 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fit Like You Sample: Sample-Efficient Generalized Score Matching from Fast Mixing Markov Chains
Jun 20, 2023
Score matching is an approach to learning probability distributions parametrized up to a constant of proportionality (e.g. Energy-Based Models). The idea is to fit the score of the distribution, rather than the likelihood, thus avoiding the need to evaluate the constant of proportionality. While there's a clear algorithmic benefit, the statistical "cost'' can be steep: recent work by Koehler et al. 2022 showed that for distributions that have poor isoperimetric properties (a large Poincar\'e or log-Sobolev constant), score matching is substantially statistically less efficient than maximum likelihood. However, many natural realistic distributions, e.g. multimodal distributions as simple as a mixture of two Gaussians in one dimension -- have a poor Poincar\'e constant. In this paper, we show a close connection between the mixing time of an arbitrary Markov process with generator $\mathcal{L}$ and an appropriately chosen generalized score matching loss that tries to fit $\frac{\mathcal{O} p}{p}$. If $\mathcal{L}$ corresponds to a Markov process corresponding to a continuous version of simulated tempering, we show the corresponding generalized score matching loss is a Gaussian-convolution annealed score matching loss, akin to the one proposed in Song and Ermon 2019. Moreover, we show that if the distribution being learned is a finite mixture of Gaussians in $d$ dimensions with a shared covariance, the sample complexity of annealed score matching is polynomial in the ambient dimension, the diameter the means, and the smallest and largest eigenvalues of the covariance -- obviating the Poincar\'e constant-based lower bounds of the basic score matching loss shown in Koehler et al. 2022. This is the first result characterizing the benefits of annealing for score matching -- a crucial component in more sophisticated score-based approaches like Song and Ermon 2019.
Diffsurv: Differentiable sorting for censored time-to-event data
Apr 26, 2023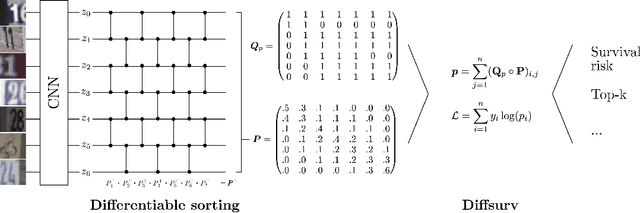

Survival analysis is a crucial semi-supervised task in machine learning with numerous real-world applications, particularly in healthcare. Currently, the most common approach to survival analysis is based on Cox's partial likelihood, which can be interpreted as a ranking model optimized on a lower bound of the concordance index. This relation between ranking models and Cox's partial likelihood considers only pairwise comparisons. Recent work has developed differentiable sorting methods which relax this pairwise independence assumption, enabling the ranking of sets of samples. However, current differentiable sorting methods cannot account for censoring, a key factor in many real-world datasets. To address this limitation, we propose a novel method called Diffsurv. We extend differentiable sorting methods to handle censored tasks by predicting matrices of possible permutations that take into account the label uncertainty introduced by censored samples. We contrast this approach with methods derived from partial likelihood and ranking losses. Our experiments show that Diffsurv outperforms established baselines in various simulated and real-world risk prediction scenarios. Additionally, we demonstrate the benefits of the algorithmic supervision enabled by Diffsurv by presenting a novel method for top-k risk prediction that outperforms current methods.
Intelligent Multi-channel Meta-imagers for Accelerating Machine Vision
Jun 12, 2023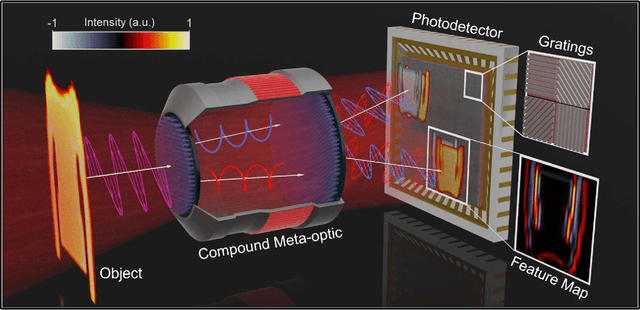
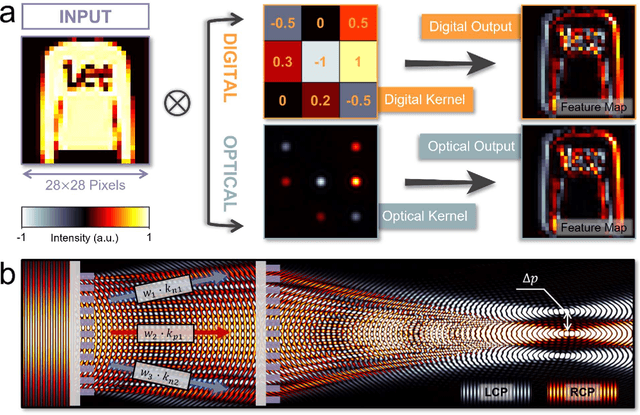
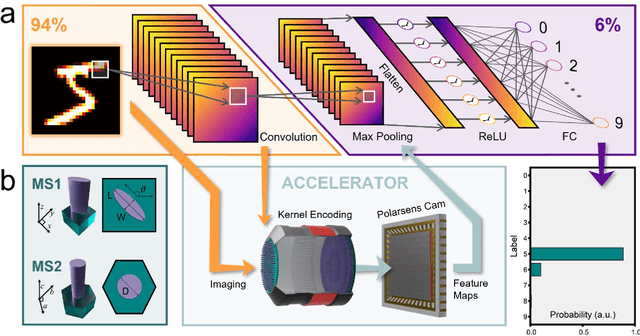
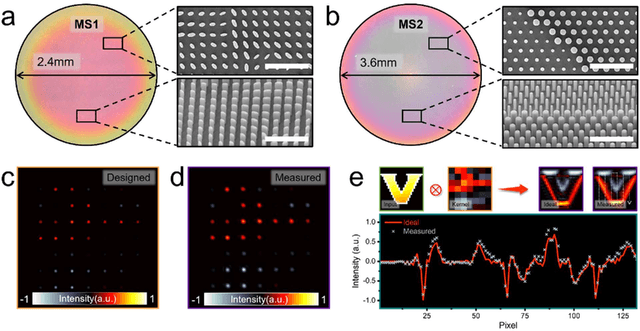
Rapid developments in machine vision have led to advances in a variety of industries, from medical image analysis to autonomous systems. These achievements, however, typically necessitate digital neural networks with heavy computational requirements, which are limited by high energy consumption and further hinder real-time decision-making when computation resources are not accessible. Here, we demonstrate an intelligent meta-imager that is designed to work in concert with a digital back-end to off-load computationally expensive convolution operations into high-speed and low-power optics. In this architecture, metasurfaces enable both angle and polarization multiplexing to create multiple information channels that perform positive and negatively valued convolution operations in a single shot. The meta-imager is employed for object classification, experimentally achieving 98.6% accurate classification of handwritten digits and 88.8% accuracy in classifying fashion images. With compactness, high speed, and low power consumption, this approach could find a wide range of applications in artificial intelligence and machine vision applications.
High-speed Autonomous Racing using Trajectory-aided Deep Reinforcement Learning
Jun 12, 2023The classical method of autonomous racing uses real-time localisation to follow a precalculated optimal trajectory. In contrast, end-to-end deep reinforcement learning (DRL) can train agents to race using only raw LiDAR scans. While classical methods prioritise optimization for high-performance racing, DRL approaches have focused on low-performance contexts with little consideration of the speed profile. This work addresses the problem of using end-to-end DRL agents for high-speed autonomous racing. We present trajectory-aided learning (TAL) that trains DRL agents for high-performance racing by incorporating the optimal trajectory (racing line) into the learning formulation. Our method is evaluated using the TD3 algorithm on four maps in the open-source F1Tenth simulator. The results demonstrate that our method achieves a significantly higher lap completion rate at high speeds compared to the baseline. This is due to TAL training the agent to select a feasible speed profile of slowing down in the corners and roughly tracking the optimal trajectory.
Reconstructing Heterogeneous Cryo-EM Molecular Structures by Decomposing Them into Polymer Chains
Jun 12, 2023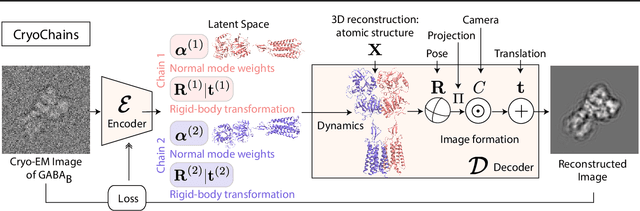
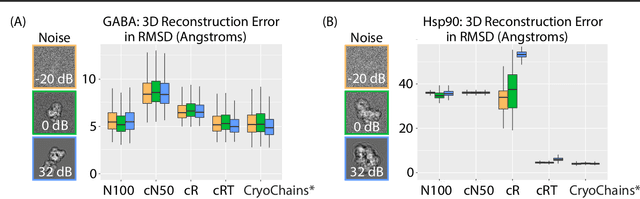
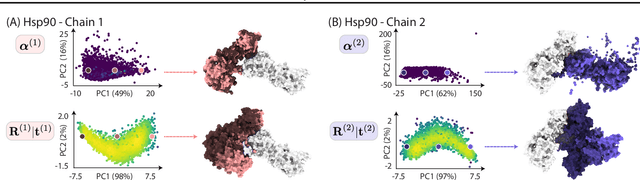

Cryogenic electron microscopy (cryo-EM) has transformed structural biology by allowing to reconstruct 3D biomolecular structures up to near-atomic resolution. However, the 3D reconstruction process remains challenging, as the 3D structures may exhibit substantial shape variations, while the 2D image acquisition suffers from a low signal-to-noise ratio, requiring to acquire very large datasets that are time-consuming to process. Current reconstruction methods are precise but computationally expensive, or faster but lack a physically-plausible model of large molecular shape variations. To fill this gap, we propose CryoChains that encodes large deformations of biomolecules via rigid body transformation of their polymer instances (chains), while representing their finer shape variations with the normal mode analysis framework of biophysics. Our synthetic data experiments on the human $\text{GABA}_{\text{B}}$ and heat shock protein show that CryoChains gives a biophysically-grounded quantification of the heterogeneous conformations of biomolecules, while reconstructing their 3D molecular structures at an improved resolution compared to the current fastest, interpretable deep learning method.
Transformer-based GAN for Terahertz Spatial-Temporal Channel Modeling and Generating
Jun 12, 2023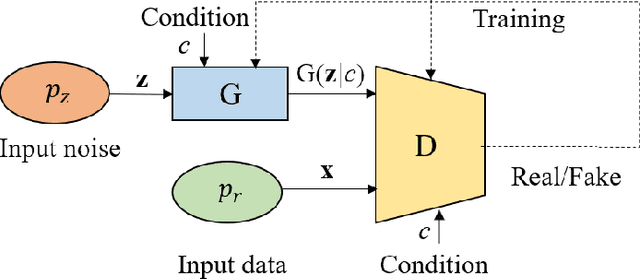
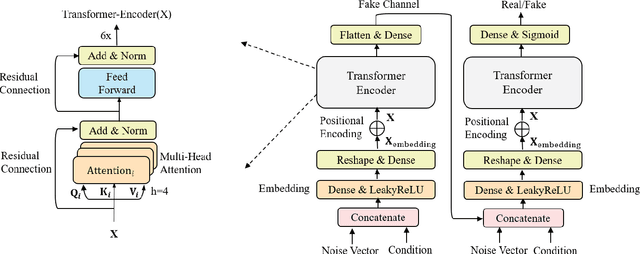
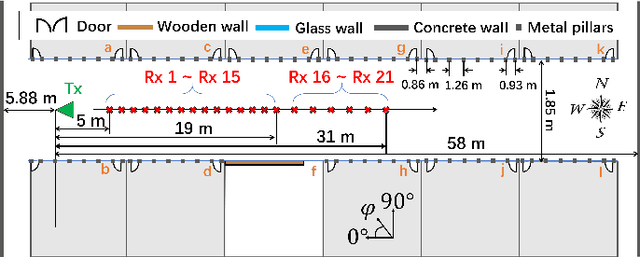
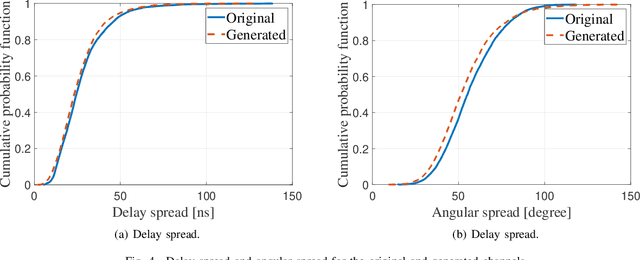
Terahertz (THz) communications are envisioned as a promising technology for 6G and beyond wireless systems, providing ultra-broad continuous bandwidth and thus Terabit-per-second (Tbps) data rates. However, as foundation of designing THz communications, channel modeling and characterization are fundamental to scrutinize the potential of the new spectrum. Relied on time-consuming and costly physical measurements, traditional statistical channel modeling methods suffer from the problem of low accuracy with the assumed certain distributions and empirical parameters. In this paper, a transformer-based generative adversarial network modeling method (T-GAN) is proposed in the THz band, which exploits the advantage of GAN in modeling the complex distribution, and the powerful expressive capability of transformer structure. Experimental results reveal that the distribution of channels generated by the proposed T-GAN method shows good agreement with the original channels in terms of the delay spread and angular spread. Moreover, T-GAN achieves good performance in modeling the power delay angular profile, with 2.18 dB root-mean-square error (RMSE).
Beamforming Design for IRS-and-UAV-aided Two-way Amplify-and-Forward Relay Networks
Jun 01, 2023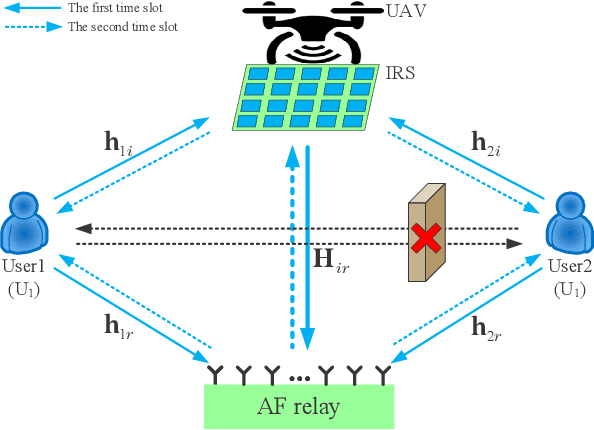
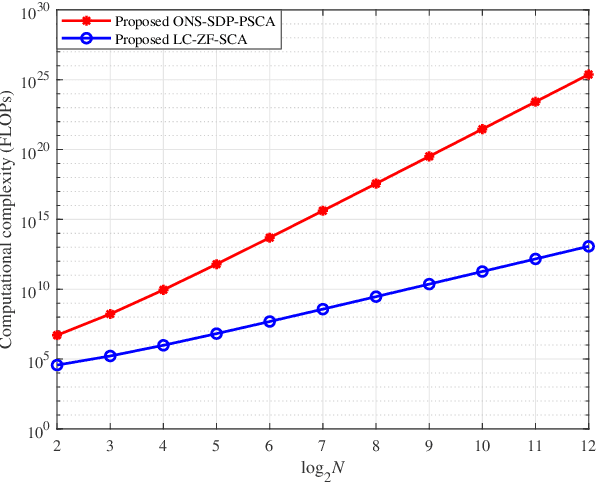
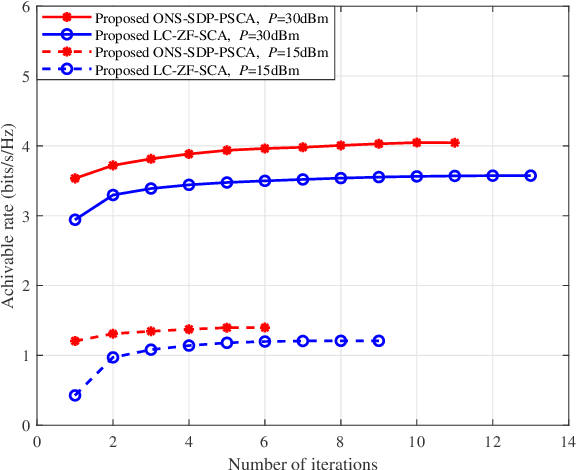
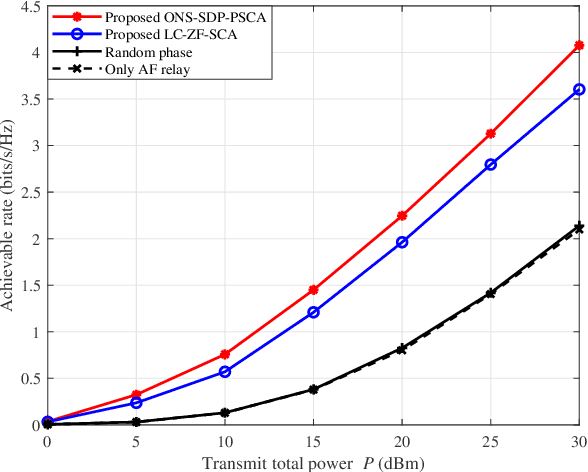
As a promising solution to improve communication quality, unmanned aerial vehicle (UAV) has been widely integrated into wireless networks. In this paper, for the sake of enhancing the message exchange rate between User1 (U1) and User2 (U2), an intelligent reflective surface (IRS)-and-UAV- assisted two-way amplify-and-forward (AF) relay wireless system is proposed, where U1 and U2 can communicate each other via a UAV-mounted IRS and an AF relay. Besides, an optimization problem of maximizing minimum rate is casted, where the variables, namely AF relay beamforming matrix and IRS phase shifts of two time slots, need to be optimized. To achieve a maximum rate, a low-complexity alternately iterative (AI) scheme based on zero forcing and successive convex approximation (LC-ZF-SCA) algorithm is put forward, where the expression of AF relay beamforming matrix can be derived in semi-closed form by ZF method, and IRS phase shift vectors of two time slots can be respectively optimized by utilizing SCA algorithm. To obtain a significant rate enhancement, a high-performance AI method based on one step, semidefinite programming and penalty SCA (ONS-SDP-PSCA) is proposed, where the beamforming matrix at AF relay can be firstly solved by singular value decomposition and ONS method, IRS phase shift matrices of two time slots are optimized by SDP and PSCA algorithms. Simulation results present that the rate performance of the proposed LC-ZF-SCA and ONS-SDP-PSCA methods surpass those of random phase and only AF relay. In particular, when total transmit power is equal to 30dBm, the proposed two methods can harvest more than 68.5% rate gain compared to random phase and only AF relay. Meanwhile, the rate performance of ONS-SDP-PSCA method at cost of extremely high complexity is superior to that of LC-ZF-SCA method.
Efficient Encoder-Decoder and Dual-Path Conformer for Comprehensive Feature Learning in Speech Enhancement
Jun 09, 2023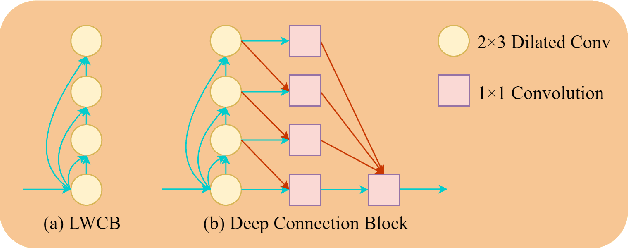
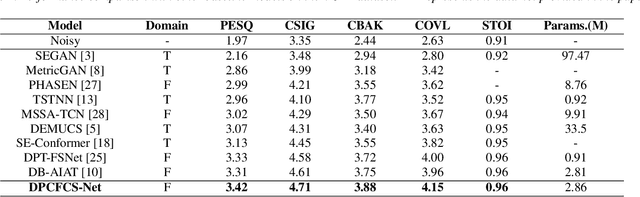
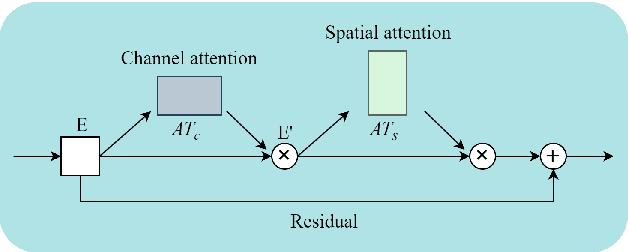
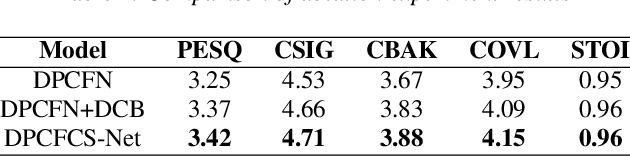
Current speech enhancement (SE) research has largely neglected channel attention and spatial attention, and encoder-decoder architecture-based networks have not adequately considered how to provide efficient inputs to the intermediate enhancement layer. To address these issues, this paper proposes a time-frequency (T-F) domain SE network (DPCFCS-Net) that incorporates improved densely connected blocks, dual-path modules, convolution-augmented transformers (conformers), channel attention, and spatial attention. Compared with previous models, our proposed model has a more efficient encoder-decoder and can learn comprehensive features. Experimental results on the VCTK+DEMAND dataset demonstrate that our method outperforms existing techniques in SE performance. Furthermore, the improved densely connected block and two dimensions attention module developed in this work are highly adaptable and easily integrated into existing networks.
Faster Discrete Convex Function Minimization with Predictions: The M-Convex Case
Jun 09, 2023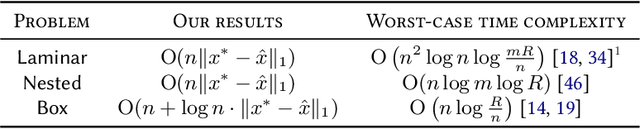

Recent years have seen a growing interest in accelerating optimization algorithms with machine-learned predictions. Sakaue and Oki (NeurIPS 2022) have developed a general framework that warm-starts the L-convex function minimization method with predictions, revealing the idea's usefulness for various discrete optimization problems. In this paper, we present a framework for using predictions to accelerate M-convex function minimization, thus complementing previous research and extending the range of discrete optimization algorithms that can benefit from predictions. Our framework is particularly effective for an important subclass called laminar convex minimization, which appears in many operations research applications. Our methods can improve time complexity bounds upon the best worst-case results by using predictions and even have potential to go beyond a lower-bound result.
German CheXpert Chest X-ray Radiology Report Labeler
Jun 05, 2023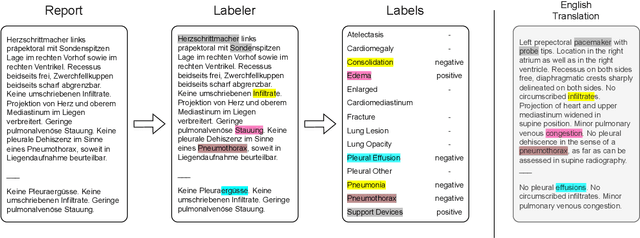
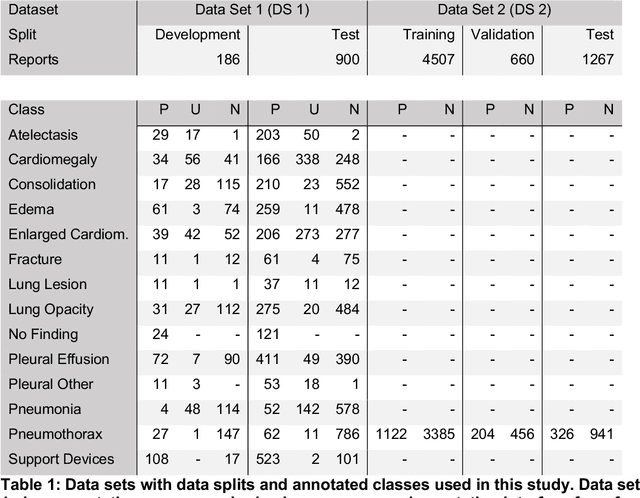

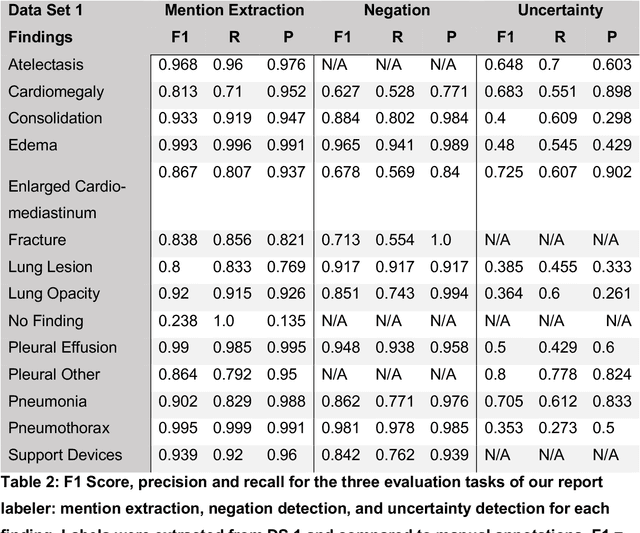
This study aimed to develop an algorithm to automatically extract annotations for chest X-ray classification models from German thoracic radiology reports. An automatic label extraction model was designed based on the CheXpert architecture, and a web-based annotation interface was created for iterative improvements. Results showed that automated label extraction can reduce time spent on manual labeling and improve overall modeling performance. The model trained on automatically extracted labels performed competitively to manually labeled data and strongly outperformed the model trained on publicly available data.