 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bridging the Gap between Decision and Logits in Decision-based Knowledge Distillation for Pre-trained Language Models
Jun 15, 2023
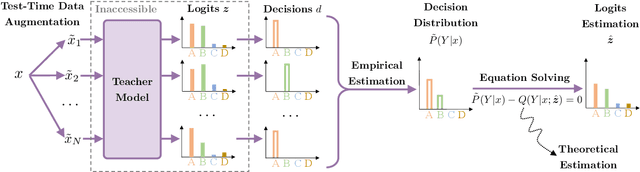
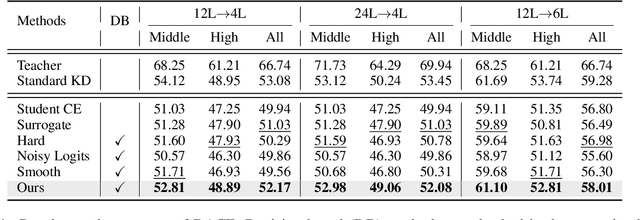
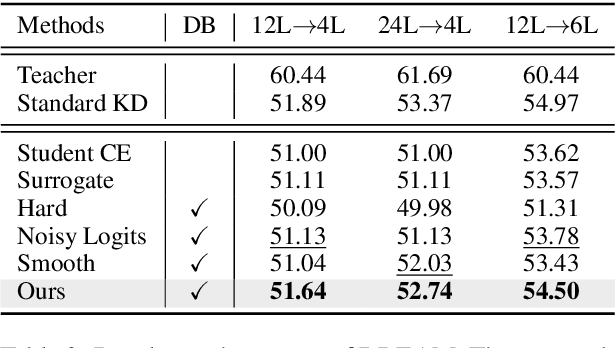
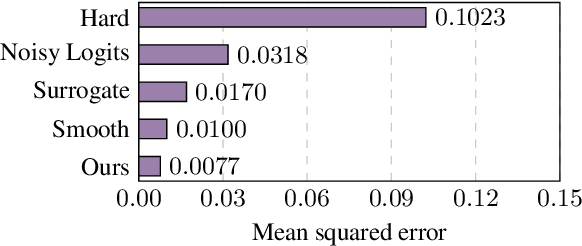
Conventional knowledge distillation (KD) methods require access to the internal information of teachers, e.g., logits. However, such information may not always be accessible for large pre-trained language models (PLMs). In this work, we focus on decision-based KD for PLMs, where only teacher decisions (i.e., top-1 labels) are accessible. Considering the information gap between logits and decisions, we propose a novel method to estimate logits from the decision distributions. Specifically, decision distributions can be both derived as a function of logits theoretically and estimated with test-time data augmentation empirically. By combining the theoretical and empirical estimations of the decision distributions together, the estimation of logits can be successfully reduced to a simple root-finding problem. Extensive experiments show that our method significantly outperforms strong baselines on both natural language understanding and machine reading comprehension datasets.
One-Shot Federated Learning for LEO Constellations that Reduces Convergence Time from Days to 90 Minutes
May 21, 2023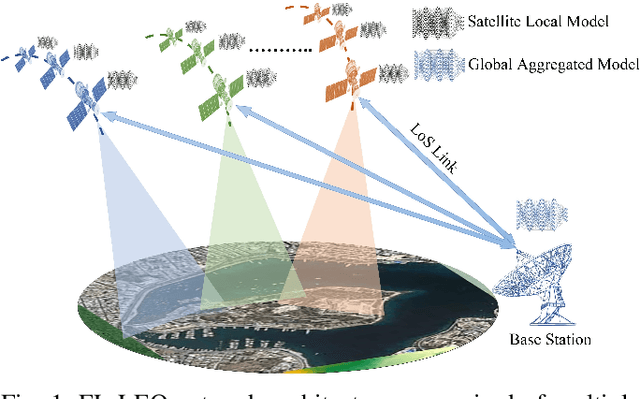
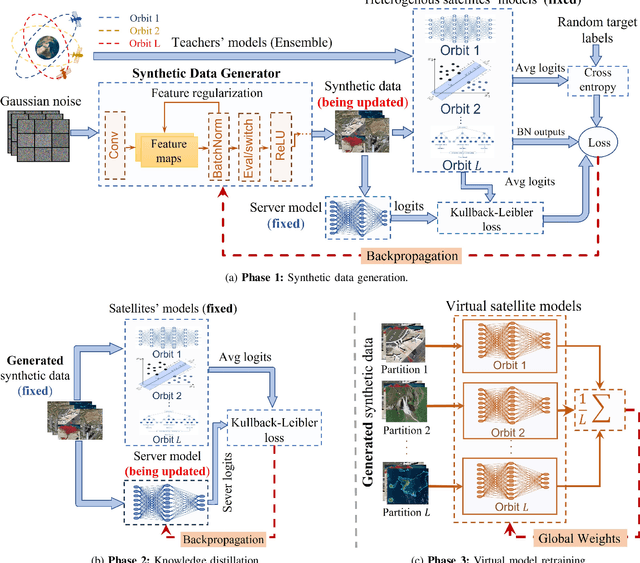
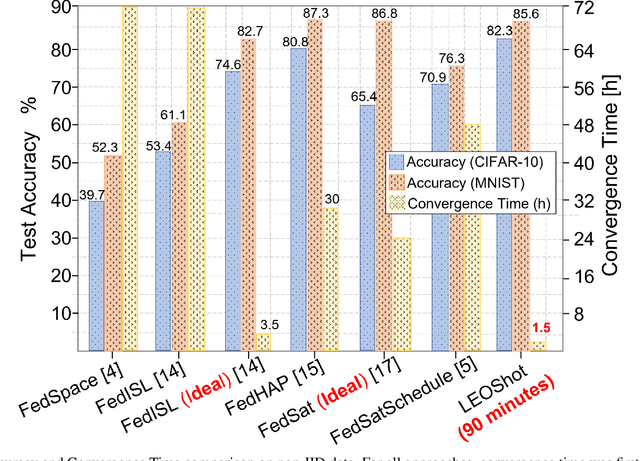

A Low Earth orbit (LEO) satellite constellation consists of a large number of small satellites traveling in space with high mobility and collecting vast amounts of mobility data such as cloud movement for weather forecast, large herds of animals migrating across geo-regions, spreading of forest fires, and aircraft tracking. Machine learning can be utilized to analyze these mobility data to address global challenges, and Federated Learning (FL) is a promising approach because it eliminates the need for transmitting raw data and hence is both bandwidth and privacy-friendly. However, FL requires many communication rounds between clients (satellites) and the parameter server (PS), leading to substantial delays of up to several days in LEO constellations. In this paper, we propose a novel one-shot FL approach for LEO satellites, called LEOShot, that needs only a single communication round to complete the entire learning process. LEOShot comprises three processes: (i) synthetic data generation, (ii) knowledge distillation, and (iii) virtual model retraining. We evaluate and benchmark LEOShot against the state of the art and the results show that it drastically expedites FL convergence by more than an order of magnitude. Also surprisingly, despite the one-shot nature, its model accuracy is on par with or even outperforms regular iterative FL schemes by a large margin
DisasterNets: Embedding Machine Learning in Disaster Mapping
Jun 16, 2023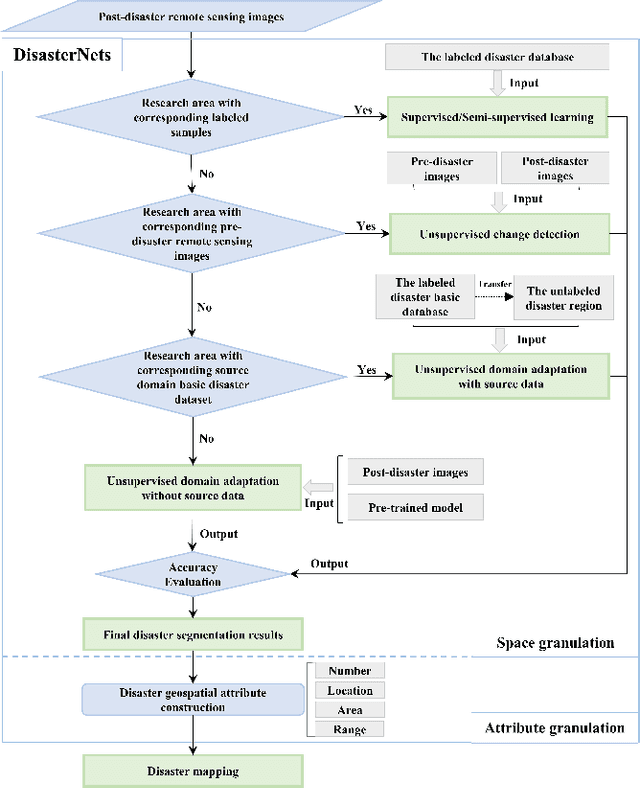
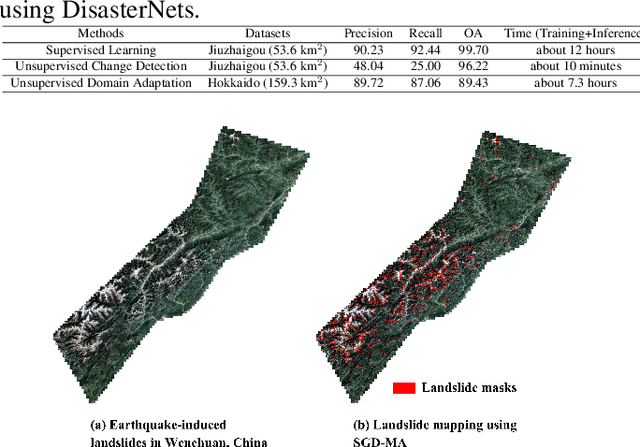
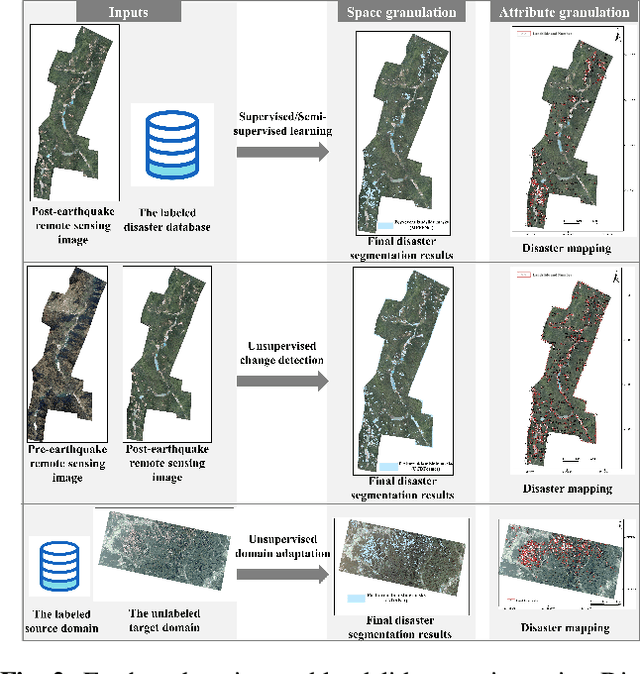

Disaster mapping is a critical task that often requires on-site experts and is time-consuming. To address this, a comprehensive framework is presented for fast and accurate recognition of disasters using machine learning, termed DisasterNets. It consists of two stages, space granulation and attribute granulation. The space granulation stage leverages supervised/semi-supervised learning, unsupervised change detection, and domain adaptation with/without source data techniques to handle different disaster mapping scenarios. Furthermore, the disaster database with the corresponding geographic information field properties is built by using the attribute granulation stage. The framework is applied to earthquake-triggered landslide mapping and large-scale flood mapping. The results demonstrate a competitive performance for high-precision, high-efficiency, and cross-scene recognition of disasters. To bridge the gap between disaster mapping and machine learning communities, we will provide an openly accessible tool based on DisasterNets. The framework and tool will be available at https://github.com/HydroPML/DisasterNets.
Unsupervised Learning of Style-Aware Facial Animation from Real Acting Performances
Jun 16, 2023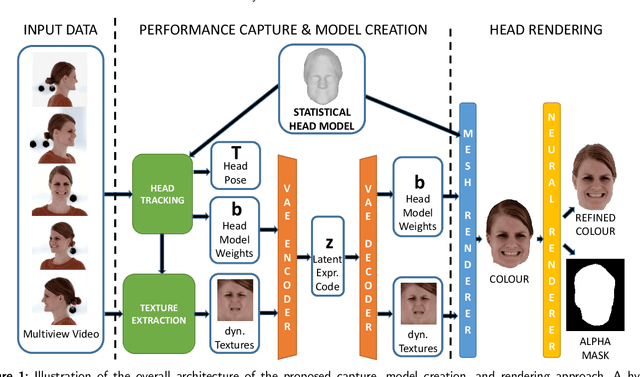
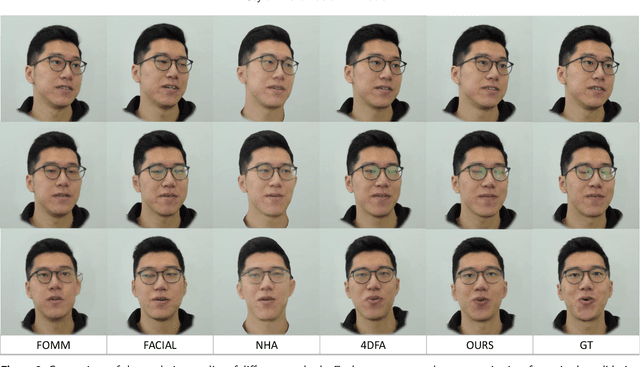


This paper presents a novel approach for text/speech-driven animation of a photo-realistic head model based on blend-shape geometry, dynamic textures, and neural rendering. Training a VAE for geometry and texture yields a parametric model for accurate capturing and realistic synthesis of facial expressions from a latent feature vector. Our animation method is based on a conditional CNN that transforms text or speech into a sequence of animation parameters. In contrast to previous approaches, our animation model learns disentangling/synthesizing different acting-styles in an unsupervised manner, requiring only phonetic labels that describe the content of training sequences. For realistic real-time rendering, we train a U-Net that refines rasterization-based renderings by computing improved pixel colors and a foreground matte. We compare our framework qualitatively/quantitatively against recent methods for head modeling as well as facial animation and evaluate the perceived rendering/animation quality in a user-study, which indicates large improvements compared to state-of-the-art approaches
Low-Resource Text-to-Speech Using Specific Data and Noise Augmentation
Jun 16, 2023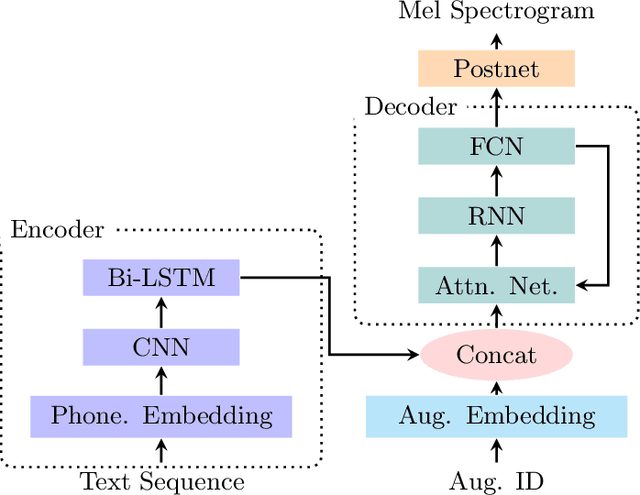
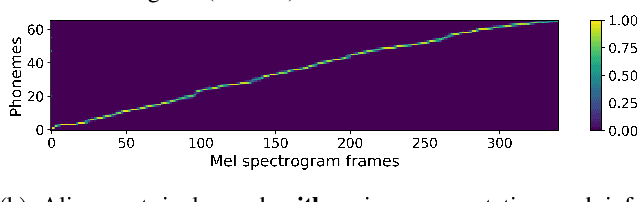
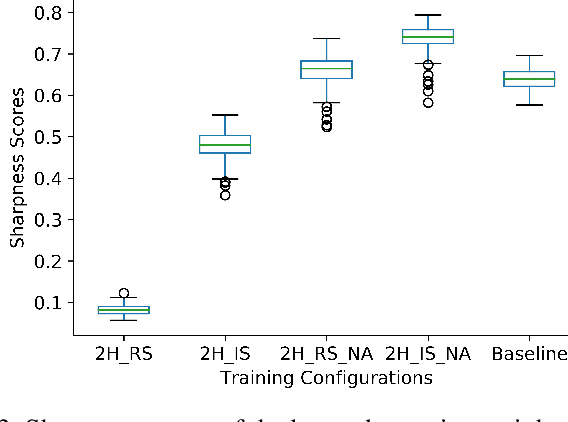
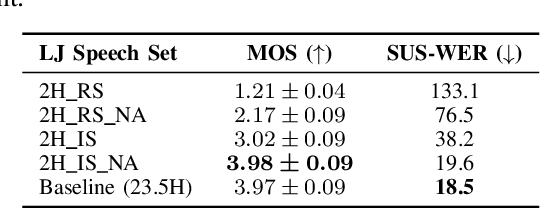
Many neural text-to-speech architectures can synthesize nearly natural speech from text inputs. These architectures must be trained with tens of hours of annotated and high-quality speech data. Compiling such large databases for every new voice requires a lot of time and effort. In this paper, we describe a method to extend the popular Tacotron-2 architecture and its training with data augmentation to enable single-speaker synthesis using a limited amount of specific training data. In contrast to elaborate augmentation methods proposed in the literature, we use simple stationary noises for data augmentation. Our extension is easy to implement and adds almost no computational overhead during training and inference. Using only two hours of training data, our approach was rated by human listeners to be on par with the baseline Tacotron-2 trained with 23.5 hours of LJSpeech data. In addition, we tested our model with a semantically unpredictable sentences test, which showed that both models exhibit similar intelligibility levels.
Cooperative Multi-Objective Reinforcement Learning for Traffic Signal Control and Carbon Emission Reduction
Jun 16, 2023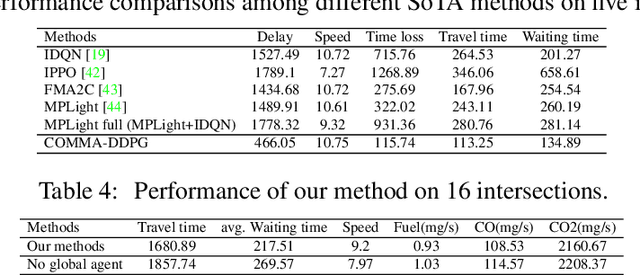
Existing traffic signal control systems rely on oversimplified rule-based methods, and even RL-based methods are often suboptimal and unstable. To address this, we propose a cooperative multi-objective architecture called Multi-Objective Multi-Agent Deep Deterministic Policy Gradient (MOMA-DDPG), which estimates multiple reward terms for traffic signal control optimization using age-decaying weights. Our approach involves two types of agents: one focuses on optimizing local traffic at each intersection, while the other aims to optimize global traffic throughput. We evaluate our method using real-world traffic data collected from an Asian country's traffic cameras. Despite the inclusion of a global agent, our solution remains decentralized as this agent is no longer necessary during the inference stage. Our results demonstrate the effectiveness of MOMA-DDPG, outperforming state-of-the-art methods across all performance metrics. Additionally, our proposed system minimizes both waiting time and carbon emissions. Notably, this paper is the first to link carbon emissions and global agents in traffic signal control.
Enhanced Sampling with Machine Learning: A Review
Jun 16, 2023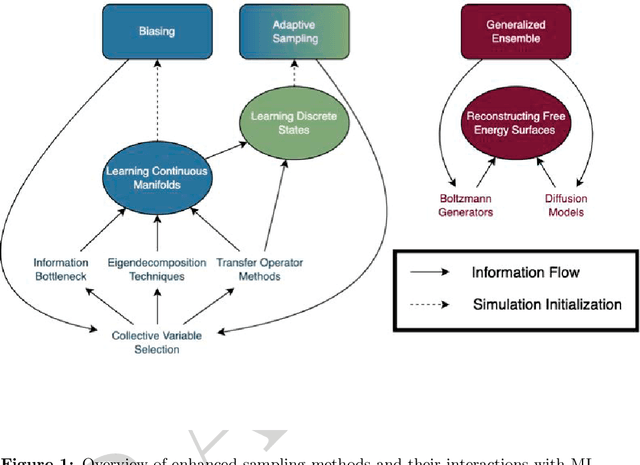
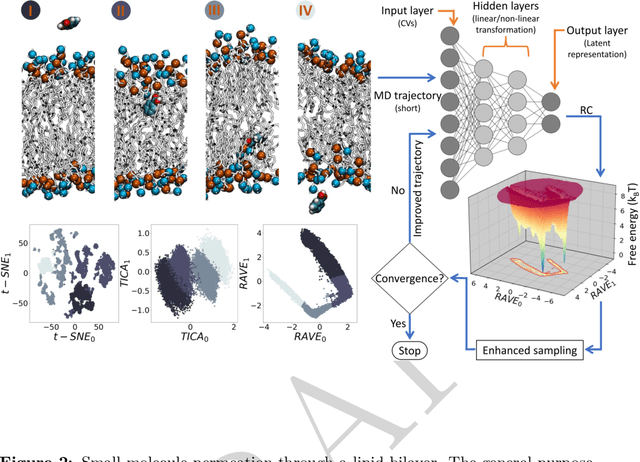
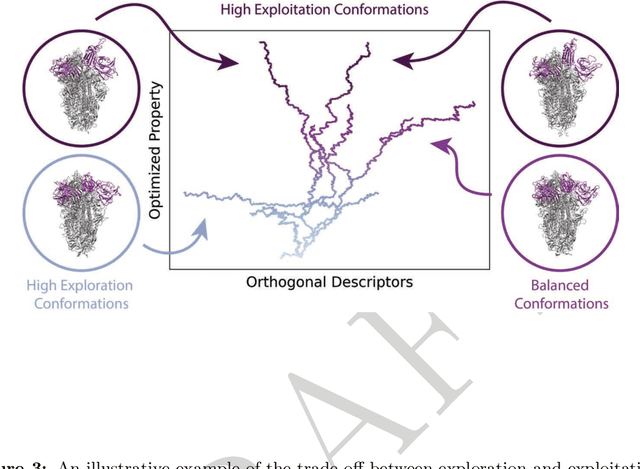
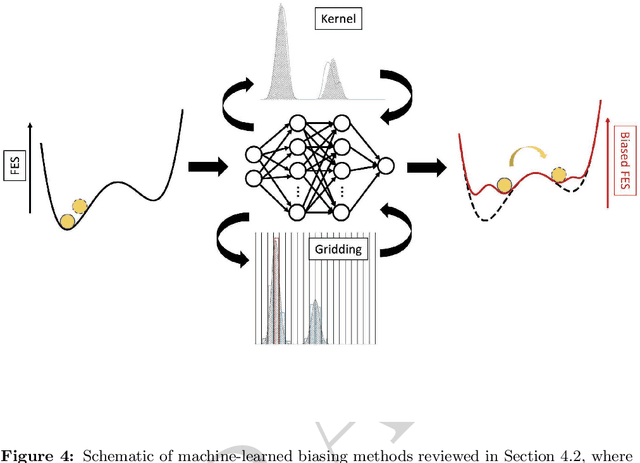
Molecular dynamics (MD) enables the study of physical systems with excellent spatiotemporal resolution but suffers from severe time-scale limitations. To address this, enhanced sampling methods have been developed to improve exploration of configurational space. However, implementing these is challenging and requires domain expertise. In recent years, integration of machine learning (ML) techniques in different domains has shown promise, prompting their adoption in enhanced sampling as well. Although ML is often employed in various fields primarily due to its data-driven nature, its integration with enhanced sampling is more natural with many common underlying synergies. This review explores the merging of ML and enhanced MD by presenting different shared viewpoints. It offers a comprehensive overview of this rapidly evolving field, which can be difficult to stay updated on. We highlight successful strategies like dimensionality reduction, reinforcement learning, and flow-based methods. Finally, we discuss open problems at the exciting ML-enhanced MD interface.
Data-Driven Model Discrimination of Switched Nonlinear Systems with Temporal Logic Inference
Jun 16, 2023
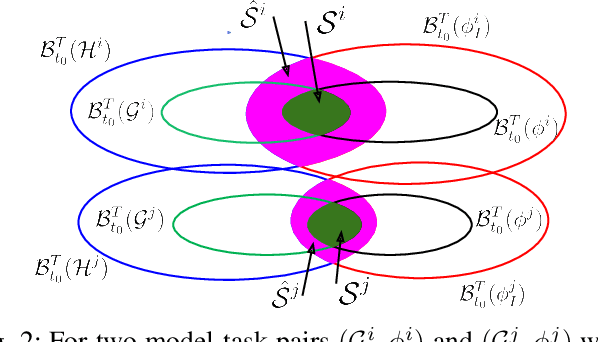
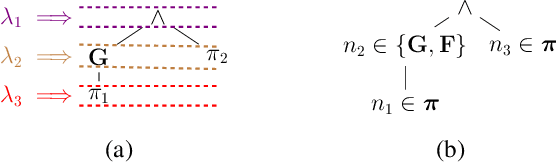
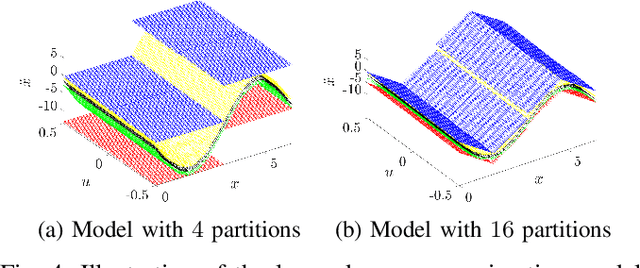
This paper addresses the problem of data-driven model discrimination for unknown switched systems with unknown linear temporal logic (LTL) specifications, representing tasks, that govern their mode sequences, where only sampled data of the unknown dynamics and tasks are available. To tackle this problem, we propose data-driven methods to over-approximate the unknown dynamics and to infer the unknown specifications such that both set-membership models of the unknown dynamics and LTL formulas are guaranteed to include the ground truth model and specification/task. Moreover, we present an optimization-based algorithm for analyzing the distinguishability of a set of learned/inferred model-task pairs as well as a model discrimination algorithm for ruling out model-task pairs from this set that are inconsistent with new observations at run time. Further, we present an approach for reducing the size of inferred specifications to increase the computational efficiency of the model discrimination algorithms.
Quantifying Causes of Arctic Amplification via Deep Learning based Time-series Causal Inference
Mar 14, 2023
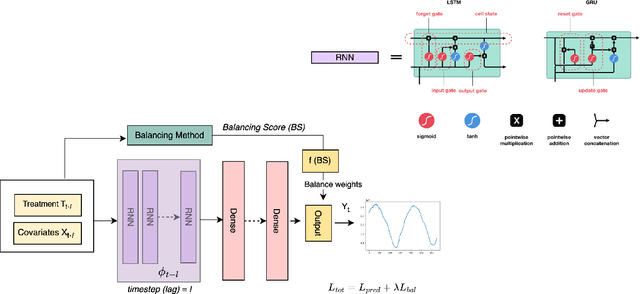

The warming of the Arctic, also known as Arctic amplification, is led by several atmospheric and oceanic drivers, however, the details of its underlying thermodynamic causes are still unknown. Inferring the causal effects of atmospheric processes on sea ice melt using fixed treatment effect strategies leads to unrealistic counterfactual estimations. Such models are also prone to bias due to time-varying confoundedness. In order to tackle these challenges, we propose TCINet - time-series causal inference model to infer causation under continuous treatment using recurrent neural networks. Through experiments on synthetic and observational data, we show how our research can substantially improve the ability to quantify the leading causes of Arctic sea ice melt.
Real-time 3D Semantic Scene Completion Via Feature Aggregation and Conditioned Prediction
Mar 25, 2023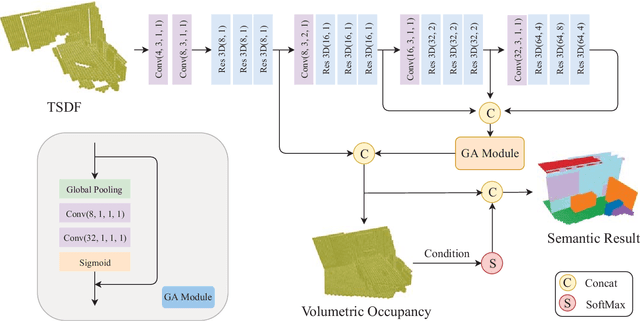

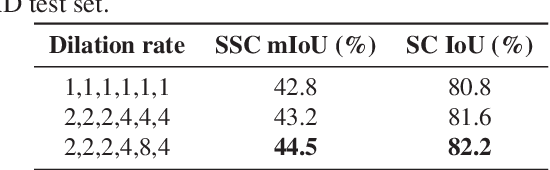
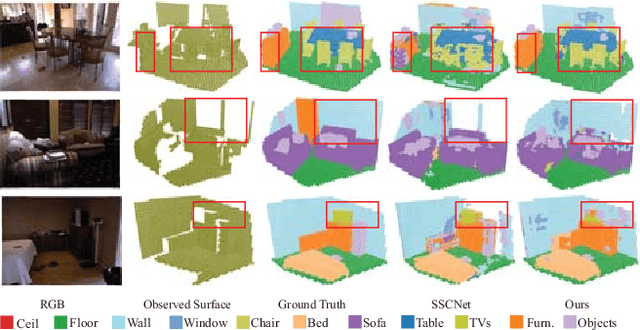
Semantic Scene Completion (SSC) aims to simultaneously predict the volumetric occupancy and semantic category of a 3D scene. In this paper, we propose a real-time semantic scene completion method with a feature aggregation strategy and conditioned prediction module. Feature aggregation fuses feature with different receptive fields and gathers context to improve scene completion performance. And the conditioned prediction module adopts a two-step prediction scheme that takes volumetric occupancy as a condition to enhance semantic completion prediction. We conduct experiments on three recognized benchmarks NYU, NYUCAD, and SUNCG. Our method achieves competitive performance at a speed of 110 FPS on one GTX 1080 Ti GPU.