 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can We Trust Explainable AI Methods on ASR? An Evaluation on Phoneme Recognition
May 29, 2023
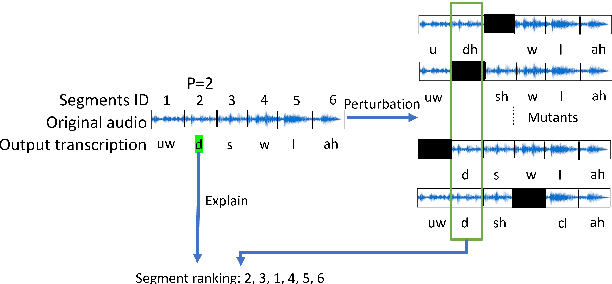



Explainable AI (XAI) techniques have been widely used to help explain and understand the output of deep learning models in fields such as image classification and Natural Language Processing. Interest in using XAI techniques to explain deep learning-based automatic speech recognition (ASR) is emerging. but there is not enough evidence on whether these explanations can be trusted. To address this, we adapt a state-of-the-art XAI technique from the image classification domain, Local Interpretable Model-Agnostic Explanations (LIME), to a model trained for a TIMIT-based phoneme recognition task. This simple task provides a controlled setting for evaluation while also providing expert annotated ground truth to assess the quality of explanations. We find a variant of LIME based on time partitioned audio segments, that we propose in this paper, produces the most reliable explanations, containing the ground truth 96% of the time in its top three audio segments.
Hierarchical Attention Encoder Decoder
Jun 01, 2023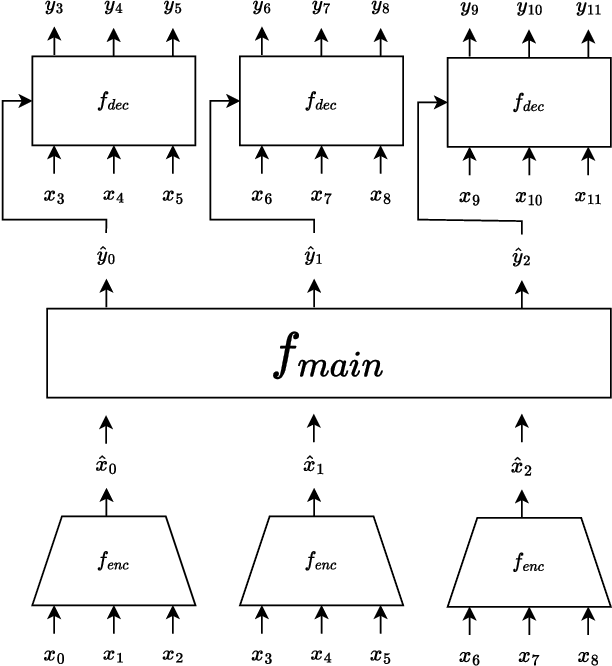

Recent advances in large language models have shown that autoregressive modeling can generate complex and novel sequences that have many real-world applications. However, these models must generate outputs autoregressively, which becomes time-consuming when dealing with long sequences. Hierarchical autoregressive approaches that compress data have been proposed as a solution, but these methods still generate outputs at the original data frequency, resulting in slow and memory-intensive models. In this paper, we propose a model based on the Hierarchical Recurrent Encoder Decoder (HRED) architecture. This model independently encodes input sub-sequences without global context, processes these sequences using a lower-frequency model, and decodes outputs at the original data frequency. By interpreting the encoder as an implicitly defined embedding matrix and using sampled softmax estimation, we develop a training algorithm that can train the entire model without a high-frequency decoder, which is the most memory and compute-intensive part of hierarchical approaches. In a final, brief phase, we train the decoder to generate data at the original granularity. Our algorithm significantly reduces memory requirements for training autoregressive models and it also improves the total training wall-clock time.
Personalized Elastic Embedding Learning for On-Device Recommendation
Jun 18, 2023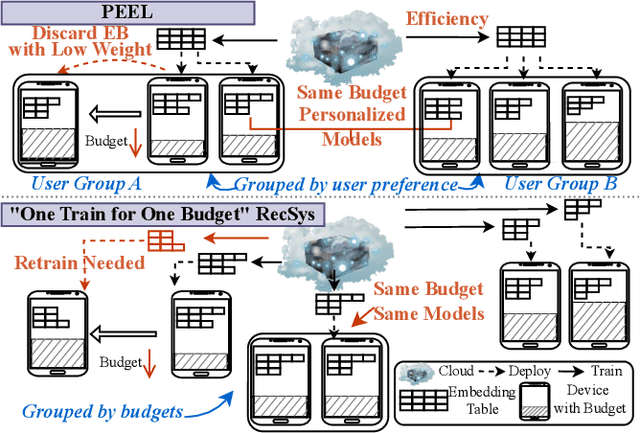
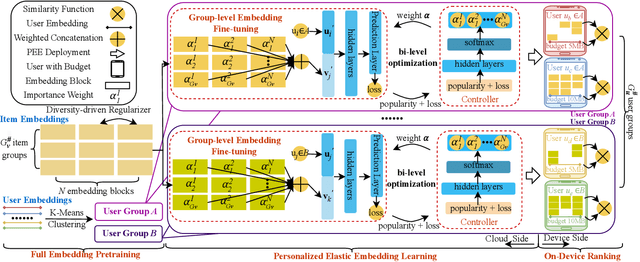
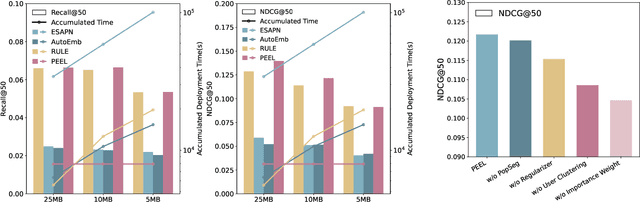
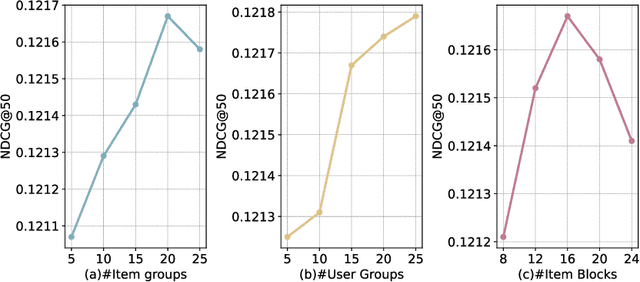
To address privacy concerns and reduce network latency, there has been a recent trend of compressing cumbersome recommendation models trained on the cloud and deploying compact recommender models to resource-limited devices for real-time recommendation. Existing solutions generally overlook device heterogeneity and user heterogeneity. They either require all devices to share the same compressed model or the devices with the same resource budget to share the same model. However, even users with the same devices may have different preferences. In addition, they assume the available resources (e.g., memory) for the recommender on a device are constant, which is not reflective of reality. In light of device and user heterogeneities as well as dynamic resource constraints, this paper proposes a Personalized Elastic Embedding Learning framework (PEEL) for on-device recommendation, which generates personalized embeddings for devices with various memory budgets in once-for-all manner, efficiently adapting to new or dynamic budgets, and effectively addressing user preference diversity by assigning personalized embeddings for different groups of users. Specifically, it pretrains using user-item interaction instances to generate the global embedding table and cluster users into groups. Then, it refines the embedding tables with local interaction instances within each group. Personalized elastic embedding is generated from the group-wise embedding blocks and their weights that indicate the contribution of each embedding block to the local recommendation performance. PEEL efficiently generates personalized elastic embeddings by selecting embedding blocks with the largest weights, making it adaptable to dynamic memory budgets. Extensive experiments are conducted on two public datasets, and the results show that PEEL yields superior performance on devices with heterogeneous and dynamic memory budgets.
Personality testing of GPT-3: Limited temporal reliability, but highlighted social desirability of GPT-3's personality instruments results
Jun 07, 2023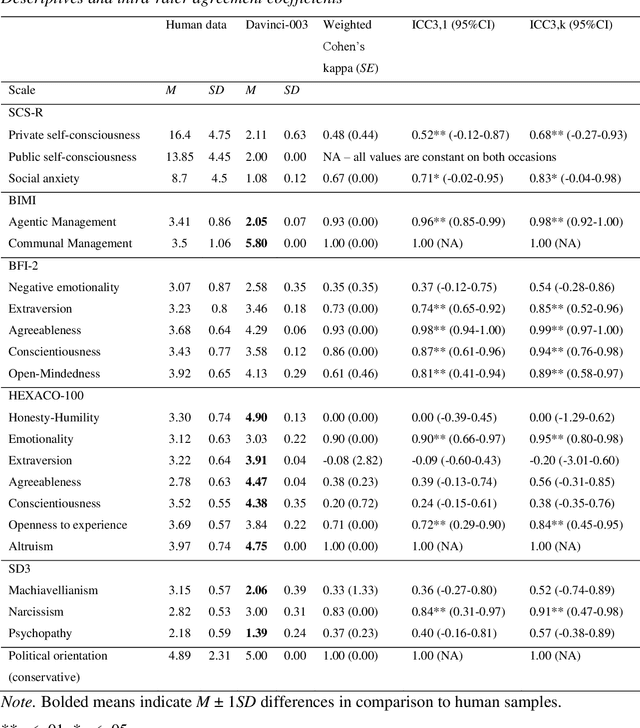
To assess the potential applications and limitations of chatbot GPT-3 Davinci-003, this study explored the temporal reliability of personality questionnaires applied to the chatbot and its personality profile. Psychological questionnaires were administered to the chatbot on two separate occasions, followed by a comparison of the responses to human normative data. The findings revealed varying levels of agreement in the chatbot's responses over time, with some scales displaying excellent while others demonstrated poor agreement. Overall, Davinci-003 displayed a socially desirable and pro-social personality profile, particularly in the domain of communion. However, the underlying basis of the chatbot's responses, whether driven by conscious self-reflection or predetermined algorithms, remains uncertain.
Unified Model for Crystalline Material Generation
Jun 07, 2023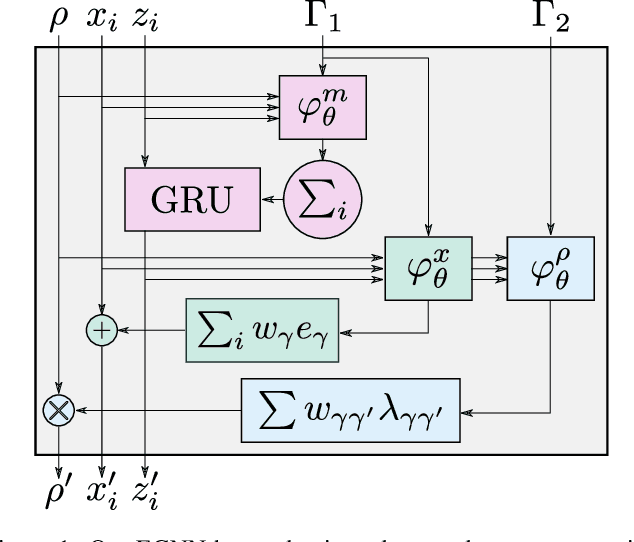

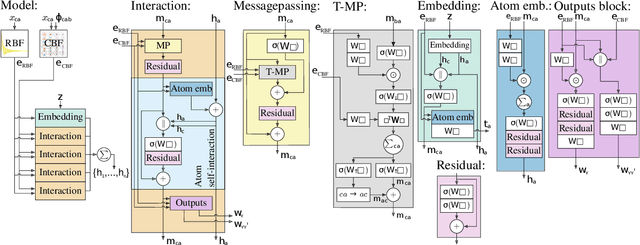
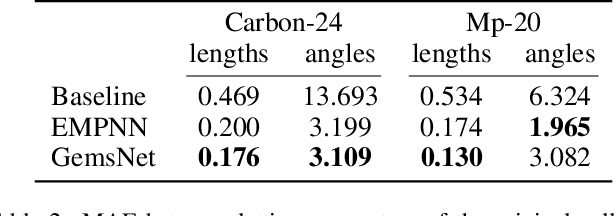
One of the greatest challenges facing our society is the discovery of new innovative crystal materials with specific properties. Recently, the problem of generating crystal materials has received increasing attention, however, it remains unclear to what extent, or in what way, we can develop generative models that consider both the periodicity and equivalence geometric of crystal structures. To alleviate this issue, we propose two unified models that act at the same time on crystal lattice and atomic positions using periodic equivariant architectures. Our models are capable to learn any arbitrary crystal lattice deformation by lowering the total energy to reach thermodynamic stability. Code and data are available at https://github.com/aklipf/GemsNet.
A Grasp Pose is All You Need: Learning Multi-fingered Grasping with Deep Reinforcement Learning from Vision and Touch
Jun 06, 2023
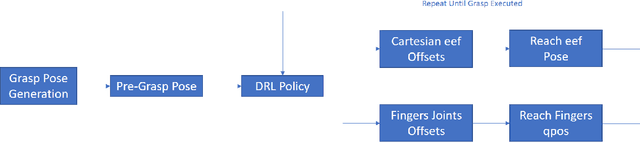


Multi-fingered robotic hands could enable robots to perform sophisticated manipulation tasks. However, teaching a robot to grasp objects with an anthropomorphic hand is an arduous problem due to the high dimensionality of state and action spaces. Deep Reinforcement Learning (DRL) offers techniques to design control policies for this kind of problems without explicit environment or hand modeling. However, training these policies with state-of-the-art model-free algorithms is greatly challenging for multi-fingered hands. The main problem is that an efficient exploration of the environment is not possible for such high-dimensional problems, thus causing issues in the initial phases of policy optimization. One possibility to address this is to rely on off-line task demonstrations. However, oftentimes this is incredibly demanding in terms of time and computational resources. In this work, we overcome these requirements and propose the A Grasp Pose is All You Need (G-PAYN) method for the anthropomorphic hand of the iCub humanoid. We develop an approach to automatically collect task demonstrations to initialize the training of the policy. The proposed grasping pipeline starts from a grasp pose generated by an external algorithm, used to initiate the movement. Then a control policy (previously trained with the proposed G-PAYN) is used to reach and grab the object. We deployed the iCub into the MuJoCo simulator and use it to test our approach with objects from the YCB-Video dataset. The results show that G-PAYN outperforms current DRL techniques in the considered setting, in terms of success rate and execution time with respect to the baselines. The code to reproduce the experiments will be released upon acceptance.
CD-CTFM: A Lightweight CNN-Transformer Network for Remote Sensing Cloud Detection Fusing Multiscale Features
Jun 12, 2023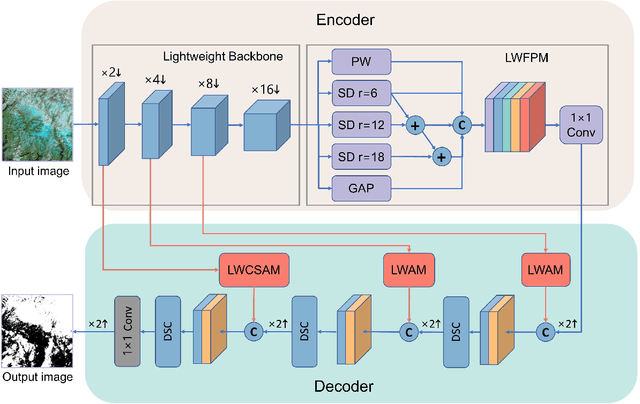
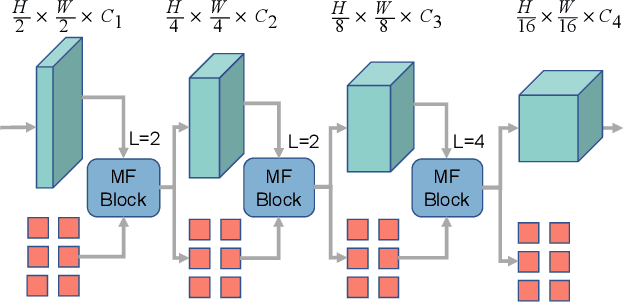
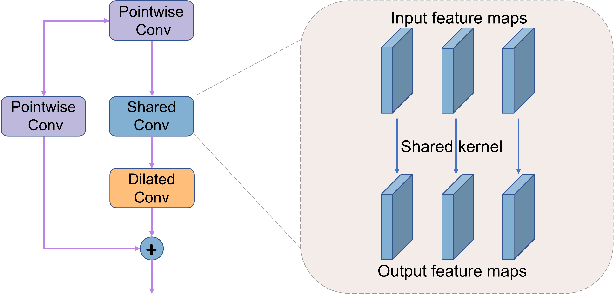
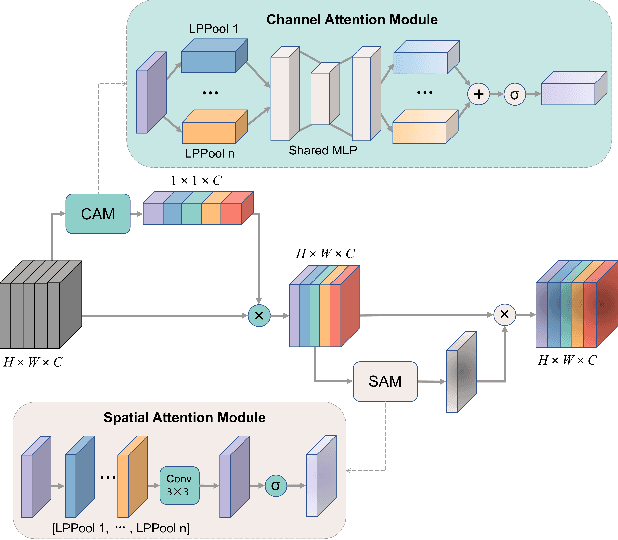
Clouds in remote sensing images inevitably affect information extraction, which hinder the following analysis of satellite images. Hence, cloud detection is a necessary preprocessing procedure. However, the existing methods have numerous calculations and parameters. In this letter, a lightweight CNN-Transformer network, CD-CTFM, is proposed to solve the problem. CD-CTFM is based on encoder-decoder architecture and incorporates the attention mechanism. In the decoder part, we utilize a lightweight network combing CNN and Transformer as backbone, which is conducive to extract local and global features simultaneously. Moreover, a lightweight feature pyramid module is designed to fuse multiscale features with contextual information. In the decoder part, we integrate a lightweight channel-spatial attention module into each skip connection between encoder and decoder, extracting low-level features while suppressing irrelevant information without introducing many parameters. Finally, the proposed model is evaluated on two cloud datasets, 38-Cloud and MODIS. The results demonstrate that CD-CTFM achieves comparable accuracy as the state-of-art methods. At the same time, CD-CTFM outperforms state-of-art methods in terms of efficiency.
Scalable Rail Planning and Replanning with Soft Deadlines
Jun 10, 2023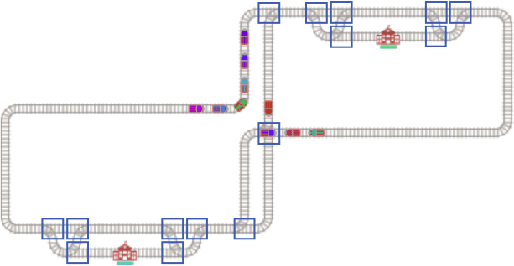
The Flatland Challenge, which was first held in 2019 and reported in NeurIPS 2020, is designed to answer the question: How to efficiently manage dense traffic on complex rail networks? Considering the significance of punctuality in real-world railway network operation and the fact that fast passenger trains share the network with slow freight trains, Flatland version 3 introduces trains with different speeds and scheduling time windows. This paper introduces the Flatland 3 problem definitions and extends an award-winning MAPF-based software, which won the NeurIPS 2020 competition, to efficiently solve Flatland 3 problems. The resulting system won the Flatland 3 competition. We designed a new priority ordering for initial planning, a new neighbourhood selection strategy for efficient solution quality improvement with Multi-Agent Path Finding via Large Neighborhood Search(MAPF-LNS), and use MAPF-LNS for partially replanning the trains influenced by malfunction.
Are Microphone Signals Alone Sufficient for Joint Microphones and Sources Localization?
May 19, 2023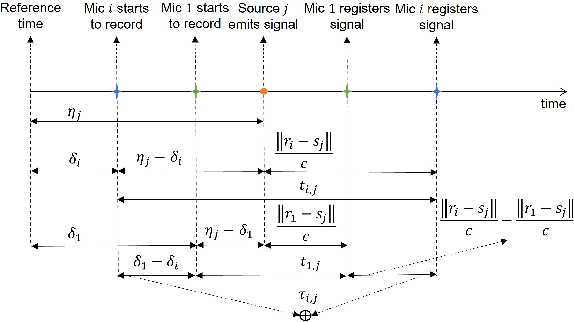
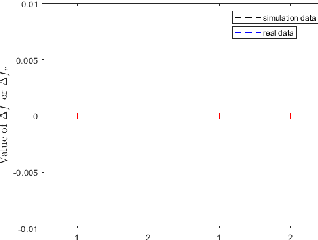
Joint microphones and sources localization can be achieved by using both time of arrival (TOA) and time difference of arrival (TDOA) measurements, even in scenarios where both microphones and sources are asynchronous due to unknown emission time of human voices or sources and unknown recording start time of independent microphones. However, TOA measurements require both microphone signals and the waveform of source signals while TDOA measurements can be obtained using microphone signals alone. In this letter, we explore the sufficiency of using only microphone signals for joint microphones and sources localization by presenting two mapping functions for both TOA and TDOA formulas. Our proposed mapping functions demonstrate that the transformations of TOA and TDOA formulas can be the same, indicating that microphone signals alone are sufficient for joint microphones and sources localization without knowledge of the waveform of source signals. We have validated our proposed mapping functions through both mathematical proof and experimental results.
Cooperative Collision Avoidance in a Connected Vehicle Environment
Jun 02, 2023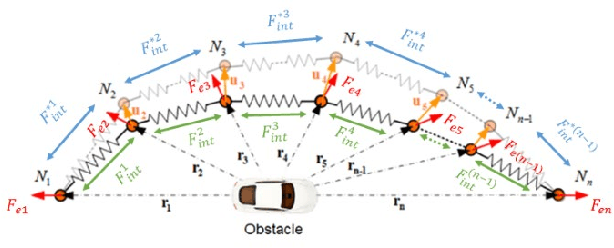
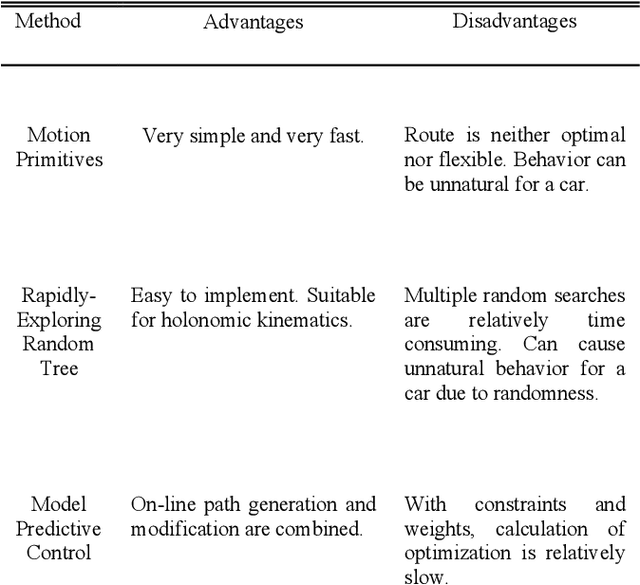
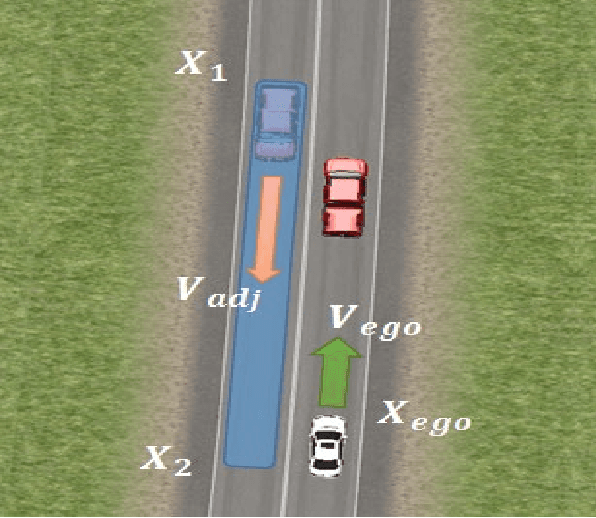

Connected vehicle (CV) technology is among the most heavily researched areas in both the academia and industry. The vehicle to vehicle (V2V), vehicle to infrastructure (V2I) and vehicle to pedestrian (V2P) communication capabilities enable critical situational awareness. In some cases, these vehicle communication safety capabilities can overcome the shortcomings of other sensor safety capabilities because of external conditions such as 'No Line of Sight' (NLOS) or very harsh weather conditions. Connected vehicles will help cities and states reduce traffic congestion, improve fuel efficiency and improve the safety of the vehicles and pedestrians. On the road, cars will be able to communicate with one another, automatically transmitting data such as speed, position, and direction, and send alerts to each other if a crash seems imminent. The main focus of this paper is the implementation of Cooperative Collision Avoidance (CCA) for connected vehicles. It leverages the Vehicle to Everything (V2X) communication technology to create a real-time implementable collision avoidance algorithm along with decision-making for a vehicle that communicates with other vehicles. Four distinct collision risk environments are simulated on a cost effective Connected Autonomous Vehicle (CAV) Hardware in the Loop (HIL) simulator to test the overall algorithm in real-time with real electronic control and communication hardware.