 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bus Ridership Prediction with Time Section, Weather, and Ridership Trend Aware Multiple LSTM
Apr 13, 2023
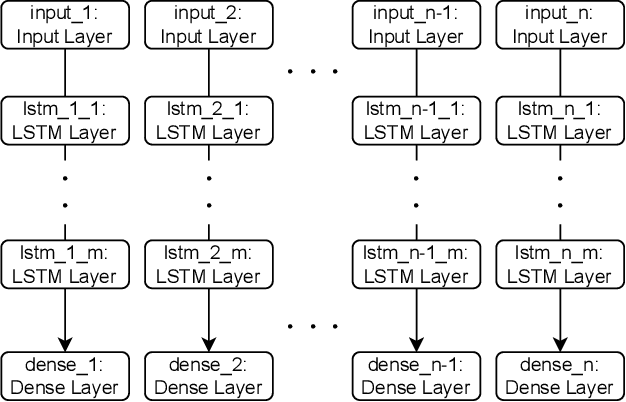
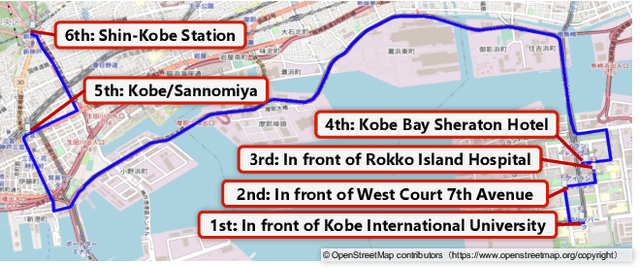
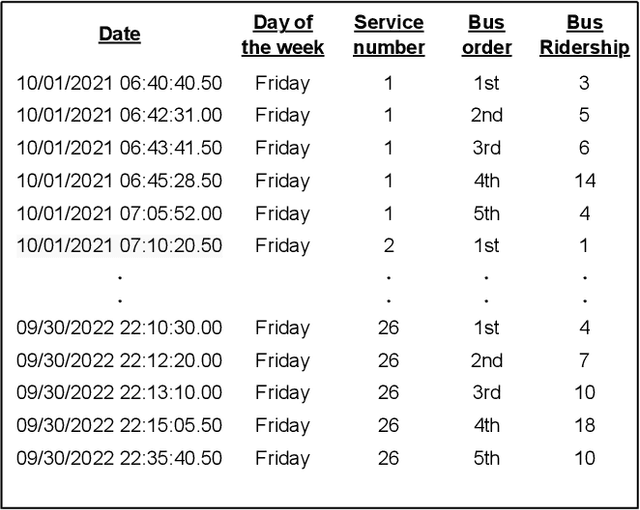
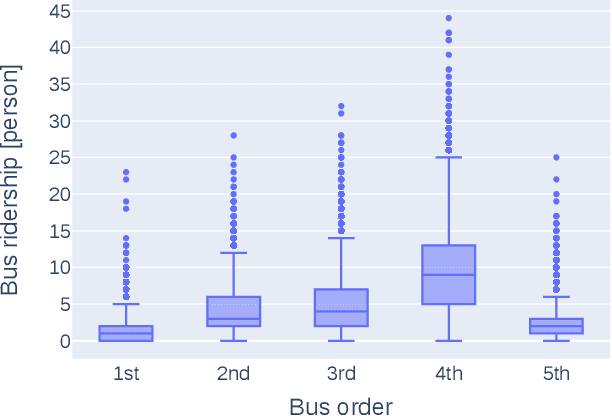
Public transportation has been essential in people's lives in recent years. Bus ridership is a factor in people's choice to board the bus. Therefore, from the perspective of improving service quality, it is important to inform passengers who have not boarded the bus yet about future bus ridership. However, there is a concern that providing inaccurate information may cause a negative experience. Against this backdrop, there is a need to provide bus passengers who have not boarded yet with highly accurate predictions. Many researchers are working on studies on this. However, two issues summarize related studies. The first is that the correlation of bus ridership between consecutive bus stops should be considered for the prediction. The second is that the prediction has yet to be made using all of the features shown to be useful in each related study. This study proposes a prediction method that addresses both of these issues. We solve the first issue by designing an LSTM-based architecture for each bus stop and a single model for the entire bus stop. We solve the second issue by inputting all useful data, the past bus ridership, day of the week, time section, weather, and precipitation, as features. Bus ridership at each bus stop collected from buses operated by Minato Kanko Bus Inc, in Kobe city, Hyogo, Japan, from October 1, 2021, to September 30, 2022, were used to compare accuracy. The proposed method improved RMSE by 23% on average and up to 27% compared to existing methods.
Correlated Noise in Epoch-Based Stochastic Gradient Descent: Implications for Weight Variances
Jun 08, 2023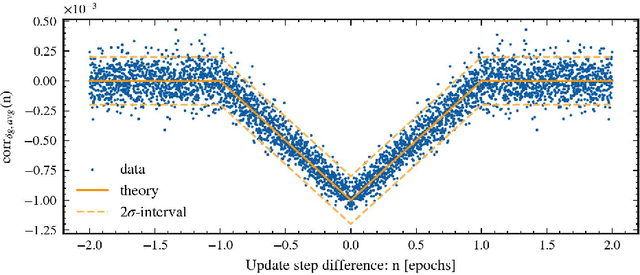
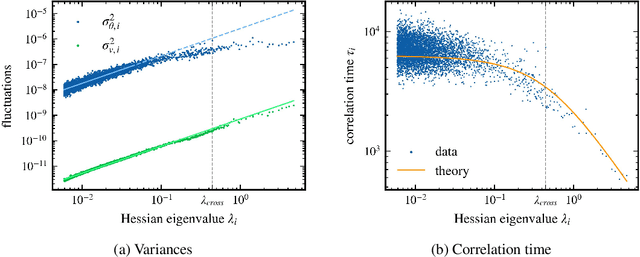
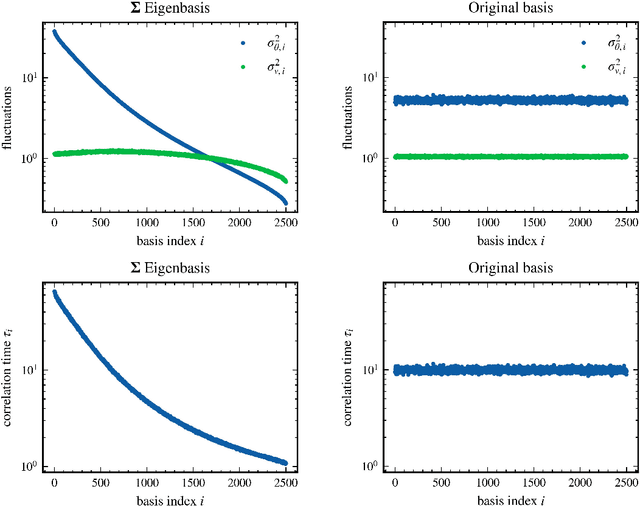
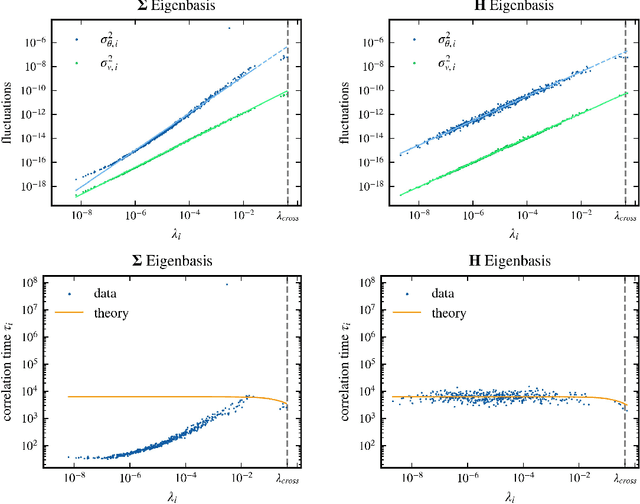
Stochastic gradient descent (SGD) has become a cornerstone of neural network optimization, yet the noise introduced by SGD is often assumed to be uncorrelated over time, despite the ubiquity of epoch-based training. In this work, we challenge this assumption and investigate the effects of epoch-based noise correlations on the stationary distribution of discrete-time SGD with momentum, limited to a quadratic loss. Our main contributions are twofold: first, we calculate the exact autocorrelation of the noise for training in epochs under the assumption that the noise is independent of small fluctuations in the weight vector; second, we explore the influence of correlations introduced by the epoch-based learning scheme on SGD dynamics. We find that for directions with a curvature greater than a hyperparameter-dependent crossover value, the results for uncorrelated noise are recovered. However, for relatively flat directions, the weight variance is significantly reduced. We provide an intuitive explanation for these results based on a crossover between correlation times, contributing to a deeper understanding of the dynamics of SGD in the presence of epoch-based noise correlations.
Ambulance Demand Prediction via Convolutional Neural Networks
Jun 08, 2023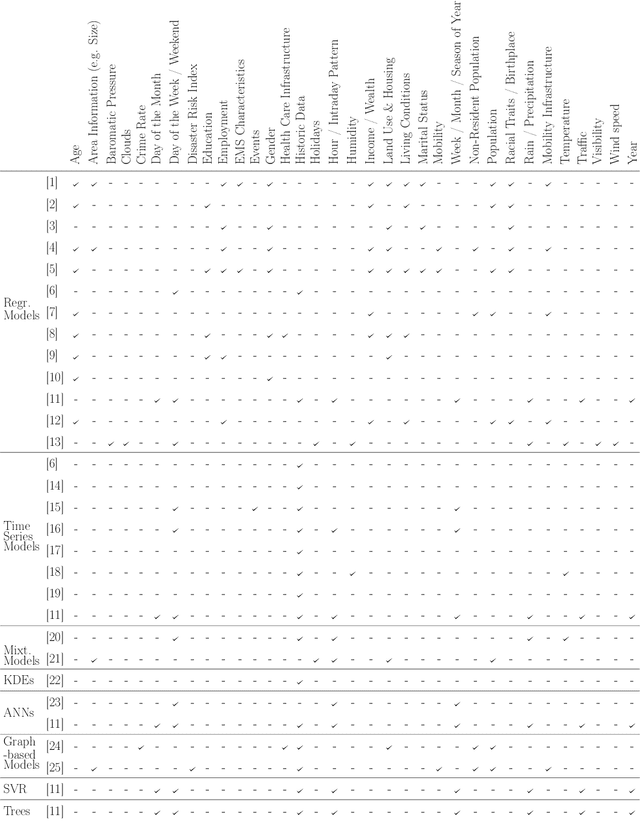
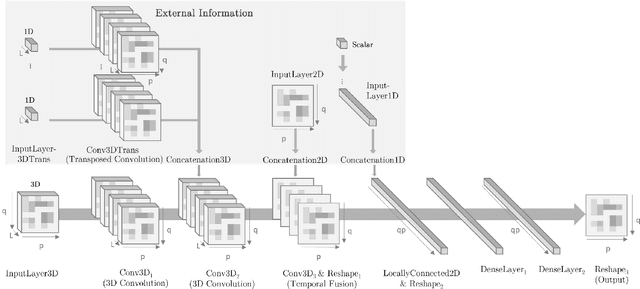
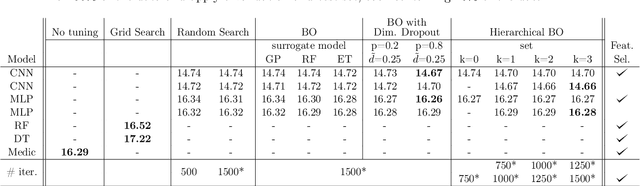
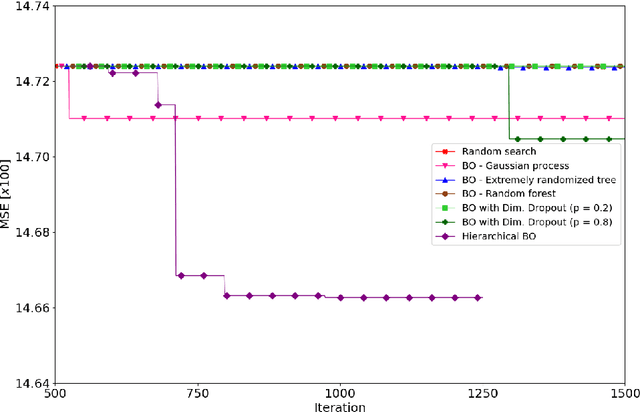
Minimizing response times is crucial for emergency medical services to reduce patients' waiting times and to increase their survival rates. Many models exist to optimize operational tasks such as ambulance allocation and dispatching. Including accurate demand forecasts in such models can improve operational decision-making. Against this background, we present a novel convolutional neural network (CNN) architecture that transforms time series data into heatmaps to predict ambulance demand. Applying such predictions requires incorporating external features that influence ambulance demands. We contribute to the existing literature by providing a flexible, generic CNN architecture, allowing for the inclusion of external features with varying dimensions. Additionally, we provide a feature selection and hyperparameter optimization framework utilizing Bayesian optimization. We integrate historical ambulance demand and external information such as weather, events, holidays, and time. To show the superiority of the developed CNN architecture over existing approaches, we conduct a case study for Seattle's 911 call data and include external information. We show that the developed CNN architecture outperforms existing state-of-the-art methods and industry practice by more than 9%.
Learning Stage-wise GANs for Whistle Extraction in Time-Frequency Spectrograms
Apr 05, 2023
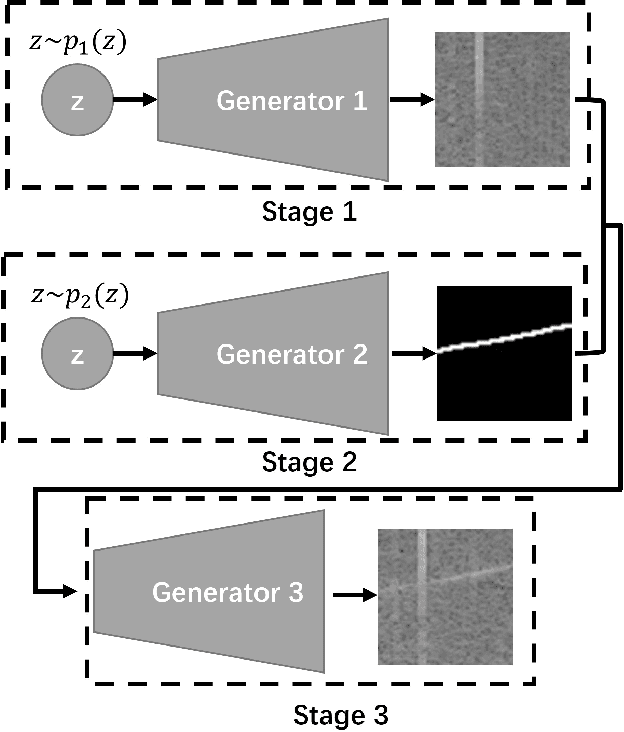

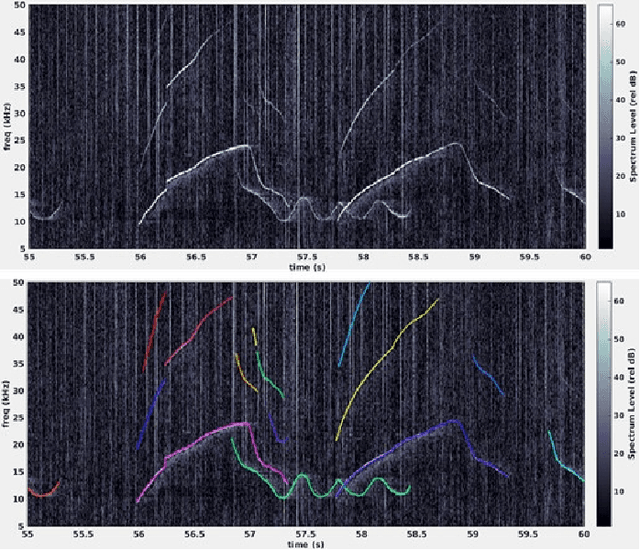
Whistle contour extraction aims to derive animal whistles from time-frequency spectrograms as polylines. For toothed whales, whistle extraction results can serve as the basis for analyzing animal abundance, species identity, and social activities. During the last few decades, as long-term recording systems have become affordable, automated whistle extraction algorithms were proposed to process large volumes of recording data. Recently, a deep learning-based method demonstrated superior performance in extracting whistles under varying noise conditions. However, training such networks requires a large amount of labor-intensive annotation, which is not available for many species. To overcome this limitation, we present a framework of stage-wise generative adversarial networks (GANs), which compile new whistle data suitable for deep model training via three stages: generation of background noise in the spectrogram, generation of whistle contours, and generation of whistle signals. By separating the generation of different components in the samples, our framework composes visually promising whistle data and labels even when few expert annotated data are available. Regardless of the amount of human-annotated data, the proposed data augmentation framework leads to a consistent improvement in performance of the whistle extraction model, with a maximum increase of 1.69 in the whistle extraction mean F1-score. Our stage-wise GAN also surpasses one single GAN in improving whistle extraction models with augmented data. The data and code will be available at https://github.com/Paul-LiPu/CompositeGAN\_WhistleAugment.
Deep Learning-Enabled Sleep Staging From Vital Signs and Activity Measured Using a Near-Infrared Video Camera
Jun 06, 2023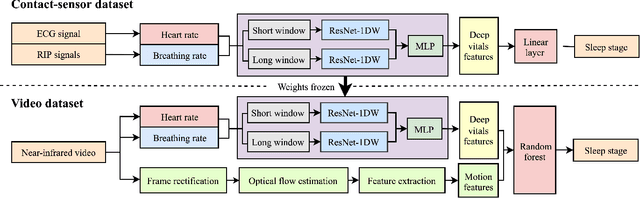


Conventional sleep monitoring is time-consuming, expensive and uncomfortable, requiring a large number of contact sensors to be attached to the patient. Video data is commonly recorded as part of a sleep laboratory assessment. If accurate sleep staging could be achieved solely from video, this would overcome many of the problems of traditional methods. In this work we use heart rate, breathing rate and activity measures, all derived from a near-infrared video camera, to perform sleep stage classification. We use a deep transfer learning approach to overcome data scarcity, by using an existing contact-sensor dataset to learn effective representations from the heart and breathing rate time series. Using a dataset of 50 healthy volunteers, we achieve an accuracy of 73.4\% and a Cohen's kappa of 0.61 in four-class sleep stage classification, establishing a new state-of-the-art for video-based sleep staging.
Phase perturbation improves channel robustness for speech spoofing countermeasures
Jun 06, 2023
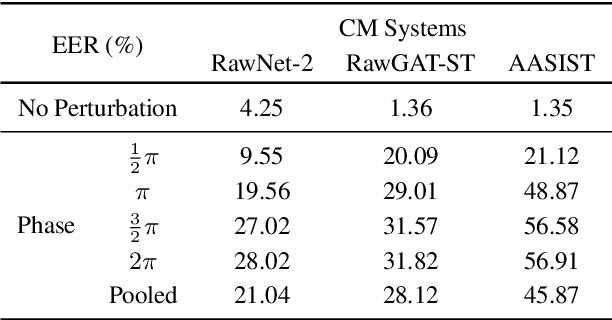
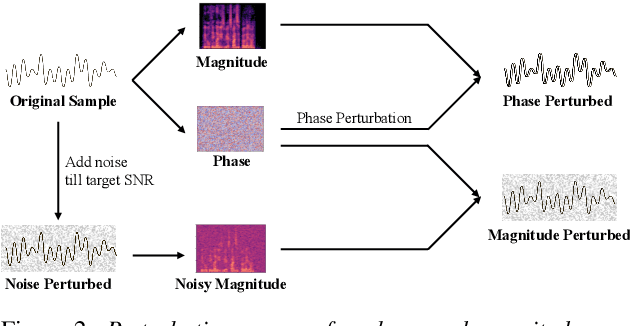
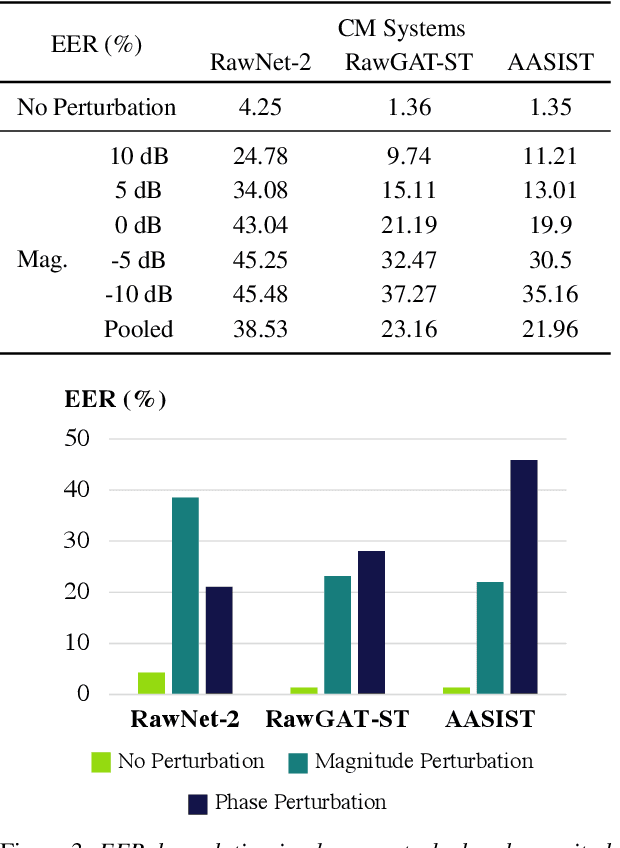
In this paper, we aim to address the problem of channel robustness in speech countermeasure (CM) systems, which are used to distinguish synthetic speech from human natural speech. On the basis of two hypotheses, we suggest an approach for perturbing phase information during the training of time-domain CM systems. Communication networks often employ lossy compression codec that encodes only magnitude information, therefore heavily altering phase information. Also, state-of-the-art CM systems rely on phase information to identify spoofed speech. Thus, we believe the information loss in the phase domain induced by lossy compression codec degrades the performance of the unseen channel. We first establish the dependence of time-domain CM systems on phase information by perturbing phase in evaluation, showing strong degradation. Then, we demonstrated that perturbing phase during training leads to a significant performance improvement, whereas perturbing magnitude leads to further degradation.
Logarithmic Bayes Regret Bounds
Jun 15, 2023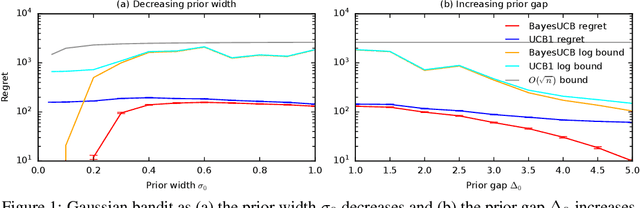
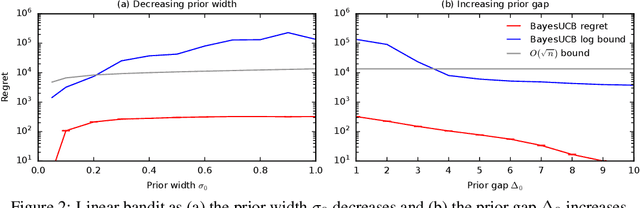
We derive the first finite-time logarithmic regret bounds for Bayesian bandits. For Gaussian bandits, we obtain a $O(c_h \log^2 n)$ bound, where $c_h$ is a prior-dependent constant. This matches the asymptotic lower bound of Lai (1987). Our proofs mark a technical departure from prior works, and are simple and general. To show generality, we apply our technique to linear bandits. Our bounds shed light on the value of the prior in the Bayesian setting, both in the objective and as a side information given to the learner. They significantly improve the $\tilde{O}(\sqrt{n})$ bounds, that despite the existing lower bounds, have become standard in the literature.
Fast Algorithms for Directed Graph Partitioning Using Flows and Reweighted Eigenvalues
Jun 15, 2023We consider a new semidefinite programming relaxation for directed edge expansion, which is obtained by adding triangle inequalities to the reweighted eigenvalue formulation. Applying the matrix multiplicative weight update method to this relaxation, we derive almost linear-time algorithms to achieve $O(\sqrt{\log{n}})$-approximation and Cheeger-type guarantee for directed edge expansion, as well as an improved cut-matching game for directed graphs. This provides a primal-dual flow-based framework to obtain the best known algorithms for directed graph partitioning. The same approach also works for vertex expansion and for hypergraphs, providing a simple and unified approach to achieve the best known results for different expansion problems and different algorithmic techniques.
Hands-on detection for steering wheels with neural networks
Jun 15, 2023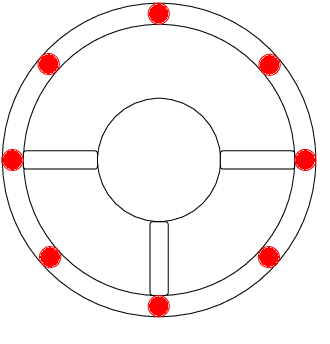
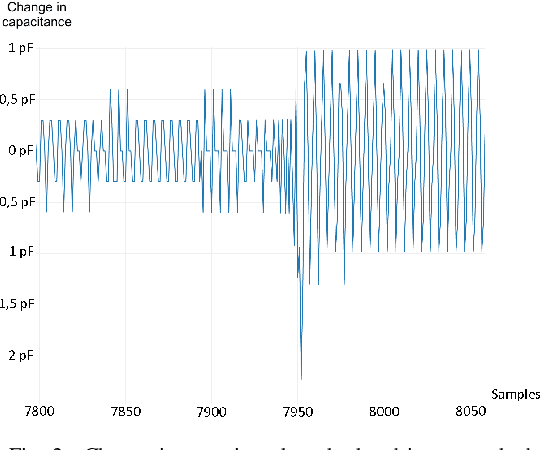
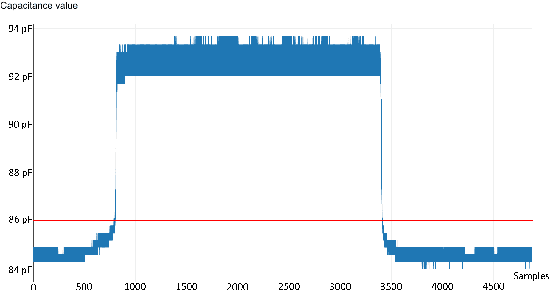
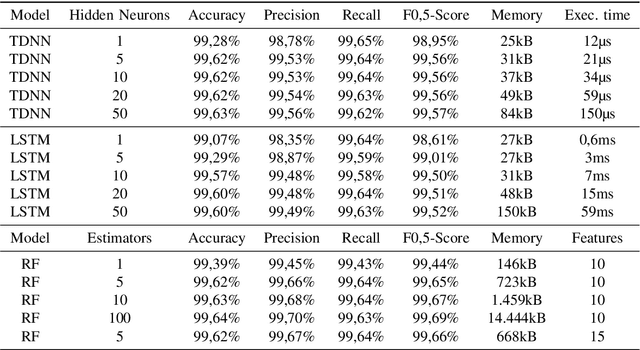
In this paper the concept of a machine learning based hands-on detection algorithm is proposed. The hand detection is implemented on the hardware side using a capacitive method. A sensor mat in the steering wheel detects a change in capacity as soon as the driver's hands come closer. The evaluation and final decision about hands-on or hands-off situations is done using machine learning. In order to find a suitable machine learning model, different models are implemented and evaluated. Based on accuracy, memory consumption and computational effort the most promising one is selected and ported on a micro controller. The entire system is then evaluated in terms of reliability and response time.
QuOTeS: Query-Oriented Technical Summarization
Jun 20, 2023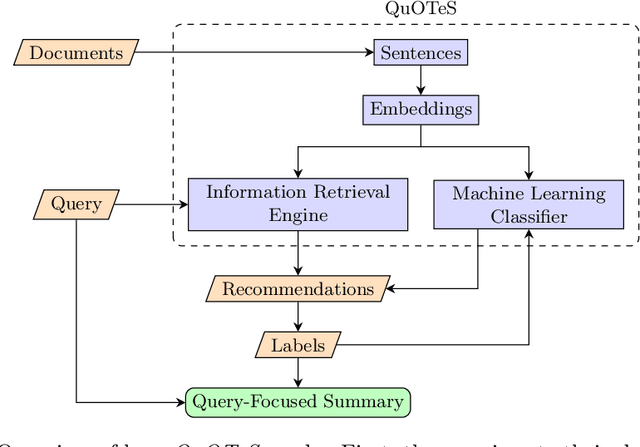


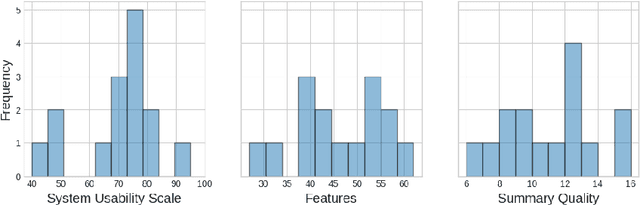
Abstract. When writing an academic paper, researchers often spend considerable time reviewing and summarizing papers to extract relevant citations and data to compose the Introduction and Related Work sections. To address this problem, we propose QuOTeS, an interactive system designed to retrieve sentences related to a summary of the research from a collection of potential references and hence assist in the composition of new papers. QuOTeS integrates techniques from Query-Focused Extractive Summarization and High-Recall Information Retrieval to provide Interactive Query-Focused Summarization of scientific documents. To measure the performance of our system, we carried out a comprehensive user study where participants uploaded papers related to their research and evaluated the system in terms of its usability and the quality of the summaries it produces. The results show that QuOTeS provides a positive user experience and consistently provides query-focused summaries that are relevant, concise, and complete. We share the code of our system and the novel Query-Focused Summarization dataset collected during our experiments at https://github.com/jarobyte91/quotes.