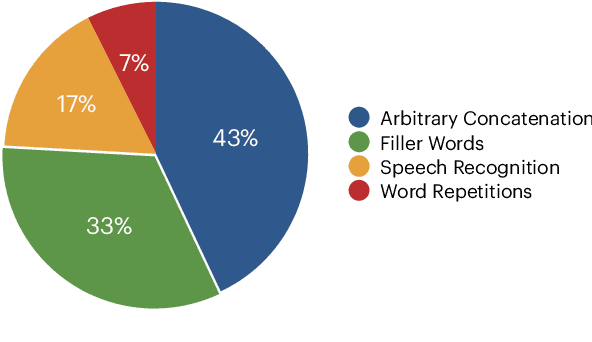
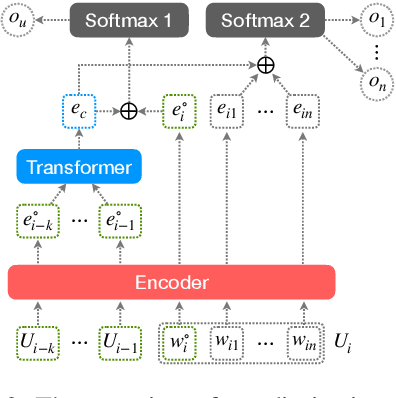
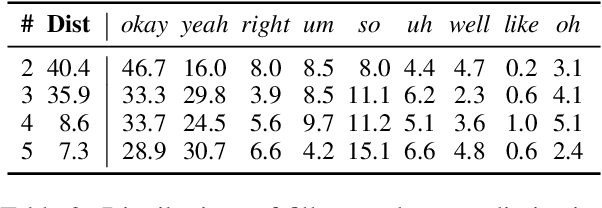
We present the InterviewBot that dynamically integrates conversation history and customized topics into a coherent embedding space to conduct 10 mins hybrid-domain (open and closed) conversations with foreign students applying to U.S. colleges for assessing their academic and cultural readiness. To build a neural-based end-to-end dialogue model, 7,361 audio recordings of human-to-human interviews are automatically transcribed, where 440 are manually corrected for finetuning and evaluation. To overcome the input/output size limit of a transformer-based encoder-decoder model, two new methods are proposed, context attention and topic storing, allowing the model to make relevant and consistent interactions. Our final model is tested both statistically by comparing its responses to the interview data and dynamically by inviting professional interviewers and various students to interact with it in real-time, finding it highly satisfactory in fluency and context awareness.
Document-Level Multi-Event Extraction with Event Proxy Nodes and Hausdorff Distance Minimization
May 30, 2023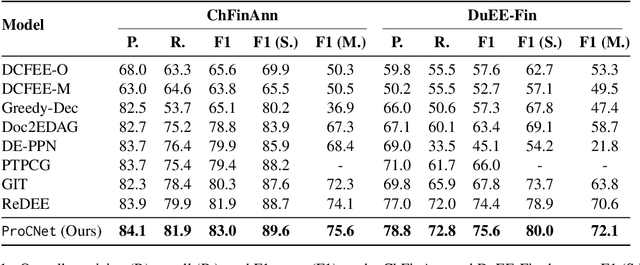
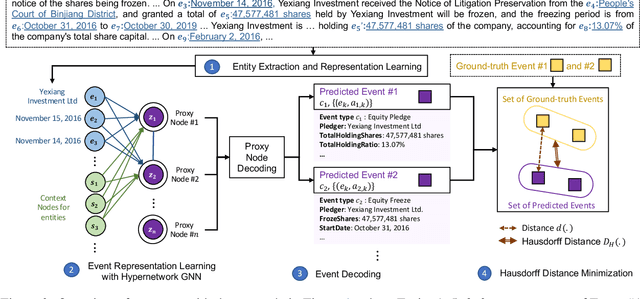
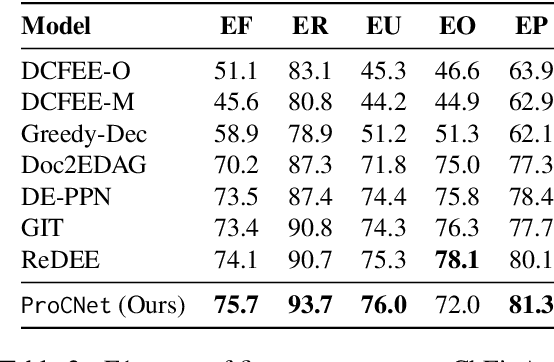
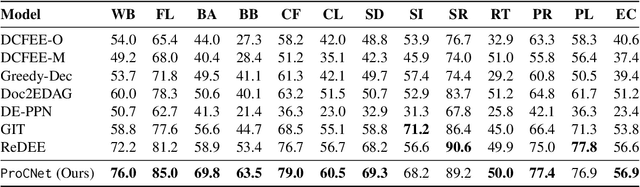
Document-level multi-event extraction aims to extract the structural information from a given document automatically. Most recent approaches usually involve two steps: (1) modeling entity interactions; (2) decoding entity interactions into events. However, such approaches ignore a global view of inter-dependency of multiple events. Moreover, an event is decoded by iteratively merging its related entities as arguments, which might suffer from error propagation and is computationally inefficient. In this paper, we propose an alternative approach for document-level multi-event extraction with event proxy nodes and Hausdorff distance minimization. The event proxy nodes, representing pseudo-events, are able to build connections with other event proxy nodes, essentially capturing global information. The Hausdorff distance makes it possible to compare the similarity between the set of predicted events and the set of ground-truth events. By directly minimizing Hausdorff distance, the model is trained towards the global optimum directly, which improves performance and reduces training time. Experimental results show that our model outperforms previous state-of-the-art method in F1-score on two datasets with only a fraction of training time.