 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ICDaeLST: Intensity-Controllable Detail Attention-enhanced for Lightweight Fast Style Transfer
Jun 29, 2023

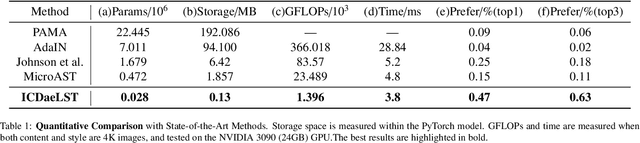


The mainstream style transfer methods usually use pre-trained deep convolutional neural network (VGG) models as encoders, or use more complex model structures to achieve better style transfer effects. This leads to extremely slow processing speeds for practical tasks due to limited resources or higher resolution image processing, such as 4K images, severely hindering the practical application value of style transfer models. We introduce a lightweight and fast styletransfer model with controllable detail attention enhancement, named ICDaeLST. The model adopts a minimal, shallow, and small architecture, forming a very compact lightweight model for efficient forward inference. Although its structure is simple and has limited parameters, we achieve better overall color and texture structure matching by introducing a style discriminator, design additional global semantic invariance loss to preserve the semantic and structural information of the content image from a high-level global perspective, and design a shallow detail attention enhancement module to preserve the detail information of the content image from a low-level detail perspective. We also achieve controllable intensity during inference for the first time (adjusting the degree of detail retention and texture structure transfer based on subjective judgment) to meet different users' subjective evaluation of stylization effects. Compared with the current best-performing and most lightweight models, our model achieves better style transfer quality and better content structure and detail retention, while having a smaller model size (17-250 times smaller) and faster speed (0.26-6.5 times faster), and achieves the fastest processing speed of 0.38s on 4K high-resolution images.
Beamfocusing Optimization for Near-Field Wideband Multi-User Communications
Jun 29, 2023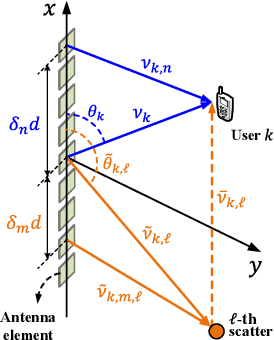
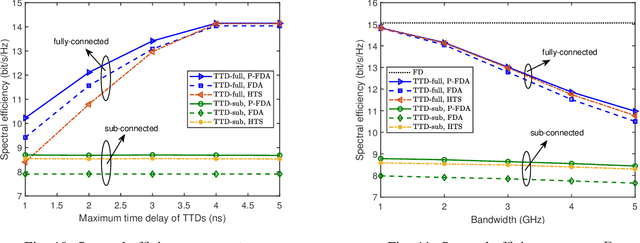
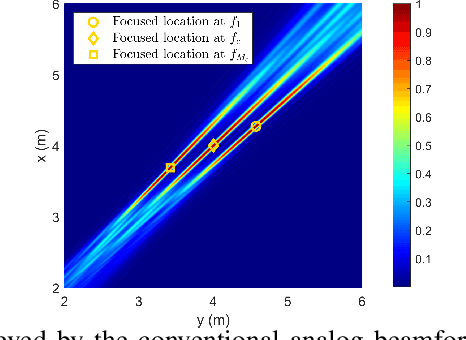
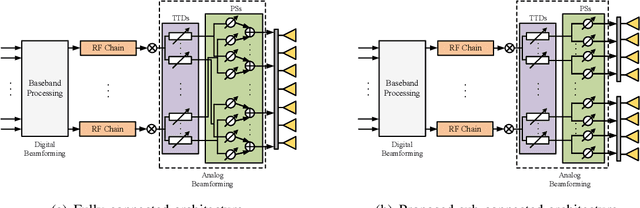
A near-field wideband communication system is studied, wherein a base station (BS) employs an extremely large-scale antenna array (ELAA) to serve multiple users situated within its near-field region. To facilitate the near-field beamfocusing and mitigate the wideband beam split, true-time delayer (TTD)-based hybrid beamforming architectures are employed at the BS. Apart from the fully-connected TTD-based architecture, a new sub-connected TTD-based architecture is proposed for enhancing energy efficiency. Three wideband beamfocusing optimization approaches are proposed to maximize spectral efficiency for both architectures. 1) Fully-digital approximation (FDA) approach: In this approach, the TTD-based hybrid beamformers are optimized to approximate the optimal fully-digital beamformers using block coordinate descent. 2) Penalty-based FDA approach: In this approach, the penalty method is leveraged in the FDA approach to guarantee the convergence to a stationary point of the spectral maximization problem. 3) Heuristic two-stage (HTS) approach: In this approach, the closed-form TTD-based analog beamformers are first designed based on the outcomes of near-field beam training and the piecewise-near-field approximation. Subsequently, the low-dimensional digital beamformer is optimized using knowledge of the low-dimensional equivalent channels, resulting in reduced computational complexity and channel estimation complexity. Our numerical results unveil that 1) the proposed approaches effectively eliminate the near-field beam split effect, and 2) compared to the fully-connected architecture, the proposed sub-connected architecture exhibits higher energy efficiency and imposes fewer hardware limitations on TTDs and system bandwidth.
A General Framework for Uncertainty Quantification via Neural SDE-RNN
Jun 01, 2023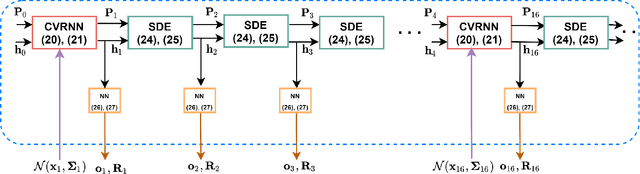
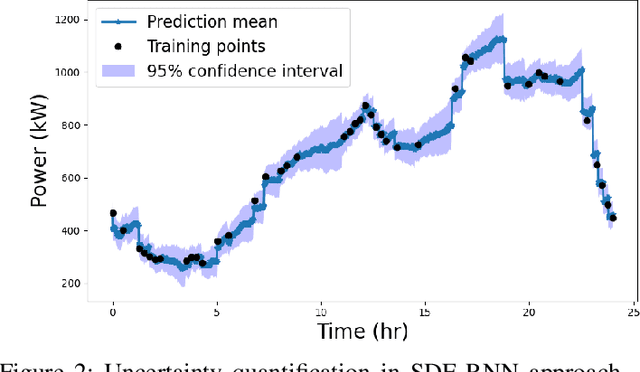
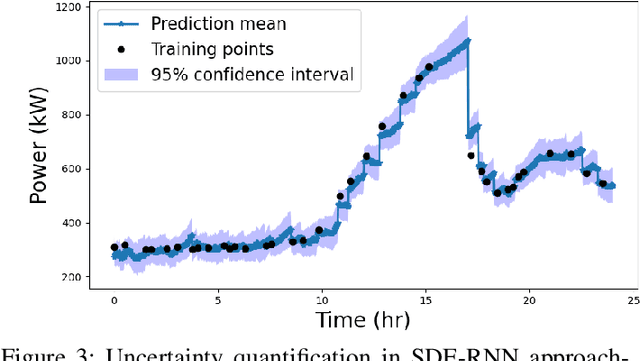
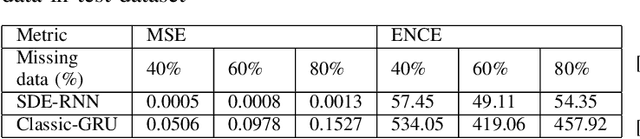
Uncertainty quantification is a critical yet unsolved challenge for deep learning, especially for the time series imputation with irregularly sampled measurements. To tackle this problem, we propose a novel framework based on the principles of recurrent neural networks and neural stochastic differential equations for reconciling irregularly sampled measurements. We impute measurements at any arbitrary timescale and quantify the uncertainty in the imputations in a principled manner. Specifically, we derive analytical expressions for quantifying and propagating the epistemic and aleatoric uncertainty across time instants. Our experiments on the IEEE 37 bus test distribution system reveal that our framework can outperform state-of-the-art uncertainty quantification approaches for time-series data imputations.
Online Self-Supervised Learning in Machine Learning Intrusion Detection for the Internet of Things
Jun 22, 2023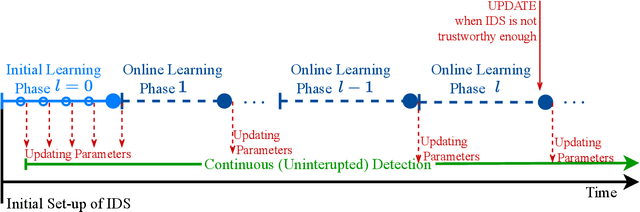

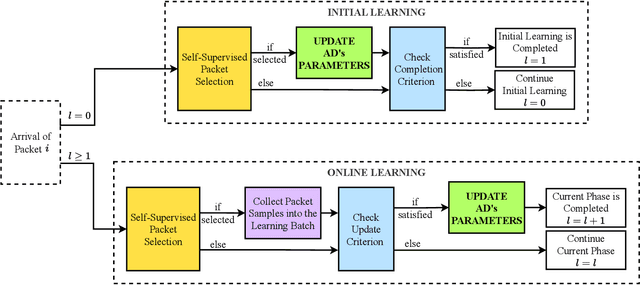
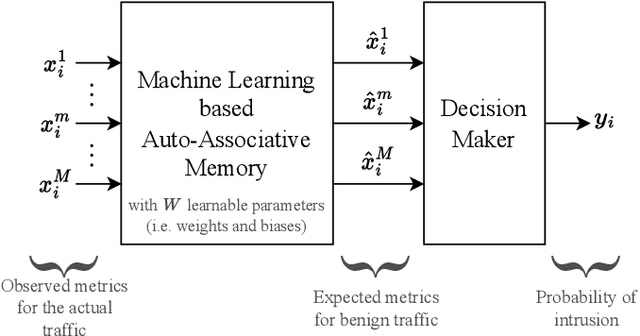
This paper proposes a novel Self-Supervised Intrusion Detection (SSID) framework, which enables a fully online Machine Learning (ML) based Intrusion Detection System (IDS) that requires no human intervention or prior off-line learning. The proposed framework analyzes and labels incoming traffic packets based only on the decisions of the IDS itself using an Auto-Associative Deep Random Neural Network, and on an online estimate of its statistically measured trustworthiness. The SSID framework enables IDS to adapt rapidly to time-varying characteristics of the network traffic, and eliminates the need for offline data collection. This approach avoids human errors in data labeling, and human labor and computational costs of model training and data collection. The approach is experimentally evaluated on public datasets and compared with well-known ML models, showing that this SSID framework is very useful and advantageous as an accurate and online learning ML-based IDS for IoT systems.
Sum-Rate Maximization of RSMA-based Aerial Communications with Energy Harvesting: A Reinforcement Learning Approach
Jun 22, 2023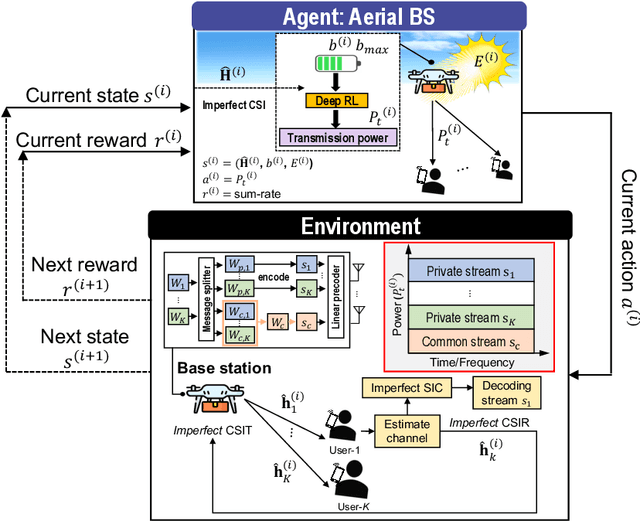
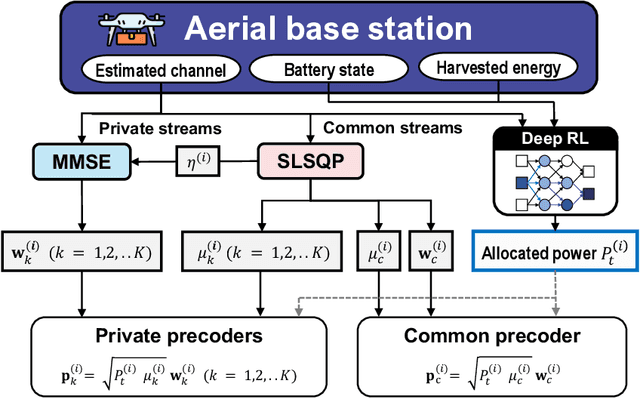
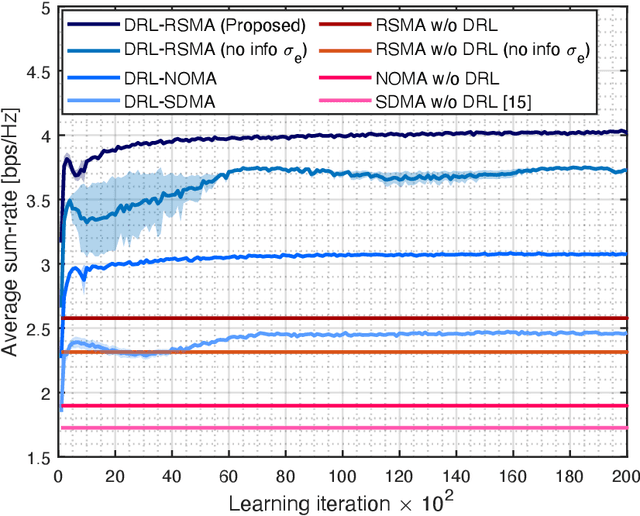
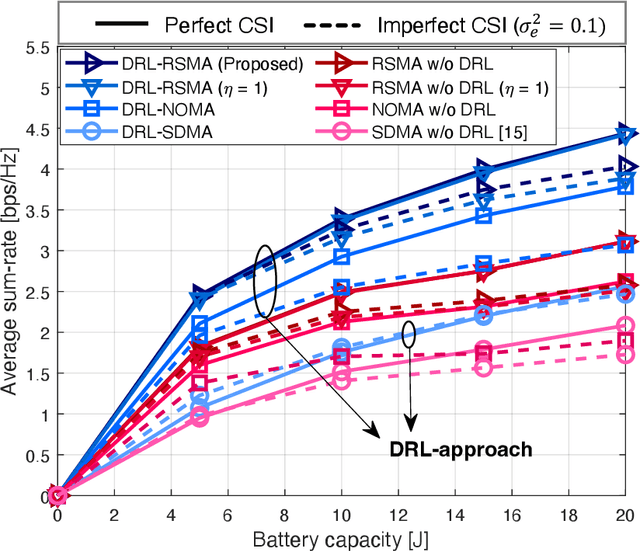
In this letter, we investigate a joint power and beamforming design problem for rate-splitting multiple access (RSMA)-based aerial communications with energy harvesting, where a self-sustainable aerial base station serves multiple users by utilizing the harvested energy. Considering maximizing the sum-rate from the long-term perspective, we utilize a deep reinforcement learning (DRL) approach, namely the soft actor-critic algorithm, to restrict the maximum transmission power at each time based on the stochastic property of the channel environment, harvested energy, and battery power information. Moreover, for designing precoders and power allocation among all the private/common streams of the RSMA, we employ sequential least squares programming (SLSQP) using the Han-Powell quasi-Newton method to maximize the sum-rate for the given transmission power via DRL. Numerical results show the superiority of the proposed scheme over several baseline methods in terms of the average sum-rate performance.
Inferring networks from time series: a neural approach
Mar 30, 2023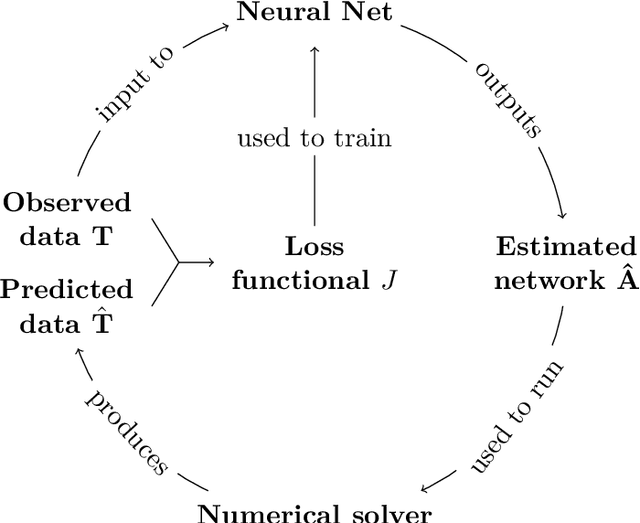
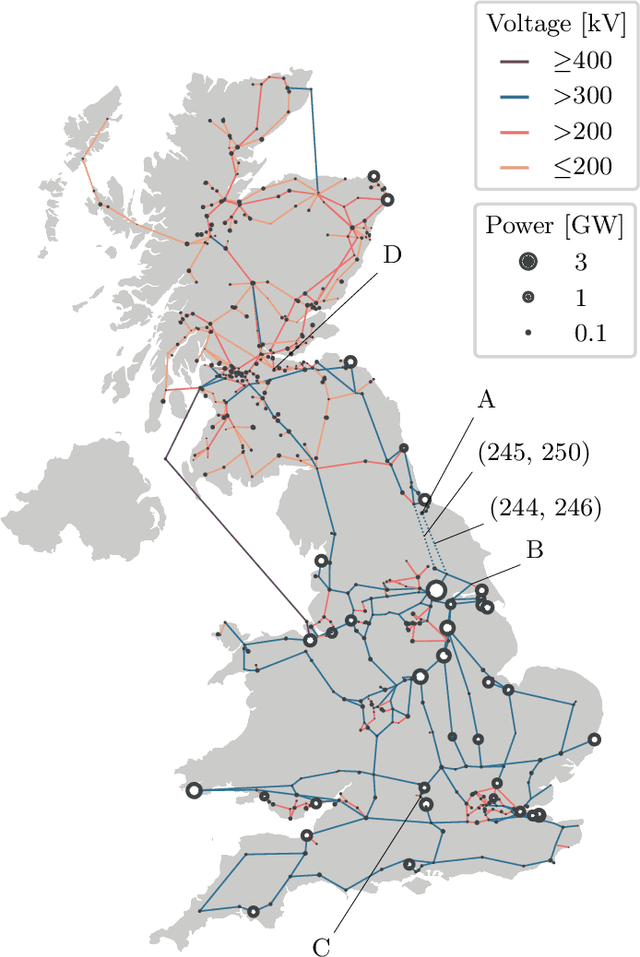
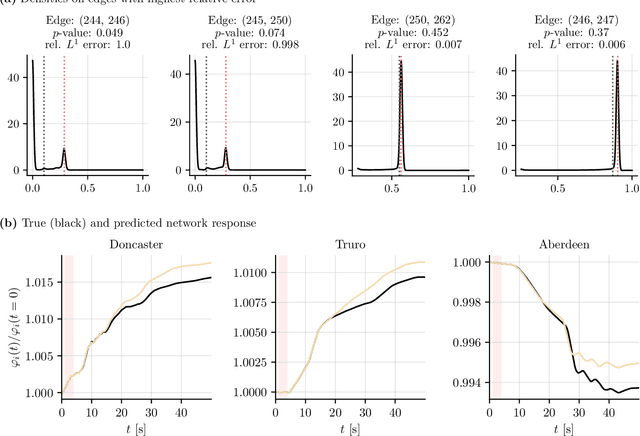
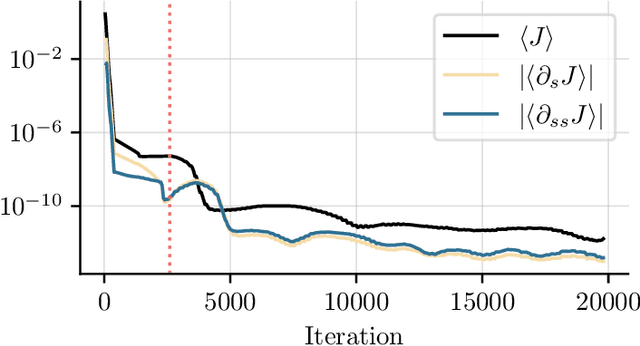
Network structures underlie the dynamics of many complex phenomena, from gene regulation and foodwebs to power grids and social media. Yet, as they often cannot be observed directly, their connectivities must be inferred from observations of their emergent dynamics. In this work we present a powerful and fast computational method to infer large network adjacency matrices from time series data using a neural network. Using a neural network provides uncertainty quantification on the prediction in a manner that reflects both the non-convexity of the inference problem as well as the noise on the data. This is useful since network inference problems are typically underdetermined, and a feature that has hitherto been lacking from network inference methods. We demonstrate our method's capabilities by inferring line failure locations in the British power grid from observations of its response to a power cut. Since the problem is underdetermined, many classical statistical tools (e.g. regression) will not be straightforwardly applicable. Our method, in contrast, provides probability densities on each edge, allowing the use of hypothesis testing to make meaningful probabilistic statements about the location of the power cut. We also demonstrate our method's ability to learn an entire cost matrix for a non-linear model from a dataset of economic activity in Greater London. Our method outperforms OLS regression on noisy data in terms of both speed and prediction accuracy, and scales as $N^2$ where OLS is cubic. Since our technique is not specifically engineered for network inference, it represents a general parameter estimation scheme that is applicable to any parameter dimension.
More efficient manual review of automatically transcribed tabular data
Jun 28, 2023
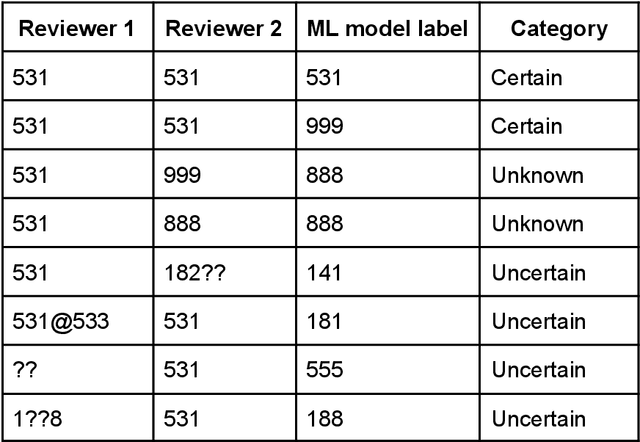
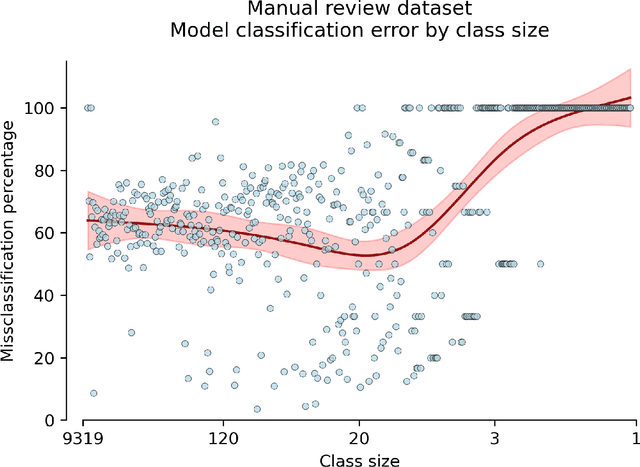
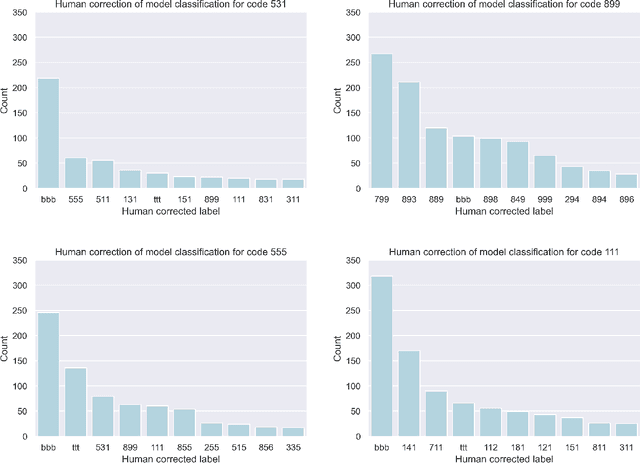
Machine learning methods have proven useful in transcribing historical data. However, results from even highly accurate methods require manual verification and correction. Such manual review can be time-consuming and expensive, therefore the objective of this paper was to make it more efficient. Previously, we used machine learning to transcribe 2.3 million handwritten occupation codes from the Norwegian 1950 census with high accuracy (97%). We manually reviewed the 90,000 (3%) codes with the lowest model confidence. We allocated those 90,000 codes to human reviewers, who used our annotation tool to review the codes. To assess reviewer agreement, some codes were assigned to multiple reviewers. We then analyzed the review results to understand the relationship between accuracy improvements and effort. Additionally, we interviewed the reviewers to improve the workflow. The reviewers corrected 62.8% of the labels and agreed with the model label in 31.9% of cases. About 0.2% of the images could not be assigned a label, while for 5.1% the reviewers were uncertain, or they assigned an invalid label. 9,000 images were independently reviewed by multiple reviewers, resulting in an agreement of 86.43% and disagreement of 8.96%. We learned that our automatic transcription is biased towards the most frequent codes, with a higher degree of misclassification for the lowest frequency codes. Our interview findings show that the reviewers did internal quality control and found our custom tool well-suited. So, only one reviewer is needed, but they should report uncertainty.
Fast Recognition of birds in offshore wind farms based on an improved deep learning model
Jun 28, 2023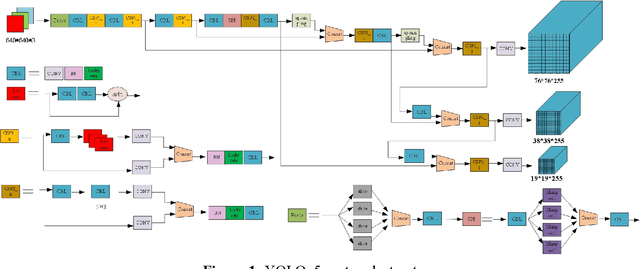
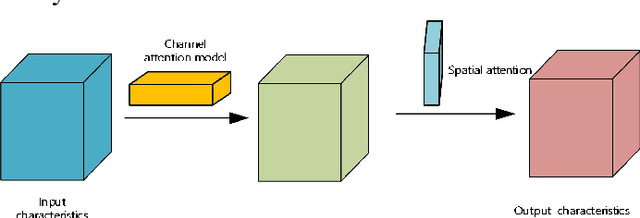

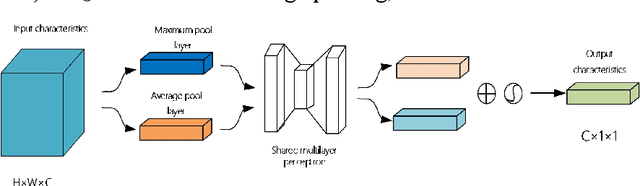
The safety of wind turbines is a prerequisite for the stable operation of offshore wind farms. However, bird damage poses a direct threat to the safe operation of wind turbines and wind turbine blades. In addition, millions of birds are killed by wind turbines every year. In order to protect the ecological environment and maintain the safe operation of offshore wind turbines, and to address the problem of the low detection capability of current target detection algorithms in low-light environments such as at night, this paper proposes a method to improve the network performance by integrating the CBAM attention mechanism and the RetinexNet network into YOLOv5. First, the training set images are fed into the YOLOv5 network with integrated CBAM attention module for training, and the optimal weight model is stored. Then, low-light images are enhanced and denoised using Decom-Net and Enhance-Net, and the accuracy is tested on the optimal weight model. In addition, the k-means++ clustering algorithm is used to optimise the anchor box selection method, which solves the problem of unstable initial centroids and achieves better clustering results. Experimental results show that the accuracy of this model in bird detection tasks can reach 87.40%, an increase of 21.25%. The model can detect birds near wind turbines in real time and shows strong stability in night, rainy and shaky conditions, proving that the model can ensure the safe and stable operation of wind turbines.
Real-World Performance of Autonomously Reporting Normal Chest Radiographs in NHS Trusts Using a Deep-Learning Algorithm on the GP Pathway
Jun 28, 2023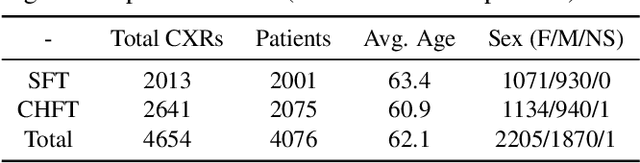
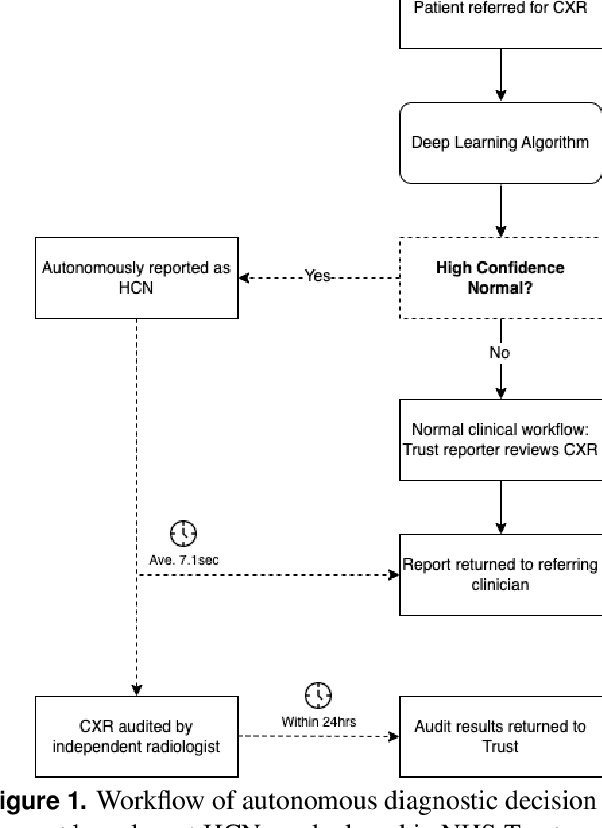
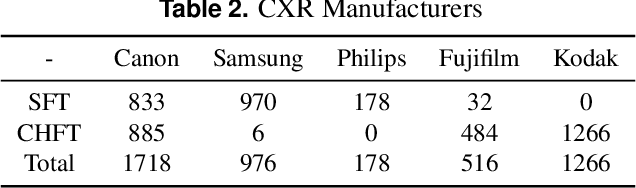
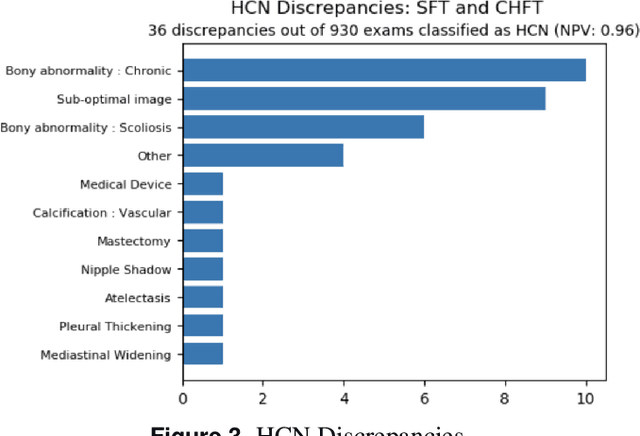
AIM To analyse the performance of a deep-learning (DL) algorithm currently deployed as diagnostic decision support software in two NHS Trusts used to identify normal chest x-rays in active clinical pathways. MATERIALS AND METHODS A DL algorithm has been deployed in Somerset NHS Foundation Trust (SFT) since December 2022, and at Calderdale & Huddersfield NHS Foundation Trust (CHFT) since March 2023. The algorithm was developed and trained prior to deployment, and is used to assign abnormality scores to each GP-requested chest x-ray (CXR). The algorithm classifies a subset of examinations with the lowest abnormality scores as High Confidence Normal (HCN), and displays this result to the Trust. This two-site study includes 4,654 CXR continuous examinations processed by the algorithm over a six-week period. RESULTS When classifying 20.0% of assessed examinations (930) as HCN, the model classified exams with a negative predictive value (NPV) of 0.96. There were 0.77% of examinations (36) classified incorrectly as HCN, with none of the abnormalities considered clinically significant by auditing radiologists. The DL software maintained fast levels of service to clinicians, with results returned to Trusts in a mean time of 7.1 seconds. CONCLUSION The DL algorithm performs with a low rate of error and is highly effective as an automated diagnostic decision support tool, used to autonomously report a subset of CXRs as normal with high confidence. Removing 20% of all CXRs reduces workload for reporters and allows radiology departments to focus resources elsewhere.
Separable Physics-Informed Neural Networks
Jun 28, 2023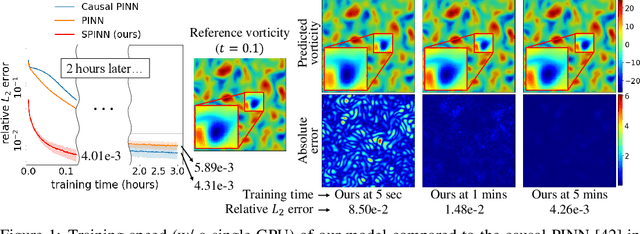

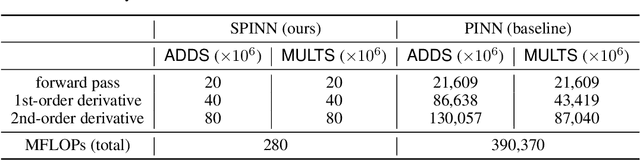
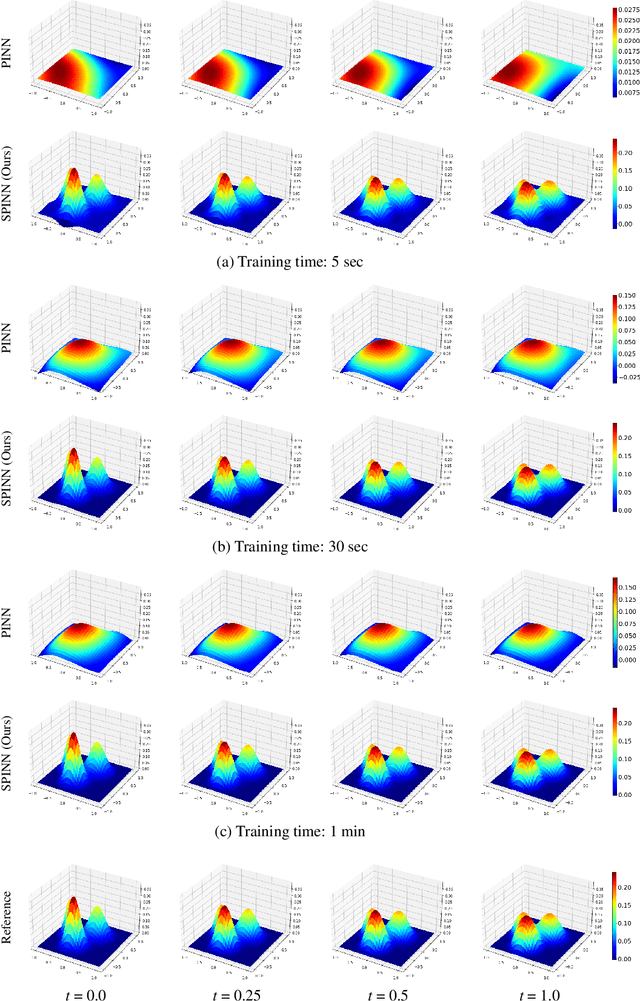
Physics-informed neural networks (PINNs) have recently emerged as promising data-driven PDE solvers showing encouraging results on various PDEs. However, there is a fundamental limitation of training PINNs to solve multi-dimensional PDEs and approximate highly complex solution functions. The number of training points (collocation points) required on these challenging PDEs grows substantially, but it is severely limited due to the expensive computational costs and heavy memory overhead. To overcome this issue, we propose a network architecture and training algorithm for PINNs. The proposed method, separable PINN (SPINN), operates on a per-axis basis to significantly reduce the number of network propagations in multi-dimensional PDEs unlike point-wise processing in conventional PINNs. We also propose using forward-mode automatic differentiation to reduce the computational cost of computing PDE residuals, enabling a large number of collocation points (>10^7) on a single commodity GPU. The experimental results show drastically reduced computational costs (62x in wall-clock time, 1,394x in FLOPs given the same number of collocation points) in multi-dimensional PDEs while achieving better accuracy. Furthermore, we present that SPINN can solve a chaotic (2+1)-d Navier-Stokes equation significantly faster than the best-performing prior method (9 minutes vs 10 hours in a single GPU), maintaining accuracy. Finally, we showcase that SPINN can accurately obtain the solution of a highly nonlinear and multi-dimensional PDE, a (3+1)-d Navier-Stokes equation.