 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Heuristics for Multi-Robot Path Planning in Crowded Environments
Jun 26, 2023
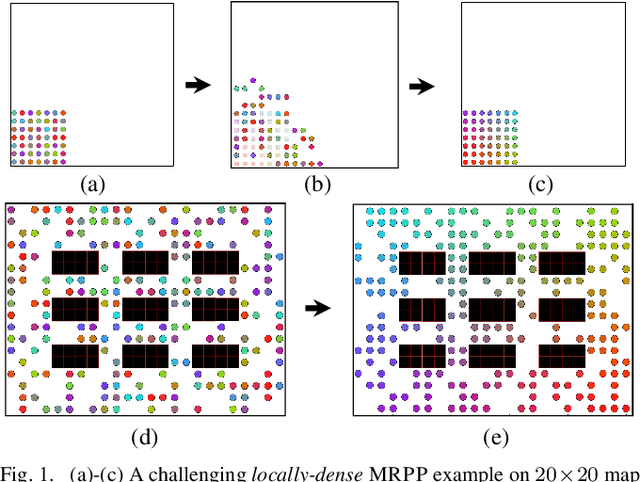
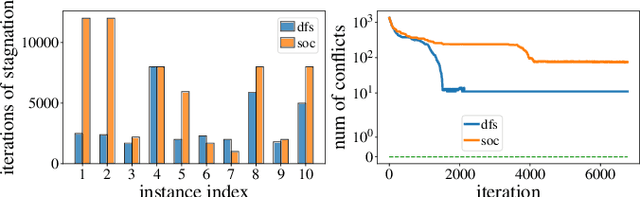
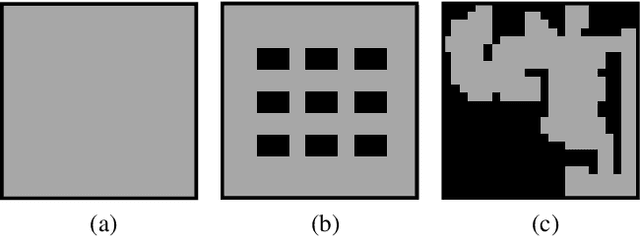
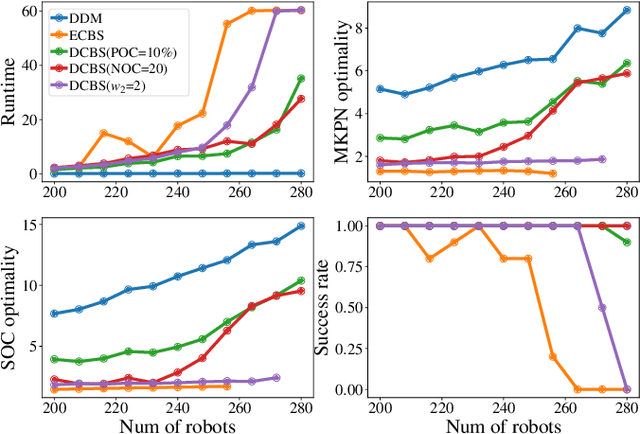
Optimal Multi-Robot Path Planning (MRPP) has garnered significant attention due to its many applications in domains including warehouse automation, transportation, and swarm robotics. Current MRPP solvers can be divided into reduction-based, search-based, and rule-based categories, each with their strengths and limitations. Regardless of the methodology, however, the issue of handling dense MRPP instances remains a significant challenge, where existing approaches generally demonstrate a dichotomy regarding solution optimality and efficiency. This study seeks to bridge the gap in optimal MRPP resolution for dense, highly-entangled scenarios, with potential applications to high-density storage systems and traffic congestion control. Toward that goal, we analyze the behaviors of SOTA MRPP algorithms in dense settings and develop two hybrid algorithms leveraging the strengths of existing SOTA algorithms: DCBS (database-accelerated enhanced conflict-based search) and SCBS (sparsified enhanced conflict-based search). Experimental validations demonstrate that DCBS and SCBS deliver a significant reduction in computational time compared to existing bounded-suboptimal methods and improve solution quality compared to existing rule-based methods, achieving a desirable balance between computational efficiency and solution optimality. As a result, DCBS and SCBS are particularly suitable for quickly computing good-quality solutions for multi-robot routing in dense settings
Reciprocal Sequential Recommendation
Jun 26, 2023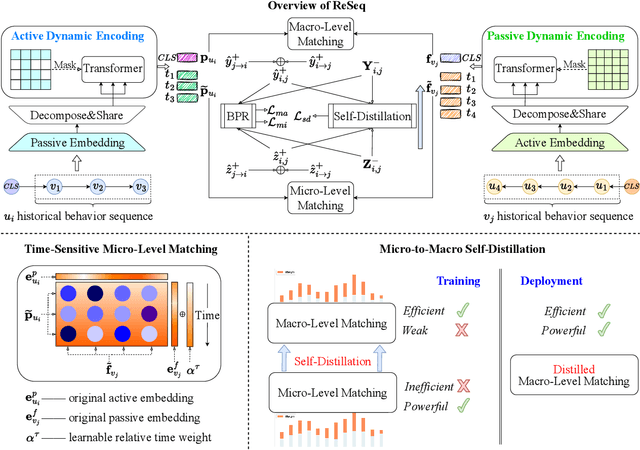
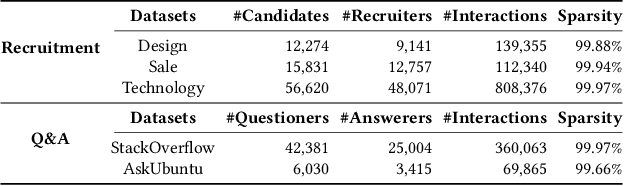
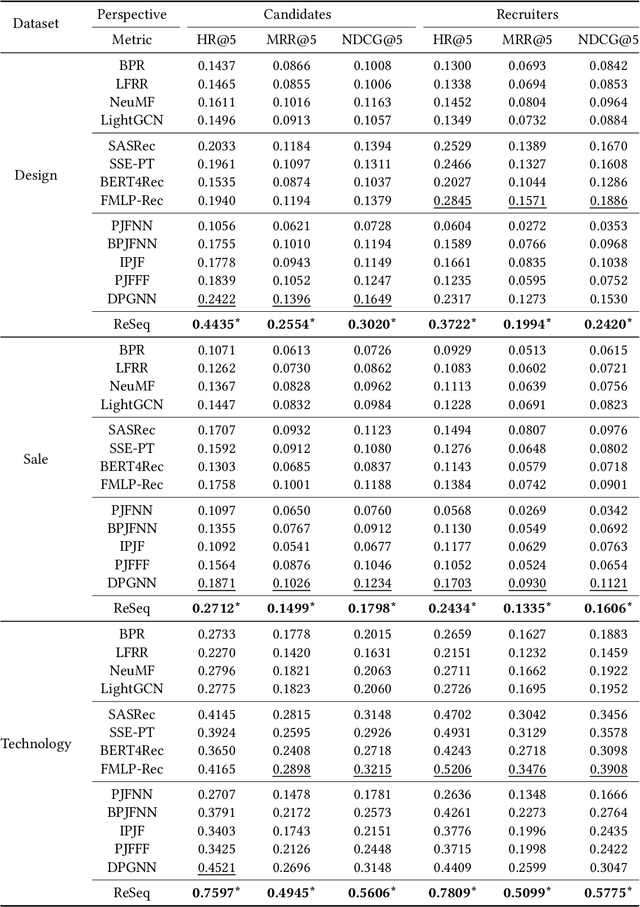
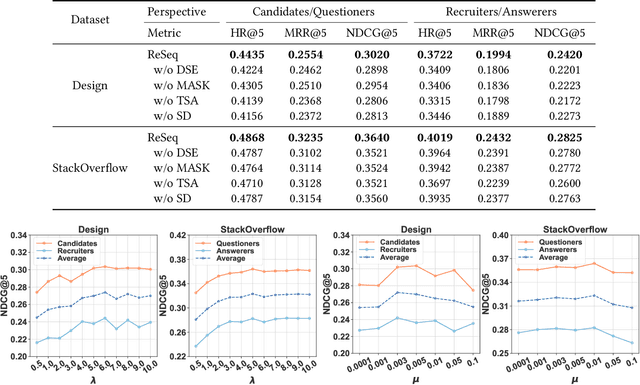
Reciprocal recommender system (RRS), considering a two-way matching between two parties, has been widely applied in online platforms like online dating and recruitment. Existing RRS models mainly capture static user preferences, which have neglected the evolving user tastes and the dynamic matching relation between the two parties. Although dynamic user modeling has been well-studied in sequential recommender systems, existing solutions are developed in a user-oriented manner. Therefore, it is non-trivial to adapt sequential recommendation algorithms to reciprocal recommendation. In this paper, we formulate RRS as a distinctive sequence matching task, and further propose a new approach ReSeq for RRS, which is short for Reciprocal Sequential recommendation. To capture dual-perspective matching, we propose to learn fine-grained sequence similarities by co-attention mechanism across different time steps. Further, to improve the inference efficiency, we introduce the self-distillation technique to distill knowledge from the fine-grained matching module into the more efficient student module. In the deployment stage, only the efficient student module is used, greatly speeding up the similarity computation. Extensive experiments on five real-world datasets from two scenarios demonstrate the effectiveness and efficiency of the proposed method. Our code is available at https://github.com/RUCAIBox/ReSeq/.
Error correcting 2D-3D cascaded network for myocardial infarct scar segmentation on late gadolinium enhancement cardiac magnetic resonance images
Jun 26, 2023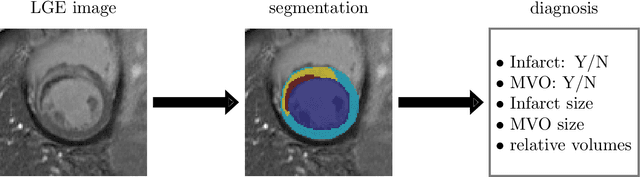
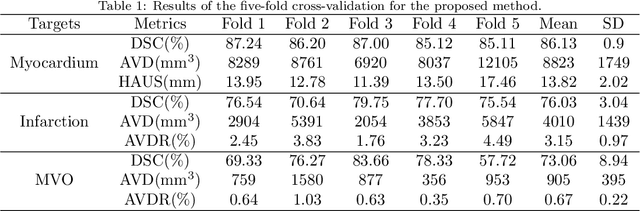
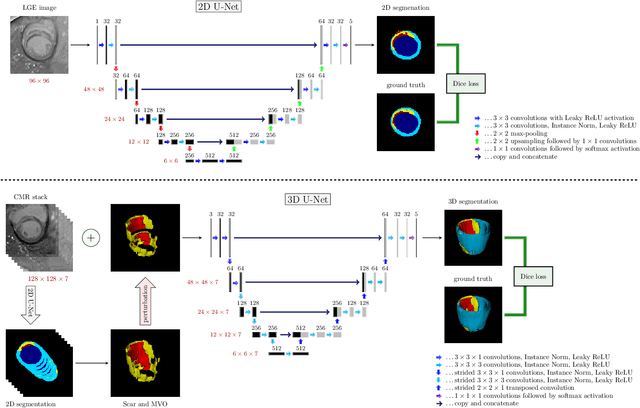
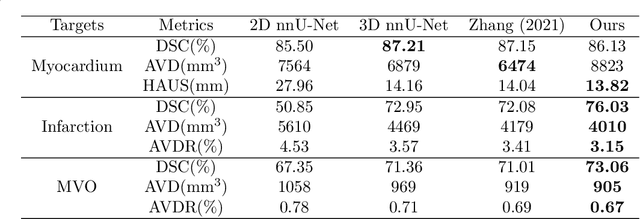
Late gadolinium enhancement (LGE) cardiac magnetic resonance (CMR) imaging is considered the in vivo reference standard for assessing infarct size (IS) and microvascular obstruction (MVO) in ST-elevation myocardial infarction (STEMI) patients. However, the exact quantification of those markers of myocardial infarct severity remains challenging and very time-consuming. As LGE distribution patterns can be quite complex and hard to delineate from the blood pool or epicardial fat, automatic segmentation of LGE CMR images is challenging. In this work, we propose a cascaded framework of two-dimensional and three-dimensional convolutional neural networks (CNNs) which enables to calculate the extent of myocardial infarction in a fully automated way. By artificially generating segmentation errors which are characteristic for 2D CNNs during training of the cascaded framework we are enforcing the detection and correction of 2D segmentation errors and hence improve the segmentation accuracy of the entire method. The proposed method was trained and evaluated in a five-fold cross validation using the training dataset from the EMIDEC challenge. We perform comparative experiments where our framework outperforms state-of-the-art methods of the EMIDEC challenge, as well as 2D and 3D nnU-Net. Furthermore, in extensive ablation studies we show the advantages that come with the proposed error correcting cascaded method.
Subjective assessment of the impact of a content adaptive optimiser for compressing 4K HDR content with AV1
Jun 26, 2023

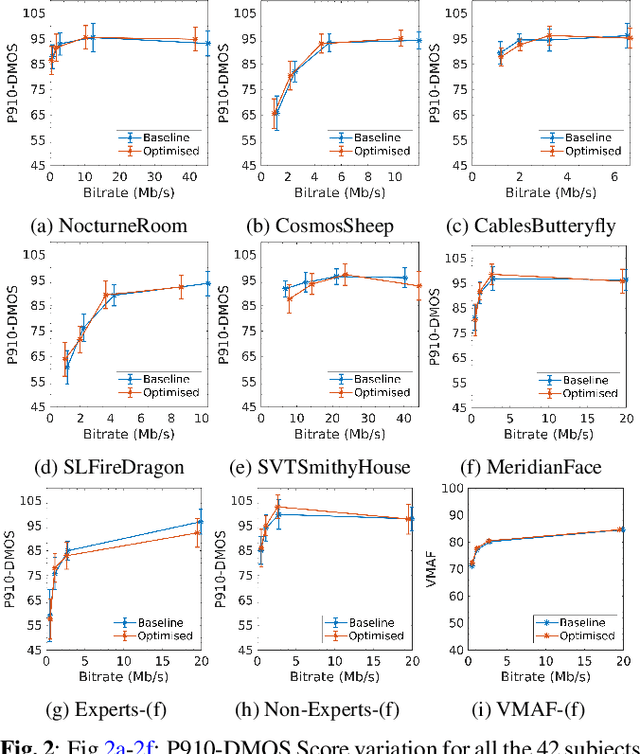
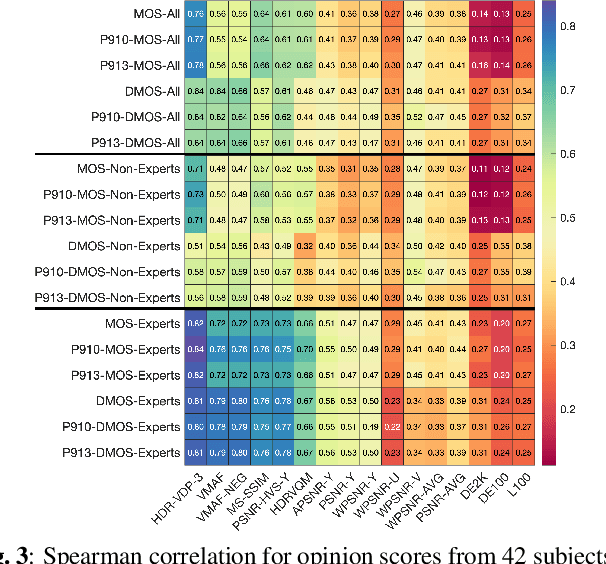
Since 2015 video dimensionality has expanded to higher spatial and temporal resolutions and a wider colour gamut. This High Dynamic Range (HDR) content has gained traction in the consumer space as it delivers an enhanced quality of experience. At the same time, the complexity of codecs is growing. This has driven the development of tools for content-adaptive optimisation that achieve optimal rate-distortion performance for HDR video at 4K resolution. While improvements of just a few percentage points in BD-Rate (1-5\%) are significant for the streaming media industry, the impact on subjective quality has been less studied especially for HDR/AV1. In this paper, we conduct a subjective quality assessment (42 subjects) of 4K HDR content with a per-clip optimisation strategy. We correlate these subjective scores with existing popular objective metrics used in standard development and show that some perceptual metrics correlate surprisingly well even though they are not tuned for HDR. We find that the DSQCS protocol is too insensitive to categorically compare the methods but the data allows us to make recommendations about the use of experts vs non-experts in HDR studies, and explain the subjective impact of film grain in HDR content under compression.
Stock Price Prediction using Dynamic Neural Networks
Jun 18, 2023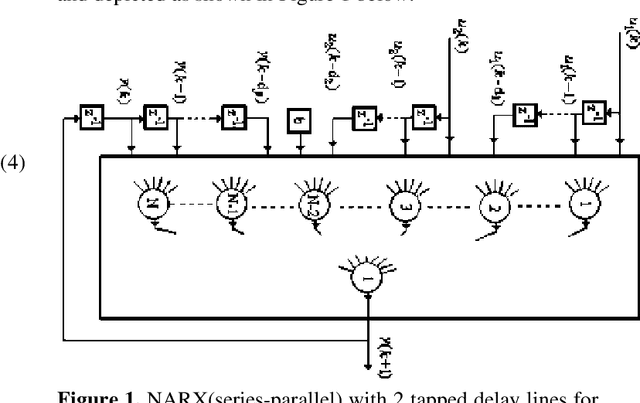
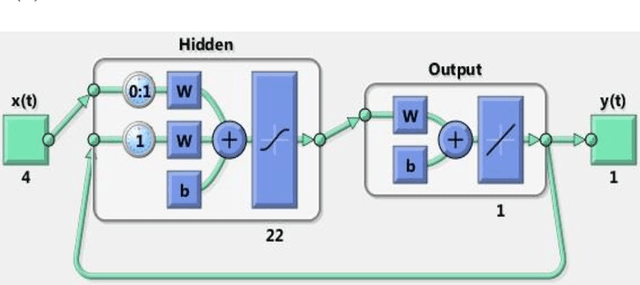
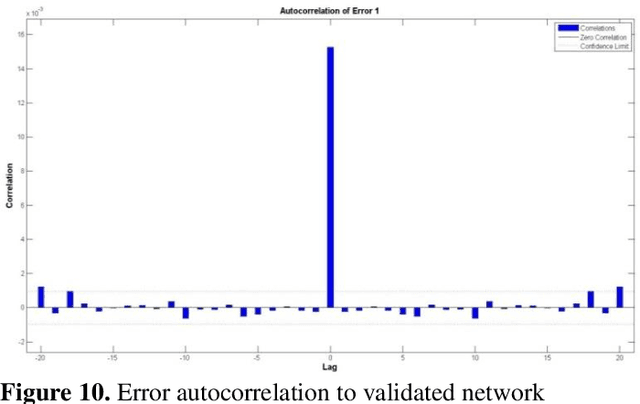
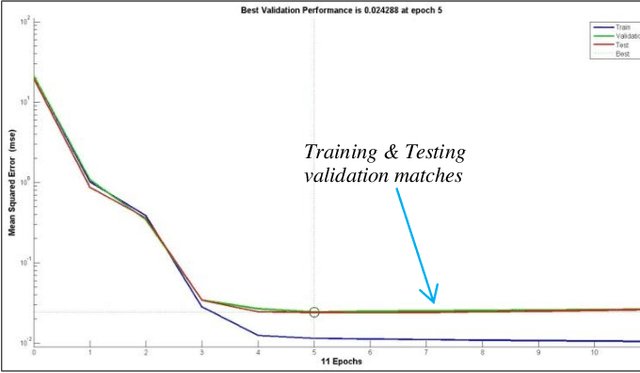
This paper will analyze and implement a time series dynamic neural network to predict daily closing stock prices. Neural networks possess unsurpassed abilities in identifying underlying patterns in chaotic, non-linear, and seemingly random data, thus providing a mechanism to predict stock price movements much more precisely than many current techniques. Contemporary methods for stock analysis, including fundamental, technical, and regression techniques, are conversed and paralleled with the performance of neural networks. Also, the Efficient Market Hypothesis (EMH) is presented and contrasted with Chaos theory using neural networks. This paper will refute the EMH and support Chaos theory. Finally, recommendations for using neural networks in stock price prediction will be presented.
Decentralized Learning Dynamics in the Gossip Model
Jun 14, 2023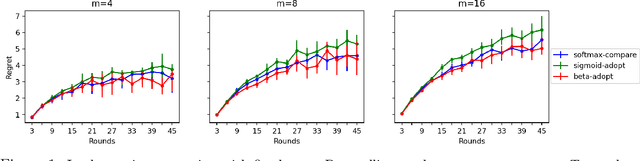
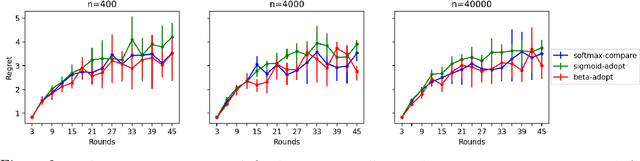
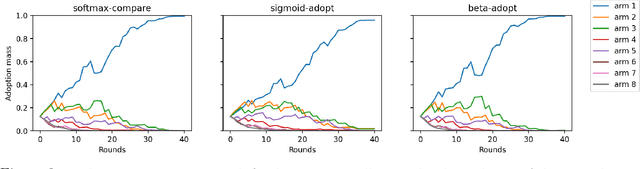
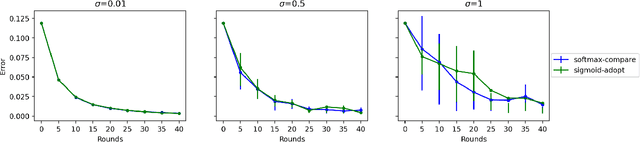
We study a distributed multi-armed bandit setting among a population of $n$ memory-constrained nodes in the gossip model: at each round, every node locally adopts one of $m$ arms, observes a reward drawn from the arm's (adversarially chosen) distribution, and then communicates with a randomly sampled neighbor, exchanging information to determine its policy in the next round. We introduce and analyze several families of dynamics for this task that are decentralized: each node's decision is entirely local and depends only on its most recently obtained reward and that of the neighbor it sampled. We show a connection between the global evolution of these decentralized dynamics with a certain class of "zero-sum" multiplicative weight update algorithms, and we develop a general framework for analyzing the population-level regret of these natural protocols. Using this framework, we derive sublinear regret bounds under a wide range of parameter regimes (i.e., the size of the population and number of arms) for both the stationary reward setting (where the mean of each arm's distribution is fixed over time) and the adversarial reward setting (where means can vary over time). Further, we show that these protocols can approximately optimize convex functions over the simplex when the reward distributions are generated from a stochastic gradient oracle.
Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) for comfortable and safe autonomous driving
Jun 15, 2023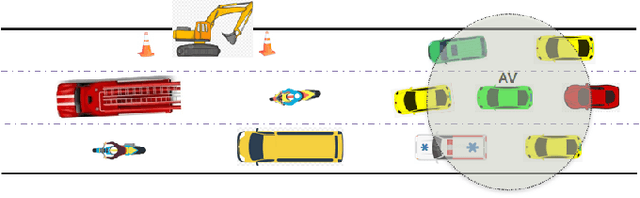
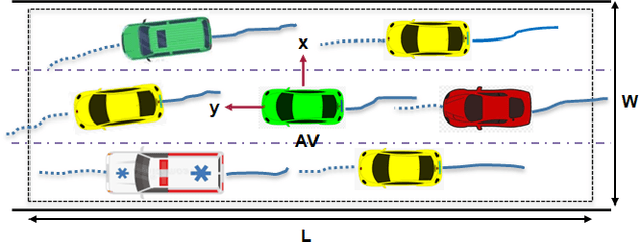
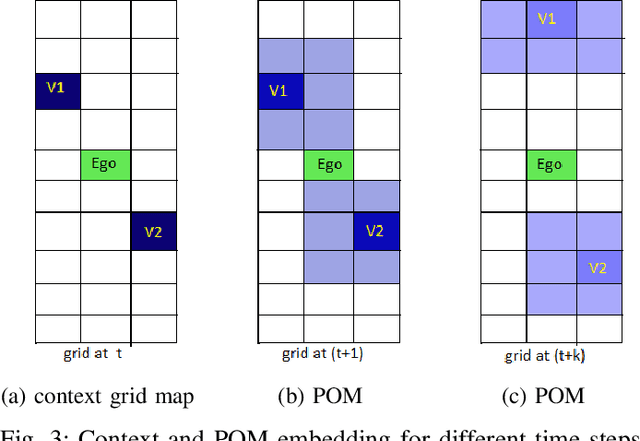
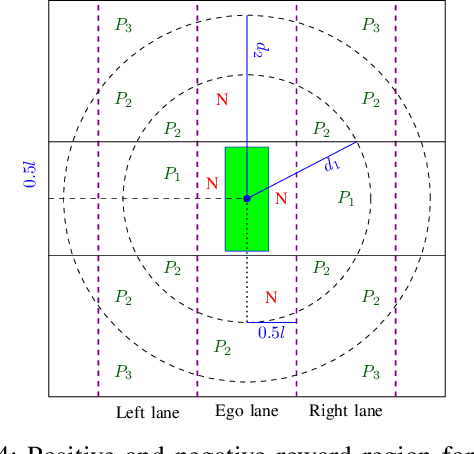
This paper presents a Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) model for maneuver planning. Traditional rule-based maneuver planning approaches often have to improve their abilities to handle the variabilities of real-world driving scenarios. By learning from its experience, a Reinforcement Learning (RL)-based driving agent can adapt to changing driving conditions and improve its performance over time. Our proposed approach combines a predictive model and an RL agent to plan for comfortable and safe maneuvers. The predictive model is trained using historical driving data to predict the future positions of other surrounding vehicles. The surrounding vehicles' past and predicted future positions are embedded in context-aware grid maps. At the same time, the RL agent learns to make maneuvers based on this spatio-temporal context information. Performance evaluation of PMP-DRL has been carried out using simulated environments generated from publicly available NGSIM US101 and I80 datasets. The training sequence shows the continuous improvement in the driving experiences. It shows that proposed PMP-DRL can learn the trade-off between safety and comfortability. The decisions generated by the recent imitation learning-based model are compared with the proposed PMP-DRL for unseen scenarios. The results clearly show that PMP-DRL can handle complex real-world scenarios and make better comfortable and safe maneuver decisions than rule-based and imitative models.
TauPETGen: Text-Conditional Tau PET Image Synthesis Based on Latent Diffusion Models
Jun 21, 2023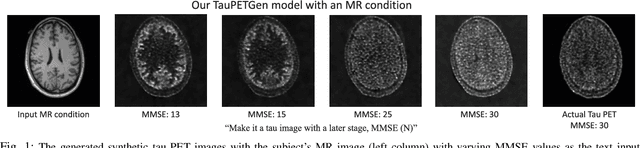
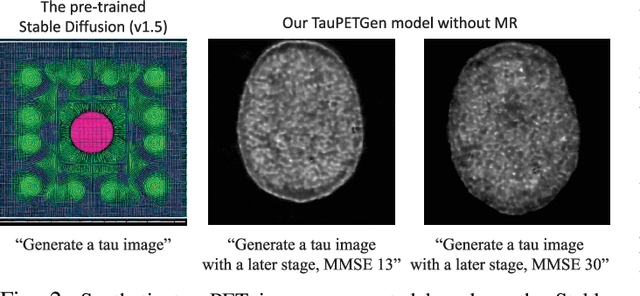
In this work, we developed a novel text-guided image synthesis technique which could generate realistic tau PET images from textual descriptions and the subject's MR image. The generated tau PET images have the potential to be used in examining relations between different measures and also increasing the public availability of tau PET datasets. The method was based on latent diffusion models. Both textual descriptions and the subject's MR prior image were utilized as conditions during image generation. The subject's MR image can provide anatomical details, while the text descriptions, such as gender, scan time, cognitive test scores, and amyloid status, can provide further guidance regarding where the tau neurofibrillary tangles might be deposited. Preliminary experimental results based on clinical [18F]MK-6240 datasets demonstrate the feasibility of the proposed method in generating realistic tau PET images at different clinical stages.
MLonMCU: TinyML Benchmarking with Fast Retargeting
Jun 15, 2023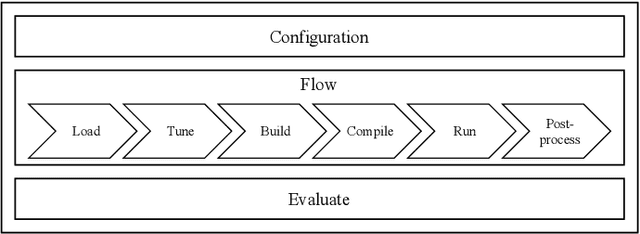


While there exist many ways to deploy machine learning models on microcontrollers, it is non-trivial to choose the optimal combination of frameworks and targets for a given application. Thus, automating the end-to-end benchmarking flow is of high relevance nowadays. A tool called MLonMCU is proposed in this paper and demonstrated by benchmarking the state-of-the-art TinyML frameworks TFLite for Microcontrollers and TVM effortlessly with a large number of configurations in a low amount of time.
Efficient Real Time Recurrent Learning through combined activity and parameter sparsity
Mar 10, 2023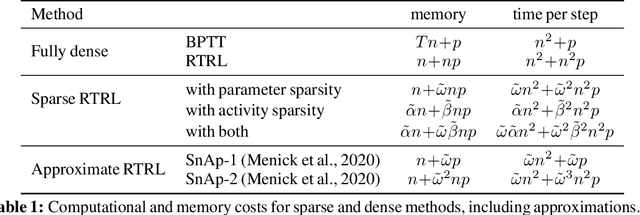
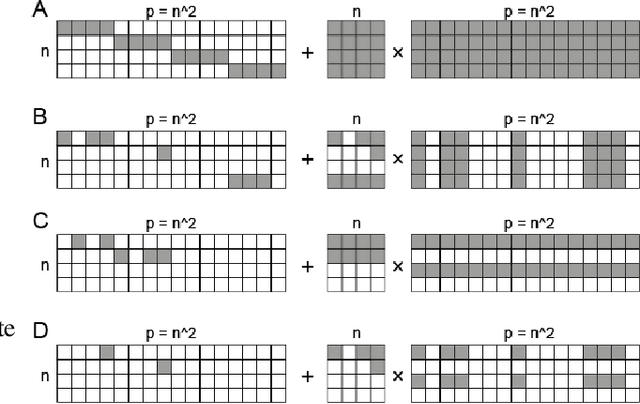
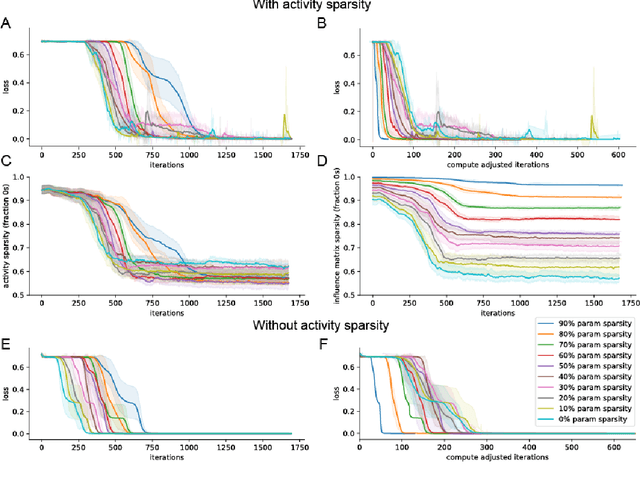
Backpropagation through time (BPTT) is the standard algorithm for training recurrent neural networks (RNNs), which requires separate simulation phases for the forward and backward passes for inference and learning, respectively. Moreover, BPTT requires storing the complete history of network states between phases, with memory consumption growing proportional to the input sequence length. This makes BPTT unsuited for online learning and presents a challenge for implementation on low-resource real-time systems. Real-Time Recurrent Learning (RTRL) allows online learning, and the growth of required memory is independent of sequence length. However, RTRL suffers from exceptionally high computational costs that grow proportional to the fourth power of the state size, making RTRL computationally intractable for all but the smallest of networks. In this work, we show that recurrent networks exhibiting high activity sparsity can reduce the computational cost of RTRL. Moreover, combining activity and parameter sparsity can lead to significant enough savings in computational and memory costs to make RTRL practical. Unlike previous work, this improvement in the efficiency of RTRL can be achieved without using any approximations for the learning process.