 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-sensitive Learning for Heterogeneous Federated Edge Intelligence
Jan 26, 2023
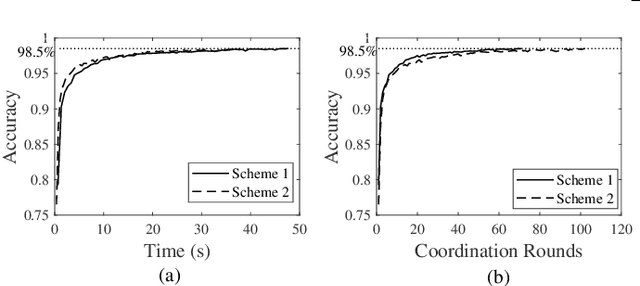
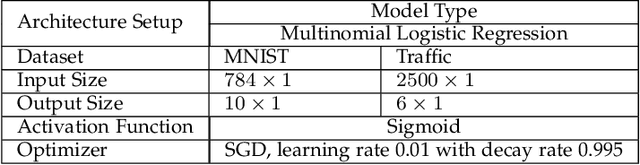
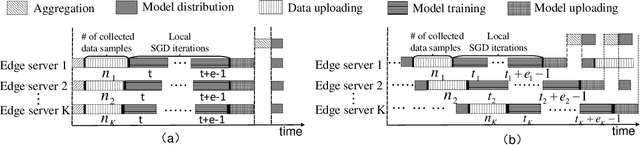

Real-time machine learning has recently attracted significant interest due to its potential to support instantaneous learning, adaptation, and decision making in a wide range of application domains, including self-driving vehicles, intelligent transportation, and industry automation. We investigate real-time ML in a federated edge intelligence (FEI) system, an edge computing system that implements federated learning (FL) solutions based on data samples collected and uploaded from decentralized data networks. FEI systems often exhibit heterogenous communication and computational resource distribution, as well as non-i.i.d. data samples, resulting in long model training time and inefficient resource utilization. Motivated by this fact, we propose a time-sensitive federated learning (TS-FL) framework to minimize the overall run-time for collaboratively training a shared ML model. Training acceleration solutions for both TS-FL with synchronous coordination (TS-FL-SC) and asynchronous coordination (TS-FL-ASC) are investigated. To address straggler effect in TS-FL-SC, we develop an analytical solution to characterize the impact of selecting different subsets of edge servers on the overall model training time. A server dropping-based solution is proposed to allow slow-performance edge servers to be removed from participating in model training if their impact on the resulting model accuracy is limited. A joint optimization algorithm is proposed to minimize the overall time consumption of model training by selecting participating edge servers, local epoch number. We develop an analytical expression to characterize the impact of staleness effect of asynchronous coordination and straggler effect of FL on the time consumption of TS-FL-ASC. Experimental results show that TS-FL-SC and TS-FL-ASC can provide up to 63% and 28% of reduction, in the overall model training time, respectively.
* IEEE Link: https://ieeexplore.ieee.org/document/10018200
Teleoperation of Soft Modular Robots: Study on Real-time Stability and Gait Control
Mar 09, 2023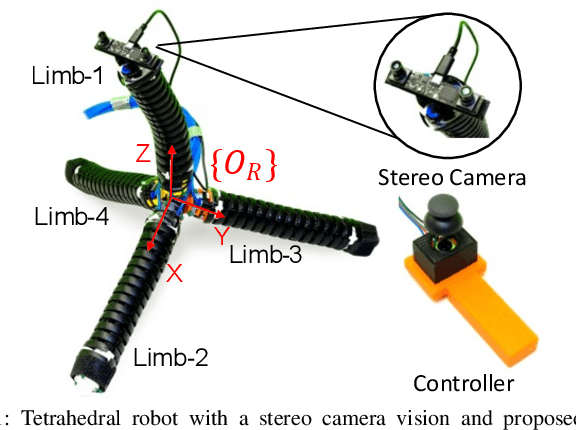
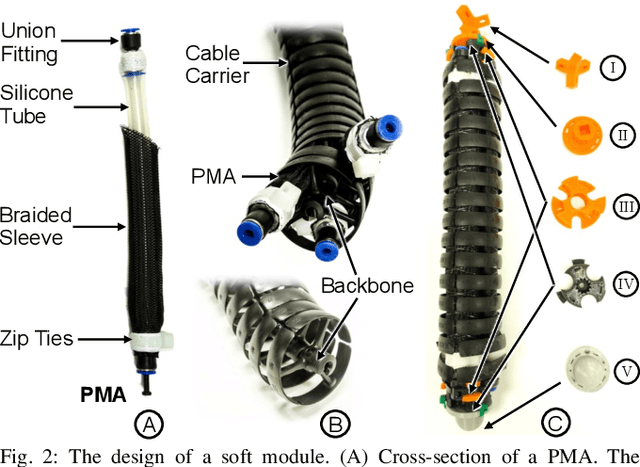
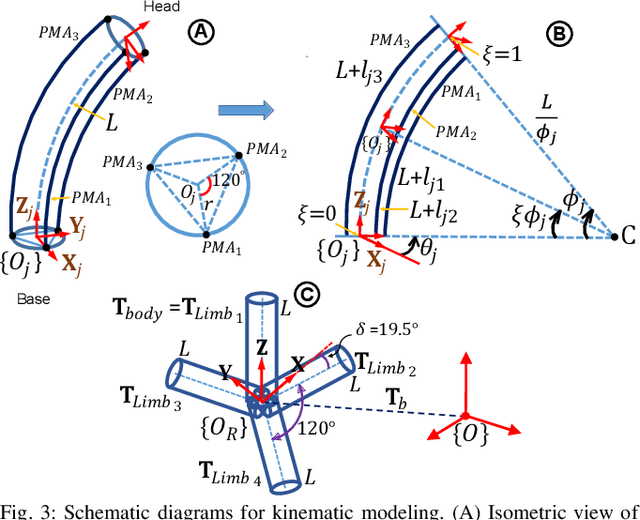
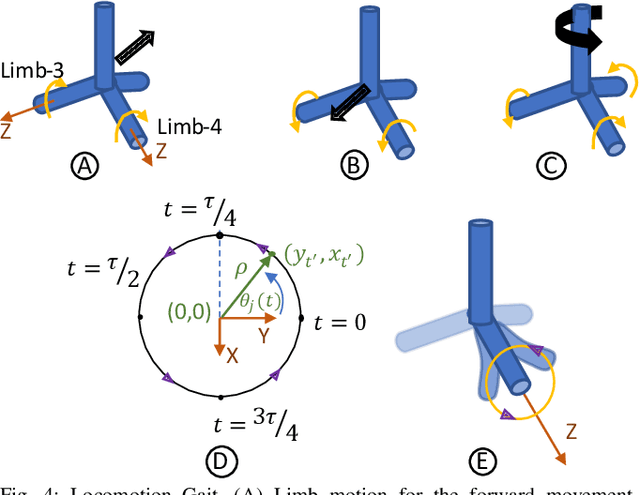
Soft robotics holds tremendous potential for various applications, especially in unstructured environments such as search and rescue operations. However, the lack of autonomy and teleoperability, limited capabilities, absence of gait diversity and real-time control, and onboard sensors to sense the surroundings are some of the common issues with soft-limbed robots. To overcome these limitations, we propose a spatially symmetric, topologically-stable, soft-limbed tetrahedral robot that can perform multiple locomotion gaits. We introduce a kinematic model, derive locomotion trajectories for different gaits, and design a teleoperation mechanism to enable real-time human-robot collaboration. We use the kinematic model to map teleoperation inputs and ensure smooth transitions between gaits. Additionally, we leverage the passive compliance and natural stability of the robot for toppling and obstacle navigation. Through experimental tests, we demonstrate the robot's ability to tackle various locomotion challenges, adapt to different situations, and navigate obstructed environments via teleoperation.
Generalizable One-shot Neural Head Avatar
Jun 14, 2023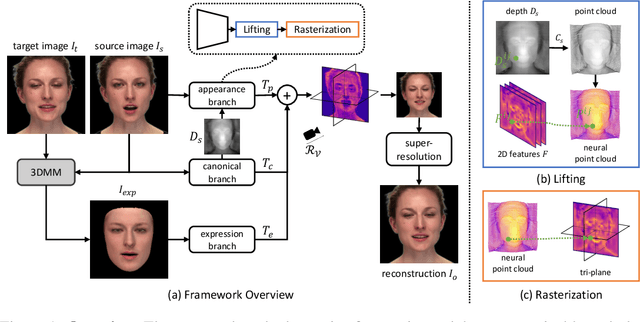
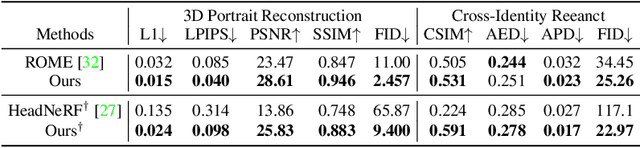

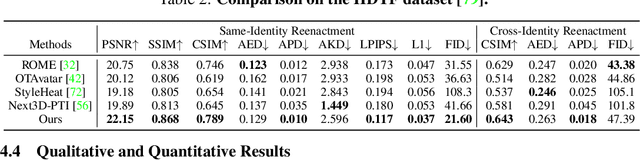
We present a method that reconstructs and animates a 3D head avatar from a single-view portrait image. Existing methods either involve time-consuming optimization for a specific person with multiple images, or they struggle to synthesize intricate appearance details beyond the facial region. To address these limitations, we propose a framework that not only generalizes to unseen identities based on a single-view image without requiring person-specific optimization, but also captures characteristic details within and beyond the face area (e.g. hairstyle, accessories, etc.). At the core of our method are three branches that produce three tri-planes representing the coarse 3D geometry, detailed appearance of a source image, as well as the expression of a target image. By applying volumetric rendering to the combination of the three tri-planes followed by a super-resolution module, our method yields a high fidelity image of the desired identity, expression and pose. Once trained, our model enables efficient 3D head avatar reconstruction and animation via a single forward pass through a network. Experiments show that the proposed approach generalizes well to unseen validation datasets, surpassing SOTA baseline methods by a large margin on head avatar reconstruction and animation.
LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting
Jun 14, 2023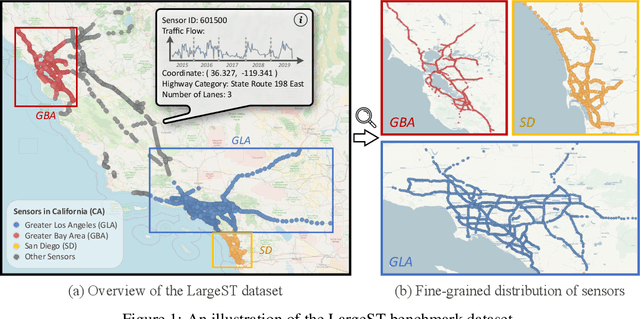
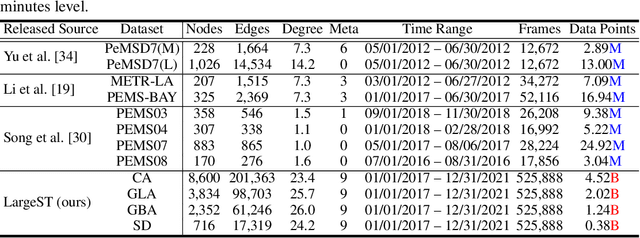

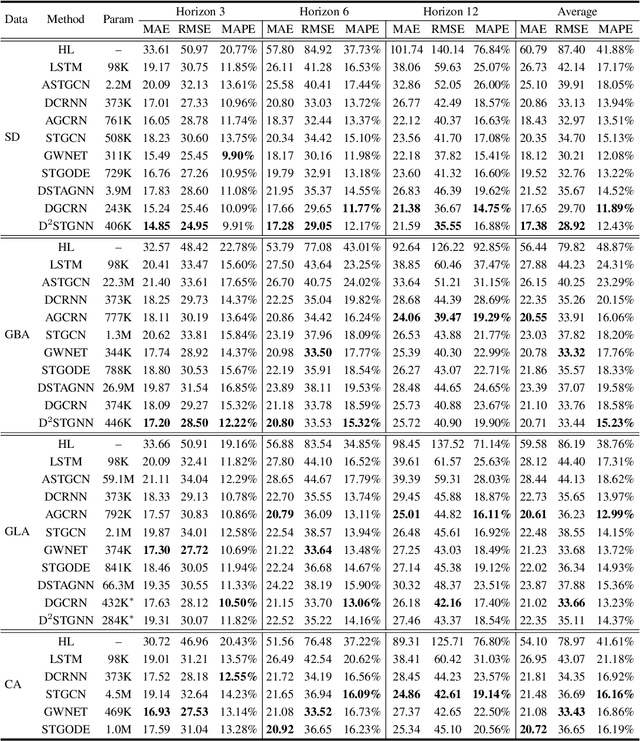
Traffic forecasting plays a critical role in smart city initiatives and has experienced significant advancements thanks to the power of deep learning in capturing non-linear patterns of traffic data. However, the promising results achieved on current public datasets may not be applicable to practical scenarios due to limitations within these datasets. First, the limited sizes of them may not reflect the real-world scale of traffic networks. Second, the temporal coverage of these datasets is typically short, posing hurdles in studying long-term patterns and acquiring sufficient samples for training deep models. Third, these datasets often lack adequate metadata for sensors, which compromises the reliability and interpretability of the data. To mitigate these limitations, we introduce the LargeST benchmark dataset. It encompasses a total number of 8,600 sensors with a 5-year time coverage and includes comprehensive metadata. Using LargeST, we perform in-depth data analysis to extract data insights, benchmark well-known baselines in terms of their performance and efficiency, and identify challenges as well as opportunities for future research. We release the datasets and baseline implementations at: https://github.com/liuxu77/LargeST.
Global-Local Processing in Convolutional Neural Networks
Jun 14, 2023
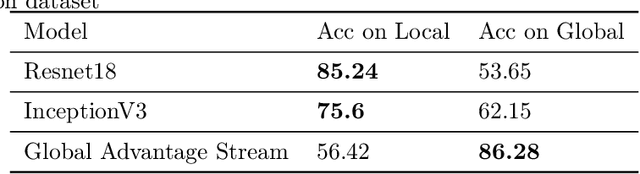
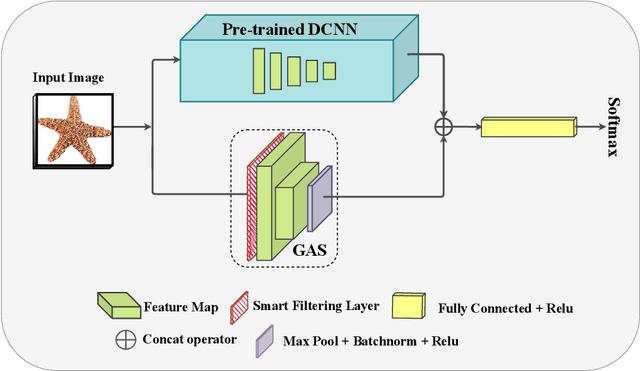
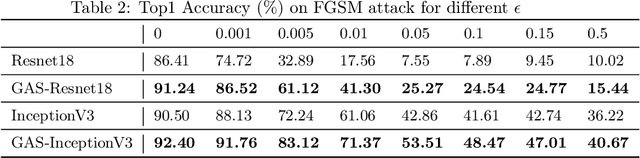
Convolutional Neural Networks (CNNs) have achieved outstanding performance on image processing challenges. Actually, CNNs imitate the typically developed human brain structures at the micro-level (Artificial neurons). At the same time, they distance themselves from imitating natural visual perception in humans at the macro architectures (high-level cognition). Recently it has been investigated that CNNs are highly biased toward local features and fail to detect the global aspects of their input. Nevertheless, the literature offers limited clues on this problem. To this end, we propose a simple yet effective solution inspired by the unconscious behavior of the human pupil. We devise a simple module called Global Advantage Stream (GAS) to learn and capture the holistic features of input samples (i.e., the global features). Then, the GAS features were combined with a CNN network as a plug-and-play component called the Global/Local Processing (GLP) model. The experimental results confirm that this stream improves the accuracy with an insignificant additional computational/temporal load and makes the network more robust to adversarial attacks. Furthermore, investigating the interpretation of the model shows that it learns a more holistic representation similar to the perceptual system of healthy humans
Ball Trajectory Inference from Multi-Agent Sports Contexts Using Set Transformer and Hierarchical Bi-LSTM
Jun 14, 2023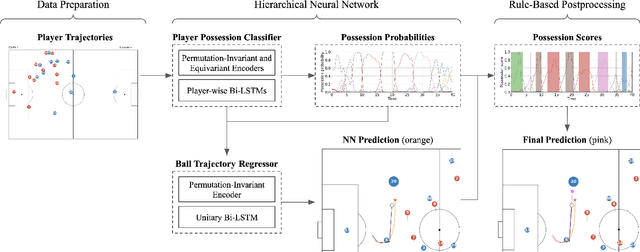
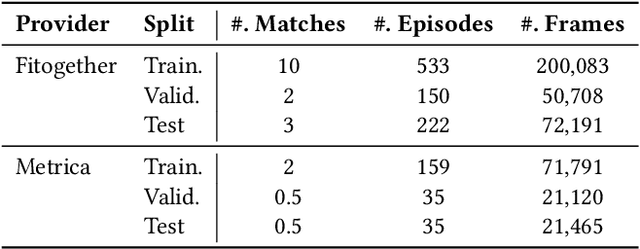
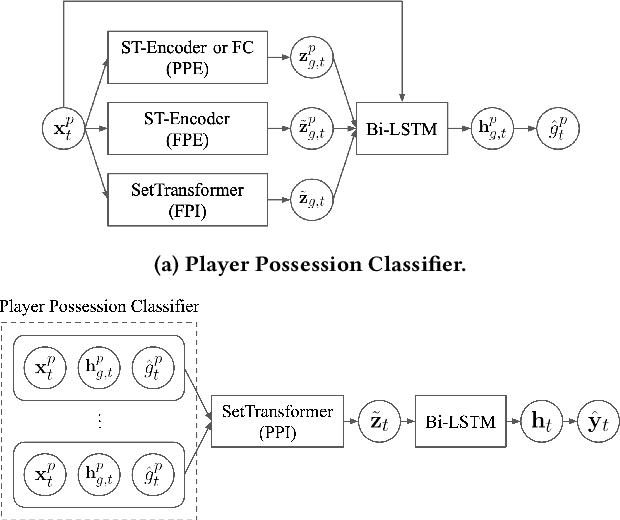
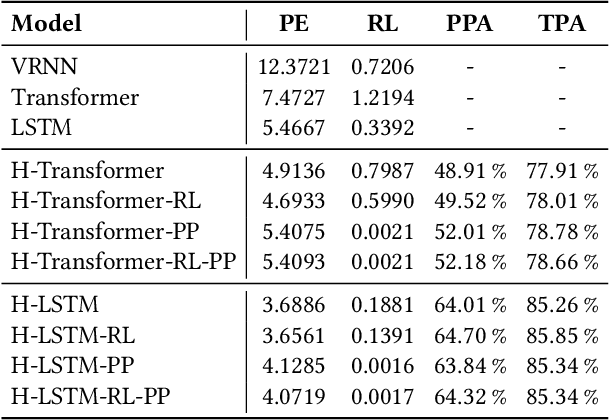
As artificial intelligence spreads out to numerous fields, the application of AI to sports analytics is also in the spotlight. However, one of the major challenges is the difficulty of automated acquisition of continuous movement data during sports matches. In particular, it is a conundrum to reliably track a tiny ball on a wide soccer pitch with obstacles such as occlusion and imitations. Tackling the problem, this paper proposes an inference framework of ball trajectory from player trajectories as a cost-efficient alternative to ball tracking. We combine Set Transformers to get permutation-invariant and equivariant representations of the multi-agent contexts with a hierarchical architecture that intermediately predicts the player ball possession to support the final trajectory inference. Also, we introduce the reality loss term and postprocessing to secure the estimated trajectories to be physically realistic. The experimental results show that our model provides natural and accurate trajectories as well as admissible player ball possession at the same time. Lastly, we suggest several practical applications of our framework including missing trajectory imputation, semi-automated pass annotation, automated zoom-in for match broadcasting, and calculating possession-wise running performance metrics.
GPU-Accelerated Verification of Machine Learning Models for Power Systems
Jun 18, 2023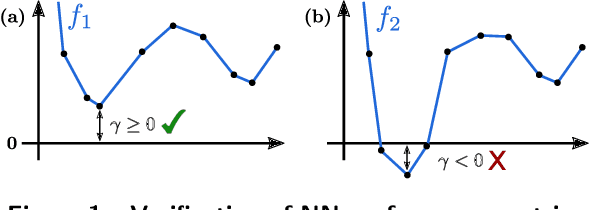
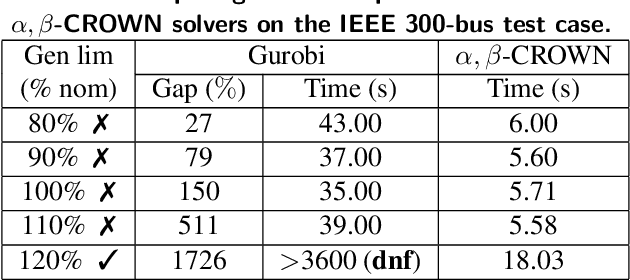
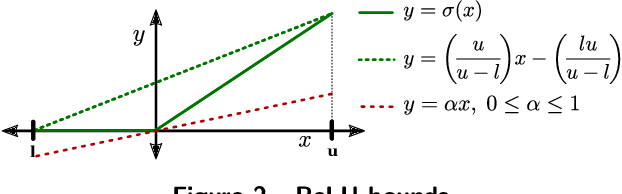
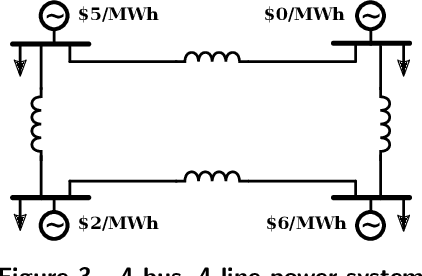
Computational tools for rigorously verifying the performance of large-scale machine learning (ML) models have progressed significantly in recent years. The most successful solvers employ highly specialized, GPU-accelerated branch and bound routines. Such tools are crucial for the successful deployment of machine learning applications in safety-critical systems, such as power systems. Despite their successes, however, barriers prevent out-of-the-box application of these routines to power system problems. This paper addresses this issue in two key ways. First, for the first time to our knowledge, we enable the simultaneous verification of multiple verification problems (e.g., checking for the violation of all line flow constraints simultaneously and not by solving individual verification problems). For that, we introduce an exact transformation that converts the "worst-case" violation across a set of potential violations to a series of ReLU-based layers that augment the original neural network. This allows verifiers to interpret them directly. Second, power system ML models often must be verified to satisfy power flow constraints. We propose a dualization procedure which encodes linear equality and inequality constraints directly into the verification problem; and in a manner which is mathematically consistent with the specialized verification tools. To demonstrate these innovations, we verify problems associated with data-driven security constrained DC-OPF solvers. We build and test our first set of innovations using the $\alpha,\beta$-CROWN solver, and we benchmark against Gurobi 10.0. Our contributions achieve a speedup that can exceed 100x and allow higher degrees of verification flexibility.
A unified recipe for deriving (time-uniform) PAC-Bayes bounds
Feb 20, 2023

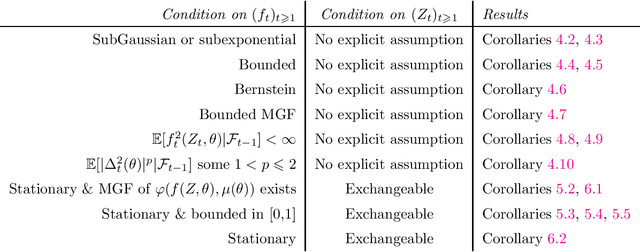
We present a unified framework for deriving PAC-Bayesian generalization bounds. Unlike most previous literature on this topic, our bounds are anytime-valid (i.e., time-uniform), meaning that they hold at all stopping times, not only for a fixed sample size. Our approach combines four tools in the following order: (a) nonnegative supermartingales or reverse submartingales, (b) the method of mixtures, (c) the Donsker-Varadhan formula (or other convex duality principles), and (d) Ville's inequality. Our main result is a PAC-Bayes theorem which holds for a wide class of discrete stochastic processes. We show how this result implies time-uniform versions of well-known classical PAC-Bayes bounds, such as those of Seeger, McAllester, Maurer, and Catoni, in addition to many recent bounds. We also present several novel bounds. Our framework also enables us to relax traditional assumptions; in particular, we consider nonstationary loss functions and non-i.i.d. data. In sum, we unify the derivation of past bounds and ease the search for future bounds: one may simply check if our supermartingale or submartingale conditions are met and, if so, be guaranteed a (time-uniform) PAC-Bayes bound.
On Robot Grasp Learning Using Equivariant Models
Jun 10, 2023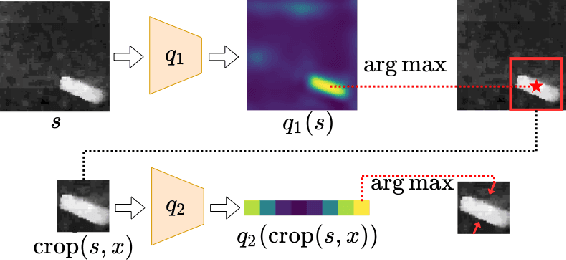

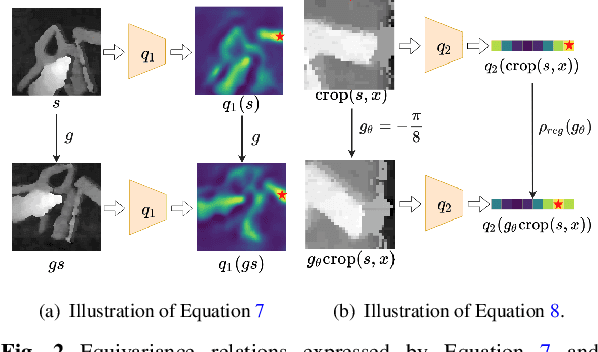

Real-world grasp detection is challenging due to the stochasticity in grasp dynamics and the noise in hardware. Ideally, the system would adapt to the real world by training directly on physical systems. However, this is generally difficult due to the large amount of training data required by most grasp learning models. In this paper, we note that the planar grasp function is $\SE(2)$-equivariant and demonstrate that this structure can be used to constrain the neural network used during learning. This creates an inductive bias that can significantly improve the sample efficiency of grasp learning and enable end-to-end training from scratch on a physical robot with as few as $600$ grasp attempts. We call this method Symmetric Grasp learning (SymGrasp) and show that it can learn to grasp ``from scratch'' in less that 1.5 hours of physical robot time.
An evaluation of time series forecasting models on water consumption data: A case study of Greece
Mar 30, 2023
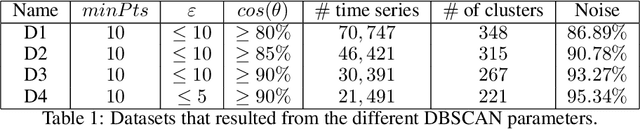
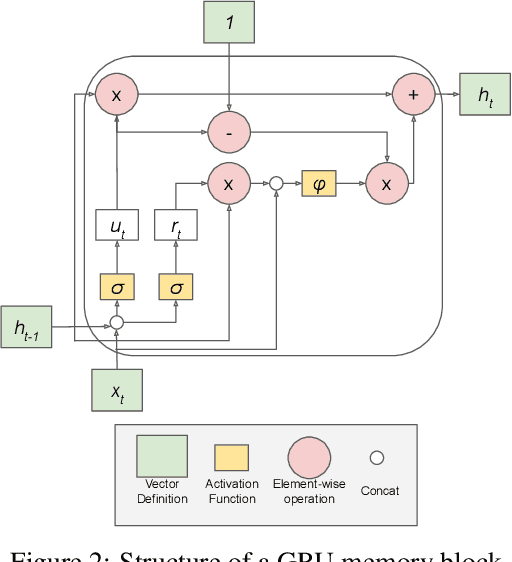
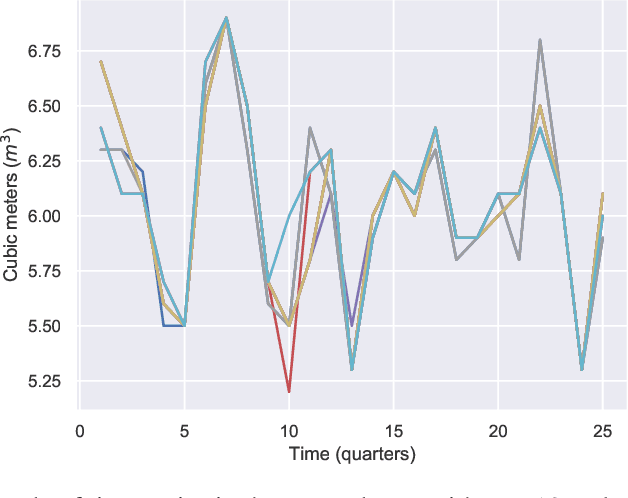
In recent years, the increased urbanization and industrialization has led to a rising water demand and resources, thus increasing the gap between demand and supply. Proper water distribution and forecasting of water consumption are key factors in mitigating the imbalance of supply and demand by improving operations, planning and management of water resources. To this end, in this paper, several well-known forecasting algorithms are evaluated over time series, water consumption data from Greece, a country with diverse socio-economic and urbanization issues. The forecasting algorithms are evaluated on a real-world dataset provided by the Water Supply and Sewerage Company of Greece revealing key insights about each algorithm and its use.