 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparison of Deep Learning Architectures for Spacecraft Anomaly Detection
Mar 19, 2024
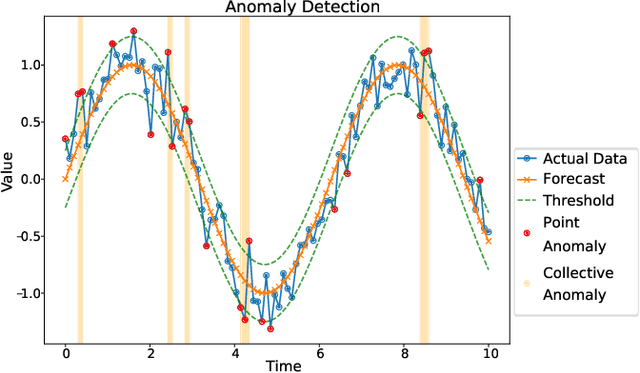
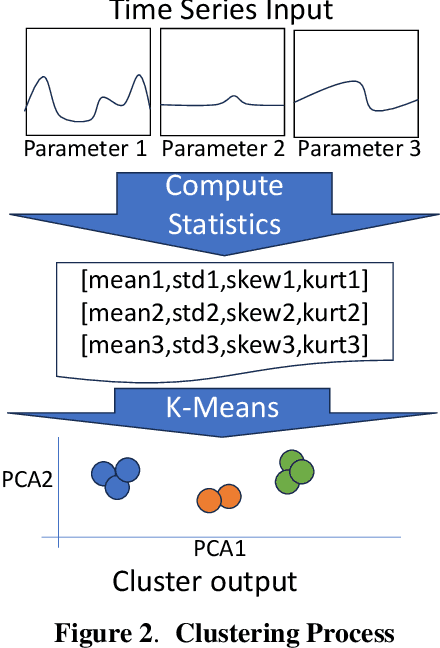
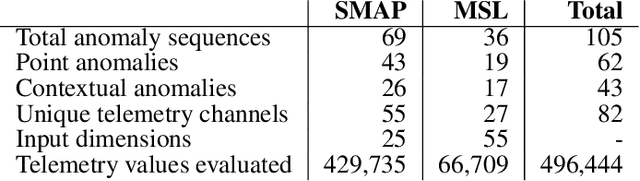
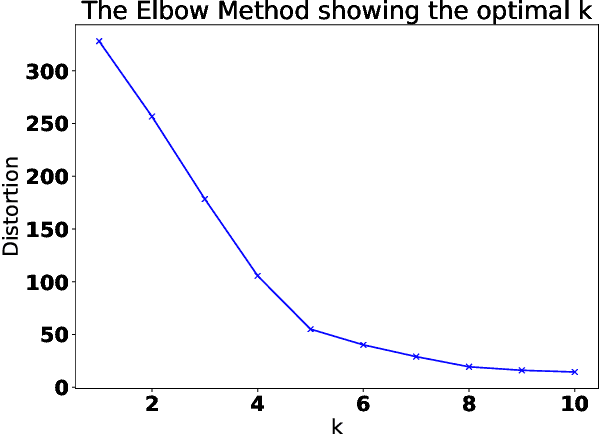
Spacecraft operations are highly critical, demanding impeccable reliability and safety. Ensuring the optimal performance of a spacecraft requires the early detection and mitigation of anomalies, which could otherwise result in unit or mission failures. With the advent of deep learning, a surge of interest has been seen in leveraging these sophisticated algorithms for anomaly detection in space operations. This study aims to compare the efficacy of various deep learning architectures in detecting anomalies in spacecraft data. The deep learning models under investigation include Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformer-based architectures. Each of these models was trained and validated using a comprehensive dataset sourced from multiple spacecraft missions, encompassing diverse operational scenarios and anomaly types. Initial results indicate that while CNNs excel in identifying spatial patterns and may be effective for some classes of spacecraft data, LSTMs and RNNs show a marked proficiency in capturing temporal anomalies seen in time-series spacecraft telemetry. The Transformer-based architectures, given their ability to focus on both local and global contexts, have showcased promising results, especially in scenarios where anomalies are subtle and span over longer durations. Additionally, considerations such as computational efficiency, ease of deployment, and real-time processing capabilities were evaluated. While CNNs and LSTMs demonstrated a balance between accuracy and computational demands, Transformer architectures, though highly accurate, require significant computational resources. In conclusion, the choice of deep learning architecture for spacecraft anomaly detection is highly contingent on the nature of the data, the type of anomalies, and operational constraints.
Near-Real-Time Mueller Polarimetric Image Processing for Neurosurgical Intervention
Mar 01, 2024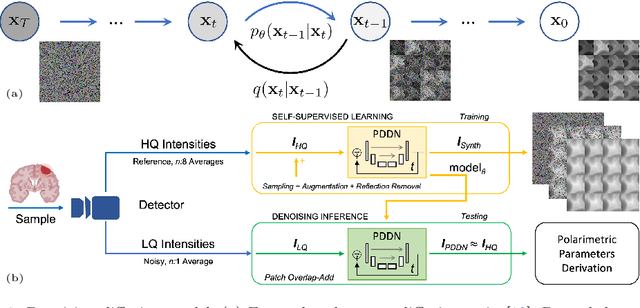

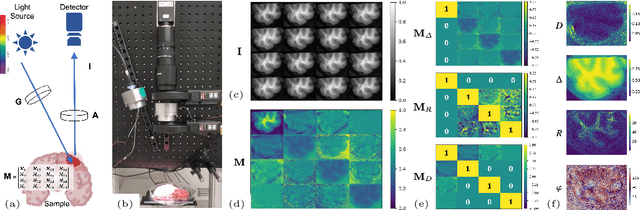
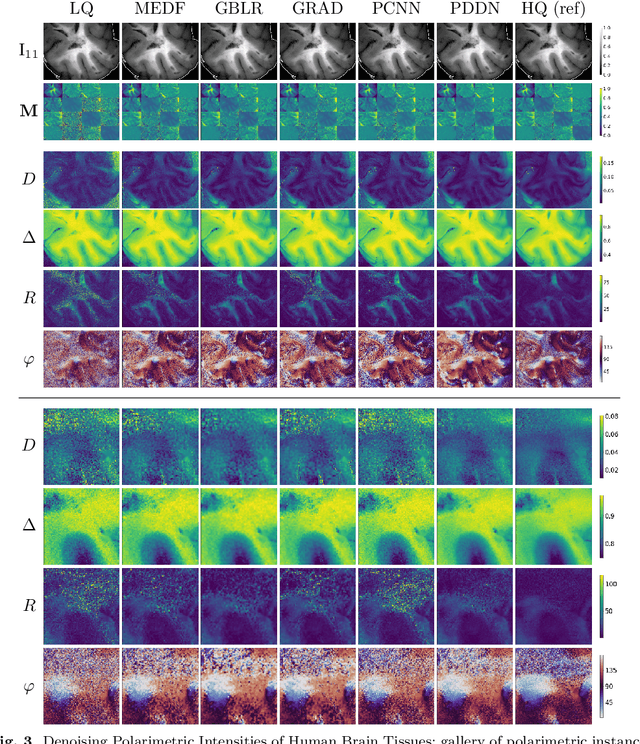
Wide-field imaging Mueller polarimetry is a revolutionary, label-free, and non-invasive modality for computer-aided intervention: in neurosurgery it aims to provide visual feedback of white matter fibre bundle orientation from derived parameters. Conventionally, robust polarimetric parameters are estimated after averaging multiple measurements of intensity for each pair of probing and detected polarised light. Long multi-shot averaging, however, is not compatible with real-time in-vivo imaging, and the current performance of polarimetric data processing hinders the translation to clinical practice. A learning-based denoising framework is tailored for fast, single-shot, noisy acquisitions of polarimetric intensities. Also, performance-optimised image processing tools are devised for the derivation of clinically relevant parameters. The combination recovers accurate polarimetric parameters from fast acquisitions with near-real-time performance, under the assumption of pseudo-Gaussian polarimetric acquisition noise. The denoising framework is trained, validated, and tested on experimental data comprising tumour-free and diseased human brain samples in different conditions. Accuracy and image quality indices showed significant improvements on testing data for a fast single-pass denoising versus the state-of-the-art and high polarimetric image quality standards. The computational time is reported for the end-to-end processing. The end-to-end image processing achieved real-time performance for a localised field of view. The denoised polarimetric intensities produced visibly clear directional patterns of neuronal fibre tracts in line with reference polarimetric image quality standards; directional disruption was kept in case of neoplastic lesions. The presented advances pave the way towards feasible oncological neurosurgical translations of novel, label free, interventional feedback.
Loss Regularizing Robotic Terrain Classification
Mar 20, 2024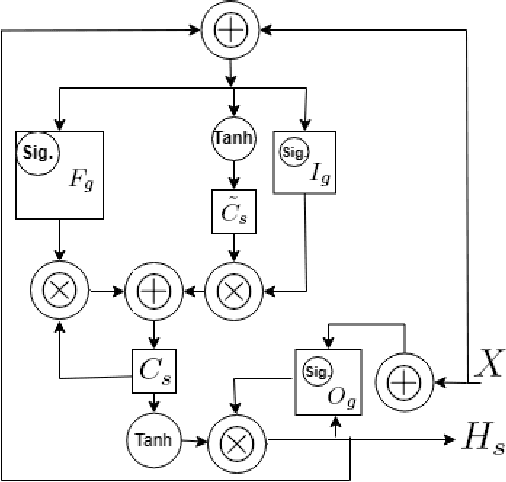
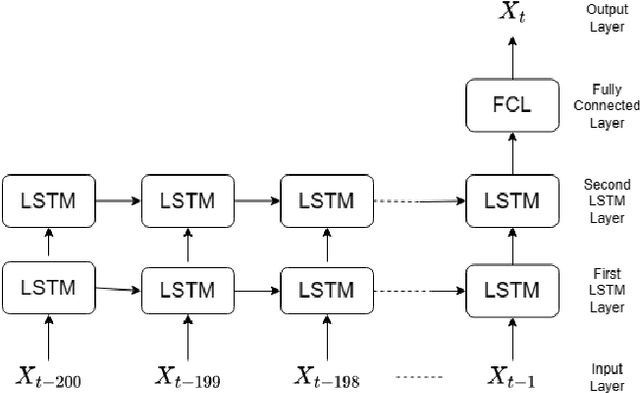
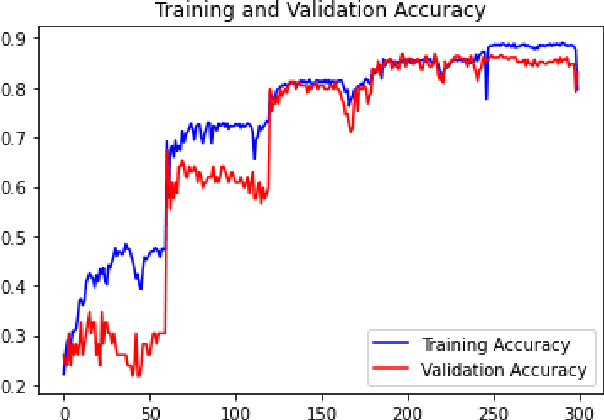
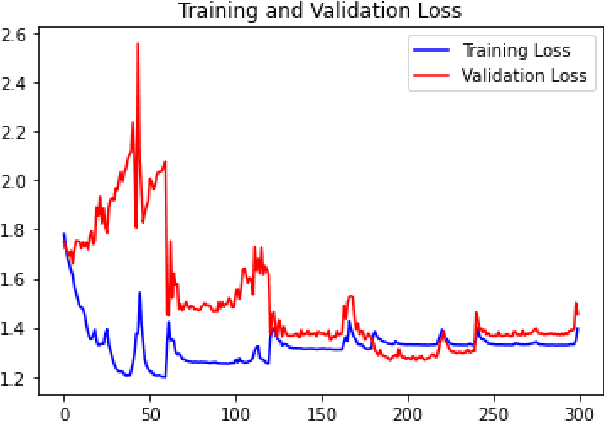
Locomotion mechanics of legged robots are suitable when pacing through difficult terrains. Recognising terrains for such robots are important to fully yoke the versatility of their movements. Consequently, robotic terrain classification becomes significant to classify terrains in real time with high accuracy. The conventional classifiers suffer from overfitting problem, low accuracy problem, high variance problem, and not suitable for live dataset. On the other hand, classifying a growing dataset is difficult for convolution based terrain classification. Supervised recurrent models are also not practical for this classification. Further, the existing recurrent architectures are still evolving to improve accuracy of terrain classification based on live variable-length sensory data collected from legged robots. This paper proposes a new semi-supervised method for terrain classification of legged robots, avoiding preprocessing of long variable-length dataset. The proposed method has a stacked Long Short-Term Memory architecture, including a new loss regularization. The proposed method solves the existing problems and improves accuracy. Comparison with the existing architectures show the improvements.
Cell Tracking in C. elegans with Cell Position Heatmap-Based Alignment and Pairwise Detection
Mar 20, 2024
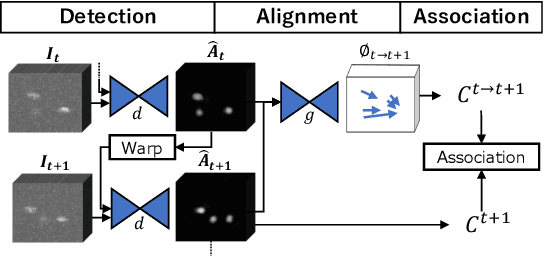
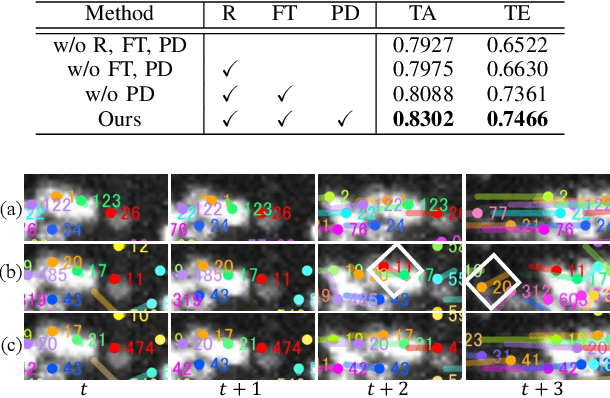

3D cell tracking in a living organism has a crucial role in live cell image analysis. Cell tracking in C. elegans has two difficulties. First, cell migration in a consecutive frame is large since they move their head during scanning. Second, cell detection is often inconsistent in consecutive frames due to touching cells and low-contrast images, and these inconsistent detections affect the tracking performance worse. In this paper, we propose a cell tracking method to address these issues, which has two main contributions. First, we introduce cell position heatmap-based non-rigid alignment with test-time fine-tuning, which can warp the detected points to near the positions at the next frame. Second, we propose a pairwise detection method, which uses the information of detection results at the previous frame for detecting cells at the current frame. The experimental results demonstrate the effectiveness of each module, and the proposed method achieved the best performance in comparison.
A Contact Model based on Denoising Diffusion to Learn Variable Impedance Control for Contact-rich Manipulation
Mar 20, 2024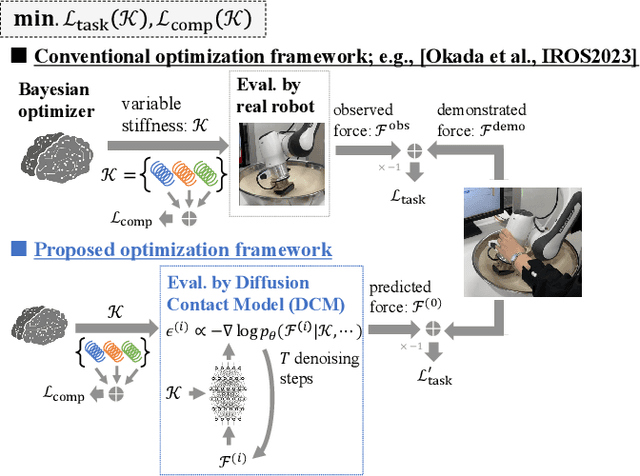
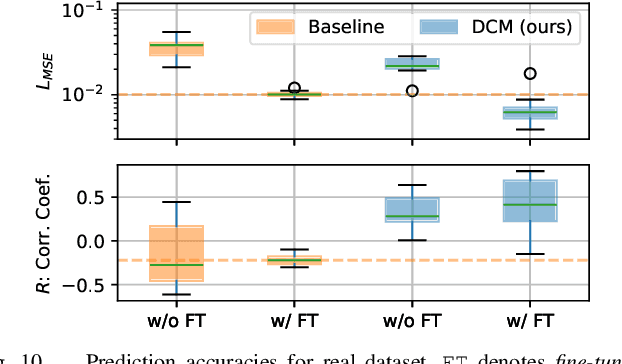
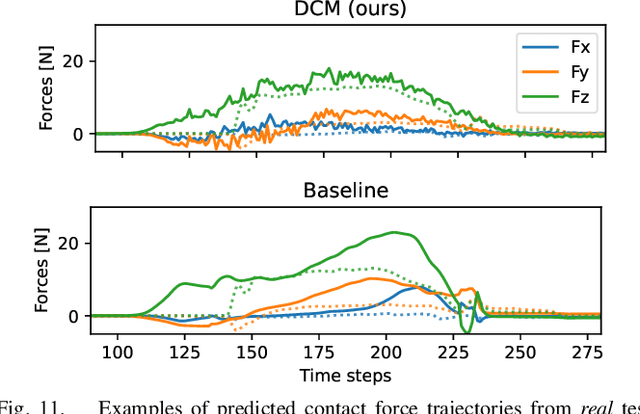
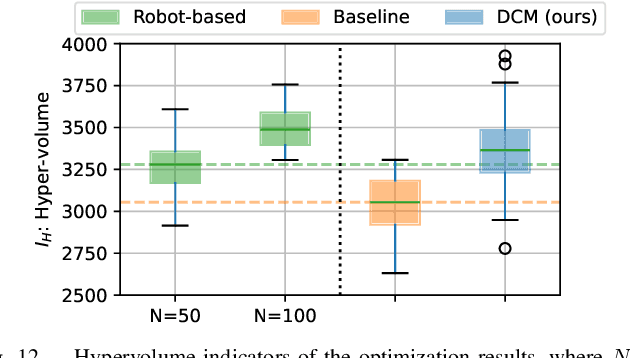
In this paper, a novel approach is proposed for learning robot control in contact-rich tasks such as wiping, by developing Diffusion Contact Model (DCM). Previous methods of learning such tasks relied on impedance control with time-varying stiffness tuning by performing Bayesian optimization by trial-and-error with robots. The proposed approach aims to reduce the cost of robot operation by predicting the robot contact trajectories from the variable stiffness inputs and using neural models. However, contact dynamics are inherently highly nonlinear, and their simulation requires iterative computations such as convex optimization. Moreover, approximating such computations by using finite-layer neural models is difficult. To overcome these limitations, the proposed DCM used the denoising diffusion models that could simulate the complex dynamics via iterative computations of multi-step denoising, thus improving the prediction accuracy. Stiffness tuning experiments conducted in simulated and real environments showed that the DCM achieved comparable performance to a conventional robot-based optimization method while reducing the number of robot trials.
Beyond Skeletons: Integrative Latent Mapping for Coherent 4D Sequence Generation
Mar 20, 2024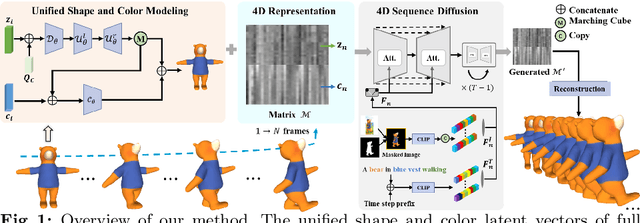
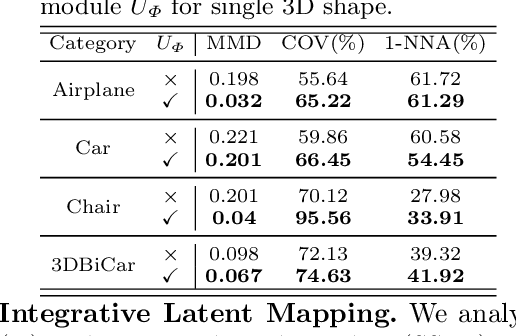
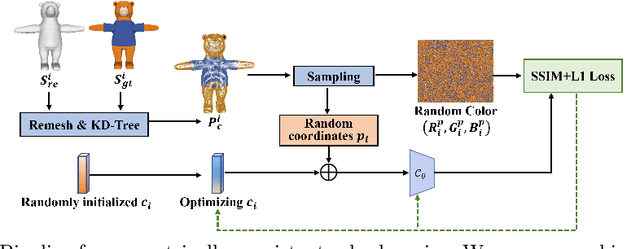
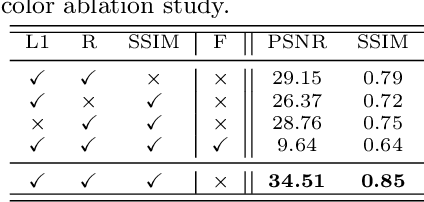
Directly learning to model 4D content, including shape, color and motion, is challenging. Existing methods depend on skeleton-based motion control and offer limited continuity in detail. To address this, we propose a novel framework that generates coherent 4D sequences with animation of 3D shapes under given conditions with dynamic evolution of shape and color over time through integrative latent mapping. We first employ an integrative latent unified representation to encode shape and color information of each detailed 3D geometry frame. The proposed skeleton-free latent 4D sequence joint representation allows us to leverage diffusion models in a low-dimensional space to control the generation of 4D sequences. Finally, temporally coherent 4D sequences are generated conforming well to the input images and text prompts. Extensive experiments on the ShapeNet, 3DBiCar and DeformingThings4D datasets for several tasks demonstrate that our method effectively learns to generate quality 3D shapes with color and 4D mesh animations, improving over the current state-of-the-art. Source code will be released.
Dynamic Resource Allocation for Virtual Machine Migration Optimization using Machine Learning
Mar 20, 2024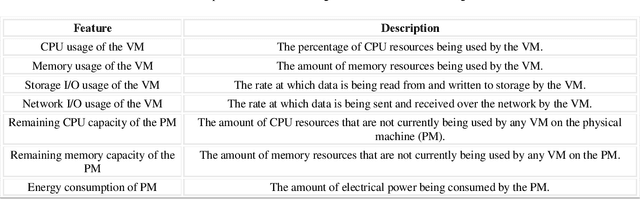
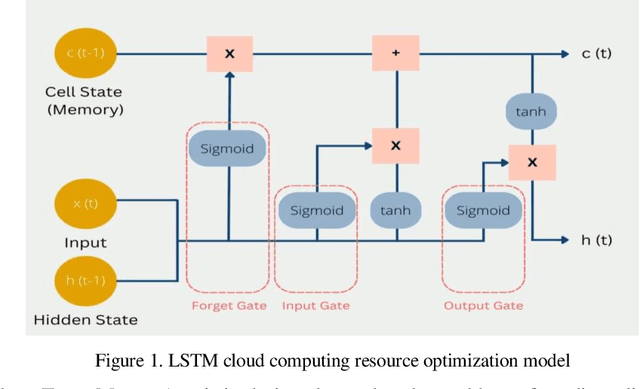
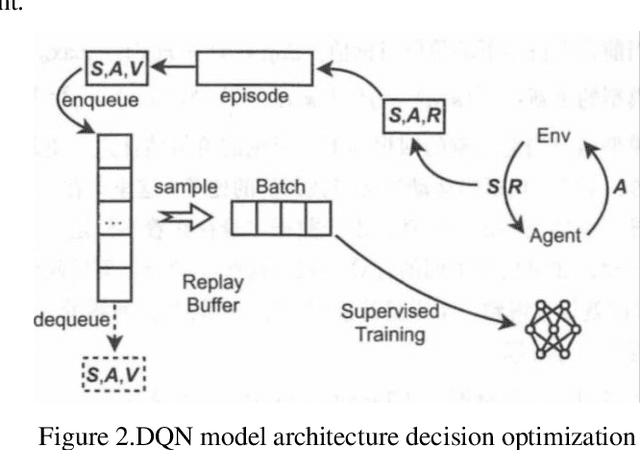
The paragraph is grammatically correct and logically coherent. It discusses the importance of mobile terminal cloud computing migration technology in meeting the demands of evolving computer and cloud computing technologies. It emphasizes the need for efficient data access and storage, as well as the utilization of cloud computing migration technology to prevent additional time delays. The paragraph also highlights the contributions of cloud computing migration technology to expanding cloud computing services. Additionally, it acknowledges the role of virtualization as a fundamental capability of cloud computing while emphasizing that cloud computing and virtualization are not inherently interconnected. Finally, it introduces machine learning-based virtual machine migration optimization and dynamic resource allocation as a critical research direction in cloud computing, citing the limitations of static rules or manual settings in traditional cloud computing environments. Overall, the paragraph effectively communicates the importance of machine learning technology in addressing resource allocation and virtual machine migration challenges in cloud computing.
Workload Estimation for Unknown Tasks: A Survey of Machine Learning Under Distribution Shift
Mar 20, 2024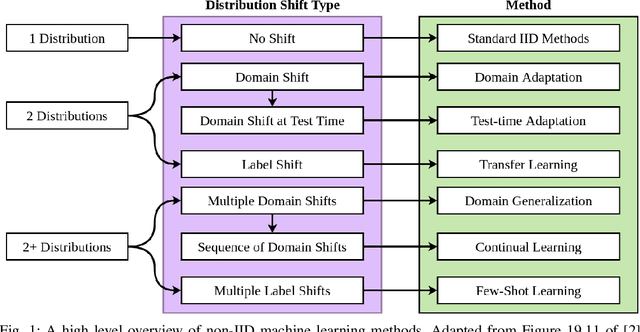
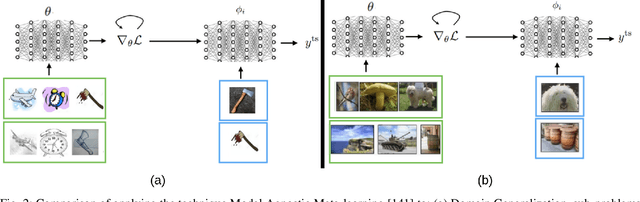
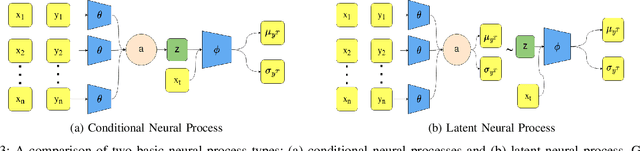
Human-robot teams involve humans and robots collaborating to achieve tasks under various environmental conditions. Successful teaming will require robots to adapt autonomously to a human teammate's internal state. An important element of such adaptation is the ability to estimate the human teammates' workload in unknown situations. Existing workload models use machine learning to model the relationships between physiological metrics and workload; however, these methods are susceptible to individual differences and are heavily influenced by other factors. These methods cannot generalize to unknown tasks, as they rely on standard machine learning approaches that assume data consists of independent and identically distributed (IID) samples. This assumption does not necessarily hold for estimating workload for new tasks. A survey of non-IID machine learning techniques is presented, where commonly used techniques are evaluated using three criteria: portability, model complexity, and adaptability. These criteria are used to argue which techniques are most applicable for estimating workload for unknown tasks in dynamic, real-time environments.
A Rule-Compliance Path Planner for Lane-Merge Scenarios Based on Responsibility-Sensitive Safety
Mar 20, 2024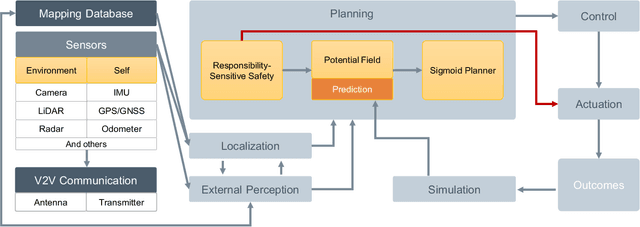
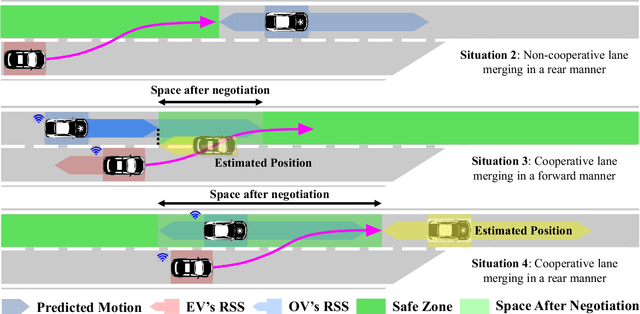
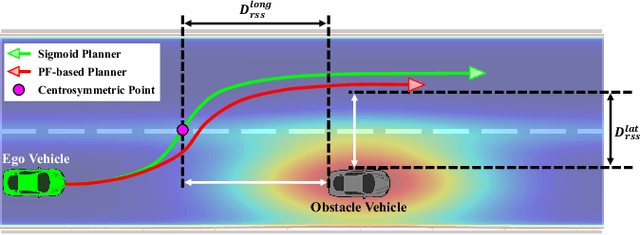
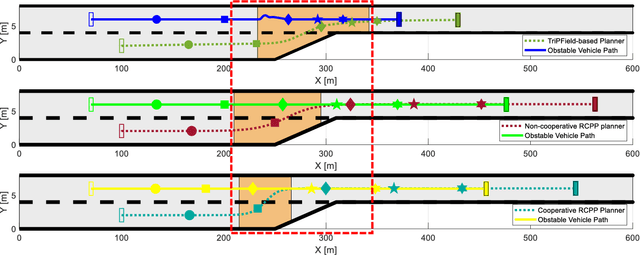
Lane merging is one of the critical tasks for self-driving cars, and how to perform lane-merge maneuvers effectively and safely has become one of the important standards in measuring the capability of autonomous driving systems. However, due to the ambiguity in driving intentions and right-of-way issues, the lane merging process in autonomous driving remains deficient in terms of maintaining or ceding the right-of-way and attributing liability, which could result in protracted durations for merging and problems such as trajectory oscillation. Hence, we present a rule-compliance path planner (RCPP) for lane-merge scenarios, which initially employs the extended responsibility-sensitive safety (RSS) to elucidate the right-of-way, followed by the potential field-based sigmoid planner for path generation. In the simulation, we have validated the efficacy of the proposed algorithm. The algorithm demonstrated superior performance over previous approaches in aspects such as merging time (Saved 72.3%), path length (reduced 53.4%), and eliminating the trajectory oscillation.
It's All About Your Sketch: Democratising Sketch Control in Diffusion Models
Mar 20, 2024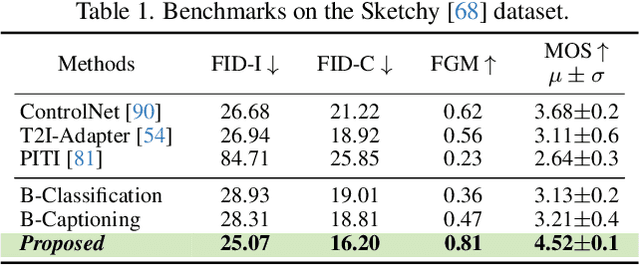

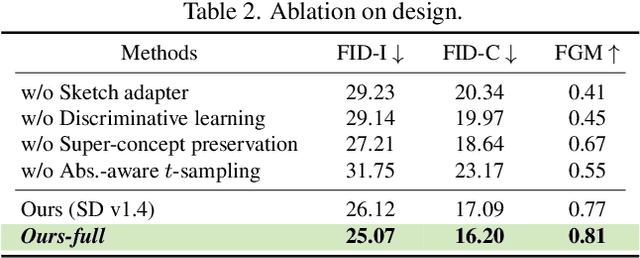

This paper unravels the potential of sketches for diffusion models, addressing the deceptive promise of direct sketch control in generative AI. We importantly democratise the process, enabling amateur sketches to generate precise images, living up to the commitment of "what you sketch is what you get". A pilot study underscores the necessity, revealing that deformities in existing models stem from spatial-conditioning. To rectify this, we propose an abstraction-aware framework, utilising a sketch adapter, adaptive time-step sampling, and discriminative guidance from a pre-trained fine-grained sketch-based image retrieval model, working synergistically to reinforce fine-grained sketch-photo association. Our approach operates seamlessly during inference without the need for textual prompts; a simple, rough sketch akin to what you and I can create suffices! We welcome everyone to examine results presented in the paper and its supplementary. Contributions include democratising sketch control, introducing an abstraction-aware framework, and leveraging discriminative guidance, validated through extensive experiments.