 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BackpropTools: A Fast, Portable Deep Reinforcement Learning Library for Continuous Control
Jun 06, 2023
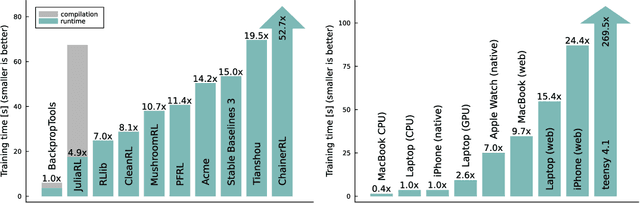

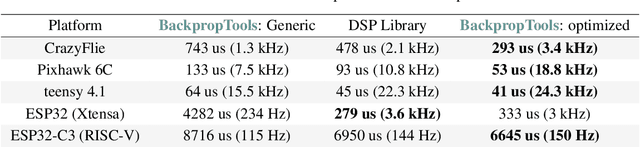
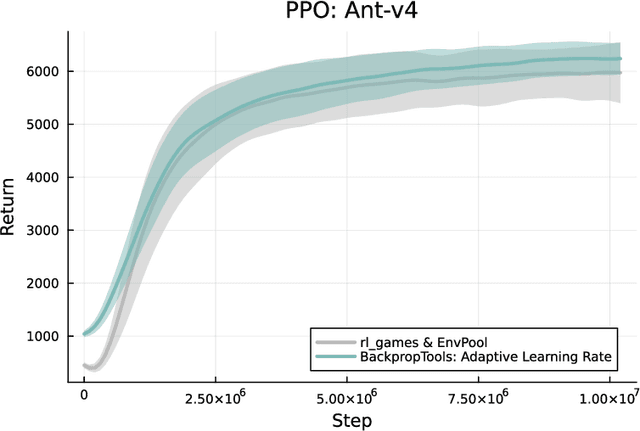
Deep Reinforcement Learning (RL) has been demonstrated to yield capable agents and control policies in several domains but is commonly plagued by prohibitively long training times. Additionally, in the case of continuous control problems, the applicability of learned policies on real-world embedded devices is limited due to the lack of real-time guarantees and portability of existing deep learning libraries. To address these challenges, we present BackpropTools, a dependency-free, header-only, pure C++ library for deep supervised and reinforcement learning. Leveraging the template meta-programming capabilities of recent C++ standards, we provide composable components that can be tightly integrated by the compiler. Its novel architecture allows BackpropTools to be used seamlessly on a heterogeneous set of platforms, from HPC clusters over workstations and laptops to smartphones, smartwatches, and microcontrollers. Specifically, due to the tight integration of the RL algorithms with simulation environments, BackpropTools can solve popular RL problems like the Pendulum-v1 swing-up about 7 to 15 times faster in terms of wall-clock training time compared to other popular RL frameworks when using TD3. We also provide a low-overhead and parallelized interface to the MuJoCo simulator, showing that our PPO implementation achieves state of the art returns in the Ant-v4 environment while achieving a 25 to 30 percent faster wall-clock training time. Finally, we also benchmark the policy inference on a diverse set of microcontrollers and show that in most cases our optimized inference implementation is much faster than even the manufacturer's DSP libraries. To the best of our knowledge, BackpropTools enables the first-ever demonstration of training a deep RL algorithm directly on a microcontroller, giving rise to the field of Tiny Reinforcement Learning (TinyRL). Project page: https://backprop.tools
Forgotten Knowledge: Examining the Citational Amnesia in NLP
May 29, 2023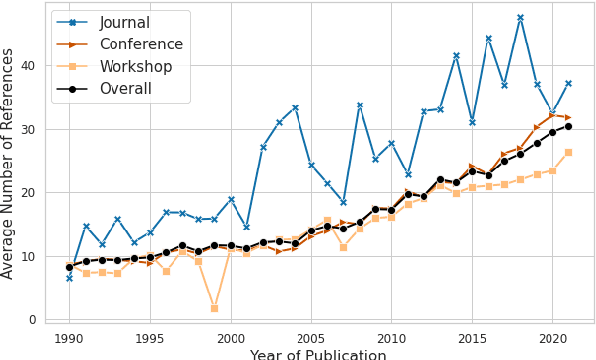
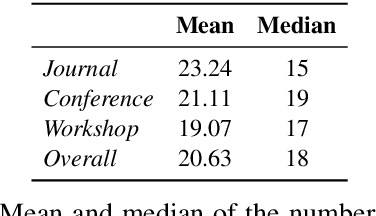
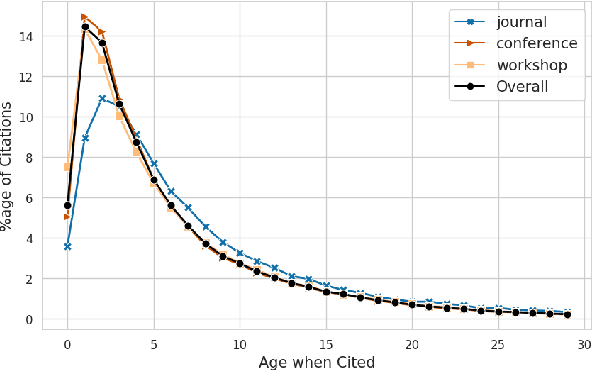
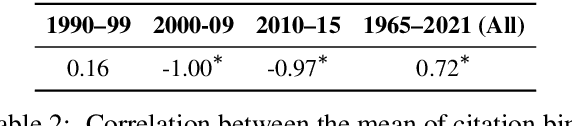
Citing papers is the primary method through which modern scientific writing discusses and builds on past work. Collectively, citing a diverse set of papers (in time and area of study) is an indicator of how widely the community is reading. Yet, there is little work looking at broad temporal patterns of citation. This work systematically and empirically examines: How far back in time do we tend to go to cite papers? How has that changed over time, and what factors correlate with this citational attention/amnesia? We chose NLP as our domain of interest and analyzed approximately 71.5K papers to show and quantify several key trends in citation. Notably, around 62% of cited papers are from the immediate five years prior to publication, whereas only about 17% are more than ten years old. Furthermore, we show that the median age and age diversity of cited papers were steadily increasing from 1990 to 2014, but since then, the trend has reversed, and current NLP papers have an all-time low temporal citation diversity. Finally, we show that unlike the 1990s, the highly cited papers in the last decade were also papers with the least citation diversity, likely contributing to the intense (and arguably harmful) recency focus. Code, data, and a demo are available on the project homepage.
Near Optimal Heteroscedastic Regression with Symbiotic Learning
Jun 25, 2023
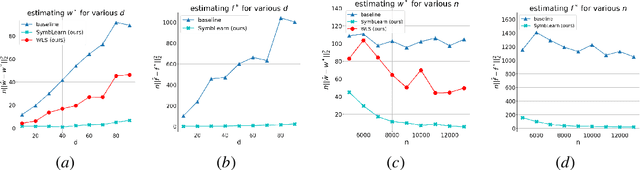
We consider the classical problem of heteroscedastic linear regression, where we are given $n$ samples $(\mathbf{x}_i, y_i) \in \mathbb{R}^d \times \mathbb{R}$ obtained from $y_i = \langle \mathbf{w}^{*}, \mathbf{x}_i \rangle + \epsilon_i \cdot \langle \mathbf{f}^{*}, \mathbf{x}_i \rangle$, where $\mathbf{x}_i \sim N(0,\mathbf{I})$, $\epsilon_i \sim N(0,1)$, and our task is to estimate $\mathbf{w}^{*}$. In addition to the classical applications of heteroscedastic models in fields such as statistics, econometrics, time series analysis etc., it is also particularly relevant in machine learning when data is collected from multiple sources of varying but apriori unknown quality, e.g., large model training. Our work shows that we can estimate $\mathbf{w}^{*}$ in squared norm up to an error of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2 \cdot \left(\frac{1}{n} + \left(\frac{d}{n}\right)^2\right)\right)$ and prove a matching lower bound (up to logarithmic factors). Our result substantially improves upon the previous best known upper bound of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2\cdot \frac{d}{n}\right)$. Our upper bound result is based on a novel analysis of a simple, classical heuristic going back to at least Davidian and Carroll (1987) and constitutes the first non-asymptotic convergence guarantee for this approach. As a byproduct, our analysis also provides improved rates of estimation for both linear regression and phase retrieval with multiplicative noise, which maybe of independent interest. The lower bound result relies on a careful application of LeCam's two point method, adapted to work with heavy tailed random variables where the relevant mutual information quantities are infinite (precluding a direct application of LeCam's method), and could also be of broader interest.
One-Shot Federated Learning for LEO Constellations that Reduces Convergence Time from Days to 90 Minutes
May 21, 2023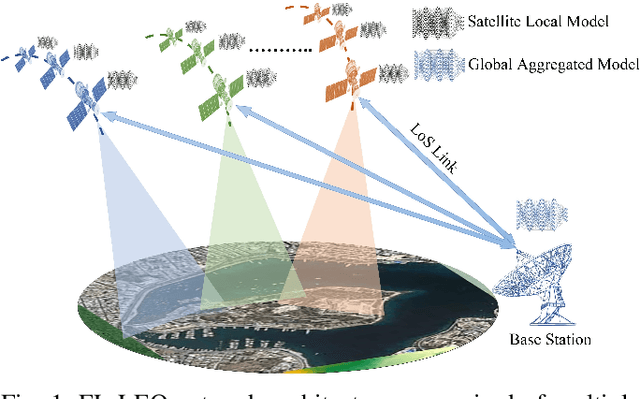
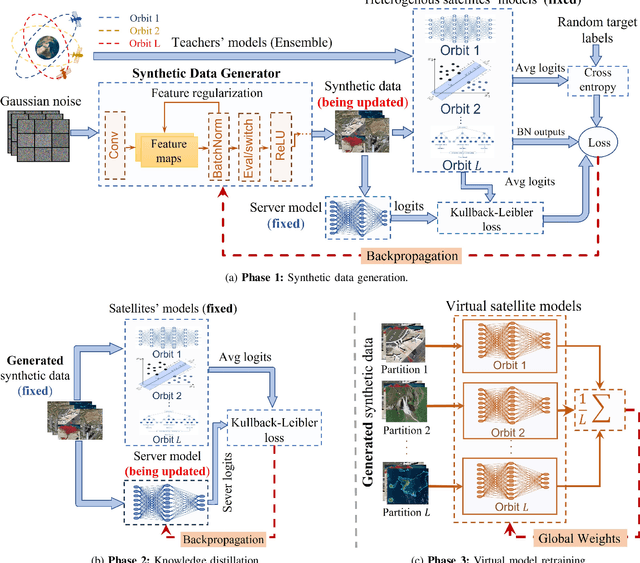
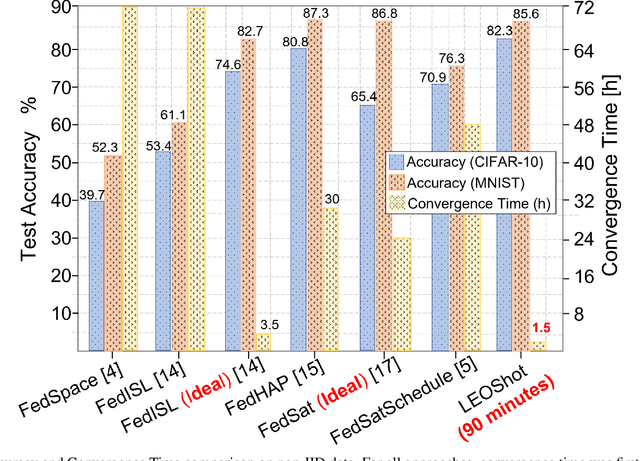

A Low Earth orbit (LEO) satellite constellation consists of a large number of small satellites traveling in space with high mobility and collecting vast amounts of mobility data such as cloud movement for weather forecast, large herds of animals migrating across geo-regions, spreading of forest fires, and aircraft tracking. Machine learning can be utilized to analyze these mobility data to address global challenges, and Federated Learning (FL) is a promising approach because it eliminates the need for transmitting raw data and hence is both bandwidth and privacy-friendly. However, FL requires many communication rounds between clients (satellites) and the parameter server (PS), leading to substantial delays of up to several days in LEO constellations. In this paper, we propose a novel one-shot FL approach for LEO satellites, called LEOShot, that needs only a single communication round to complete the entire learning process. LEOShot comprises three processes: (i) synthetic data generation, (ii) knowledge distillation, and (iii) virtual model retraining. We evaluate and benchmark LEOShot against the state of the art and the results show that it drastically expedites FL convergence by more than an order of magnitude. Also surprisingly, despite the one-shot nature, its model accuracy is on par with or even outperforms regular iterative FL schemes by a large margin
Policy Optimization for Continuous Reinforcement Learning
Jun 02, 2023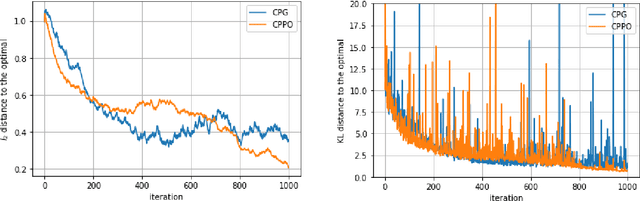
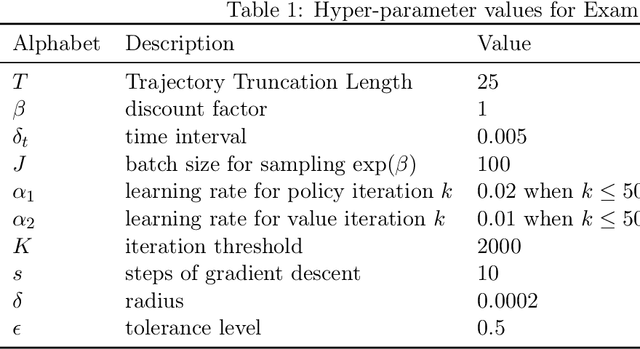
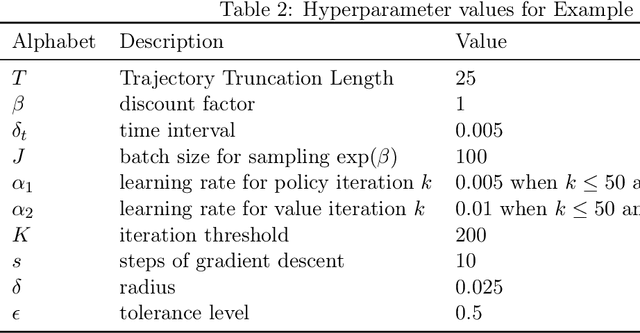
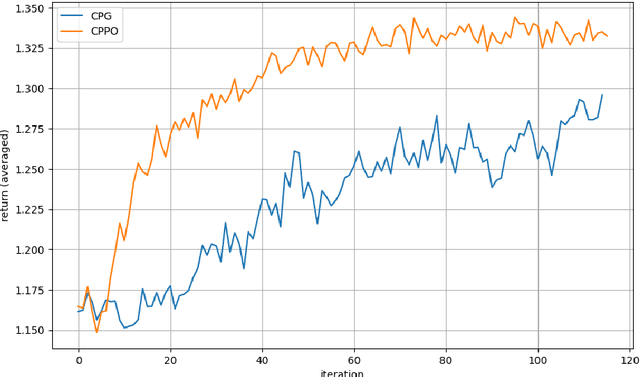
We study reinforcement learning (RL) in the setting of continuous time and space, for an infinite horizon with a discounted objective and the underlying dynamics driven by a stochastic differential equation. Built upon recent advances in the continuous approach to RL, we develop a notion of occupation time (specifically for a discounted objective), and show how it can be effectively used to derive performance-difference and local-approximation formulas. We further extend these results to illustrate their applications in the PG (policy gradient) and TRPO/PPO (trust region policy optimization/ proximal policy optimization) methods, which have been familiar and powerful tools in the discrete RL setting but under-developed in continuous RL. Through numerical experiments, we demonstrate the effectiveness and advantages of our approach.
ZeroForge: Feedforward Text-to-Shape Without 3D Supervision
Jun 14, 2023
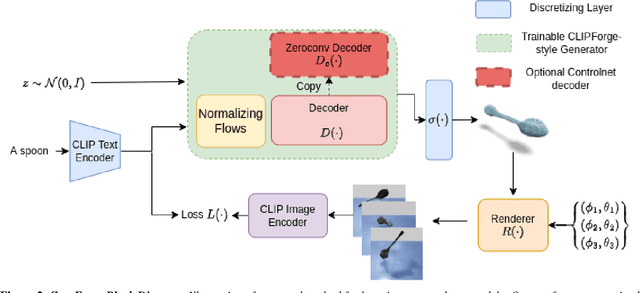

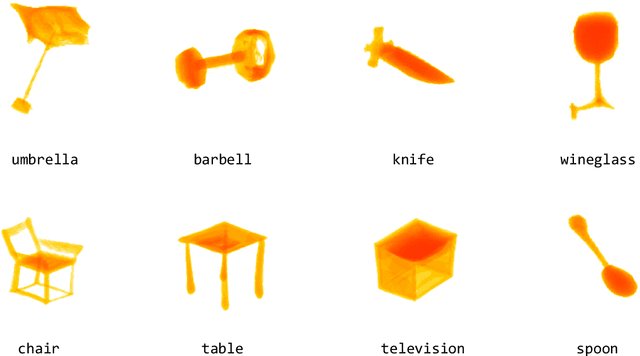
Current state-of-the-art methods for text-to-shape generation either require supervised training using a labeled dataset of pre-defined 3D shapes, or perform expensive inference-time optimization of implicit neural representations. In this work, we present ZeroForge, an approach for zero-shot text-to-shape generation that avoids both pitfalls. To achieve open-vocabulary shape generation, we require careful architectural adaptation of existing feed-forward approaches, as well as a combination of data-free CLIP-loss and contrastive losses to avoid mode collapse. Using these techniques, we are able to considerably expand the generative ability of existing feed-forward text-to-shape models such as CLIP-Forge. We support our method via extensive qualitative and quantitative evaluations
ASTRIDE: Adaptive Symbolization for Time Series Databases
Feb 08, 2023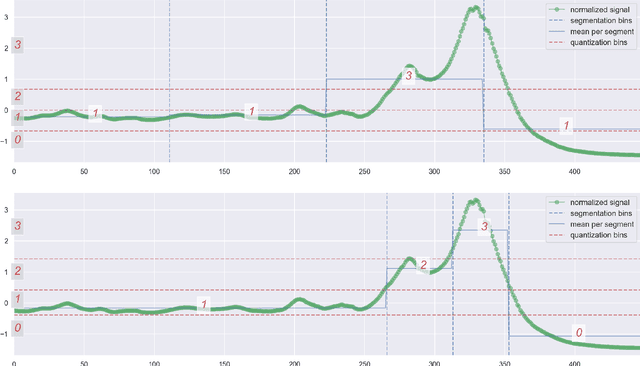
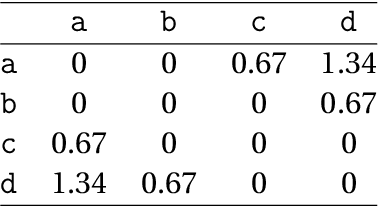
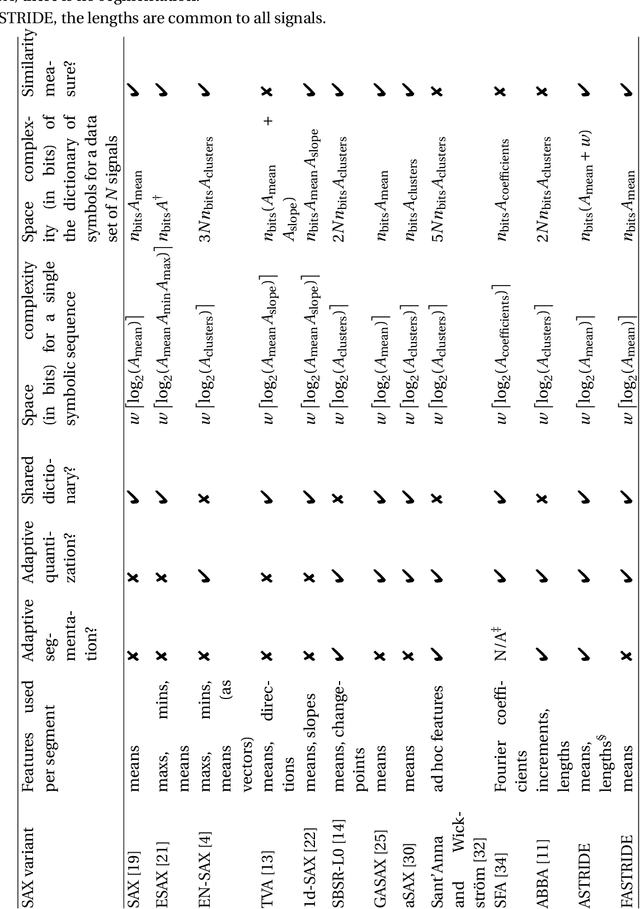
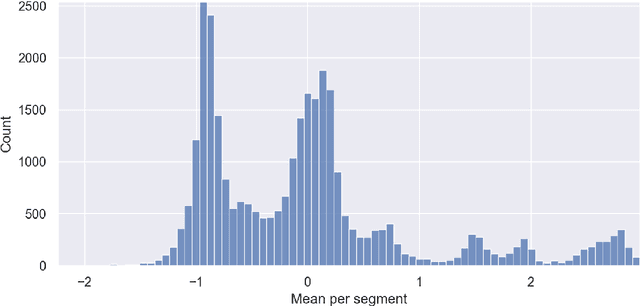
We introduce ASTRIDE (Adaptive Symbolization for Time seRIes DatabasEs), a novel symbolic representation of time series, along with its accelerated variant FASTRIDE (Fast ASTRIDE). Unlike most symbolization procedures, ASTRIDE is adaptive during both the segmentation step by performing change-point detection and the quantization step by using quantiles. Instead of proceeding signal by signal, ASTRIDE builds a dictionary of symbols that is common to all signals in a data set. We also introduce D-GED (Dynamic General Edit Distance), a novel similarity measure on symbolic representations based on the general edit distance. We demonstrate the performance of the ASTRIDE and FASTRIDE representations compared to SAX (Symbolic Aggregate approXimation), 1d-SAX, SFA (Symbolic Fourier Approximation), and ABBA (Adaptive Brownian Bridge-based Aggregation) on reconstruction and, when applicable, on classification tasks. These algorithms are evaluated on 86 univariate equal-size data sets from the UCR Time Series Classification Archive. An open source GitHub repository called astride is made available to reproduce all the experiments in Python.
Real-Time Tilt Undersampling Optimization during Electron Tomography of Beam Sensitive Samples using Golden Ratio Scanning and RECAST3D
Apr 01, 2023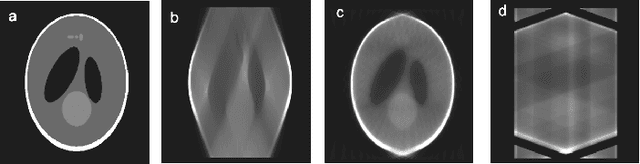
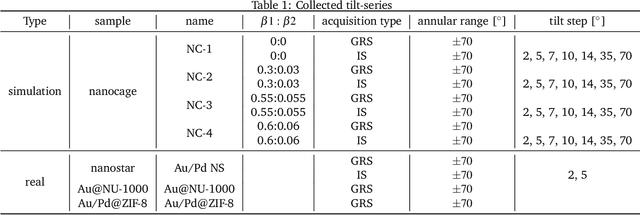
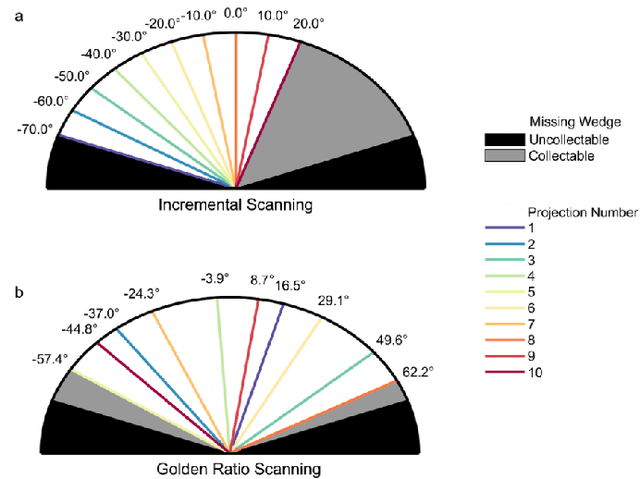
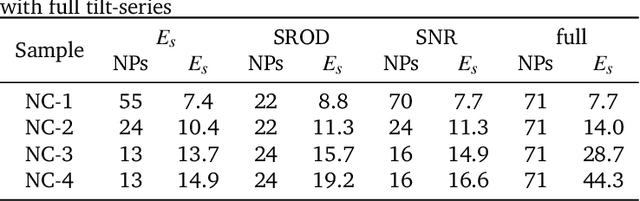
Electron tomography is a widely used technique for 3D structural analysis of nanomaterials, but it can cause damage to samples due to high electron doses and long exposure times. To minimize such damage, researchers often reduce beam exposure by acquiring fewer projections through tilt undersampling. However, this approach can also introduce reconstruction artifacts due to insufficient sampling. Therefore, it is important to determine the optimal number of projections that minimizes both beam exposure and undersampling artifacts for accurate reconstructions of beam-sensitive samples. Current methods for determining this optimal number of projections involve acquiring and post-processing multiple reconstructions with different numbers of projections, which can be time-consuming and requires multiple samples due to sample damage. To improve this process, we propose a protocol that combines golden ratio scanning and quasi-3D reconstruction to estimate the optimal number of projections in real-time during a single acquisition. This protocol was validated using simulated and realistic nanoparticles, and was successfully applied to reconstruct two beam-sensitive metal-organic framework complexes.
* accepted in Nanoscale journal. 17 pages, 9 figures, 9 supplementary figures
Unsupervised speech enhancement with deep dynamical generative speech and noise models
Jun 13, 2023
This work builds on a previous work on unsupervised speech enhancement using a dynamical variational autoencoder (DVAE) as the clean speech model and non-negative matrix factorization (NMF) as the noise model. We propose to replace the NMF noise model with a deep dynamical generative model (DDGM) depending either on the DVAE latent variables, or on the noisy observations, or on both. This DDGM can be trained in three configurations: noise-agnostic, noise-dependent and noise adaptation after noise-dependent training. Experimental results show that the proposed method achieves competitive performance compared to state-of-the-art unsupervised speech enhancement methods, while the noise-dependent training configuration yields a much more time-efficient inference process.
Decoding Brain Motor Imagery with various Machine Learning techniques
Jun 13, 2023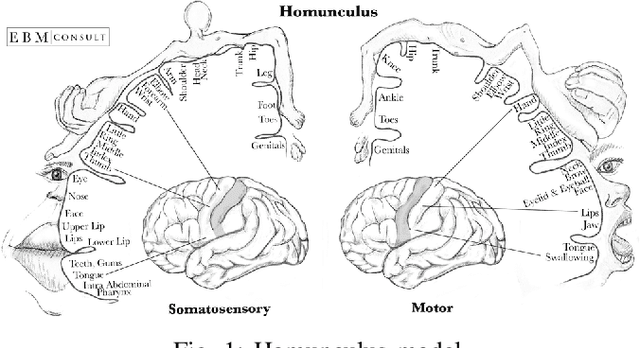
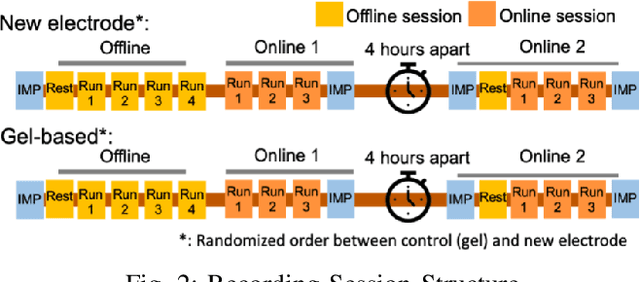
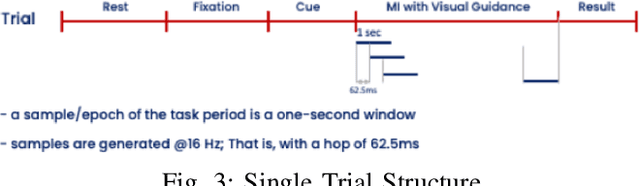
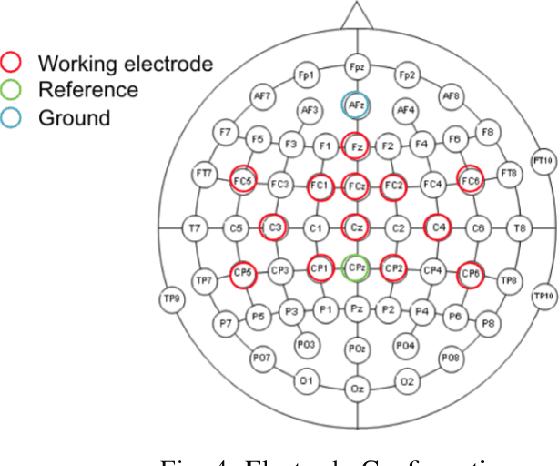
Motor imagery (MI) is a well-documented technique used by subjects in BCI (Brain Computer Interface) experiments to modulate brain activity within the motor cortex and surrounding areas of the brain. In our term project, we conducted an experiment in which the subjects were instructed to perform motor imagery that would be divided into two classes (Right and Left). Experiments were conducted with two different types of electrodes (Gel and POLiTag) and data for individual subjects was collected. In this paper, we will apply different machine learning (ML) methods to create a decoder based on offline training data that uses evidence accumulation to predict a subject's intent from their modulated brain signals in real-time.