 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Trans-Dimensional Generative Modeling via Jump Diffusion Models
May 25, 2023
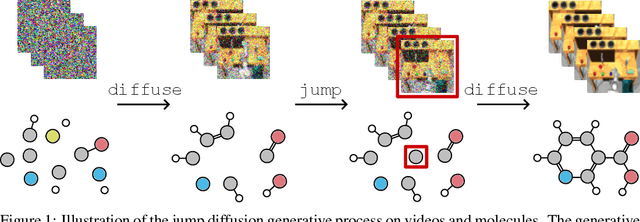

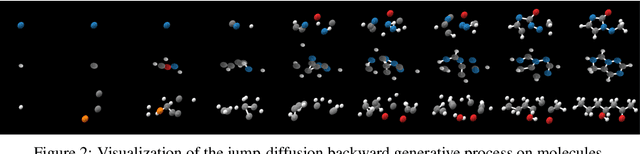
We propose a new class of generative models that naturally handle data of varying dimensionality by jointly modeling the state and dimension of each datapoint. The generative process is formulated as a jump diffusion process that makes jumps between different dimensional spaces. We first define a dimension destroying forward noising process, before deriving the dimension creating time-reversed generative process along with a novel evidence lower bound training objective for learning to approximate it. Simulating our learned approximation to the time-reversed generative process then provides an effective way of sampling data of varying dimensionality by jointly generating state values and dimensions. We demonstrate our approach on molecular and video datasets of varying dimensionality, reporting better compatibility with test-time diffusion guidance imputation tasks and improved interpolation capabilities versus fixed dimensional models that generate state values and dimensions separately.
Dynamic Geometry-Based Stochastic Channel Modeling for Polarized MIMO Systems with Moving Scatterers
Jun 07, 2023This paper introduces a four-dimensional (4D) geometry-based stochastic model (GBSM) for polarized multiple-input multiple-output (MIMO) systems with moving scatterers. We propose a novel motion path model with high degrees of freedom based on the Brownian Motion (BM) random process for randomly moving scatterers. This model is capable of analyzing the effect of both deterministically and randomly moving scatterers on channel properties. The mixture of Von Mises Fisher (VMF) distribution is considered for scatterers resulting in a more general and practical model. The proposed motion path model is applied to the clusters of scatterers with the mixture of VMF distribution, and a closed form formula for calculating space time correlation function (STCF) is achieved, allowing the study of the behavior of channel correlation and channel capacity in the time domain with the presence of stationary and moving scatterers. To obtain numerical results for channel capacity, we employed Monte Carlo simulation method for channel realization purpose. The impact of moving scatterers on the performance of polarized MIMO systems is evaluated using 2 by 2 MIMO configurations with various dual polarizations, i.e. V/V, V/H, and slanted 45{\deg} polarizations for different signal-to-noise (SNR) regimes. The proposed motion path model can be applied to study various dynamic systems with moving objects. The presented process and achieved formula are general and can be applied to polarized MIMO systems with any arbitrary number of antennas and polarizations.
Agent Performing Autonomous Stock Trading under Good and Bad Situations
Jun 06, 2023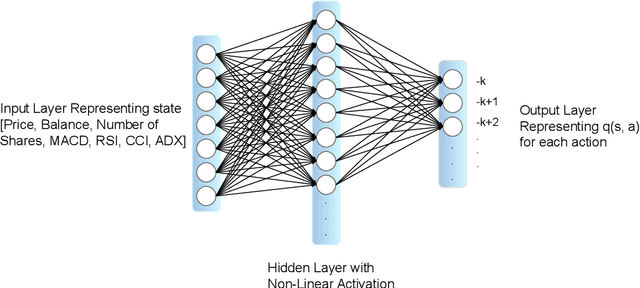

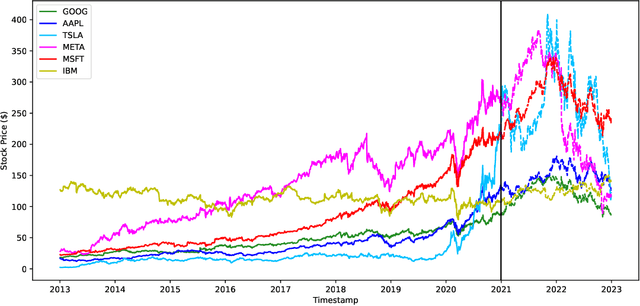
Stock trading is one of the popular ways for financial management. However, the market and the environment of economy is unstable and usually not predictable. Furthermore, engaging in stock trading requires time and effort to analyze, create strategies, and make decisions. It would be convenient and effective if an agent could assist or even do the task of analyzing and modeling the past data and then generate a strategy for autonomous trading. Recently, reinforcement learning has been shown to be robust in various tasks that involve achieving a goal with a decision making strategy based on time-series data. In this project, we have developed a pipeline that simulates the stock trading environment and have trained an agent to automate the stock trading process with deep reinforcement learning methods, including deep Q-learning, deep SARSA, and the policy gradient method. We evaluate our platform during relatively good (before 2021) and bad (2021 - 2022) situations. The stocks we've evaluated on including Google, Apple, Tesla, Meta, Microsoft, and IBM. These stocks are among the popular ones, and the changes in trends are representative in terms of having good and bad situations. We showed that before 2021, the three reinforcement methods we have tried always provide promising profit returns with total annual rates around $70\%$ to $90\%$, while maintain a positive profit return after 2021 with total annual rates around 2% to 7%.
Sequential Principal-Agent Problems with Communication: Efficient Computation and Learning
Jun 06, 2023We study a sequential decision making problem between a principal and an agent with incomplete information on both sides. In this model, the principal and the agent interact in a stochastic environment, and each is privy to observations about the state not available to the other. The principal has the power of commitment, both to elicit information from the agent and to provide signals about her own information. The principal and the agent communicate their signals to each other, and select their actions independently based on this communication. Each player receives a payoff based on the state and their joint actions, and the environment moves to a new state. The interaction continues over a finite time horizon, and both players act to optimize their own total payoffs over the horizon. Our model encompasses as special cases stochastic games of incomplete information and POMDPs, as well as sequential Bayesian persuasion and mechanism design problems. We study both computation of optimal policies and learning in our setting. While the general problems are computationally intractable, we study algorithmic solutions under a conditional independence assumption on the underlying state-observation distributions. We present an polynomial-time algorithm to compute the principal's optimal policy up to an additive approximation. Additionally, we show an efficient learning algorithm in the case where the transition probabilities are not known beforehand. The algorithm guarantees sublinear regret for both players.
Linearly-scalable learning of smooth low-dimensional patterns with permutation-aided entropic dimension reduction
Jun 17, 2023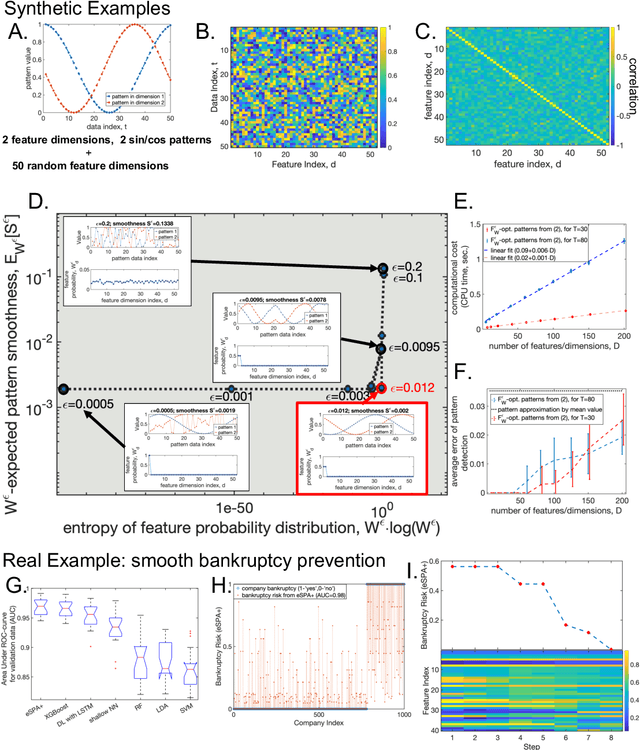
In many data science applications, the objective is to extract appropriately-ordered smooth low-dimensional data patterns from high-dimensional data sets. This is challenging since common sorting algorithms are primarily aiming at finding monotonic orderings in low-dimensional data, whereas typical dimension reduction and feature extraction algorithms are not primarily designed for extracting smooth low-dimensional data patterns. We show that when selecting the Euclidean smoothness as a pattern quality criterium, both of these problems (finding the optimal 'crisp' data permutation and extracting the sparse set of permuted low-dimensional smooth patterns) can be efficiently solved numerically as one unsupervised entropy-regularized iterative optimization problem. We formulate and prove the conditions for monotonicity and convergence of this linearly-scalable (in dimension) numerical procedure, with the iteration cost scaling of $\mathcal{O}(DT^2)$, where $T$ is the size of the data statistics and $D$ is a feature space dimension. The efficacy of the proposed method is demonstrated through the examination of synthetic examples as well as a real-world application involving the identification of smooth bankruptcy risk minimizing transition patterns from high-dimensional economical data. The results showcase that the statistical properties of the overall time complexity of the method exhibit linear scaling in the dimensionality $D$ within the specified confidence intervals.
Human-In-the-Loop for Bayesian Autonomous Materials Phase Mapping
Jun 17, 2023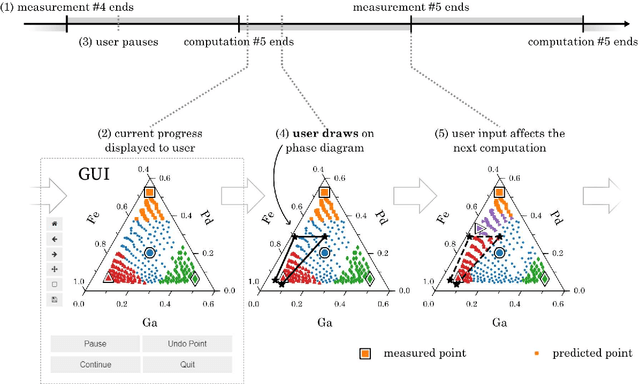
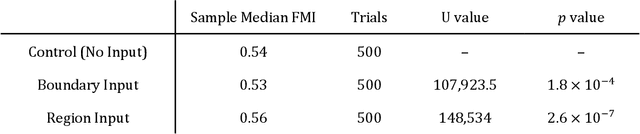
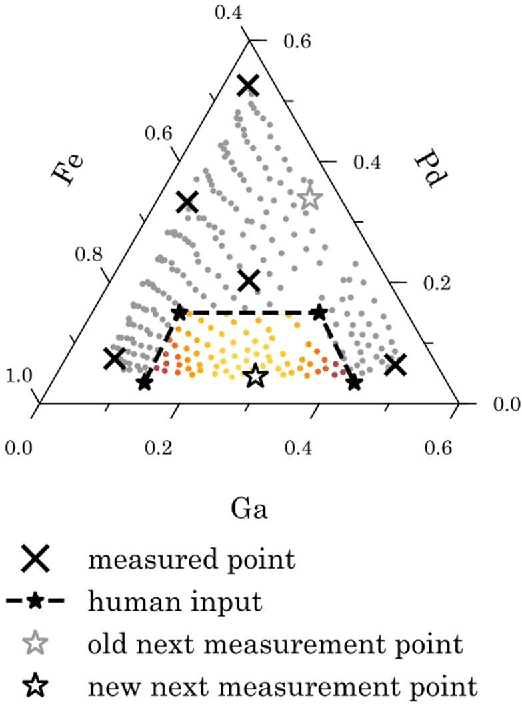
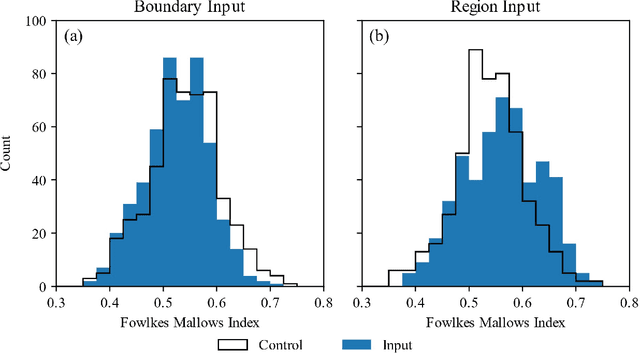
Autonomous experimentation (AE) combines machine learning and research hardware automation in a closed loop, guiding subsequent experiments toward user goals. As applied to materials research, AE can accelerate materials exploration, reducing time and cost compared to traditional Edisonian studies. Additionally, integrating knowledge from diverse sources including theory, simulations, literature, and domain experts can boost AE performance. Domain experts may provide unique knowledge addressing tasks that are difficult to automate. Here, we present a set of methods for integrating human input into an autonomous materials exploration campaign for composition-structure phase mapping. The methods are demonstrated on x-ray diffraction data collected from a thin film ternary combinatorial library. At any point during the campaign, the user can choose to provide input by indicating regions-of-interest, likely phase regions, and likely phase boundaries based on their prior knowledge (e.g., knowledge of the phase map of a similar material system), along with quantifying their certainty. The human input is integrated by defining a set of probabilistic priors over the phase map. Algorithm output is a probabilistic distribution over potential phase maps, given the data, model, and human input. We demonstrate a significant improvement in phase mapping performance given appropriate human input.
Neural Fast Full-Rank Spatial Covariance Analysis for Blind Source Separation
Jun 17, 2023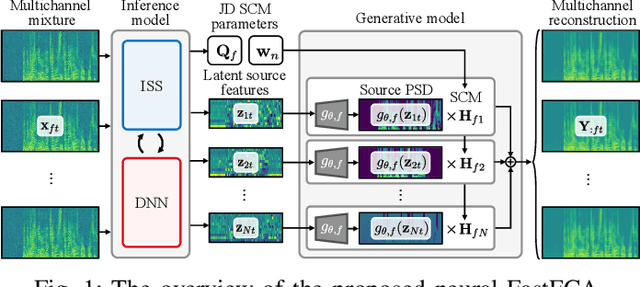
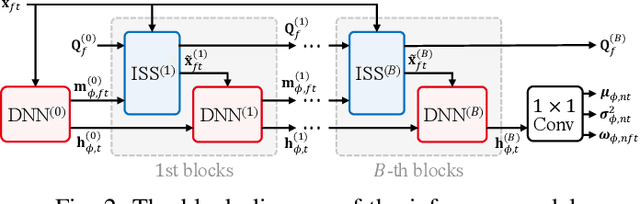
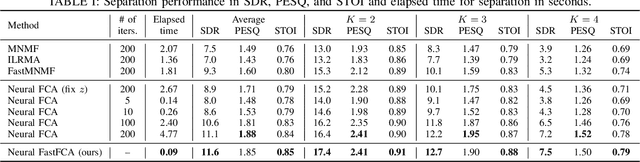
This paper describes an efficient unsupervised learning method for a neural source separation model that utilizes a probabilistic generative model of observed multichannel mixtures proposed for blind source separation (BSS). For this purpose, amortized variational inference (AVI) has been used for directly solving the inverse problem of BSS with full-rank spatial covariance analysis (FCA). Although this unsupervised technique called neural FCA is in principle free from the domain mismatch problem, it is computationally demanding due to the full rankness of the spatial model in exchange for robustness against relatively short reverberations. To reduce the model complexity without sacrificing performance, we propose neural FastFCA based on the jointly-diagonalizable yet full-rank spatial model. Our neural separation model introduced for AVI alternately performs neural network blocks and single steps of an efficient iterative algorithm called iterative source steering. This alternating architecture enables the separation model to quickly separate the mixture spectrogram by leveraging both the deep neural network and the multichannel optimization algorithm. The training objective with AVI is derived to maximize the marginalized likelihood of the observed mixtures. The experiment using mixture signals of two to four sound sources shows that neural FastFCA outperforms conventional BSS methods and reduces the computational time to about 2% of that for the neural FCA.
Scalable 3D Captioning with Pretrained Models
Jun 12, 2023

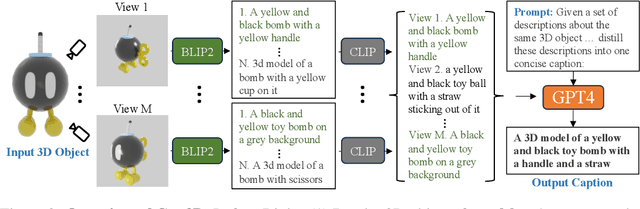
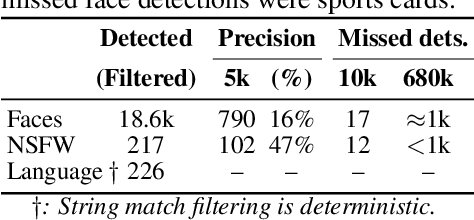
We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.
SafeDiffuser: Safe Planning with Diffusion Probabilistic Models
May 31, 2023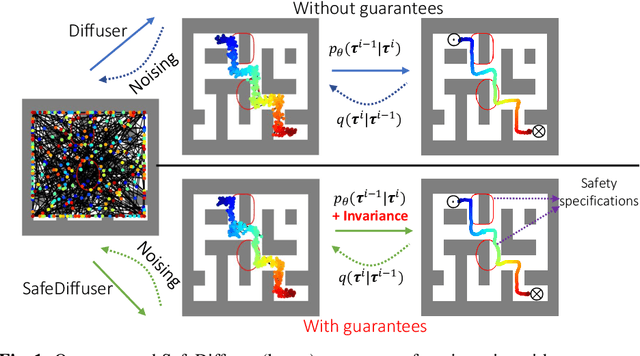
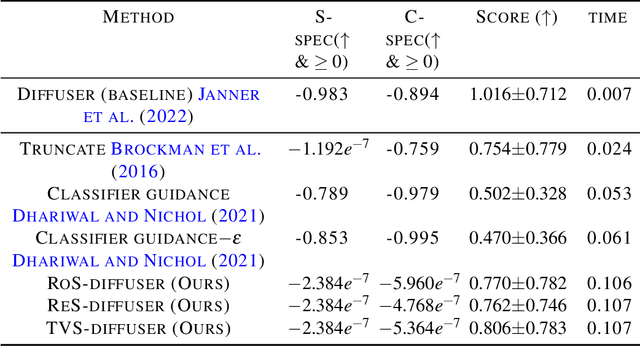
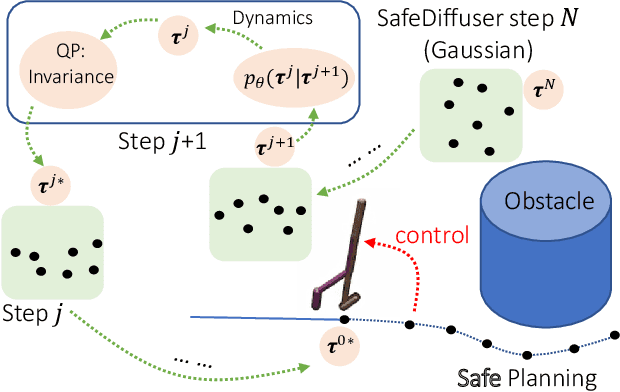
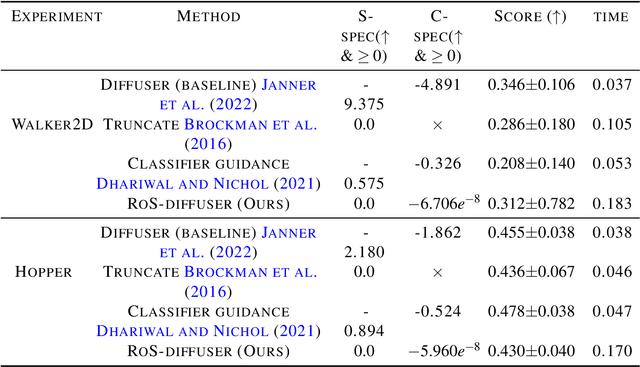
Diffusion model-based approaches have shown promise in data-driven planning, but there are no safety guarantees, thus making it hard to be applied for safety-critical applications. To address these challenges, we propose a new method, called SafeDiffuser, to ensure diffusion probabilistic models satisfy specifications by using a class of control barrier functions. The key idea of our approach is to embed the proposed finite-time diffusion invariance into the denoising diffusion procedure, which enables trustworthy diffusion data generation. Moreover, we demonstrate that our finite-time diffusion invariance method through generative models not only maintains generalization performance but also creates robustness in safe data generation. We test our method on a series of safe planning tasks, including maze path generation, legged robot locomotion, and 3D space manipulation, with results showing the advantages of robustness and guarantees over vanilla diffusion models.
Understanding and Mitigating Copying in Diffusion Models
May 31, 2023
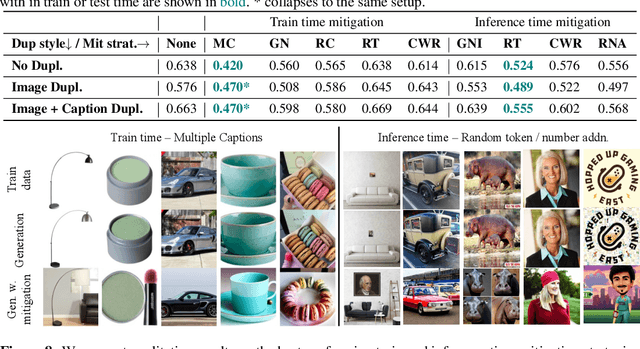

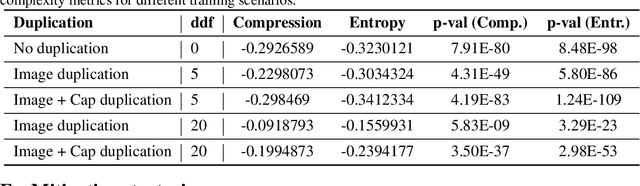
Images generated by diffusion models like Stable Diffusion are increasingly widespread. Recent works and even lawsuits have shown that these models are prone to replicating their training data, unbeknownst to the user. In this paper, we first analyze this memorization problem in text-to-image diffusion models. While it is widely believed that duplicated images in the training set are responsible for content replication at inference time, we observe that the text conditioning of the model plays a similarly important role. In fact, we see in our experiments that data replication often does not happen for unconditional models, while it is common in the text-conditional case. Motivated by our findings, we then propose several techniques for reducing data replication at both training and inference time by randomizing and augmenting image captions in the training set.