 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Tilt Undersampling Optimization during Electron Tomography of Beam Sensitive Samples using Golden Ratio Scanning and RECAST3D
Apr 01, 2023
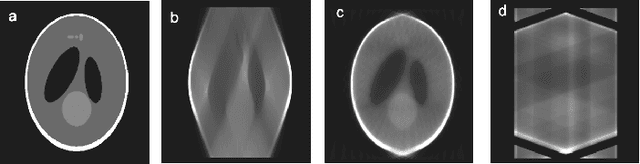
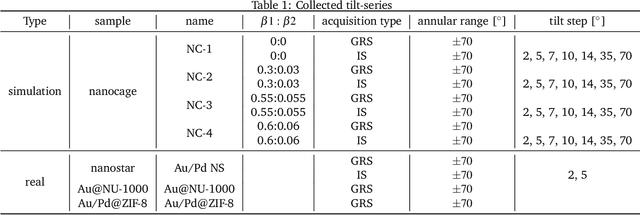
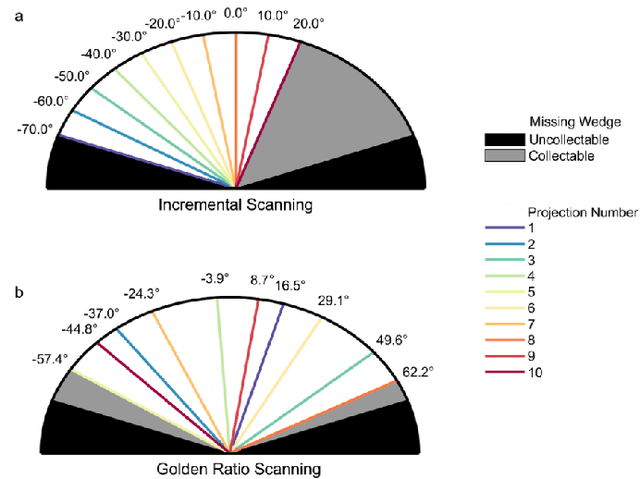
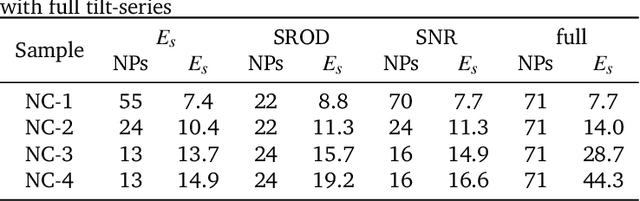
Electron tomography is a widely used technique for 3D structural analysis of nanomaterials, but it can cause damage to samples due to high electron doses and long exposure times. To minimize such damage, researchers often reduce beam exposure by acquiring fewer projections through tilt undersampling. However, this approach can also introduce reconstruction artifacts due to insufficient sampling. Therefore, it is important to determine the optimal number of projections that minimizes both beam exposure and undersampling artifacts for accurate reconstructions of beam-sensitive samples. Current methods for determining this optimal number of projections involve acquiring and post-processing multiple reconstructions with different numbers of projections, which can be time-consuming and requires multiple samples due to sample damage. To improve this process, we propose a protocol that combines golden ratio scanning and quasi-3D reconstruction to estimate the optimal number of projections in real-time during a single acquisition. This protocol was validated using simulated and realistic nanoparticles, and was successfully applied to reconstruct two beam-sensitive metal-organic framework complexes.
* accepted in Nanoscale journal. 17 pages, 9 figures, 9 supplementary figures
Score-based Data Assimilation
Jun 18, 2023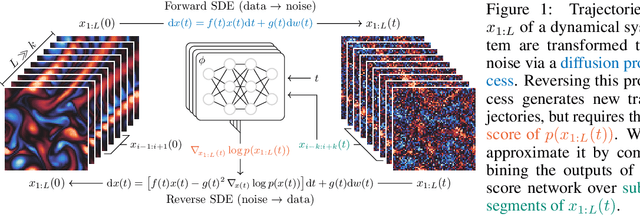
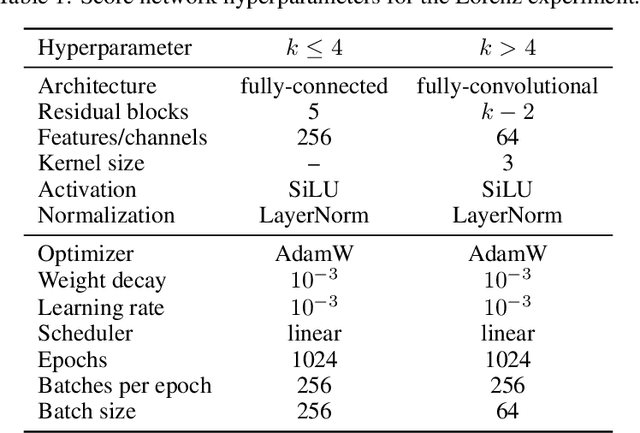
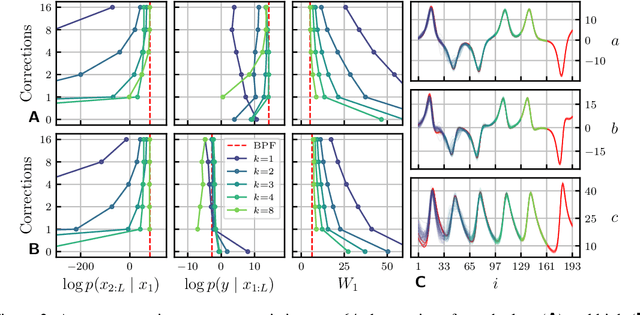
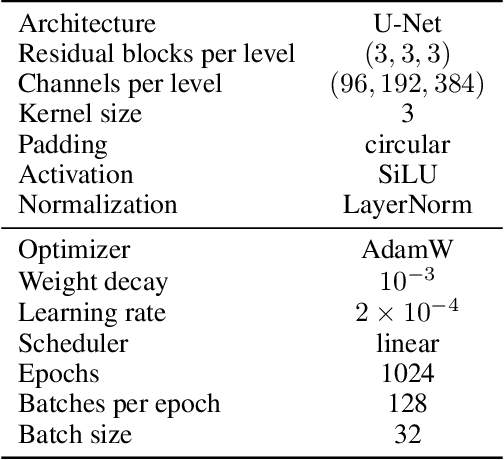
Data assimilation, in its most comprehensive form, addresses the Bayesian inverse problem of identifying plausible state trajectories that explain noisy or incomplete observations of stochastic dynamical systems. Various approaches have been proposed to solve this problem, including particle-based and variational methods. However, most algorithms depend on the transition dynamics for inference, which becomes intractable for long time horizons or for high-dimensional systems with complex dynamics, such as oceans or atmospheres. In this work, we introduce score-based data assimilation for trajectory inference. We learn a score-based generative model of state trajectories based on the key insight that the score of an arbitrarily long trajectory can be decomposed into a series of scores over short segments. After training, inference is carried out using the score model, in a non-autoregressive manner by generating all states simultaneously. Quite distinctively, we decouple the observation model from the training procedure and use it only at inference to guide the generative process, which enables a wide range of zero-shot observation scenarios. We present theoretical and empirical evidence supporting the effectiveness of our method.
Instance-Optimal Cluster Recovery in the Labeled Stochastic Block Model
Jun 18, 2023We consider the problem of recovering hidden communities in the Labeled Stochastic Block Model (LSBM) with a finite number of clusters, where cluster sizes grow linearly with the total number $n$ of items. In the LSBM, a label is (independently) observed for each pair of items. Our objective is to devise an efficient algorithm that recovers clusters using the observed labels. To this end, we revisit instance-specific lower bounds on the expected number of misclassified items satisfied by any clustering algorithm. We present Instance-Adaptive Clustering (IAC), the first algorithm whose performance matches these lower bounds both in expectation and with high probability. IAC consists of a one-time spectral clustering algorithm followed by an iterative likelihood-based cluster assignment improvement. This approach is based on the instance-specific lower bound and does not require any model parameters, including the number of clusters. By performing the spectral clustering only once, IAC maintains an overall computational complexity of $\mathcal{O}(n \text{polylog}(n))$. We illustrate the effectiveness of our approach through numerical experiments.
Knowledge Distillation for Efficient Audio-Visual Video Captioning
Jun 16, 2023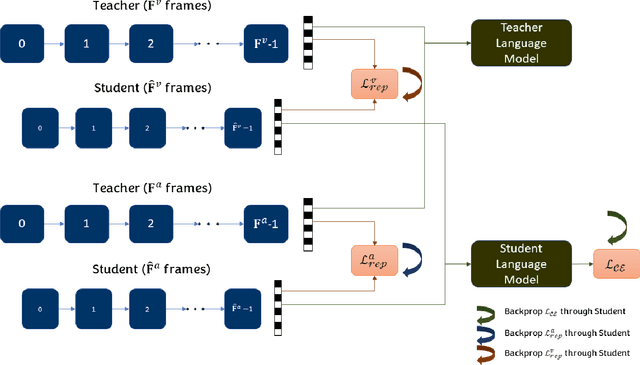
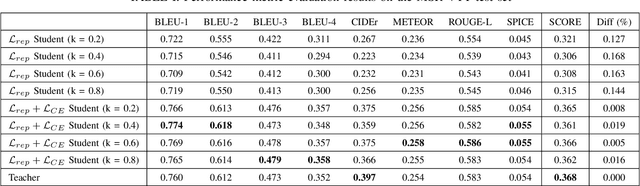
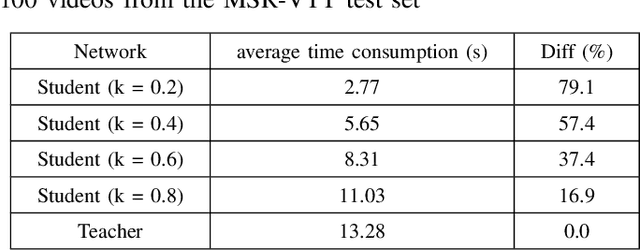
Automatically describing audio-visual content with texts, namely video captioning, has received significant attention due to its potential applications across diverse fields. Deep neural networks are the dominant methods, offering state-of-the-art performance. However, these methods are often undeployable in low-power devices like smartphones due to the large size of the model parameters. In this paper, we propose to exploit simple pooling front-end and down-sampling algorithms with knowledge distillation for audio and visual attributes using a reduced number of audio-visual frames. With the help of knowledge distillation from the teacher model, our proposed method greatly reduces the redundant information in audio-visual streams without losing critical contexts for caption generation. Extensive experimental evaluations on the MSR-VTT dataset demonstrate that our proposed approach significantly reduces the inference time by about 80% with a small sacrifice (less than 0.02%) in captioning accuracy.
Conservative Prediction via Data-Driven Confidence Minimization
Jun 08, 2023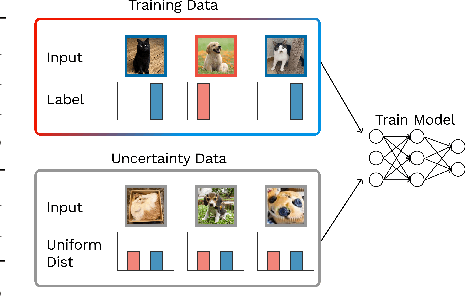
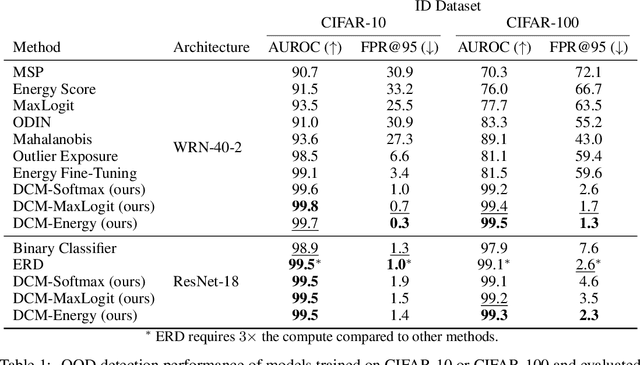
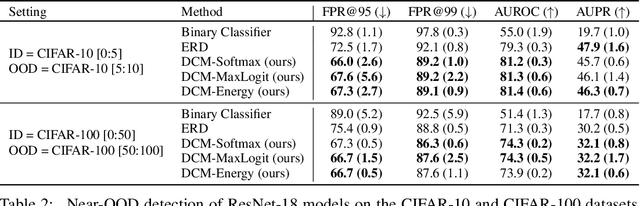
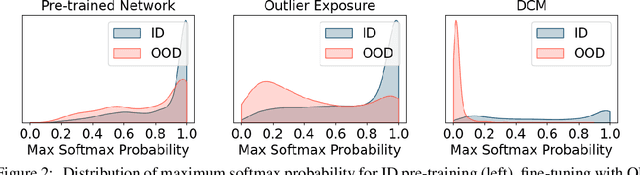
Errors of machine learning models are costly, especially in safety-critical domains such as healthcare, where such mistakes can prevent the deployment of machine learning altogether. In these settings, conservative models -- models which can defer to human judgment when they are likely to make an error -- may offer a solution. However, detecting unusual or difficult examples is notably challenging, as it is impossible to anticipate all potential inputs at test time. To address this issue, prior work has proposed to minimize the model's confidence on an auxiliary pseudo-OOD dataset. We theoretically analyze the effect of confidence minimization and show that the choice of auxiliary dataset is critical. Specifically, if the auxiliary dataset includes samples from the OOD region of interest, confidence minimization provably separates ID and OOD inputs by predictive confidence. Taking inspiration from this result, we present data-driven confidence minimization (DCM), which minimizes confidence on an uncertainty dataset containing examples that the model is likely to misclassify at test time. Our experiments show that DCM consistently outperforms state-of-the-art OOD detection methods on 8 ID-OOD dataset pairs, reducing FPR (at TPR 95%) by 6.3% and 58.1% on CIFAR-10 and CIFAR-100, and outperforms existing selective classification approaches on 4 datasets in conditions of distribution shift.
Spain on Fire: A novel wildfire risk assessment model based on image satellite processing and atmospheric information
Jun 08, 2023
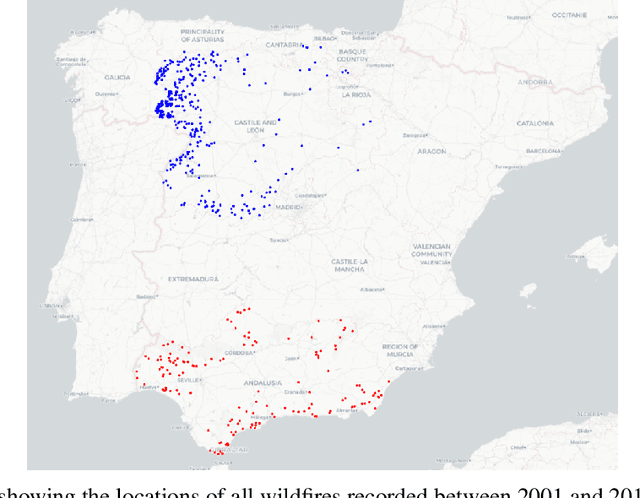
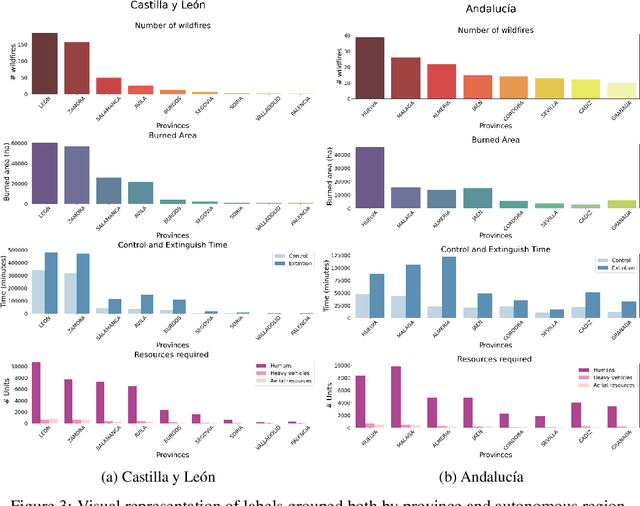
Each year, wildfires destroy larger areas of Spain, threatening numerous ecosystems. Humans cause 90% of them (negligence or provoked) and the behaviour of individuals is unpredictable. However, atmospheric and environmental variables affect the spread of wildfires, and they can be analysed by using deep learning. In order to mitigate the damage of these events we proposed the novel Wildfire Assessment Model (WAM). Our aim is to anticipate the economic and ecological impact of a wildfire, assisting managers resource allocation and decision making for dangerous regions in Spain, Castilla y Le\'on and Andaluc\'ia. The WAM uses a residual-style convolutional network architecture to perform regression over atmospheric variables and the greenness index, computing necessary resources, the control and extinction time, and the expected burnt surface area. It is first pre-trained with self-supervision over 100,000 examples of unlabelled data with a masked patch prediction objective and fine-tuned using 311 samples of wildfires. The pretraining allows the model to understand situations, outclassing baselines with a 1,4%, 3,7% and 9% improvement estimating human, heavy and aerial resources; 21% and 10,2% in expected extinction and control time; and 18,8% in expected burnt area. Using the WAM we provide an example assessment map of Castilla y Le\'on, visualizing the expected resources over an entire region.
TinyAD: Memory-efficient anomaly detection for time series data in Industrial IoT
Mar 07, 2023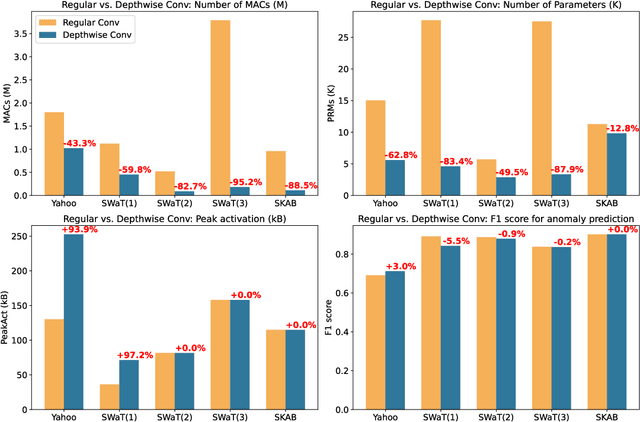
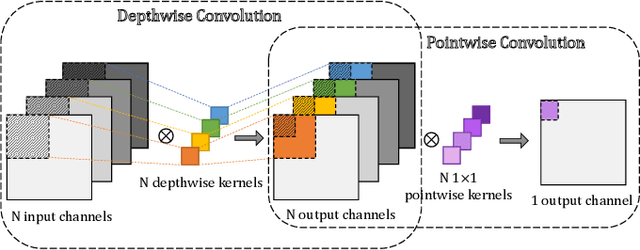
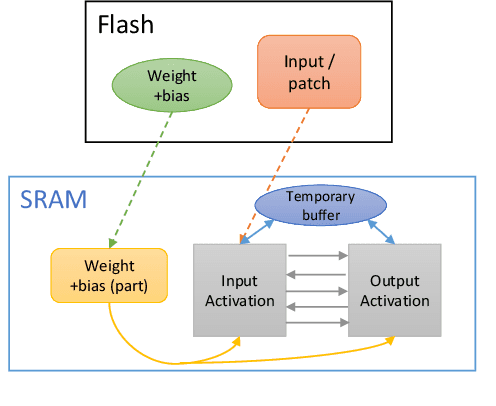
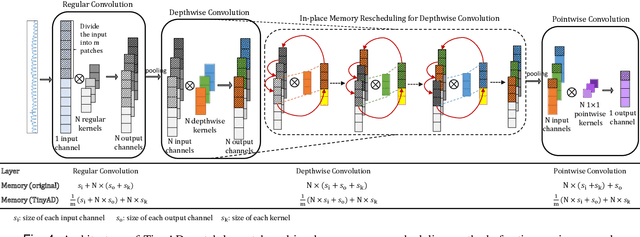
Monitoring and detecting abnormal events in cyber-physical systems is crucial to industrial production. With the prevalent deployment of the Industrial Internet of Things (IIoT), an enormous amount of time series data is collected to facilitate machine learning models for anomaly detection, and it is of the utmost importance to directly deploy the trained models on the IIoT devices. However, it is most challenging to deploy complex deep learning models such as Convolutional Neural Networks (CNNs) on these memory-constrained IIoT devices embedded with microcontrollers (MCUs). To alleviate the memory constraints of MCUs, we propose a novel framework named Tiny Anomaly Detection (TinyAD) to efficiently facilitate onboard inference of CNNs for real-time anomaly detection. First, we conduct a comprehensive analysis of depthwise separable CNNs and regular CNNs for anomaly detection and find that the depthwise separable convolution operation can reduce the model size by 50-90% compared with the traditional CNNs. Then, to reduce the peak memory consumption of CNNs, we explore two complementary strategies, in-place, and patch-by-patch memory rescheduling, and integrate them into a unified framework. The in-place method decreases the peak memory of the depthwise convolution by sparing a temporary buffer to transfer the activation results, while the patch-by-patch method further reduces the peak memory of layer-wise execution by slicing the input data into corresponding receptive fields and executing in order. Furthermore, by adjusting the dimension of convolution filters, these strategies apply to both univariate time series and multidomain time series features. Extensive experiments on real-world industrial datasets show that our framework can reduce peak memory consumption by 2-5x with negligible computation overhead.
Liver Segmentation in Time-resolved C-arm CT Volumes Reconstructed from Dynamic Perfusion Scans using Time Separation Technique
Feb 09, 2023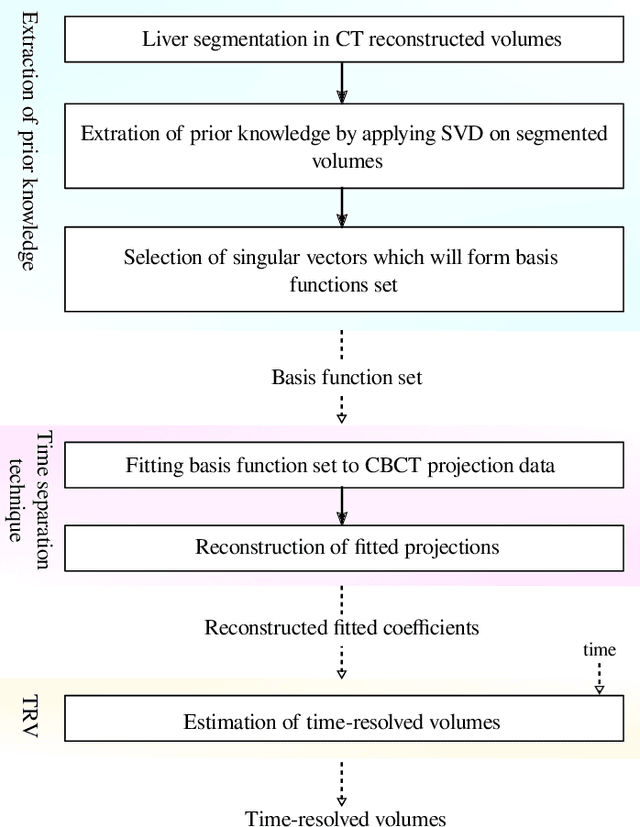


Perfusion imaging is a valuable tool for diagnosing and treatment planning for liver tumours. The time separation technique (TST) has been successfully used for modelling C-arm cone-beam computed tomography (CBCT) perfusion data. The reconstruction can be accompanied by the segmentation of the liver - for better visualisation and for generating comprehensive perfusion maps. Recently introduced Turbolift learning has been seen to perform well while working with TST reconstructions, but has not been explored for the time-resolved volumes (TRV) estimated out of TST reconstructions. The segmentation of the TRVs can be useful for tracking the movement of the liver over time. This research explores this possibility by training the multi-scale attention UNet of Turbolift learning at its third stage on the TRVs and shows the robustness of Turbolift learning since it can even work efficiently with the TRVs, resulting in a Dice score of 0.864$\pm$0.004.
Learning time-scales in two-layers neural networks
Mar 16, 2023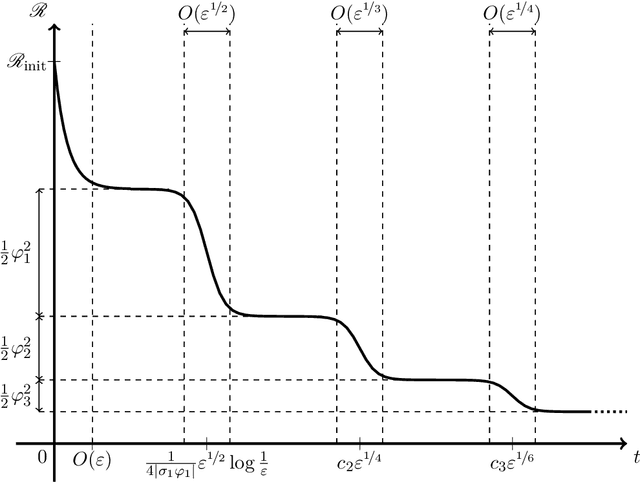
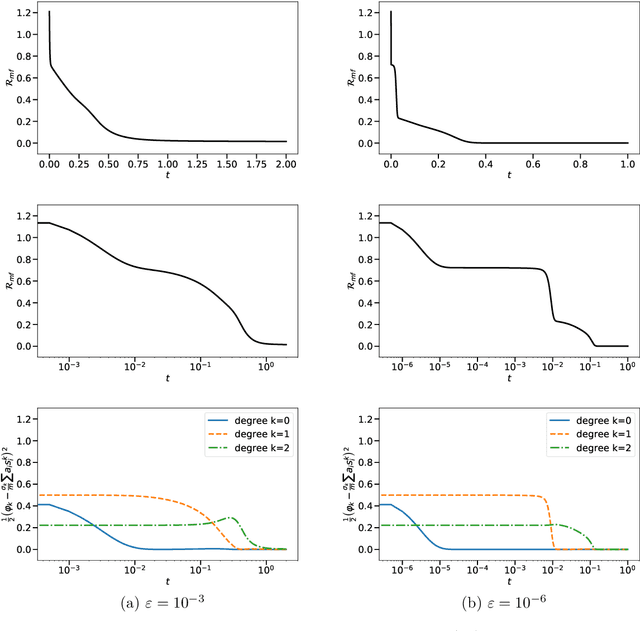

Gradient-based learning in multi-layer neural networks displays a number of striking features. In particular, the decrease rate of empirical risk is non-monotone even after averaging over large batches. Long plateaus in which one observes barely any progress alternate with intervals of rapid decrease. These successive phases of learning often take place on very different time scales. Finally, models learnt in an early phase are typically `simpler' or `easier to learn' although in a way that is difficult to formalize. Although theoretical explanations of these phenomena have been put forward, each of them captures at best certain specific regimes. In this paper, we study the gradient flow dynamics of a wide two-layer neural network in high-dimension, when data are distributed according to a single-index model (i.e., the target function depends on a one-dimensional projection of the covariates). Based on a mixture of new rigorous results, non-rigorous mathematical derivations, and numerical simulations, we propose a scenario for the learning dynamics in this setting. In particular, the proposed evolution exhibits separation of timescales and intermittency. These behaviors arise naturally because the population gradient flow can be recast as a singularly perturbed dynamical system.
iPLAN: Intent-Aware Planning in Heterogeneous Traffic via Distributed Multi-Agent Reinforcement Learning
Jun 09, 2023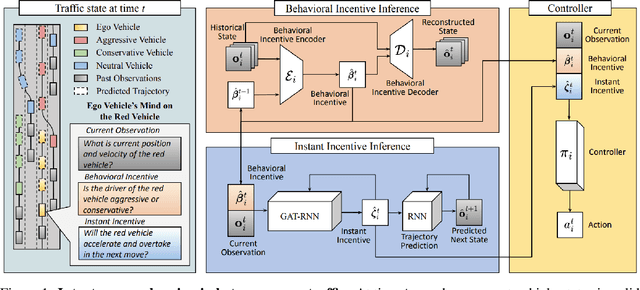
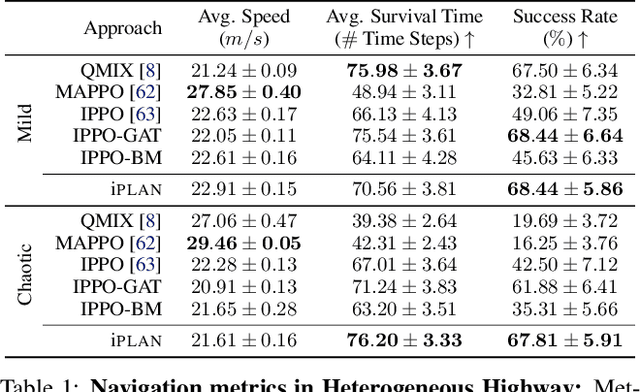
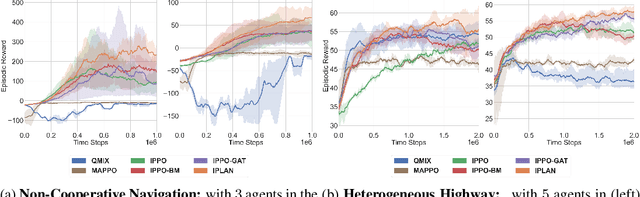
Navigating safely and efficiently in dense and heterogeneous traffic scenarios is challenging for autonomous vehicles (AVs) due to their inability to infer the behaviors or intentions of nearby drivers. In this work, we propose a distributed multi-agent reinforcement learning (MARL) algorithm with trajectory and intent prediction in dense and heterogeneous traffic scenarios. Our approach for intent-aware planning, iPLAN, allows agents to infer nearby drivers' intents solely from their local observations. We model two distinct incentives for agents' strategies: Behavioral incentives for agents' long-term planning based on their driving behavior or personality; Instant incentives for agents' short-term planning for collision avoidance based on the current traffic state. We design a two-stream inference module that allows agents to infer their opponents' incentives and incorporate their inferred information into decision-making. We perform experiments on two simulation environments, Non-Cooperative Navigation and Heterogeneous Highway. In Heterogeneous Highway, results show that, compared with centralized MARL baselines such as QMIX and MAPPO, our method yields a 4.0% and 35.7% higher episodic reward in mild and chaotic traffic, with 48.1% higher success rate and 80.6% longer survival time in chaotic traffic. We also compare with a decentralized baseline IPPO and demonstrate a higher episodic reward of 9.2% and 10.3% in mild traffic and chaotic traffic, 25.3% higher success rate, and 13.7% longer survival time.