 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating Multiframe Blind Deconvolution via Deep Learning
Jun 21, 2023
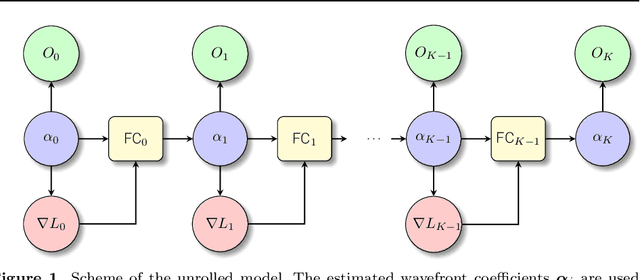
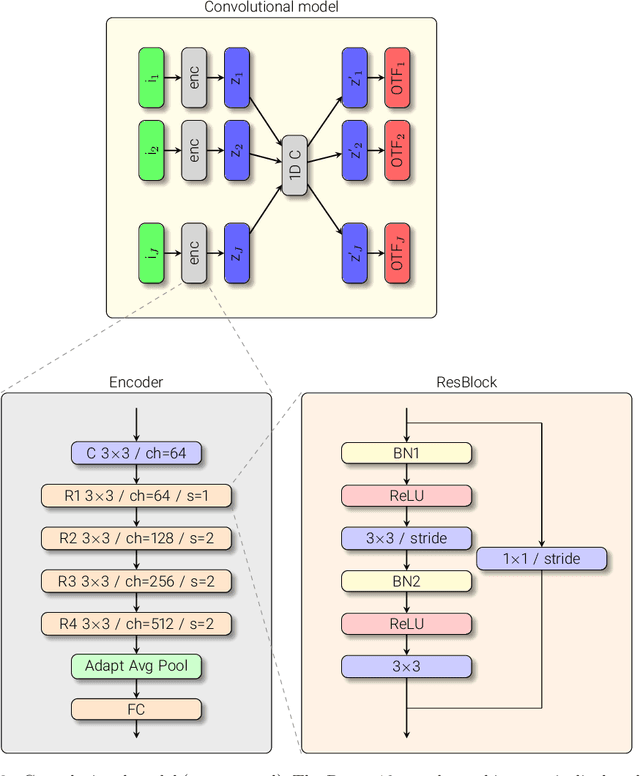

Ground-based solar image restoration is a computationally expensive procedure that involves nonlinear optimization techniques. The presence of atmospheric turbulence produces perturbations in individual images that make it necessary to apply blind deconvolution techniques. These techniques rely on the observation of many short exposure frames that are used to simultaneously infer the instantaneous state of the atmosphere and the unperturbed object. We have recently explored the use of machine learning to accelerate this process, with promising results. We build upon this previous work to propose several interesting improvements that lead to better models. As well, we propose a new method to accelerate the restoration based on algorithm unrolling. In this method, the image restoration problem is solved with a gradient descent method that is unrolled and accelerated aided by a few small neural networks. The role of the neural networks is to correct the estimation of the solution at each iterative step. The model is trained to perform the optimization in a small fixed number of steps with a curated dataset. Our findings demonstrate that both methods significantly reduce the restoration time compared to the standard optimization procedure. Furthermore, we showcase that these models can be trained in an unsupervised manner using observed images from three different instruments. Remarkably, they also exhibit robust generalization capabilities when applied to new datasets. To foster further research and collaboration, we openly provide the trained models, along with the corresponding training and evaluation code, as well as the training dataset, to the scientific community.
When to Use Efficient Self Attention? Profiling Text, Speech and Image Transformer Variants
Jun 14, 2023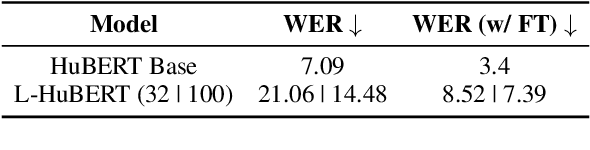
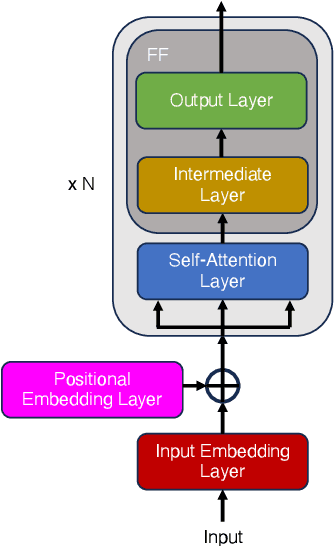
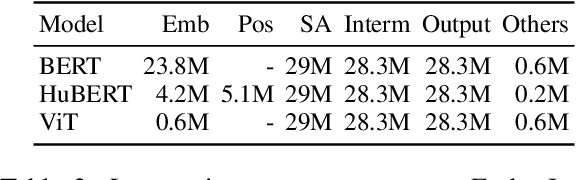
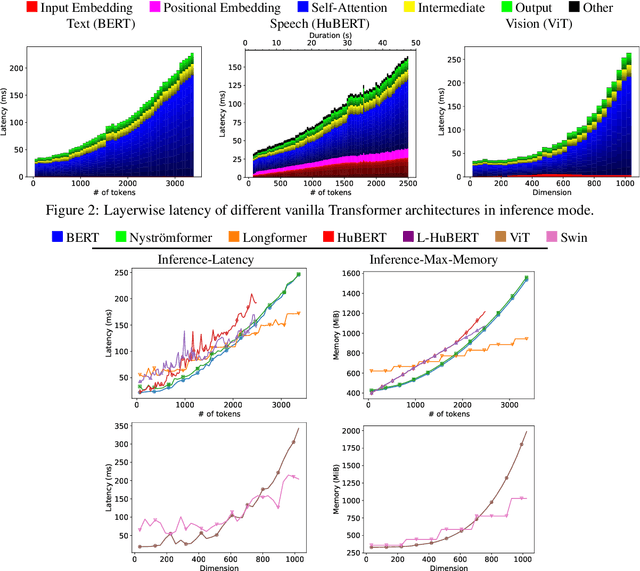
We present the first unified study of the efficiency of self-attention-based Transformer variants spanning text, speech and vision. We identify input length thresholds (tipping points) at which efficient Transformer variants become more efficient than vanilla models, using a variety of efficiency metrics (latency, throughput, and memory). To conduct this analysis for speech, we introduce L-HuBERT, a novel local-attention variant of a self-supervised speech model. We observe that these thresholds are (a) much higher than typical dataset sequence lengths and (b) dependent on the metric and modality, showing that choosing the right model depends on modality, task type (long-form vs. typical context) and resource constraints (time vs. memory). By visualising the breakdown of the computational costs for transformer components, we also show that non-self-attention components exhibit significant computational costs. We release our profiling toolkit at https://github.com/ajd12342/profiling-transformers .
PoetryDiffusion: Towards Joint Semantic and Metrical Manipulation in Poetry Generation
Jun 14, 2023
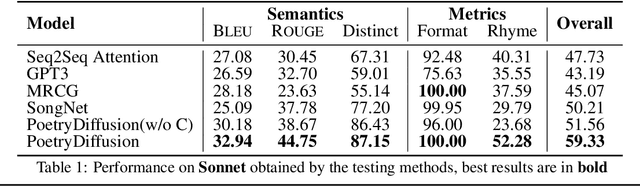
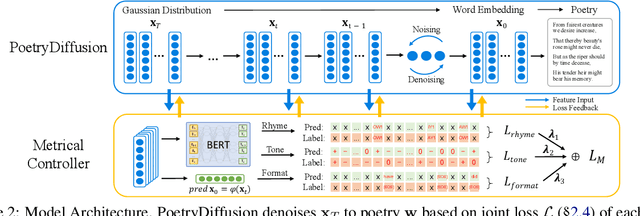
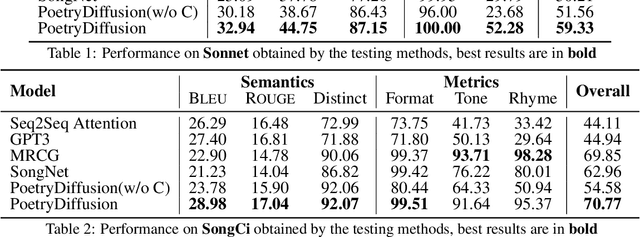
Poetry generation is a typical and popular task in natural language generation. While prior works have shown success in controlling either semantic or metrical aspects of poetry generation, there are still challenges in addressing both perspectives simultaneously. In this paper, we employ the Diffusion model to generate poetry in Sonnet and SongCi in Chinese for the first time to tackle such challenges. Different from autoregressive generation, our PoetryDiffusion model, based on Diffusion model, generates the complete sentence or poetry by taking into account the whole sentence information, resulting in improved semantic expression. Additionally, we incorporate a novel metrical controller to manipulate and evaluate metrics (format and rhythm). The denoising process in PoetryDiffusion allows for gradual enhancement of semantics and flexible integration of the metrical controller. Experimental results on two datasets demonstrate that our model outperforms existing models in terms of semantic, metrical and overall performance.
Information Theory Inspired Pattern Analysis for Time-series Data
Feb 22, 2023
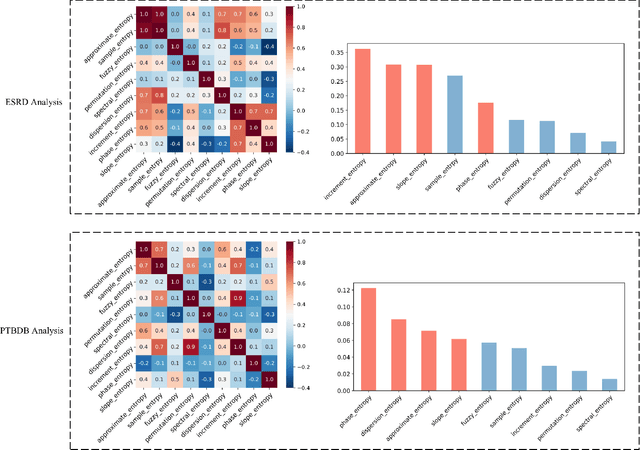

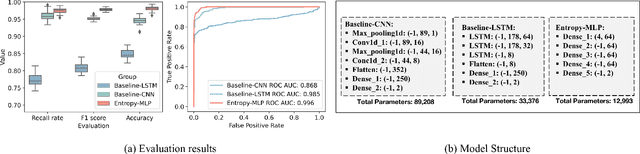
Current methods for pattern analysis in time series mainly rely on statistical features or probabilistic learning and inference methods to identify patterns and trends in the data. Such methods do not generalize well when applied to multivariate, multi-source, state-varying, and noisy time-series data. To address these issues, we propose a highly generalizable method that uses information theory-based features to identify and learn from patterns in multivariate time-series data. To demonstrate the proposed approach, we analyze pattern changes in human activity data. For applications with stochastic state transitions, features are developed based on Shannon's entropy of Markov chains, entropy rates of Markov chains, entropy production of Markov chains, and von Neumann entropy of Markov chains. For applications where state modeling is not applicable, we utilize five entropy variants, including approximate entropy, increment entropy, dispersion entropy, phase entropy, and slope entropy. The results show the proposed information theory-based features improve the recall rate, F1 score, and accuracy on average by up to 23.01\% compared with the baseline models and a simpler model structure, with an average reduction of 18.75 times in the number of model parameters.
Regular Time-series Generation using SGM
Jan 20, 2023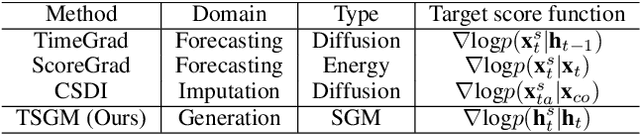
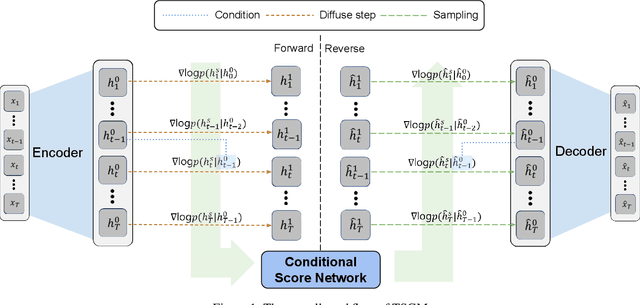
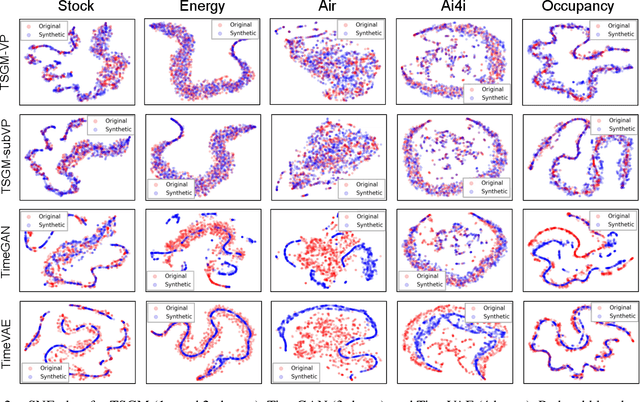
Score-based generative models (SGMs) are generative models that are in the spotlight these days. Time-series frequently occurs in our daily life, e.g., stock data, climate data, and so on. Especially, time-series forecasting and classification are popular research topics in the field of machine learning. SGMs are also known for outperforming other generative models. As a result, we apply SGMs to synthesize time-series data by learning conditional score functions. We propose a conditional score network for the time-series generation domain. Furthermore, we also derive the loss function between the score matching and the denoising score matching in the time-series generation domain. Finally, we achieve state-of-the-art results on real-world datasets in terms of sampling diversity and quality.
ASTRIDE: Adaptive Symbolization for Time Series Databases
Feb 08, 2023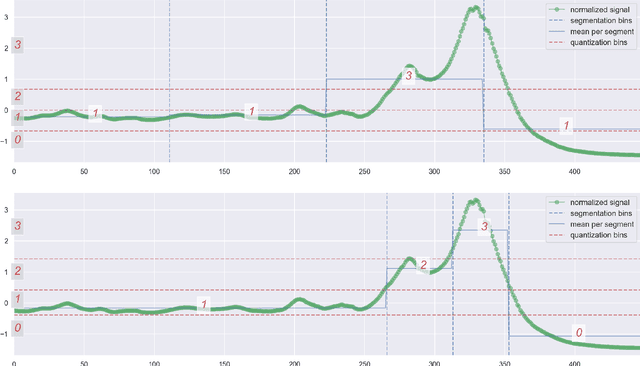
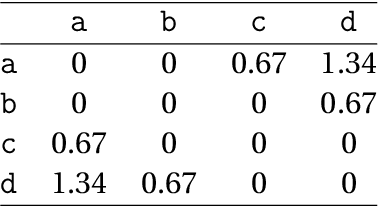
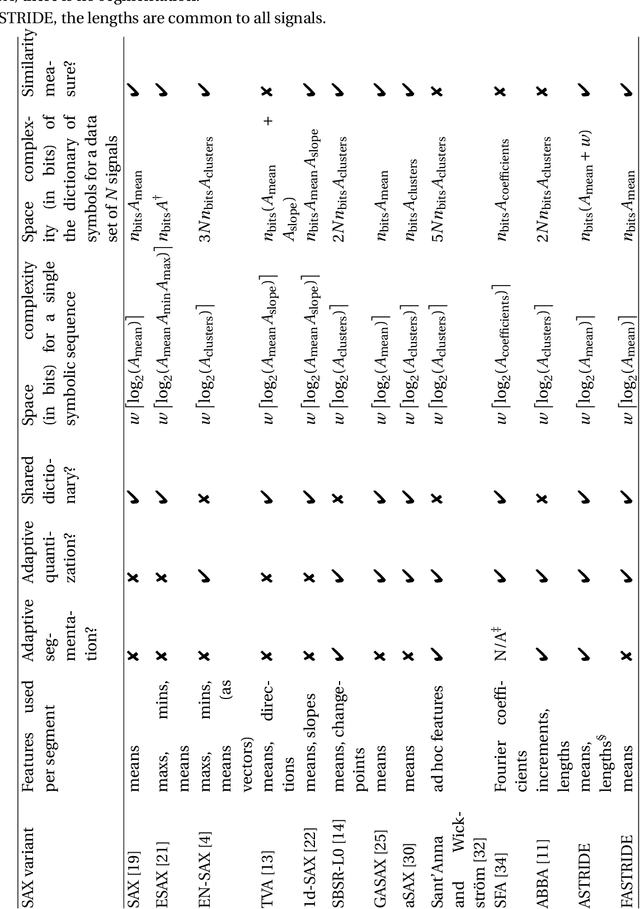
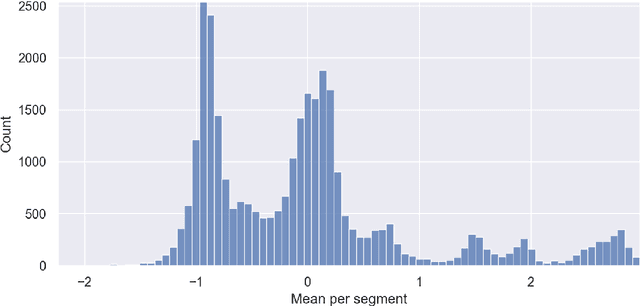
We introduce ASTRIDE (Adaptive Symbolization for Time seRIes DatabasEs), a novel symbolic representation of time series, along with its accelerated variant FASTRIDE (Fast ASTRIDE). Unlike most symbolization procedures, ASTRIDE is adaptive during both the segmentation step by performing change-point detection and the quantization step by using quantiles. Instead of proceeding signal by signal, ASTRIDE builds a dictionary of symbols that is common to all signals in a data set. We also introduce D-GED (Dynamic General Edit Distance), a novel similarity measure on symbolic representations based on the general edit distance. We demonstrate the performance of the ASTRIDE and FASTRIDE representations compared to SAX (Symbolic Aggregate approXimation), 1d-SAX, SFA (Symbolic Fourier Approximation), and ABBA (Adaptive Brownian Bridge-based Aggregation) on reconstruction and, when applicable, on classification tasks. These algorithms are evaluated on 86 univariate equal-size data sets from the UCR Time Series Classification Archive. An open source GitHub repository called astride is made available to reproduce all the experiments in Python.
Online Learning with Feedback Graphs: The True Shape of Regret
Jun 05, 2023
Sequential learning with feedback graphs is a natural extension of the multi-armed bandit problem where the problem is equipped with an underlying graph structure that provides additional information - playing an action reveals the losses of all the neighbors of the action. This problem was introduced by \citet{mannor2011} and received considerable attention in recent years. It is generally stated in the literature that the minimax regret rate for this problem is of order $\sqrt{\alpha T}$, where $\alpha$ is the independence number of the graph, and $T$ is the time horizon. However, this is proven only when the number of rounds $T$ is larger than $\alpha^3$, which poses a significant restriction for the usability of this result in large graphs. In this paper, we define a new quantity $R^*$, called the \emph{problem complexity}, and prove that the minimax regret is proportional to $R^*$ for any graph and time horizon $T$. Introducing an intricate exploration strategy, we define the \mainAlgorithm algorithm that achieves the minimax optimal regret bound and becomes the first provably optimal algorithm for this setting, even if $T$ is smaller than $\alpha^3$.
Representation-agnostic distance-driven perturbation for optimizing ill-conditioned problems
Jun 05, 2023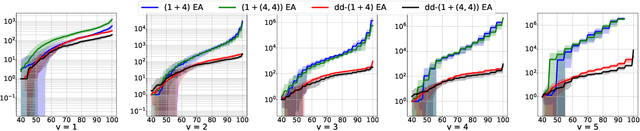
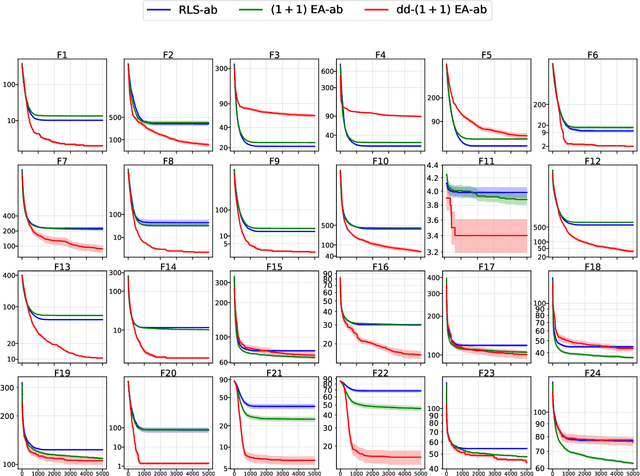
Locality is a crucial property for efficiently optimising black-box problems with randomized search heuristics. However, in practical applications, it is not likely to always find such a genotype encoding of candidate solutions that this property is upheld with respect to the Hamming distance. At the same time, it may be possible to use domain-specific knowledge to define a metric with locality property. We propose two mutation operators to solve such optimization problems more efficiently using the metric. The first operator assumes prior knowledge about the distance, the second operator uses the distance as a black box. Those operators apply an estimation of distribution algorithm to find the best mutant according to the defined in the paper function, which employs the given distance. For pseudo-boolean and integer optimization problems, we experimentally show that both mutation operators speed up the search on most of the functions when applied in considered evolutionary algorithms and random local search. Moreover, those operators can be applied in any randomized search heuristic which uses perturbations. However, our mutation operators increase wall-clock time and so are helpful in practice when distance is (much) cheaper to compute than the real objective function.
Case Studies on X-Ray Imaging, MRI and Nuclear Imaging
Jun 17, 2023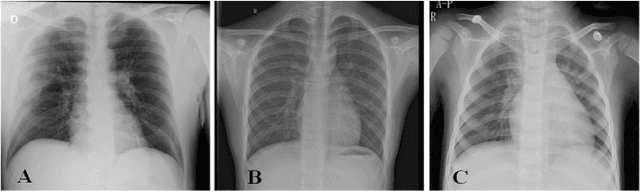
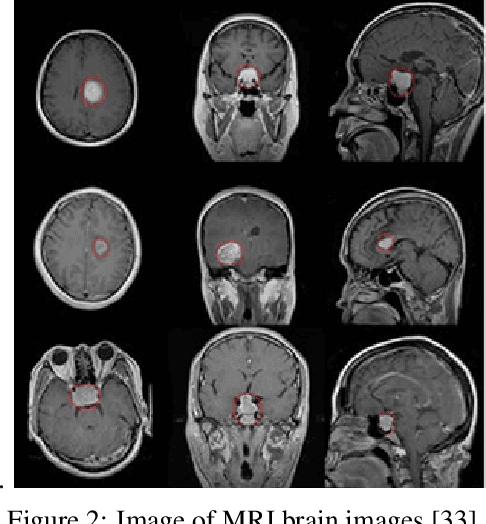
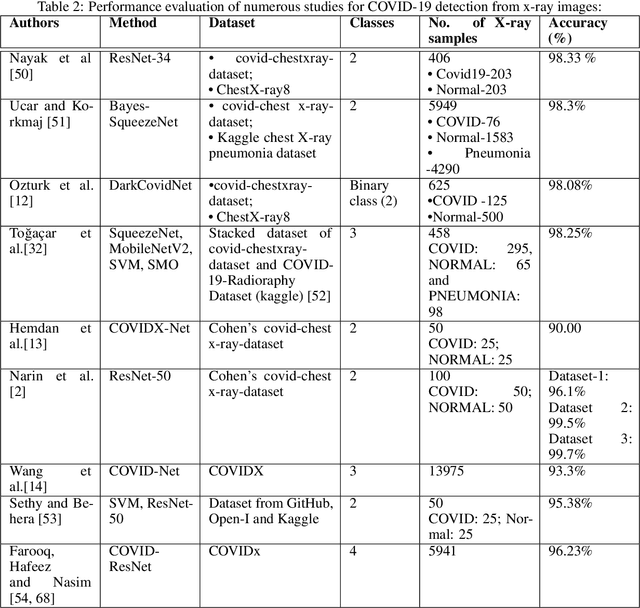
The field of medical imaging is an essential aspect of the medical sciences, involving various forms of radiation to capture images of the internal tissues and organs of the body. These images provide vital information for clinical diagnosis, and in this chapter, we will explore the use of X-ray, MRI, and nuclear imaging in detecting severe illnesses. However, manual evaluation and storage of these images can be a challenging and time-consuming process. To address this issue, artificial intelligence (AI)-based techniques, particularly deep learning (DL), have become increasingly popular for systematic feature extraction and classification from imaging modalities, thereby aiding doctors in making rapid and accurate diagnoses. In this review study, we will focus on how AI-based approaches, particularly the use of Convolutional Neural Networks (CNN), can assist in disease detection through medical imaging technology. CNN is a commonly used approach for image analysis due to its ability to extract features from raw input images, and as such, will be the primary area of discussion in this study. Therefore, we have considered CNN as our discussion area in this study to diagnose ailments using medical imaging technology.
KEST: Kernel Distance Based Efficient Self-Training for Improving Controllable Text Generation
Jun 17, 2023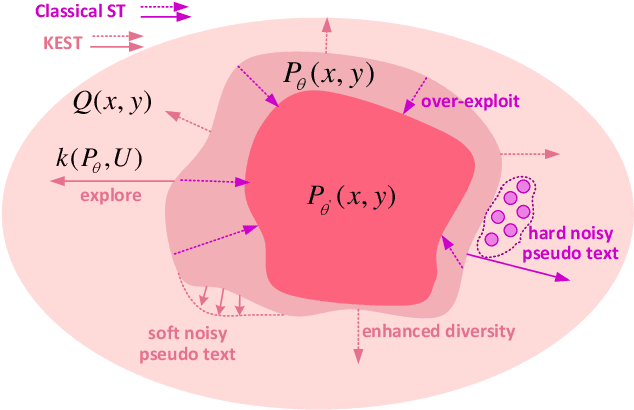
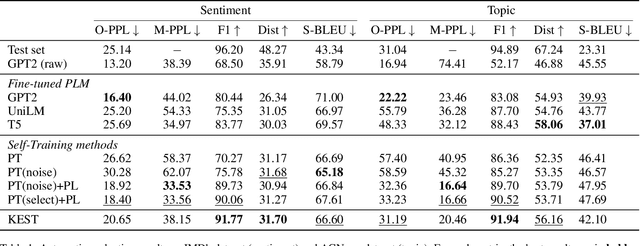
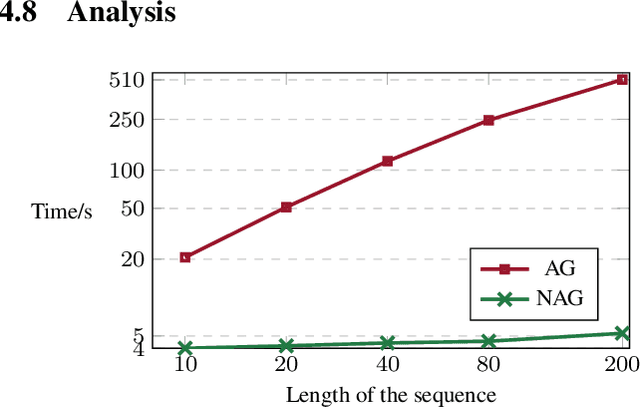
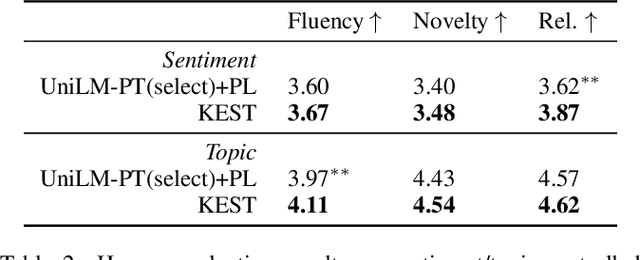
Self-training (ST) has come to fruition in language understanding tasks by producing pseudo labels, which reduces the labeling bottleneck of language model fine-tuning. Nevertheless, in facilitating semi-supervised controllable language generation, ST faces two key challenges. First, augmented by self-generated pseudo text, generation models tend to over-exploit the previously learned text distribution, suffering from mode collapse and poor generation diversity. Second, generating pseudo text in each iteration is time-consuming, severely decelerating the training process. In this work, we propose KEST, a novel and efficient self-training framework to handle these problems. KEST utilizes a kernel-based loss, rather than standard cross entropy, to learn from the soft pseudo text produced by a shared non-autoregressive generator. We demonstrate both theoretically and empirically that KEST can benefit from more diverse pseudo text in an efficient manner, which allows not only refining and exploiting the previously fitted distribution but also enhanced exploration towards a larger potential text space, providing a guarantee of improved performance. Experiments on three controllable generation tasks demonstrate that KEST significantly improves control accuracy while maintaining comparable text fluency and generation diversity against several strong baselines.