 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-shot Pose Transfer for Unrigged Stylized 3D Characters
May 31, 2023
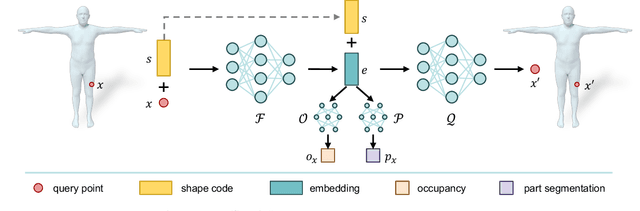

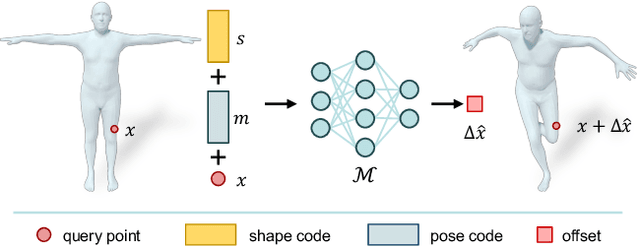
Transferring the pose of a reference avatar to stylized 3D characters of various shapes is a fundamental task in computer graphics. Existing methods either require the stylized characters to be rigged, or they use the stylized character in the desired pose as ground truth at training. We present a zero-shot approach that requires only the widely available deformed non-stylized avatars in training, and deforms stylized characters of significantly different shapes at inference. Classical methods achieve strong generalization by deforming the mesh at the triangle level, but this requires labelled correspondences. We leverage the power of local deformation, but without requiring explicit correspondence labels. We introduce a semi-supervised shape-understanding module to bypass the need for explicit correspondences at test time, and an implicit pose deformation module that deforms individual surface points to match the target pose. Furthermore, to encourage realistic and accurate deformation of stylized characters, we introduce an efficient volume-based test-time training procedure. Because it does not need rigging, nor the deformed stylized character at training time, our model generalizes to categories with scarce annotation, such as stylized quadrupeds. Extensive experiments demonstrate the effectiveness of the proposed method compared to the state-of-the-art approaches trained with comparable or more supervision. Our project page is available at https://jiashunwang.github.io/ZPT
Backdoor Attacks Against Incremental Learners: An Empirical Evaluation Study
May 28, 2023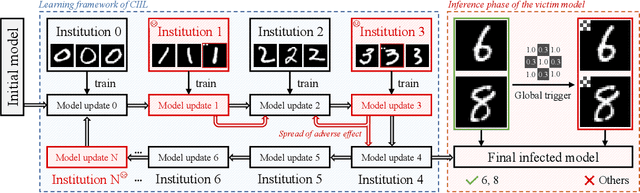
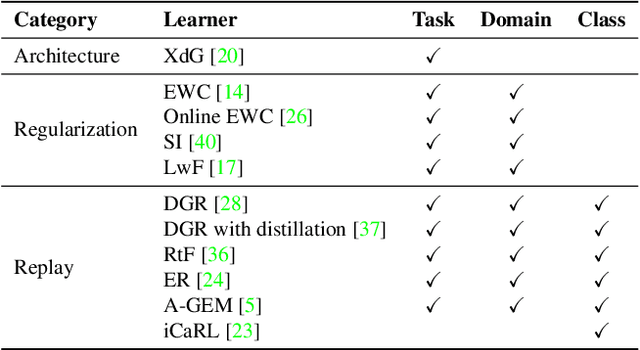

Large amounts of incremental learning algorithms have been proposed to alleviate the catastrophic forgetting issue arises while dealing with sequential data on a time series. However, the adversarial robustness of incremental learners has not been widely verified, leaving potential security risks. Specifically, for poisoning-based backdoor attacks, we argue that the nature of streaming data in IL provides great convenience to the adversary by creating the possibility of distributed and cross-task attacks -- an adversary can affect \textbf{any unknown} previous or subsequent task by data poisoning \textbf{at any time or time series} with extremely small amount of backdoor samples injected (e.g., $0.1\%$ based on our observations). To attract the attention of the research community, in this paper, we empirically reveal the high vulnerability of 11 typical incremental learners against poisoning-based backdoor attack on 3 learning scenarios, especially the cross-task generalization effect of backdoor knowledge, while the poison ratios range from $5\%$ to as low as $0.1\%$. Finally, the defense mechanism based on activation clustering is found to be effective in detecting our trigger pattern to mitigate potential security risks.
EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
Mar 13, 2023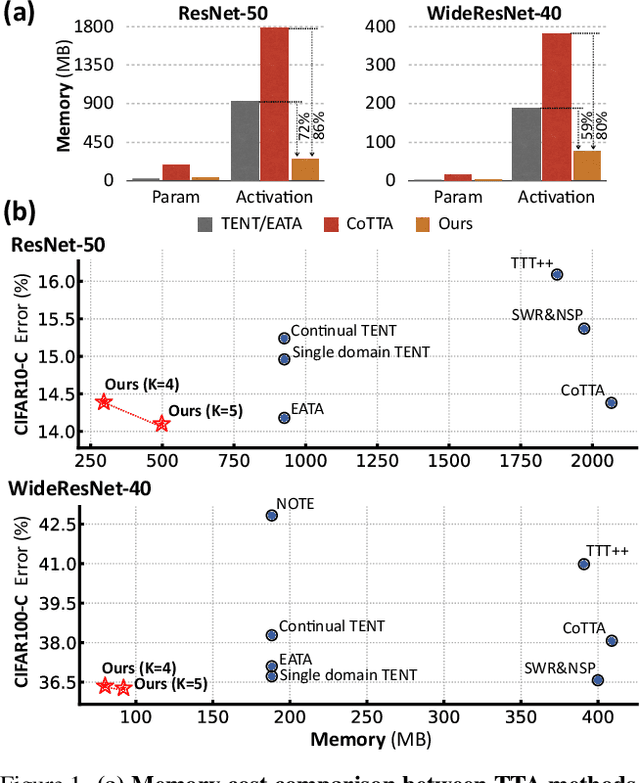
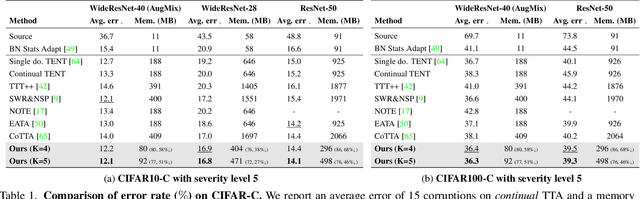
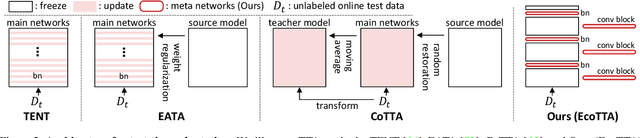
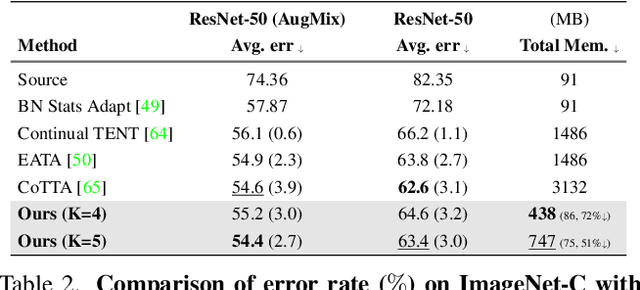
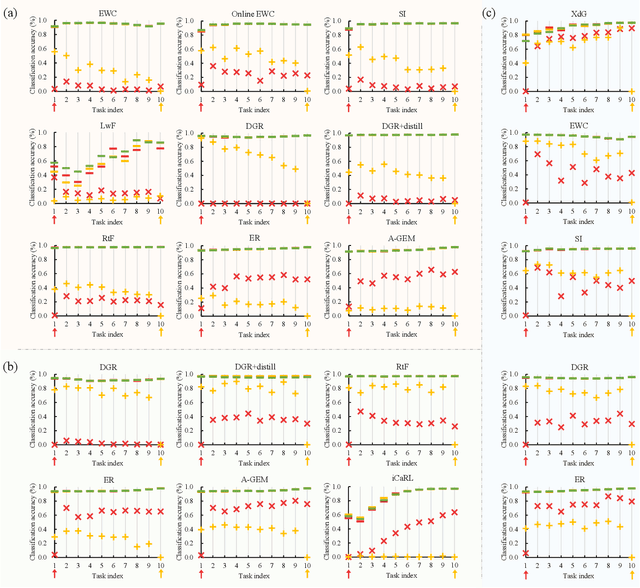
This paper presents a simple yet effective approach that improves continual test-time adaptation (TTA) in a memory-efficient manner. TTA may primarily be conducted on edge devices with limited memory, so reducing memory is crucial but has been overlooked in previous TTA studies. In addition, long-term adaptation often leads to catastrophic forgetting and error accumulation, which hinders applying TTA in real-world deployments. Our approach consists of two components to address these issues. First, we present lightweight meta networks that can adapt the frozen original networks to the target domain. This novel architecture minimizes memory consumption by decreasing the size of intermediate activations required for backpropagation. Second, our novel self-distilled regularization controls the output of the meta networks not to deviate significantly from the output of the frozen original networks, thereby preserving well-trained knowledge from the source domain. Without additional memory, this regularization prevents error accumulation and catastrophic forgetting, resulting in stable performance even in long-term test-time adaptation. We demonstrate that our simple yet effective strategy outperforms other state-of-the-art methods on various benchmarks for image classification and semantic segmentation tasks. Notably, our proposed method with ResNet-50 and WideResNet-40 takes 86% and 80% less memory than the recent state-of-the-art method, CoTTA.
Exploiting Intrinsic Stochasticity of Real-Time Simulation to Facilitate Robust Reinforcement Learning for Robot Manipulation
Apr 12, 2023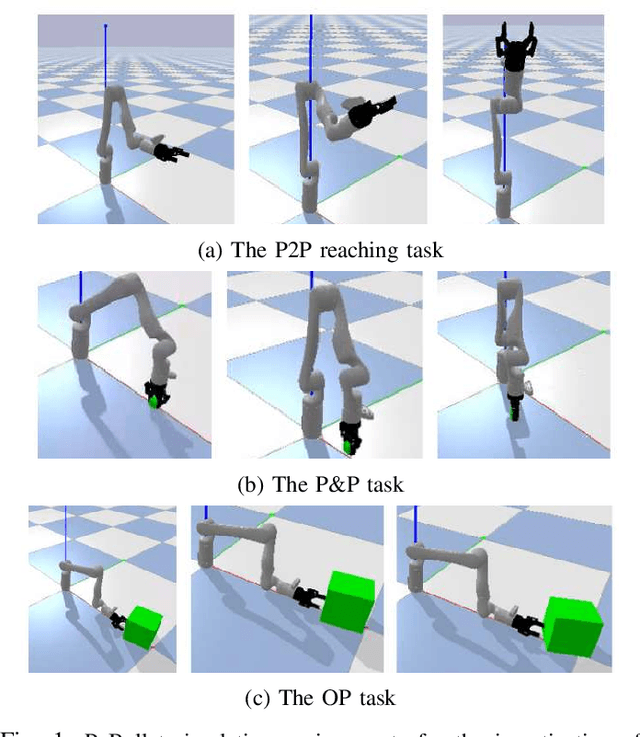

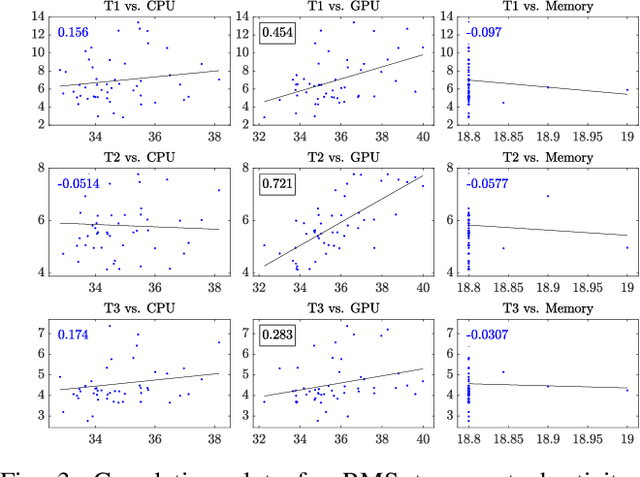
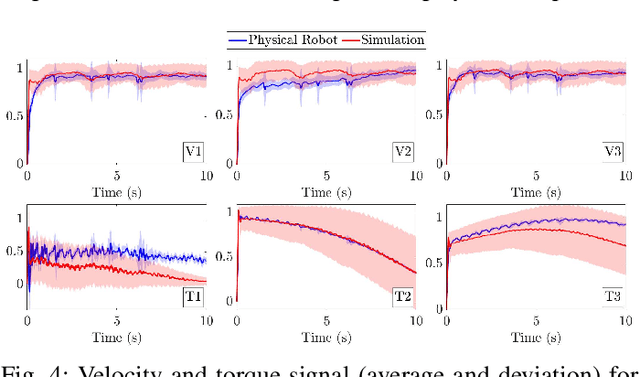
Simulation is essential to reinforcement learning (RL) before implementation in the real world, especially for safety-critical applications like robot manipulation. Conventionally, RL agents are sensitive to the discrepancies between the simulation and the real world, known as the sim-to-real gap. The application of domain randomization, a technique used to fill this gap, is limited to the imposition of heuristic-randomized models. We investigate the properties of intrinsic stochasticity of real-time simulation (RT-IS) of off-the-shelf simulation software and its potential to improve the robustness of RL methods and the performance of domain randomization. Firstly, we conduct analytical studies to measure the correlation of RT-IS with the occupation of the computer hardware and validate its comparability with the natural stochasticity of a physical robot. Then, we apply the RT-IS feature in the training of an RL agent. The simulation and physical experiment results verify the feasibility and applicability of RT-IS to robust RL agent design for robot manipulation tasks. The RT-IS-powered robust RL agent outperforms conventional RL agents on robots with modeling uncertainties. It requires fewer heuristic randomization and achieves better generalizability than the conventional domain-randomization-powered agents. Our findings provide a new perspective on the sim-to-real problem in practical applications like robot manipulation tasks.
Identifying and Extracting Rare Disease Phenotypes with Large Language Models
Jun 22, 2023
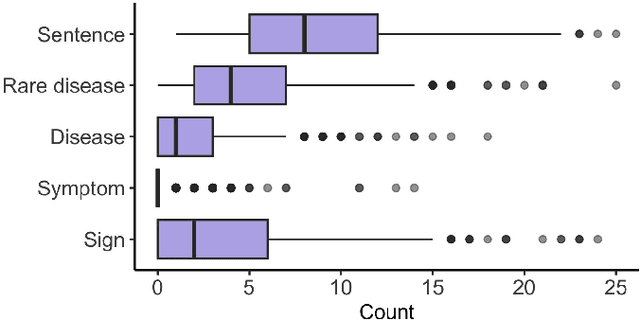

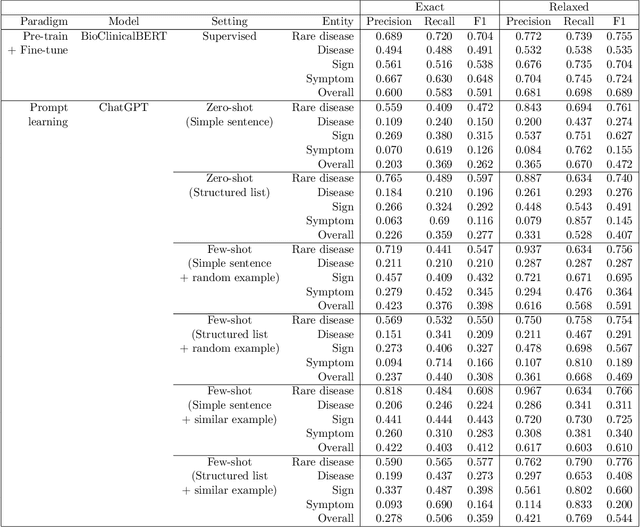
Rare diseases (RDs) are collectively common and affect 300 million people worldwide. Accurate phenotyping is critical for informing diagnosis and treatment, but RD phenotypes are often embedded in unstructured text and time-consuming to extract manually. While natural language processing (NLP) models can perform named entity recognition (NER) to automate extraction, a major bottleneck is the development of a large, annotated corpus for model training. Recently, prompt learning emerged as an NLP paradigm that can lead to more generalizable results without any (zero-shot) or few labeled samples (few-shot). Despite growing interest in ChatGPT, a revolutionary large language model capable of following complex human prompts and generating high-quality responses, none have studied its NER performance for RDs in the zero- and few-shot settings. To this end, we engineered novel prompts aimed at extracting RD phenotypes and, to the best of our knowledge, are the first the establish a benchmark for evaluating ChatGPT's performance in these settings. We compared its performance to the traditional fine-tuning approach and conducted an in-depth error analysis. Overall, fine-tuning BioClinicalBERT resulted in higher performance (F1 of 0.689) than ChatGPT (F1 of 0.472 and 0.591 in the zero- and few-shot settings, respectively). Despite this, ChatGPT achieved similar or higher accuracy for certain entities (i.e., rare diseases and signs) in the one-shot setting (F1 of 0.776 and 0.725). This suggests that with appropriate prompt engineering, ChatGPT has the potential to match or outperform fine-tuned language models for certain entity types with just one labeled sample. While the proliferation of large language models may provide opportunities for supporting RD diagnosis and treatment, researchers and clinicians should critically evaluate model outputs and be well-informed of their limitations.
Dynamic Causal Graph Convolutional Network for Traffic Prediction
Jun 12, 2023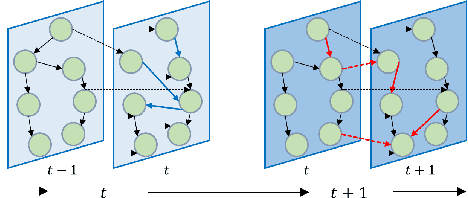
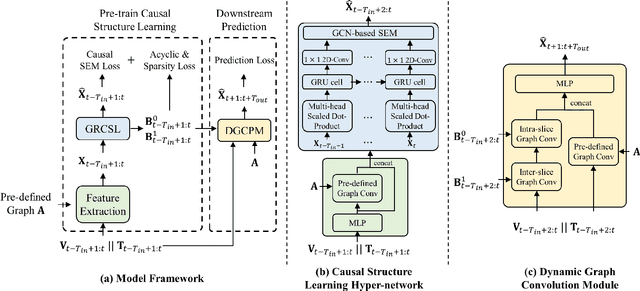
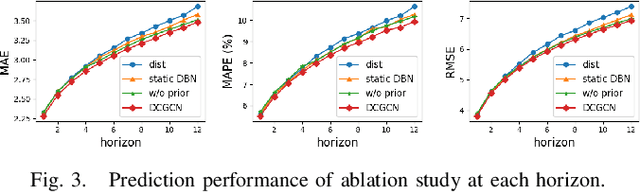
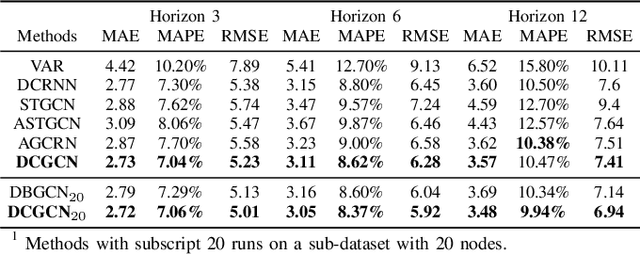
Modeling complex spatiotemporal dependencies in correlated traffic series is essential for traffic prediction. While recent works have shown improved prediction performance by using neural networks to extract spatiotemporal correlations, their effectiveness depends on the quality of the graph structures used to represent the spatial topology of the traffic network. In this work, we propose a novel approach for traffic prediction that embeds time-varying dynamic Bayesian network to capture the fine spatiotemporal topology of traffic data. We then use graph convolutional networks to generate traffic forecasts. To enable our method to efficiently model nonlinear traffic propagation patterns, we develop a deep learning-based module as a hyper-network to generate stepwise dynamic causal graphs. Our experimental results on a real traffic dataset demonstrate the superior prediction performance of the proposed method.
Quality of Service Based Radar Resource Management for Navigation and Positioning
Jun 12, 2023

In hostile environments, GNSS is a potentially unreliable solution for self-localization and navigation. Many systems only use an IMU as a backup system, resulting in integration errors which can dramatically increase during mission execution. We suggest using a fighter radar to illuminate satellites with known trajectories to enhance the self-localization information. This technique is time-consuming and resource-demanding but necessary as other tasks depend on the self-localization accuracy. Therefore an adaption of classical resource management frameworks is required. We propose a quality of service based resource manager with capabilities to account for inter-task dependencies to optimize the self-localization update strategy. Our results show that this leads to adaptive navigation update strategies, mastering the trade-off between self-localization and the requirements of other tasks.
* 8 pages, 9 figures
Parameterizing the cost function of Dynamic Time Warping with application to time series classification
Jan 24, 2023
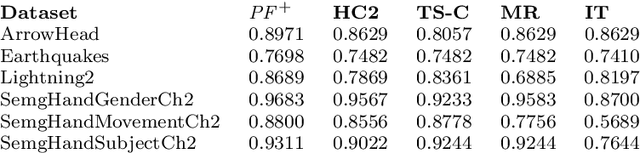
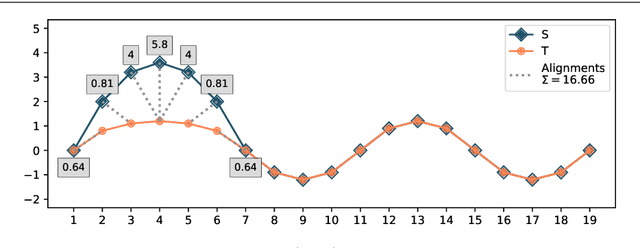
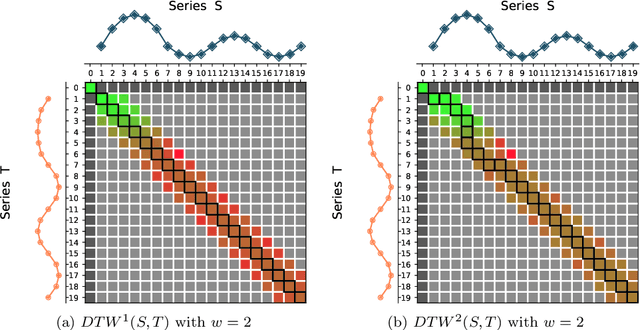
Dynamic Time Warping (DTW) is a popular time series distance measure that aligns the points in two series with one another. These alignments support warping of the time dimension to allow for processes that unfold at differing rates. The distance is the minimum sum of costs of the resulting alignments over any allowable warping of the time dimension. The cost of an alignment of two points is a function of the difference in the values of those points. The original cost function was the absolute value of this difference. Other cost functions have been proposed. A popular alternative is the square of the difference. However, to our knowledge, this is the first investigation of both the relative impacts of using different cost functions and the potential to tune cost functions to different tasks. We do so in this paper by using a tunable cost function {\lambda}{\gamma} with parameter {\gamma}. We show that higher values of {\gamma} place greater weight on larger pairwise differences, while lower values place greater weight on smaller pairwise differences. We demonstrate that training {\gamma} significantly improves the accuracy of both the DTW nearest neighbor and Proximity Forest classifiers.
Robust Statistical Beamforming with Multi-Cluster Tracking for Time-Varying Massive MIMO (Extended Version)
Mar 01, 2023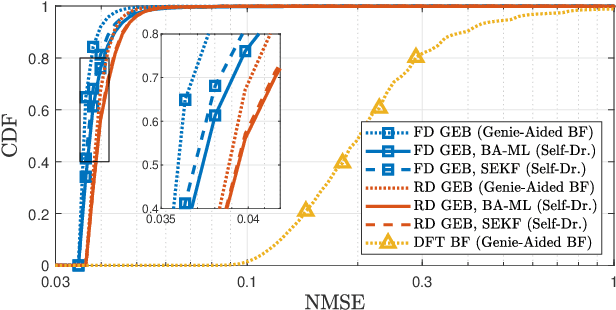
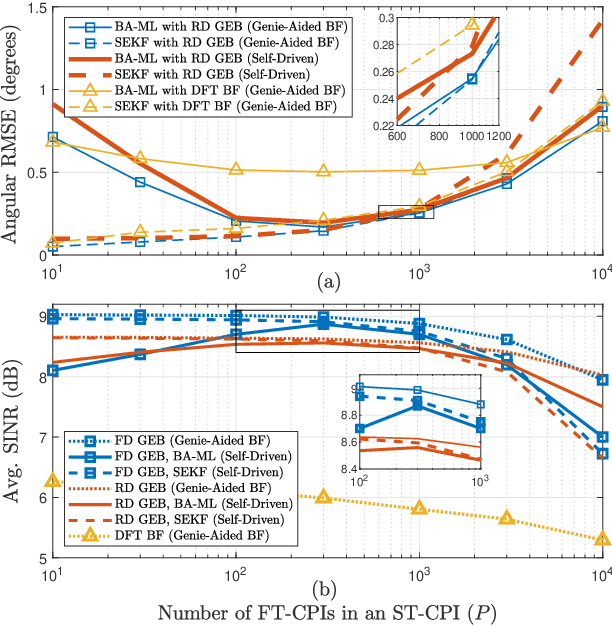
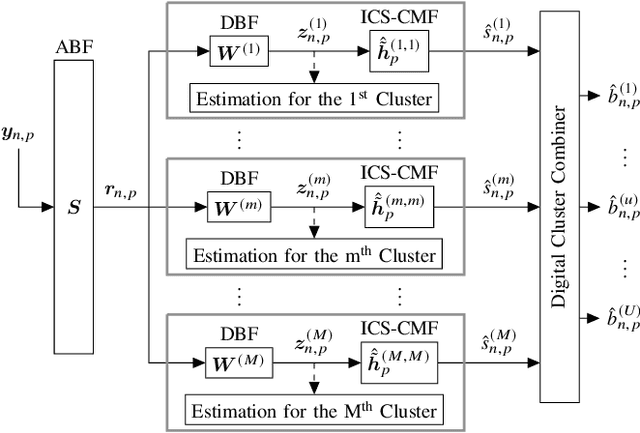
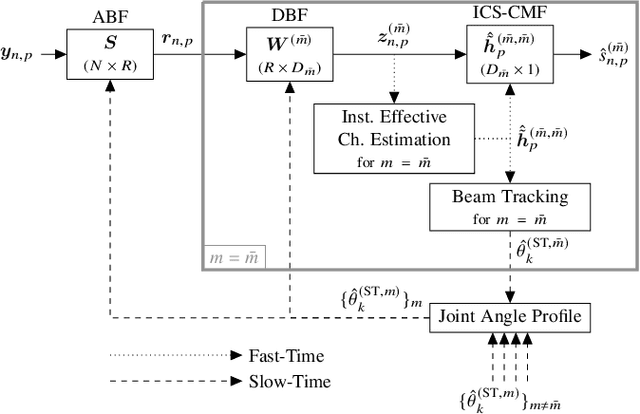
In this paper, a joint design of instantaneous channel estimation, beam tracking, and adaptive beamformer construction for a massive multiple-input multiple-output (MIMO) system is proposed. This design focuses on efficiency in terms of performance and computational complexity under the adverse effects of time variation and mobility of sources, the presence of multiuser and multipath components, or simply multi-clusters, and the near-far effect. The design is also suitable for hybrid beamforming and frequency-selective channels. In the proposed system, channel parameters are estimated in time-domain duplex (TDD) uplink mode using a per-cluster approach rather than a joint approach, which significantly reduces the complexity. Per-cluster estimation is possible thanks to the proposed interference-aware statistical beamforming method, namely reduced dimensional Generalized Eigenbeamformer (RD-GEB), which undertakes the computational load of interference mitigation and enables a simpler design for the remaining stages. In addition, the overall design is based on the separation of channel parameters as fast-time and slow-time, leaving only the instantaneous channel estimation and channel matched filtering as fast-time operations, which are handled inside cluster-specific reduced dimensional subspaces. Beam tracking and beamformer construction are held in slow-time rarely, which reduces the time-averaged complexity. Furthermore, beam tracking is performed by leveraging a batch of instantaneous channel estimates, which removes the need for an additional training process. The proposed low-complexity design is shown to outperform the conventional methods.
Online Learning for Obstacle Avoidance
Jun 14, 2023


We approach the fundamental problem of obstacle avoidance for robotic systems via the lens of online learning. In contrast to prior work that either assumes worst-case realizations of uncertainty in the environment or a stationary stochastic model of uncertainty, we propose a method that is efficient to implement and provably grants instance-optimality with respect to perturbations of trajectories generated from an open-loop planner (in the sense of minimizing worst-case regret). The resulting policy adapts online to realizations of uncertainty and provably compares well with the best obstacle avoidance policy in hindsight from a rich class of policies. The method is validated in simulation on a dynamical system environment and compared to baseline open-loop planning and robust Hamilton- Jacobi reachability techniques. Further, it is implemented on a hardware example where a quadruped robot traverses a dense obstacle field and encounters input disturbances due to time delays, model uncertainty, and dynamics nonlinearities.