 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Measurement-based Channel Characterization for A2A and A2G Wireless Drone Communication Systems
Jun 14, 2023
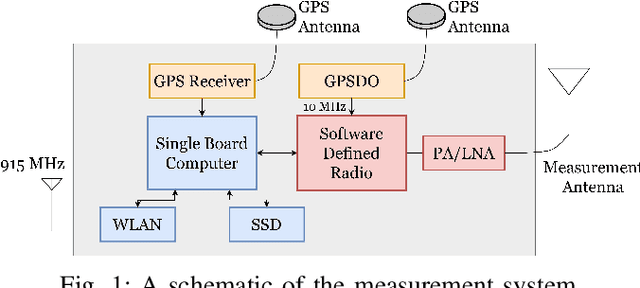

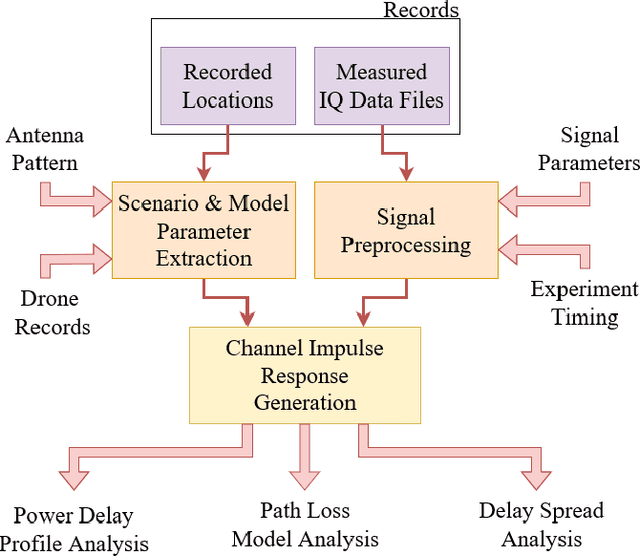
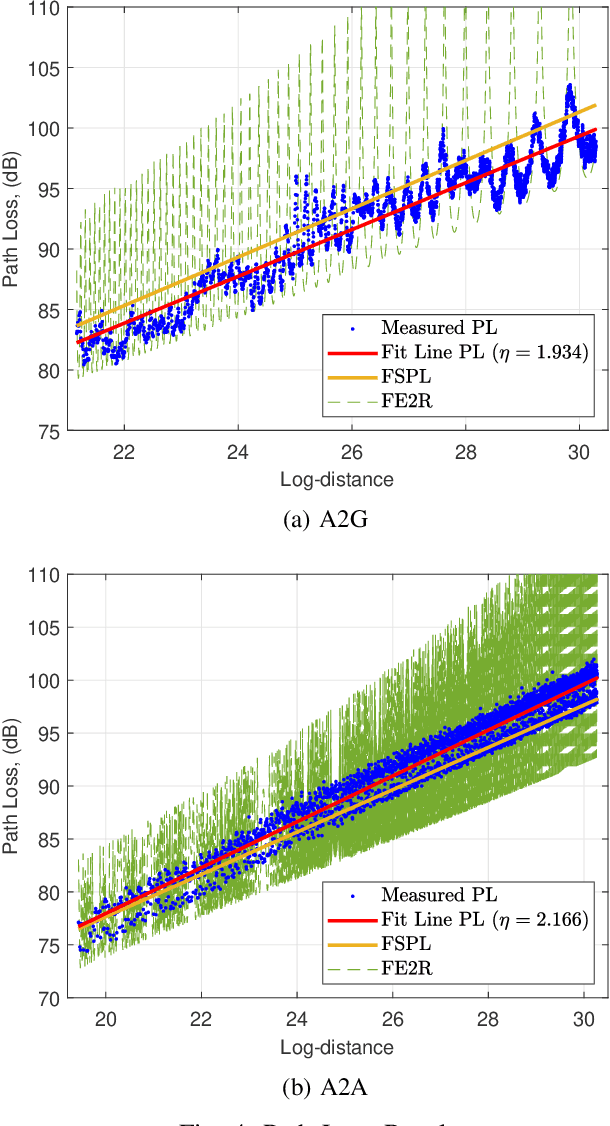
This paper presents field measurement-based channel characterization for air--to--ground (A2G) and air--to--air (A2A) wireless communication systems using two drones equipped with lightweight software-defined radios. A correlation-based channel sounder is employed such that the transmitting drone broadcasts the sounding waveform with a pseudo-noise sequence and the receiving drone captures the sounding waveform together with the location information for the post-processing analysis. The path loss results demonstrate that the measurement and flat-earth two-ray results have similar trends for A2G while the measurement and free space path loss are similar to each other for A2A. The time delays between the direct path and multipath components are widely spread for A2A while the multipath components are mostly concentrated around the direct path for A2G generating a more challenging communication environment. We observe that the reflections from several buildings having metal roofs and claddings on the measurement site cause sudden peaks in the root-mean-square delay spread. The results indicate that the A2A channel has better characteristics than the A2G under similar mobility conditions.
Computational Flash Photography through Intrinsics
Jun 09, 2023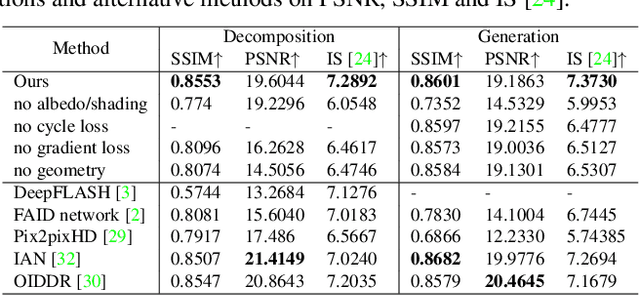



Flash is an essential tool as it often serves as the sole controllable light source in everyday photography. However, the use of flash is a binary decision at the time a photograph is captured with limited control over its characteristics such as strength or color. In this work, we study the computational control of the flash light in photographs taken with or without flash. We present a physically motivated intrinsic formulation for flash photograph formation and develop flash decomposition and generation methods for flash and no-flash photographs, respectively. We demonstrate that our intrinsic formulation outperforms alternatives in the literature and allows us to computationally control flash in in-the-wild images.
Controllable Motion Diffusion Model
Jun 01, 2023

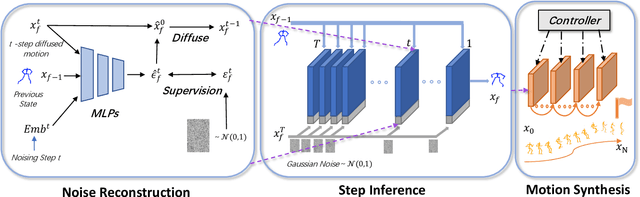

Generating realistic and controllable motions for virtual characters is a challenging task in computer animation, and its implications extend to games, simulations, and virtual reality. Recent studies have drawn inspiration from the success of diffusion models in image generation, demonstrating the potential for addressing this task. However, the majority of these studies have been limited to offline applications that target at sequence-level generation that generates all steps simultaneously. To enable real-time motion synthesis with diffusion models in response to time-varying control signals, we propose the framework of the Controllable Motion Diffusion Model (COMODO). Our framework begins with an auto-regressive motion diffusion model (A-MDM), which generates motion sequences step by step. In this way, simply using the standard DDPM algorithm without any additional complexity, our framework is able to generate high-fidelity motion sequences over extended periods with different types of control signals. Then, we propose our reinforcement learning-based controller and controlling strategies on top of the A-MDM model, so that our framework can steer the motion synthesis process across multiple tasks, including target reaching, joystick-based control, goal-oriented control, and trajectory following. The proposed framework enables the real-time generation of diverse motions that react adaptively to user commands on-the-fly, thereby enhancing the overall user experience. Besides, it is compatible with the inpainting-based editing methods and can predict much more diverse motions without additional fine-tuning of the basic motion generation models. We conduct comprehensive experiments to evaluate the effectiveness of our framework in performing various tasks and compare its performance against state-of-the-art methods.
PCF-GAN: generating sequential data via the characteristic function of measures on the path space
May 21, 2023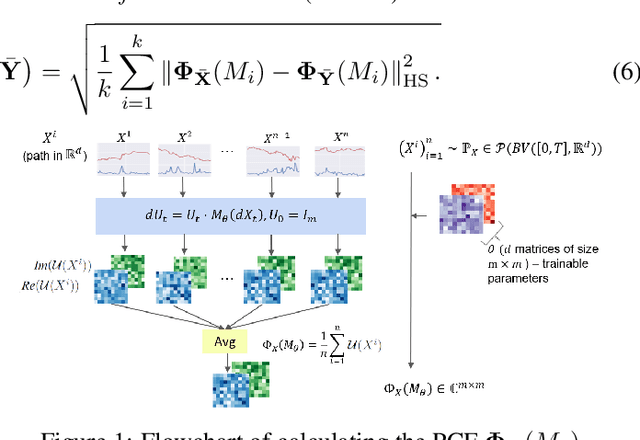

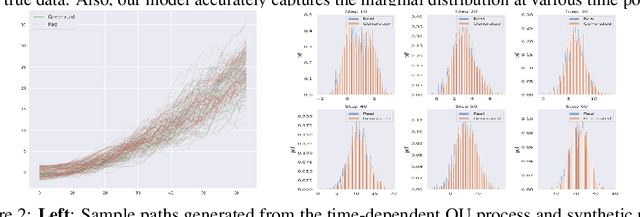
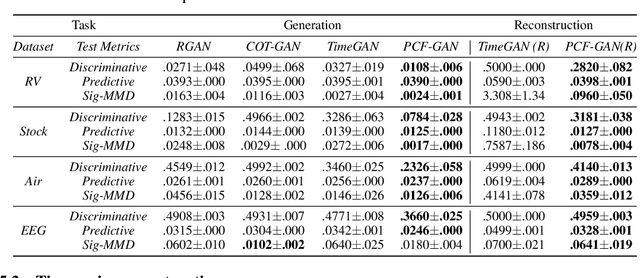
Generating high-fidelity time series data using generative adversarial networks (GANs) remains a challenging task, as it is difficult to capture the temporal dependence of joint probability distributions induced by time-series data. Towards this goal, a key step is the development of an effective discriminator to distinguish between time series distributions. We propose the so-called PCF-GAN, a novel GAN that incorporates the path characteristic function (PCF) as the principled representation of time series distribution into the discriminator to enhance its generative performance. On the one hand, we establish theoretical foundations of the PCF distance by proving its characteristicity, boundedness, differentiability with respect to generator parameters, and weak continuity, which ensure the stability and feasibility of training the PCF-GAN. On the other hand, we design efficient initialisation and optimisation schemes for PCFs to strengthen the discriminative power and accelerate training efficiency. To further boost the capabilities of complex time series generation, we integrate the auto-encoder structure via sequential embedding into the PCF-GAN, which provides additional reconstruction functionality. Extensive numerical experiments on various datasets demonstrate the consistently superior performance of PCF-GAN over state-of-the-art baselines, in both generation and reconstruction quality. Code is available at https://github.com/DeepIntoStreams/PCF-GAN.
The DeepCAR Method: Forecasting Time-Series Data That Have Change Points
Feb 22, 2023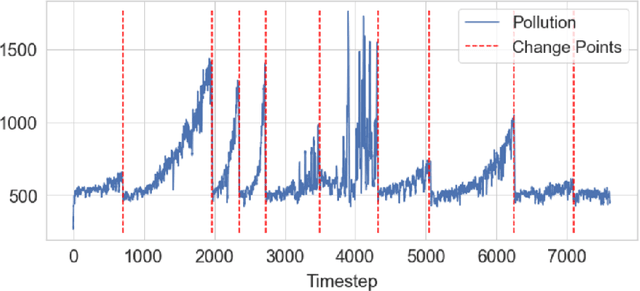
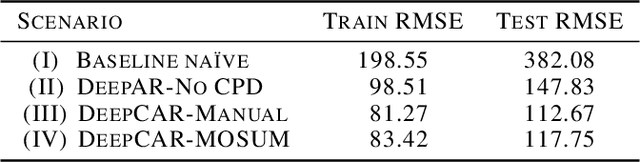
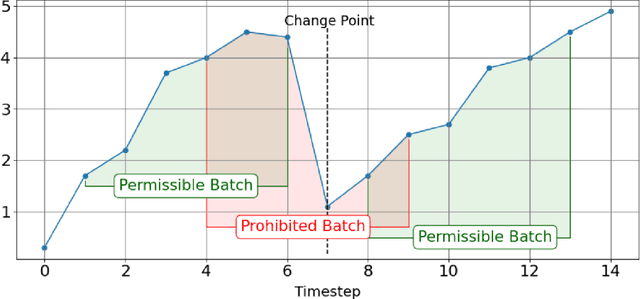
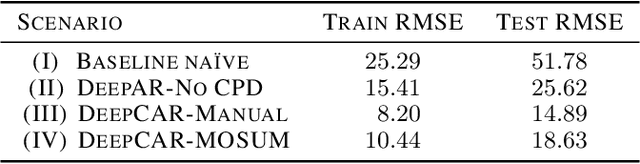
Many methods for time-series forecasting are known in classical statistics, such as autoregression, moving averages, and exponential smoothing. The DeepAR framework is a novel, recent approach for time-series forecasting based on deep learning. DeepAR has shown very promising results already. However, time series often have change points, which can degrade the DeepAR's prediction performance substantially. This paper extends the DeepAR framework by detecting and including those change points. We show that our method performs as well as standard DeepAR when there are no change points and considerably better when there are change points. More generally, we show that the batch size provides an effective and surprisingly simple way to deal with change points in DeepAR, Transformers, and other modern forecasting models.
Embedding stochastic differential equations into neural networks via dual processes
Jun 08, 2023We propose a new approach to constructing a neural network for predicting expectations of stochastic differential equations. The proposed method does not need data sets of inputs and outputs; instead, the information obtained from the time-evolution equations, i.e., the corresponding dual process, is directly compared with the weights in the neural network. As a demonstration, we construct neural networks for the Ornstein-Uhlenbeck process and the noisy van der Pol system. The remarkable feature of learned networks with the proposed method is the accuracy of inputs near the origin. Hence, it would be possible to avoid the overfitting problem because the learned network does not depend on training data sets.
Latent Exploration for Reinforcement Learning
May 31, 2023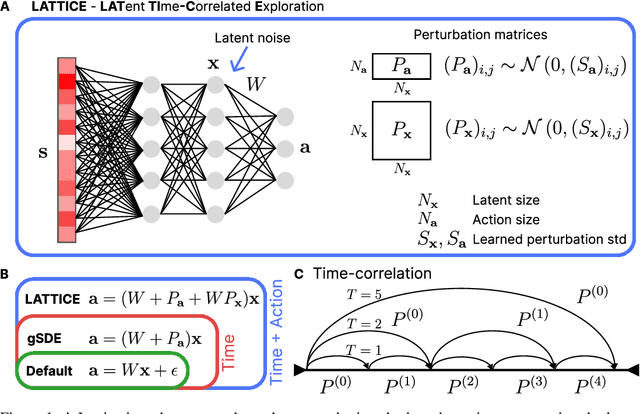
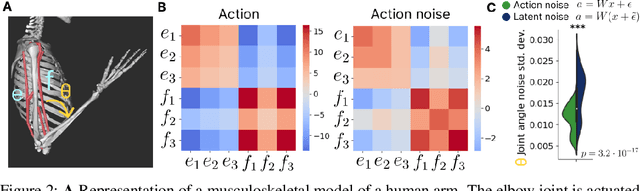
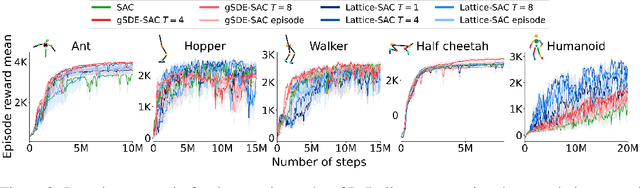
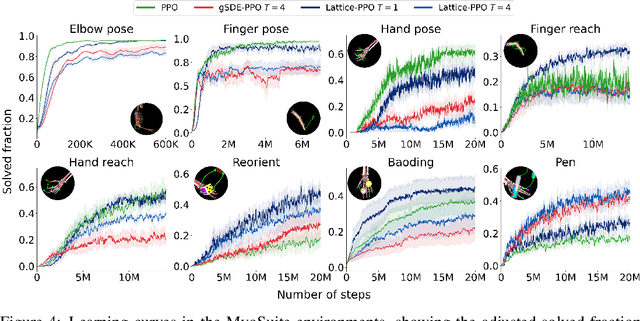
In Reinforcement Learning, agents learn policies by exploring and interacting with the environment. Due to the curse of dimensionality, learning policies that map high-dimensional sensory input to motor output is particularly challenging. During training, state of the art methods (SAC, PPO, etc.) explore the environment by perturbing the actuation with independent Gaussian noise. While this unstructured exploration has proven successful in numerous tasks, it ought to be suboptimal for overactuated systems. When multiple actuators, such as motors or muscles, drive behavior, uncorrelated perturbations risk diminishing each other's effect, or modifying the behavior in a task-irrelevant way. While solutions to introduce time correlation across action perturbations exist, introducing correlation across actuators has been largely ignored. Here, we propose LATent TIme-Correlated Exploration (Lattice), a method to inject temporally-correlated noise into the latent state of the policy network, which can be seamlessly integrated with on- and off-policy algorithms. We demonstrate that the noisy actions generated by perturbing the network's activations can be modeled as a multivariate Gaussian distribution with a full covariance matrix. In the PyBullet locomotion tasks, Lattice-SAC achieves state of the art results, and reaches 18% higher reward than unstructured exploration in the Humanoid environment. In the musculoskeletal control environments of MyoSuite, Lattice-PPO achieves higher reward in most reaching and object manipulation tasks, while also finding more energy-efficient policies with reductions of 20-60%. Overall, we demonstrate the effectiveness of structured action noise in time and actuator space for complex motor control tasks.
DiAReL: Reinforcement Learning with Disturbance Awareness for Robust Sim2Real Policy Transfer in Robot Control
Jun 15, 2023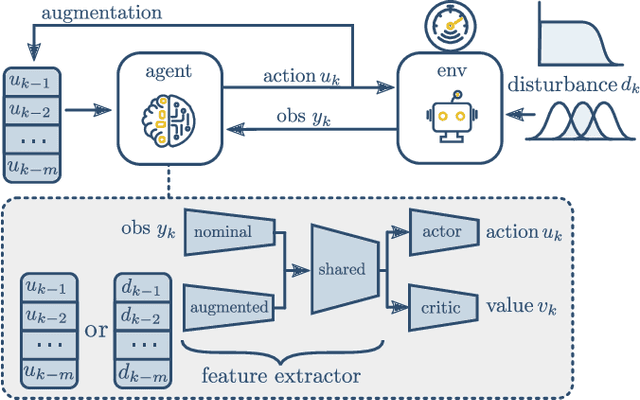
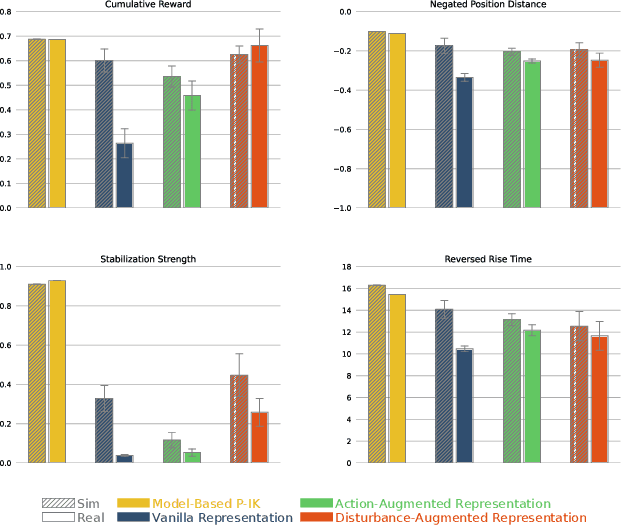
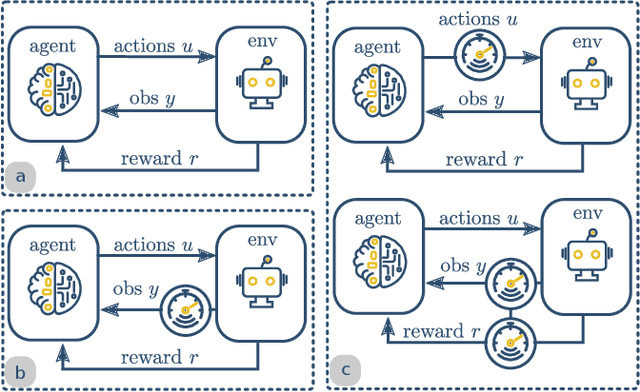
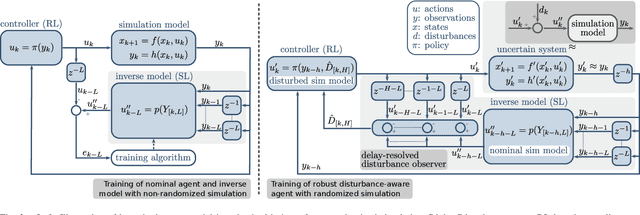
Delayed Markov decision processes fulfill the Markov property by augmenting the state space of agents with a finite time window of recently committed actions. In reliance with these state augmentations, delay-resolved reinforcement learning algorithms train policies to learn optimal interactions with environments featured with observation or action delays. Although such methods can directly be trained on the real robots, due to sample inefficiency, limited resources or safety constraints, a common approach is to transfer models trained in simulation to the physical robot. However, robotic simulations rely on approximated models of the physical systems, which hinders the sim2real transfer. In this work, we consider various uncertainties in the modelling of the robot's dynamics as unknown intrinsic disturbances applied on the system input. We introduce a disturbance-augmented Markov decision process in delayed settings as a novel representation to incorporate disturbance estimation in training on-policy reinforcement learning algorithms. The proposed method is validated across several metrics on learning a robotic reaching task and compared with disturbance-unaware baselines. The results show that the disturbance-augmented models can achieve higher stabilization and robustness in the control response, which in turn improves the prospects of successful sim2real transfer.
Modulation Classification Through Deep Learning Using Resolution Transformed Spectrograms
Jun 06, 2023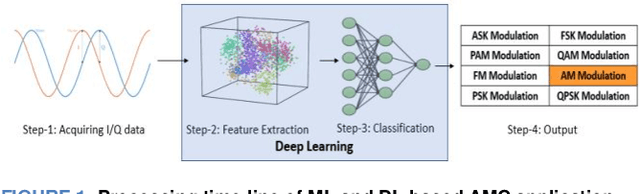
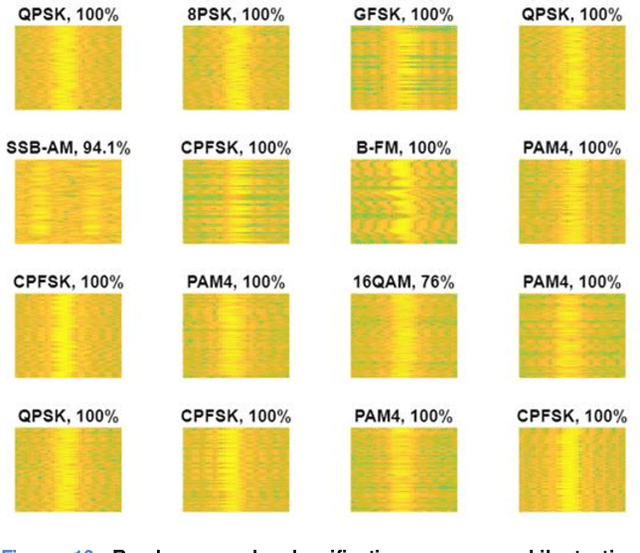
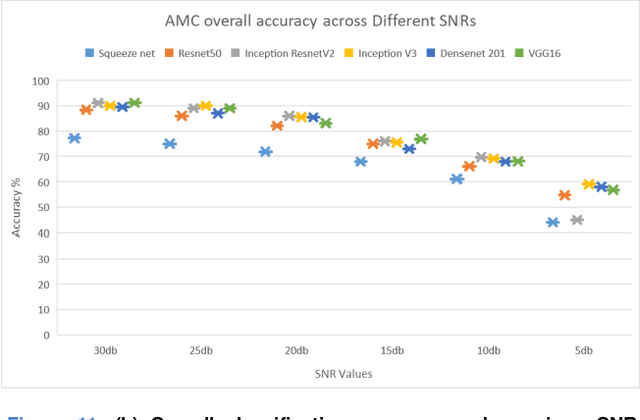
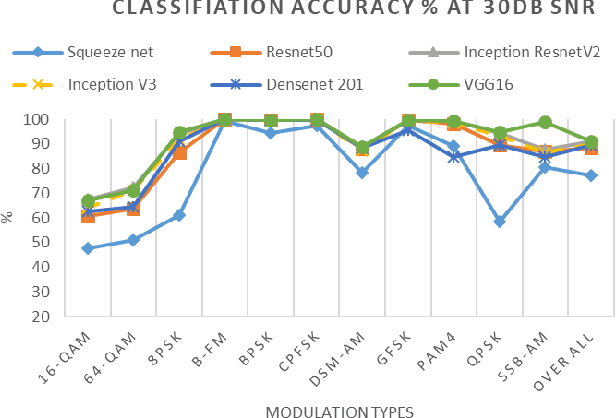
Modulation classification is an essential step of signal processing and has been regularly applied in the field of tele-communication. Since variations of frequency with respect to time remains a vital distinction among radio signals having different modulation formats, these variations can be used for feature extraction by converting 1-D radio signals into frequency domain. In this paper, we propose a scheme for Automatic Modulation Classification (AMC) using modern architectures of Convolutional Neural Networks (CNN), through generating spectrum images of eleven different modulation types. Additionally, we perform resolution transformation of spectrograms that results up to 99.61% of computational load reduction and 8x faster conversion from the received I/Q data. This proposed AMC is implemented on CPU and GPU, to recognize digital as well as analogue signal modulation schemes on signals. The performance is evaluated on existing CNN models including SqueezeNet, Resnet-50, InceptionResnet-V2, Inception-V3, VGG-16 and Densenet-201. Best results of 91.2% are achieved in presence of AWGN and other noise impairments in the signals, stating that the transformed spectrogram-based AMC has good classification accuracy as the spectral features are highly discriminant, and CNN based models have capability to extract these high-dimensional features. The spectrograms were created under different SNRs ranging from 5 to 30db with a step size of 5db to observe the experimental results at various SNR levels. The proposed methodology is efficient to be applied in wireless communication networks for real-time applications.
Divided spectro-temporal attention for sound event localization and detection in real scenes for DCASE2023 challenge
Jun 05, 2023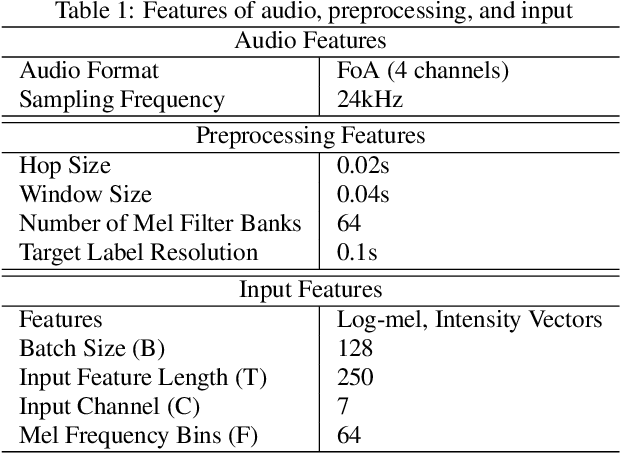
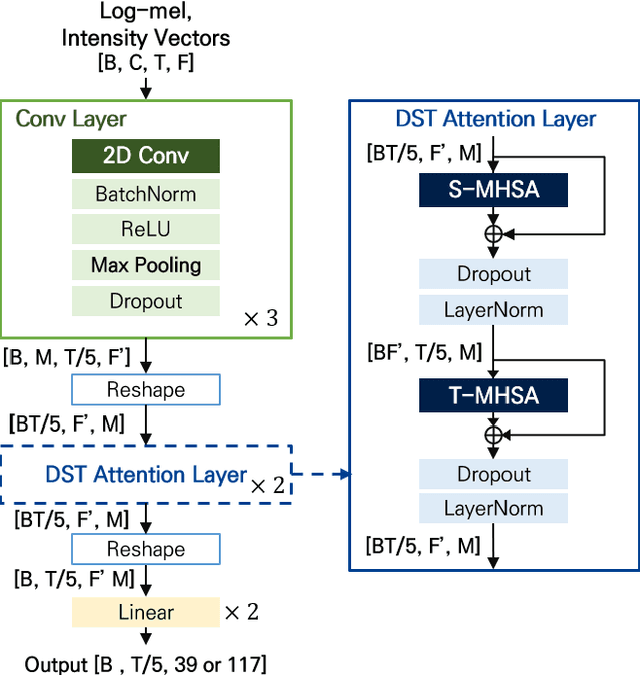
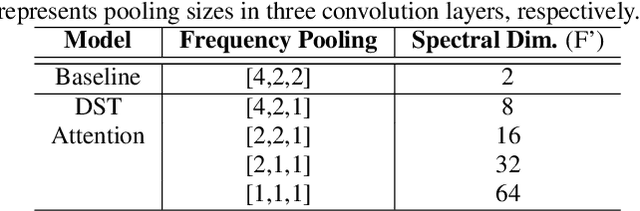
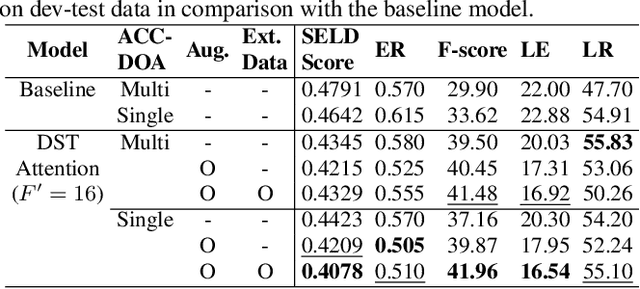
Localizing sounds and detecting events in different room environments is a difficult task, mainly due to the wide range of reflections and reverberations. When training neural network models with sounds recorded in only a few room environments, there is a tendency for the models to become overly specialized to those specific environments, resulting in overfitting. To address this overfitting issue, we propose divided spectro-temporal attention. In comparison to the baseline method, which utilizes a convolutional recurrent neural network (CRNN) followed by a temporal multi-head self-attention layer (MHSA), we introduce a separate spectral attention layer that aggregates spectral features prior to the temporal MHSA. To achieve efficient spectral attention, we reduce the frequency pooling size in the convolutional encoder of the baseline to obtain a 3D tensor that incorporates information about frequency, time, and channel. As a result, we can implement spectral attention with channel embeddings, which is not possible in the baseline method dealing with only temporal context in the RNN and MHSA layers. We demonstrate that the proposed divided spectro-temporal attention significantly improves the performance of sound event detection and localization scores for real test data from the STARSS23 development dataset. Additionally, we show that various data augmentations, such as frameshift, time masking, channel swapping, and moderate mix-up, along with the use of external data, contribute to the overall improvement in SELD performance.