 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inferring networks from time series: a neural approach
Mar 30, 2023
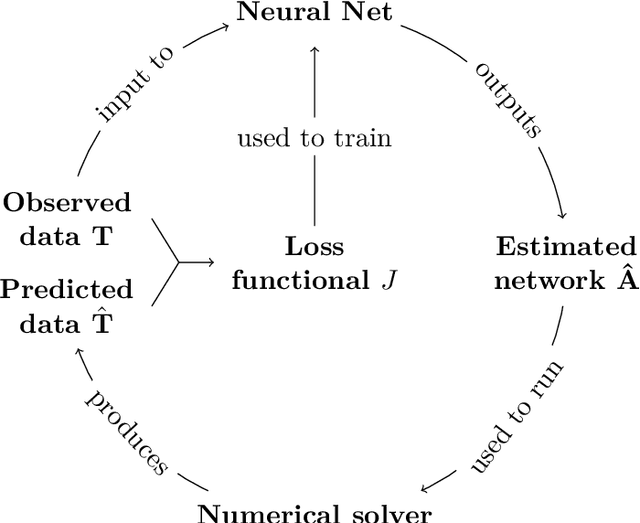
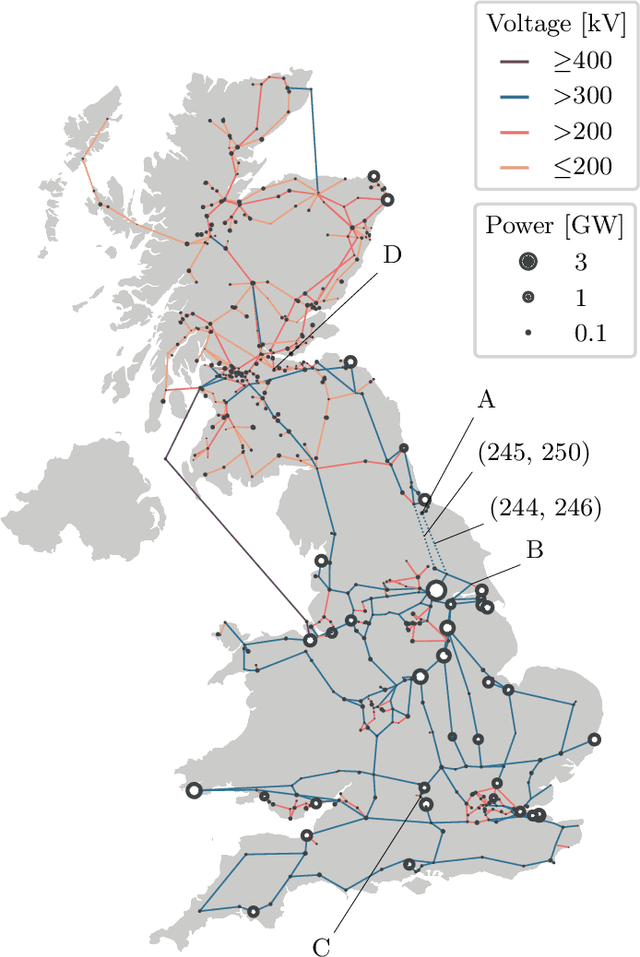
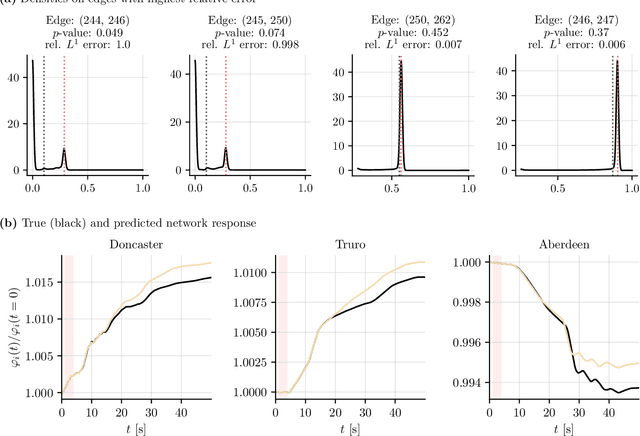
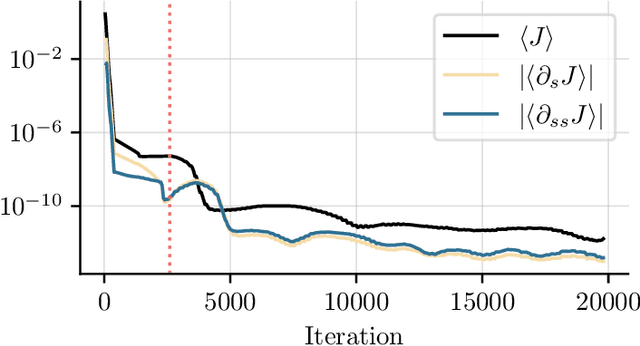
Network structures underlie the dynamics of many complex phenomena, from gene regulation and foodwebs to power grids and social media. Yet, as they often cannot be observed directly, their connectivities must be inferred from observations of their emergent dynamics. In this work we present a powerful and fast computational method to infer large network adjacency matrices from time series data using a neural network. Using a neural network provides uncertainty quantification on the prediction in a manner that reflects both the non-convexity of the inference problem as well as the noise on the data. This is useful since network inference problems are typically underdetermined, and a feature that has hitherto been lacking from network inference methods. We demonstrate our method's capabilities by inferring line failure locations in the British power grid from observations of its response to a power cut. Since the problem is underdetermined, many classical statistical tools (e.g. regression) will not be straightforwardly applicable. Our method, in contrast, provides probability densities on each edge, allowing the use of hypothesis testing to make meaningful probabilistic statements about the location of the power cut. We also demonstrate our method's ability to learn an entire cost matrix for a non-linear model from a dataset of economic activity in Greater London. Our method outperforms OLS regression on noisy data in terms of both speed and prediction accuracy, and scales as $N^2$ where OLS is cubic. Since our technique is not specifically engineered for network inference, it represents a general parameter estimation scheme that is applicable to any parameter dimension.
Automatic Trade-off Adaptation in Offline RL
Jun 16, 2023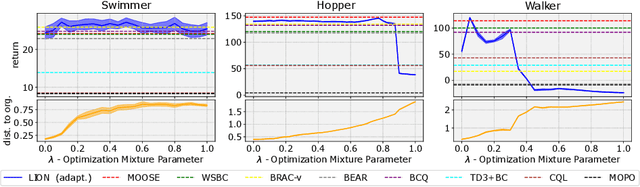
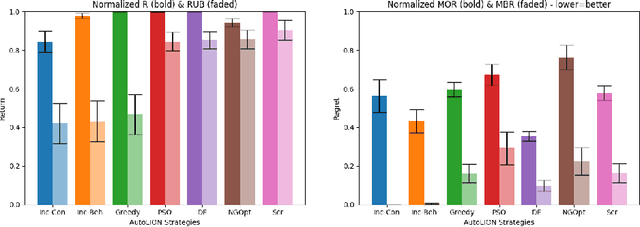
Recently, offline RL algorithms have been proposed that remain adaptive at runtime. For example, the LION algorithm \cite{lion} provides the user with an interface to set the trade-off between behavior cloning and optimality w.r.t. the estimated return at runtime. Experts can then use this interface to adapt the policy behavior according to their preferences and find a good trade-off between conservatism and performance optimization. Since expert time is precious, we extend the methodology with an autopilot that automatically finds the correct parameterization of the trade-off, yielding a new algorithm which we term AutoLION.
Fast light-field 3D microscopy with out-of-distribution detection and adaptation through Conditional Normalizing Flows
Jun 14, 2023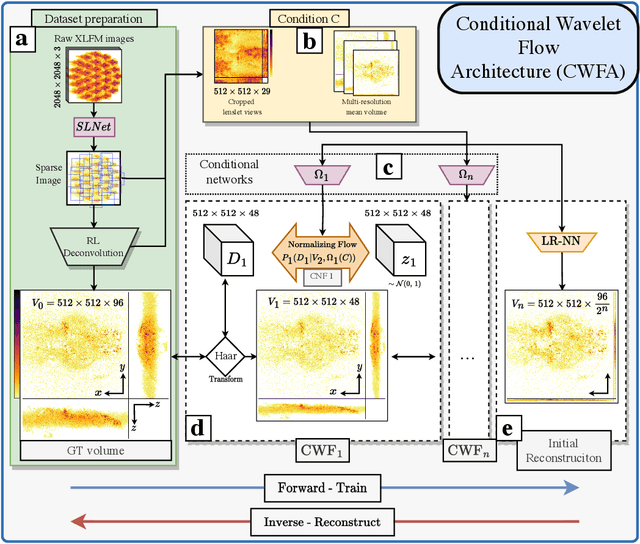
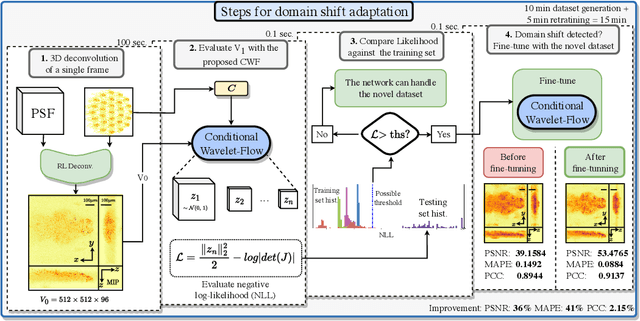
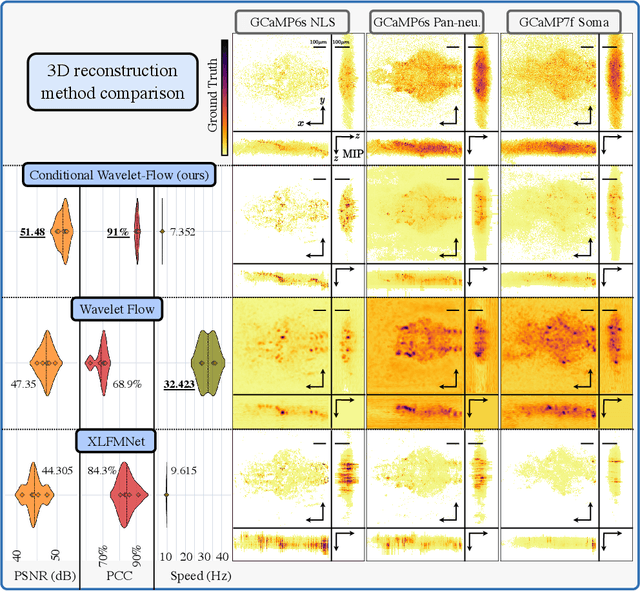
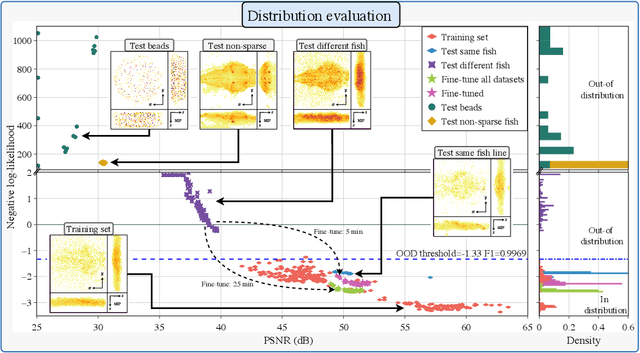
Real-time 3D fluorescence microscopy is crucial for the spatiotemporal analysis of live organisms, such as neural activity monitoring. The eXtended field-of-view light field microscope (XLFM), also known as Fourier light field microscope, is a straightforward, single snapshot solution to achieve this. The XLFM acquires spatial-angular information in a single camera exposure. In a subsequent step, a 3D volume can be algorithmically reconstructed, making it exceptionally well-suited for real-time 3D acquisition and potential analysis. Unfortunately, traditional reconstruction methods (like deconvolution) require lengthy processing times (0.0220 Hz), hampering the speed advantages of the XLFM. Neural network architectures can overcome the speed constraints at the expense of lacking certainty metrics, which renders them untrustworthy for the biomedical realm. This work proposes a novel architecture to perform fast 3D reconstructions of live immobilized zebrafish neural activity based on a conditional normalizing flow. It reconstructs volumes at 8 Hz spanning 512x512x96 voxels, and it can be trained in under two hours due to the small dataset requirements (10 image-volume pairs). Furthermore, normalizing flows allow for exact Likelihood computation, enabling distribution monitoring, followed by out-of-distribution detection and retraining of the system when a novel sample is detected. We evaluate the proposed method on a cross-validation approach involving multiple in-distribution samples (genetically identical zebrafish) and various out-of-distribution ones.
Semi-supervised Cell Recognition under Point Supervision
Jun 14, 2023Cell recognition is a fundamental task in digital histopathology image analysis. Point-based cell recognition (PCR) methods normally require a vast number of annotations, which is extremely costly, time-consuming and labor-intensive. Semi-supervised learning (SSL) can provide a shortcut to make full use of cell information in gigapixel whole slide images without exhaustive labeling. However, research into semi-supervised point-based cell recognition (SSPCR) remains largely overlooked. Previous SSPCR works are all built on density map-based PCR models, which suffer from unsatisfactory accuracy, slow inference speed and high sensitivity to hyper-parameters. To address these issues, end-to-end PCR models are proposed recently. In this paper, we develop a SSPCR framework suitable for the end-to-end PCR models for the first time. Overall, we use the current models to generate pseudo labels for unlabeled images, which are in turn utilized to supervise the models training. Besides, we introduce a co-teaching strategy to overcome the confirmation bias problem that generally exists in self-training. A distribution alignment technique is also incorporated to produce high-quality, unbiased pseudo labels for unlabeled data. Experimental results on four histopathology datasets concerning different types of staining styles show the effectiveness and versatility of the proposed framework. Code is available at \textcolor{magenta}{\url{https://github.com/windygooo/SSPCR}
AMRs Assemble! Learning to Ensemble with Autoregressive Models for AMR Parsing
Jun 19, 2023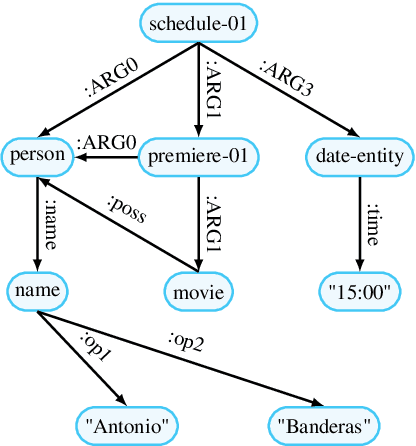

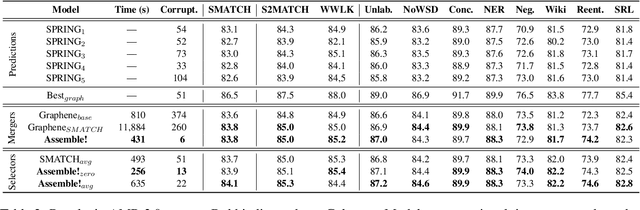
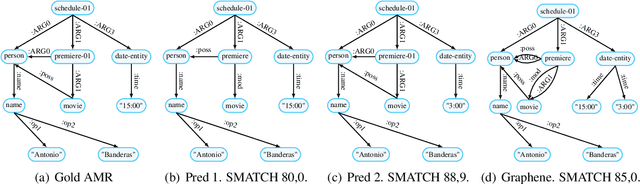
In this paper, we examine the current state-of-the-art in AMR parsing, which relies on ensemble strategies by merging multiple graph predictions. Our analysis reveals that the present models often violate AMR structural constraints. To address this issue, we develop a validation method, and show how ensemble models can exploit SMATCH metric weaknesses to obtain higher scores, but sometimes result in corrupted graphs. Additionally, we highlight the demanding need to compute the SMATCH score among all possible predictions. To overcome these challenges, we propose two novel ensemble strategies based on Transformer models, improving robustness to structural constraints, while also reducing the computational time. Our methods provide new insights for enhancing AMR parsers and metrics. Our code is available at \href{https://www.github.com/babelscape/AMRs-Assemble}{github.com/babelscape/AMRs-Assemble}.
Generating Oscillation Activity with Echo State Network to Mimic the Behavior of a Simple Central Pattern Generator
Jun 19, 2023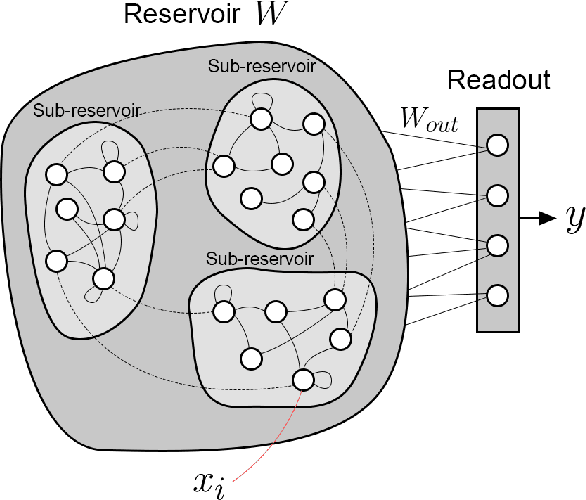
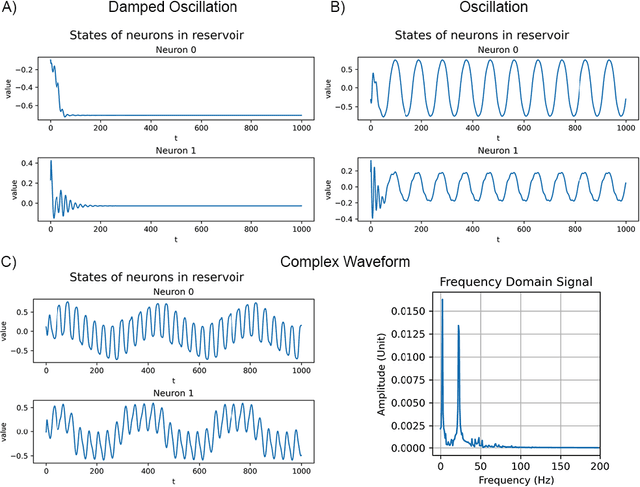
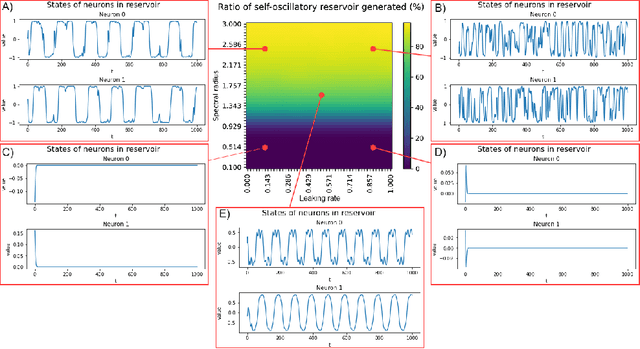
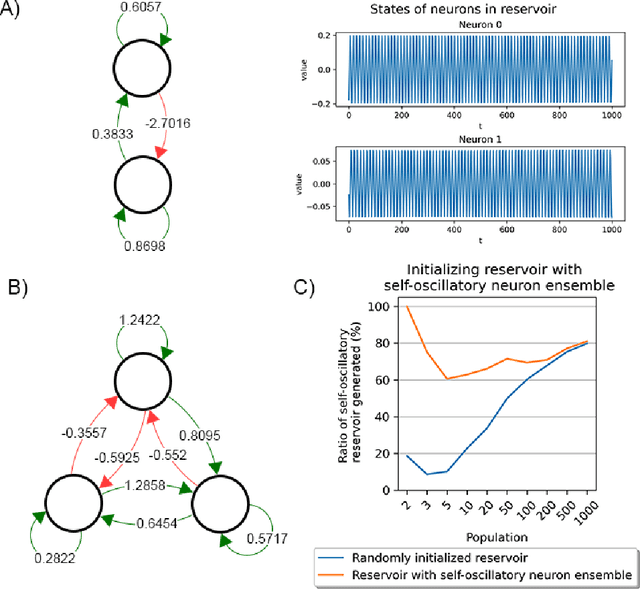
This paper presents a method for reproducing a simple central pattern generator (CPG) using a modified Echo State Network (ESN). Conventionally, the dynamical reservoir needs to be damped to stabilize and preserve memory. However, we find that a reservoir that develops oscillatory activity without any external excitation can mimic the behaviour of a simple CPG in biological systems. We define the specific neuron ensemble required for generating oscillations in the reservoir and demonstrate how adjustments to the leaking rate, spectral radius, topology, and population size can increase the probability of reproducing these oscillations. The results of the experiments, conducted on the time series simulation tasks, demonstrate that the ESN is able to generate the desired waveform without any input. This approach offers a promising solution for the development of bio-inspired controllers for robotic systems.
Optimal Control of Connected Automated Vehicles with Event-Triggered Control Barrier Functions: a Test Bed for Safe Optimal Merging
Jun 02, 2023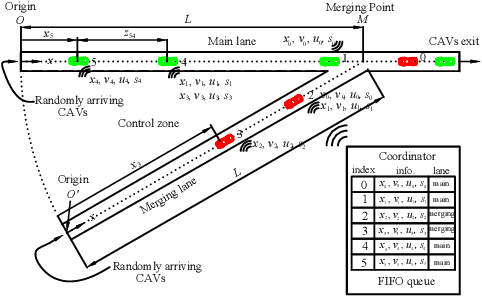
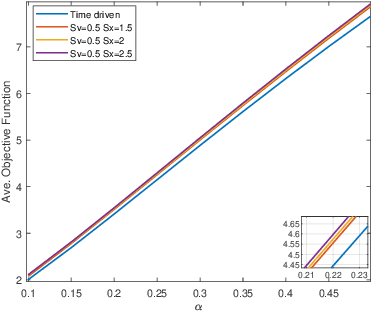
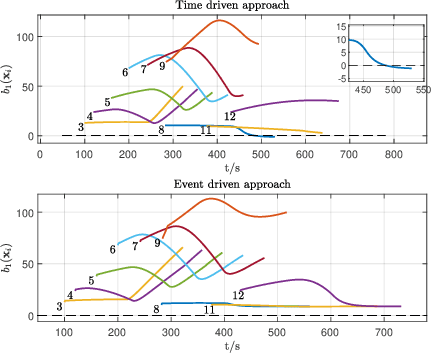
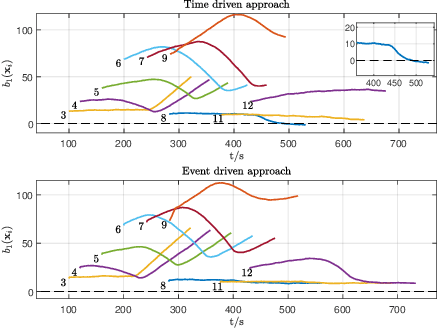
We address the problem of controlling Connected and Automated Vehicles (CAVs) in conflict areas of a traffic network subject to hard safety constraints. It has been shown that such problems can be solved through a combination of tractable optimal control problems and Control Barrier Functions (CBFs) that guarantee the satisfaction of all constraints. These solutions can be reduced to a sequence of Quadratic Programs (QPs) which are efficiently solved on line over discrete time steps. However, guaranteeing the feasibility of the CBF-based QP method within each discretized time interval requires the careful selection of time steps which need to be sufficiently small. This creates computational requirements and communication rates between agents which may hinder the controller's application to real CAVs. In this paper, we overcome this limitation by adopting an event-triggered approach for CAVs in a conflict area such that the next QP is triggered by properly defined events with a safety guarantee. We present a laboratory-scale test bed we have developed to emulate merging roadways using mobile robots as CAVs which can be used to demonstrate how the event-triggered scheme is computationally efficient and can handle measurement uncertainties and noise compared to time-driven control while guaranteeing safety.
Free-style and Fast 3D Portrait Synthesis
Jun 28, 2023
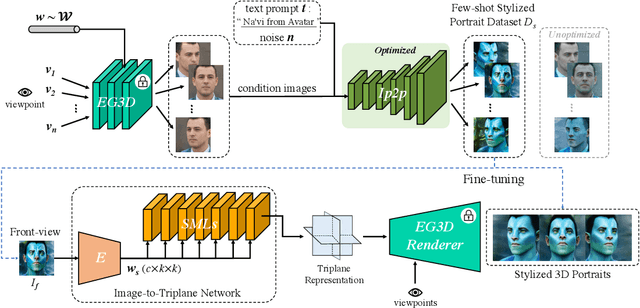


Efficiently generating a free-style 3D portrait with high quality and consistency is a promising yet challenging task. The portrait styles generated by most existing methods are usually restricted by their 3D generators, which are learned in specific facial datasets, such as FFHQ. To get a free-style 3D portrait, one can build a large-scale multi-style database to retrain the 3D generator, or use a off-the-shelf tool to do the style translation. However, the former is time-consuming due to data collection and training process, the latter may destroy the multi-view consistency. To tackle this problem, we propose a fast 3D portrait synthesis framework in this paper, which enable one to use text prompts to specify styles. Specifically, for a given portrait style, we first leverage two generative priors, a 3D-aware GAN generator (EG3D) and a text-guided image editor (Ip2p), to quickly construct a few-shot training set, where the inference process of Ip2p is optimized to make editing more stable. Then we replace original triplane generator of EG3D with a Image-to-Triplane (I2T) module for two purposes: 1) getting rid of the style constraints of pre-trained EG3D by fine-tuning I2T on the few-shot dataset; 2) improving training efficiency by fixing all parts of EG3D except I2T. Furthermore, we construct a multi-style and multi-identity 3D portrait database to demonstrate the scalability and generalization of our method. Experimental results show that our method is capable of synthesizing high-quality 3D portraits with specified styles in a few minutes, outperforming the state-of-the-art.
Image-based Visual Servo Control for Aerial Manipulation Using a Fully-Actuated UAV
Jun 28, 2023

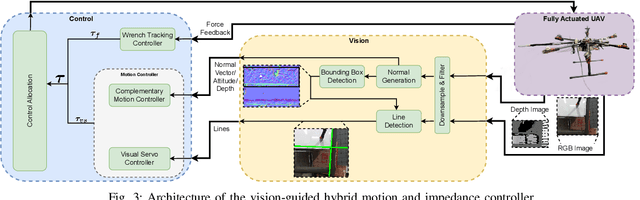
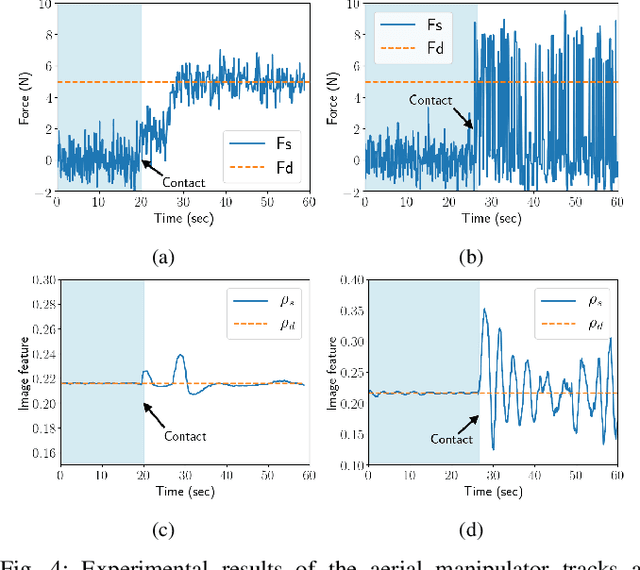
Using Unmanned Aerial Vehicles (UAVs) to perform high-altitude manipulation tasks beyond just passive visual application can reduce the time, cost, and risk of human workers. Prior research on aerial manipulation has relied on either ground truth state estimate or GPS/total station with some Simultaneous Localization and Mapping (SLAM) algorithms, which may not be practical for many applications close to infrastructure with degraded GPS signal or featureless environments. Visual servo can avoid the need to estimate robot pose. Existing works on visual servo for aerial manipulation either address solely end-effector position control or rely on precise velocity measurement and pre-defined visual visual marker with known pattern. Furthermore, most of previous work used under-actuated UAVs, resulting in complicated mechanical and hence control design for the end-effector. This paper develops an image-based visual servo control strategy for bridge maintenance using a fully-actuated UAV. The main components are (1) a visual line detection and tracking system, (2) a hybrid impedance force and motion control system. Our approach does not rely on either robot pose/velocity estimation from an external localization system or pre-defined visual markers. The complexity of the mechanical system and controller architecture is also minimized due to the fully-actuated nature. Experiments show that the system can effectively execute motion tracking and force holding using only the visual guidance for the bridge painting. To the best of our knowledge, this is one of the first studies on aerial manipulation using visual servo that is capable of achieving both motion and force control without the need of external pose/velocity information or pre-defined visual guidance.
GPT-Based Models Meet Simulation: How to Efficiently Use Large-Scale Pre-Trained Language Models Across Simulation Tasks
Jun 21, 2023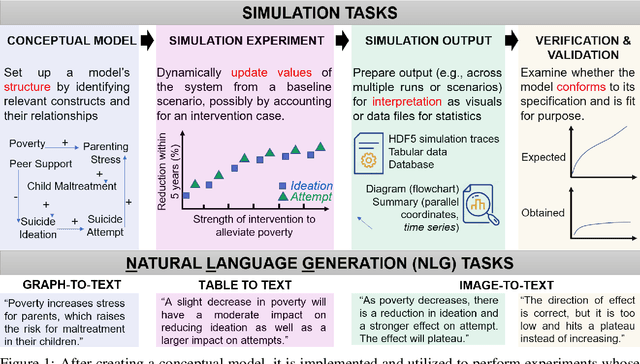
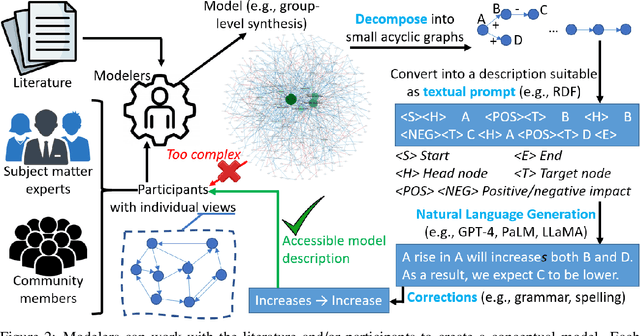
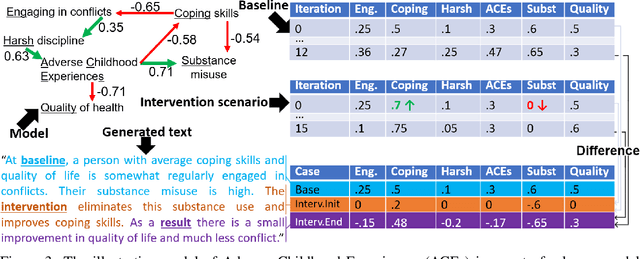
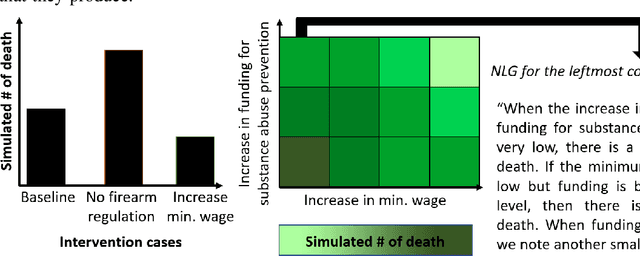
The disruptive technology provided by large-scale pre-trained language models (LLMs) such as ChatGPT or GPT-4 has received significant attention in several application domains, often with an emphasis on high-level opportunities and concerns. This paper is the first examination regarding the use of LLMs for scientific simulations. We focus on four modeling and simulation tasks, each time assessing the expected benefits and limitations of LLMs while providing practical guidance for modelers regarding the steps involved. The first task is devoted to explaining the structure of a conceptual model to promote the engagement of participants in the modeling process. The second task focuses on summarizing simulation outputs, so that model users can identify a preferred scenario. The third task seeks to broaden accessibility to simulation platforms by conveying the insights of simulation visualizations via text. Finally, the last task evokes the possibility of explaining simulation errors and providing guidance to resolve them.