 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ISI-Mitigating Character Encoding for Molecular communications via Diffusion
Jun 05, 2023
This letter introduces a novel algorithm for generating codebooks in molecular communications (MC). The proposed algorithm utilizes character entropy to effectively mitigate inter-symbol interference (ISI) during MC via diffusion. Based on Huffman coding, the algorithm ensures that consecutive bit-1s are avoided in the resulting codebook. Additionally, the error-correction process at the receiver effectively eliminates ISI in the time slot immediately following a bit-1. We conduct an ISI analysis, which confirms that the proposed algorithm significantly reduces decoding errors. Through numerical analysis, we demonstrate that the proposed codebook exhibits superior performance in terms of character error rate compared to existing codebooks. Furthermore, we validate the performance of the algorithm through experimentation on a real-time testbed.
Restless Bandits with Average Reward: Breaking the Uniform Global Attractor Assumption
May 31, 2023
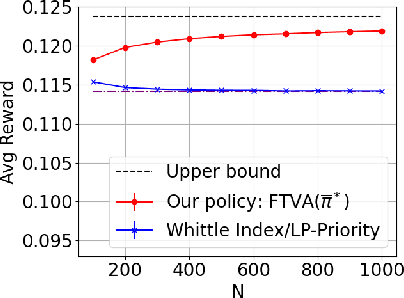
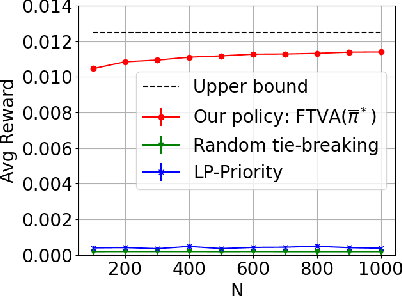
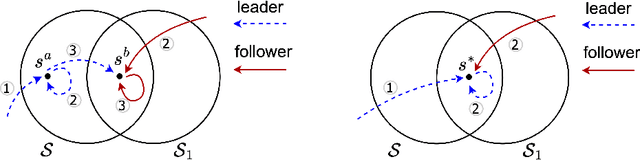
We study the infinite-horizon restless bandit problem with the average reward criterion, under both discrete-time and continuous-time settings. A fundamental question is how to design computationally efficient policies that achieve a diminishing optimality gap as the number of arms, $N$, grows large. Existing results on asymptotical optimality all rely on the uniform global attractor property (UGAP), a complex and challenging-to-verify assumption. In this paper, we propose a general, simulation-based framework that converts any single-armed policy into a policy for the original $N$-armed problem. This is accomplished by simulating the single-armed policy on each arm and carefully steering the real state towards the simulated state. Our framework can be instantiated to produce a policy with an $O(1/\sqrt{N})$ optimality gap. In the discrete-time setting, our result holds under a simpler synchronization assumption, which covers some problem instances that do not satisfy UGAP. More notably, in the continuous-time setting, our result does not require any additional assumptions beyond the standard unichain condition. In both settings, we establish the first asymptotic optimality result that does not require UGAP.
Automated Task-Time Interventions to Improve Teamwork using Imitation Learning
Mar 02, 2023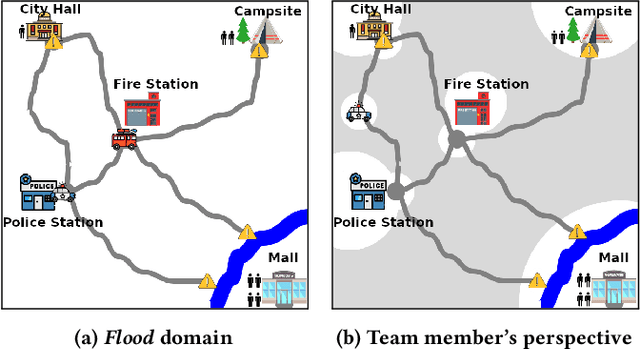
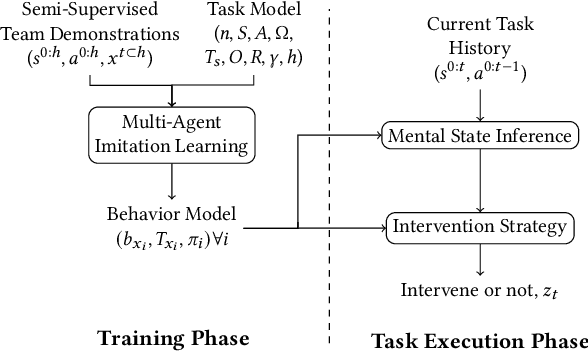
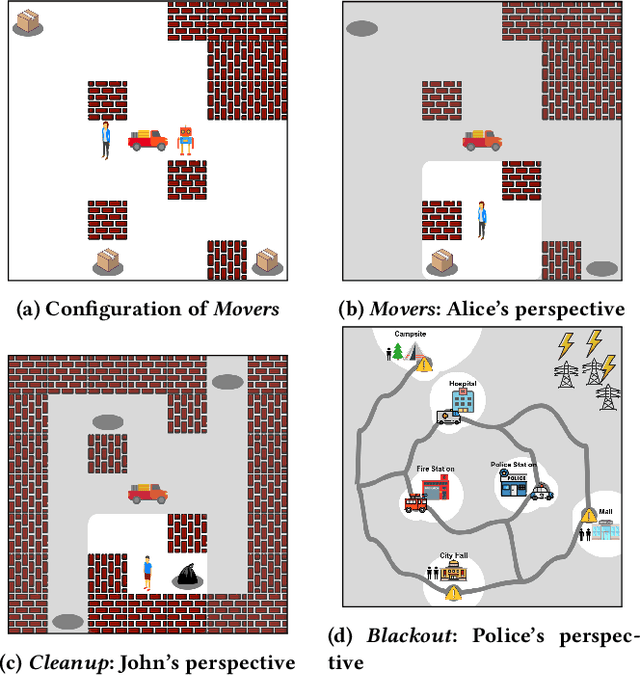
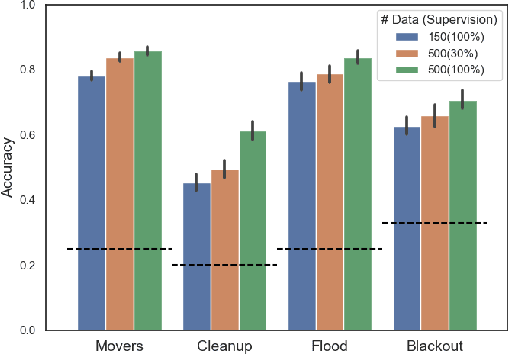
Effective human-human and human-autonomy teamwork is critical but often challenging to perfect. The challenge is particularly relevant in time-critical domains, such as healthcare and disaster response, where the time pressures can make coordination increasingly difficult to achieve and the consequences of imperfect coordination can be severe. To improve teamwork in these and other domains, we present TIC: an automated intervention approach for improving coordination between team members. Using BTIL, a multi-agent imitation learning algorithm, our approach first learns a generative model of team behavior from past task execution data. Next, it utilizes the learned generative model and team's task objective (shared reward) to algorithmically generate execution-time interventions. We evaluate our approach in synthetic multi-agent teaming scenarios, where team members make decentralized decisions without full observability of the environment. The experiments demonstrate that the automated interventions can successfully improve team performance and shed light on the design of autonomous agents for improving teamwork.
Wireless Communications with Space-Time Modulated Metasurfaces
Feb 16, 2023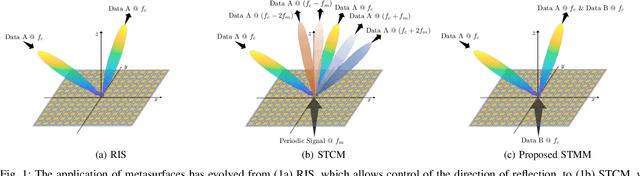
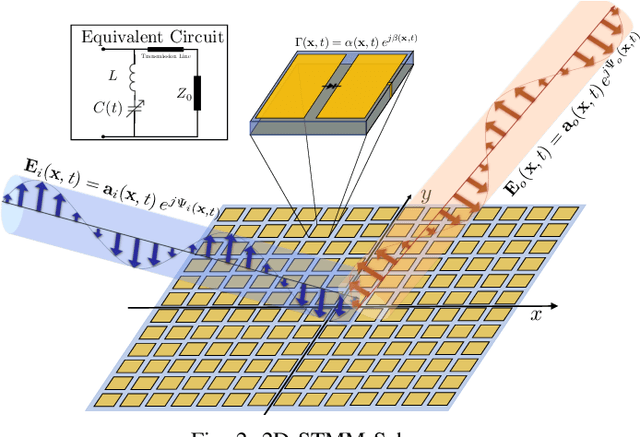
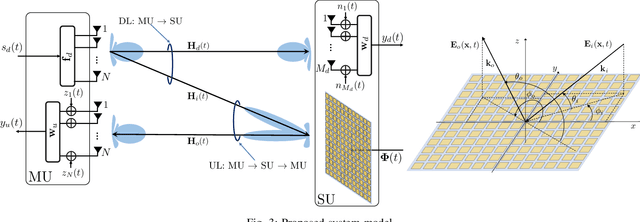
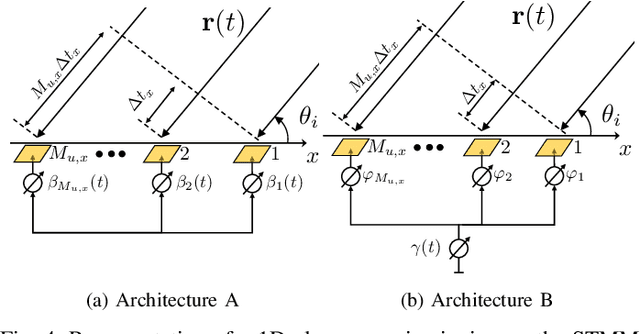
Space-time modulated metasurfaces (STMMs) are a newly investigated technology for next 6G generation wireless communication networks. An STMM augments the spatial phase function with a time-varying one across the elements, allowing for the conveyance of information that possibly modulates the impinging signal. Hence, STMM represents an evolution of reconfigurable intelligent surfaces (RIS), which only design the spatial phase pattern. STMMs convey signals without a relevant increase in the energy budget, which is convenient for applications where energy is a strong constraint. This paper proposes a mathematical model for STMM-based wireless communication, that creates the basics for two potential STMM architectures. One has excellent design flexibility, whereas the other is more cost-effective. The model describes STMM's distinguishing features, such as space-time coupling, and their impact on system performance. The proposed STMM model addresses the design criteria of a full-duplex system architecture, in which the temporal signal originating at the STMM generates a modulation overlapped with the incident one. The presented numerical results demonstrate the efficacy of the proposed model and its potential to revolutionize wireless communication.
Collision-free Motion Generation Based on Stochastic Optimization and Composite Signed Distance Field Networks of Articulated Robot
Jun 07, 2023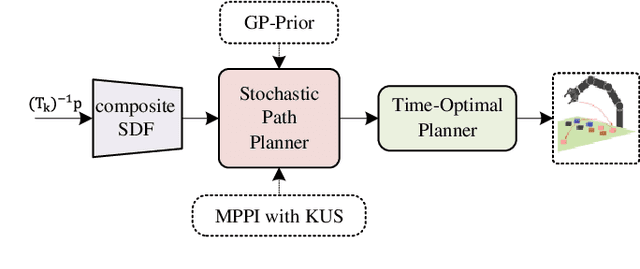
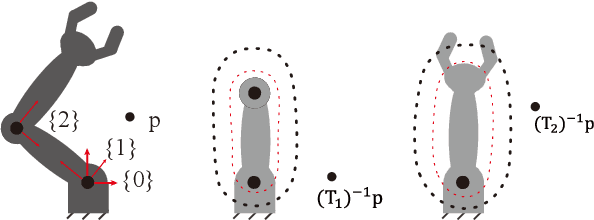
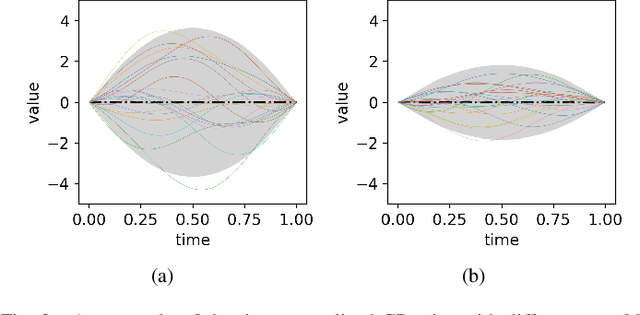
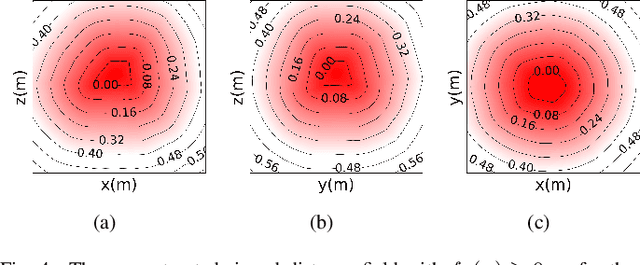
Safe robot motion generation is critical for practical applications from manufacturing to homes. In this work, we proposed a stochastic optimization-based motion generation method to generate collision-free and time-optimal motion for the articulated robot represented by composite signed distance field (SDF) networks. First, we propose composite SDF networks to learn the SDF for articulated robots. The learned composite SDF networks combined with the kinematics of the robot allow for quick and accurate estimates of the minimum distance between the robot and obstacles in a batch fashion. Then, a stochastic optimization-based trajectory planning algorithm generates a spatial-optimized and collision-free trajectory offline with the learned composite SDF networks. This stochastic trajectory planner is formulated as a Bayesian Inference problem with a time-normalized Gaussian process prior and exponential likelihood function. The Gaussian process prior can enforce initial and goal position constraints in Configuration Space. Besides, it can encode the correlation of waypoints in time series. The likelihood function aims at encoding task-related cost terms, such as collision avoidance, trajectory length penalty, boundary avoidance, etc. The kernel updating strategies combined with model-predictive path integral (MPPI) is proposed to solve the maximum a posteriori inference problems. Lastly, we integrate the learned composite SDF networks into the trajectory planning algorithm and apply it to a Franka Emika Panda robot. The simulation and experiment results validate the effectiveness of the proposed method.
Dual Graph Multitask Framework for Imbalanced Delivery Time Estimation
Feb 17, 2023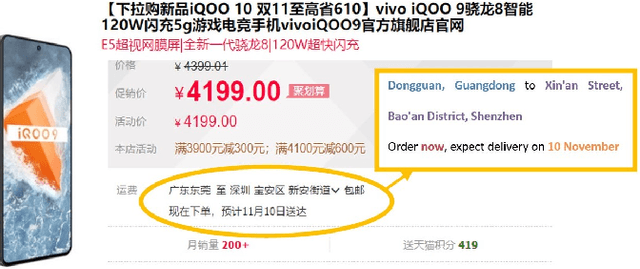
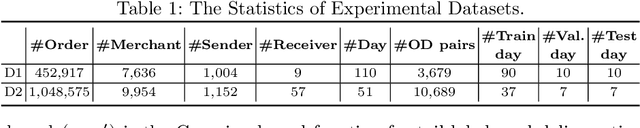
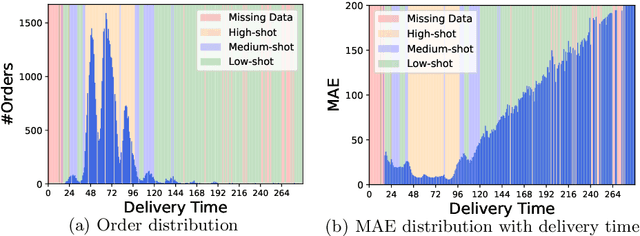
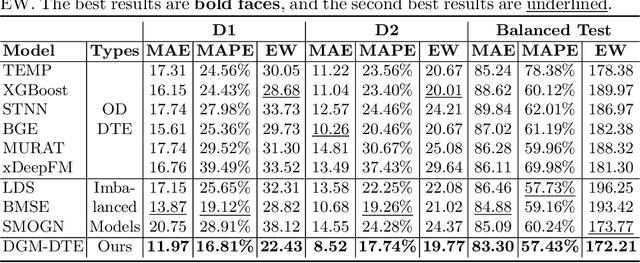
Delivery Time Estimation (DTE) is a crucial component of the e-commerce supply chain that predicts delivery time based on merchant information, sending address, receiving address, and payment time. Accurate DTE can boost platform revenue and reduce customer complaints and refunds. However, the imbalanced nature of industrial data impedes previous models from reaching satisfactory prediction performance. Although imbalanced regression methods can be applied to the DTE task, we experimentally find that they improve the prediction performance of low-shot data samples at the sacrifice of overall performance. To address the issue, we propose a novel Dual Graph Multitask framework for imbalanced Delivery Time Estimation (DGM-DTE). Our framework first classifies package delivery time as head and tail data. Then, a dual graph-based model is utilized to learn representations of the two categories of data. In particular, DGM-DTE re-weights the embedding of tail data by estimating its kernel density. We fuse two graph-based representations to capture both high- and low-shot data representations. Experiments on real-world Taobao logistics datasets demonstrate the superior performance of DGM-DTE compared to baselines.
A Content Adaptive Learnable Time-Frequency Representation For Audio Signal Processing
Mar 18, 2023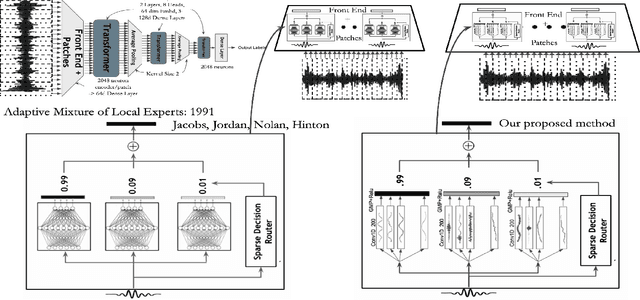
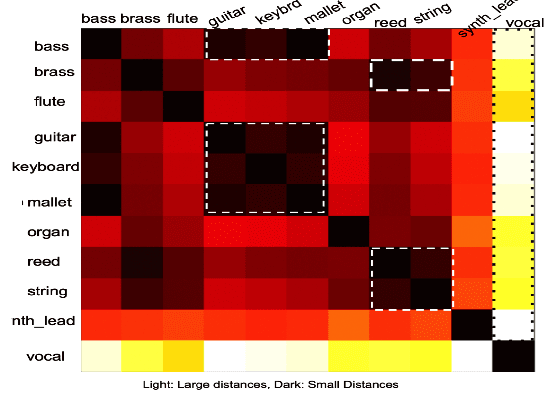
We propose a learnable content adaptive front end for audio signal processing. Before the modern advent of deep learning, we used fixed representation non-learnable front-ends like spectrogram or mel-spectrogram with/without neural architectures. With convolutional architectures supporting various applications such as ASR and acoustic scene understanding, a shift to a learnable front ends occurred in which both the type of basis functions and the weight were learned from scratch and optimized for the particular task of interest. With the shift to transformer-based architectures with no convolutional blocks present, a linear layer projects small waveform patches onto a small latent dimension before feeding them to a transformer architecture. In this work, we propose a way of computing a content-adaptive learnable time-frequency representation. We pass each audio signal through a bank of convolutional filters, each giving a fixed-dimensional vector. It is akin to learning a bank of finite impulse-response filterbanks and passing the input signal through the optimum filter bank depending on the content of the input signal. A content-adaptive learnable time-frequency representation may be more broadly applicable, beyond the experiments in this paper.
Dish-TS: A General Paradigm for Alleviating Distribution Shift in Time Series Forecasting
Mar 14, 2023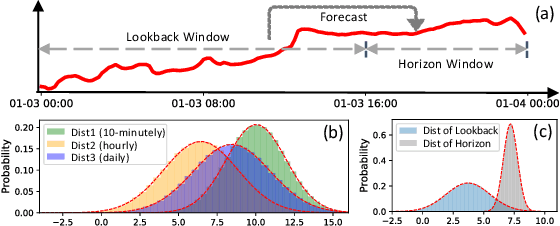
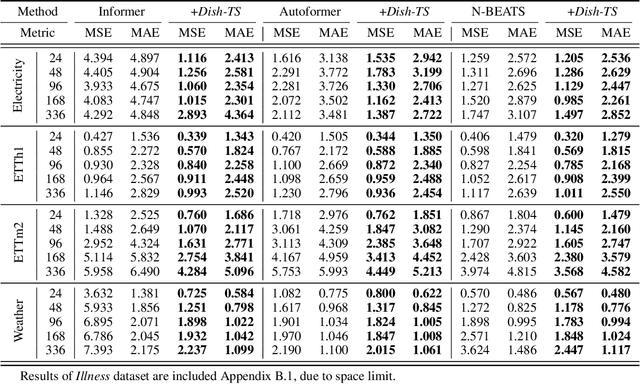
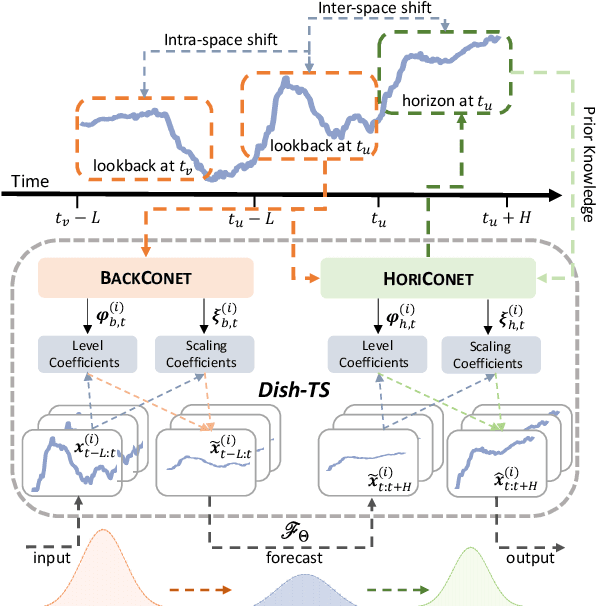
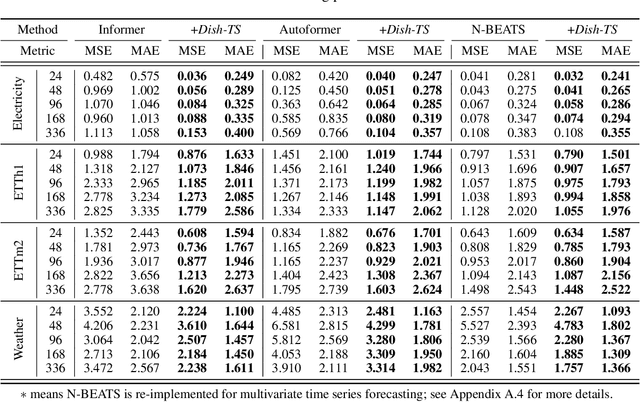
The distribution shift in Time Series Forecasting (TSF), indicating series distribution changes over time, largely hinders the performance of TSF models. Existing works towards distribution shift in time series are mostly limited in the quantification of distribution and, more importantly, overlook the potential shift between lookback and horizon windows. To address above challenges, we systematically summarize the distribution shift in TSF into two categories. Regarding lookback windows as input-space and horizon windows as output-space, there exist (i) intra-space shift, that the distribution within the input-space keeps shifted over time, and (ii) inter-space shift, that the distribution is shifted between input-space and output-space. Then we introduce, Dish-TS, a general neural paradigm for alleviating distribution shift in TSF. Specifically, for better distribution estimation, we propose the coefficient net (CONET), which can be any neural architectures, to map input sequences into learnable distribution coefficients. To relieve intra-space and inter-space shift, we organize Dish-TS as a Dual-CONET framework to separately learn the distribution of input- and output-space, which naturally captures the distribution difference of two spaces. In addition, we introduce a more effective training strategy for intractable CONET learning. Finally, we conduct extensive experiments on several datasets coupled with different state-of-the-art forecasting models. Experimental results show Dish-TS consistently boosts them with a more than 20% average improvement. Code is available.
Leveraging GPT-4 for Food Effect Summarization to Enhance Product-Specific Guidance Development via Iterative Prompting
Jun 28, 2023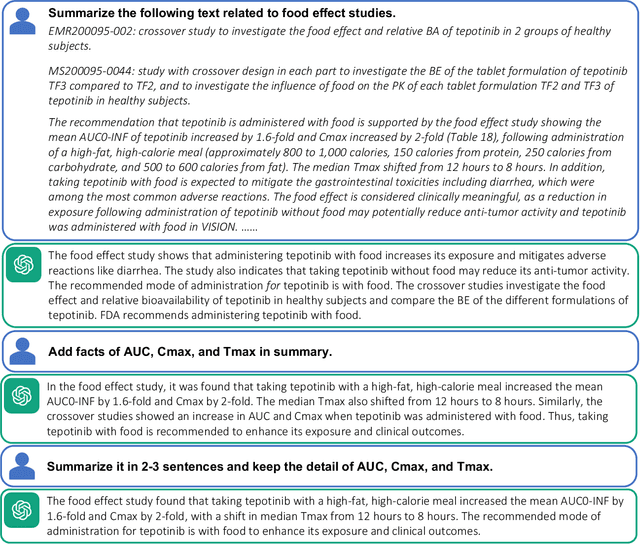
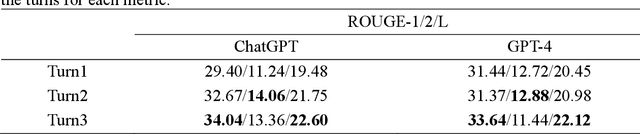

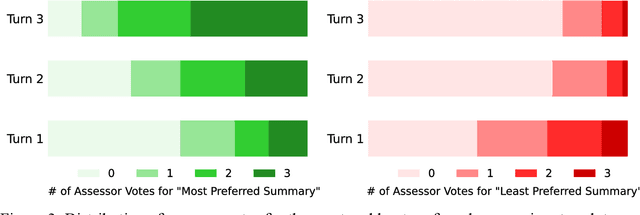
Food effect summarization from New Drug Application (NDA) is an essential component of product-specific guidance (PSG) development and assessment. However, manual summarization of food effect from extensive drug application review documents is time-consuming, which arouses a need to develop automated methods. Recent advances in large language models (LLMs) such as ChatGPT and GPT-4, have demonstrated great potential in improving the effectiveness of automated text summarization, but its ability regarding the accuracy in summarizing food effect for PSG assessment remains unclear. In this study, we introduce a simple yet effective approach, iterative prompting, which allows one to interact with ChatGPT or GPT-4 more effectively and efficiently through multi-turn interaction. Specifically, we propose a three-turn iterative prompting approach to food effect summarization in which the keyword-focused and length-controlled prompts are respectively provided in consecutive turns to refine the quality of the generated summary. We conduct a series of extensive evaluations, ranging from automated metrics to FDA professionals and even evaluation by GPT-4, on 100 NDA review documents selected over the past five years. We observe that the summary quality is progressively improved throughout the process. Moreover, we find that GPT-4 performs better than ChatGPT, as evaluated by FDA professionals (43% vs. 12%) and GPT-4 (64% vs. 35%). Importantly, all the FDA professionals unanimously rated that 85% of the summaries generated by GPT-4 are factually consistent with the golden reference summary, a finding further supported by GPT-4 rating of 72% consistency. These results strongly suggest a great potential for GPT-4 to draft food effect summaries that could be reviewed by FDA professionals, thereby improving the efficiency of PSG assessment cycle and promoting the generic drug product development.
Summarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023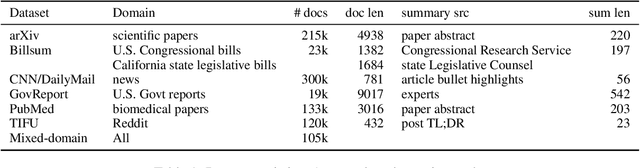
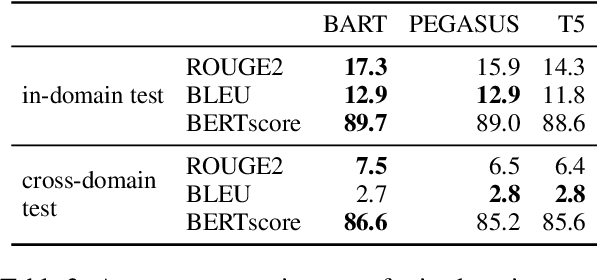
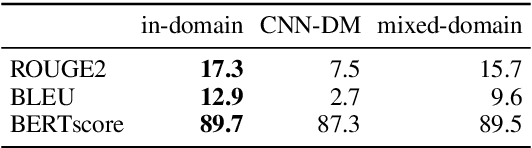
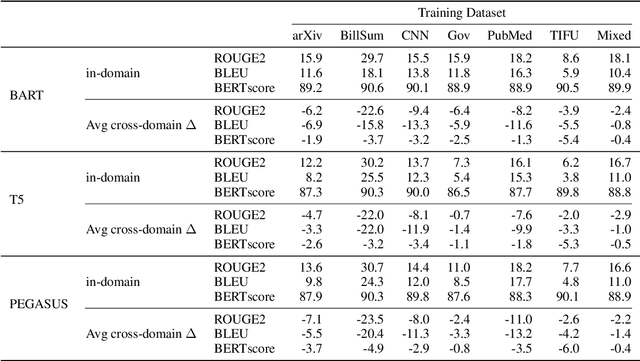
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.