 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Integrated FPGA Accelerator for Deep Learning-based 2D/3D Path Planning
Jun 30, 2023
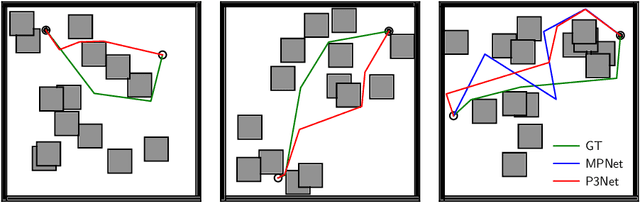
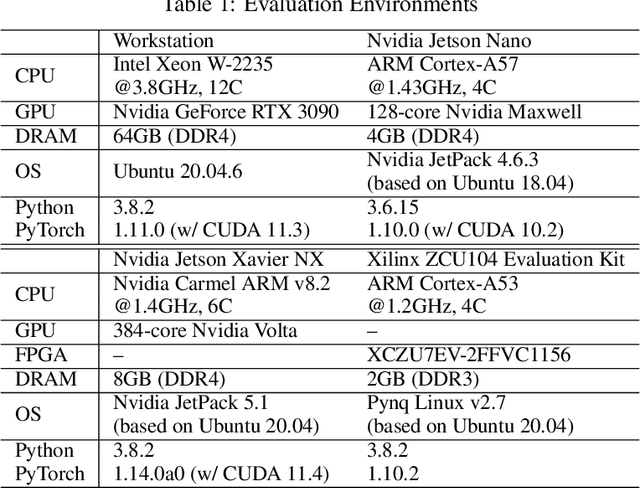
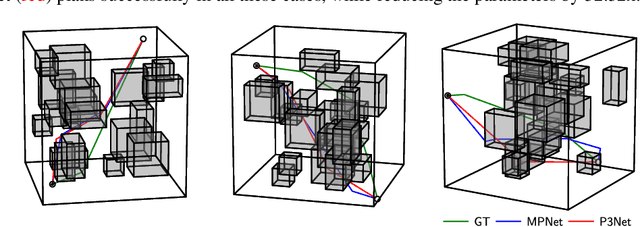
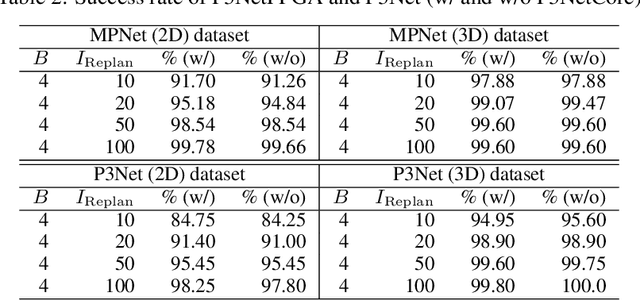
Path planning is a crucial component for realizing the autonomy of mobile robots. However, due to limited computational resources on mobile robots, it remains challenging to deploy state-of-the-art methods and achieve real-time performance. To address this, we propose P3Net (PointNet-based Path Planning Networks), a lightweight deep-learning-based method for 2D/3D path planning, and design an IP core (P3NetCore) targeting FPGA SoCs (Xilinx ZCU104). P3Net improves the algorithm and model architecture of the recently-proposed MPNet. P3Net employs an encoder with a PointNet backbone and a lightweight planning network in order to extract robust point cloud features and sample path points from a promising region. P3NetCore is comprised of the fully-pipelined point cloud encoder, batched bidirectional path planner, and parallel collision checker, to cover most part of the algorithm. On the 2D (3D) datasets, P3Net with the IP core runs 24.54-149.57x and 6.19-115.25x (10.03-59.47x and 3.38-28.76x) faster than ARM Cortex CPU and Nvidia Jetson while only consuming 0.255W (0.809W), and is up to 1049.42x (133.84x) power-efficient than the workstation. P3Net improves the success rate by up to 28.2% and plans a near-optimal path, leading to a significantly better tradeoff between computation and solution quality than MPNet and the state-of-the-art sampling-based methods.
Self-supervised Equality Embedded Deep Lagrange Dual for Approximate Constrained Optimization
Jun 15, 2023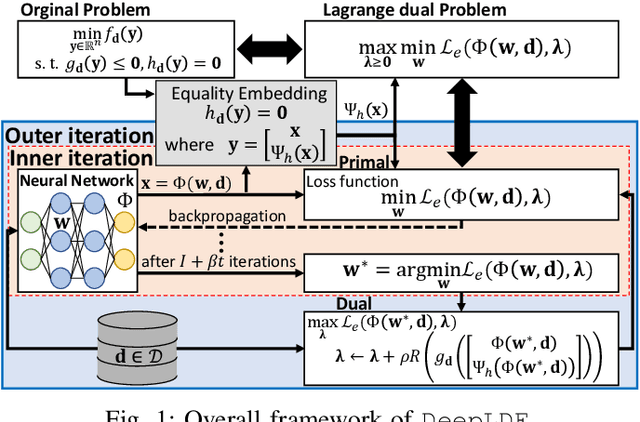
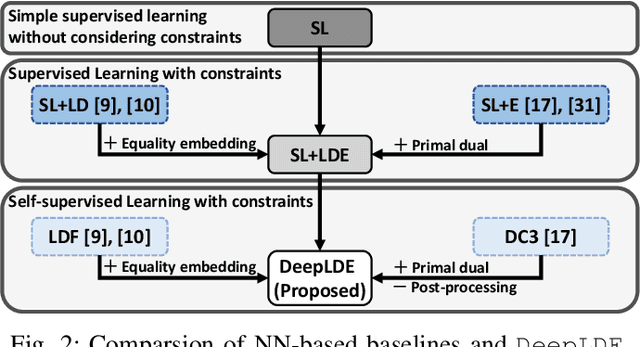
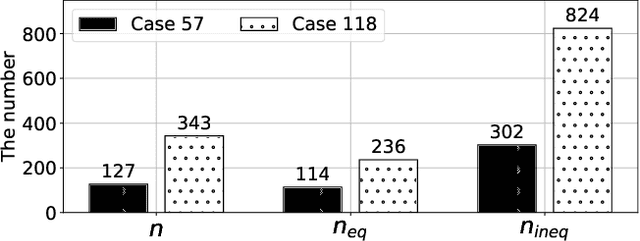
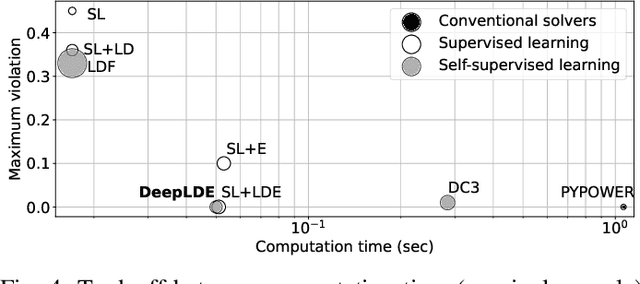
Conventional solvers are often computationally expensive for constrained optimization, particularly in large-scale and time-critical problems. While this leads to a growing interest in using neural networks (NNs) as fast optimal solution approximators, incorporating the constraints with NNs is challenging. In this regard, we propose deep Lagrange dual with equality embedding (DeepLDE), a framework that learns to find an optimal solution without using labels. To ensure feasible solutions, we embed equality constraints into the NNs and train the NNs using the primal-dual method to impose inequality constraints. Furthermore, we prove the convergence of DeepLDE and show that the primal-dual learning method alone cannot ensure equality constraints without the help of equality embedding. Simulation results on convex, non-convex, and AC optimal power flow (AC-OPF) problems show that the proposed DeepLDE achieves the smallest optimality gap among all the NN-based approaches while always ensuring feasible solutions. Furthermore, the computation time of the proposed method is about 5 to 250 times faster than DC3 and the conventional solvers in solving constrained convex, non-convex optimization, and/or AC-OPF.
Leaping through tree space: continuous phylogenetic inference for rooted and unrooted trees
Jun 15, 2023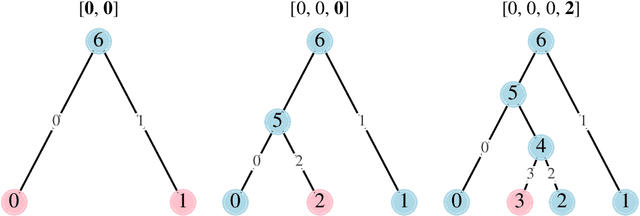
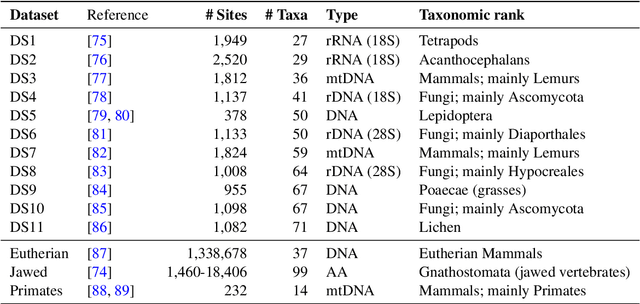
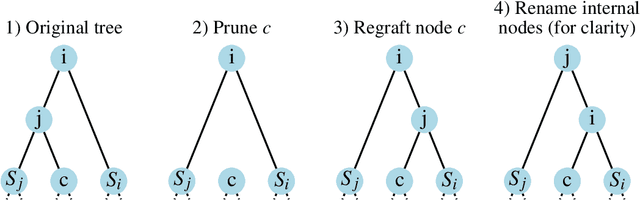
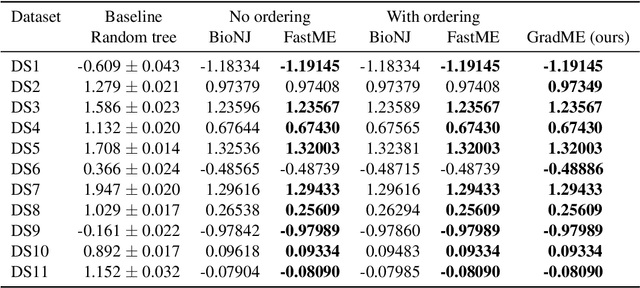
Phylogenetics is now fundamental in life sciences, providing insights into the earliest branches of life and the origins and spread of epidemics. However, finding suitable phylogenies from the vast space of possible trees remains challenging. To address this problem, for the first time, we perform both tree exploration and inference in a continuous space where the computation of gradients is possible. This continuous relaxation allows for major leaps across tree space in both rooted and unrooted trees, and is less susceptible to convergence to local minima. Our approach outperforms the current best methods for inference on unrooted trees and, in simulation, accurately infers the tree and root in ultrametric cases. The approach is effective in cases of empirical data with negligible amounts of data, which we demonstrate on the phylogeny of jawed vertebrates. Indeed, only a few genes with an ultrametric signal were generally sufficient for resolving the major lineages of vertebrate. With cubic-time complexity and efficient optimisation via automatic differentiation, our method presents an effective way forwards for exploring the most difficult, data-deficient phylogenetic questions.
Deep Declarative Dynamic Time Warping for End-to-End Learning of Alignment Paths
Mar 19, 2023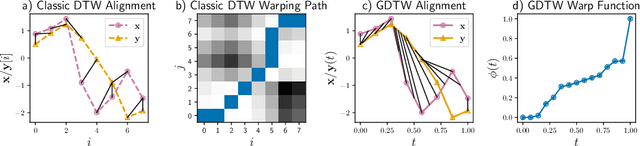

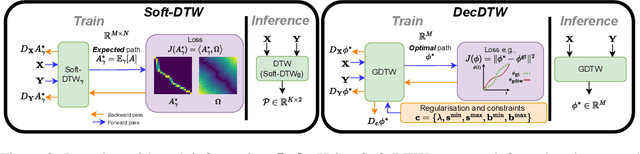
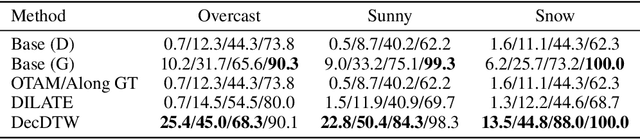
This paper addresses learning end-to-end models for time series data that include a temporal alignment step via dynamic time warping (DTW). Existing approaches to differentiable DTW either differentiate through a fixed warping path or apply a differentiable relaxation to the min operator found in the recursive steps used to solve the DTW problem. We instead propose a DTW layer based around bi-level optimisation and deep declarative networks, which we name DecDTW. By formulating DTW as a continuous, inequality constrained optimisation problem, we can compute gradients for the solution of the optimal alignment (with respect to the underlying time series) using implicit differentiation. An interesting byproduct of this formulation is that DecDTW outputs the optimal warping path between two time series as opposed to a soft approximation, recoverable from Soft-DTW. We show that this property is particularly useful for applications where downstream loss functions are defined on the optimal alignment path itself. This naturally occurs, for instance, when learning to improve the accuracy of predicted alignments against ground truth alignments. We evaluate DecDTW on two such applications, namely the audio-to-score alignment task in music information retrieval and the visual place recognition task in robotics, demonstrating state-of-the-art results in both.
Whole-Body Exploration with a Manipulator Using Heat Equation
Jun 29, 2023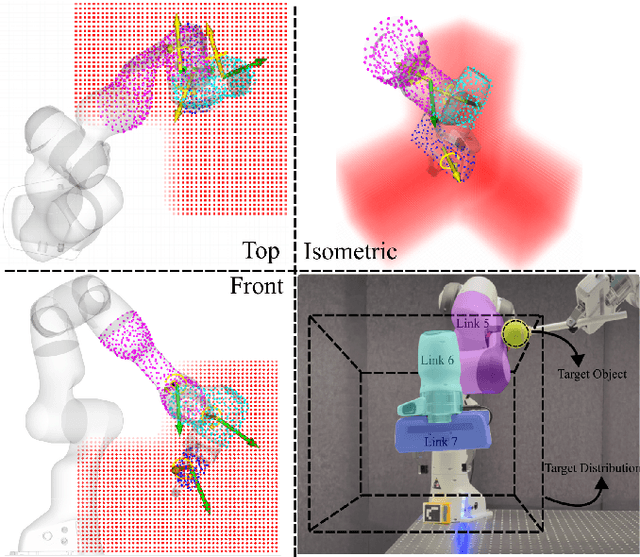

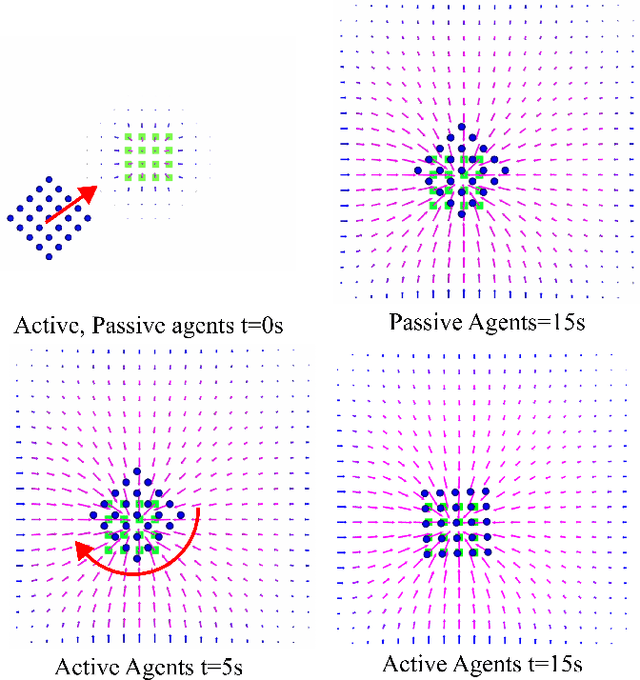
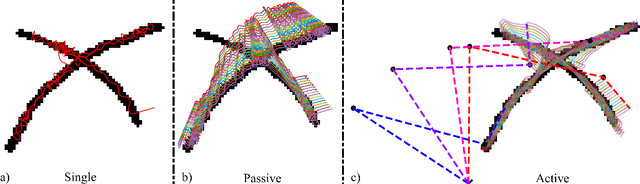
This paper presents a whole-body robot control method for exploring and probing a given region of interest. The ergodic control formalism behind such an exploration behavior consists of matching the time-averaged statistics of a robot trajectory with the spatial statistics of the target distribution. Most existing ergodic control approaches assume the robots/sensors as individual point agents moving in space. We introduce an approach exploiting multiple kinematically constrained agents on the whole-body of a robotic manipulator, where a consensus among the agents is found for generating control actions. To do so, we exploit an existing ergodic control formulation called heat equation-driven area coverage (HEDAC), combining local and global exploration on a potential field resulting from heat diffusion. Our approach extends HEDAC to applications where robots have multiple sensors on the whole-body (such as tactile skin) and use all sensors to optimally explore the given region. We show that our approach increases the exploration performance in terms of ergodicity and scales well to real-world problems using agents distributed on multiple robot links. We compare our method with HEDAC in kinematic simulation and demonstrate the applicability of an online exploration task with a 7-axis Franka Emika robot.
Ongoing EEG artifact correction using blind source separation
Jun 29, 2023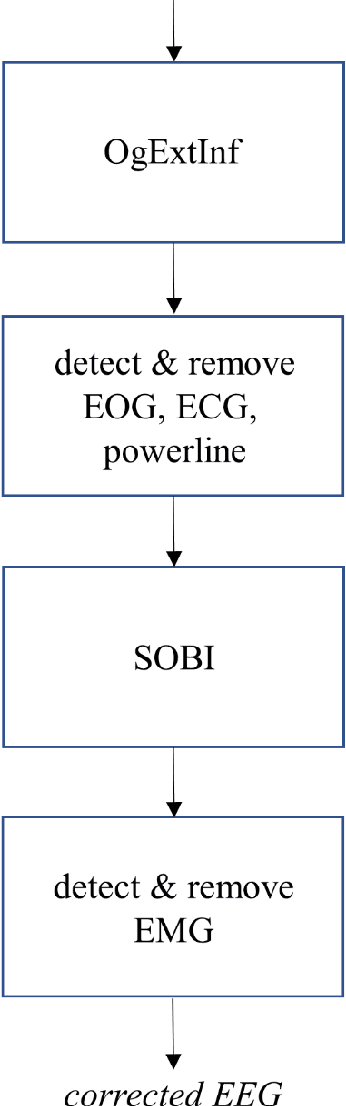
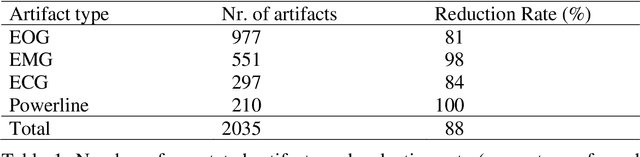
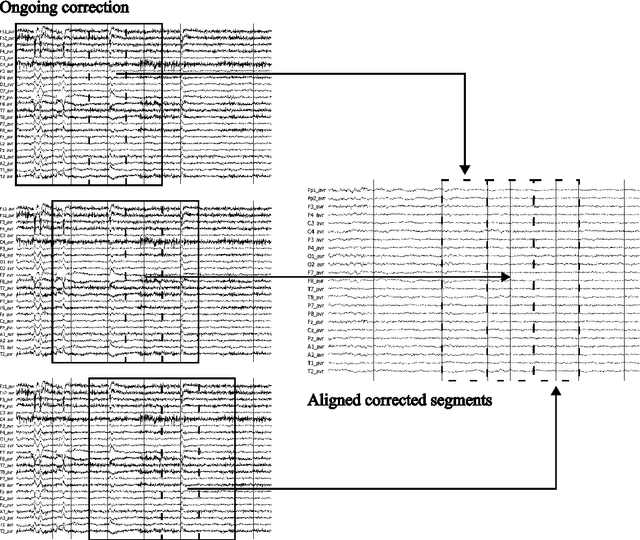
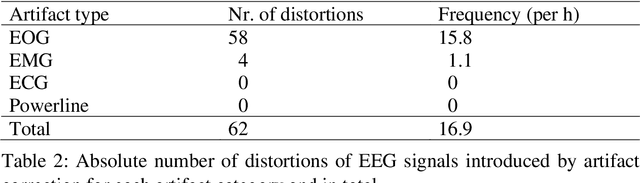
Objective: Analysis of the electroencephalogram (EEG) for epileptic spike and seizure detection or brain-computer interfaces can be severely hampered by the presence of artifacts. The aim of this study is to describe and evaluate a fast automatic algorithm for ongoing correction of artifacts in continuous EEG recordings, which can be applied offline and online. Methods: The automatic algorithm for ongoing correction of artifacts is based on fast blind source separation. It uses a sliding window technique with overlapping epochs and features in the spatial, temporal and frequency domain to detect and correct ocular, cardiac, muscle and powerline artifacts. Results: The approach was validated in an independent evaluation study on publicly available continuous EEG data with 2035 marked artifacts. Validation confirmed that 88% of the artifacts could be removed successfully (ocular: 81%, cardiac: 84%, muscle: 98%, powerline: 100%). It outperformed state-of-the-art algorithms both in terms of artifact reduction rates and computation time. Conclusions: Fast ongoing artifact correction successfully removed a good proportion of artifacts, while preserving most of the EEG signals. Significance: The presented algorithm may be useful for ongoing correction of artifacts, e.g., in online systems for epileptic spike and seizure detection or brain-computer interfaces.
PCDAL: A Perturbation Consistency-Driven Active Learning Approach for Medical Image Segmentation and Classification
Jun 29, 2023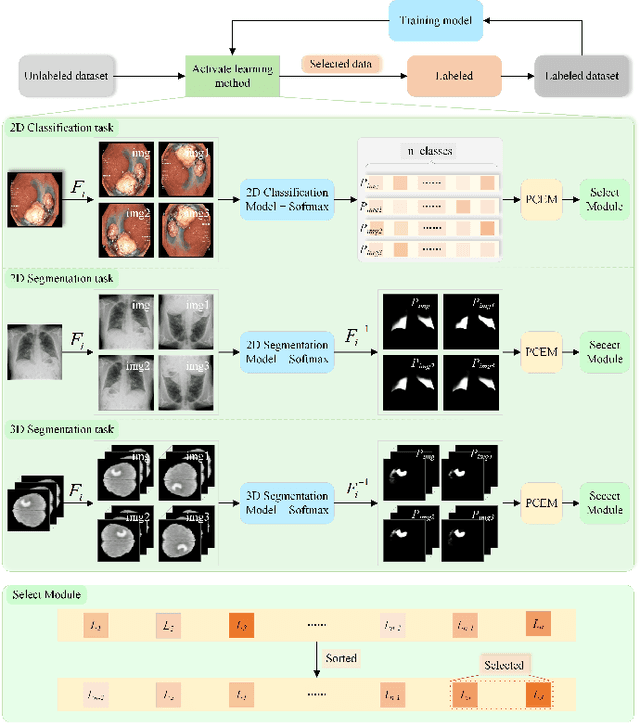
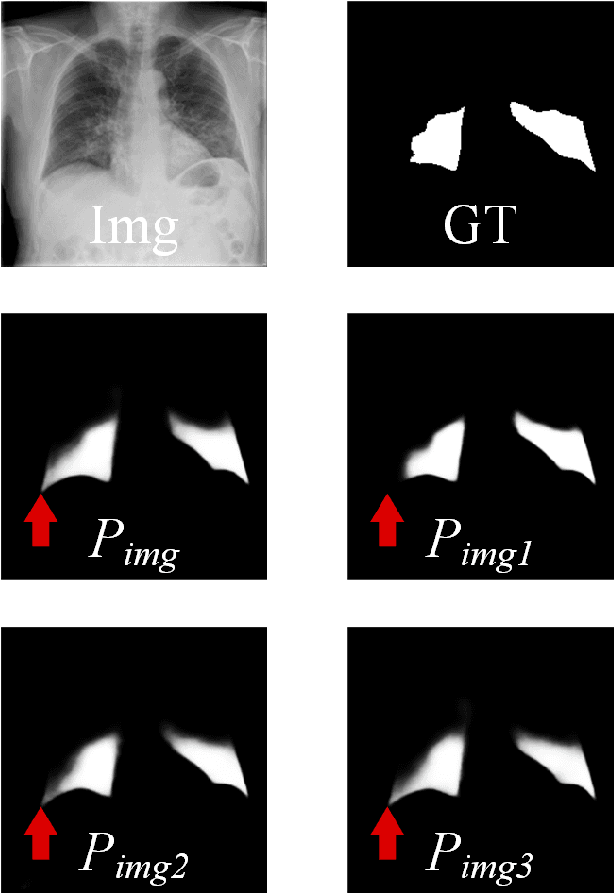
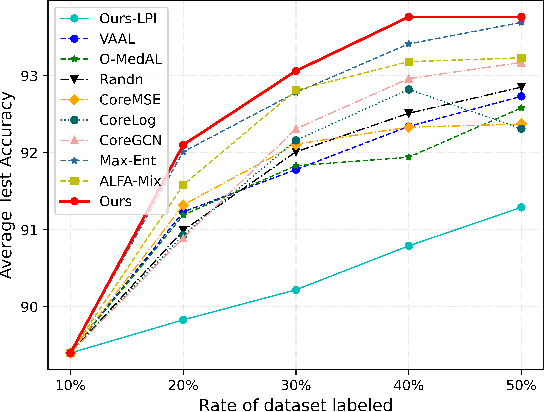
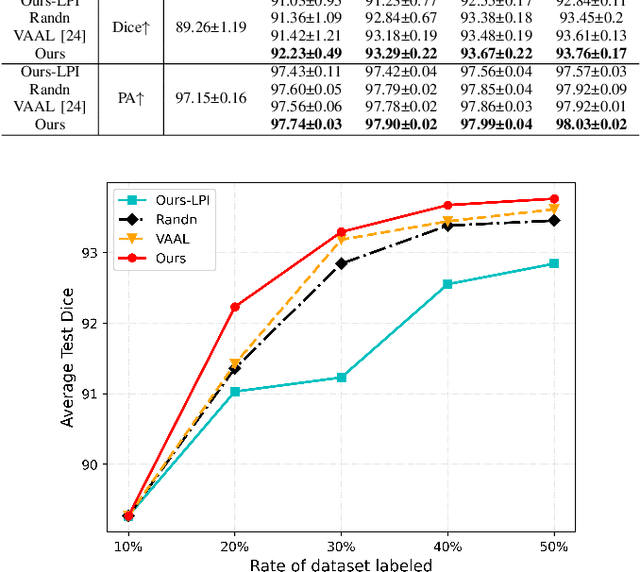
In recent years, deep learning has become a breakthrough technique in assisting medical image diagnosis. Supervised learning using convolutional neural networks (CNN) provides state-of-the-art performance and has served as a benchmark for various medical image segmentation and classification. However, supervised learning deeply relies on large-scale annotated data, which is expensive, time-consuming, and even impractical to acquire in medical imaging applications. Active Learning (AL) methods have been widely applied in natural image classification tasks to reduce annotation costs by selecting more valuable examples from the unlabeled data pool. However, their application in medical image segmentation tasks is limited, and there is currently no effective and universal AL-based method specifically designed for 3D medical image segmentation. To address this limitation, we propose an AL-based method that can be simultaneously applied to 2D medical image classification, segmentation, and 3D medical image segmentation tasks. We extensively validated our proposed active learning method on three publicly available and challenging medical image datasets, Kvasir Dataset, COVID-19 Infection Segmentation Dataset, and BraTS2019 Dataset. The experimental results demonstrate that our PCDAL can achieve significantly improved performance with fewer annotations in 2D classification and segmentation and 3D segmentation tasks. The codes of this study are available at https://github.com/ortonwang/PCDAL.
Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging
Jun 29, 2023
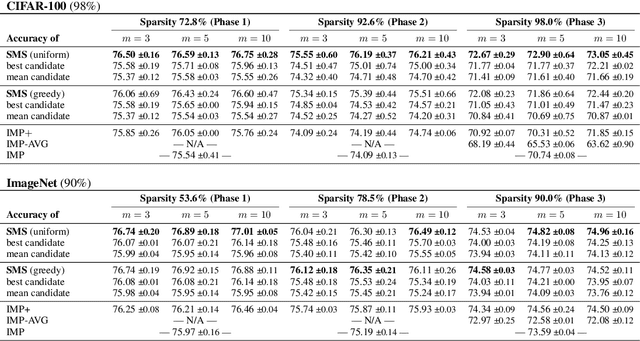

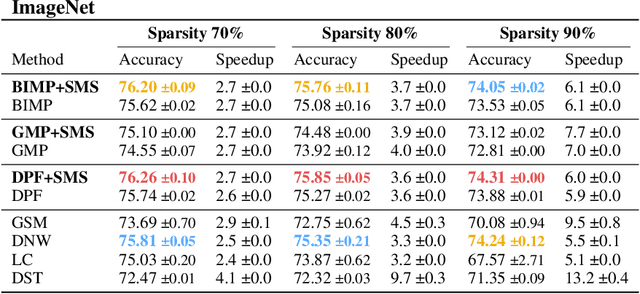
Neural networks can be significantly compressed by pruning, leading to sparse models requiring considerably less storage and floating-point operations while maintaining predictive performance. Model soups (Wortsman et al., 2022) improve generalization and out-of-distribution performance by averaging the parameters of multiple models into a single one without increased inference time. However, identifying models in the same loss basin to leverage both sparsity and parameter averaging is challenging, as averaging arbitrary sparse models reduces the overall sparsity due to differing sparse connectivities. In this work, we address these challenges by demonstrating that exploring a single retraining phase of Iterative Magnitude Pruning (IMP) with varying hyperparameter configurations, such as batch ordering or weight decay, produces models that are suitable for averaging and share the same sparse connectivity by design. Averaging these models significantly enhances generalization performance compared to their individual components. Building on this idea, we introduce Sparse Model Soups (SMS), a novel method for merging sparse models by initiating each prune-retrain cycle with the averaged model of the previous phase. SMS maintains sparsity, exploits sparse network benefits being modular and fully parallelizable, and substantially improves IMP's performance. Additionally, we demonstrate that SMS can be adapted to enhance the performance of state-of-the-art pruning during training approaches.
GraMMaR: Ground-aware Motion Model for 3D Human Motion Reconstruction
Jun 29, 2023
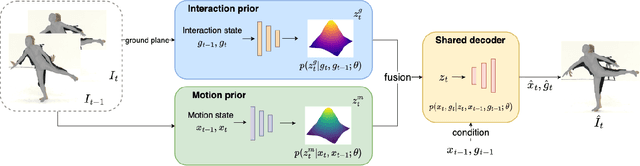
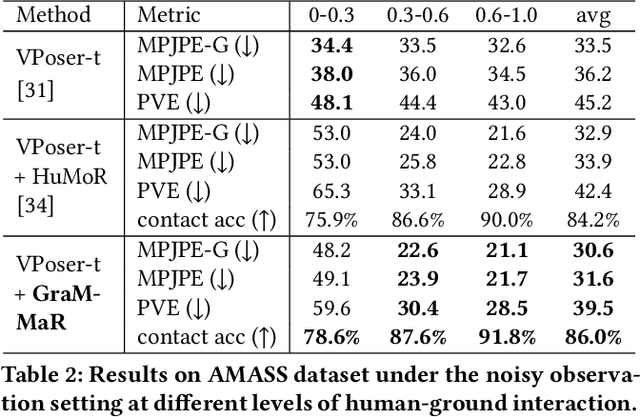
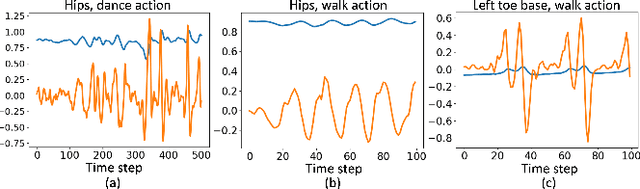
Demystifying complex human-ground interactions is essential for accurate and realistic 3D human motion reconstruction from RGB videos, as it ensures consistency between the humans and the ground plane. Prior methods have modeled human-ground interactions either implicitly or in a sparse manner, often resulting in unrealistic and incorrect motions when faced with noise and uncertainty. In contrast, our approach explicitly represents these interactions in a dense and continuous manner. To this end, we propose a novel Ground-aware Motion Model for 3D Human Motion Reconstruction, named GraMMaR, which jointly learns the distribution of transitions in both pose and interaction between every joint and ground plane at each time step of a motion sequence. It is trained to explicitly promote consistency between the motion and distance change towards the ground. After training, we establish a joint optimization strategy that utilizes GraMMaR as a dual-prior, regularizing the optimization towards the space of plausible ground-aware motions. This leads to realistic and coherent motion reconstruction, irrespective of the assumed or learned ground plane. Through extensive evaluation on the AMASS and AIST++ datasets, our model demonstrates good generalization and discriminating abilities in challenging cases including complex and ambiguous human-ground interactions. The code will be released.
Computationally-efficient and perceptually-motivated rendering of diffuse reflections in room acoustics simulation
Jun 29, 2023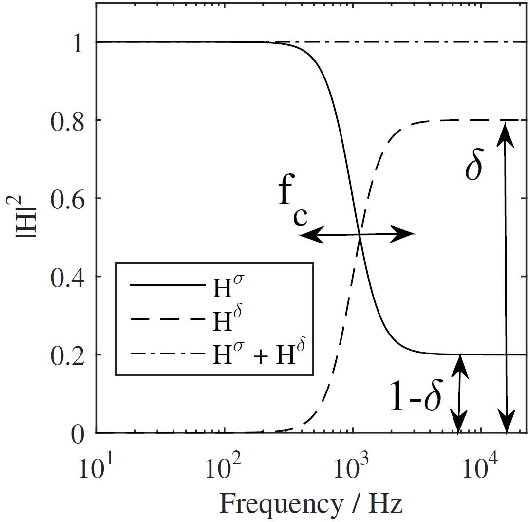
Geometrical acoustics is well suited for simulating room reverberation in interactive real-time applications. While the image source model (ISM) is exceptionally fast, the restriction to specular reflections impacts its perceptual plausibility. To account for diffuse late reverberation, hybrid approaches have been proposed, e.g., using a feedback delay network (FDN) in combination with the ISM. Here, a computationally-efficient, digital-filter approach is suggested to account for effects of non-specular reflections in the ISM and to couple scattered sound into a diffuse reverberation model using a spatially rendered FDN. Depending on the scattering coefficient of a room boundary, energy of each image source is split into a specular and a scattered part which is added to the diffuse sound field. Temporal effects as observed for an infinite ideal diffuse (Lambertian) reflector are simulated using cascaded all-pass filters. Effects of scattering and multiple (inter-) reflections caused by larger geometric disturbances at walls and by objects in the room are accounted for in a highly simplified manner. Using a single parameter to quantify deviations from an empty shoebox room, each reflection is temporally smeared using cascaded all-pass filters. The proposed method was perceptually evaluated against dummy head recordings of real rooms.