 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Resources and Evaluations for Multi-Distribution Dense Information Retrieval
Jun 21, 2023
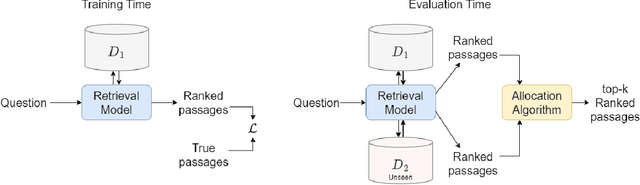

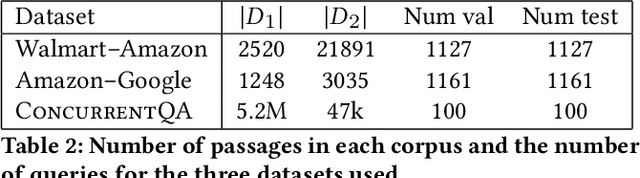
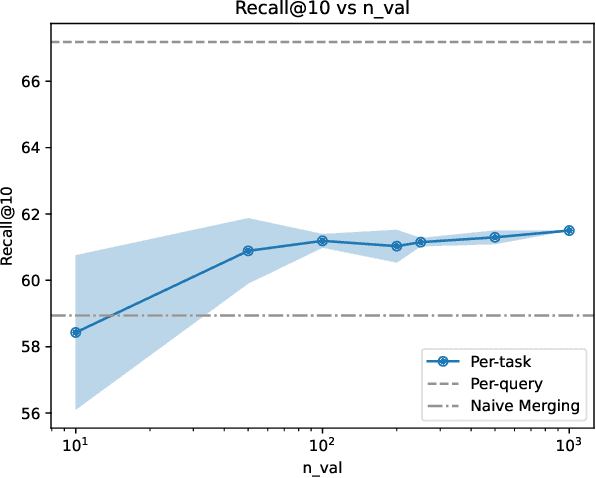
We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
Label-efficient Time Series Representation Learning: A Review
Feb 13, 2023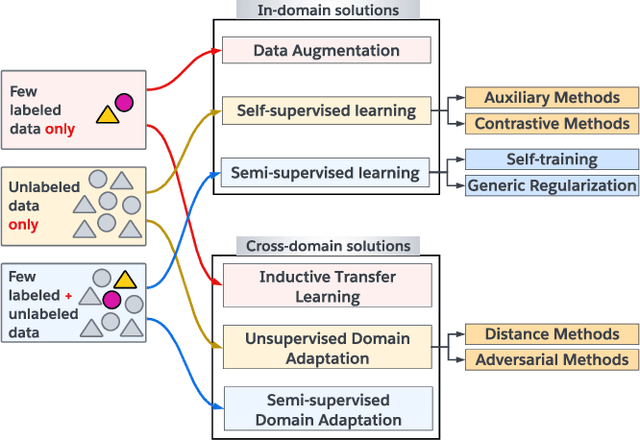
The scarcity of labeled data is one of the main challenges of applying deep learning models on time series data in the real world. Therefore, several approaches, e.g., transfer learning, self-supervised learning, and semi-supervised learning, have been recently developed to promote the learning capability of deep learning models from the limited time series labels. In this survey, for the first time, we provide a novel taxonomy to categorize existing approaches that address the scarcity of labeled data problem in time series data based on their reliance on external data sources. Moreover, we present a review of the recent advances in each approach and conclude the limitations of the current works and provide future directions that could yield better progress in the field.
Patterns Detection in Glucose Time Series by Domain Transformations and Deep Learning
Mar 30, 2023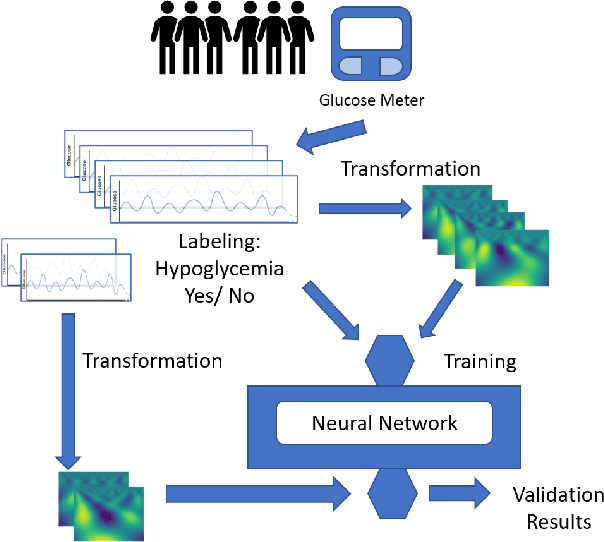
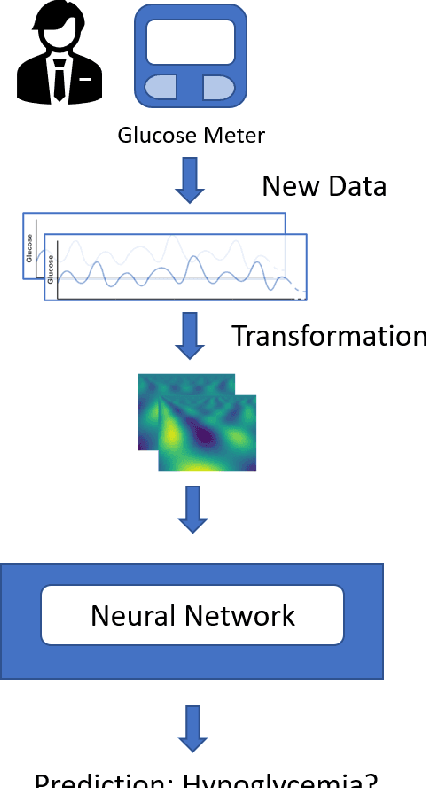
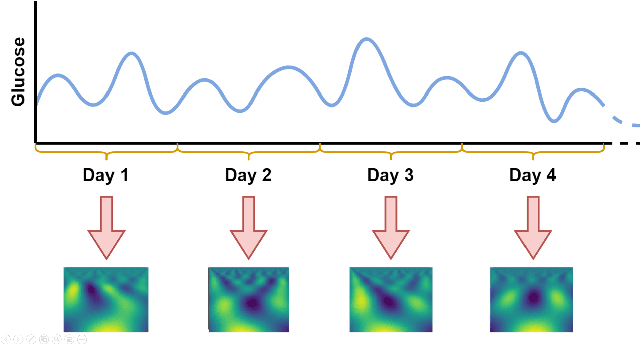
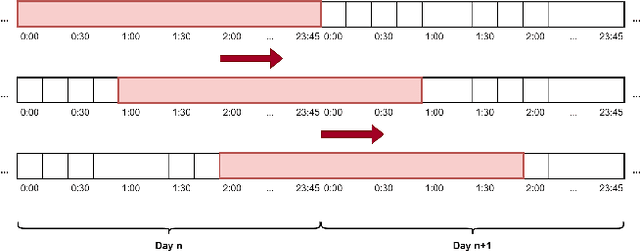
People with diabetes have to manage their blood glucose level to keep it within an appropriate range. Predicting whether future glucose values will be outside the healthy threshold is of vital importance in order to take corrective actions to avoid potential health damage. In this paper we describe our research with the aim of predicting the future behavior of blood glucose levels, so that hypoglycemic events may be anticipated. The approach of this work is the application of transformation functions on glucose time series, and their use in convolutional neural networks. We have tested our proposed method using real data from 4 different diabetes patients with promising results.
C(NN)FD -- a deep learning framework for turbomachinery CFD analysis
Jun 09, 2023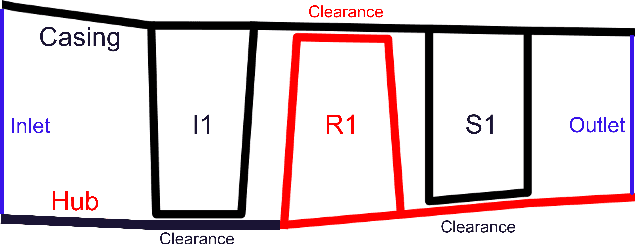
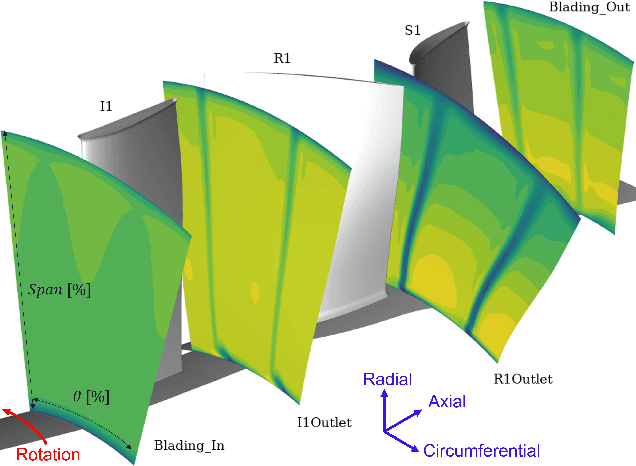
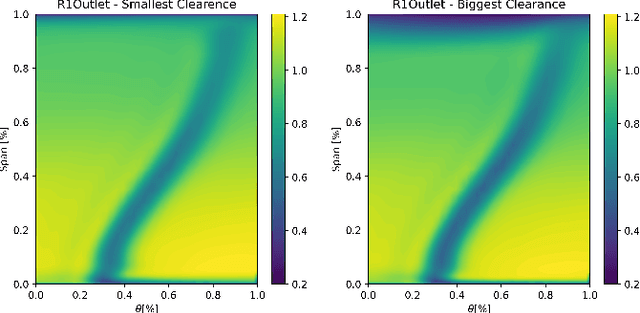
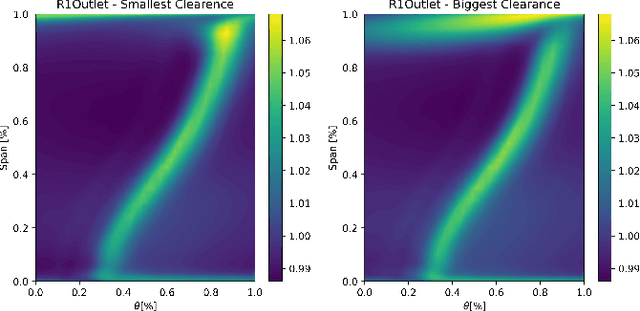
Deep Learning methods have seen a wide range of successful applications across different industries. Up until now, applications to physical simulations such as CFD (Computational Fluid Dynamics), have been limited to simple test-cases of minor industrial relevance. This paper demonstrates the development of a novel deep learning framework for real-time predictions of the impact of manufacturing and build variations on the overall performance of axial compressors in gas turbines, with a focus on tip clearance variations. The associated scatter in efficiency can significantly increase the $CO_2$ emissions, thus being of great industrial and environmental relevance. The proposed \textit{C(NN)FD} architecture achieves in real-time accuracy comparable to the CFD benchmark. Predicting the flow field and using it to calculate the corresponding overall performance renders the methodology generalisable, while filtering only relevant parts of the CFD solution makes the methodology scalable to industrial applications.
Decision-Dependent Distributionally Robust Markov Decision Process Method in Dynamic Epidemic Control
Jun 24, 2023In this paper, we present a Distributionally Robust Markov Decision Process (DRMDP) approach for addressing the dynamic epidemic control problem. The Susceptible-Exposed-Infectious-Recovered (SEIR) model is widely used to represent the stochastic spread of infectious diseases, such as COVID-19. While Markov Decision Processes (MDP) offers a mathematical framework for identifying optimal actions, such as vaccination and transmission-reducing intervention, to combat disease spreading according to the SEIR model. However, uncertainties in these scenarios demand a more robust approach that is less reliant on error-prone assumptions. The primary objective of our study is to introduce a new DRMDP framework that allows for an ambiguous distribution of transition dynamics. Specifically, we consider the worst-case distribution of these transition probabilities within a decision-dependent ambiguity set. To overcome the computational complexities associated with policy determination, we propose an efficient Real-Time Dynamic Programming (RTDP) algorithm that is capable of computing optimal policies based on the reformulated DRMDP model in an accurate, timely, and scalable manner. Comparative analysis against the classic MDP model demonstrates that the DRMDP achieves a lower proportion of infections and susceptibilities at a reduced cost.
Multi-perspective Information Fusion Res2Net with RandomSpecmix for Fake Speech Detection
Jun 27, 2023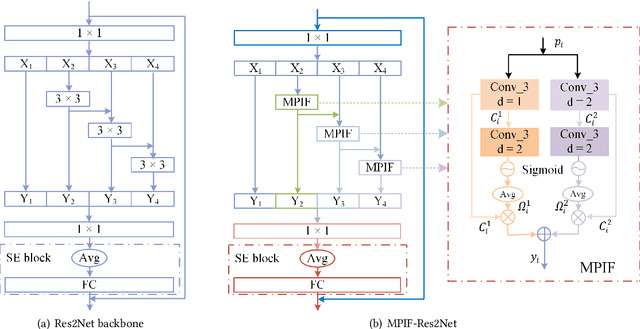

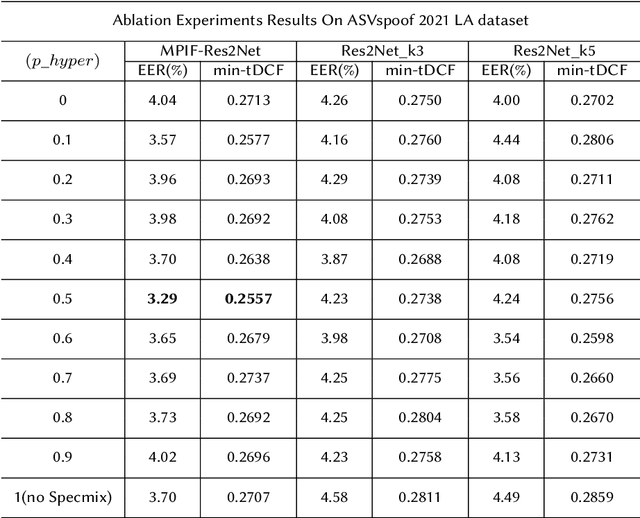
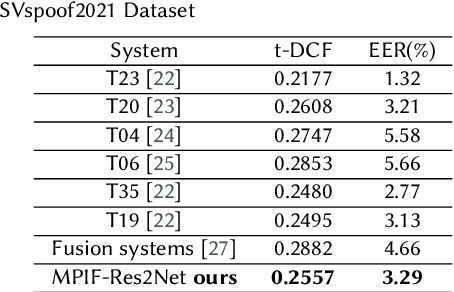
In this paper, we propose the multi-perspective information fusion (MPIF) Res2Net with random Specmix for fake speech detection (FSD). The main purpose of this system is to improve the model's ability to learn precise forgery information for FSD task in low-quality scenarios. The task of random Specmix, a data augmentation, is to improve the generalization ability of the model and enhance the model's ability to locate discriminative information. Specmix cuts and pastes the frequency dimension information of the spectrogram in the same batch of samples without introducing other data, which helps the model to locate the really useful information. At the same time, we randomly select samples for augmentation to reduce the impact of data augmentation directly changing all the data. Once the purpose of helping the model to locate information is achieved, it is also important to reduce unnecessary information. The role of MPIF-Res2Net is to reduce redundant interference information. Deceptive information from a single perspective is always similar, so the model learning this similar information will produce redundant spoofing clues and interfere with truly discriminative information. The proposed MPIF-Res2Net fuses information from different perspectives, making the information learned by the model more diverse, thereby reducing the redundancy caused by similar information and avoiding interference with the learning of discriminative information. The results on the ASVspoof 2021 LA dataset demonstrate the effectiveness of our proposed method, achieving EER and min-tDCF of 3.29% and 0.2557, respectively.
Evidential Detection and Tracking Collaboration: New Problem, Benchmark and Algorithm for Robust Anti-UAV System
Jun 27, 2023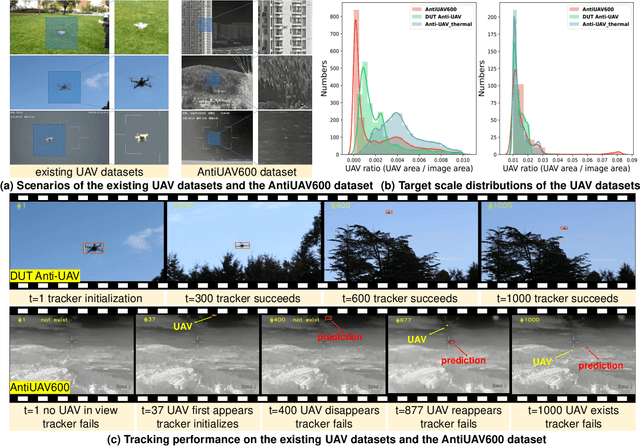
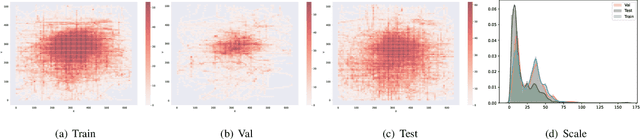
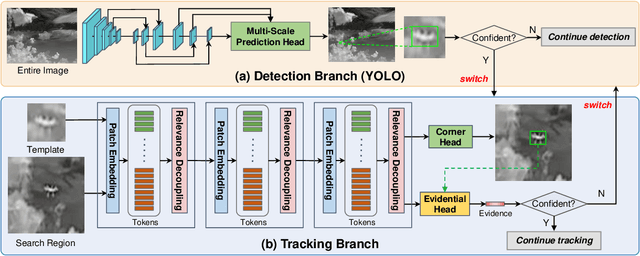
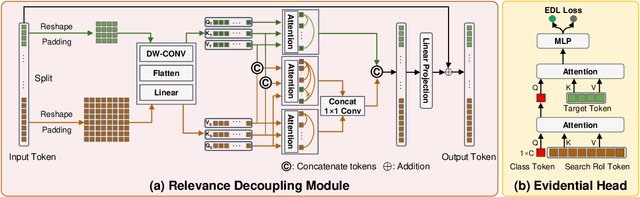
Unmanned Aerial Vehicles (UAVs) have been widely used in many areas, including transportation, surveillance, and military. However, their potential for safety and privacy violations is an increasing issue and highly limits their broader applications, underscoring the critical importance of UAV perception and defense (anti-UAV). Still, previous works have simplified such an anti-UAV task as a tracking problem, where the prior information of UAVs is always provided; such a scheme fails in real-world anti-UAV tasks (i.e. complex scenes, indeterminate-appear and -reappear UAVs, and real-time UAV surveillance). In this paper, we first formulate a new and practical anti-UAV problem featuring the UAVs perception in complex scenes without prior UAVs information. To benchmark such a challenging task, we propose the largest UAV dataset dubbed AntiUAV600 and a new evaluation metric. The AntiUAV600 comprises 600 video sequences of challenging scenes with random, fast, and small-scale UAVs, with over 723K thermal infrared frames densely annotated with bounding boxes. Finally, we develop a novel anti-UAV approach via an evidential collaboration of global UAVs detection and local UAVs tracking, which effectively tackles the proposed problem and can serve as a strong baseline for future research. Extensive experiments show our method outperforms SOTA approaches and validate the ability of AntiUAV600 to enhance UAV perception performance due to its large scale and complexity. Our dataset, pretrained models, and source codes will be released publically.
DCP-NAS: Discrepant Child-Parent Neural Architecture Search for 1-bit CNNs
Jun 27, 2023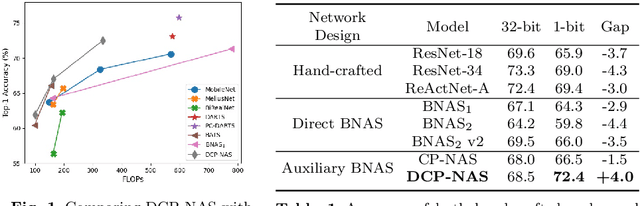
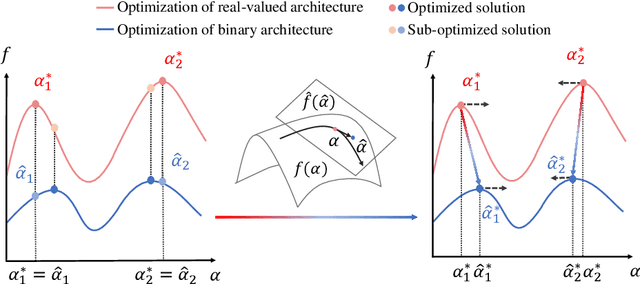

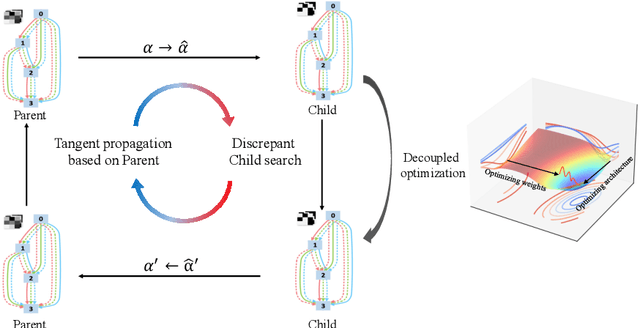
Neural architecture search (NAS) proves to be among the effective approaches for many tasks by generating an application-adaptive neural architecture, which is still challenged by high computational cost and memory consumption. At the same time, 1-bit convolutional neural networks (CNNs) with binary weights and activations show their potential for resource-limited embedded devices. One natural approach is to use 1-bit CNNs to reduce the computation and memory cost of NAS by taking advantage of the strengths of each in a unified framework, while searching the 1-bit CNNs is more challenging due to the more complicated processes involved. In this paper, we introduce Discrepant Child-Parent Neural Architecture Search (DCP-NAS) to efficiently search 1-bit CNNs, based on a new framework of searching the 1-bit model (Child) under the supervision of a real-valued model (Parent). Particularly, we first utilize a Parent model to calculate a tangent direction, based on which the tangent propagation method is introduced to search the optimized 1-bit Child. We further observe a coupling relationship between the weights and architecture parameters existing in such differentiable frameworks. To address the issue, we propose a decoupled optimization method to search an optimized architecture. Extensive experiments demonstrate that our DCP-NAS achieves much better results than prior arts on both CIFAR-10 and ImageNet datasets. In particular, the backbones achieved by our DCP-NAS achieve strong generalization performance on person re-identification and object detection.
Beyond Exponential Graph: Communication-Efficient Topologies for Decentralized Learning via Finite-time Convergence
May 19, 2023
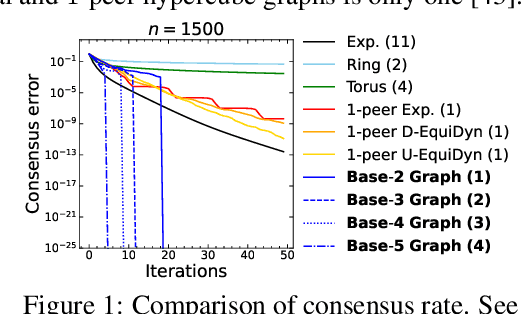
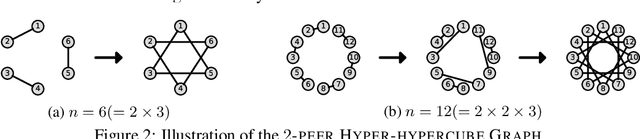

Decentralized learning has recently been attracting increasing attention for its applications in parallel computation and privacy preservation. Many recent studies stated that the underlying network topology with a faster consensus rate (a.k.a. spectral gap) leads to a better convergence rate and accuracy for decentralized learning. However, a topology with a fast consensus rate, e.g., the exponential graph, generally has a large maximum degree, which incurs significant communication costs. Thus, seeking topologies with both a fast consensus rate and small maximum degree is important. In this study, we propose a novel topology combining both a fast consensus rate and small maximum degree called the Base-$(k + 1)$ Graph. Unlike the existing topologies, the Base-$(k + 1)$ Graph enables all nodes to reach the exact consensus after a finite number of iterations for any number of nodes and maximum degree k. Thanks to this favorable property, the Base-$(k + 1)$ Graph endows Decentralized SGD (DSGD) with both a faster convergence rate and more communication efficiency than the exponential graph. We conducted experiments with various topologies, demonstrating that the Base-$(k + 1)$ Graph enables various decentralized learning methods to achieve higher accuracy with better communication efficiency than the existing topologies.
Estimating Treatment Effects in Continuous Time with Hidden Confounders
Feb 21, 2023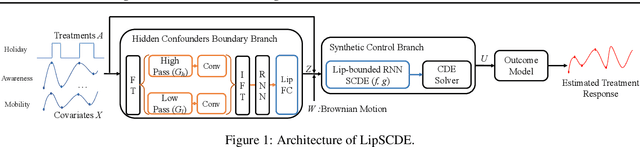
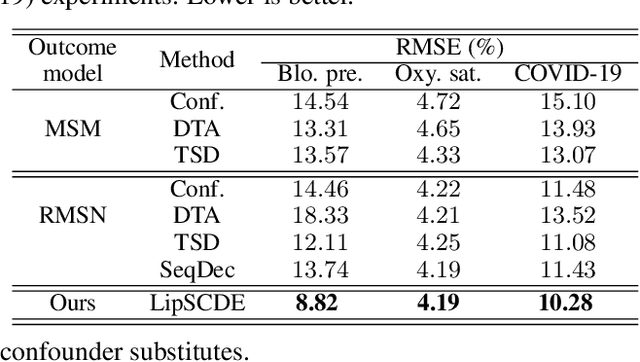
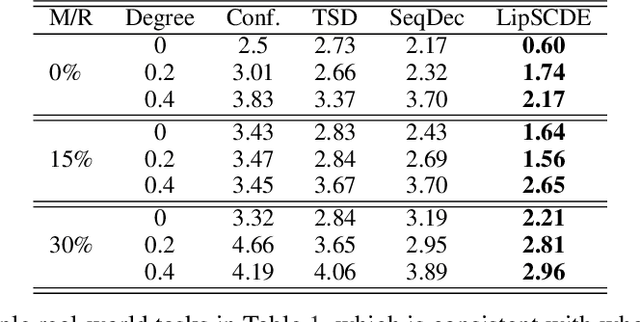
Estimating treatment effects plays a crucial role in causal inference, having many real-world applications like policy analysis and decision making. Nevertheless, estimating treatment effects in the longitudinal setting in the presence of hidden confounders remains an extremely challenging problem. Recently, there is a growing body of work attempting to obtain unbiased ITE estimates from time-dynamic observational data by ignoring the possible existence of hidden confounders. Additionally, many existing works handling hidden confounders are not applicable for continuous-time settings. In this paper, we extend the line of work focusing on deconfounding in the dynamic time setting in the presence of hidden confounders. We leverage recent advancements in neural differential equations to build a latent factor model using a stochastic controlled differential equation and Lipschitz constrained convolutional operation in order to continuously incorporate information about ongoing interventions and irregularly sampled observations. Experiments on both synthetic and real-world datasets highlight the promise of continuous time methods for estimating treatment effects in the presence of hidden confounders.