 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed TD(0) with Almost No Communication
May 25, 2023
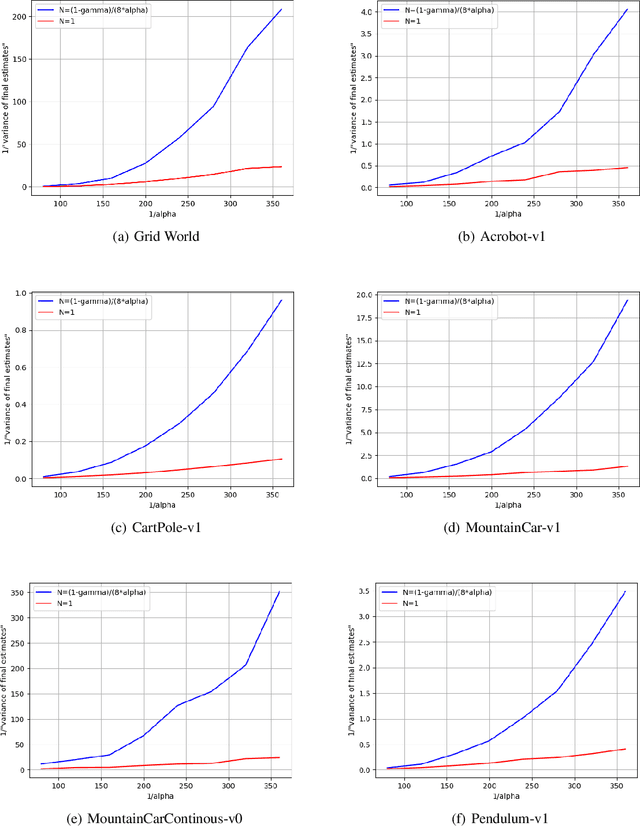
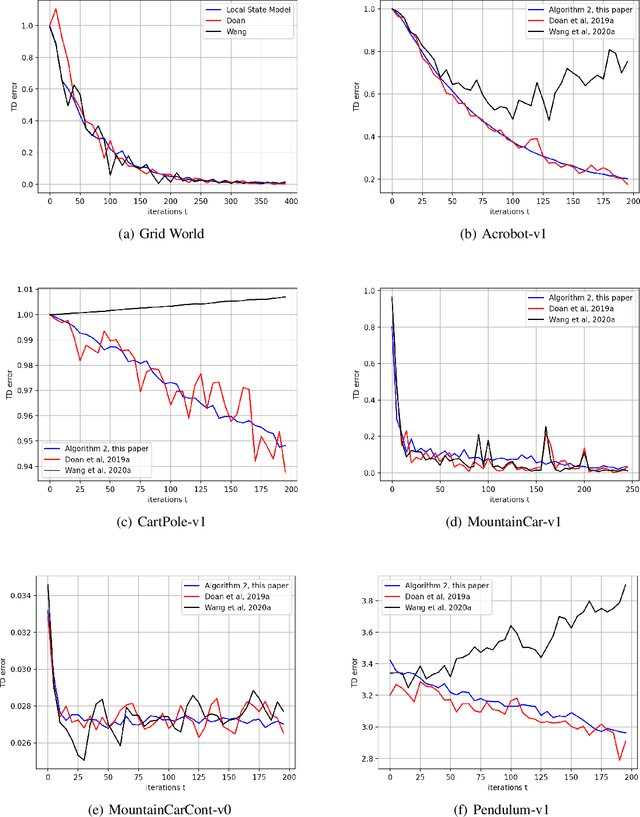
We provide a new non-asymptotic analysis of distributed temporal difference learning with linear function approximation. Our approach relies on ``one-shot averaging,'' where $N$ agents run identical local copies of the TD(0) method and average the outcomes only once at the very end. We demonstrate a version of the linear time speedup phenomenon, where the convergence time of the distributed process is a factor of $N$ faster than the convergence time of TD(0). This is the first result proving benefits from parallelism for temporal difference methods.
Unfolding Framework with Prior of Convolution-Transformer Mixture and Uncertainty Estimation for Video Snapshot Compressive Imaging
Jun 20, 2023We consider the problem of video snapshot compressive imaging (SCI), where sequential high-speed frames are modulated by different masks and captured by a single measurement. The underlying principle of reconstructing multi-frame images from only one single measurement is to solve an ill-posed problem. By combining optimization algorithms and neural networks, deep unfolding networks (DUNs) score tremendous achievements in solving inverse problems. In this paper, our proposed model is under the DUN framework and we propose a 3D Convolution-Transformer Mixture (CTM) module with a 3D efficient and scalable attention model plugged in, which helps fully learn the correlation between temporal and spatial dimensions by virtue of Transformer. To our best knowledge, this is the first time that Transformer is employed to video SCI reconstruction. Besides, to further investigate the high-frequency information during the reconstruction process which are neglected in previous studies, we introduce variance estimation characterizing the uncertainty on a pixel-by-pixel basis. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) (with a 1.2dB gain in PSNR over previous SOTA algorithm) results. We will release the code.
How to Efficiently Adapt Large Segmentation Model(SAM) to Medical Images
Jun 23, 2023
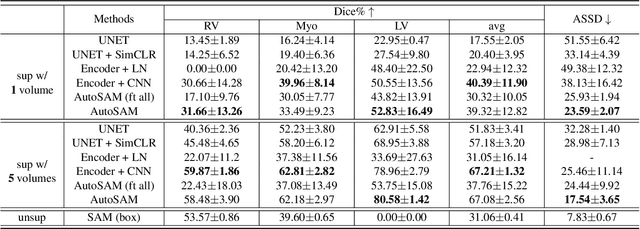
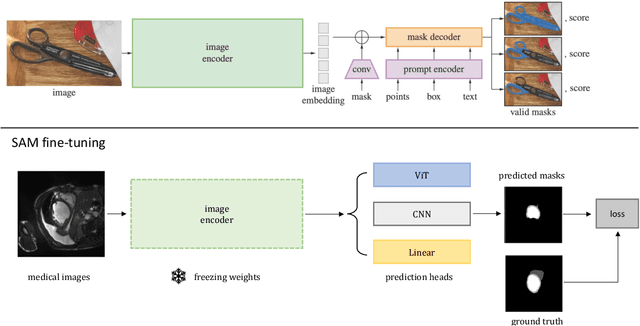

The emerging scale segmentation model, Segment Anything (SAM), exhibits impressive capabilities in zero-shot segmentation for natural images. However, when applied to medical images, SAM suffers from noticeable performance drop. To make SAM a real ``foundation model" for the computer vision community, it is critical to find an efficient way to customize SAM for medical image dataset. In this work, we propose to freeze SAM encoder and finetune a lightweight task-specific prediction head, as most of weights in SAM are contributed by the encoder. In addition, SAM is a promptable model, while prompt is not necessarily available in all application cases, and precise prompts for multiple class segmentation are also time-consuming. Therefore, we explore three types of prompt-free prediction heads in this work, include ViT, CNN, and linear layers. For ViT head, we remove the prompt tokens in the mask decoder of SAM, which is named AutoSAM. AutoSAM can also generate masks for different classes with one single inference after modification. To evaluate the label-efficiency of our finetuning method, we compare the results of these three prediction heads on a public medical image segmentation dataset with limited labeled data. Experiments demonstrate that finetuning SAM significantly improves its performance on medical image dataset, even with just one labeled volume. Moreover, AutoSAM and CNN prediction head also has better segmentation accuracy than training from scratch and self-supervised learning approaches when there is a shortage of annotations.
An Efficient Off-Policy Reinforcement Learning Algorithm for the Continuous-Time LQR Problem
Mar 31, 2023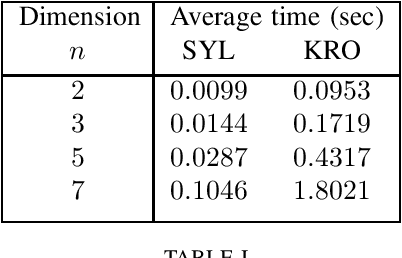
In this paper, an off-policy reinforcement learning algorithm is designed to solve the continuous-time LQR problem using only input-state data measured from the system. Different from other algorithms in the literature, we propose the use of a specific persistently exciting input as the exploration signal during the data collection step. We then show that, using this persistently excited data, the solution of the matrix equation in our algorithm is guaranteed to exist and to be unique at every iteration. Convergence of the algorithm to the optimal control input is also proven. Moreover, we formulate the policy evaluation step as the solution of a Sylvester-transpose equation, which increases the efficiency of its solution. Finally, a method to determine a stabilizing policy to initialize the algorithm using only measured data is proposed.
Adaptive DNN Surgery for Selfish Inference Acceleration with On-demand Edge Resource
Jun 21, 2023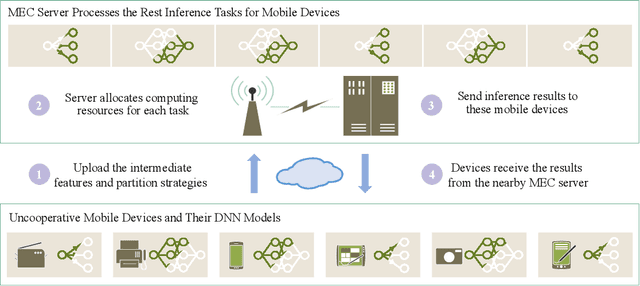
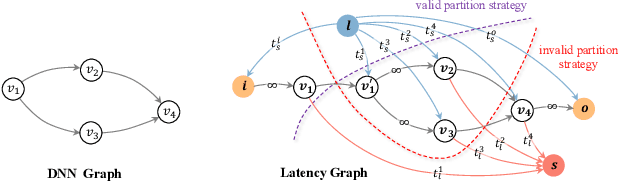
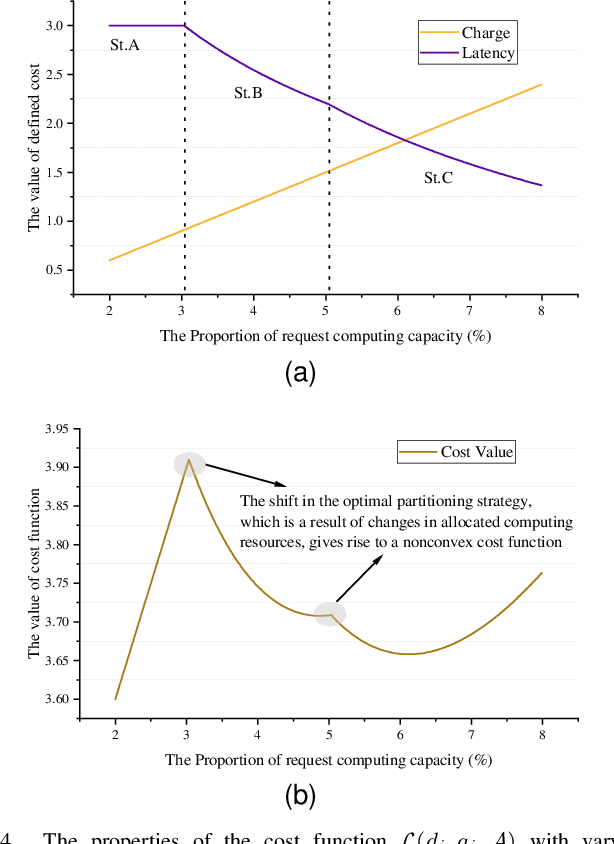
Deep Neural Networks (DNNs) have significantly improved the accuracy of intelligent applications on mobile devices. DNN surgery, which partitions DNN processing between mobile devices and multi-access edge computing (MEC) servers, can enable real-time inference despite the computational limitations of mobile devices. However, DNN surgery faces a critical challenge: determining the optimal computing resource demand from the server and the corresponding partition strategy, while considering both inference latency and MEC server usage costs. This problem is compounded by two factors: (1) the finite computing capacity of the MEC server, which is shared among multiple devices, leading to inter-dependent demands, and (2) the shift in modern DNN architecture from chains to directed acyclic graphs (DAGs), which complicates potential solutions. In this paper, we introduce a novel Decentralized DNN Surgery (DDS) framework. We formulate the partition strategy as a min-cut and propose a resource allocation game to adaptively schedule the demands of mobile devices in an MEC environment. We prove the existence of a Nash Equilibrium (NE), and develop an iterative algorithm to efficiently reach the NE for each device. Our extensive experiments demonstrate that DDS can effectively handle varying MEC scenarios, achieving up to 1.25$\times$ acceleration compared to the state-of-the-art algorithm.
Block-Wise Index Modulation and Receiver Design for High-Mobility OTFS Communications
Jun 21, 2023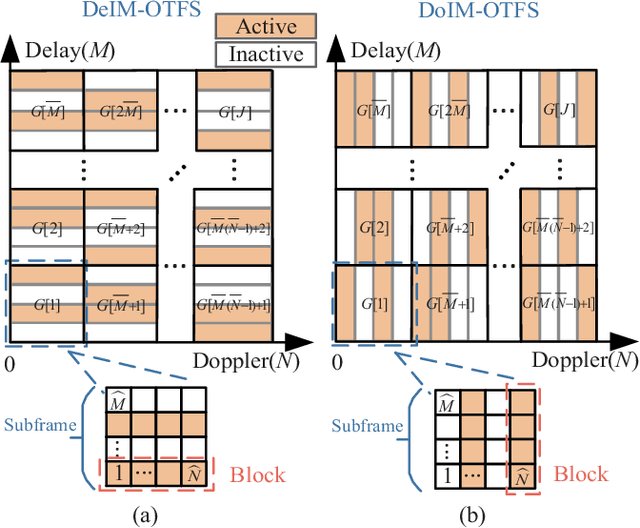
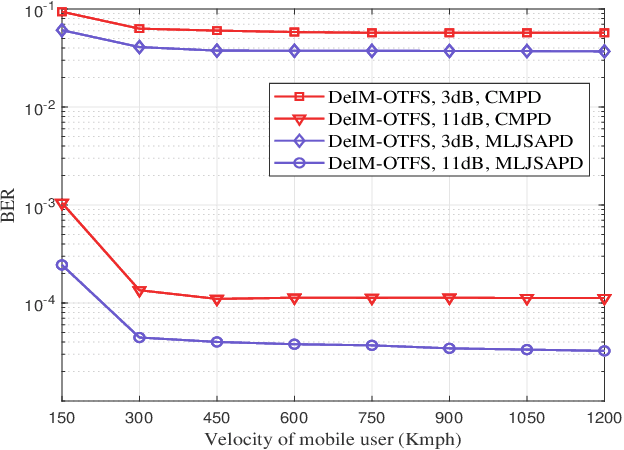
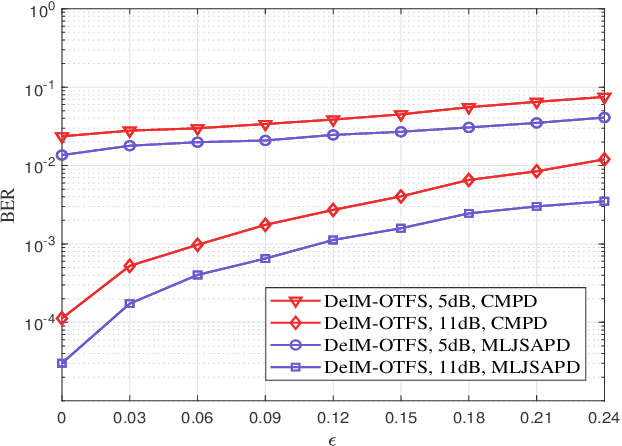
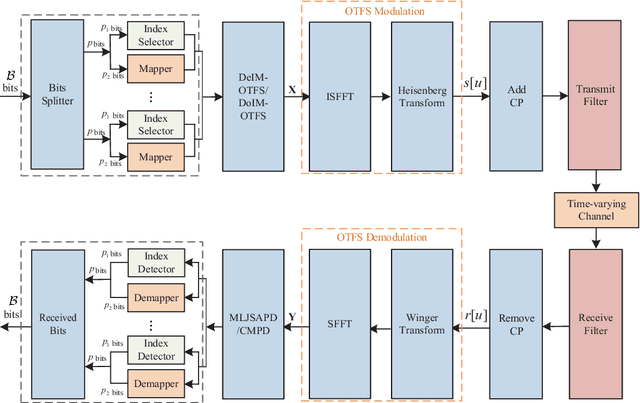
As a promising technique for high-mobility wireless communications, orthogonal time frequency space (OTFS) has been proved to enjoy excellent advantages with respect to traditional orthogonal frequency division multiplexing (OFDM). Although multiple studies have considered index modulation (IM) based OTFS (IM-OTFS) schemes to further improve system performance, a challenging and open problem is the development of effective IM schemes and efficient receivers for practical OTFS systems that must operate in the presence of channel delays and Doppler shifts. In this paper, we propose two novel block-wise IM schemes for OTFS systems, named delay-IM with OTFS (DeIM-OTFS) and Doppler-IM with OTFS (DoIM-OTFS), where a block of delay/Doppler resource bins are activated simultaneously. Based on a maximum likelihood (ML) detector, we analyze upper bounds on the average bit error rates for the proposed DeIM-OTFS and DoIM-OTFS schemes, and verify their performance advantages over the existing IM-OTFS systems. We also develop a multi-layer joint symbol and activation pattern detection (MLJSAPD) algorithm and a customized message passing detection (CMPD) algorithm for our proposed DeIMOTFS and DoIM-OTFS systems with low complexity. Simulation results demonstrate that our proposed MLJSAPD and CMPD algorithms can achieve desired performance with robustness to the imperfect channel state information (CSI).
TADIL: Task-Agnostic Domain-Incremental Learning through Task-ID Inference using Transformer Nearest-Centroid Embeddings
Jun 21, 2023Machine Learning (ML) models struggle with data that changes over time or across domains due to factors such as noise, occlusion, illumination, or frequency, unlike humans who can learn from such non independent and identically distributed data. Consequently, a Continual Learning (CL) approach is indispensable, particularly, Domain-Incremental Learning. In this paper, we propose a novel pipeline for identifying tasks in domain-incremental learning scenarios without supervision. The pipeline comprises four steps. First, we obtain base embeddings from the raw data using an existing transformer-based model. Second, we group the embedding densities based on their similarity to obtain the nearest points to each cluster centroid. Third, we train an incremental task classifier using only these few points. Finally, we leverage the lightweight computational requirements of the pipeline to devise an algorithm that decides in an online fashion when to learn a new task using the task classifier and a drift detector. We conduct experiments using the SODA10M real-world driving dataset and several CL strategies. We demonstrate that the performance of these CL strategies with our pipeline can match the ground-truth approach, both in classical experiments assuming task boundaries, and also in more realistic task-agnostic scenarios that require detecting new tasks on-the-fly
Temporal Conditioning Spiking Latent Variable Models of the Neural Response to Natural Visual Scenes
Jun 21, 2023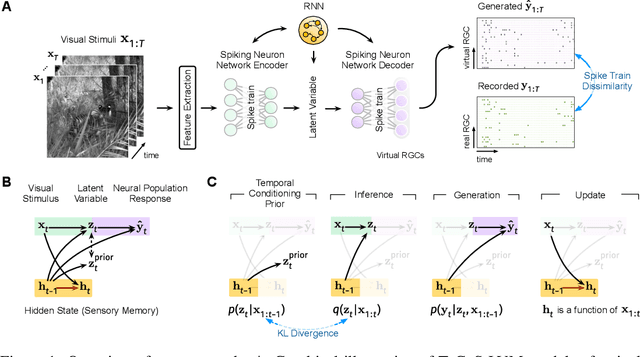


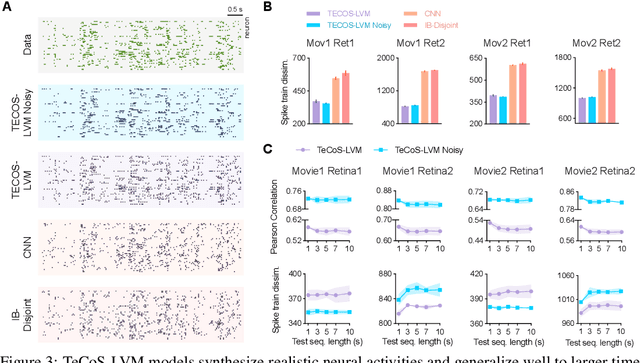
Developing computational models of neural response is crucial for understanding sensory processing and neural computations. Current state-of-the-art neural network methods use temporal filters to handle temporal dependencies, resulting in an unrealistic and inflexible processing flow. Meanwhile, these methods target trial-averaged firing rates and fail to capture important features in spike trains. This work presents the temporal conditioning spiking latent variable models (TeCoS-LVM) to simulate the neural response to natural visual stimuli. We use spiking neurons to produce spike outputs that directly match the recorded trains. This approach helps to avoid losing information embedded in the original spike trains. We exclude the temporal dimension from the model parameter space and introduce a temporal conditioning operation to allow the model to adaptively explore and exploit temporal dependencies in stimuli sequences in a natural paradigm. We show that TeCoS-LVM models can produce more realistic spike activities and accurately fit spike statistics than powerful alternatives. Additionally, learned TeCoS-LVM models can generalize well to longer time scales. Overall, while remaining computationally tractable, our model effectively captures key features of neural coding systems. It thus provides a useful tool for building accurate predictive computational accounts for various sensory perception circuits.
Beyond OOD State Actions: Supported Cross-Domain Offline Reinforcement Learning
Jun 22, 2023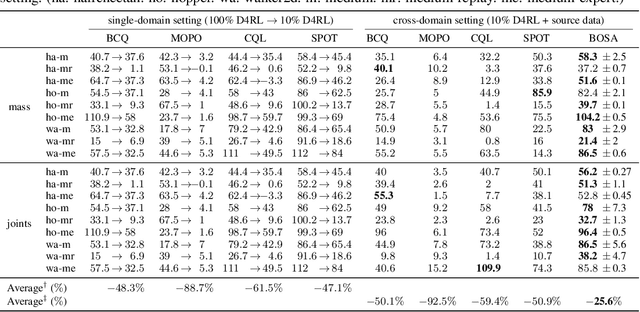
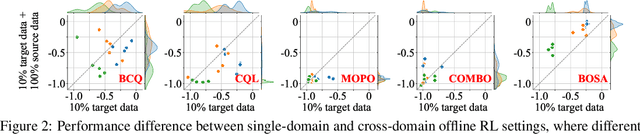


Offline reinforcement learning (RL) aims to learn a policy using only pre-collected and fixed data. Although avoiding the time-consuming online interactions in RL, it poses challenges for out-of-distribution (OOD) state actions and often suffers from data inefficiency for training. Despite many efforts being devoted to addressing OOD state actions, the latter (data inefficiency) receives little attention in offline RL. To address this, this paper proposes the cross-domain offline RL, which assumes offline data incorporate additional source-domain data from varying transition dynamics (environments), and expects it to contribute to the offline data efficiency. To do so, we identify a new challenge of OOD transition dynamics, beyond the common OOD state actions issue, when utilizing cross-domain offline data. Then, we propose our method BOSA, which employs two support-constrained objectives to address the above OOD issues. Through extensive experiments in the cross-domain offline RL setting, we demonstrate BOSA can greatly improve offline data efficiency: using only 10\% of the target data, BOSA could achieve {74.4\%} of the SOTA offline RL performance that uses 100\% of the target data. Additionally, we also show BOSA can be effortlessly plugged into model-based offline RL and noising data augmentation techniques (used for generating source-domain data), which naturally avoids the potential dynamics mismatch between target-domain data and newly generated source-domain data.
Context-lumpable stochastic bandits
Jun 22, 2023We consider a contextual bandit problem with $S $ contexts and $A $ actions. In each round $t=1,2,\dots$ the learner observes a random context and chooses an action based on its past experience. The learner then observes a random reward whose mean is a function of the context and the action for the round. Under the assumption that the contexts can be lumped into $r\le \min\{S ,A \}$ groups such that the mean reward for the various actions is the same for any two contexts that are in the same group, we give an algorithm that outputs an $\epsilon$-optimal policy after using at most $\widetilde O(r (S +A )/\epsilon^2)$ samples with high probability and provide a matching $\widetilde\Omega(r (S +A )/\epsilon^2)$ lower bound. In the regret minimization setting, we give an algorithm whose cumulative regret up to time $T$ is bounded by $\widetilde O(\sqrt{r^3(S +A )T})$. To the best of our knowledge, we are the first to show the near-optimal sample complexity in the PAC setting and $\widetilde O(\sqrt{{poly}(r)(S+K)T})$ minimax regret in the online setting for this problem. We also show our algorithms can be applied to more general low-rank bandits and get improved regret bounds in some scenarios.