 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Message Quantization and Parallelization for Distributed Full-graph GNN Training
Jun 02, 2023
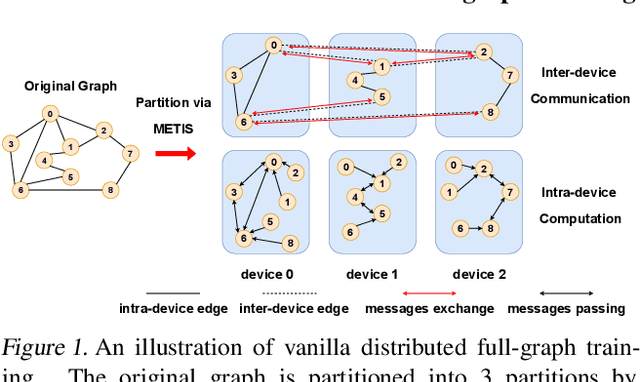
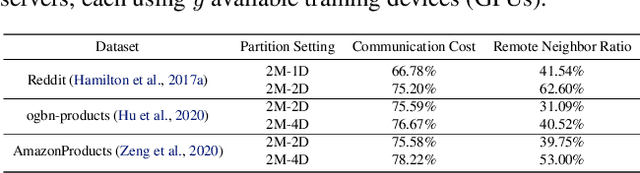
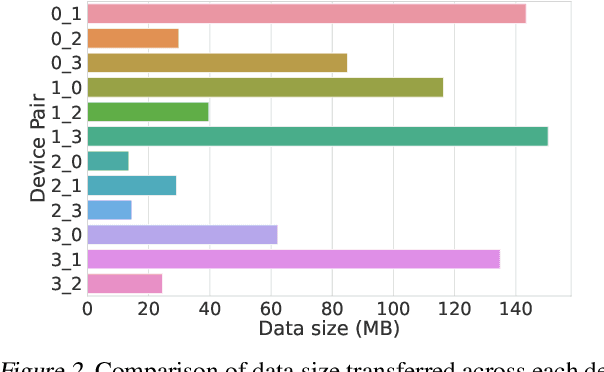
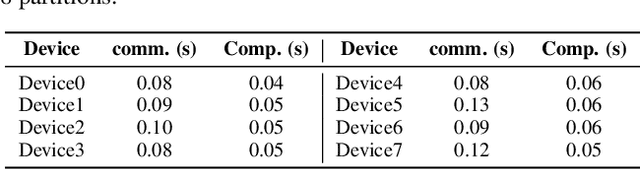
Distributed full-graph training of Graph Neural Networks (GNNs) over large graphs is bandwidth-demanding and time-consuming. Frequent exchanges of node features, embeddings and embedding gradients (all referred to as messages) across devices bring significant communication overhead for nodes with remote neighbors on other devices (marginal nodes) and unnecessary waiting time for nodes without remote neighbors (central nodes) in the training graph. This paper proposes an efficient GNN training system, AdaQP, to expedite distributed full-graph GNN training. We stochastically quantize messages transferred across devices to lower-precision integers for communication traffic reduction and advocate communication-computation parallelization between marginal nodes and central nodes. We provide theoretical analysis to prove fast training convergence (at the rate of O(T^{-1}) with T being the total number of training epochs) and design an adaptive quantization bit-width assignment scheme for each message based on the analysis, targeting a good trade-off between training convergence and efficiency. Extensive experiments on mainstream graph datasets show that AdaQP substantially improves distributed full-graph training's throughput (up to 3.01 X) with negligible accuracy drop (at most 0.30%) or even accuracy improvement (up to 0.19%) in most cases, showing significant advantages over the state-of-the-art works.
Cooperative Collision Avoidance in a Connected Vehicle Environment
Jun 02, 2023
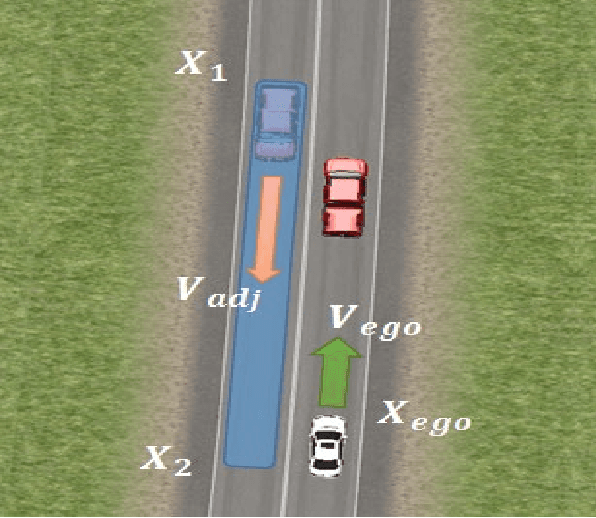

Connected vehicle (CV) technology is among the most heavily researched areas in both the academia and industry. The vehicle to vehicle (V2V), vehicle to infrastructure (V2I) and vehicle to pedestrian (V2P) communication capabilities enable critical situational awareness. In some cases, these vehicle communication safety capabilities can overcome the shortcomings of other sensor safety capabilities because of external conditions such as 'No Line of Sight' (NLOS) or very harsh weather conditions. Connected vehicles will help cities and states reduce traffic congestion, improve fuel efficiency and improve the safety of the vehicles and pedestrians. On the road, cars will be able to communicate with one another, automatically transmitting data such as speed, position, and direction, and send alerts to each other if a crash seems imminent. The main focus of this paper is the implementation of Cooperative Collision Avoidance (CCA) for connected vehicles. It leverages the Vehicle to Everything (V2X) communication technology to create a real-time implementable collision avoidance algorithm along with decision-making for a vehicle that communicates with other vehicles. Four distinct collision risk environments are simulated on a cost effective Connected Autonomous Vehicle (CAV) Hardware in the Loop (HIL) simulator to test the overall algorithm in real-time with real electronic control and communication hardware.
Are Microphone Signals Alone Sufficient for Joint Microphones and Sources Localization?
May 19, 2023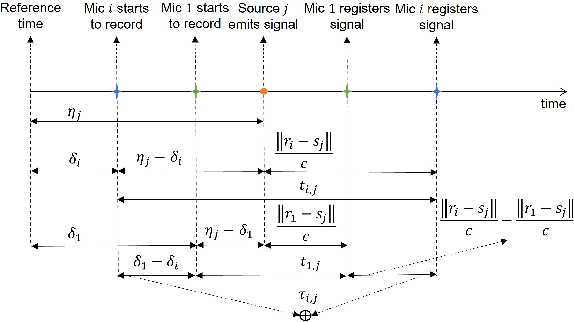
Joint microphones and sources localization can be achieved by using both time of arrival (TOA) and time difference of arrival (TDOA) measurements, even in scenarios where both microphones and sources are asynchronous due to unknown emission time of human voices or sources and unknown recording start time of independent microphones. However, TOA measurements require both microphone signals and the waveform of source signals while TDOA measurements can be obtained using microphone signals alone. In this letter, we explore the sufficiency of using only microphone signals for joint microphones and sources localization by presenting two mapping functions for both TOA and TDOA formulas. Our proposed mapping functions demonstrate that the transformations of TOA and TDOA formulas can be the same, indicating that microphone signals alone are sufficient for joint microphones and sources localization without knowledge of the waveform of source signals. We have validated our proposed mapping functions through both mathematical proof and experimental results.
ATT3D: Amortized Text-to-3D Object Synthesis
Jun 06, 2023


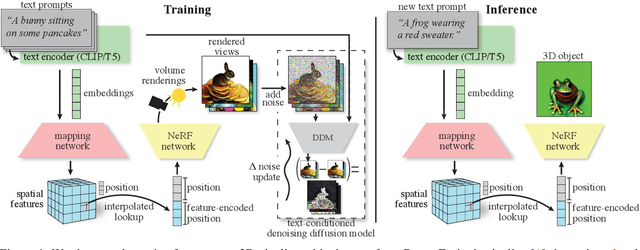
Text-to-3D modelling has seen exciting progress by combining generative text-to-image models with image-to-3D methods like Neural Radiance Fields. DreamFusion recently achieved high-quality results but requires a lengthy, per-prompt optimization to create 3D objects. To address this, we amortize optimization over text prompts by training on many prompts simultaneously with a unified model, instead of separately. With this, we share computation across a prompt set, training in less time than per-prompt optimization. Our framework - Amortized text-to-3D (ATT3D) - enables knowledge-sharing between prompts to generalize to unseen setups and smooth interpolations between text for novel assets and simple animations.
Fast and Accurate Dual-Way Streaming PARAFAC2 for Irregular Tensors -- Algorithm and Application
May 28, 2023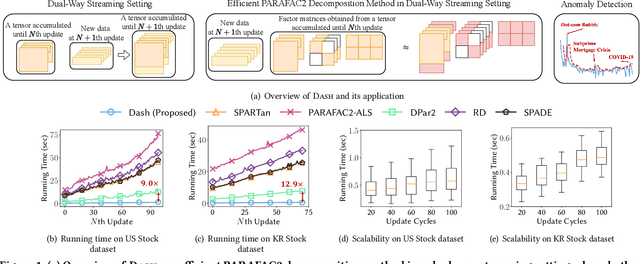
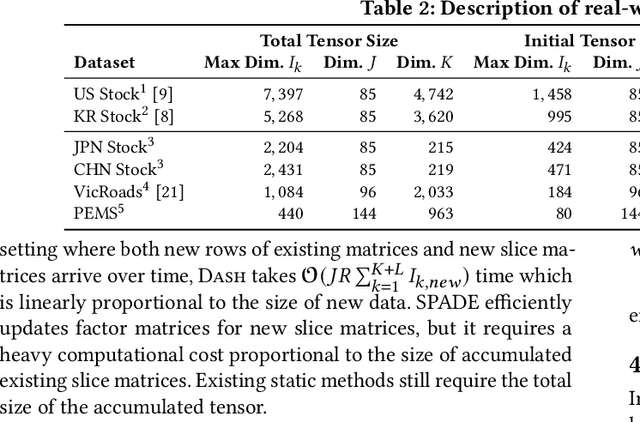
How can we efficiently and accurately analyze an irregular tensor in a dual-way streaming setting where the sizes of two dimensions of the tensor increase over time? What types of anomalies are there in the dual-way streaming setting? An irregular tensor is a collection of matrices whose column lengths are the same while their row lengths are different. In a dual-way streaming setting, both new rows of existing matrices and new matrices arrive over time. PARAFAC2 decomposition is a crucial tool for analyzing irregular tensors. Although real-time analysis is necessary in the dual-way streaming, static PARAFAC2 decomposition methods fail to efficiently work in this setting since they perform PARAFAC2 decomposition for accumulated tensors whenever new data arrive. Existing streaming PARAFAC2 decomposition methods work in a limited setting and fail to handle new rows of matrices efficiently. In this paper, we propose Dash, an efficient and accurate PARAFAC2 decomposition method working in the dual-way streaming setting. When new data are given, Dash efficiently performs PARAFAC2 decomposition by carefully dividing the terms related to old and new data and avoiding naive computations involved with old data. Furthermore, applying a forgetting factor makes Dash follow recent movements. Extensive experiments show that Dash achieves up to 14.0x faster speed than existing PARAFAC2 decomposition methods for newly arrived data. We also provide discoveries for detecting anomalies in real-world datasets, including Subprime Mortgage Crisis and COVID-19.
Bkd-FedGNN: A Benchmark for Classification Backdoor Attacks on Federated Graph Neural Network
Jun 17, 2023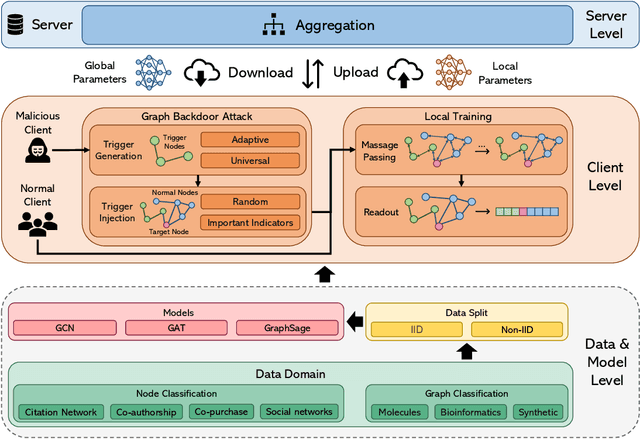

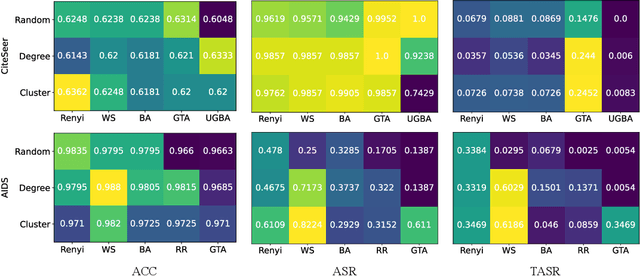
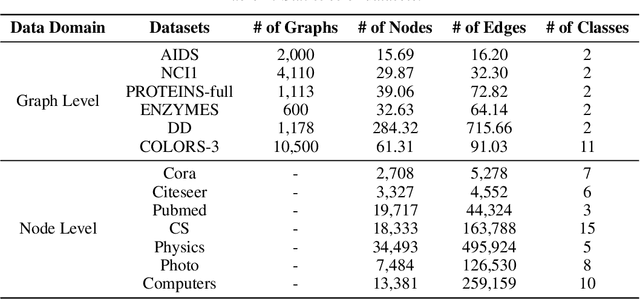
Federated Graph Neural Network (FedGNN) has recently emerged as a rapidly growing research topic, as it integrates the strengths of graph neural networks and federated learning to enable advanced machine learning applications without direct access to sensitive data. Despite its advantages, the distributed nature of FedGNN introduces additional vulnerabilities, particularly backdoor attacks stemming from malicious participants. Although graph backdoor attacks have been explored, the compounded complexity introduced by the combination of GNNs and federated learning has hindered a comprehensive understanding of these attacks, as existing research lacks extensive benchmark coverage and in-depth analysis of critical factors. To address these limitations, we propose Bkd-FedGNN, a benchmark for backdoor attacks on FedGNN. Specifically, Bkd-FedGNN decomposes the graph backdoor attack into trigger generation and injection steps, and extending the attack to the node-level federated setting, resulting in a unified framework that covers both node-level and graph-level classification tasks. Moreover, we thoroughly investigate the impact of multiple critical factors in backdoor attacks on FedGNN. These factors are categorized into global-level and local-level factors, including data distribution, the number of malicious attackers, attack time, overlapping rate, trigger size, trigger type, trigger position, and poisoning rate. Finally, we conduct comprehensive evaluations on 13 benchmark datasets and 13 critical factors, comprising 1,725 experimental configurations for node-level and graph-level tasks from six domains. These experiments encompass over 8,000 individual tests, allowing us to provide a thorough evaluation and insightful observations that advance our understanding of backdoor attacks on FedGNN.The Bkd-FedGNN benchmark is publicly available at https://github.com/usail-hkust/BkdFedGCN.
DrMaMP: Distributed Real-time Multi-agent Mission Planning in Cluttered Environment
Feb 28, 2023
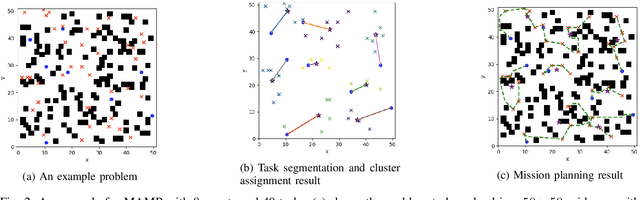
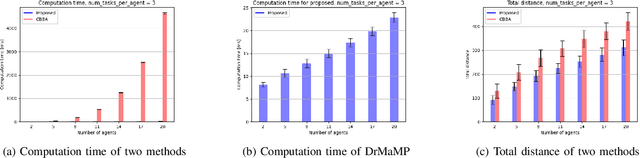
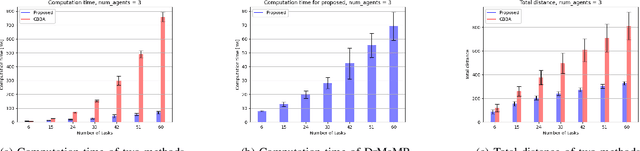
Solving a collision-aware multi-agent mission planning (task allocation and path finding) problem is challenging due to the requirement of real-time computational performance, scalability, and capability of handling static/dynamic obstacles and tasks in a cluttered environment. This paper proposes a distributed real-time (on the order of millisecond) algorithm DrMaMP, which partitions the entire unassigned task set into subsets via approximation and decomposes the original problem into several single-agent mission planning problems. This paper presents experiments with dynamic obstacles and tasks and conducts optimality and scalability comparisons with an existing method, where DrMaMP outperforms the existing method in both indices. Finally, this paper analyzes the computational burden of DrMaMP which is consistent with the observations from comparisons, and presents the optimality gap in small-size problems.
Benchmarking optimality of time series classification methods in distinguishing diffusions
Feb 05, 2023
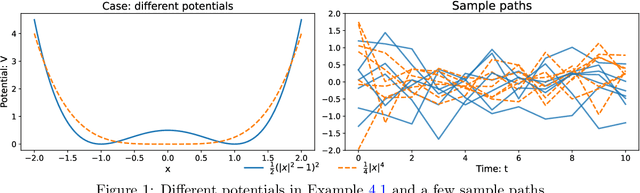
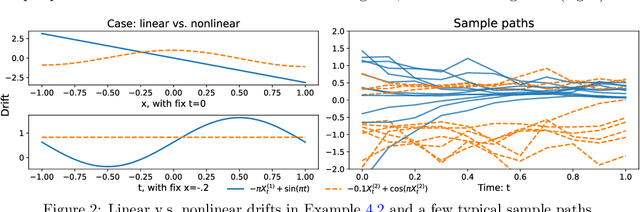

Performance benchmarking is a crucial component of time series classification (TSC) algorithm design, and a fast-growing number of datasets have been established for empirical benchmarking. However, the empirical benchmarks are costly and do not guarantee statistical optimality. This study proposes to benchmark the optimality of TSC algorithms in distinguishing diffusion processes by the likelihood ratio test (LRT). The LRT is optimal in the sense of the Neyman-Pearson lemma: it has the smallest false positive rate among classifiers with a controlled level of false negative rate. The LRT requires the likelihood ratio of the time series to be computable. The diffusion processes from stochastic differential equations provide such time series and are flexible in design for generating linear or nonlinear time series. We demonstrate the benchmarking with three scalable state-of-the-art TSC algorithms: random forest, ResNet, and ROCKET. Test results show that they can achieve LRT optimality for univariate time series and multivariate Gaussian processes. However, these model-agnostic algorithms are suboptimal in classifying nonlinear multivariate time series from high-dimensional stochastic interacting particle systems. Additionally, the LRT benchmark provides tools to analyze the dependence of classification accuracy on the time length, dimension, temporal sampling frequency, and randomness of the time series. Thus, the LRT with diffusion processes can systematically and efficiently benchmark the optimality of TSC algorithms and may guide their future improvements.
JCCS-PFGM: A Novel Circle-Supervision based Poisson Flow Generative Model for Multiphase CECT Progressive Low-Dose Reconstruction with Joint Condition
Jun 13, 2023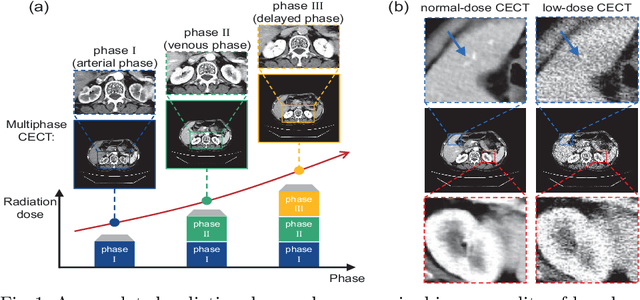

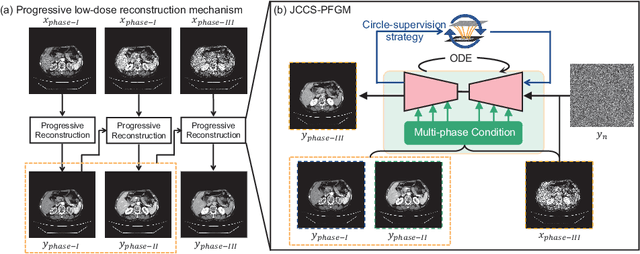
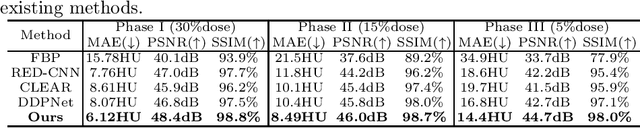
Multiphase contrast-enhanced computed tomography (CECT) scan is clinically significant to demonstrate the anatomy at different phases. In practice, such a multiphase CECT scan inherently takes longer time and deposits much more radiation dose into a patient body than a regular CT scan, and reduction of the radiation dose typically compromise the CECT image quality and its diagnostic value. With Joint Condition and Circle-Supervision, here we propose a novel Poisson Flow Generative Model (JCCS-PFGM) to promote the progressive low-dose reconstruction for multiphase CECT. JCCS-PFGM is characterized by the following three aspects: a progressive low-dose reconstruction scheme, a circle-supervision strategy, and a joint condition mechanism. Our extensive experiments are performed on a clinical dataset consisting of 11436 images. The results show that our JCCS-PFGM achieves promising PSNR up to 46.3dB, SSIM up to 98.5%, and MAE down to 9.67 HU averagely on phases I, II and III, in quantitative evaluations, as well as gains high-quality readable visualizations in qualitative assessments. All of these findings reveal our method a great potential to be adapted for clinical CECT scans at a much-reduced radiation dose.
GQFedWAvg: Optimization-Based Quantized Federated Learning in General Edge Computing Systems
Jun 13, 2023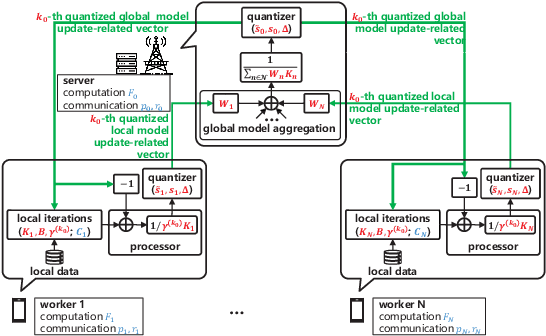
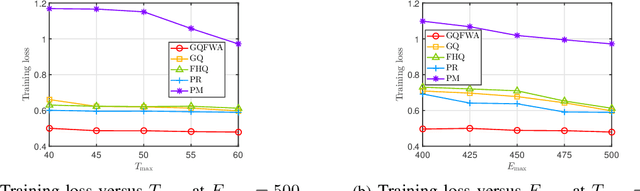
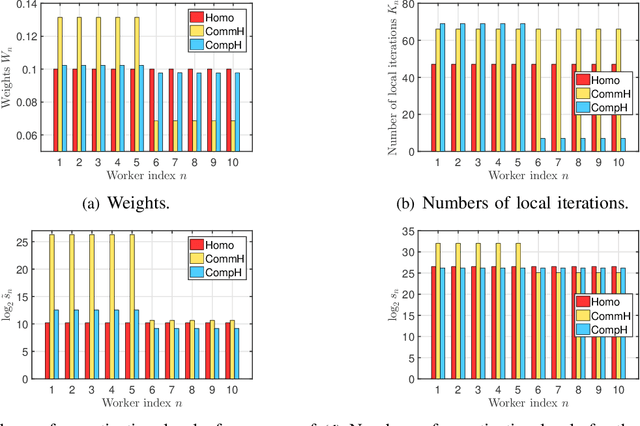
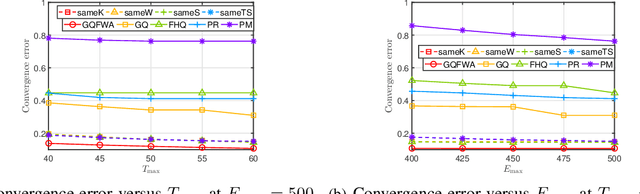
The optimal implementation of federated learning (FL) in practical edge computing systems has been an outstanding problem. In this paper, we propose an optimization-based quantized FL algorithm, which can appropriately fit a general edge computing system with uniform or nonuniform computing and communication resources at the workers. Specifically, we first present a new random quantization scheme and analyze its properties. Then, we propose a general quantized FL algorithm, namely GQFedWAvg. Specifically, GQFedWAvg applies the proposed quantization scheme to quantize wisely chosen model update-related vectors and adopts a generalized mini-batch stochastic gradient descent (SGD) method with the weighted average local model updates in global model aggregation. Besides, GQFedWAvg has several adjustable algorithm parameters to flexibly adapt to the computing and communication resources at the server and workers. We also analyze the convergence of GQFedWAvg. Next, we optimize the algorithm parameters of GQFedWAvg to minimize the convergence error under the time and energy constraints. We successfully tackle the challenging non-convex problem using general inner approximation (GIA) and multiple delicate tricks. Finally, we interpret GQFedWAvg's function principle and show its considerable gains over existing FL algorithms using numerical results.