 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding and Mitigating Copying in Diffusion Models
May 31, 2023

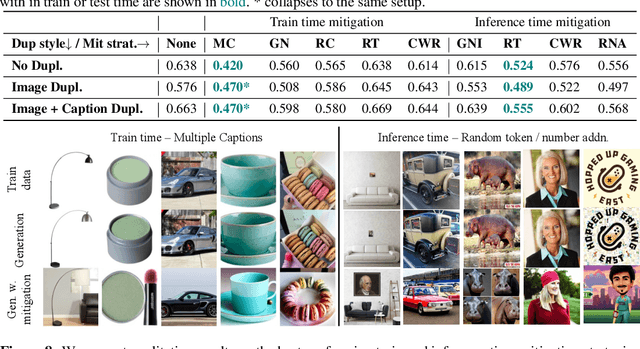

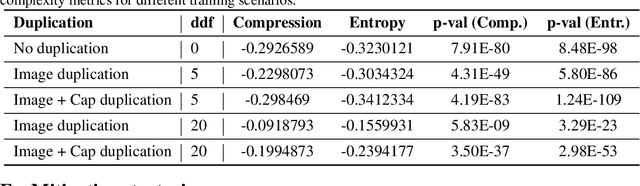
Images generated by diffusion models like Stable Diffusion are increasingly widespread. Recent works and even lawsuits have shown that these models are prone to replicating their training data, unbeknownst to the user. In this paper, we first analyze this memorization problem in text-to-image diffusion models. While it is widely believed that duplicated images in the training set are responsible for content replication at inference time, we observe that the text conditioning of the model plays a similarly important role. In fact, we see in our experiments that data replication often does not happen for unconditional models, while it is common in the text-conditional case. Motivated by our findings, we then propose several techniques for reducing data replication at both training and inference time by randomizing and augmenting image captions in the training set.
A Tale of Two Laws of Semantic Change: Predicting Synonym Changes with Distributional Semantic Models
May 30, 2023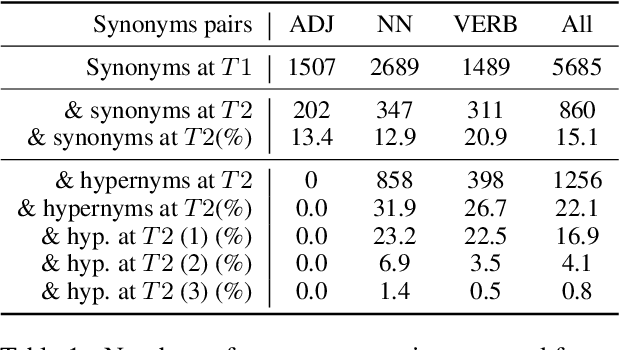
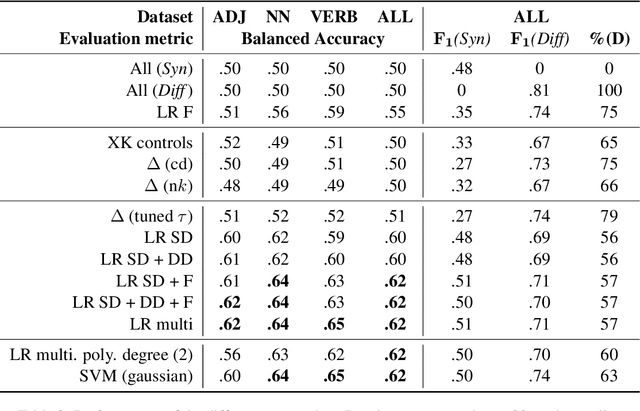
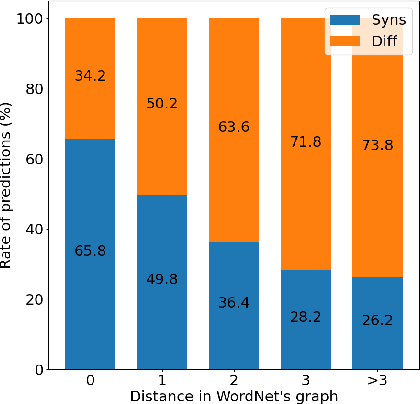
Lexical Semantic Change is the study of how the meaning of words evolves through time. Another related question is whether and how lexical relations over pairs of words, such as synonymy, change over time. There are currently two competing, apparently opposite hypotheses in the historical linguistic literature regarding how synonymous words evolve: the Law of Differentiation (LD) argues that synonyms tend to take on different meanings over time, whereas the Law of Parallel Change (LPC) claims that synonyms tend to undergo the same semantic change and therefore remain synonyms. So far, there has been little research using distributional models to assess to what extent these laws apply on historical corpora. In this work, we take a first step toward detecting whether LD or LPC operates for given word pairs. After recasting the problem into a more tractable task, we combine two linguistic resources to propose the first complete evaluation framework on this problem and provide empirical evidence in favor of a dominance of LD. We then propose various computational approaches to the problem using Distributional Semantic Models and grounded in recent literature on Lexical Semantic Change detection. Our best approaches achieve a balanced accuracy above 0.6 on our dataset. We discuss challenges still faced by these approaches, such as polysemy or the potential confusion between synonymy and hypernymy.
Actor-Critic learning for mean-field control in continuous time
Mar 13, 2023
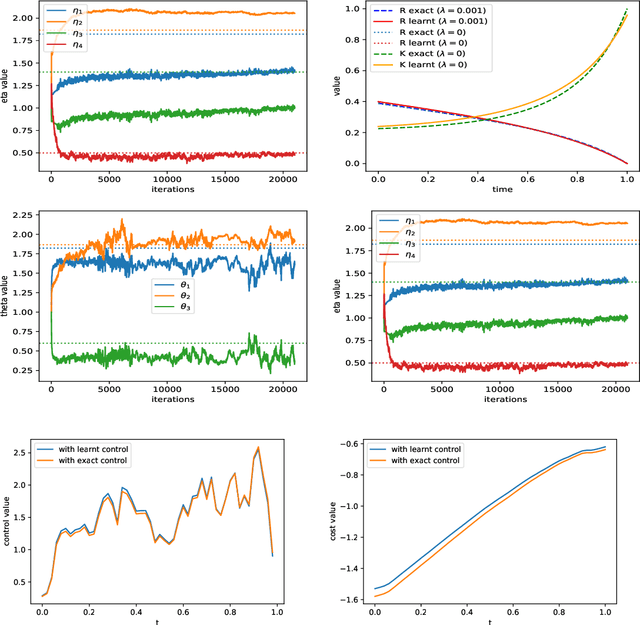
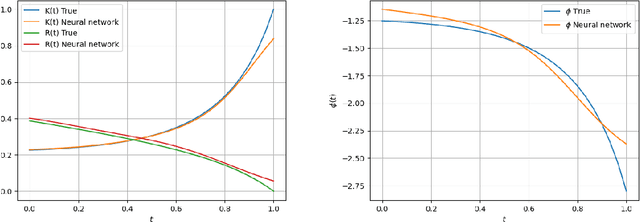
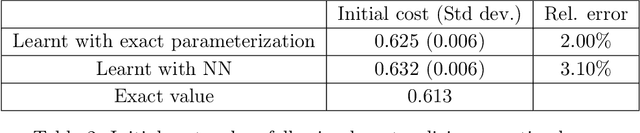
We study policy gradient for mean-field control in continuous time in a reinforcement learning setting. By considering randomised policies with entropy regularisation, we derive a gradient expectation representation of the value function, which is amenable to actor-critic type algorithms, where the value functions and the policies are learnt alternately based on observation samples of the state and model-free estimation of the population state distribution, either by offline or online learning. In the linear-quadratic mean-field framework, we obtain an exact parametrisation of the actor and critic functions defined on the Wasserstein space. Finally, we illustrate the results of our algorithms with some numerical experiments on concrete examples.
FormerTime: Hierarchical Multi-Scale Representations for Multivariate Time Series Classification
Feb 20, 2023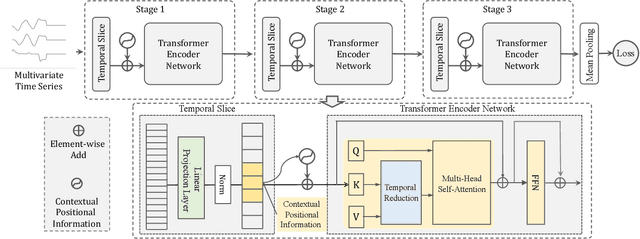
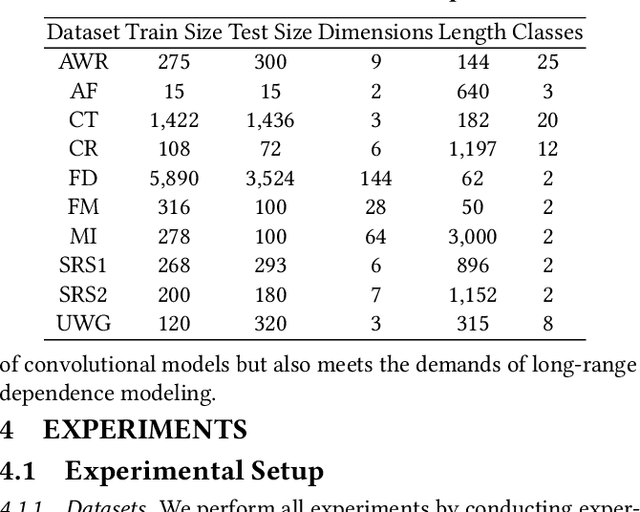
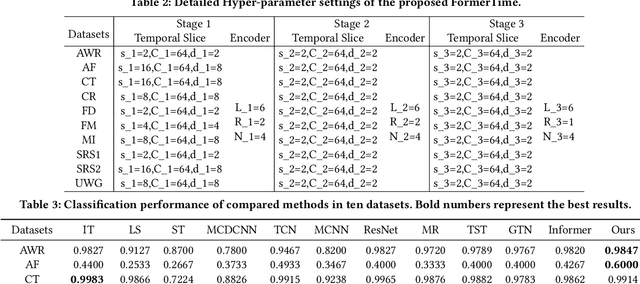

Deep learning-based algorithms, e.g., convolutional networks, have significantly facilitated multivariate time series classification (MTSC) task. Nevertheless, they suffer from the limitation in modeling long-range dependence due to the nature of convolution operations. Recent advancements have shown the potential of transformers to capture long-range dependence. However, it would incur severe issues, such as fixed scale representations, temporal-invariant and quadratic time complexity, with transformers directly applicable to the MTSC task because of the distinct properties of time series data. To tackle these issues, we propose FormerTime, an hierarchical representation model for improving the classification capacity for the MTSC task. In the proposed FormerTime, we employ a hierarchical network architecture to perform multi-scale feature maps. Besides, a novel transformer encoder is further designed, in which an efficient temporal reduction attention layer and a well-informed contextual positional encoding generating strategy are developed. To sum up, FormerTime exhibits three aspects of merits: (1) learning hierarchical multi-scale representations from time series data, (2) inheriting the strength of both transformers and convolutional networks, and (3) tacking the efficiency challenges incurred by the self-attention mechanism. Extensive experiments performed on $10$ publicly available datasets from UEA archive verify the superiorities of the FormerTime compared to previous competitive baselines.
Real time enhancement of operator's ergonomics in physical human - robot collaboration scenarios using a multi-stereo camera system
Apr 11, 2023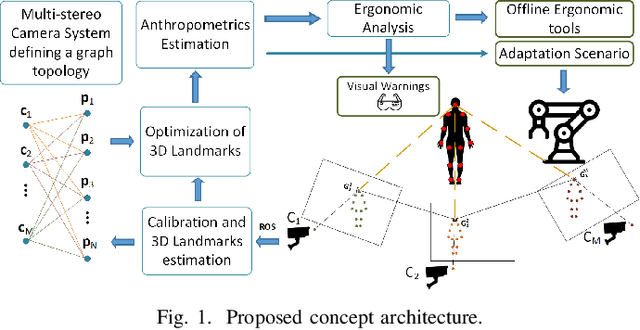
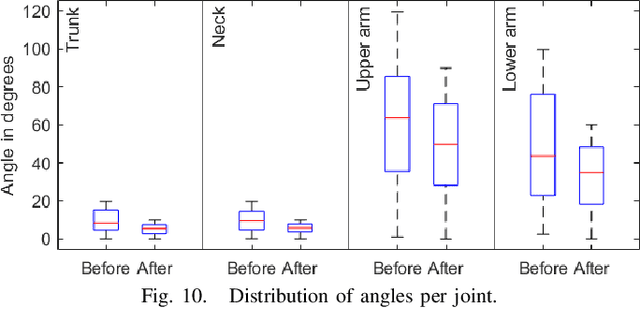

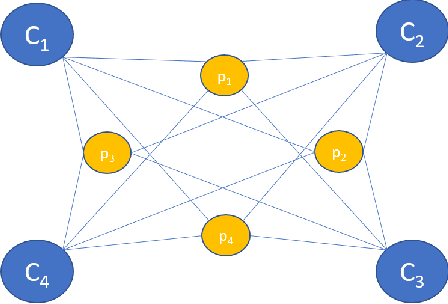
In collaborative tasks where humans work alongside machines, the robot's movements and behaviour can have a significant impact on the operator's safety, health, and comfort. To address this issue, we present a multi-stereo camera system that continuously monitors the operator's posture while they work with the robot. This system uses a novel distributed fusion approach to assess the operator's posture in real-time and to help avoid uncomfortable or unsafe positions. The system adjusts the robot's movements and informs the operator of any incorrect or potentially harmful postures, reducing the risk of accidents, strain, and musculoskeletal disorders. The analysis is personalized, taking into account the unique anthropometric characteristics of each operator, to ensure optimal ergonomics. The results of our experiments show that the proposed approach leads to improved human body postures and offers a promising solution for enhancing the ergonomics of operators in collaborative tasks.
EdgeYOLO: An Edge-Real-Time Object Detector
Feb 15, 2023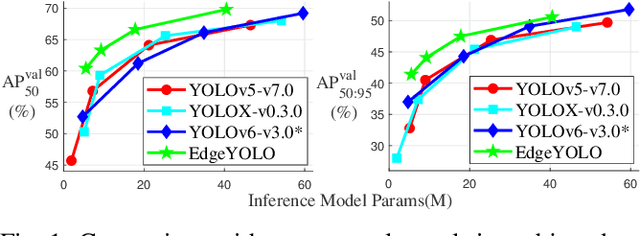
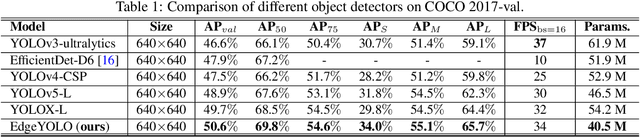

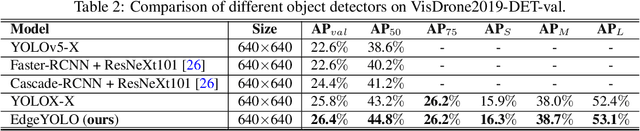
This paper proposes an efficient, low-complexity and anchor-free object detector based on the state-of-the-art YOLO framework, which can be implemented in real time on edge computing platforms. We develop an enhanced data augmentation method to effectively suppress overfitting during training, and design a hybrid random loss function to improve the detection accuracy of small objects. Inspired by FCOS, a lighter and more efficient decoupled head is proposed, and its inference speed can be improved with little loss of precision. Our baseline model can reach the accuracy of 50.6% AP50:95 and 69.8% AP50 in MS COCO2017 dataset, 26.4% AP50:95 and 44.8% AP50 in VisDrone2019-DET dataset, and it meets real-time requirements (FPS>=30) on edge-computing device Nvidia Jetson AGX Xavier. We also designed lighter models with less parameters for edge computing devices with lower computing power, which also show better performances. Our source code, hyper-parameters and model weights are all available at https://github.com/LSH9832/edgeyolo.
InGram: Inductive Knowledge Graph Embedding via Relation Graphs
Jun 01, 2023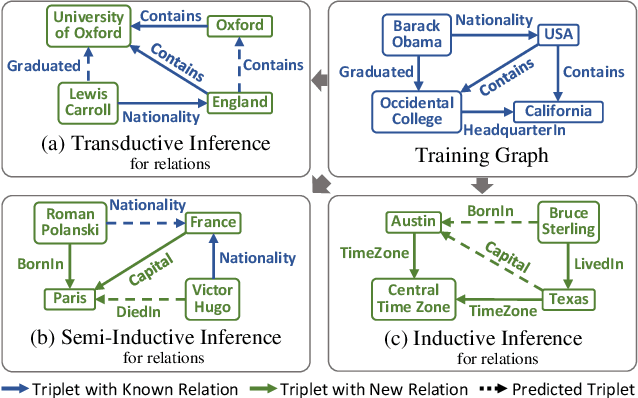
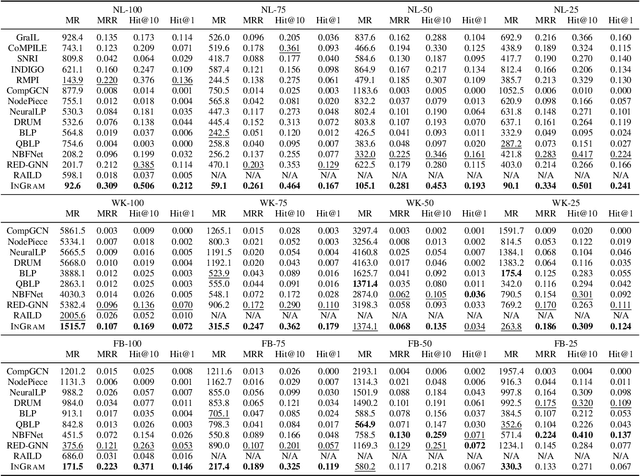
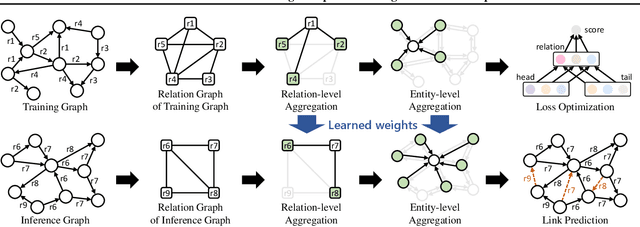
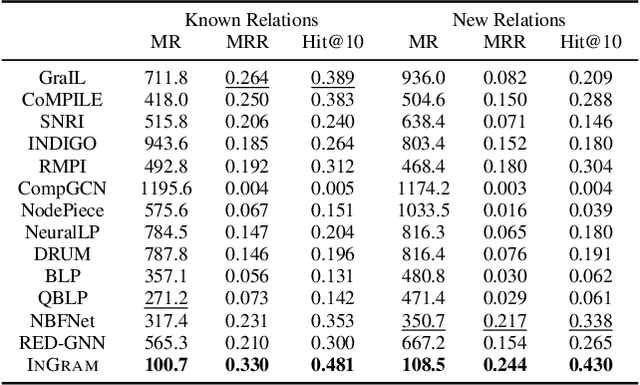
Inductive knowledge graph completion has been considered as the task of predicting missing triplets between new entities that are not observed during training. While most inductive knowledge graph completion methods assume that all entities can be new, they do not allow new relations to appear at inference time. This restriction prohibits the existing methods from appropriately handling real-world knowledge graphs where new entities accompany new relations. In this paper, we propose an INductive knowledge GRAph eMbedding method, InGram, that can generate embeddings of new relations as well as new entities at inference time. Given a knowledge graph, we define a relation graph as a weighted graph consisting of relations and the affinity weights between them. Based on the relation graph and the original knowledge graph, InGram learns how to aggregate neighboring embeddings to generate relation and entity embeddings using an attention mechanism. Experimental results show that InGram outperforms 14 different state-of-the-art methods on varied inductive learning scenarios.
TransAdapt: A Transformative Framework for Online Test Time Adaptive Semantic Segmentation
Feb 24, 2023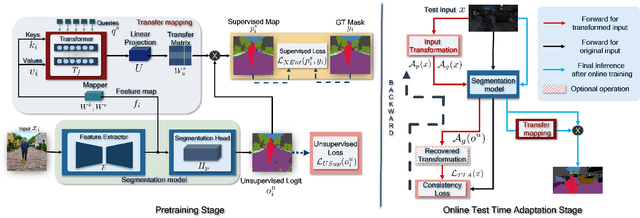
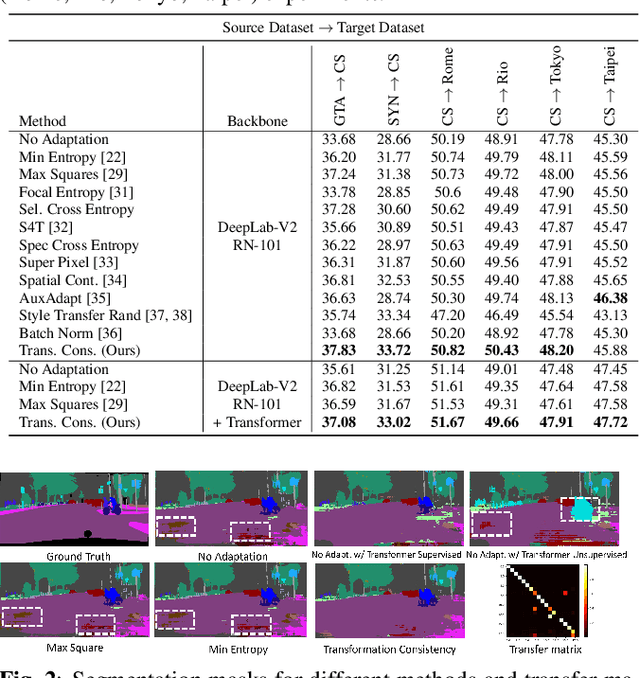

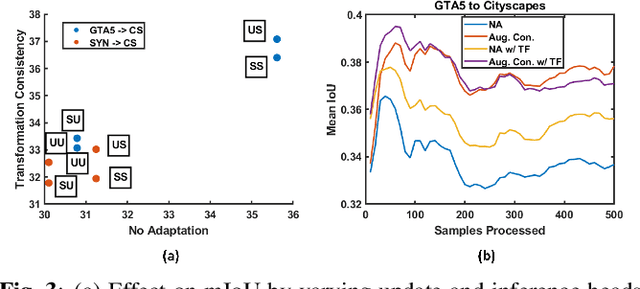
Test-time adaptive (TTA) semantic segmentation adapts a source pre-trained image semantic segmentation model to unlabeled batches of target domain test images, different from real-world, where samples arrive one-by-one in an online fashion. To tackle online settings, we propose TransAdapt, a framework that uses transformer and input transformations to improve segmentation performance. Specifically, we pre-train a transformer-based module on a segmentation network that transforms unsupervised segmentation output to a more reliable supervised output, without requiring test-time online training. To also facilitate test-time adaptation, we propose an unsupervised loss based on the transformed input that enforces the model to be invariant and equivariant to photometric and geometric perturbations, respectively. Overall, our framework produces higher quality segmentation masks with up to 17.6% and 2.8% mIOU improvement over no-adaptation and competitive baselines, respectively.
PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices
May 15, 2023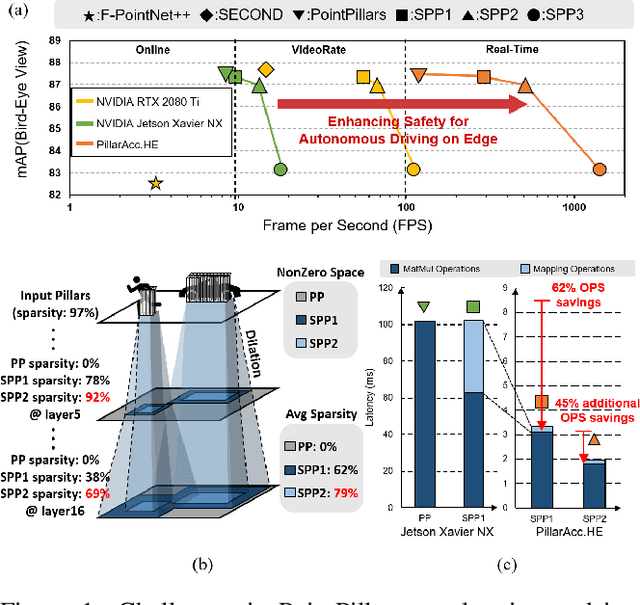
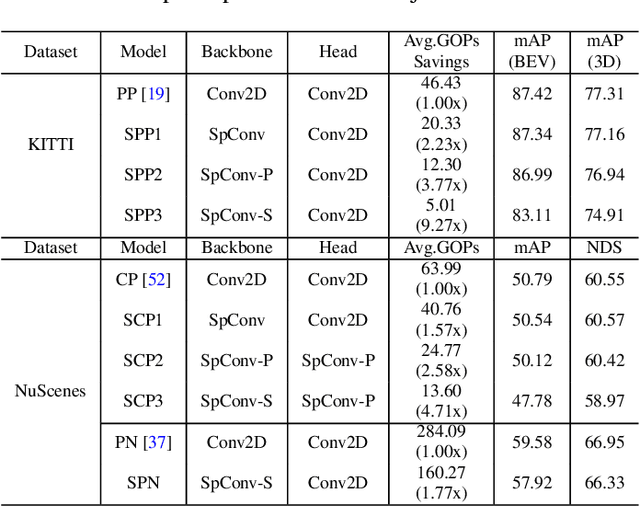
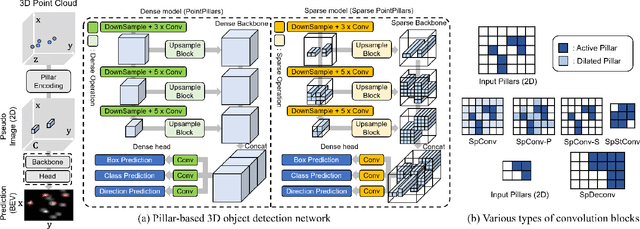
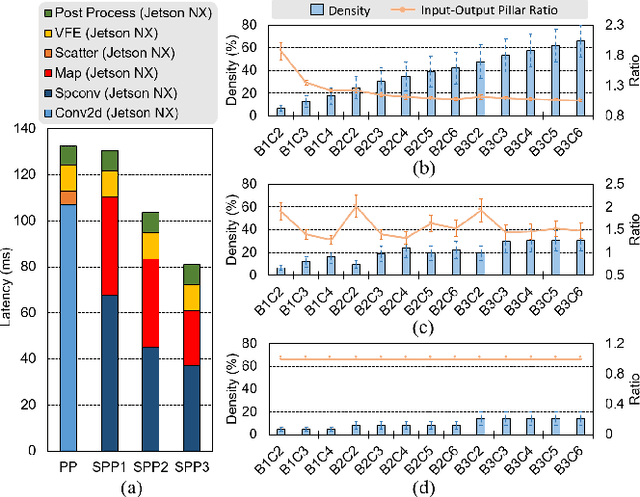
3D object detection using point cloud (PC) data is vital for autonomous driving perception pipelines, where efficient encoding is key to meeting stringent resource and latency requirements. PointPillars, a widely adopted bird's-eye view (BEV) encoding, aggregates 3D point cloud data into 2D pillars for high-accuracy 3D object detection. However, most state-of-the-art methods employing PointPillar overlook the inherent sparsity of pillar encoding, missing opportunities for significant computational reduction. In this study, we propose a groundbreaking algorithm-hardware co-design that accelerates sparse convolution processing and maximizes sparsity utilization in pillar-based 3D object detection networks. We investigate sparsification opportunities using an advanced pillar-pruning method, achieving an optimal balance between accuracy and sparsity. We introduce PillarAcc, a state-of-the-art sparsity support mechanism that enhances sparse pillar convolution through linear complexity input-output mapping generation and conflict-free gather-scatter memory access. Additionally, we propose dataflow optimization techniques, dynamically adjusting the pillar processing schedule for optimal hardware utilization under diverse sparsity operations. We evaluate PillarAcc on various cutting-edge 3D object detection networks and benchmarks, achieving remarkable speedup and energy savings compared to representative edge platforms, demonstrating record-breaking PointPillars speed of 500FPS with minimal compromise in accuracy.
Image Captioners Are Scalable Vision Learners Too
Jun 13, 2023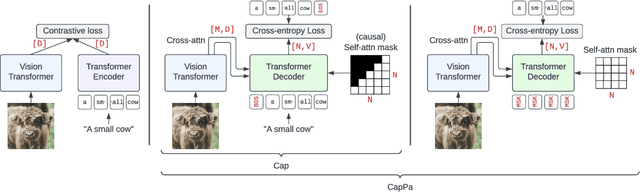
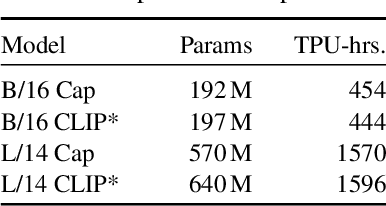
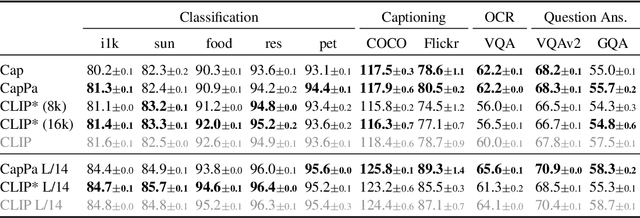
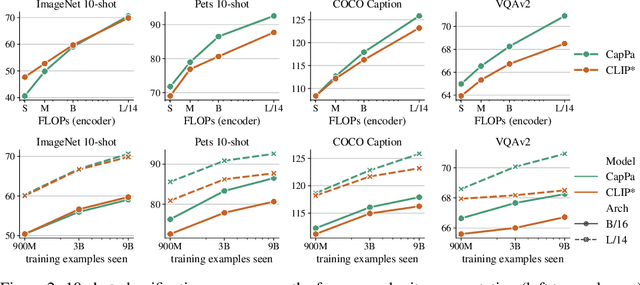
Contrastive pretraining on image-text pairs from the web is one of the most popular large-scale pretraining strategies for vision backbones, especially in the context of large multimodal models. At the same time, image captioning on this type of data is commonly considered an inferior pretraining strategy. In this paper, we perform a fair comparison of these two pretraining strategies, carefully matching training data, compute, and model capacity. Using a standard encoder-decoder transformer, we find that captioning alone is surprisingly effective: on classification tasks, captioning produces vision encoders competitive with contrastively pretrained encoders, while surpassing them on vision & language tasks. We further analyze the effect of the model architecture and scale, as well as the pretraining data on the representation quality, and find that captioning exhibits the same or better scaling behavior along these axes. Overall our results show that plain image captioning is a more powerful pretraining strategy than was previously believed.