 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems
Jun 13, 2023
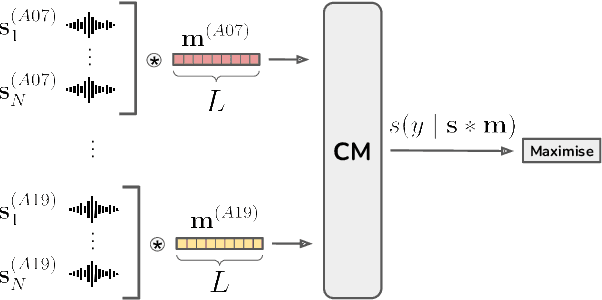
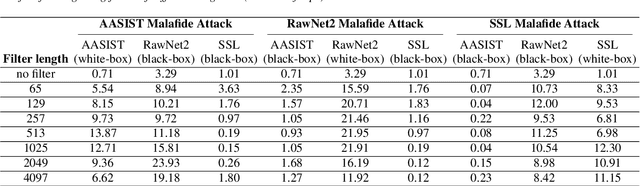
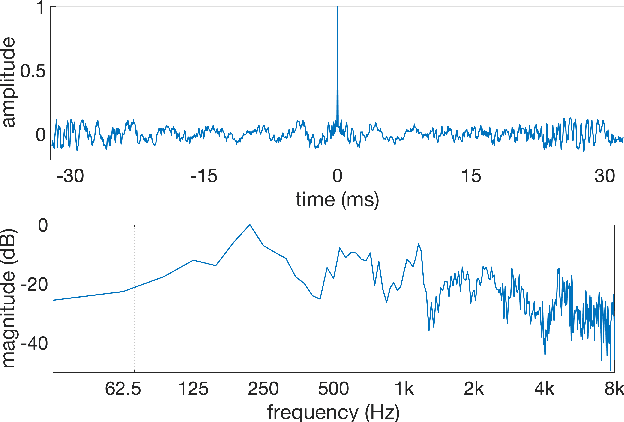
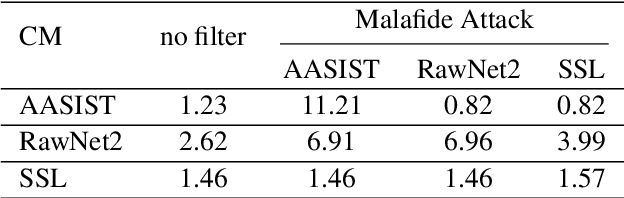
We present Malafide, a universal adversarial attack against automatic speaker verification (ASV) spoofing countermeasures (CMs). By introducing convolutional noise using an optimised linear time-invariant filter, Malafide attacks can be used to compromise CM reliability while preserving other speech attributes such as quality and the speaker's voice. In contrast to other adversarial attacks proposed recently, Malafide filters are optimised independently of the input utterance and duration, are tuned instead to the underlying spoofing attack, and require the optimisation of only a small number of filter coefficients. Even so, they degrade CM performance estimates by an order of magnitude, even in black-box settings, and can also be configured to overcome integrated CM and ASV subsystems. Integrated solutions that use self-supervised learning CMs, however, are more robust, under both black-box and white-box settings.
SurvivalGAN: Generating Time-to-Event Data for Survival Analysis
Feb 24, 2023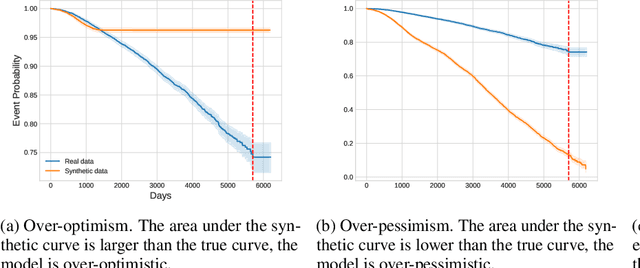
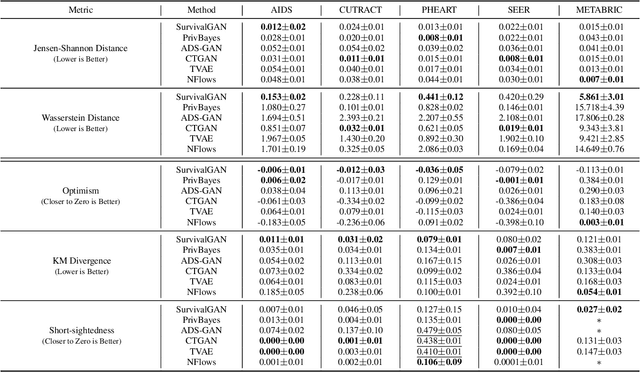
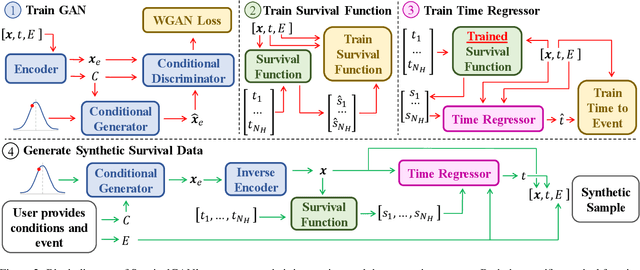
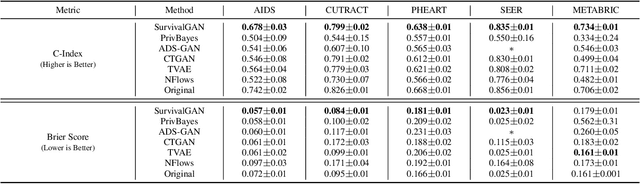
Synthetic data is becoming an increasingly promising technology, and successful applications can improve privacy, fairness, and data democratization. While there are many methods for generating synthetic tabular data, the task remains non-trivial and unexplored for specific scenarios. One such scenario is survival data. Here, the key difficulty is censoring: for some instances, we are not aware of the time of event, or if one even occurred. Imbalances in censoring and time horizons cause generative models to experience three new failure modes specific to survival analysis: (1) generating too few at-risk members; (2) generating too many at-risk members; and (3) censoring too early. We formalize these failure modes and provide three new generative metrics to quantify them. Following this, we propose SurvivalGAN, a generative model that handles survival data firstly by addressing the imbalance in the censoring and event horizons, and secondly by using a dedicated mechanism for approximating time-to-event/censoring. We evaluate this method via extensive experiments on medical datasets. SurvivalGAN outperforms multiple baselines at generating survival data, and in particular addresses the failure modes as measured by the new metrics, in addition to improving downstream performance of survival models trained on the synthetic data.
Learning time-scales in two-layers neural networks
Mar 16, 2023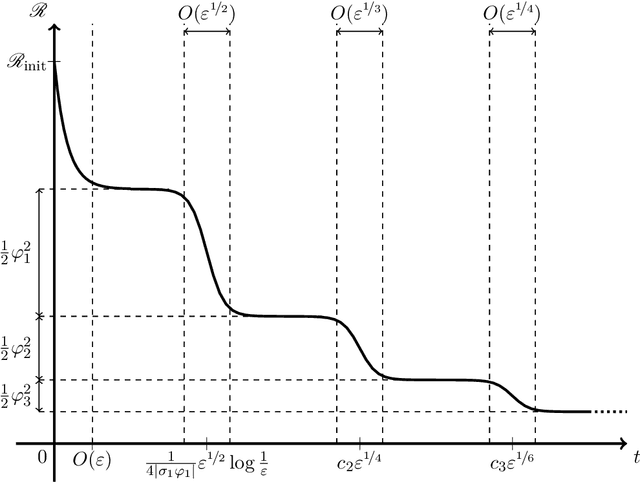
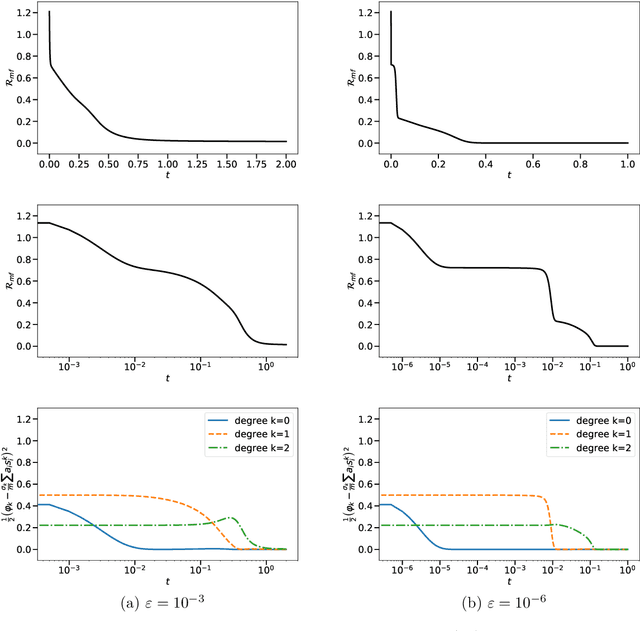

Gradient-based learning in multi-layer neural networks displays a number of striking features. In particular, the decrease rate of empirical risk is non-monotone even after averaging over large batches. Long plateaus in which one observes barely any progress alternate with intervals of rapid decrease. These successive phases of learning often take place on very different time scales. Finally, models learnt in an early phase are typically `simpler' or `easier to learn' although in a way that is difficult to formalize. Although theoretical explanations of these phenomena have been put forward, each of them captures at best certain specific regimes. In this paper, we study the gradient flow dynamics of a wide two-layer neural network in high-dimension, when data are distributed according to a single-index model (i.e., the target function depends on a one-dimensional projection of the covariates). Based on a mixture of new rigorous results, non-rigorous mathematical derivations, and numerical simulations, we propose a scenario for the learning dynamics in this setting. In particular, the proposed evolution exhibits separation of timescales and intermittency. These behaviors arise naturally because the population gradient flow can be recast as a singularly perturbed dynamical system.
MOV-Modified-FxLMS algorithm with Variable Penalty Factor in a Practical Power Output Constrained Active Control System
Jun 15, 2023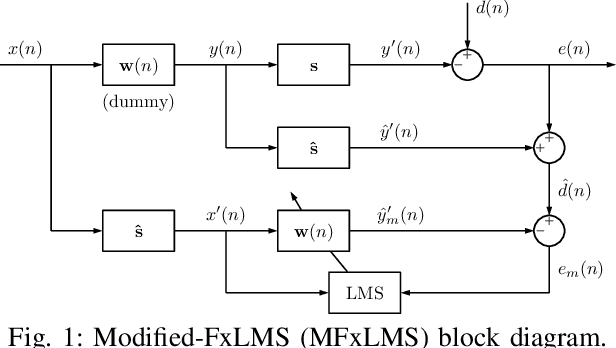
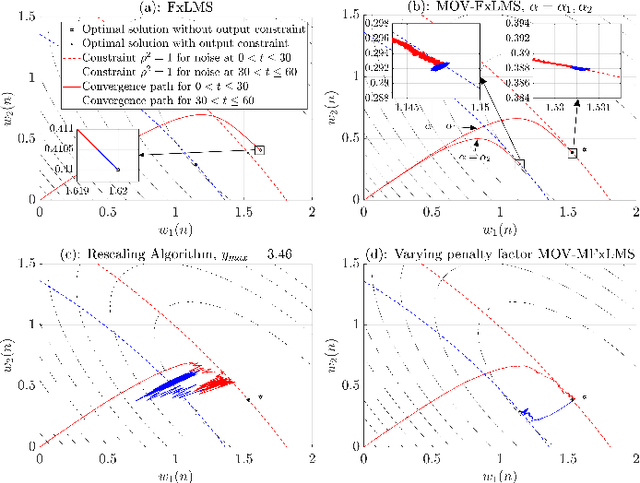
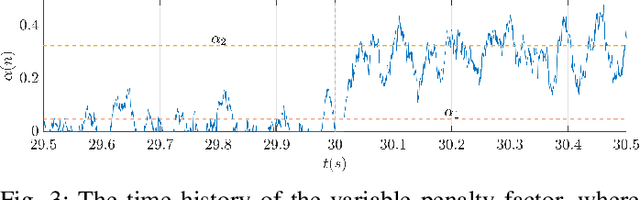
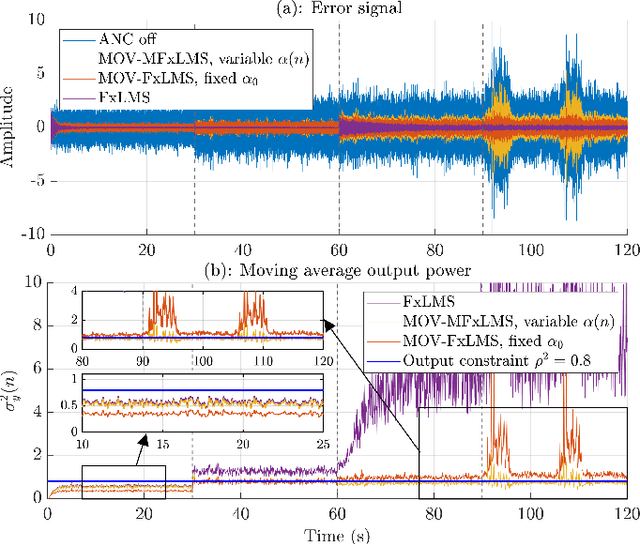
Practical Active Noise Control (ANC) systems typically require a restriction in their maximum output power, to prevent overdriving the loudspeaker and causing system instability. Recently, the minimum output variance filtered-reference least mean square (MOV-FxLMS) algorithm was shown to have optimal control under output constraint with an analytically formulated penalty factor, but it needs offline knowledge of disturbance power and secondary path gain. The constant penalty factor in MOV-FxLMS is also susceptible to variations in disturbance power that could cause output power constraint violations. This paper presents a new variable penalty factor that utilizes the estimated disturbance in the established Modified-FxLMS (MFxLMS) algorithm, resulting in a computationally efficient MOV-MFxLMS algorithm that can adapt to changes in disturbance levels in real-time. Numerical simulation with real noise and plant response showed that the variable penalty factor always manages to meet its maximum power output constraint despite sudden changes in disturbance power, whereas the fixed penalty factor has suffered from a constraint mismatch.
Feed Two Birds with One Scone: Exploiting Wild Data for Both Out-of-Distribution Generalization and Detection
Jun 15, 2023

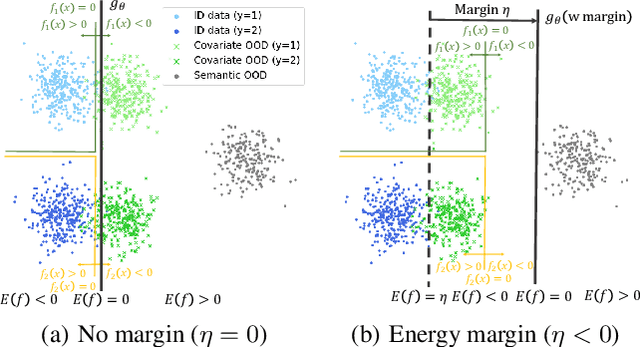
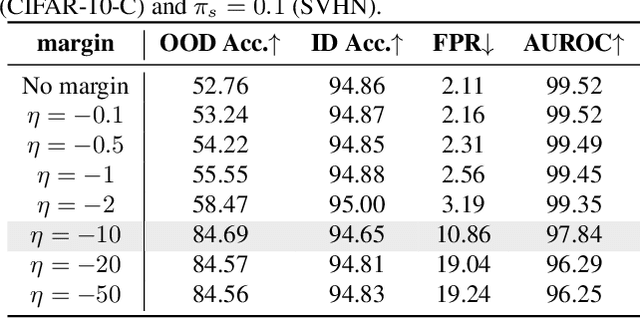
Modern machine learning models deployed in the wild can encounter both covariate and semantic shifts, giving rise to the problems of out-of-distribution (OOD) generalization and OOD detection respectively. While both problems have received significant research attention lately, they have been pursued independently. This may not be surprising, since the two tasks have seemingly conflicting goals. This paper provides a new unified approach that is capable of simultaneously generalizing to covariate shifts while robustly detecting semantic shifts. We propose a margin-based learning framework that exploits freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. We show both empirically and theoretically that the proposed margin constraint is the key to achieving both OOD generalization and detection. Extensive experiments show the superiority of our framework, outperforming competitive baselines that specialize in either OOD generalization or OOD detection. Code is publicly available at https://github.com/deeplearning-wisc/scone.
Path Generation for Wheeled Robots Autonomous Navigation on Vegetated Terrain
Jun 15, 2023
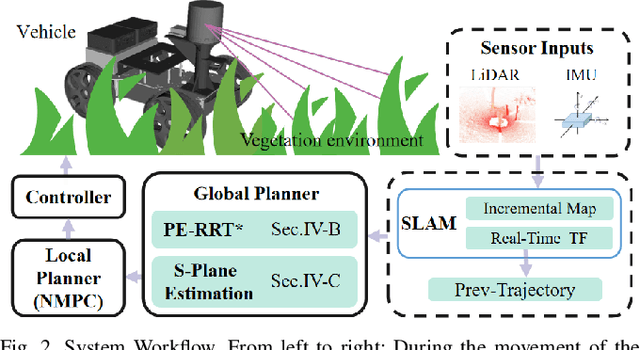
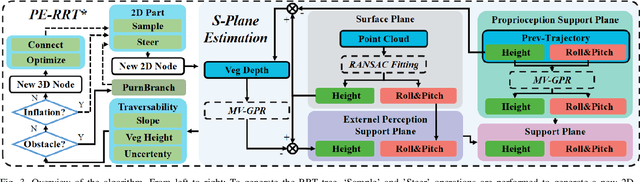
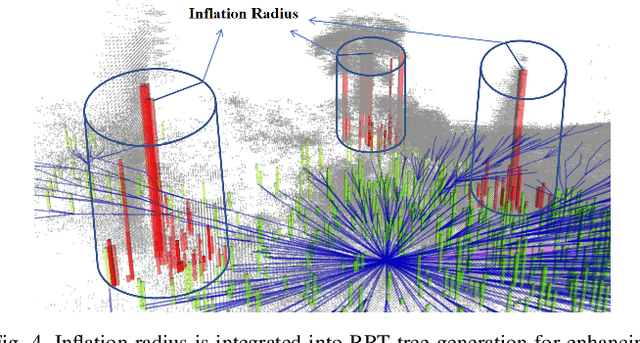
Wheeled robot navigation has been widely used in urban environments, but little research has been conducted on its navigation in wild vegetation. External sensors (LiDAR, camera etc.) are often used to construct point cloud map of the surrounding environment, however, the supporting rigid ground used for travelling cannot be detected due to the occlusion of vegetation. This often causes unsafe or not smooth path during planning process. To address the drawback, we propose the PE-RRT* algorithm, which effectively combines a novel support plane estimation method and sampling algorithm to generate real-time feasible and safe path in vegetation environments. In order to accurately estimate the support plane, we combine external perception and proprioception, and use Multivariate Gaussian Processe Regression (MV-GPR) to estimate the terrain at the sampling nodes. We build a physical experimental platform and conduct experiments in different outdoor environments. Experimental results show that our method has high safety, robustness and generalization.
Learning from Local Experience: Informed Sampling Distributions for High Dimensional Motion Planning
Jun 15, 2023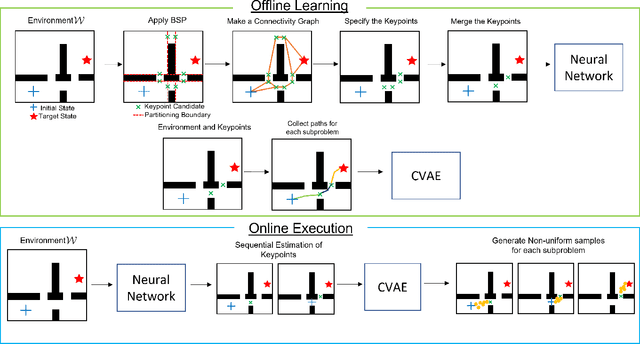

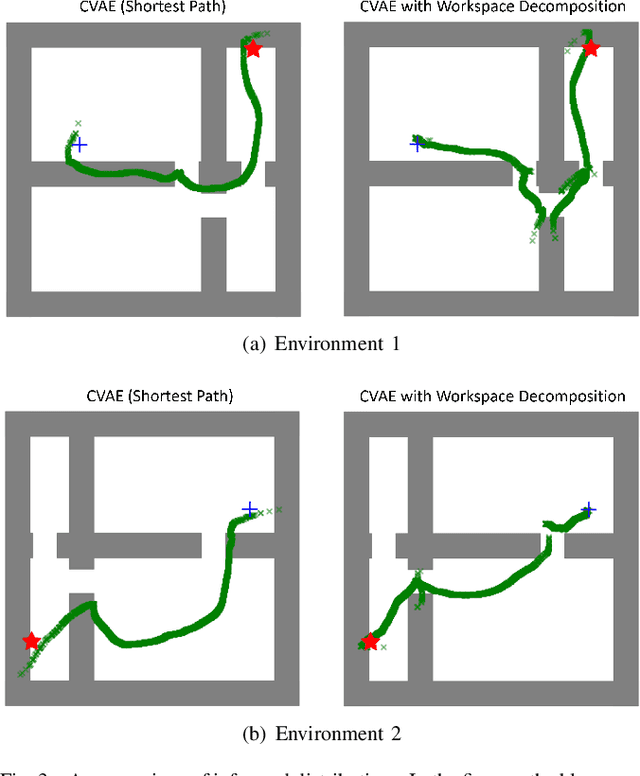
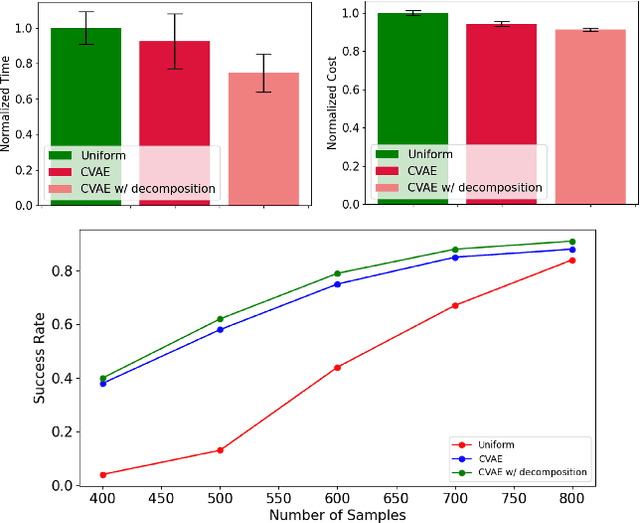
This paper presents a sampling-based motion planning framework that leverages the geometry of obstacles in a workspace as well as prior experiences from motion planning problems. Previous studies have demonstrated the benefits of utilizing prior solutions to motion planning problems for improving planning efficiency. However, particularly for high-dimensional systems, achieving high performance across randomized environments remains a technical challenge for experience-based approaches due to the substantial variance between each query. To address this challenge, we propose a novel approach that involves decoupling the problem into subproblems through algorithmic workspace decomposition and graph search. Additionally, we capitalize on prior experience within each subproblem. This approach effectively reduces the variance across different problems, leading to improved performance for experience-based planners. To validate the effectiveness of our framework, we conduct experiments using 2D and 6D robotic systems. The experimental results demonstrate that our framework outperforms existing algorithms in terms of planning time and cost.
Optimization of RIS-Aided MIMO -- A Mutually Coupled Loaded Wire Dipole Model
Jun 15, 2023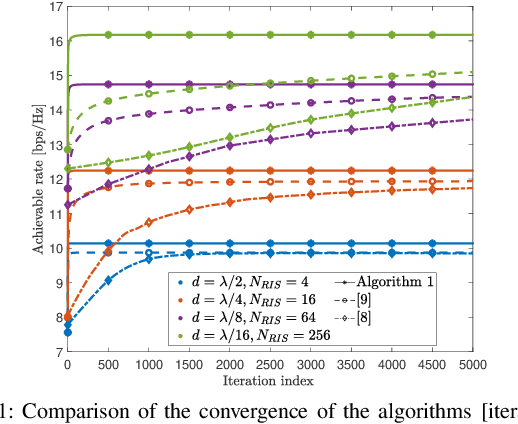
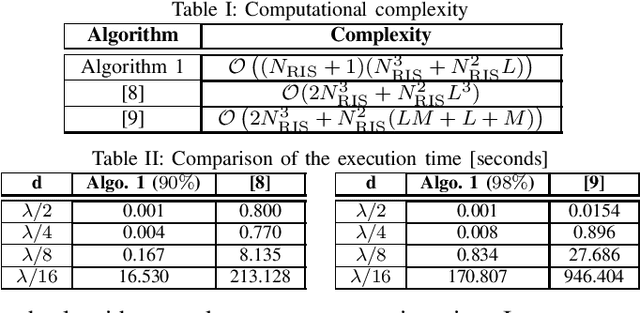
In this letter, we consider a reconfigurable intelligent surface (RIS) assisted multiple-input multiple-output (MIMO) system in the presence of scattering objects. The MIMO transmitter and receiver, the RIS, and the scattering objects are modeled as mutually coupled thin wires connected to load impedances. We introduce a novel numerical algorithm for optimizing the tunable loads connected to the RIS. Compared with currently available algorithms, the proposed approach does not rely on the Neumann series approximation, but it optimizes the tunable load impedances alternately and one by one. At each iteration step, a closed-form expression for each impedance is provided by applying the Gram-Schmidt orthogonalization method. The algorithm is provably convergent and has a polynomial complexity with the number of RIS elements. Also, it is shown to outperform, in terms of achievable rate, two benchmark algorithms, which are based on a similar electromagnetic model, while requiring fewer iterations and a reduced execution time to reach convergence.
Privacy-Preserving by Design: Indoor Positioning System Using Wi-Fi Passive TDOA
Jun 03, 2023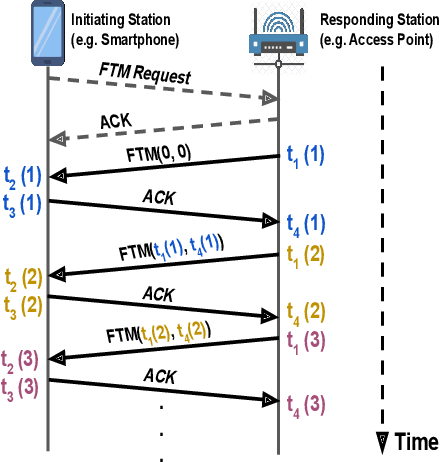
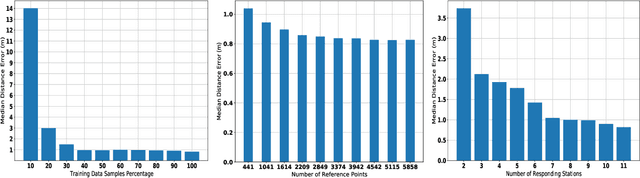
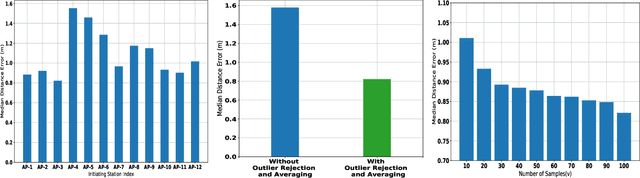
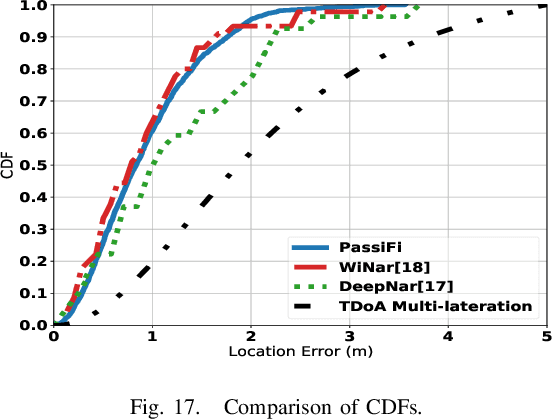
Indoor localization systems have become increasingly important in a wide range of applications, including industry, security, logistics, and emergency services. However, the growing demand for accurate localization has heightened concerns over privacy, as many localization systems rely on active signals that can be misused by an adversary to track users' movements or manipulate their measurements. This paper presents PassiFi, a novel passive Wi-Fi time-based indoor localization system that effectively balances accuracy and privacy. PassiFi uses a passive WiFi Time Difference of Arrival (TDoA) approach that ensures users' privacy and safeguards the integrity of their measurement data while still achieving high accuracy. The system adopts a fingerprinting approach to address multi-path and non-line-of-sight problems and utilizes deep neural networks to learn the complex relationship between TDoA and location. Evaluation in a real-world testbed demonstrates PassiFi's exceptional performance, surpassing traditional multilateration by 128%, achieving sub-meter accuracy on par with state-of-the-art active measurement systems, all while preserving privacy.
UniTS: A Universal Time Series Analysis Framework with Self-supervised Representation Learning
Mar 24, 2023
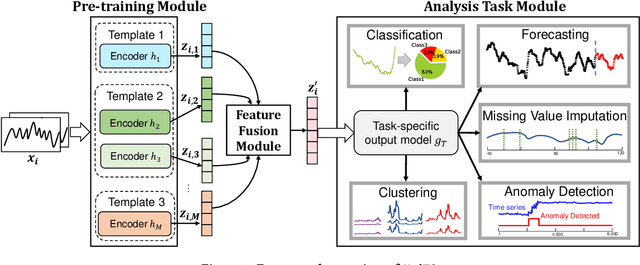
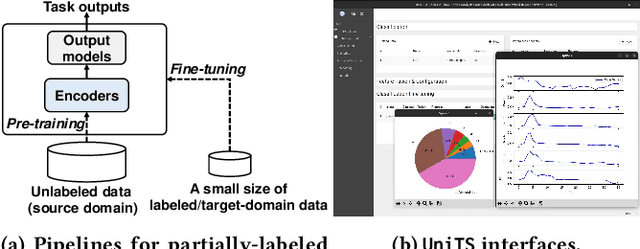
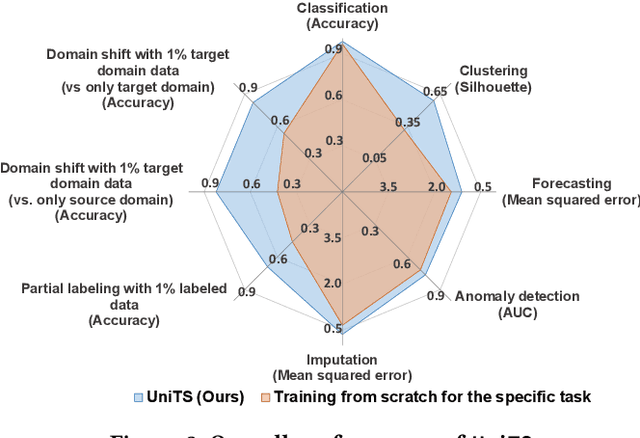
Machine learning has emerged as a powerful tool for time series analysis. Existing methods are usually customized for different analysis tasks and face challenges in tackling practical problems such as partial labeling and domain shift. To achieve universal analysis and address the aforementioned problems, we develop UniTS, a novel framework that incorporates self-supervised representation learning (or pre-training). The components of UniTS are designed using sklearn-like APIs to allow flexible extensions. We demonstrate how users can easily perform an analysis task using the user-friendly GUIs, and show the superior performance of UniTS over the traditional task-specific methods without self-supervised pre-training on five mainstream tasks and two practical settings.