 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023
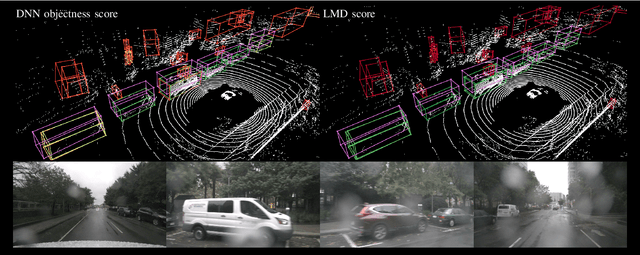
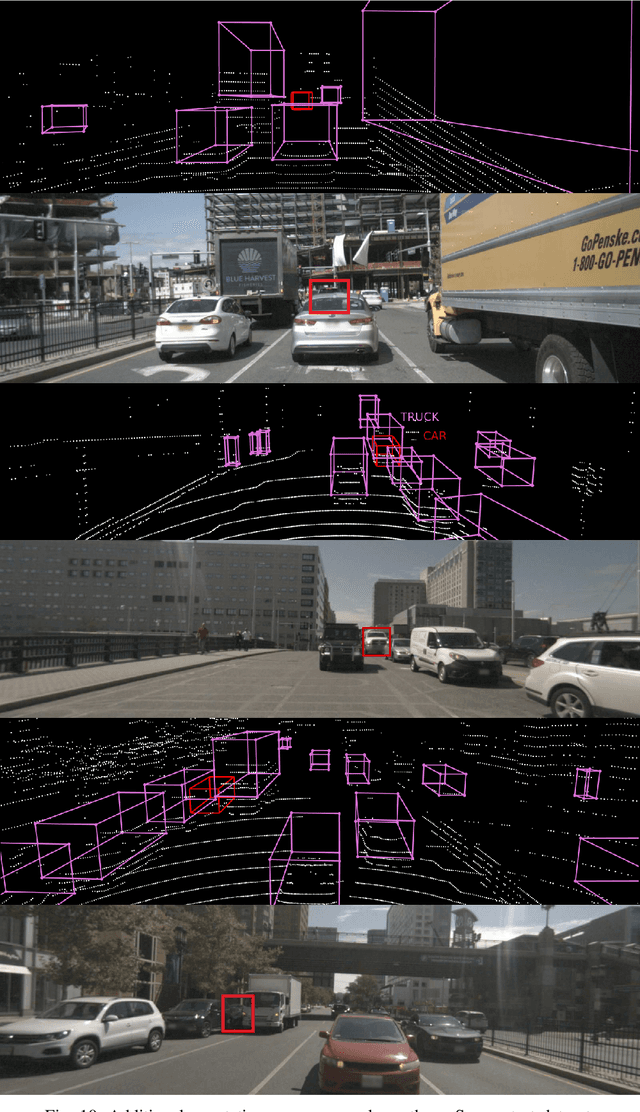

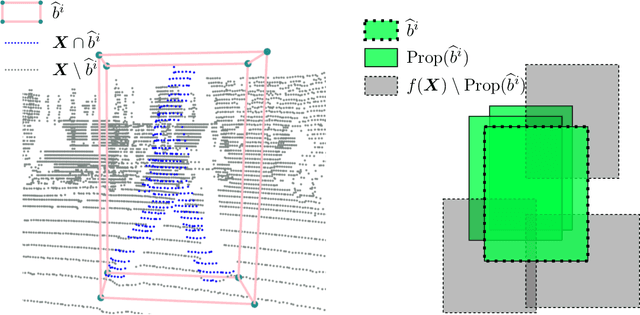
Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
LOVM: Language-Only Vision Model Selection
Jun 15, 2023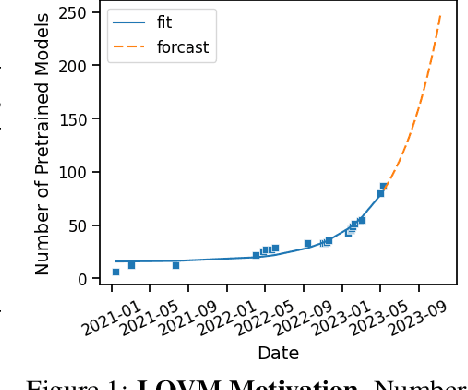
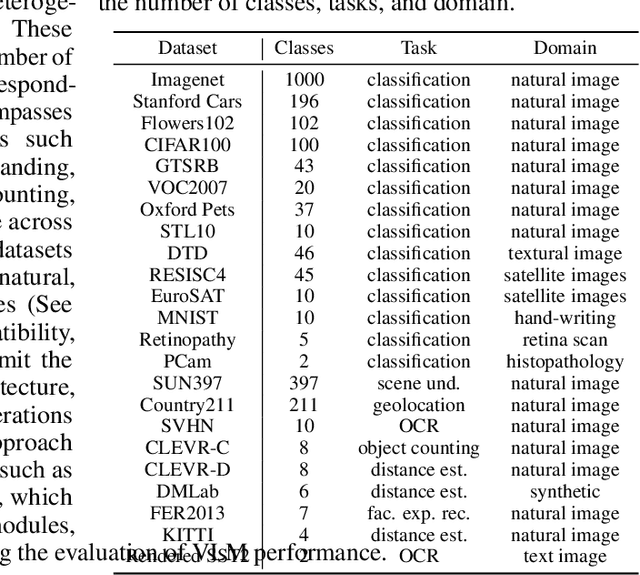
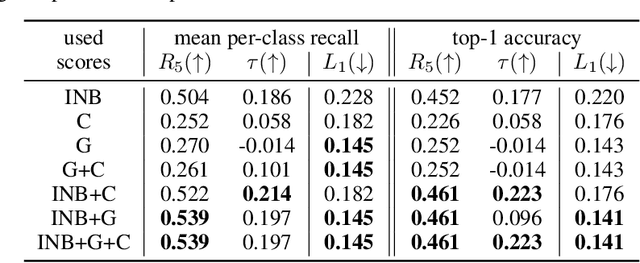

Pre-trained multi-modal vision-language models (VLMs) are becoming increasingly popular due to their exceptional performance on downstream vision applications, particularly in the few- and zero-shot settings. However, selecting the best-performing VLM for some downstream applications is non-trivial, as it is dataset and task-dependent. Meanwhile, the exhaustive evaluation of all available VLMs on a novel application is not only time and computationally demanding but also necessitates the collection of a labeled dataset for evaluation. As the number of open-source VLM variants increases, there is a need for an efficient model selection strategy that does not require access to a curated evaluation dataset. This paper proposes a novel task and benchmark for efficiently evaluating VLMs' zero-shot performance on downstream applications without access to the downstream task dataset. Specifically, we introduce a new task LOVM: Language-Only Vision Model Selection, where methods are expected to perform both model selection and performance prediction based solely on a text description of the desired downstream application. We then introduced an extensive LOVM benchmark consisting of ground-truth evaluations of 35 pre-trained VLMs and 23 datasets, where methods are expected to rank the pre-trained VLMs and predict their zero-shot performance.
Online Heavy-tailed Change-point detection
Jun 15, 2023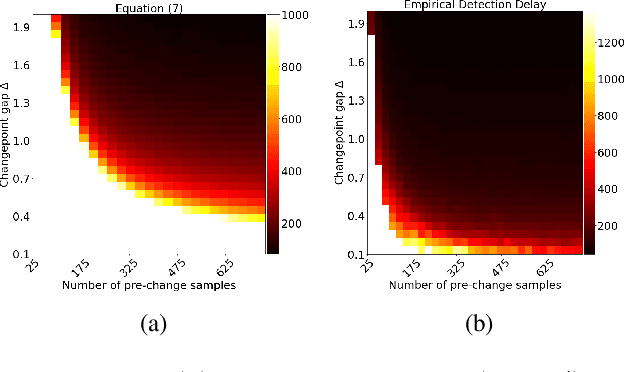
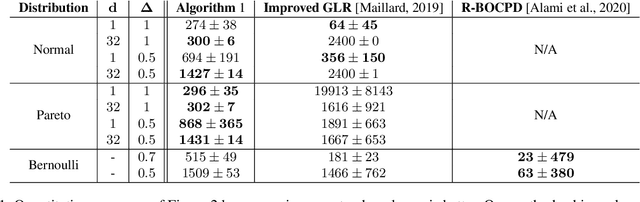
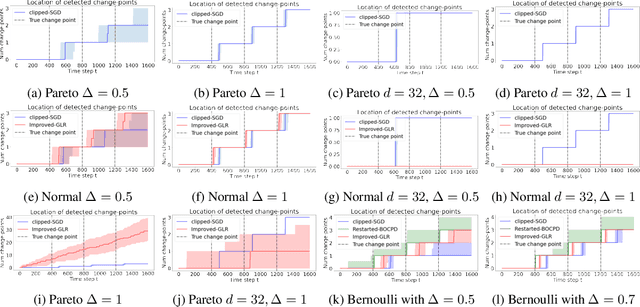

We study algorithms for online change-point detection (OCPD), where samples that are potentially heavy-tailed, are presented one at a time and a change in the underlying mean must be detected as early as possible. We present an algorithm based on clipped Stochastic Gradient Descent (SGD), that works even if we only assume that the second moment of the data generating process is bounded. We derive guarantees on worst-case, finite-sample false-positive rate (FPR) over the family of all distributions with bounded second moment. Thus, our method is the first OCPD algorithm that guarantees finite-sample FPR, even if the data is high dimensional and the underlying distributions are heavy-tailed. The technical contribution of our paper is to show that clipped-SGD can estimate the mean of a random vector and simultaneously provide confidence bounds at all confidence values. We combine this robust estimate with a union bound argument and construct a sequential change-point algorithm with finite-sample FPR guarantees. We show empirically that our algorithm works well in a variety of situations, whether the underlying data are heavy-tailed, light-tailed, high dimensional or discrete. No other algorithm achieves bounded FPR theoretically or empirically, over all settings we study simultaneously.
Equitable Multi-task Learning
Jun 15, 2023Multi-task learning (MTL) has achieved great success in various research domains, such as CV, NLP and IR etc. Due to the complex and competing task correlation, na\"ive training all tasks may lead to inequitable learning, \textit{i.e.} some tasks are learned well while others are overlooked. Multi-task optimization (MTO) aims to improve all tasks at same time, but conventional methods often perform poor when tasks with large loss scale or gradient norm magnitude difference. To solve the issue, we in-depth investigate the equity problem for MTL and find that regularizing relative contribution of different tasks (\textit{i.e.} value of task-specific loss divides its raw gradient norm) in updating shared parameter can improve generalization performance of MTL. Based on our theoretical analysis, we propose a novel multi-task optimization method, named \textit{EMTL}, to achieve equitable MTL. Specifically, we efficiently add variance regularization to make different tasks' relative contribution closer. Extensive experiments have been conduct to evaluate EMTL, our method stably outperforms state-of-the-art methods on the public benchmark datasets of two different research domains. Furthermore, offline and online A/B test on multi-task recommendation are conducted too. EMTL improves multi-task recommendation significantly, demonstrating the superiority and practicability of our method in industrial landscape.
OMS-DPM: Optimizing the Model Schedule for Diffusion Probabilistic Models
Jun 15, 2023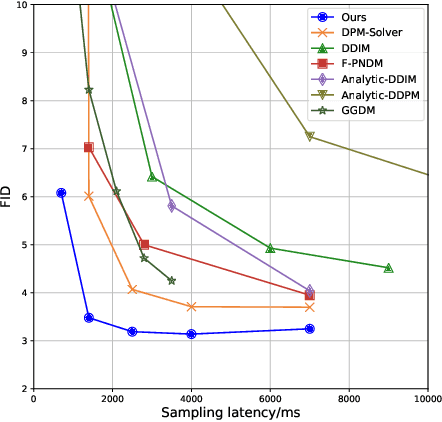
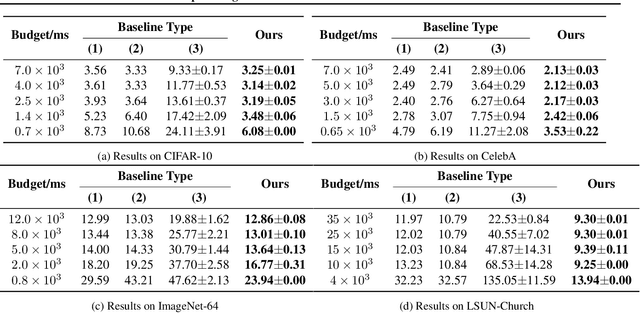
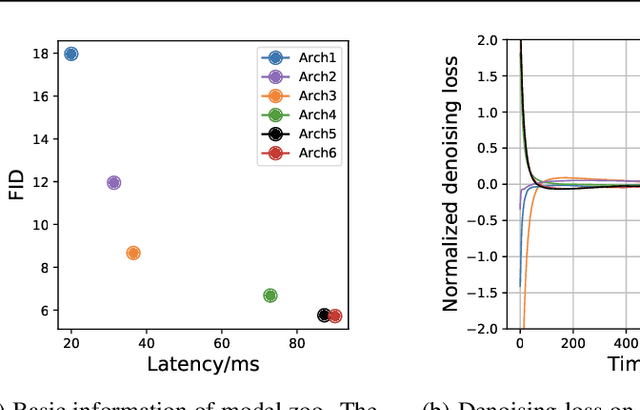
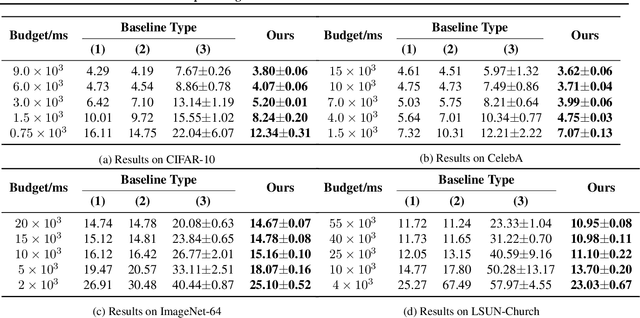
Diffusion probabilistic models (DPMs) are a new class of generative models that have achieved state-of-the-art generation quality in various domains. Despite the promise, one major drawback of DPMs is the slow generation speed due to the large number of neural network evaluations required in the generation process. In this paper, we reveal an overlooked dimension -- model schedule -- for optimizing the trade-off between generation quality and speed. More specifically, we observe that small models, though having worse generation quality when used alone, could outperform large models in certain generation steps. Therefore, unlike the traditional way of using a single model, using different models in different generation steps in a carefully designed \emph{model schedule} could potentially improve generation quality and speed \emph{simultaneously}. We design OMS-DPM, a predictor-based search algorithm, to optimize the model schedule given an arbitrary generation time budget and a set of pre-trained models. We demonstrate that OMS-DPM can find model schedules that improve generation quality and speed than prior state-of-the-art methods across CIFAR-10, CelebA, ImageNet, and LSUN datasets. When applied to the public checkpoints of the Stable Diffusion model, we are able to accelerate the sampling by 2$\times$ while maintaining the generation quality.
Towards Faster Non-Asymptotic Convergence for Diffusion-Based Generative Models
Jun 15, 2023Diffusion models, which convert noise into new data instances by learning to reverse a Markov diffusion process, have become a cornerstone in contemporary generative modeling. While their practical power has now been widely recognized, the theoretical underpinnings remain far from mature. In this work, we develop a suite of non-asymptotic theory towards understanding the data generation process of diffusion models in discrete time, assuming access to reliable estimates of the (Stein) score functions. For a popular deterministic sampler (based on the probability flow ODE), we establish a convergence rate proportional to $1/T$ (with $T$ the total number of steps), improving upon past results; for another mainstream stochastic sampler (i.e., a type of the denoising diffusion probabilistic model (DDPM)), we derive a convergence rate proportional to $1/\sqrt{T}$, matching the state-of-the-art theory. Our theory imposes only minimal assumptions on the target data distribution (e.g., no smoothness assumption is imposed), and is developed based on an elementary yet versatile non-asymptotic approach without resorting to toolboxes for SDEs and ODEs. Further, we design two accelerated variants, improving the convergence to $1/T^2$ for the ODE-based sampler and $1/T$ for the DDPM-type sampler, which might be of independent theoretical and empirical interest.
Map Reconstruction of radio observations with Conditional Invertible Neural Networks
Jun 15, 2023In radio astronomy, the challenge of reconstructing a sky map from time ordered data (TOD) is known as an inverse problem. Standard map-making techniques and gridding algorithms are commonly employed to address this problem, each offering its own benefits such as producing minimum-variance maps. However, these approaches also carry limitations such as computational inefficiency and numerical instability in map-making and the inability to remove beam effects in grid-based methods. To overcome these challenges, this study proposes a novel solution through the use of the conditional invertible neural network (cINN) for efficient sky map reconstruction. With the aid of forward modeling, where the simulated TODs are generated from a given sky model with a specific observation, the trained neural network can produce accurate reconstructed sky maps. Using the five-hundred-meter aperture spherical radio telescope (FAST) as an example, cINN demonstrates remarkable performance in map reconstruction from simulated TODs, achieving a mean squared error of $2.29\pm 2.14 \times 10^{-4}~\rm K^2$, a structural similarity index of $0.968\pm0.002$, and a peak signal-to-noise ratio of $26.13\pm5.22$ at the $1\sigma$ level. Furthermore, by sampling in the latent space of cINN, the reconstruction errors for each pixel can be accurately quantified.
Memory-Based Dual Gaussian Processes for Sequential Learning
Jun 06, 2023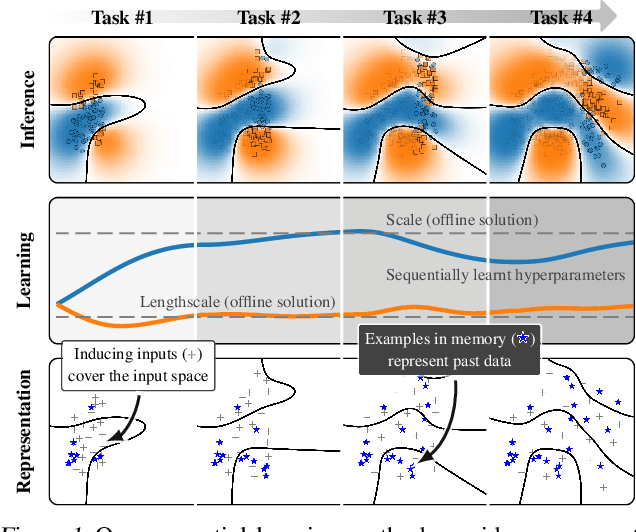
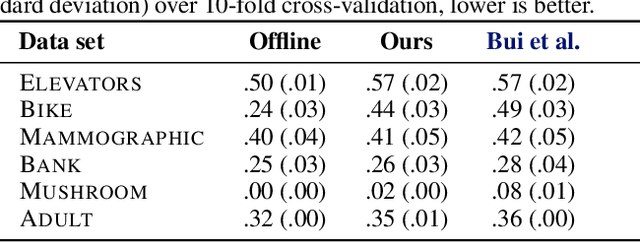

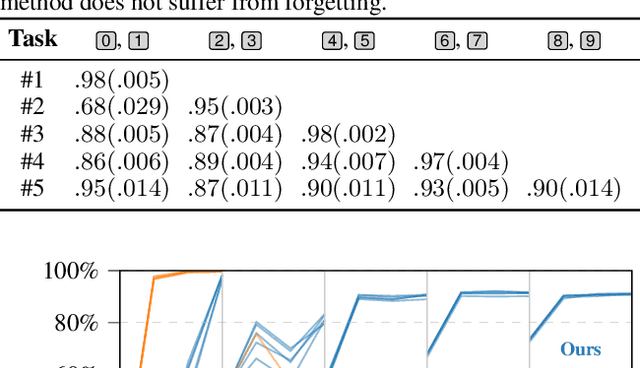
Sequential learning with Gaussian processes (GPs) is challenging when access to past data is limited, for example, in continual and active learning. In such cases, errors can accumulate over time due to inaccuracies in the posterior, hyperparameters, and inducing points, making accurate learning challenging. Here, we present a method to keep all such errors in check using the recently proposed dual sparse variational GP. Our method enables accurate inference for generic likelihoods and improves learning by actively building and updating a memory of past data. We demonstrate its effectiveness in several applications involving Bayesian optimization, active learning, and continual learning.
HePCo: Data-Free Heterogeneous Prompt Consolidation for Continual Federated Learning
Jun 16, 2023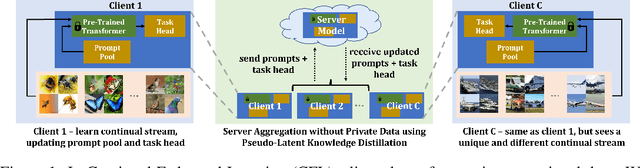

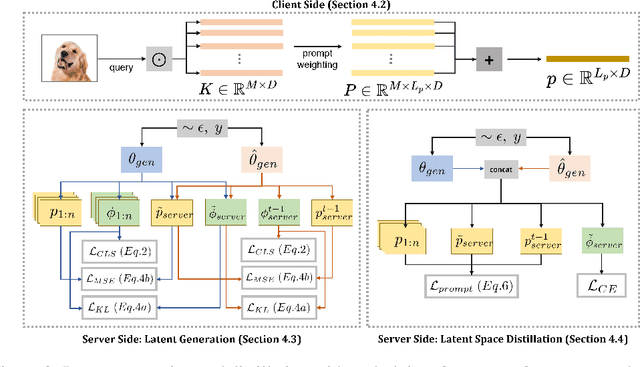

In this paper, we focus on the important yet understudied problem of Continual Federated Learning (CFL), where a server communicates with a set of clients to incrementally learn new concepts over time without sharing or storing any data. The complexity of this problem is compounded by challenges from both the Continual and Federated Learning perspectives. Specifically, models trained in a CFL setup suffer from catastrophic forgetting which is exacerbated by data heterogeneity across clients. Existing attempts at this problem tend to impose large overheads on clients and communication channels or require access to stored data which renders them unsuitable for real-world use due to privacy. In this paper, we attempt to tackle forgetting and heterogeneity while minimizing overhead costs and without requiring access to any stored data. We achieve this by leveraging a prompting based approach (such that only prompts and classifier heads have to be communicated) and proposing a novel and lightweight generation and distillation scheme to consolidate client models at the server. We formulate this problem for image classification and establish strong baselines for comparison, conduct experiments on CIFAR-100 as well as challenging, large-scale datasets like ImageNet-R and DomainNet. Our approach outperforms both existing methods and our own baselines by as much as 7% while significantly reducing communication and client-level computation costs.
Catastrophic Forgetting in the Context of Model Updates
Jun 16, 2023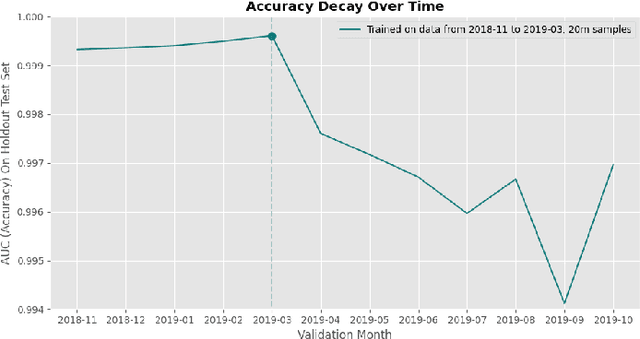
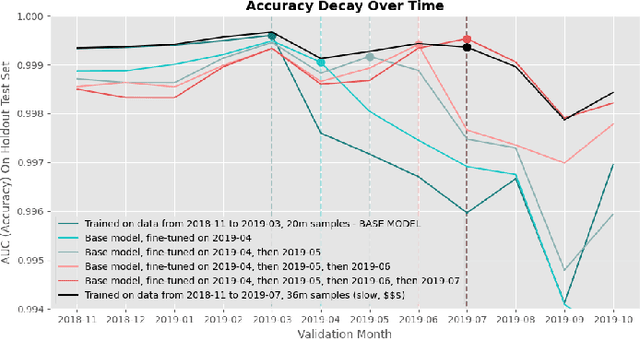
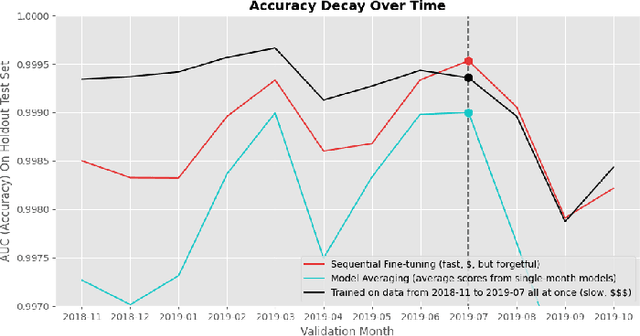
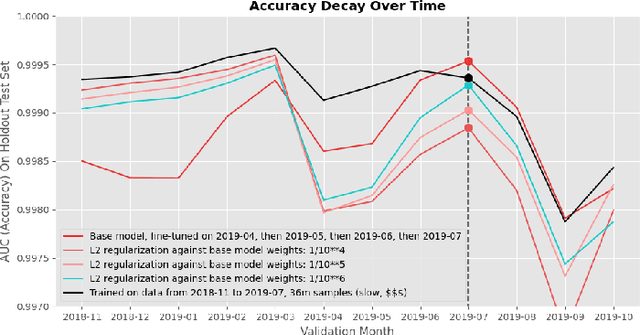
A large obstacle to deploying deep learning models in practice is the process of updating models post-deployment (ideally, frequently). Deep neural networks can cost many thousands of dollars to train. When new data comes in the pipeline, you can train a new model from scratch (randomly initialized weights) on all existing data. Instead, you can take an existing model and fine-tune (continue to train) it on new data. The former is costly and slow. The latter is cheap and fast, but catastrophic forgetting generally causes the new model to 'forget' how to classify older data well. There are a plethora of complicated techniques to keep models from forgetting their past learnings. Arguably the most basic is to mix in a small amount of past data into the new data during fine-tuning: also known as 'data rehearsal'. In this paper, we compare various methods of limiting catastrophic forgetting and conclude that if you can maintain access to a portion of your past data (or tasks), data rehearsal is ideal in terms of overall accuracy across all time periods, and performs even better when combined with methods like Elastic Weight Consolidation (EWC). Especially when the amount of past data (past 'tasks') is large compared to new data, the cost of updating an existing model is far cheaper and faster than training a new model from scratch.