 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023
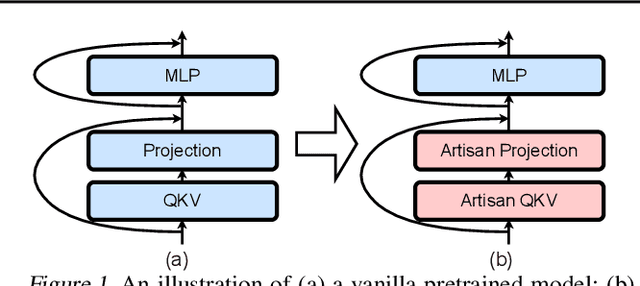
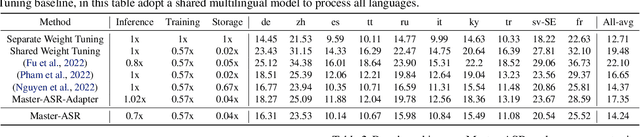
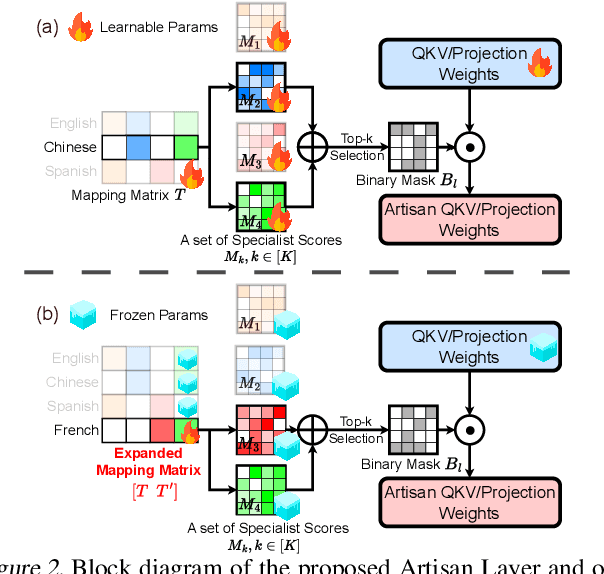
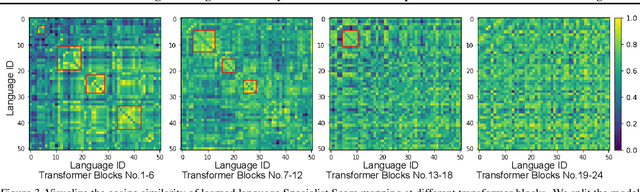
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.
Human Activity Behavioural Pattern Recognition in Smarthome with Long-hour Data Collection
Jun 23, 2023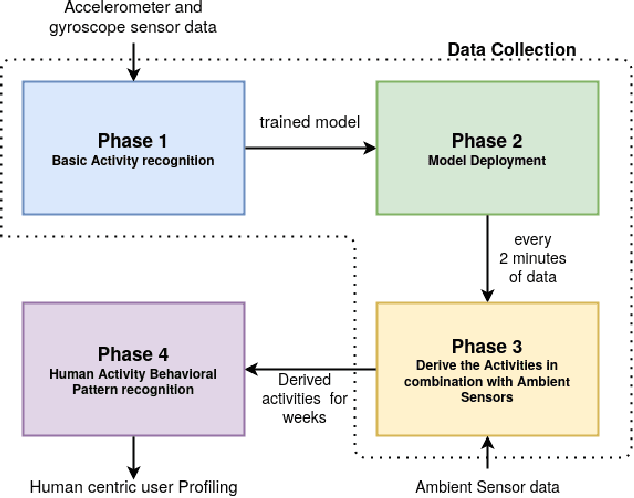
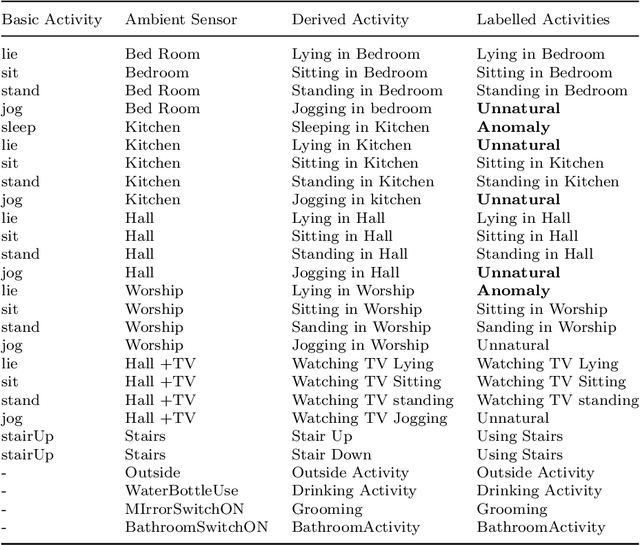
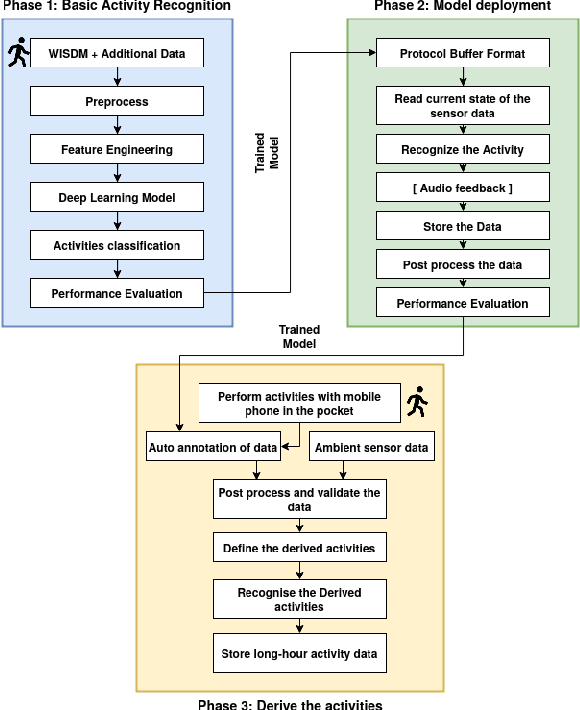
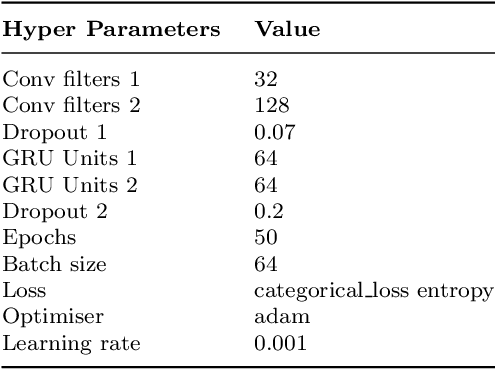
The research on human activity recognition has provided novel solutions to many applications like healthcare, sports, and user profiling. Considering the complex nature of human activities, it is still challenging even after effective and efficient sensors are available. The existing works on human activity recognition using smartphone sensors focus on recognizing basic human activities like sitting, sleeping, standing, stair up and down and running. However, more than these basic activities is needed to analyze human behavioural pattern. The proposed framework recognizes basic human activities using deep learning models. Also, ambient sensors like PIR, pressure sensors, and smartphone-based sensors like accelerometers and gyroscopes are combined to make it hybrid-sensor-based human activity recognition. The hybrid approach helped derive more activities than the basic ones, which also helped derive human activity patterns or user profiling. User profiling provides sufficient information to identify daily living activity patterns and predict whether any anomaly exists. The framework provides the base for applications such as elderly monitoring when they are alone at home. The GRU model's accuracy of 95\% is observed to recognize the basic activities. Finally, Human activity patterns over time are recognized based on the duration and frequency of the activities. It is observed that human activity pattern, like, morning walking duration, varies depending on the day of the week.
Cross-CBAM: A Lightweight network for Scene Segmentation
Jun 04, 2023
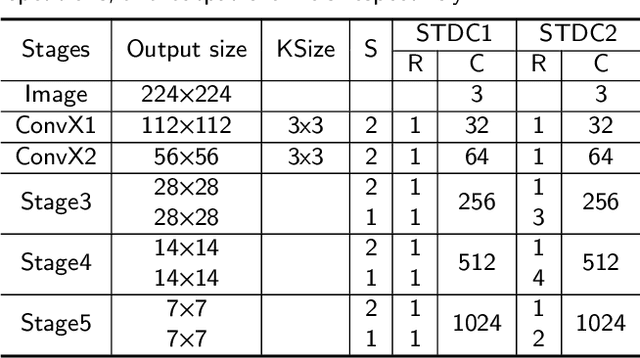
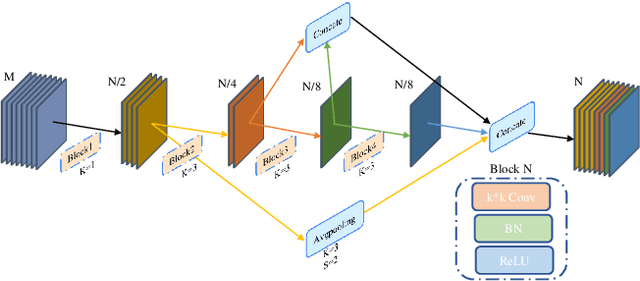
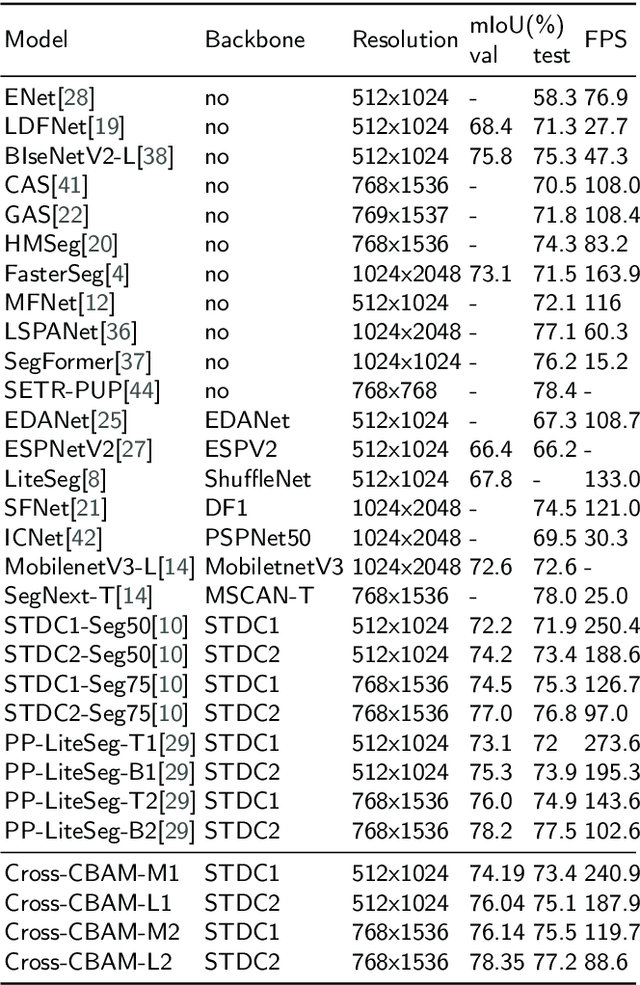
Scene parsing is a great challenge for real-time semantic segmentation. Although traditional semantic segmentation networks have made remarkable leap-forwards in semantic accuracy, the performance of inference speed is unsatisfactory. Meanwhile, this progress is achieved with fairly large networks and powerful computational resources. However, it is difficult to run extremely large models on edge computing devices with limited computing power, which poses a huge challenge to the real-time semantic segmentation tasks. In this paper, we present the Cross-CBAM network, a novel lightweight network for real-time semantic segmentation. Specifically, a Squeeze-and-Excitation Atrous Spatial Pyramid Pooling Module(SE-ASPP) is proposed to get variable field-of-view and multiscale information. And we propose a Cross Convolutional Block Attention Module(CCBAM), in which a cross-multiply operation is employed in the CCBAM module to make high-level semantic information guide low-level detail information. Different from previous work, these works use attention to focus on the desired information in the backbone. CCBAM uses cross-attention for feature fusion in the FPN structure. Extensive experiments on the Cityscapes dataset and Camvid dataset demonstrate the effectiveness of the proposed Cross-CBAM model by achieving a promising trade-off between segmentation accuracy and inference speed. On the Cityscapes test set, we achieve 73.4% mIoU with a speed of 240.9FPS and 77.2% mIoU with a speed of 88.6FPS on NVIDIA GTX 1080Ti.
A Bio-Inspired Chaos Sensor Based on the Perceptron Neural Network: Concept and Application for Computational Neuro-science
Jun 03, 2023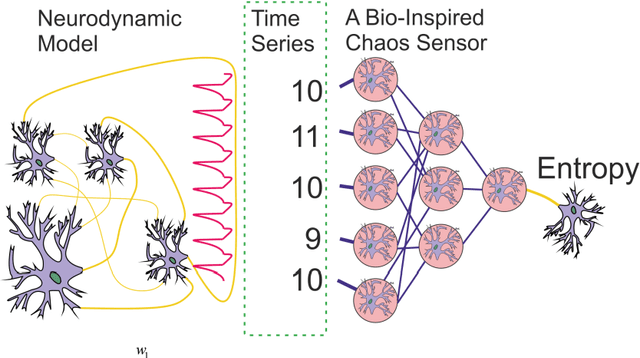

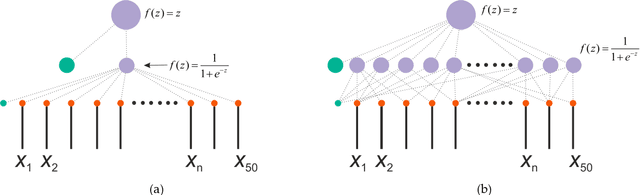
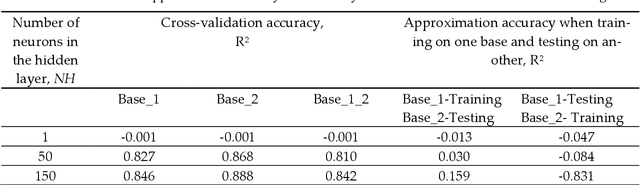
The study presents a bio-inspired chaos sensor based on the perceptron neural network. After training, the sensor on perceptron, having 50 neurons in the hidden layer and 1 neuron at the output, approximates the fuzzy entropy of short time series with high accuracy with a determination coefficient R2 ~ 0.9. The Hindmarsh-Rose spike model was used to generate time series of spike intervals, and datasets for training and testing the perceptron. The selection of the hyperparameters of the perceptron model and the estimation of the sensor accuracy were performed using the K-block cross-validation method. Even for a hidden layer with 1 neuron, the model approximates the fuzzy entropy with good results and the metric R2 ~ 0.5-0.8. In a simplified model with 1 neuron and equal weights in the first layer, the principle of approximation is based on the linear transformation of the average value of the time series into the entropy value. The bio-inspired chaos sensor model based on an ensemble of neurons is able to dynamically track the chaotic behavior of a spiked biosystem and transmit this information to other parts of the bio-system for further processing. The study will be useful for specialists in the field of computational neuroscience.
Fully Dynamic Submodular Maximization over Matroids
May 31, 2023Maximizing monotone submodular functions under a matroid constraint is a classic algorithmic problem with multiple applications in data mining and machine learning. We study this classic problem in the fully dynamic setting, where elements can be both inserted and deleted in real-time. Our main result is a randomized algorithm that maintains an efficient data structure with an $\tilde{O}(k^2)$ amortized update time (in the number of additions and deletions) and yields a $4$-approximate solution, where $k$ is the rank of the matroid.
Studying Generalization on Memory-Based Methods in Continual Learning
Jun 16, 2023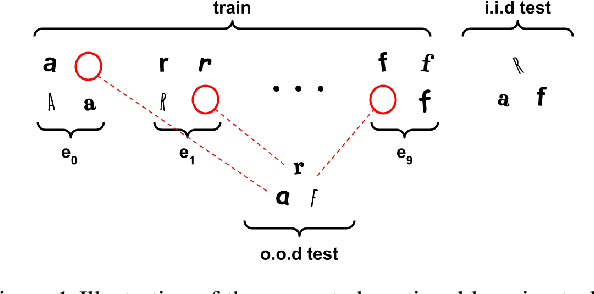
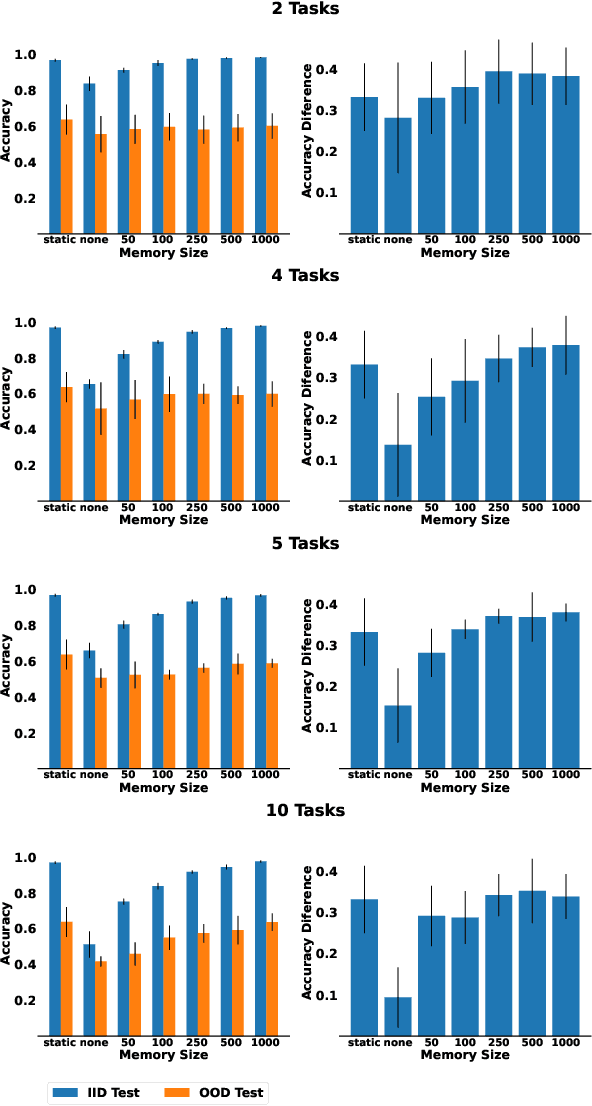
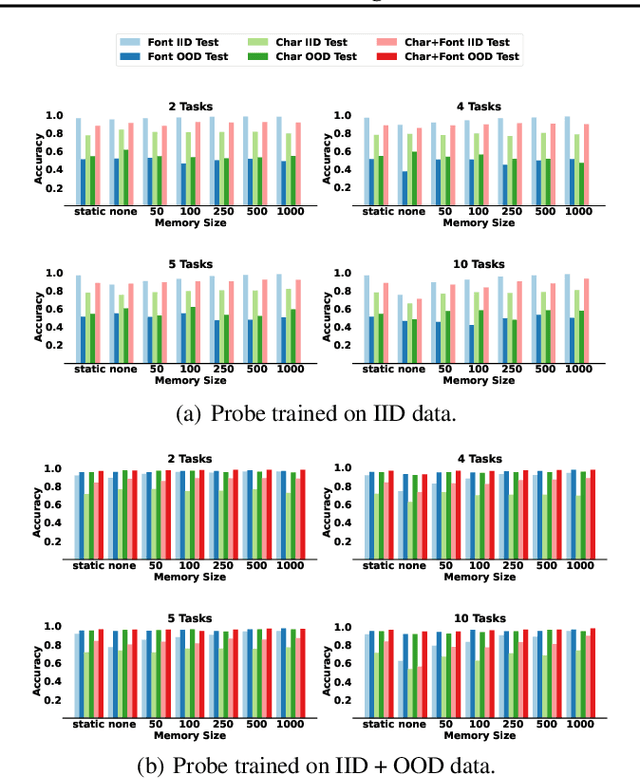
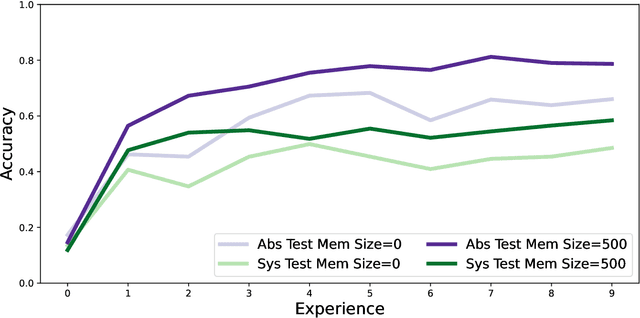
One of the objectives of Continual Learning is to learn new concepts continually over a stream of experiences and at the same time avoid catastrophic forgetting. To mitigate complete knowledge overwriting, memory-based methods store a percentage of previous data distributions to be used during training. Although these methods produce good results, few studies have tested their out-of-distribution generalization properties, as well as whether these methods overfit the replay memory. In this work, we show that although these methods can help in traditional in-distribution generalization, they can strongly impair out-of-distribution generalization by learning spurious features and correlations. Using a controlled environment, the Synbol benchmark generator (Lacoste et al., 2020), we demonstrate that this lack of out-of-distribution generalization mainly occurs in the linear classifier.
FAMO: Fast Adaptive Multitask Optimization
Jun 06, 2023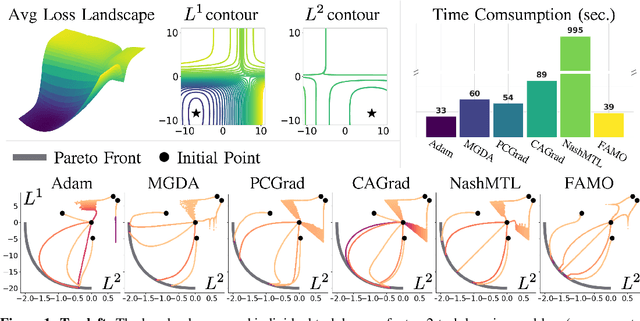
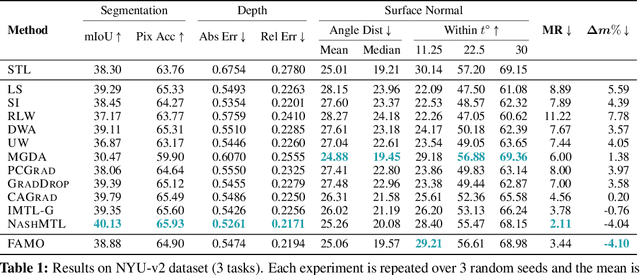
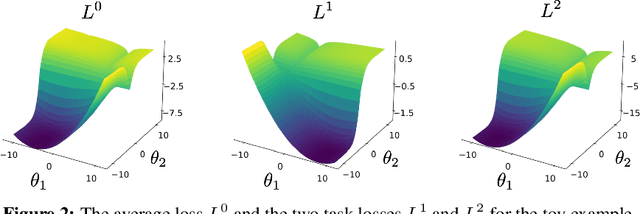
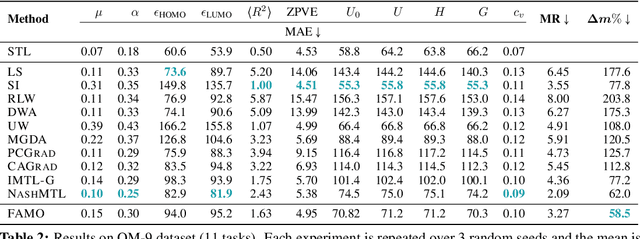
One of the grand enduring goals of AI is to create generalist agents that can learn multiple different tasks from diverse data via multitask learning (MTL). However, gradient descent (GD) on the average loss across all tasks may yield poor multitask performance due to severe under-optimization of certain tasks. Previous approaches that manipulate task gradients for a more balanced loss decrease require storing and computing all task gradients (O(K) space and time where K is the number of tasks), limiting their use in large-scale scenarios. In this work, we introduce Fast Adaptive Multitask Optimization (FAMO), a dynamic weighting method that decreases task losses in a balanced way using O(1) space and time. We conduct an extensive set of experiments covering multi-task supervised and reinforcement learning problems. Our results indicate that FAMO achieves comparable or superior performance to state-of-the-art gradient manipulation techniques while offering significant improvements in space and computational efficiency. Code is available at https://github.com/Cranial-XIX/FAMO.
Rigorous Runtime Analysis of MOEA/D for Solving Multi-Objective Minimum Weight Base Problems
Jun 06, 2023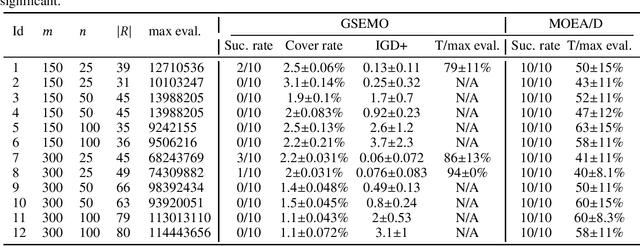
We study the multi-objective minimum weight base problem, an abstraction of classical NP-hard combinatorial problems such as the multi-objective minimum spanning tree problem. We prove some important properties of the convex hull of the non-dominated front, such as its approximation quality and an upper bound on the number of extreme points. Using these properties, we give the first run-time analysis of the MOEA/D algorithm for this problem, an evolutionary algorithm that effectively optimizes by decomposing the objectives into single-objective components. We show that the MOEA/D, given an appropriate decomposition setting, finds all extreme points within expected fixed-parameter polynomial time in the oracle model, the parameter being the number of objectives. Experiments are conducted on random bi-objective minimum spanning tree instances, and the results agree with our theoretical findings. Furthermore, compared with a previously studied evolutionary algorithm for the problem GSEMO, MOEA/D finds all extreme points much faster across all instances.
Quantifying Causes of Arctic Amplification via Deep Learning based Time-series Causal Inference
Mar 14, 2023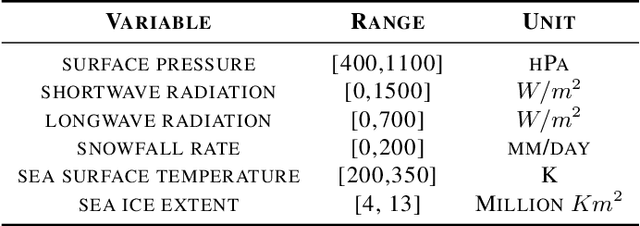
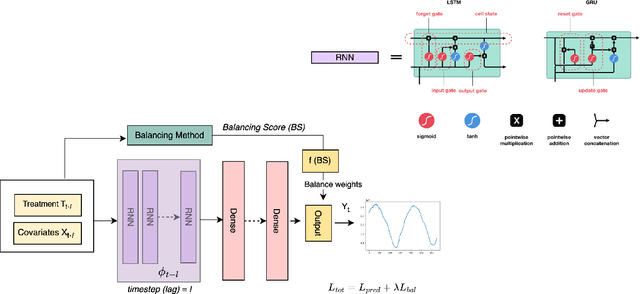

The warming of the Arctic, also known as Arctic amplification, is led by several atmospheric and oceanic drivers, however, the details of its underlying thermodynamic causes are still unknown. Inferring the causal effects of atmospheric processes on sea ice melt using fixed treatment effect strategies leads to unrealistic counterfactual estimations. Such models are also prone to bias due to time-varying confoundedness. In order to tackle these challenges, we propose TCINet - time-series causal inference model to infer causation under continuous treatment using recurrent neural networks. Through experiments on synthetic and observational data, we show how our research can substantially improve the ability to quantify the leading causes of Arctic sea ice melt.
On Consistency of Signatures Using Lasso
May 24, 2023
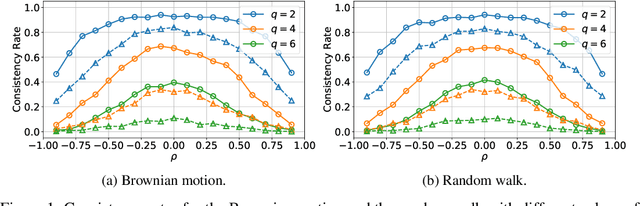
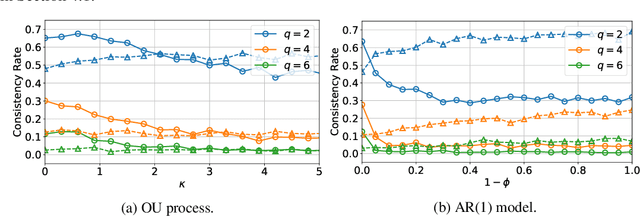
Signature transforms are iterated path integrals of continuous and discrete-time time series data, and their universal nonlinearity linearizes the problem of feature selection. This paper revisits the consistency issue of Lasso regression for the signature transform, both theoretically and numerically. Our study shows that, for processes and time series that are closer to Brownian motion or random walk with weaker inter-dimensional correlations, the Lasso regression is more consistent for their signatures defined by It\^o integrals; for mean reverting processes and time series, their signatures defined by Stratonovich integrals have more consistency in the Lasso regression. Our findings highlight the importance of choosing appropriate definitions of signatures and stochastic models in statistical inference and machine learning.