 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-Offline Reinforcement Learning for Optimized Text Generation
Jun 16, 2023
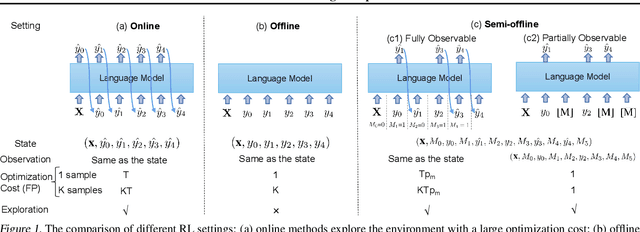
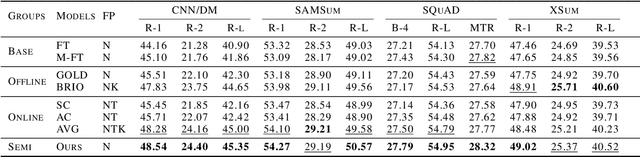
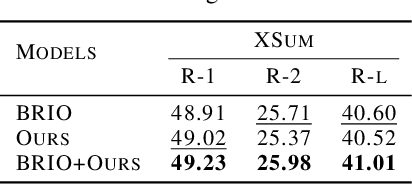
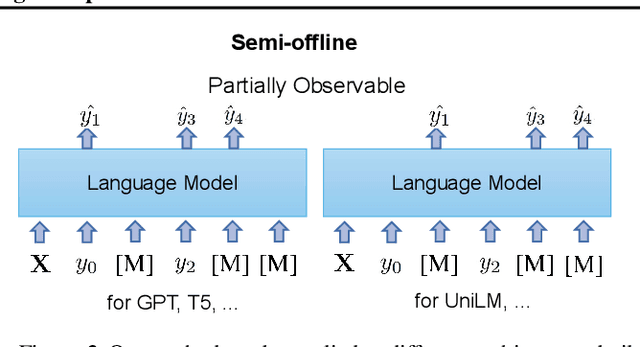
In reinforcement learning (RL), there are two major settings for interacting with the environment: online and offline. Online methods explore the environment at significant time cost, and offline methods efficiently obtain reward signals by sacrificing exploration capability. We propose semi-offline RL, a novel paradigm that smoothly transits from offline to online settings, balances exploration capability and training cost, and provides a theoretical foundation for comparing different RL settings. Based on the semi-offline formulation, we present the RL setting that is optimal in terms of optimization cost, asymptotic error, and overfitting error bound. Extensive experiments show that our semi-offline approach is efficient and yields comparable or often better performance compared with state-of-the-art methods.
Triggering Dark Showers with Conditional Dual Auto-Encoders
Jun 22, 2023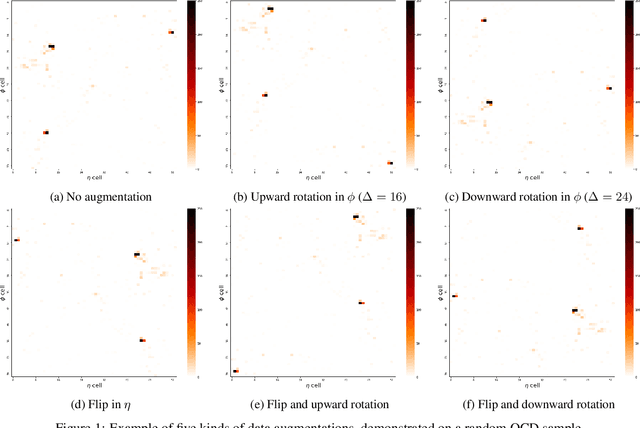
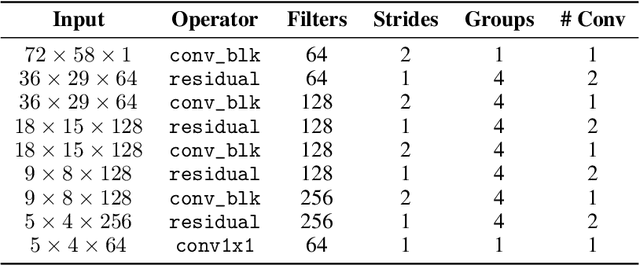
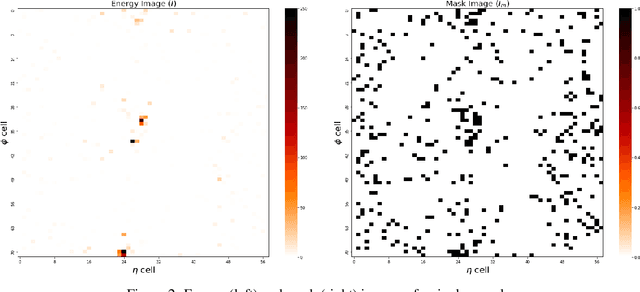
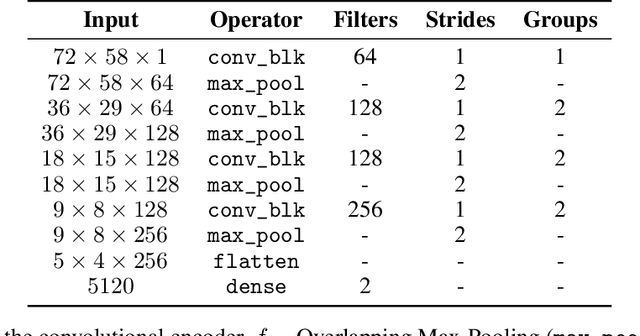
Auto-encoders (AEs) have the potential to be effective and generic tools for new physics searches at colliders, requiring little to no model-dependent assumptions. New hypothetical physics signals can be considered anomalies that deviate from the well-known background processes generally expected to describe the whole dataset. We present a search formulated as an anomaly detection (AD) problem, using an AE to define a criterion to decide about the physics nature of an event. In this work, we perform an AD search for manifestations of a dark version of strong force using raw detector images, which are large and very sparse, without leveraging any physics-based pre-processing or assumption on the signals. We propose a dual-encoder design which can learn a compact latent space through conditioning. In the context of multiple AD metrics, we present a clear improvement over competitive baselines and prior approaches. It is the first time that an AE is shown to exhibit excellent discrimination against multiple dark shower models, illustrating the suitability of this method as a performant, model-independent algorithm to deploy, e.g., in the trigger stage of LHC experiments such as ATLAS and CMS.
CamChoice: A Corpus of Multiple Choice Questions and Candidate Response Distributions
Jun 22, 2023
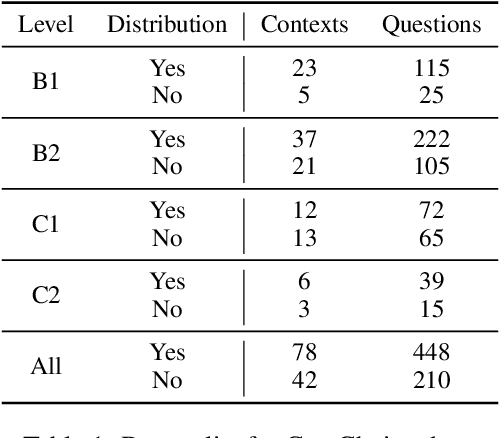
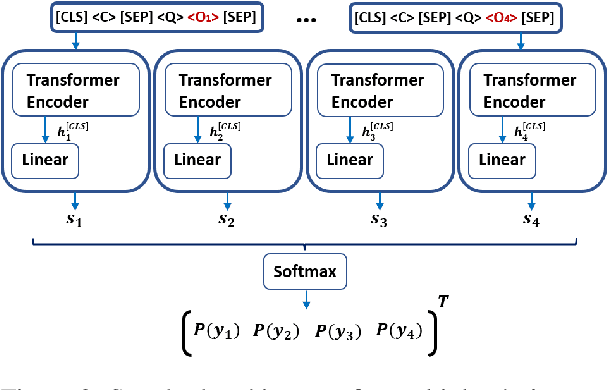
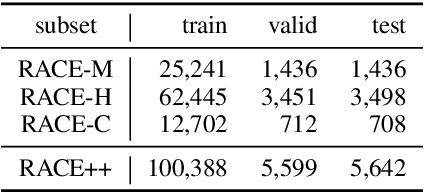
Multiple Choice examinations are a ubiquitous form of assessment that is used to measure the ability of candidates across various domains and tasks. Maintaining the quality of proposed questions is of great importance to test designers, and therefore newly proposed questions go through several pre-test evaluation stages before they can be deployed into real-world exams. This process is currently quite manual, which can lead to time lags in the question development cycle. Automating this process would lead to a large improvement in efficiency, however, current datasets do not contain sufficient pre-test analysis information. In this paper, we introduce CamChoice; a multiple-choice comprehension dataset with questions at different target levels, where questions have the true candidate selected options distributions. We introduce the task of candidate distribution matching, propose several evaluation metrics for the task, and demonstrate that automatic systems trained on RACE++ can be leveraged as baselines for our task. We further demonstrate that these automatic systems can be used for practical pre-test evaluation tasks such as detecting underperforming distractors, where our detection systems can automatically identify poor distractors that few candidates select. We release the data publicly for future research.
Deep Metric Learning with Soft Orthogonal Proxies
Jun 22, 2023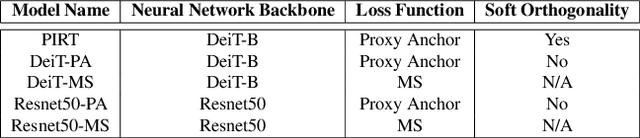
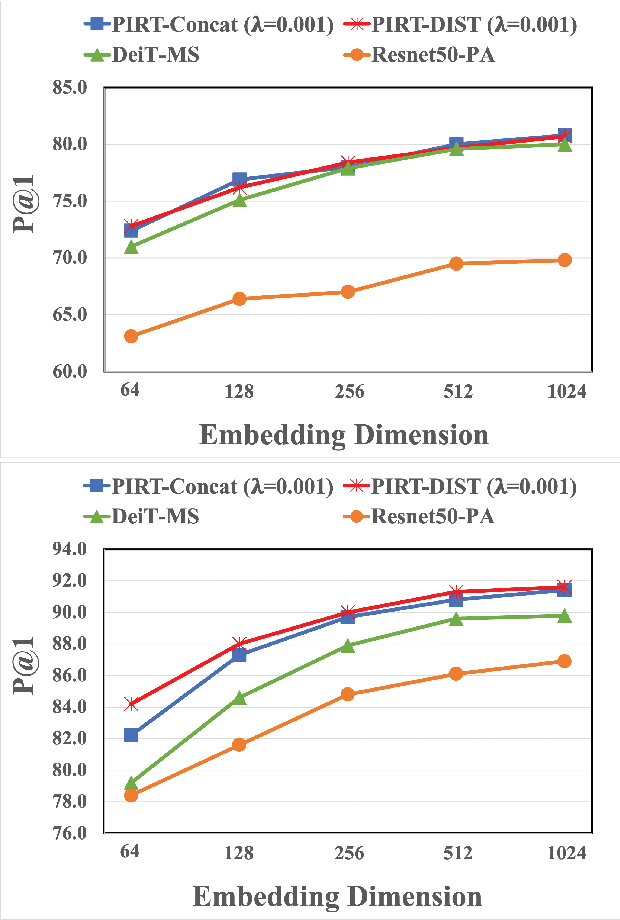
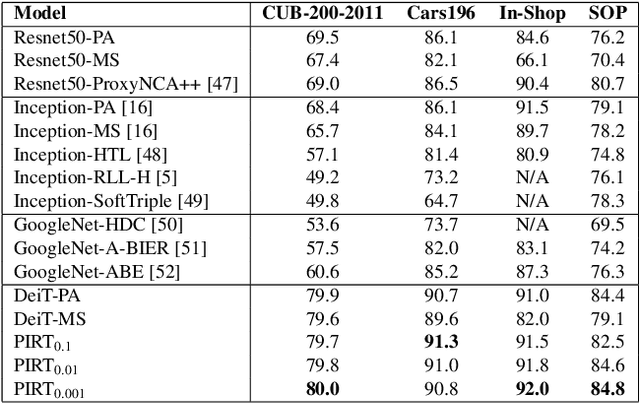

Deep Metric Learning (DML) models rely on strong representations and similarity-based measures with specific loss functions. Proxy-based losses have shown great performance compared to pair-based losses in terms of convergence speed. However, proxies that are assigned to different classes may end up being closely located in the embedding space and hence having a hard time to distinguish between positive and negative items. Alternatively, they may become highly correlated and hence provide redundant information with the model. To address these issues, we propose a novel approach that introduces Soft Orthogonality (SO) constraint on proxies. The constraint ensures the proxies to be as orthogonal as possible and hence control their positions in the embedding space. Our approach leverages Data-Efficient Image Transformer (DeiT) as an encoder to extract contextual features from images along with a DML objective. The objective is made of the Proxy Anchor loss along with the SO regularization. We evaluate our method on four public benchmarks for category-level image retrieval and demonstrate its effectiveness with comprehensive experimental results and ablation studies. Our evaluations demonstrate the superiority of our proposed approach over state-of-the-art methods by a significant margin.
HypeRS: Building a Hypergraph-driven ensemble Recommender System
Jun 22, 2023
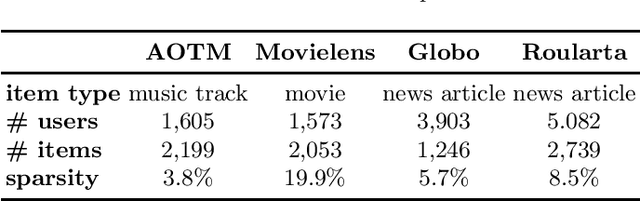
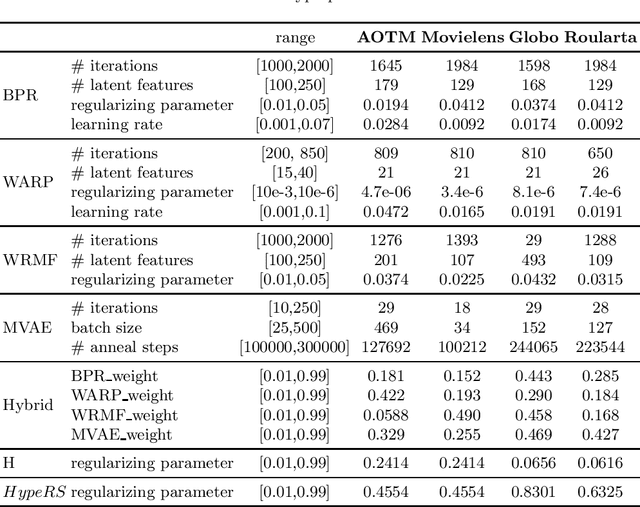
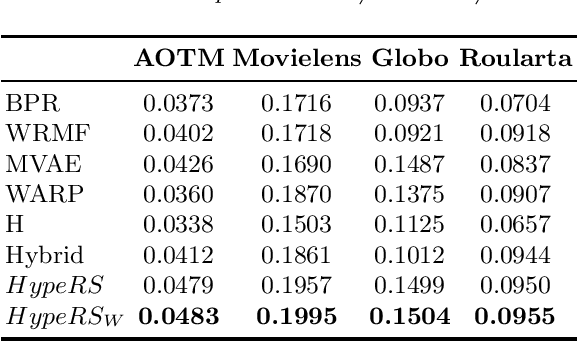
Recommender systems are designed to predict user preferences over collections of items. These systems process users' previous interactions to decide which items should be ranked higher to satisfy their desires. An ensemble recommender system can achieve great recommendation performance by effectively combining the decisions generated by individual models. In this paper, we propose a novel ensemble recommender system that combines predictions made by different models into a unified hypergraph ranking framework. This is the first time that hypergraph ranking has been employed to model an ensemble of recommender systems. Hypergraphs are generalizations of graphs where multiple vertices can be connected via hyperedges, efficiently modeling high-order relations. We differentiate real and predicted connections between users and items by assigning different hyperedge weights to individual recommender systems. We perform experiments using four datasets from the fields of movie, music and news media recommendation. The obtained results show that the ensemble hypergraph ranking method generates more accurate recommendations compared to the individual models and a weighted hybrid approach. The assignment of different hyperedge weights to the ensemble hypergraph further improves the performance compared to a setting with identical hyperedge weights.
DiffWA: Diffusion Models for Watermark Attack
Jun 22, 2023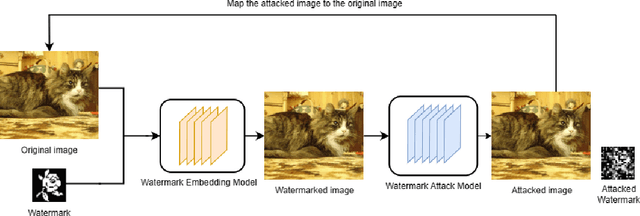



With the rapid development of deep neural networks(DNNs), many robust blind watermarking algorithms and frameworks have been proposed and achieved good results. At present, the watermark attack algorithm can not compete with the watermark addition algorithm. And many watermark attack algorithms only care about interfering with the normal extraction of the watermark, and the watermark attack will cause great visual loss to the image. To this end, we propose DiffWA, a conditional diffusion model with distance guidance for watermark attack, which can restore the image while removing the embedded watermark. The core of our method is training an image-to-image conditional diffusion model on unwatermarked images and guiding the conditional model using a distance guidance when sampling so that the model will generate unwatermarked images which is similar to original images. We conducted experiments on CIFAR-10 using our proposed models. The results shows that the model can remove the watermark with good effect and make the bit error rate of watermark extraction higher than 0.4. At the same time, the attacked image will maintain good visual effect with PSNR more than 31 and SSIM more than 0.97 compared with the original image.
Don't be so Monotone: Relaxing Stochastic Line Search in Over-Parameterized Models
Jun 22, 2023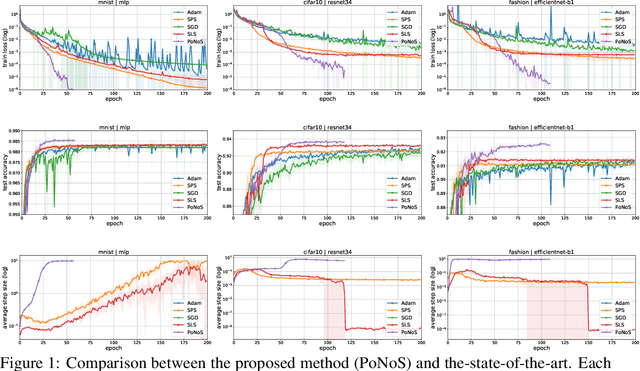
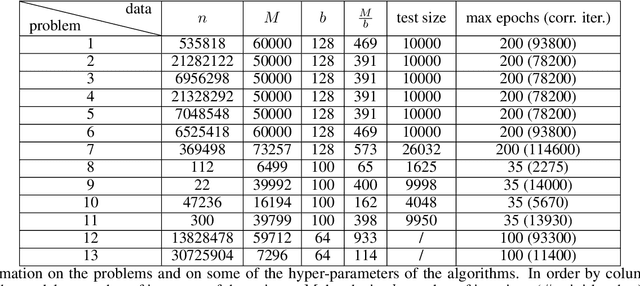
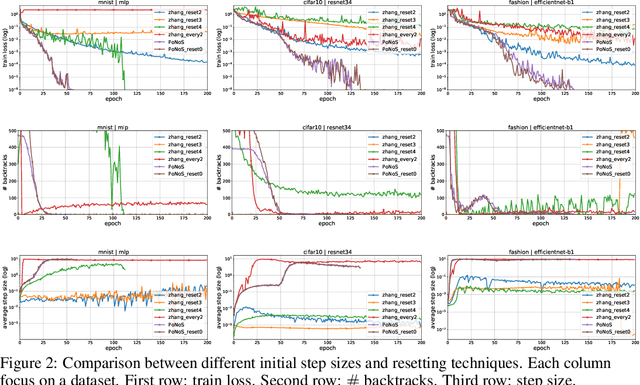

Recent works have shown that line search methods can speed up Stochastic Gradient Descent (SGD) and Adam in modern over-parameterized settings. However, existing line searches may take steps that are smaller than necessary since they require a monotone decrease of the (mini-)batch objective function. We explore nonmonotone line search methods to relax this condition and possibly accept larger step sizes. Despite the lack of a monotonic decrease, we prove the same fast rates of convergence as in the monotone case. Our experiments show that nonmonotone methods improve the speed of convergence and generalization properties of SGD/Adam even beyond the previous monotone line searches. We propose a POlyak NOnmonotone Stochastic (PoNoS) method, obtained by combining a nonmonotone line search with a Polyak initial step size. Furthermore, we develop a new resetting technique that in the majority of the iterations reduces the amount of backtracks to zero while still maintaining a large initial step size. To the best of our knowledge, a first runtime comparison shows that the epoch-wise advantage of line-search-based methods gets reflected in the overall computational time.
Multimodal Zero-Shot Learning for Tactile Texture Recognition
Jun 22, 2023Tactile sensing plays an irreplaceable role in robotic material recognition. It enables robots to distinguish material properties such as their local geometry and textures, especially for materials like textiles. However, most tactile recognition methods can only classify known materials that have been touched and trained with tactile data, yet cannot classify unknown materials that are not trained with tactile data. To solve this problem, we propose a tactile zero-shot learning framework to recognise unknown materials when they are touched for the first time without requiring training tactile samples. The visual modality, providing tactile cues from sight, and semantic attributes, giving high-level characteristics, are combined together to bridge the gap between touched classes and untouched classes. A generative model is learnt to synthesise tactile features according to corresponding visual images and semantic embeddings, and then a classifier can be trained using the synthesised tactile features of untouched materials for zero-shot recognition. Extensive experiments demonstrate that our proposed multimodal generative model can achieve a high recognition accuracy of 83.06% in classifying materials that were not touched before. The robotic experiment demo and the dataset are available at https://sites.google.com/view/multimodalzsl.
Estimating Treatment Effects in Continuous Time with Hidden Confounders
Feb 21, 2023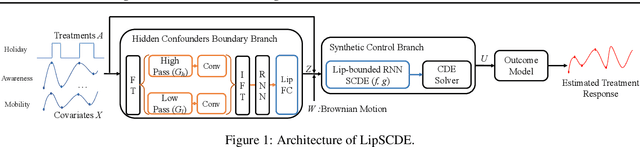
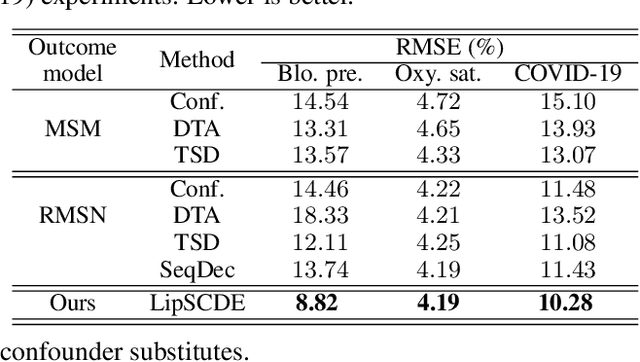
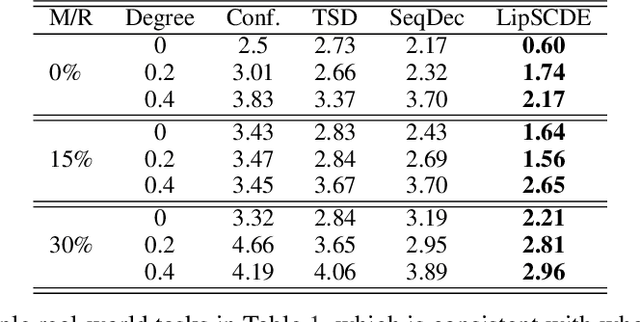
Estimating treatment effects plays a crucial role in causal inference, having many real-world applications like policy analysis and decision making. Nevertheless, estimating treatment effects in the longitudinal setting in the presence of hidden confounders remains an extremely challenging problem. Recently, there is a growing body of work attempting to obtain unbiased ITE estimates from time-dynamic observational data by ignoring the possible existence of hidden confounders. Additionally, many existing works handling hidden confounders are not applicable for continuous-time settings. In this paper, we extend the line of work focusing on deconfounding in the dynamic time setting in the presence of hidden confounders. We leverage recent advancements in neural differential equations to build a latent factor model using a stochastic controlled differential equation and Lipschitz constrained convolutional operation in order to continuously incorporate information about ongoing interventions and irregularly sampled observations. Experiments on both synthetic and real-world datasets highlight the promise of continuous time methods for estimating treatment effects in the presence of hidden confounders.
Fast Dynamic 1D Simulation of Divertor Plasmas with Neural PDE Surrogates
May 30, 2023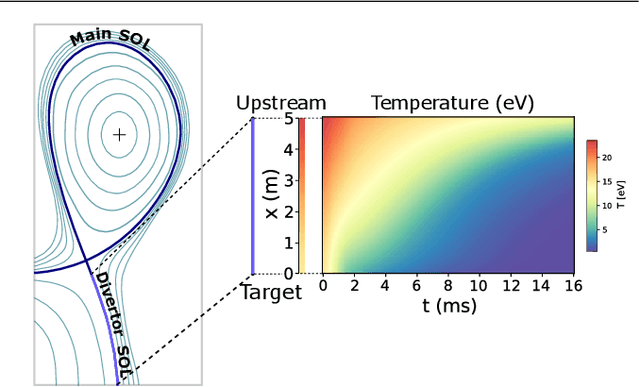
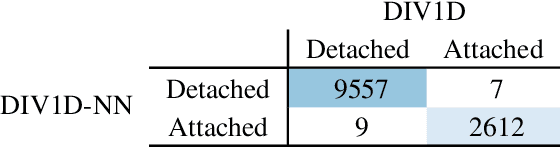
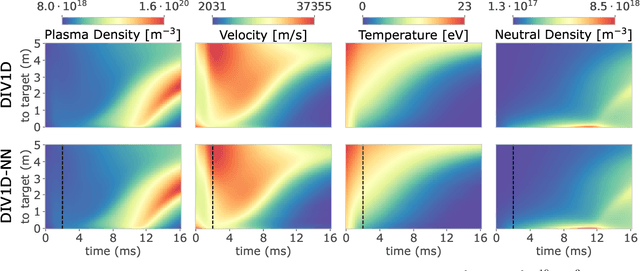
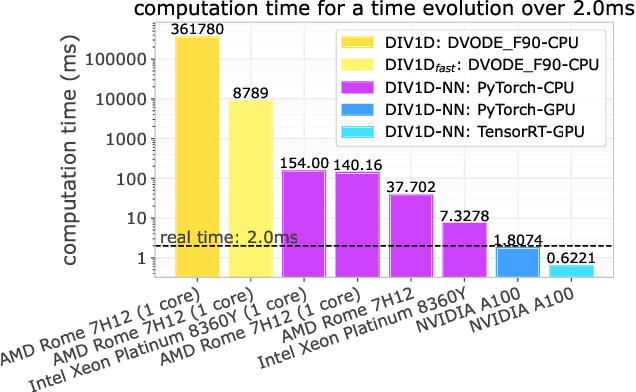
Managing divertor plasmas is crucial for operating reactor scale tokamak devices due to heat and particle flux constraints on the divertor target. Simulation is an important tool to understand and control these plasmas, however, for real-time applications or exhaustive parameter scans only simple approximations are currently fast enough. We address this lack of fast simulators using neural PDE surrogates, data-driven neural network-based surrogate models trained using solutions generated with a classical numerical method. The surrogate approximates a time-stepping operator that evolves the full spatial solution of a reference physics-based model over time. We use DIV1D, a 1D dynamic model of the divertor plasma, as reference model to generate data. DIV1D's domain covers a 1D heat flux tube from the X-point (upstream) to the target. We simulate a realistic TCV divertor plasma with dynamics induced by upstream density ramps and provide an exploratory outlook towards fast transients. State-of-the-art neural PDE surrogates are evaluated in a common framework and extended for properties of the DIV1D data. We evaluate (1) the speed-accuracy trade-off; (2) recreating non-linear behavior; (3) data efficiency; and (4) parameter inter- and extrapolation. Once trained, neural PDE surrogates can faithfully approximate DIV1D's divertor plasma dynamics at sub real-time computation speeds: In the proposed configuration, 2ms of plasma dynamics can be computed in $\approx$0.63ms of wall-clock time, several orders of magnitude faster than DIV1D.