 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Summarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023
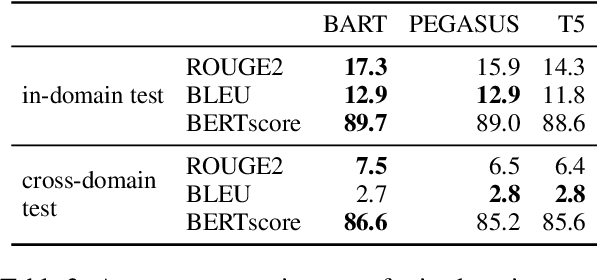
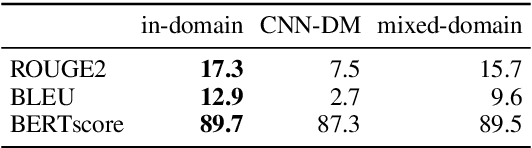
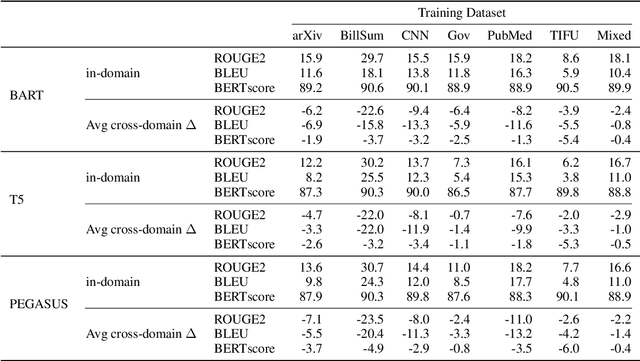
Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.
EVD Surgical Guidance with Retro-Reflective Tool Tracking and Spatial Reconstruction using Head-Mounted Augmented Reality Device
Jun 27, 2023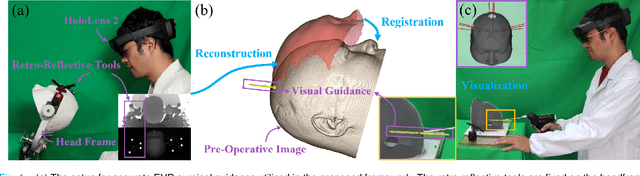

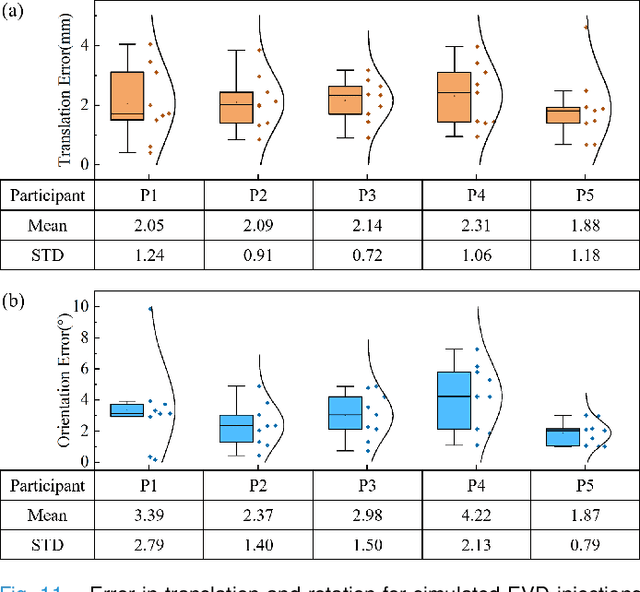
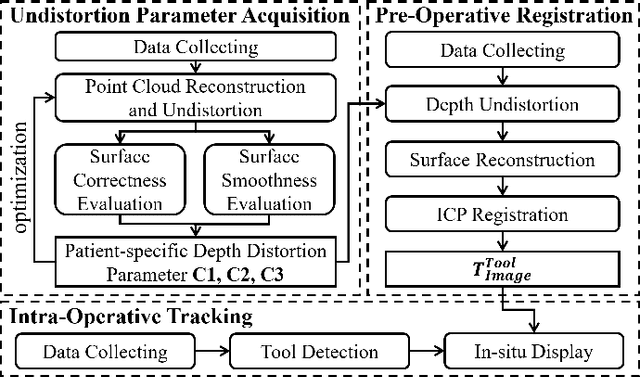
Augmented Reality (AR) has been used to facilitate surgical guidance during External Ventricular Drain (EVD) surgery, reducing the risks of misplacement in manual operations. During this procedure, the pivotal challenge is the accurate estimation of spatial relationship between pre-operative images and actual patient anatomy in AR environment. In this research, we propose a novel framework utilizing Time of Flight (ToF) depth sensors integrated in commercially available AR Head Mounted Devices (HMD) for precise EVD surgical guidance. As previous studies have proven depth errors for ToF sensors, we first conducted a comprehensive assessment for the properties of this error on AR-HMDs. Subsequently, a depth error model and patient-specific model parameter identification method, is introduced for accurate surface information. After that, a tracking procedure combining retro-reflective markers and point clouds is proposed for accurate head tracking, where head surface is reconstructed using ToF sensor data for spatial registration, avoiding fixing tracking targets rigidly on the patient's cranium. Firstly, $7.580\pm 1.488 mm$ ToF sensor depth value error was revealed on human skin, indicating the significance of depth correction. Our results showed that the ToF sensor depth error was reduced by over $85\%$ using proposed depth correction method on head phantoms in different materials. Meanwhile, the head surface reconstructed with corrected depth data achieved sub-millimeter accuracy. Experiment on a sheep head revealed $0.79 mm$ reconstruction error. Furthermore, a user study was conducted for the performance of proposed framework in simulated EVD surgery, where 5 surgeons performed 9 k-wire injections on a head phantom with virtual guidance. Results of this study revealed $2.09 \pm 0.16 mm$ translational accuracy and $2.97\pm 0.91 ^\circ$ orientational accuracy.
Physics-inspired spatiotemporal-graph AI ensemble for gravitational wave detection
Jun 27, 2023
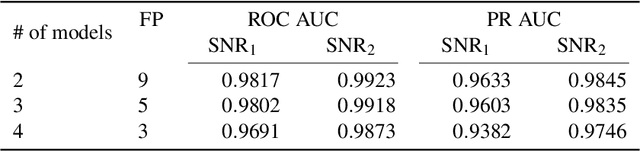
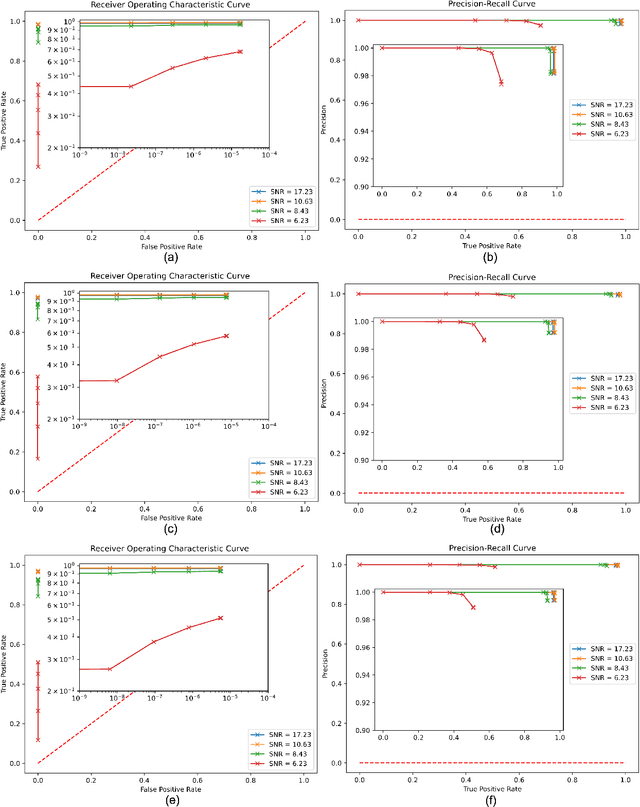
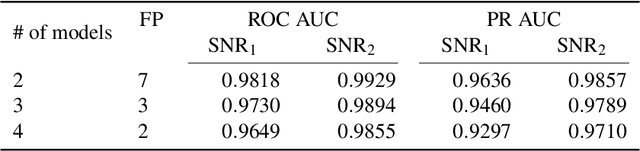
We introduce a novel method for gravitational wave detection that combines: 1) hybrid dilated convolution neural networks to accurately model both short- and long-range temporal sequential information of gravitational wave signals; and 2) graph neural networks to capture spatial correlations among gravitational wave observatories to consistently describe and identify the presence of a signal in a detector network. These spatiotemporal-graph AI models are tested for signal detection of gravitational waves emitted by quasi-circular, non-spinning and quasi-circular, spinning, non-precessing binary black hole mergers. For the latter case, we needed a dataset of 1.2 million modeled waveforms to densely sample this signal manifold. Thus, we reduced time-to-solution by training several AI models in the Polaris supercomputer at the Argonne Leadership Supercomputing Facility within 1.7 hours by distributing the training over 256 NVIDIA A100 GPUs, achieving optimal classification performance. This approach also exhibits strong scaling up to 512 NVIDIA A100 GPUs. We then created ensembles of AI models to process data from a three detector network, namely, the advanced LIGO Hanford and Livingston detectors, and the advanced Virgo detector. An ensemble of 2 AI models achieves state-of-the-art performance for signal detection, and reports seven misclassifications per decade of searched data, whereas an ensemble of 4 AI models achieves optimal performance for signal detection with two misclassifications for every decade of searched data. Finally, when we distributed AI inference over 128 GPUs in the Polaris supercomputer and 128 nodes in the Theta supercomputer, our AI ensemble is capable of processing a decade of gravitational wave data from a three detector network within 3.5 hours.
Predicting the Impact of Batch Refactoring Code Smells on Application Resource Consumption
Jun 27, 2023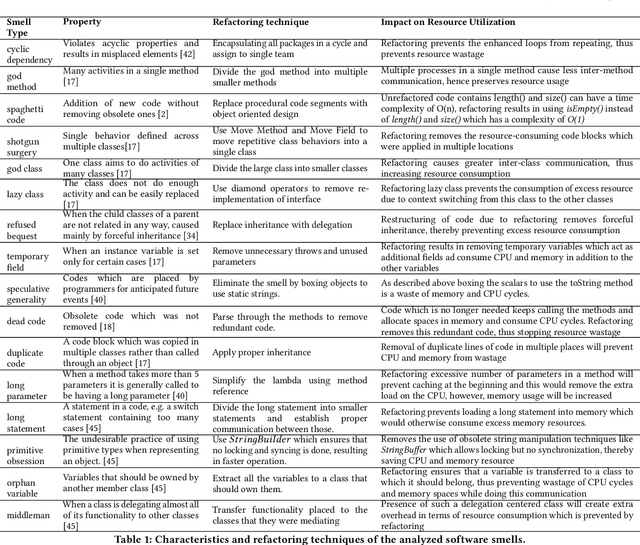
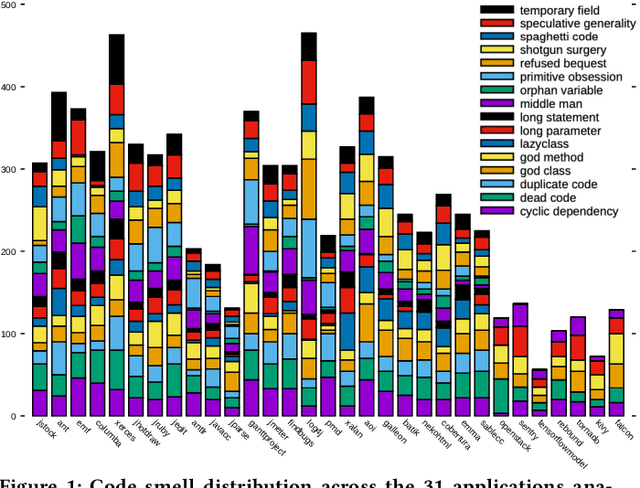
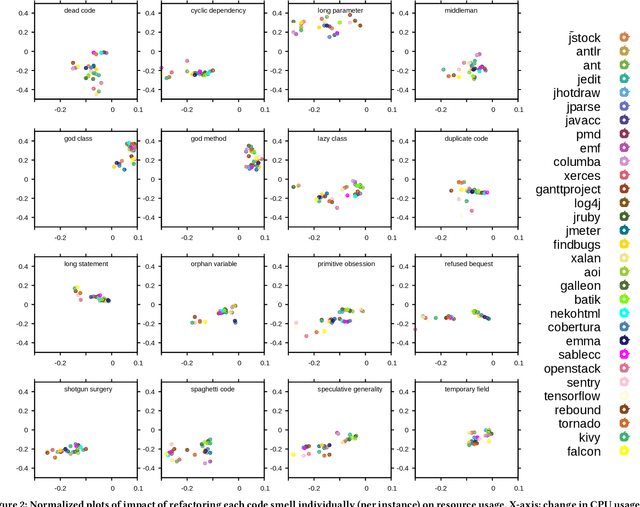
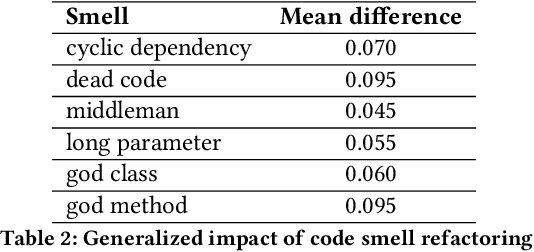
Automated batch refactoring has become a de-facto mechanism to restructure software that may have significant design flaws negatively impacting the code quality and maintainability. Although automated batch refactoring techniques are known to significantly improve overall software quality and maintainability, their impact on resource utilization is not well studied. This paper aims to bridge the gap between batch refactoring code smells and consumption of resources. It determines the relationship between software code smell batch refactoring, and resource consumption. Next, it aims to design algorithms to predict the impact of code smell refactoring on resource consumption. This paper investigates 16 code smell types and their joint effect on resource utilization for 31 open source applications. It provides a detailed empirical analysis of the change in application CPU and memory utilization after refactoring specific code smells in isolation and in batches. This analysis is then used to train regression algorithms to predict the impact of batch refactoring on CPU and memory utilization before making any refactoring decisions. Experimental results also show that our ANN-based regression model provides highly accurate predictions for the impact of batch refactoring on resource consumption. It allows the software developers to intelligently decide which code smells they should refactor jointly to achieve high code quality and maintainability without increasing the application resource utilization. This paper responds to the important and urgent need of software engineers across a broad range of software applications, who are looking to refactor code smells and at the same time improve resource consumption. Finally, it brings forward the concept of resource aware code smell refactoring to the most crucial software applications.
Unsupervised Episode Generation for Graph Meta-learning
Jun 27, 2023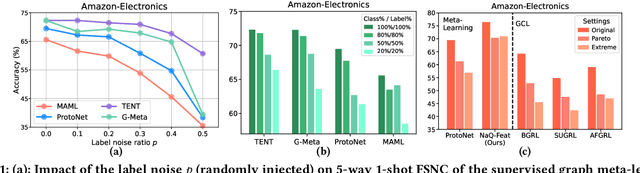
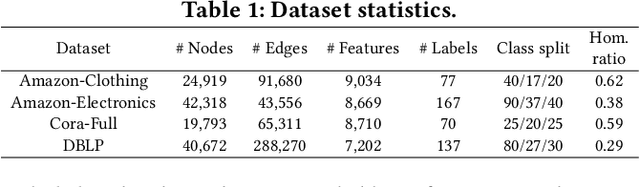
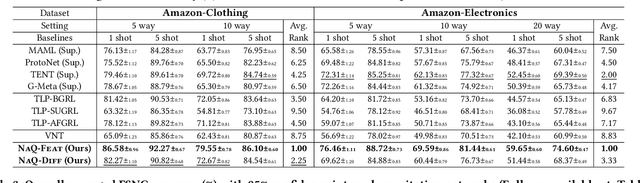
In this paper, we investigate Unsupervised Episode Generation methods to solve Few-Shot Node-Classification (FSNC) problem via Meta-learning without labels. Dominant meta-learning methodologies for FSNC were developed under the existence of abundant labeled nodes for training, which however may not be possible to obtain in the real-world. Although few studies have been proposed to tackle the label-scarcity problem, they still rely on a limited amount of labeled data, which hinders the full utilization of the information of all nodes in a graph. Despite the effectiveness of Self-Supervised Learning (SSL) approaches on FSNC without labels, they mainly learn generic node embeddings without consideration on the downstream task to be solved, which may limit its performance. In this work, we propose unsupervised episode generation methods to benefit from their generalization ability for FSNC tasks while resolving label-scarcity problem. We first propose a method that utilizes graph augmentation to generate training episodes called g-UMTRA, which however has several drawbacks, i.e., 1) increased training time due to the computation of augmented features and 2) low applicability to existing baselines. Hence, we propose Neighbors as Queries (NaQ), which generates episodes from structural neighbors found by graph diffusion. Our proposed methods are model-agnostic, that is, they can be plugged into any existing graph meta-learning models, while not sacrificing much of their performance or sometimes even improving them. We provide theoretical insights to support why our unsupervised episode generation methodologies work, and extensive experimental results demonstrate the potential of our unsupervised episode generation methods for graph meta-learning towards FSNC problems.
Exploring the Performance and Efficiency of Transformer Models for NLP on Mobile Devices
Jun 20, 2023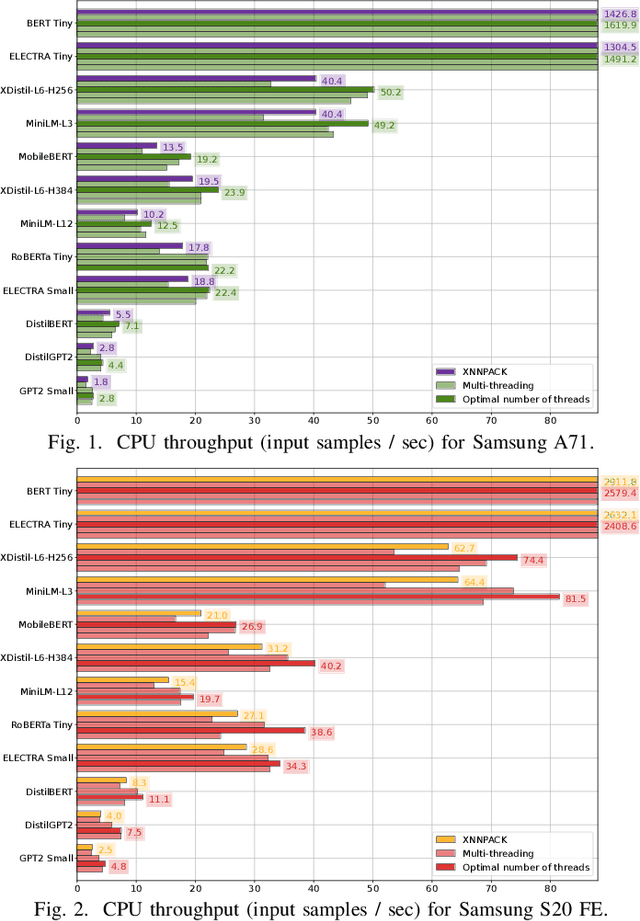
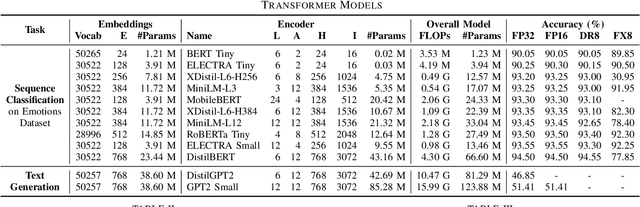


Deep learning (DL) is characterised by its dynamic nature, with new deep neural network (DNN) architectures and approaches emerging every few years, driving the field's advancement. At the same time, the ever-increasing use of mobile devices (MDs) has resulted in a surge of DNN-based mobile applications. Although traditional architectures, like CNNs and RNNs, have been successfully integrated into MDs, this is not the case for Transformers, a relatively new model family that has achieved new levels of accuracy across AI tasks, but poses significant computational challenges. In this work, we aim to make steps towards bridging this gap by examining the current state of Transformers' on-device execution. To this end, we construct a benchmark of representative models and thoroughly evaluate their performance across MDs with different computational capabilities. Our experimental results show that Transformers are not accelerator-friendly and indicate the need for software and hardware optimisations to achieve efficient deployment.
Timestamped Embedding-Matching Acoustic-to-Word CTC ASR
Jun 20, 2023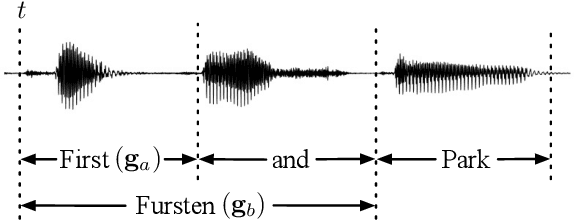
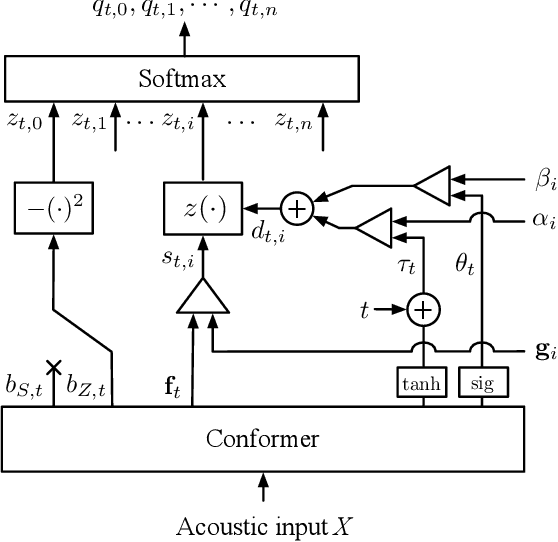
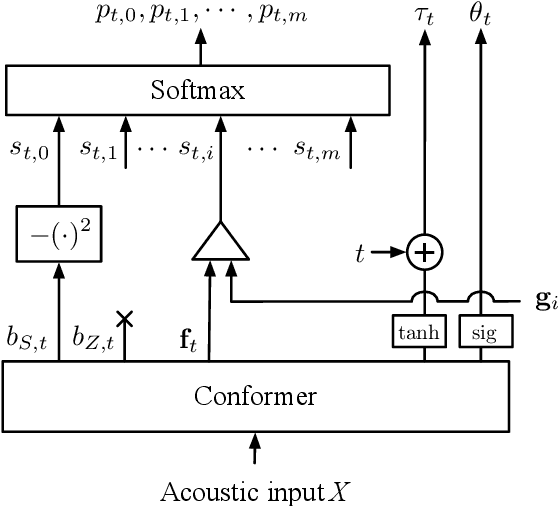
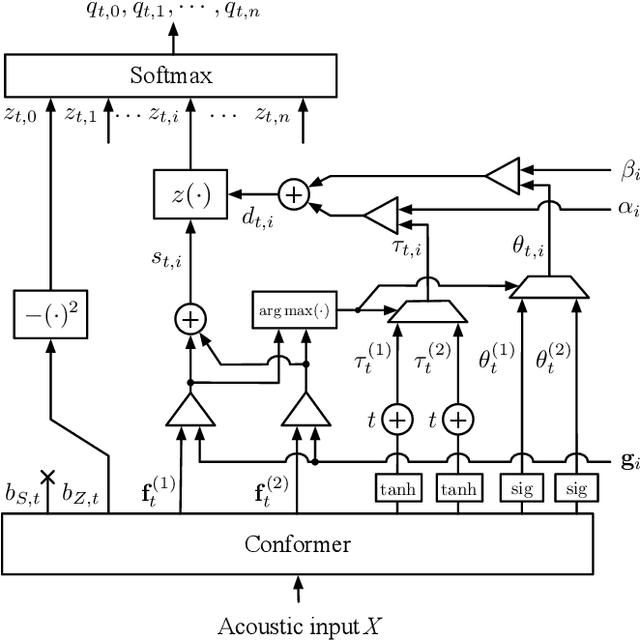
In this work, we describe a novel method of training an embedding-matching word-level connectionist temporal classification (CTC) automatic speech recognizer (ASR) such that it directly produces word start times and durations, required by many real-world applications, in addition to the transcription. The word timestamps enable the ASR to output word segmentations and word confusion networks without relying on a secondary model or forced alignment process when testing. Our proposed system has similar word segmentation accuracy as a hybrid DNN-HMM (Deep Neural Network-Hidden Markov Model) system, with less than 3ms difference in mean absolute error in word start times on TIMIT data. At the same time, we observed less than 5% relative increase in the word error rate compared to the non-timestamped system when using the same audio training data and nearly identical model size. We also contribute more rigorous analysis of multiple-hypothesis embedding-matching ASR in general.
Restless Bandits with Average Reward: Breaking the Uniform Global Attractor Assumption
May 31, 2023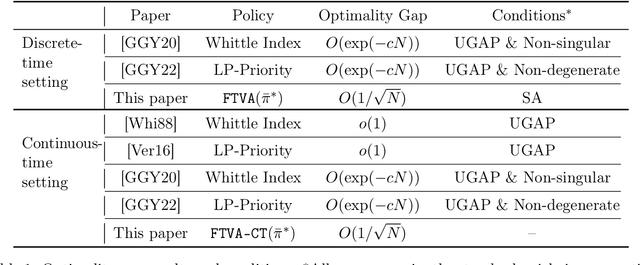
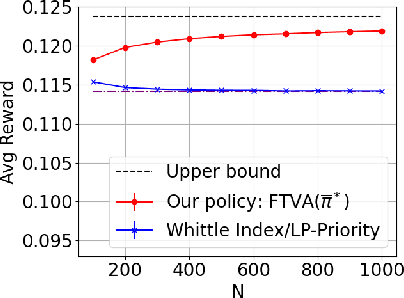
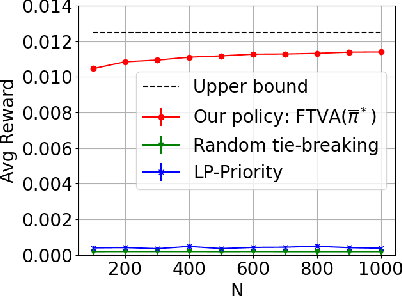
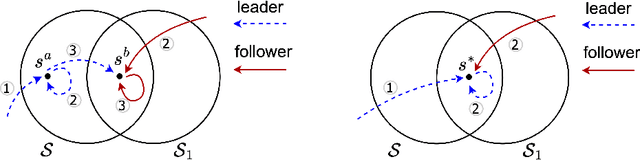
We study the infinite-horizon restless bandit problem with the average reward criterion, under both discrete-time and continuous-time settings. A fundamental question is how to design computationally efficient policies that achieve a diminishing optimality gap as the number of arms, $N$, grows large. Existing results on asymptotical optimality all rely on the uniform global attractor property (UGAP), a complex and challenging-to-verify assumption. In this paper, we propose a general, simulation-based framework that converts any single-armed policy into a policy for the original $N$-armed problem. This is accomplished by simulating the single-armed policy on each arm and carefully steering the real state towards the simulated state. Our framework can be instantiated to produce a policy with an $O(1/\sqrt{N})$ optimality gap. In the discrete-time setting, our result holds under a simpler synchronization assumption, which covers some problem instances that do not satisfy UGAP. More notably, in the continuous-time setting, our result does not require any additional assumptions beyond the standard unichain condition. In both settings, we establish the first asymptotic optimality result that does not require UGAP.
Multi-Agent Deep Reinforcement Learning for Dynamic Avatar Migration in AIoT-enabled Vehicular Metaverses with Trajectory Prediction
Jun 26, 2023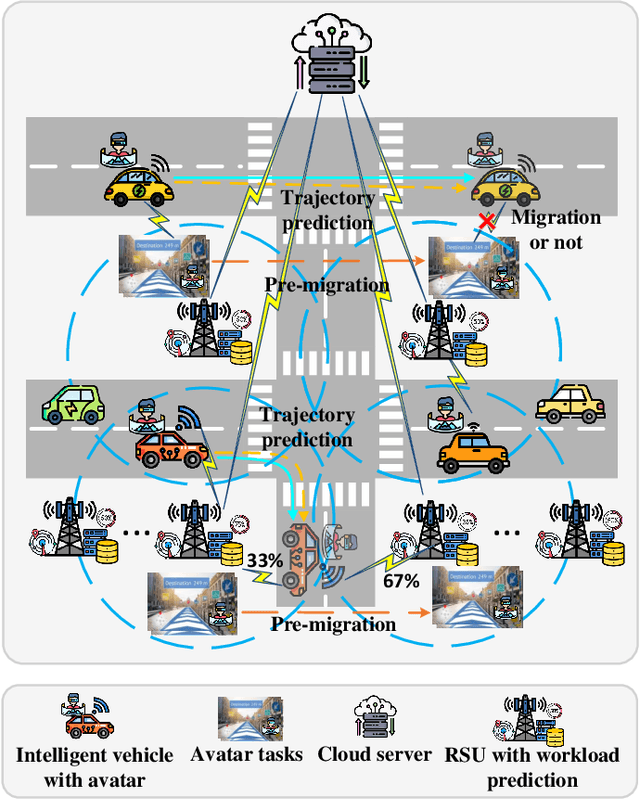
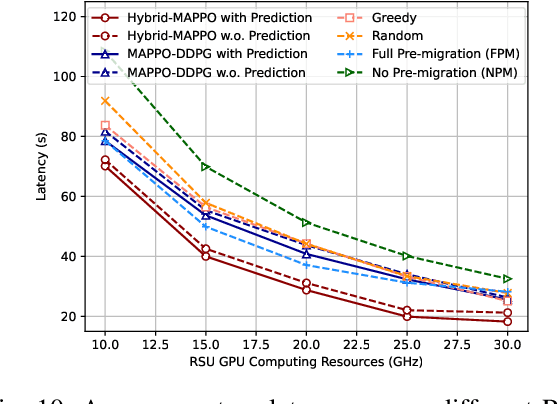
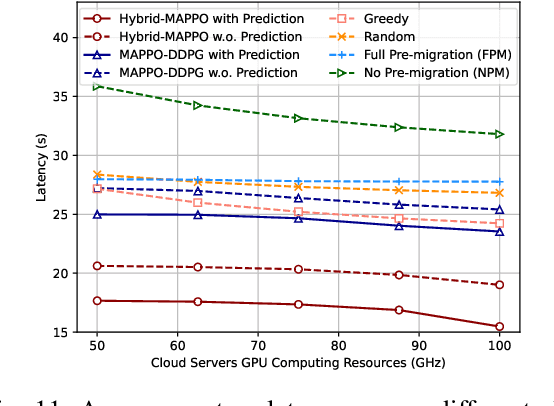
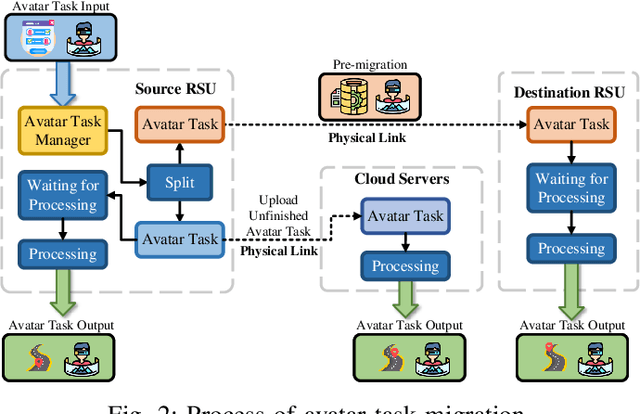
Avatars, as promising digital assistants in Vehicular Metaverses, can enable drivers and passengers to immerse in 3D virtual spaces, serving as a practical emerging example of Artificial Intelligence of Things (AIoT) in intelligent vehicular environments. The immersive experience is achieved through seamless human-avatar interaction, e.g., augmented reality navigation, which requires intensive resources that are inefficient and impractical to process on intelligent vehicles locally. Fortunately, offloading avatar tasks to RoadSide Units (RSUs) or cloud servers for remote execution can effectively reduce resource consumption. However, the high mobility of vehicles, the dynamic workload of RSUs, and the heterogeneity of RSUs pose novel challenges to making avatar migration decisions. To address these challenges, in this paper, we propose a dynamic migration framework for avatar tasks based on real-time trajectory prediction and Multi-Agent Deep Reinforcement Learning (MADRL). Specifically, we propose a model to predict the future trajectories of intelligent vehicles based on their historical data, indicating the future workloads of RSUs.Based on the expected workloads of RSUs, we formulate the avatar task migration problem as a long-term mixed integer programming problem. To tackle this problem efficiently, the problem is transformed into a Partially Observable Markov Decision Process (POMDP) and solved by multiple DRL agents with hybrid continuous and discrete actions in decentralized. Numerical results demonstrate that our proposed algorithm can effectively reduce the latency of executing avatar tasks by around 25% without prediction and 30% with prediction and enhance user immersive experiences in the AIoT-enabled Vehicular Metaverse (AeVeM).
Video object detection for privacy-preserving patient monitoring in intensive care
Jun 26, 2023

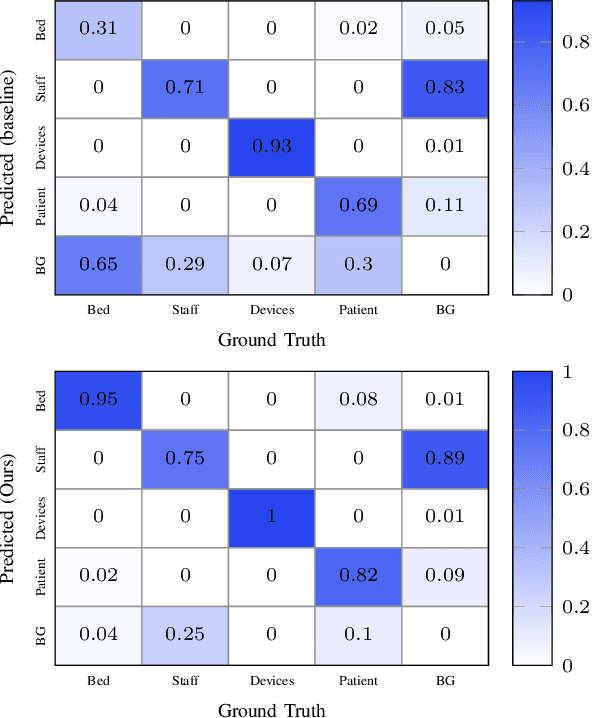
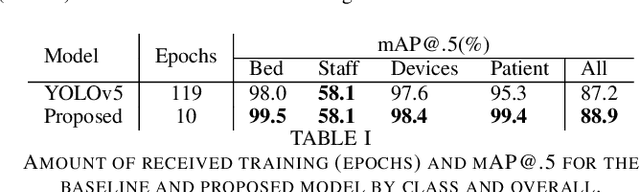
Patient monitoring in intensive care units, although assisted by biosensors, needs continuous supervision of staff. To reduce the burden on staff members, IT infrastructures are built to record monitoring data and develop clinical decision support systems. These systems, however, are vulnerable to artifacts (e.g. muscle movement due to ongoing treatment), which are often indistinguishable from real and potentially dangerous signals. Video recordings could facilitate the reliable classification of biosignals using object detection (OD) methods to find sources of unwanted artifacts. Due to privacy restrictions, only blurred videos can be stored, which severely impairs the possibility to detect clinically relevant events such as interventions or changes in patient status with standard OD methods. Hence, new kinds of approaches are necessary that exploit every kind of available information due to the reduced information content of blurred footage and that are at the same time easily implementable within the IT infrastructure of a normal hospital. In this paper, we propose a new method for exploiting information in the temporal succession of video frames. To be efficiently implementable using off-the-shelf object detectors that comply with given hardware constraints, we repurpose the image color channels to account for temporal consistency, leading to an improved detection rate of the object classes. Our method outperforms a standard YOLOv5 baseline model by +1.7% mAP@.5 while also training over ten times faster on our proprietary dataset. We conclude that this approach has shown effectiveness in the preliminary experiments and holds potential for more general video OD in the future.