 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Synthetic Demographic Data Generation for Card Fraud Detection Using GANs
Jun 29, 2023
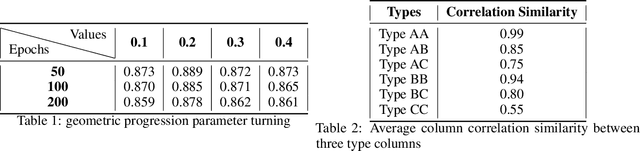
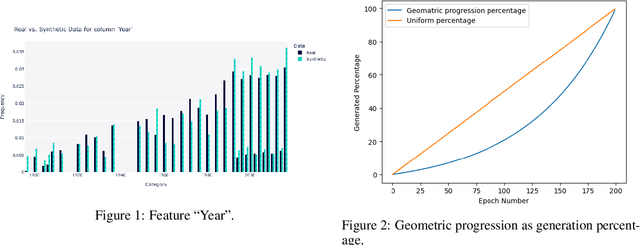
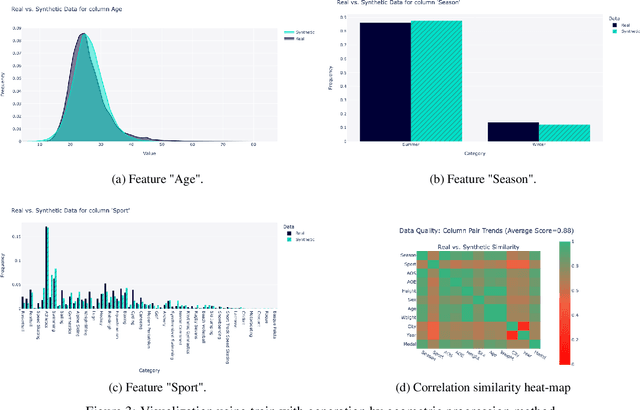
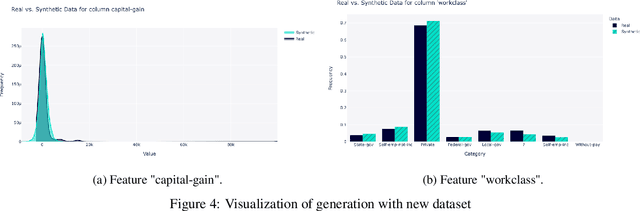
Using machine learning models to generate synthetic data has become common in many fields. Technology to generate synthetic transactions that can be used to detect fraud is also growing fast. Generally, this synthetic data contains only information about the transaction, such as the time, place, and amount of money. It does not usually contain the individual user's characteristics (age and gender are occasionally included). Using relatively complex synthetic demographic data may improve the complexity of transaction data features, thus improving the fraud detection performance. Benefiting from developments of machine learning, some deep learning models have potential to perform better than other well-established synthetic data generation methods, such as microsimulation. In this study, we built a deep-learning Generative Adversarial Network (GAN), called DGGAN, which will be used for demographic data generation. Our model generates samples during model training, which we found important to overcame class imbalance issues. This study can help improve the cognition of synthetic data and further explore the application of synthetic data generation in card fraud detection.
Macro Placement by Wire-Mask-Guided Black-Box Optimization
Jun 29, 2023The development of very large-scale integration (VLSI) technology has posed new challenges for electronic design automation (EDA) techniques in chip floorplanning. During this process, macro placement is an important subproblem, which tries to determine the positions of all macros with the aim of minimizing half-perimeter wirelength (HPWL) and avoiding overlapping. Previous methods include packing-based, analytical and reinforcement learning methods. In this paper, we propose a new black-box optimization (BBO) framework (called WireMask-BBO) for macro placement, by using a wire-mask-guided greedy procedure for objective evaluation. Equipped with different BBO algorithms, WireMask-BBO empirically achieves significant improvements over previous methods, i.e., achieves significantly shorter HPWL by using much less time. Furthermore, it can fine-tune existing placements by treating them as initial solutions, which can bring up to 50% improvement in HPWL. WireMask-BBO has the potential to significantly improve the quality and efficiency of chip floorplanning, which makes it appealing to researchers and practitioners in EDA and will also promote the application of BBO.
Computationally Assisted Quality Control for Public Health Data Streams
Jun 29, 2023Irregularities in public health data streams (like COVID-19 Cases) hamper data-driven decision-making for public health stakeholders. A real-time, computer-generated list of the most important, outlying data points from thousands of daily-updated public health data streams could assist an expert reviewer in identifying these irregularities. However, existing outlier detection frameworks perform poorly on this task because they do not account for the data volume or for the statistical properties of public health streams. Accordingly, we developed FlaSH (Flagging Streams in public Health), a practical outlier detection framework for public health data users that uses simple, scalable models to capture these statistical properties explicitly. In an experiment where human experts evaluate FlaSH and existing methods (including deep learning approaches), FlaSH scales to the data volume of this task, matches or exceeds these other methods in mean accuracy, and identifies the outlier points that users empirically rate as more helpful. Based on these results, FlaSH has been deployed on data streams used by public health stakeholders.
Towards Zero-Shot Scale-Aware Monocular Depth Estimation
Jun 29, 2023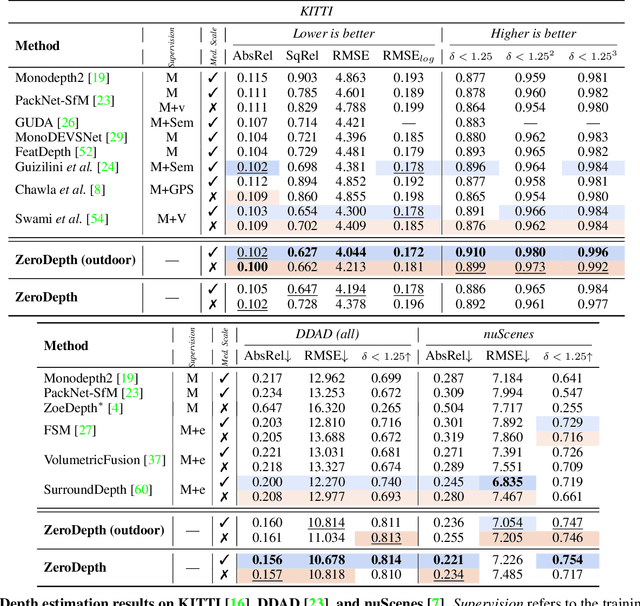
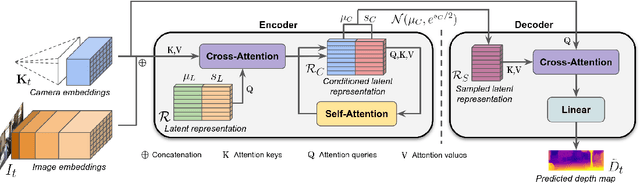
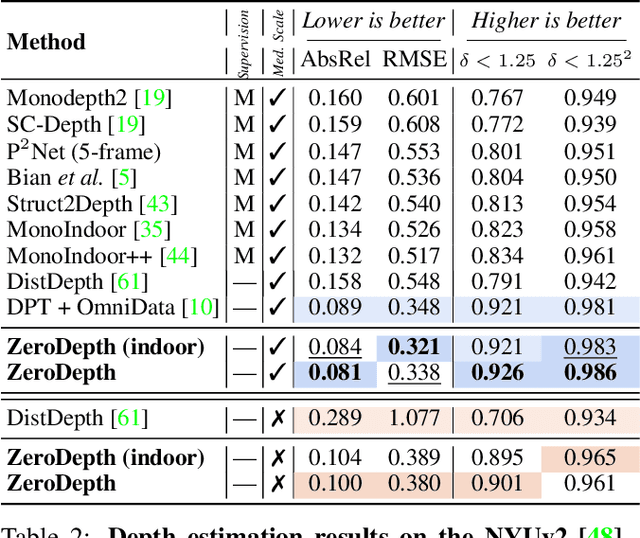
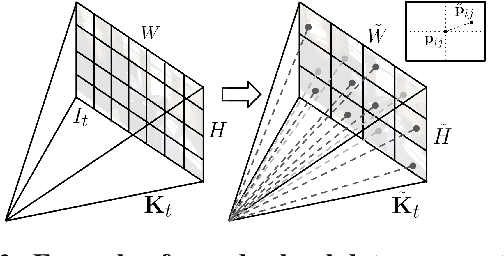
Monocular depth estimation is scale-ambiguous, and thus requires scale supervision to produce metric predictions. Even so, the resulting models will be geometry-specific, with learned scales that cannot be directly transferred across domains. Because of that, recent works focus instead on relative depth, eschewing scale in favor of improved up-to-scale zero-shot transfer. In this work we introduce ZeroDepth, a novel monocular depth estimation framework capable of predicting metric scale for arbitrary test images from different domains and camera parameters. This is achieved by (i) the use of input-level geometric embeddings that enable the network to learn a scale prior over objects; and (ii) decoupling the encoder and decoder stages, via a variational latent representation that is conditioned on single frame information. We evaluated ZeroDepth targeting both outdoor (KITTI, DDAD, nuScenes) and indoor (NYUv2) benchmarks, and achieved a new state-of-the-art in both settings using the same pre-trained model, outperforming methods that train on in-domain data and require test-time scaling to produce metric estimates.
Multi-IMU with Online Self-Consistency for Freehand 3D Ultrasound Reconstruction
Jun 29, 2023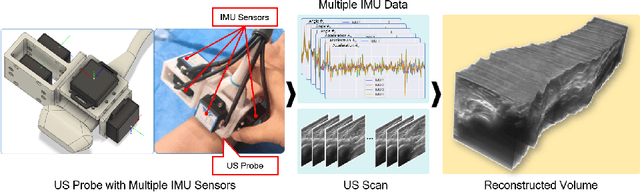
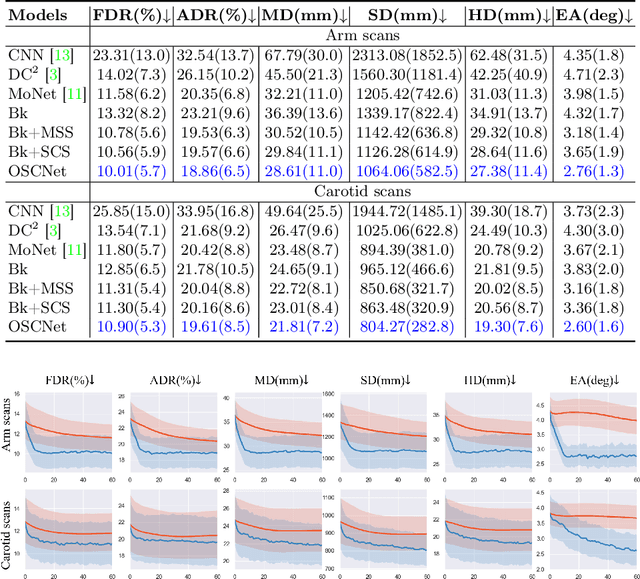
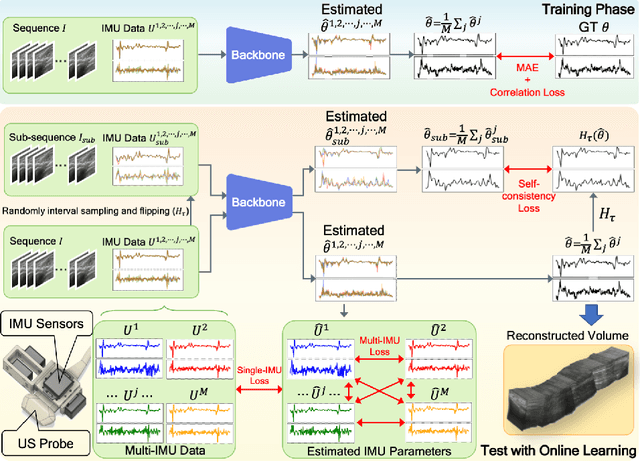
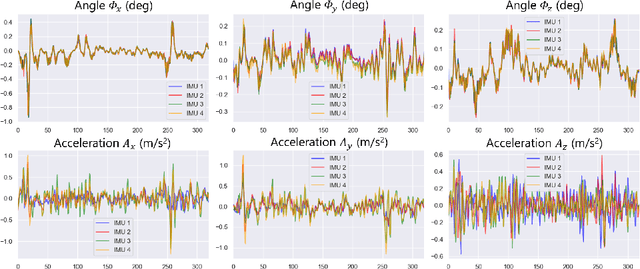
Ultrasound (US) imaging is a popular tool in clinical diagnosis, offering safety, repeatability, and real-time capabilities. Freehand 3D US is a technique that provides a deeper understanding of scanned regions without increasing complexity. However, estimating elevation displacement and accumulation error remains challenging, making it difficult to infer the relative position using images alone. The addition of external lightweight sensors has been proposed to enhance reconstruction performance without adding complexity, which has been shown to be beneficial. We propose a novel online self-consistency network (OSCNet) using multiple inertial measurement units (IMUs) to improve reconstruction performance. OSCNet utilizes a modal-level self-supervised strategy to fuse multiple IMU information and reduce differences between reconstruction results obtained from each IMU data. Additionally, a sequence-level self-consistency strategy is proposed to improve the hierarchical consistency of prediction results among the scanning sequence and its sub-sequences. Experiments on large-scale arm and carotid datasets with multiple scanning tactics demonstrate that our OSCNet outperforms previous methods, achieving state-of-the-art reconstruction performance.
Joint Level Generation and Translation Using Gameplay Videos
Jun 29, 2023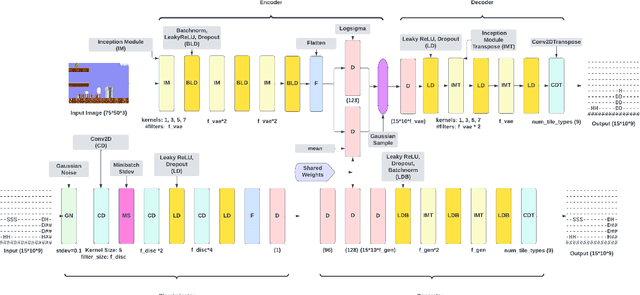
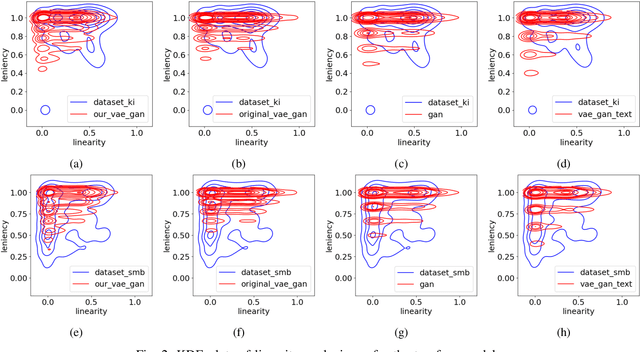
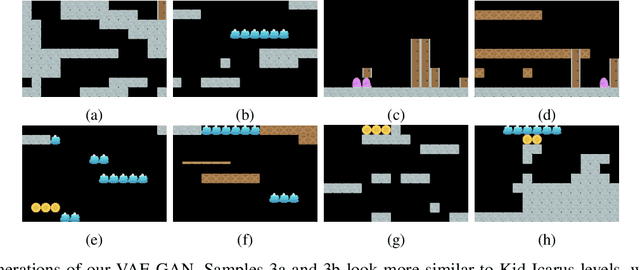
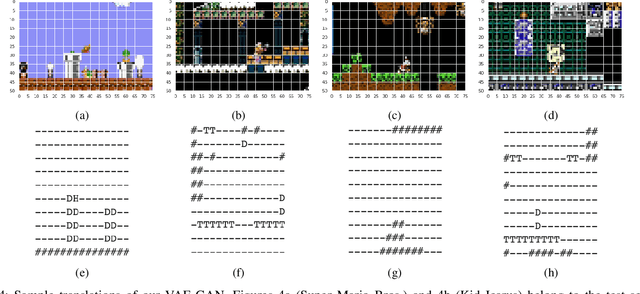
Procedural Content Generation via Machine Learning (PCGML) faces a significant hurdle that sets it apart from other fields, such as image or text generation, which is limited annotated data. Many existing methods for procedural level generation via machine learning require a secondary representation besides level images. However, the current methods for obtaining such representations are laborious and time-consuming, which contributes to this problem. In this work, we aim to address this problem by utilizing gameplay videos of two human-annotated games to develop a novel multi-tail framework that learns to perform simultaneous level translation and generation. The translation tail of our framework can convert gameplay video frames to an equivalent secondary representation, while its generation tail can produce novel level segments. Evaluation results and comparisons between our framework and baselines suggest that combining the level generation and translation tasks can lead to an overall improved performance regarding both tasks. This represents a possible solution to limited annotated level data, and we demonstrate the potential for future versions to generalize to unseen games.
* 8 pages, 4 figures
Robustness and Generalization Performance of Deep Learning Models on Cyber-Physical Systems: A Comparative Study
Jun 13, 2023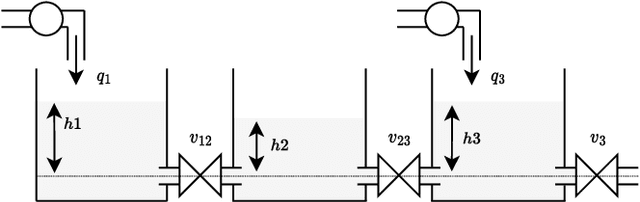
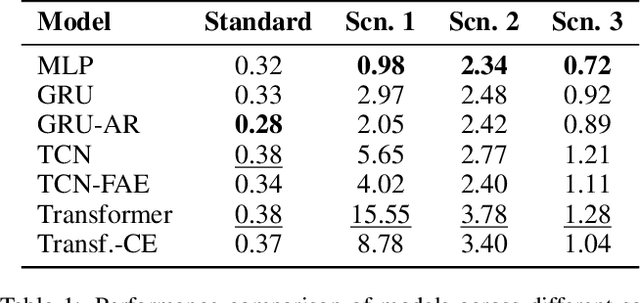
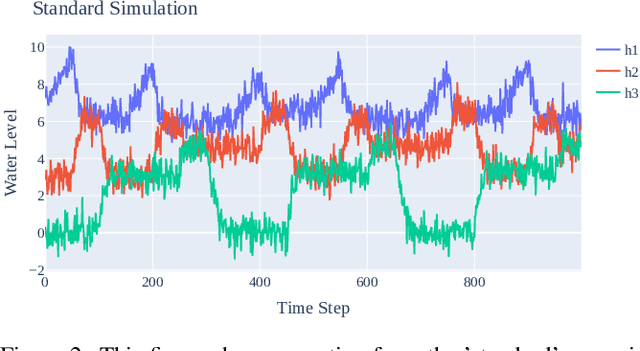
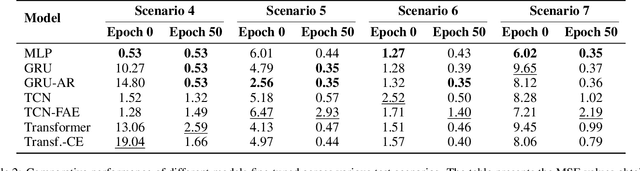
Deep learning (DL) models have seen increased attention for time series forecasting, yet the application on cyber-physical systems (CPS) is hindered by the lacking robustness of these methods. Thus, this study evaluates the robustness and generalization performance of DL architectures on multivariate time series data from CPS. Our investigation focuses on the models' ability to handle a range of perturbations, such as sensor faults and noise, and assesses their impact on overall performance. Furthermore, we test the generalization and transfer learning capabilities of these models by exposing them to out-of-distribution (OOD) samples. These include deviations from standard system operations, while the core dynamics of the underlying physical system are preserved. Additionally, we test how well the models respond to several data augmentation techniques, including added noise and time warping. Our experimental framework utilizes a simulated three-tank system, proposed as a novel benchmark for evaluating the robustness and generalization performance of DL algorithms in CPS data contexts. The findings reveal that certain DL model architectures and training techniques exhibit superior effectiveness in handling OOD samples and various perturbations. These insights have significant implications for the development of DL models that deliver reliable and robust performance in real-world CPS applications.
Deep Learning-Based Spatiotemporal Multi-Event Reconstruction for Delay Line Detectors
Jun 13, 2023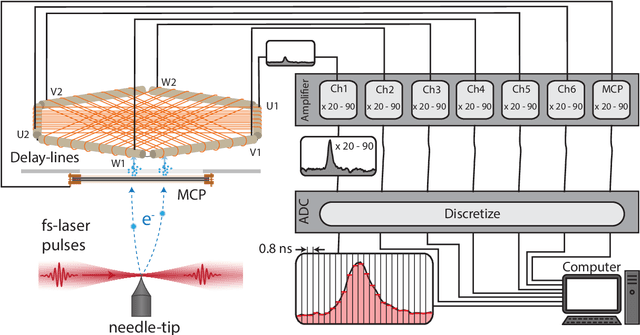
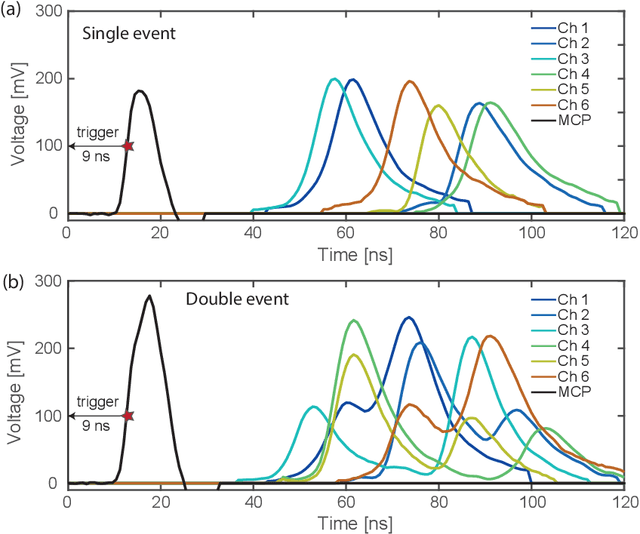
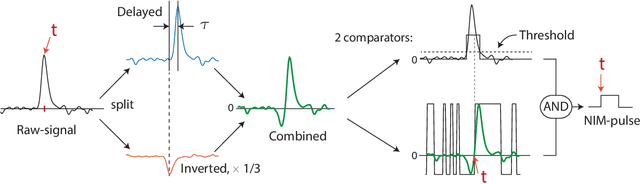
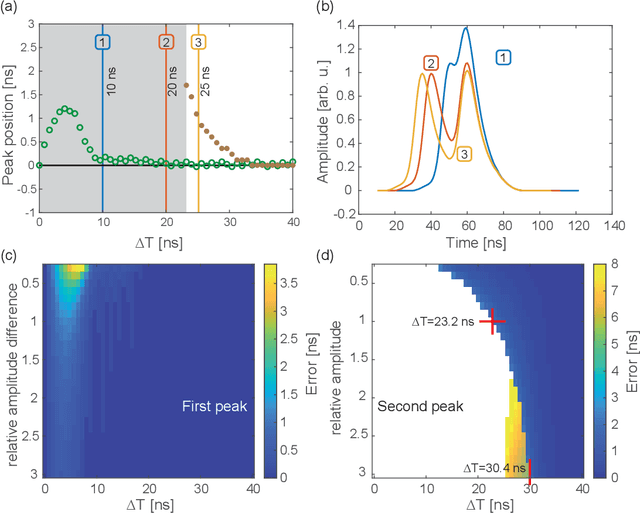
Accurate observation of two or more particles within a very narrow time window has always been a challenge in modern physics. It creates the possibility of correlation experiments, such as the ground-breaking Hanbury Brown-Twiss experiment, leading to new physical insights. For low-energy electrons, one possibility is to use a microchannel plate with subsequent delay lines for the readout of the incident particle hits, a setup called a Delay Line Detector. The spatial and temporal coordinates of more than one particle can be fully reconstructed outside a region called the dead radius. For interesting events, where two electrons are close in space and time, the determination of the individual positions of the electrons requires elaborate peak finding algorithms. While classical methods work well with single particle hits, they fail to identify and reconstruct events caused by multiple nearby particles. To address this challenge, we present a new spatiotemporal machine learning model to identify and reconstruct the position and time of such multi-hit particle signals. This model achieves a much better resolution for nearby particle hits compared to the classical approach, removing some of the artifacts and reducing the dead radius by half. We show that machine learning models can be effective in improving the spatiotemporal performance of delay line detectors.
Implicit View-Time Interpolation of Stereo Videos using Multi-Plane Disparities and Non-Uniform Coordinates
Mar 30, 2023
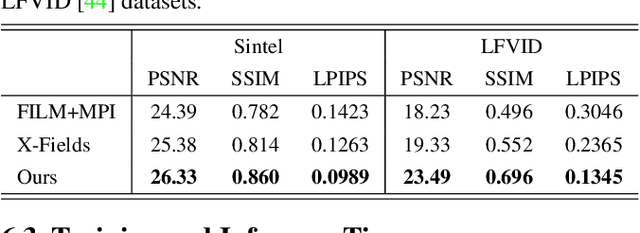

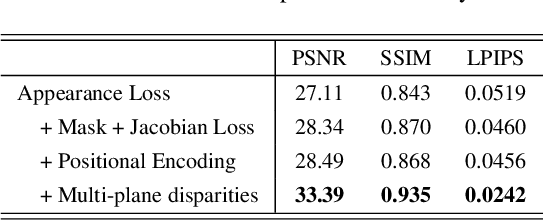
In this paper, we propose an approach for view-time interpolation of stereo videos. Specifically, we build upon X-Fields that approximates an interpolatable mapping between the input coordinates and 2D RGB images using a convolutional decoder. Our main contribution is to analyze and identify the sources of the problems with using X-Fields in our application and propose novel techniques to overcome these challenges. Specifically, we observe that X-Fields struggles to implicitly interpolate the disparities for large baseline cameras. Therefore, we propose multi-plane disparities to reduce the spatial distance of the objects in the stereo views. Moreover, we propose non-uniform time coordinates to handle the non-linear and sudden motion spikes in videos. We additionally introduce several simple, but important, improvements over X-Fields. We demonstrate that our approach is able to produce better results than the state of the art, while running in near real-time rates and having low memory and storage costs.
Separable Physics-Informed Neural Networks
Jul 03, 2023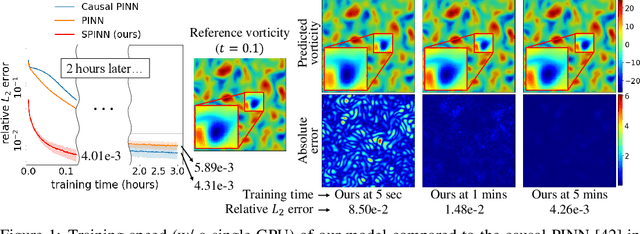

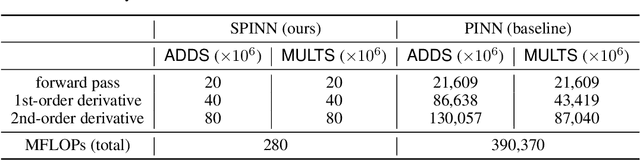
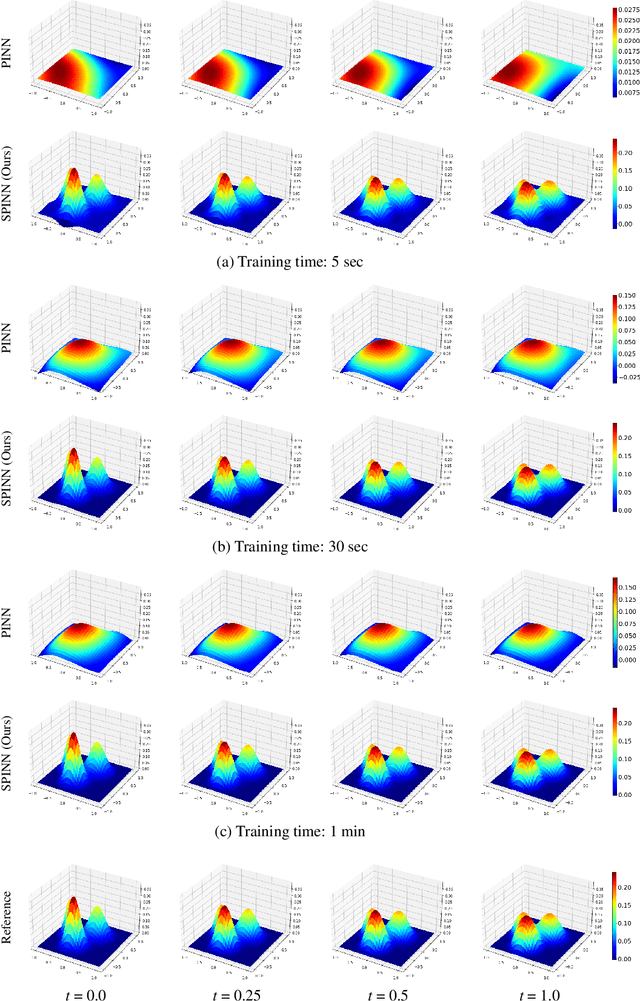
Physics-informed neural networks (PINNs) have recently emerged as promising data-driven PDE solvers showing encouraging results on various PDEs. However, there is a fundamental limitation of training PINNs to solve multi-dimensional PDEs and approximate highly complex solution functions. The number of training points (collocation points) required on these challenging PDEs grows substantially, but it is severely limited due to the expensive computational costs and heavy memory overhead. To overcome this issue, we propose a network architecture and training algorithm for PINNs. The proposed method, separable PINN (SPINN), operates on a per-axis basis to significantly reduce the number of network propagations in multi-dimensional PDEs unlike point-wise processing in conventional PINNs. We also propose using forward-mode automatic differentiation to reduce the computational cost of computing PDE residuals, enabling a large number of collocation points (>10^7) on a single commodity GPU. The experimental results show drastically reduced computational costs (62x in wall-clock time, 1,394x in FLOPs given the same number of collocation points) in multi-dimensional PDEs while achieving better accuracy. Furthermore, we present that SPINN can solve a chaotic (2+1)-d Navier-Stokes equation significantly faster than the best-performing prior method (9 minutes vs 10 hours in a single GPU), maintaining accuracy. Finally, we showcase that SPINN can accurately obtain the solution of a highly nonlinear and multi-dimensional PDE, a (3+1)-d Navier-Stokes equation. For visualized results and code, please see https://jwcho5576.github.io/spinn.github.io/.