 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Algorithms of Sampling-Frequency-Independent Layers for Non-integer Strides
Jun 19, 2023

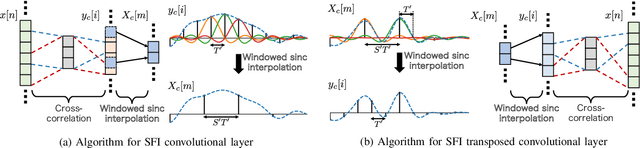
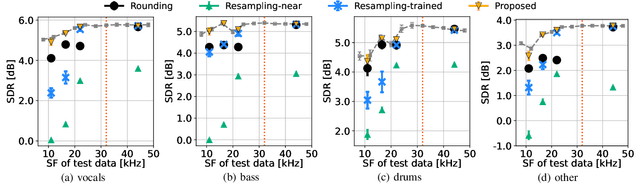

In this paper, we propose algorithms for handling non-integer strides in sampling-frequency-independent (SFI) convolutional and transposed convolutional layers. The SFI layers have been developed for handling various sampling frequencies (SFs) by a single neural network. They are replaceable with their non-SFI counterparts and can be introduced into various network architectures. However, they could not handle some specific configurations when combined with non-SFI layers. For example, an SFI extension of Conv-TasNet, a standard audio source separation model, cannot handle some pairs of trained and target SFs because the strides of the SFI layers become non-integers. This problem cannot be solved by simple rounding or signal resampling, resulting in the significant performance degradation. To overcome this problem, we propose algorithms for handling non-integer strides by using windowed sinc interpolation. The proposed algorithms realize the continuous-time representations of features using the interpolation and enable us to sample instants with the desired stride. Experimental results on music source separation showed that the proposed algorithms outperformed the rounding- and signal-resampling-based methods at SFs lower than the trained SF.
Cases of EFL Secondary Students' Prompt Engineering Pathways to Complete a Writing Task with ChatGPT
Jun 19, 2023ChatGPT is a state-of-the-art (SOTA) chatbot. Although it has potential to support English as a foreign language (EFL) students' writing, to effectively collaborate with it, a student must learn to engineer prompts, that is, the skill of crafting appropriate instructions so that ChatGPT produces desired outputs. However, writing an appropriate prompt for ChatGPT is not straightforward for non-technical users who suffer a trial-and-error process. This paper examines the content of EFL students' ChatGPT prompts when completing a writing task and explores patterns in the quality and quantity of the prompts. The data come from iPad screen recordings of secondary school EFL students who used ChatGPT and other SOTA chatbots for the first time to complete the same writing task. The paper presents a case study of four distinct pathways that illustrate the trial-and-error process and show different combinations of prompt content and quantity. The cases contribute evidence for the need to provide prompt engineering education in the context of the EFL writing classroom, if students are to move beyond an individual trial-and-error process, learning a greater variety of prompt content and more sophisticated prompts to support their writing.
Vocal Timbre Effects with Differentiable Digital Signal Processing
Jun 19, 2023We explore two approaches to creatively altering vocal timbre using Differentiable Digital Signal Processing (DDSP). The first approach is inspired by classic cross-synthesis techniques. A pretrained DDSP decoder predicts a filter for a noise source and a harmonic distribution, based on pitch and loudness information extracted from the vocal input. Before synthesis, the harmonic distribution is modified by interpolating between the predicted distribution and the harmonics of the input. We provide a real-time implementation of this approach in the form of a Neutone model. In the second approach, autoencoder models are trained on datasets consisting of both vocal and instrument training data. To apply the effect, the trained autoencoder attempts to reconstruct the vocal input. We find that there is a desirable "sweet spot" during training, where the model has learned to reconstruct the phonetic content of the input vocals, but is still affected by the timbre of the instrument mixed into the training data. After further training, that effect disappears. A perceptual evaluation compares the two approaches. We find that the autoencoder in the second approach is able to reconstruct intelligible lyrical content without any explicit phonetic information provided during training.
Machine learning of hidden variables in multiscale fluid simulation
Jun 19, 2023Solving fluid dynamics equations often requires the use of closure relations that account for missing microphysics. For example, when solving equations related to fluid dynamics for systems with a large Reynolds number, sub-grid effects become important and a turbulence closure is required, and in systems with a large Knudsen number, kinetic effects become important and a kinetic closure is required. By adding an equation governing the growth and transport of the quantity requiring the closure relation, it becomes possible to capture microphysics through the introduction of ``hidden variables'' that are non-local in space and time. The behavior of the ``hidden variables'' in response to the fluid conditions can be learned from a higher fidelity or ab-initio model that contains all the microphysics. In our study, a partial differential equation simulator that is end-to-end differentiable is used to train judiciously placed neural networks against ground-truth simulations. We show that this method enables an Euler equation based approach to reproduce non-linear, large Knudsen number plasma physics that can otherwise only be modeled using Boltzmann-like equation simulators such as Vlasov or Particle-In-Cell modeling.
Black-Box Prediction of Flaky Test Fix Categories Using Language Models
Jun 21, 2023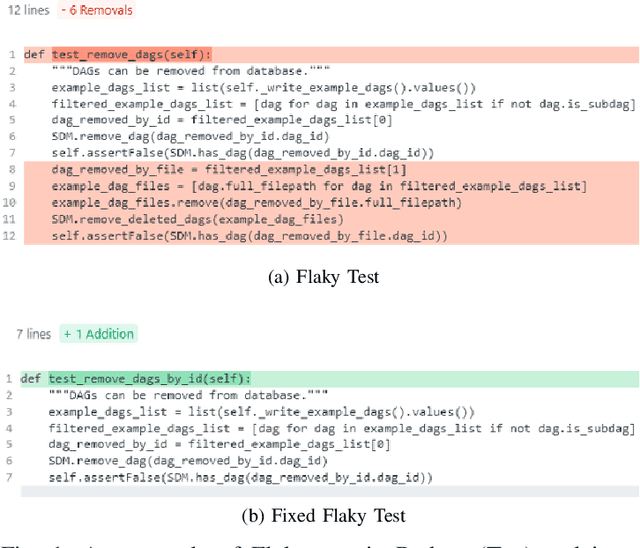
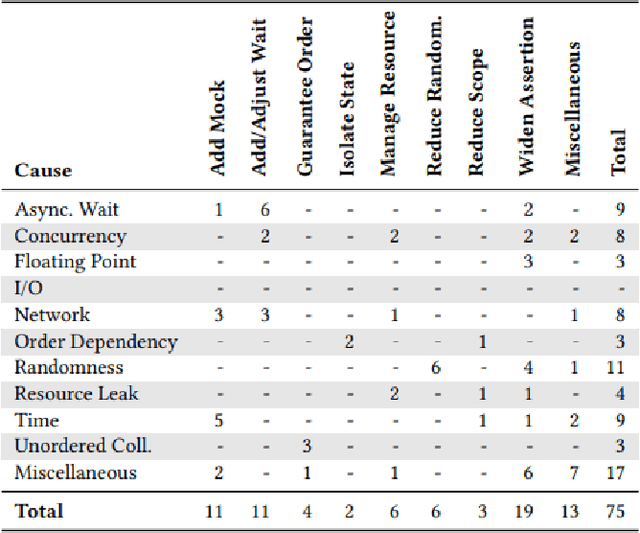


Flaky tests are problematic because they non-deterministically pass or fail for the same software version under test, causing confusion and wasting developer time. While machine learning models have been used to predict flakiness and its root causes, there is less work on providing support to fix the problem. To address this gap, we propose a framework that automatically generates labeled datasets for 13 fix categories and train models to predict the fix category of a flaky test by analyzing the test code only. Though it is unrealistic at this stage to accurately predict the fix itself, the categories provide precise guidance about what part of the test code to look at. Our approach is based on language models, namely CodeBERT and UniXcoder, whose output is fine-tuned with a Feed Forward Neural Network (FNN) or a Siamese Network-based Few Shot Learning (FSL). Our experimental results show that UniXcoder outperforms CodeBERT, in correctly predicting most of the categories of fixes a developer should apply. Furthermore, FSL does not appear to have any significant effect. Given the high accuracy obtained for most fix categories, our proposed framework has the potential to help developers to fix flaky tests quickly and accurately.To aid future research, we make our automated labeling tool, dataset, prediction models, and experimental infrastructure publicly available.
STAN: Stage-Adaptive Network for Multi-Task Recommendation by Learning User Lifecycle-Based Representation
Jun 21, 2023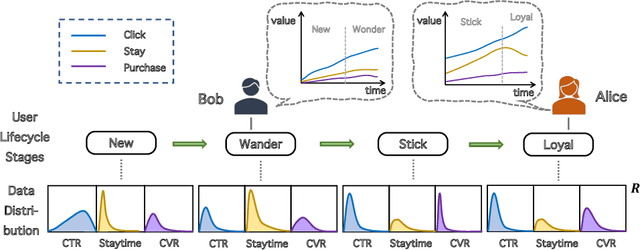
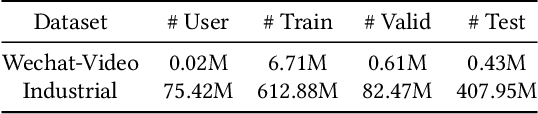
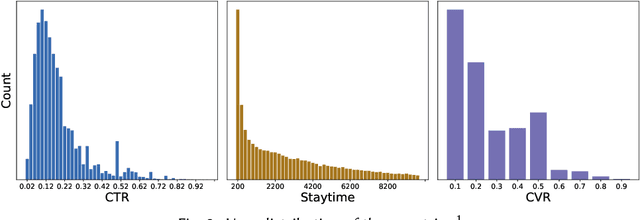
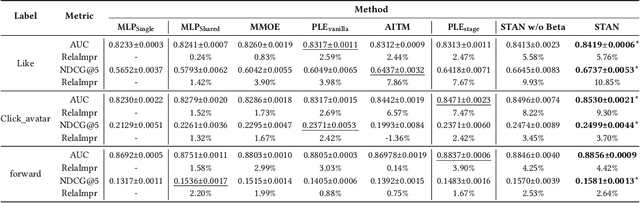
Recommendation systems play a vital role in many online platforms, with their primary objective being to satisfy and retain users. As directly optimizing user retention is challenging, multiple evaluation metrics are often employed. Existing methods generally formulate the optimization of these evaluation metrics as a multitask learning problem, but often overlook the fact that user preferences for different tasks are personalized and change over time. Identifying and tracking the evolution of user preferences can lead to better user retention. To address this issue, we introduce the concept of "user lifecycle", consisting of multiple stages characterized by users' varying preferences for different tasks. We propose a novel Stage-Adaptive Network (STAN) framework for modeling user lifecycle stages. STAN first identifies latent user lifecycle stages based on learned user preferences, and then employs the stage representation to enhance multi-task learning performance. Our experimental results using both public and industrial datasets demonstrate that the proposed model significantly improves multi-task prediction performance compared to state-of-the-art methods, highlighting the importance of considering user lifecycle stages in recommendation systems. Furthermore, online A/B testing reveals that our model outperforms the existing model, achieving a significant improvement of 3.05% in staytime per user and 0.88% in CVR. These results indicate that our approach effectively improves the overall efficiency of the multi-task recommendation system.
Encoding Enhanced Complex CNN for Accurate and Highly Accelerated MRI
Jun 21, 2023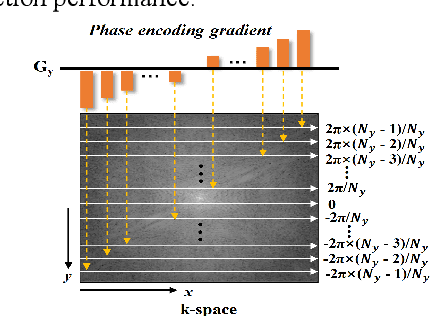
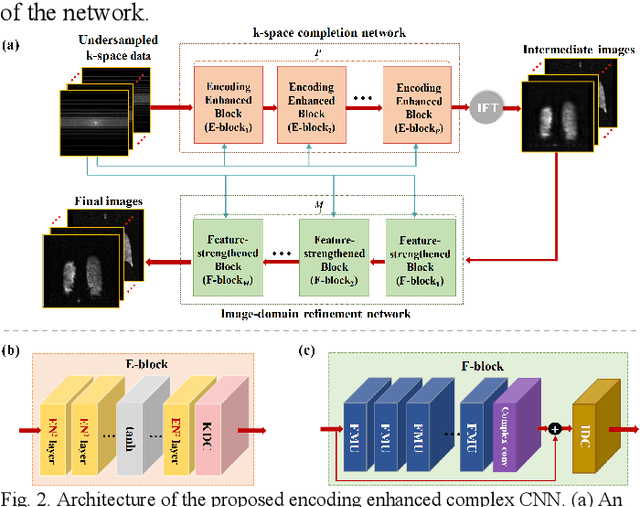
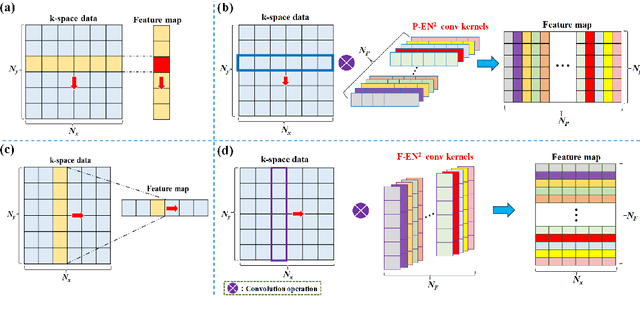
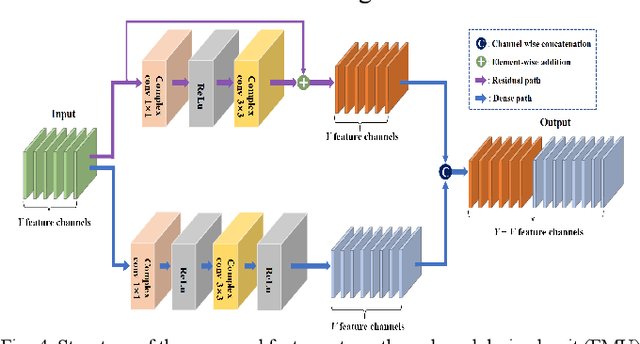
Magnetic resonance imaging (MRI) using hyperpolarized noble gases provides a way to visualize the structure and function of human lung, but the long imaging time limits its broad research and clinical applications. Deep learning has demonstrated great potential for accelerating MRI by reconstructing images from undersampled data. However, most existing deep conventional neural networks (CNN) directly apply square convolution to k-space data without considering the inherent properties of k-space sampling, limiting k-space learning efficiency and image reconstruction quality. In this work, we propose an encoding enhanced (EN2) complex CNN for highly undersampled pulmonary MRI reconstruction. EN2 employs convolution along either the frequency or phase-encoding direction, resembling the mechanisms of k-space sampling, to maximize the utilization of the encoding correlation and integrity within a row or column of k-space. We also employ complex convolution to learn rich representations from the complex k-space data. In addition, we develop a feature-strengthened modularized unit to further boost the reconstruction performance. Experiments demonstrate that our approach can accurately reconstruct hyperpolarized 129Xe and 1H lung MRI from 6-fold undersampled k-space data and provide lung function measurements with minimal biases compared with fully-sampled image. These results demonstrate the effectiveness of the proposed algorithmic components and indicate that the proposed approach could be used for accelerated pulmonary MRI in research and clinical lung disease patient care.
Retrieval-Based Transformer for Table Augmentation
Jun 20, 2023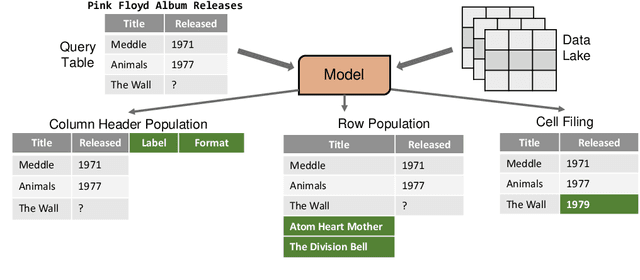
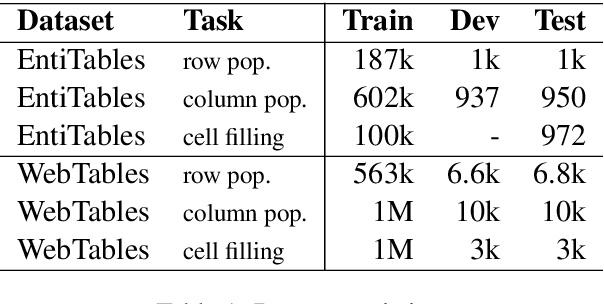
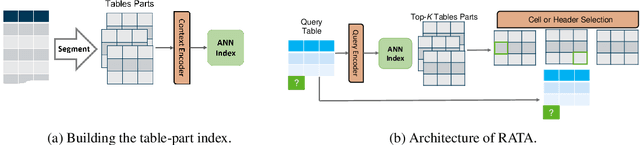
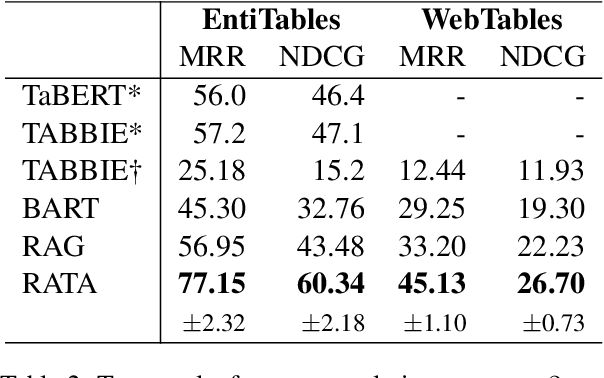
Data preparation, also called data wrangling, is considered one of the most expensive and time-consuming steps when performing analytics or building machine learning models. Preparing data typically involves collecting and merging data from complex heterogeneous, and often large-scale data sources, such as data lakes. In this paper, we introduce a novel approach toward automatic data wrangling in an attempt to alleviate the effort of end-users, e.g. data analysts, in structuring dynamic views from data lakes in the form of tabular data. We aim to address table augmentation tasks, including row/column population and data imputation. Given a corpus of tables, we propose a retrieval augmented self-trained transformer model. Our self-learning strategy consists in randomly ablating tables from the corpus and training the retrieval-based model to reconstruct the original values or headers given the partial tables as input. We adopt this strategy to first train the dense neural retrieval model encoding table-parts to vectors, and then the end-to-end model trained to perform table augmentation tasks. We test on EntiTables, the standard benchmark for table augmentation, as well as introduce a new benchmark to advance further research: WebTables. Our model consistently and substantially outperforms both supervised statistical methods and the current state-of-the-art transformer-based models.
Spatio-temporal DeepKriging for Interpolation and Probabilistic Forecasting
Jun 20, 2023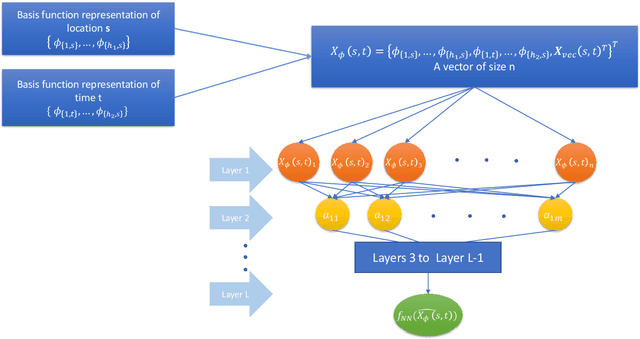

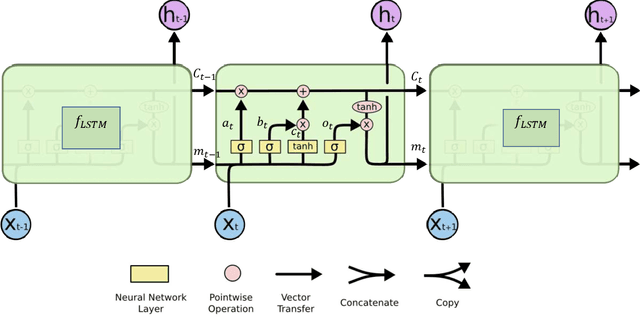
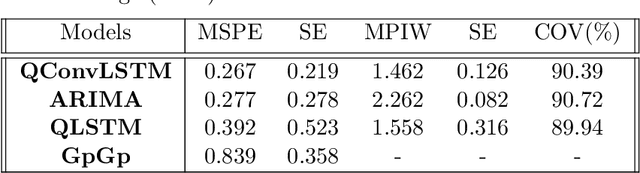
Gaussian processes (GP) and Kriging are widely used in traditional spatio-temporal mod-elling and prediction. These techniques typically presuppose that the data are observed from a stationary GP with parametric covariance structure. However, processes in real-world applications often exhibit non-Gaussianity and nonstationarity. Moreover, likelihood-based inference for GPs is computationally expensive and thus prohibitive for large datasets. In this paper we propose a deep neural network (DNN) based two-stage model for spatio-temporal interpolation and forecasting. Interpolation is performed in the first step, which utilizes a dependent DNN with the embedding layer constructed with spatio-temporal basis functions. For the second stage, we use Long-Short Term Memory (LSTM) and convolutional LSTM to forecast future observations at a given location. We adopt the quantile-based loss function in the DNN to provide probabilistic forecasting. Compared to Kriging, the proposed method does not require specifying covariance functions or making stationarity assumption, and is computationally efficient. Therefore, it is suitable for large-scale prediction of complex spatio-temporal processes. We apply our method to monthly $PM_{2.5}$ data at more than $200,000$ space-time locations from January 1999 to December 2022 for fast imputation of missing values and forecasts with uncertainties.
Radar Sensing via OTFS Signaling
Jun 20, 2023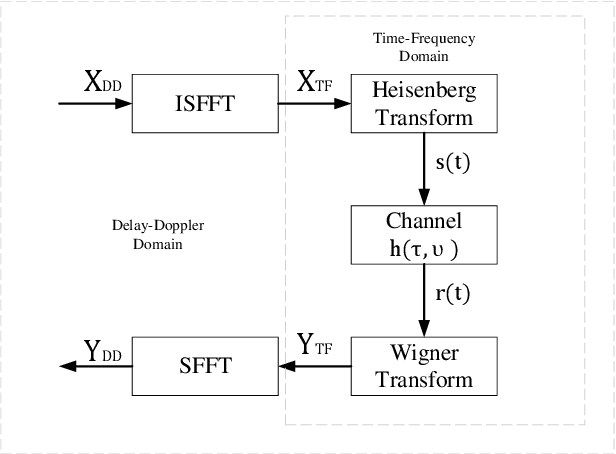
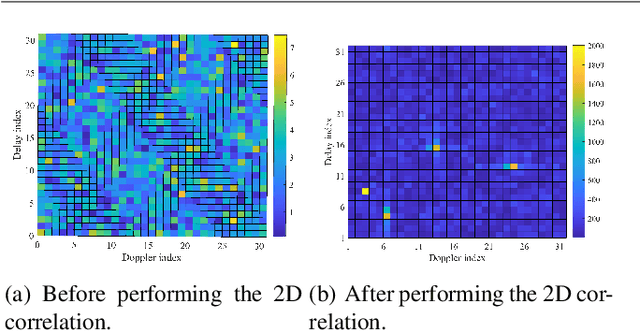
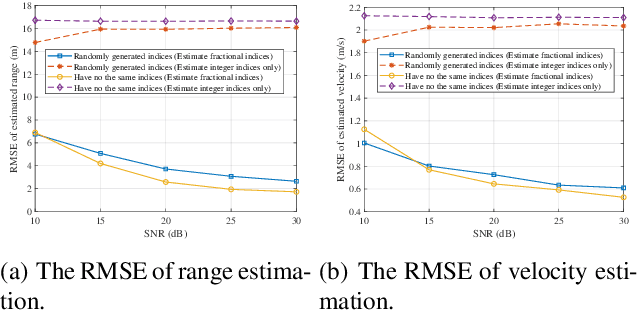
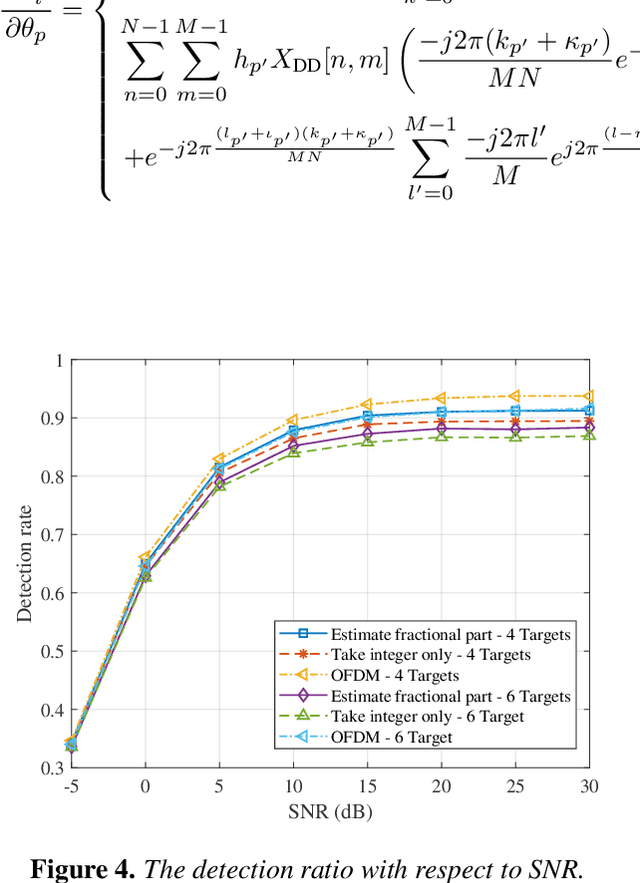
By multiplexing information symbols in the delay-Doppler (DD) domain, orthogonal time frequency space (OTFS) is a promising candidate for future wireless communication in high-mobility scenarios. In addition to the superior communication performance, OTFS is also a natural choice for radar sensing since the primary parameters (range and velocity of targets) in radar signal processing can be inferred directly from the delay and Doppler shifts. Though there are several works on OTFS radar sensing, most of them consider the integer parameter estimation only, while the delay and Doppler shifts are usually fractional in the real world. In this paper, we propose a two-step method to estimate the fractional delay and Doppler shifts. We first perform the two-dimensional (2D) correlation between the received and transmitted DD domain symbols to obtain the integer parts of the parameters. Then a difference-based method is implemented to estimate the fractional parts of delay and Doppler indices. Meanwhile, we implement a target detection method based on a generalized likelihood ratio test since the number of potential targets in the sensing scenario is usually unknown. The simulation results show that the proposed method can obtain the delay and Doppler shifts accurately and get the number of sensing targets with a high detection probability.