 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
cuSLINK: Single-linkage Agglomerative Clustering on the GPU
Jun 28, 2023

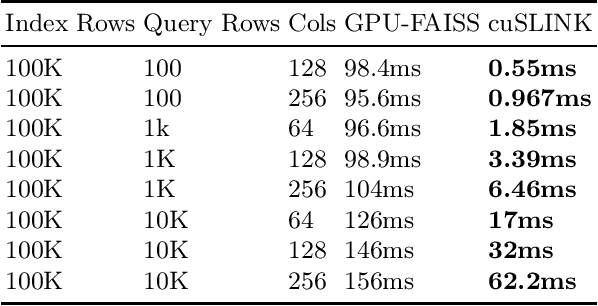

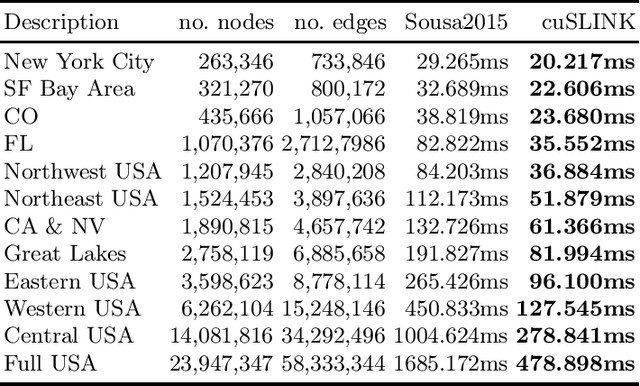
In this paper, we propose cuSLINK, a novel and state-of-the-art reformulation of the SLINK algorithm on the GPU which requires only $O(Nk)$ space and uses a parameter $k$ to trade off space and time. We also propose a set of novel and reusable building blocks that compose cuSLINK. These building blocks include highly optimized computational patterns for $k$-NN graph construction, spanning trees, and dendrogram cluster extraction. We show how we used our primitives to implement cuSLINK end-to-end on the GPU, further enabling a wide range of real-world data mining and machine learning applications that were once intractable. In addition to being a primary computational bottleneck in the popular HDBSCAN algorithm, the impact of our end-to-end cuSLINK algorithm spans a large range of important applications, including cluster analysis in social and computer networks, natural language processing, and computer vision. Users can obtain cuSLINK at https://docs.rapids.ai/api/cuml/latest/api/#agglomerative-clustering
What Sentiment and Fun Facts We Learnt Before FIFA World Cup Qatar 2022 Using Twitter and AI
Jun 28, 2023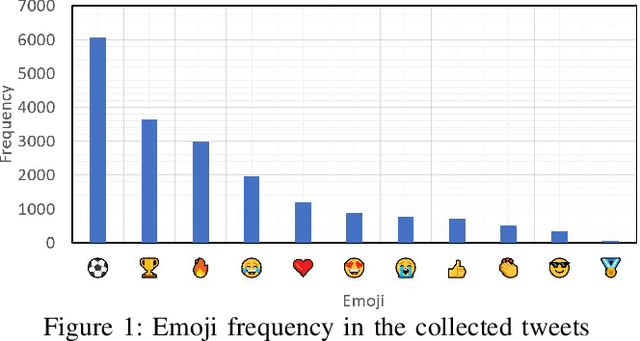


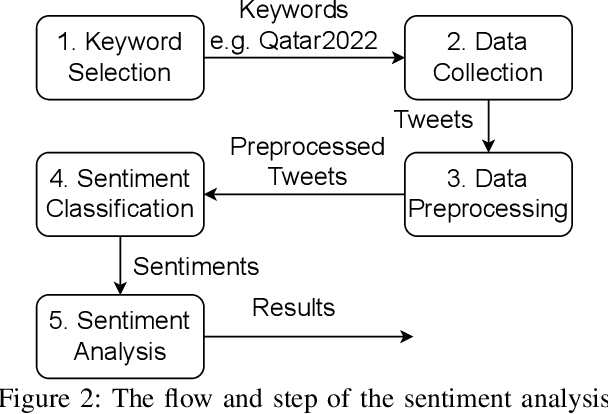
Twitter is a social media platform bridging most countries and allows real-time news discovery. Since the tweets on Twitter are usually short and express public feelings, thus provide a source for opinion mining and sentiment analysis for global events. This paper proposed an effective solution, in providing a sentiment on tweets related to the FIFA World Cup. At least 130k tweets, as the first in the community, are collected and implemented as a dataset to evaluate the performance of the proposed machine learning solution. These tweets are collected with the related hashtags and keywords of the Qatar World Cup 2022. The Vader algorithm is used in this paper for sentiment analysis. Through the machine learning method and collected Twitter tweets, we discovered the sentiments and fun facts of several aspects important to the period before the World Cup. The result shows people are positive to the opening of the World Cup.
Sequential Attention Source Identification Based on Feature Representation
Jun 28, 2023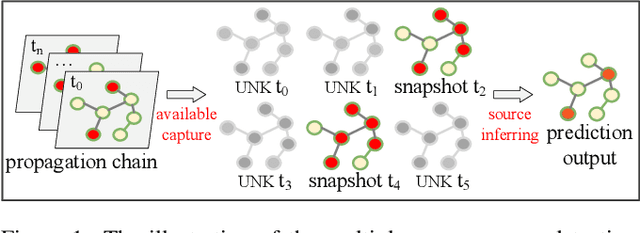
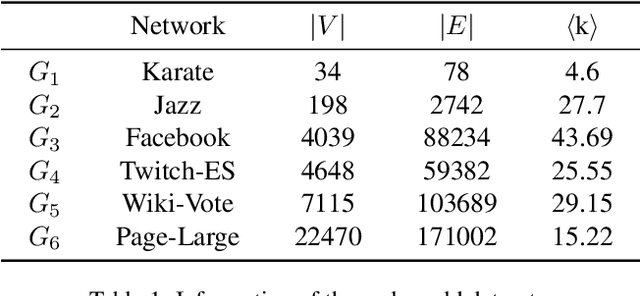
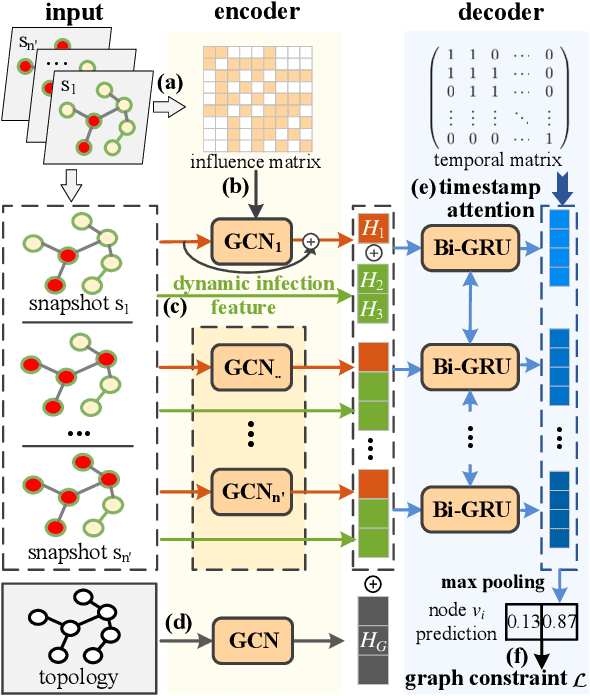
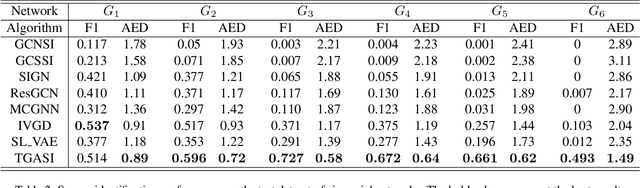
Snapshot observation based source localization has been widely studied due to its accessibility and low cost. However, the interaction of users in existing methods does not be addressed in time-varying infection scenarios. So these methods have a decreased accuracy in heterogeneous interaction scenarios. To solve this critical issue, this paper proposes a sequence-to-sequence based localization framework called Temporal-sequence based Graph Attention Source Identification (TGASI) based on an inductive learning idea. More specifically, the encoder focuses on generating multiple features by estimating the influence probability between two users, and the decoder distinguishes the importance of prediction sources in different timestamps by a designed temporal attention mechanism. It's worth mentioning that the inductive learning idea ensures that TGASI can detect the sources in new scenarios without knowing other prior knowledge, which proves the scalability of TGASI. Comprehensive experiments with the SOTA methods demonstrate the higher detection performance and scalability in different scenarios of TGASI.
Multi-Task Self-Supervised Time-Series Representation Learning
Mar 02, 2023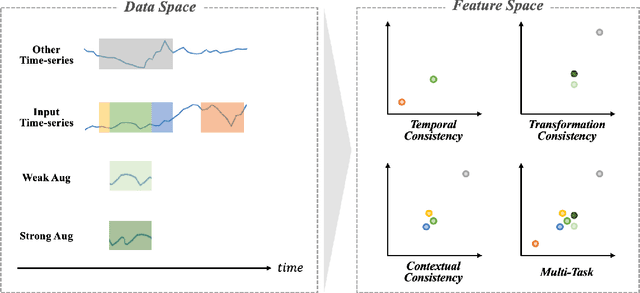
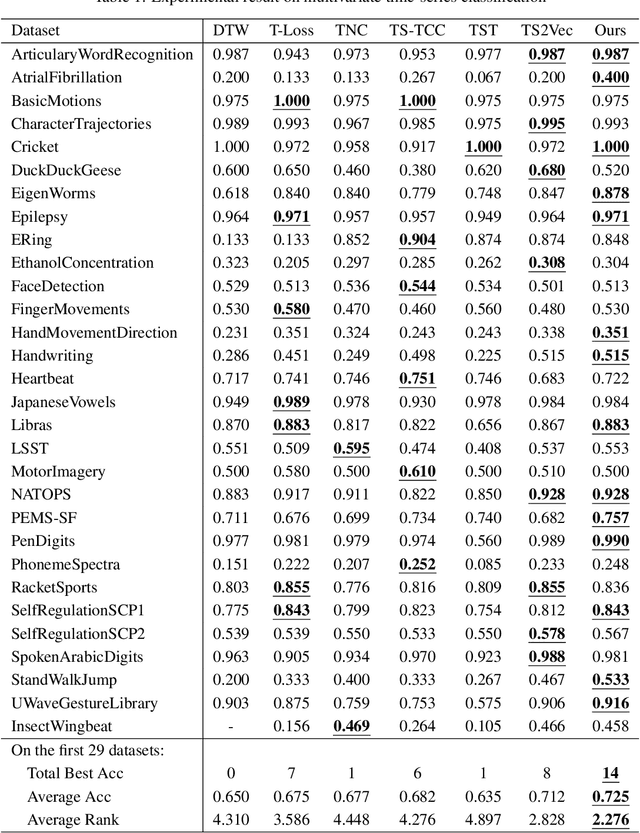
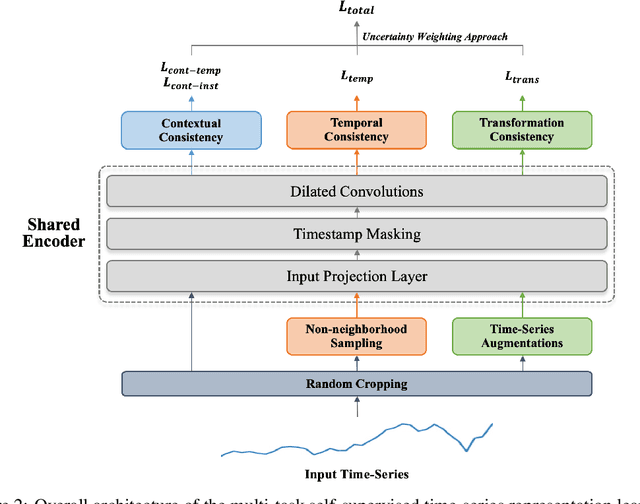
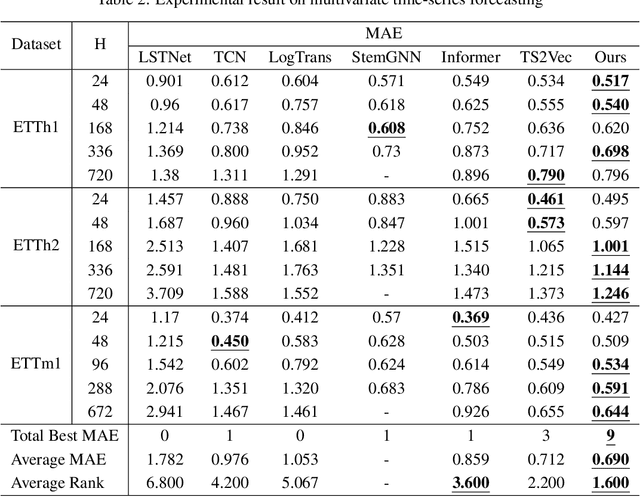
Time-series representation learning can extract representations from data with temporal dynamics and sparse labels. When labeled data are sparse but unlabeled data are abundant, contrastive learning, i.e., a framework to learn a latent space where similar samples are close to each other while dissimilar ones are far from each other, has shown outstanding performance. This strategy can encourage varied consistency of time-series representations depending on the positive pair selection and contrastive loss. We propose a new time-series representation learning method by combining the advantages of self-supervised tasks related to contextual, temporal, and transformation consistency. It allows the network to learn general representations for various downstream tasks and domains. Specifically, we first adopt data preprocessing to generate positive and negative pairs for each self-supervised task. The model then performs contextual, temporal, and transformation contrastive learning and is optimized jointly using their contrastive losses. We further investigate an uncertainty weighting approach to enable effective multi-task learning by considering the contribution of each consistency. We evaluate the proposed framework on three downstream tasks: time-series classification, forecasting, and anomaly detection. Experimental results show that our method not only outperforms the benchmark models on these downstream tasks, but also shows efficiency in cross-domain transfer learning.
Unsupervised speech intelligibility assessment with utterance level alignment distance between teacher and learner Wav2Vec-2.0 representations
Jun 15, 2023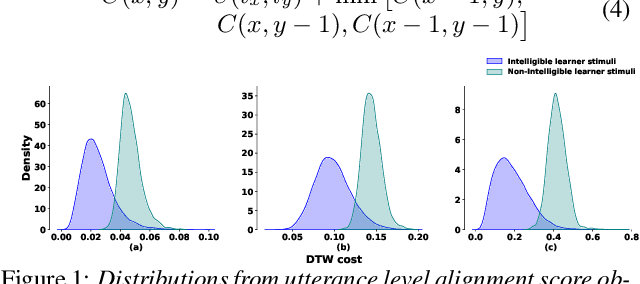
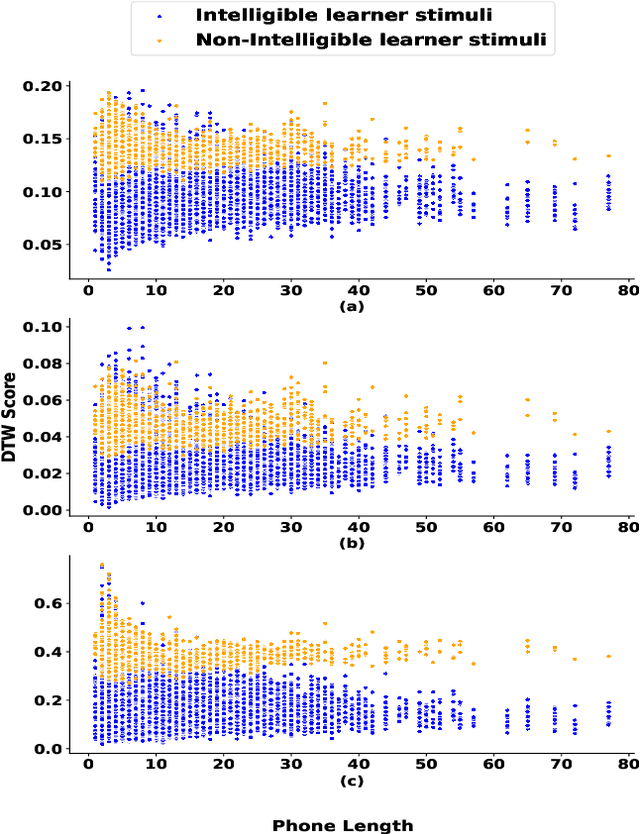
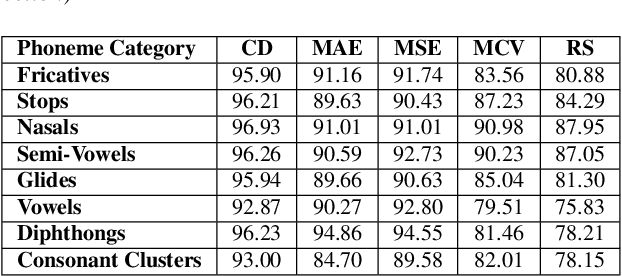
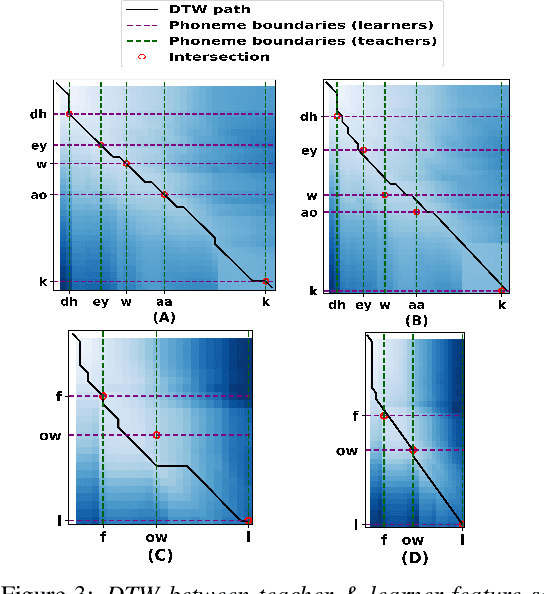
Speech intelligibility is crucial in language learning for effective communication. Thus, to develop computer-assisted language learning systems, automatic speech intelligibility detection (SID) is necessary. Most of the works have assessed the intelligibility in a supervised manner considering manual annotations, which requires cost and time; hence scalability is limited. To overcome these, this work proposes an unsupervised approach for SID. The proposed approach considers alignment distance computed with dynamic-time warping (DTW) between teacher and learner representation sequence as a measure to separate intelligible versus non-intelligible speech. We obtain the feature sequence using current state-of-the-art self-supervised representations from Wav2Vec-2.0. We found the detection accuracies as 90.37\%, 92.57\% and 96.58\%, respectively, with three alignment distance measures -- mean absolute error, mean squared error and cosine distance (equal to one minus cosine similarity).
Static Background Removal in Vehicular Radar: Filtering in Azimuth-Elevation-Doppler Domain
Jul 04, 2023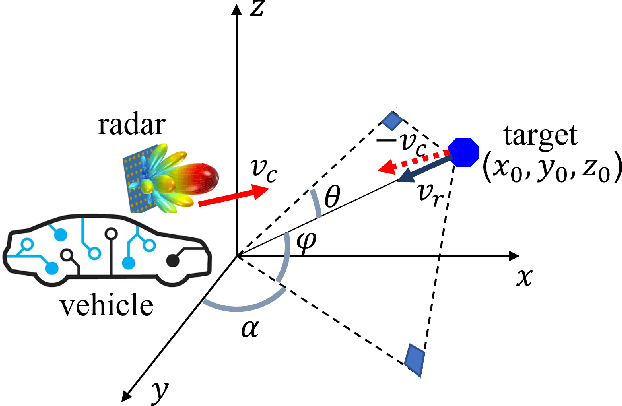
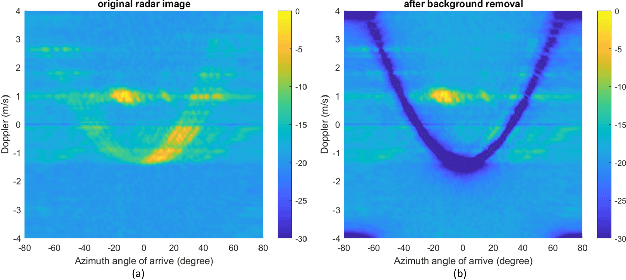
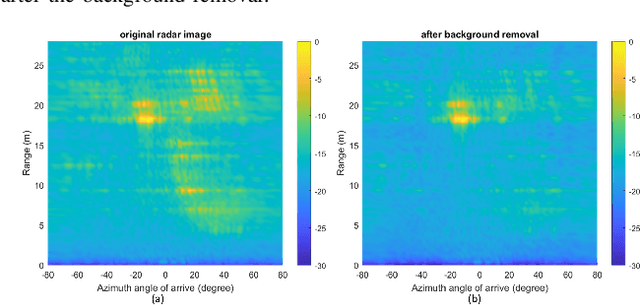
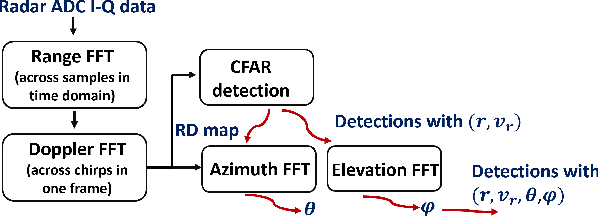
A significant challenge in autonomous driving systems lies in image understanding within complex environments, particularly dense traffic scenarios. An effective solution to this challenge involves removing the background or static objects from the scene, so as to enhance the detection of moving targets as key component of improving overall system performance. In this paper, we present an efficient algorithm for background removal in automotive radar applications, specifically utilizing a frequency-modulated continuous wave (FMCW) radar. Our proposed algorithm follows a three-step approach, encompassing radar signal preprocessing, three-dimensional (3D) ego-motion estimation, and notch filter-based background removal in the azimuth-elevation-Doppler domain. To begin, we model the received signal of the FMCW multiple-input multiple-output (MIMO) radar and develop a signal processing framework for extracting four-dimensional (4D) point clouds. Subsequently, we introduce a robust 3D ego-motion estimation algorithm that accurately estimates radar ego-motion speed, accounting for Doppler ambiguity, by processing the point clouds. Additionally, our algorithm leverages the relationship between Doppler velocity, azimuth angle, elevation angle, and radar ego-motion speed to identify the spectrum belonging to background clutter. Subsequently, we employ notch filters to effectively filter out the background clutter. The performance of our algorithm is evaluated using both simulated data and extensive experiments with real-world data. The results demonstrate its effectiveness in efficiently removing background clutter and enhacing perception within complex environments. By offering a fast and computationally efficient solution, our approach effectively addresses challenges posed by non-homogeneous environments and real-time processing requirements.
RRCNN: A novel signal decomposition approach based on recurrent residue convolutional neural network
Jul 04, 2023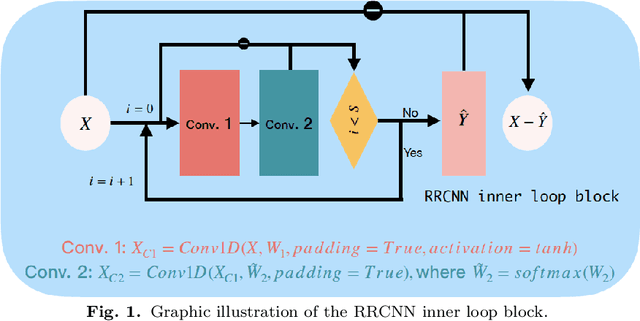
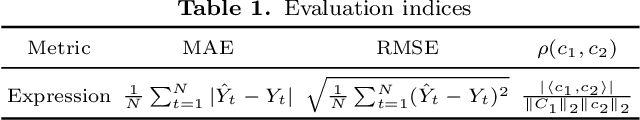
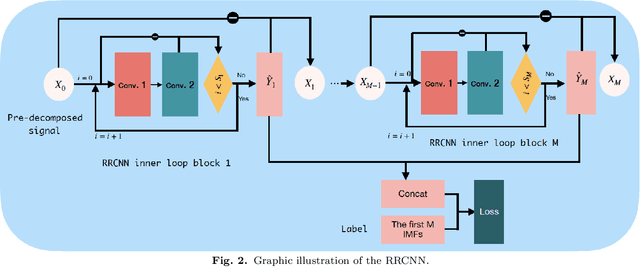

The decomposition of non-stationary signals is an important and challenging task in the field of signal time-frequency analysis. In the recent two decades, many signal decomposition methods led by the empirical mode decomposition, which was pioneered by Huang et al. in 1998, have been proposed by different research groups. However, they still have some limitations. For example, they are generally prone to boundary and mode mixing effects and are not very robust to noise. Inspired by the successful applications of deep learning in fields like image processing and natural language processing, and given the lack in the literature of works in which deep learning techniques are used directly to decompose non-stationary signals into simple oscillatory components, we use the convolutional neural network, residual structure and nonlinear activation function to compute in an innovative way the local average of the signal, and study a new non-stationary signal decomposition method under the framework of deep learning. We discuss the training process of the proposed model and study the convergence analysis of the learning algorithm. In the experiments, we evaluate the performance of the proposed model from two points of view: the calculation of the local average and the signal decomposition. Furthermore, we study the mode mixing, noise interference, and orthogonality properties of the decomposed components produced by the proposed method. All results show that the proposed model allows for better handling boundary effect, mode mixing effect, robustness, and the orthogonality of the decomposed components than existing methods.
Deploying Machine Learning Models to Ahead-of-Time Runtime on Edge Using MicroTVM
Apr 14, 2023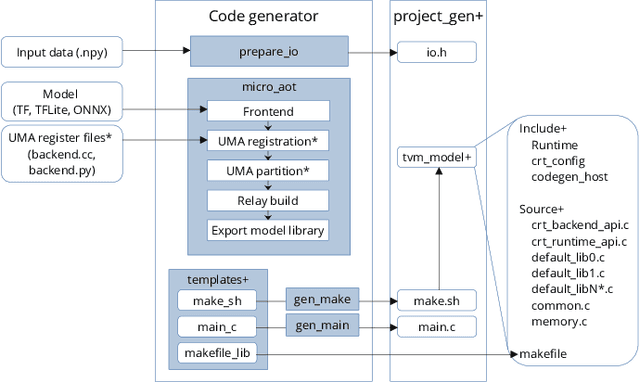

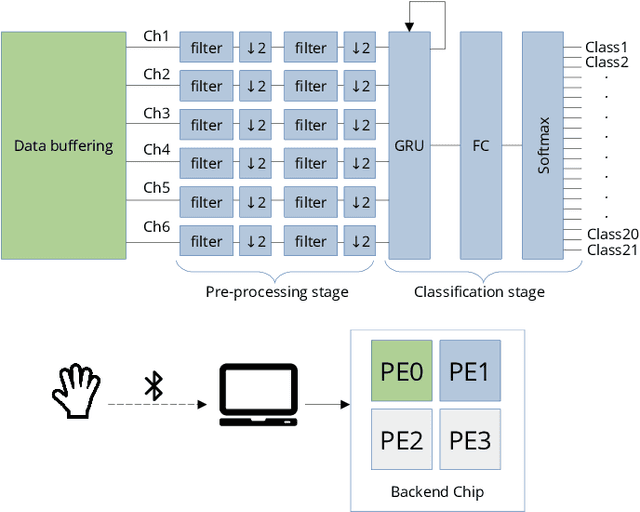
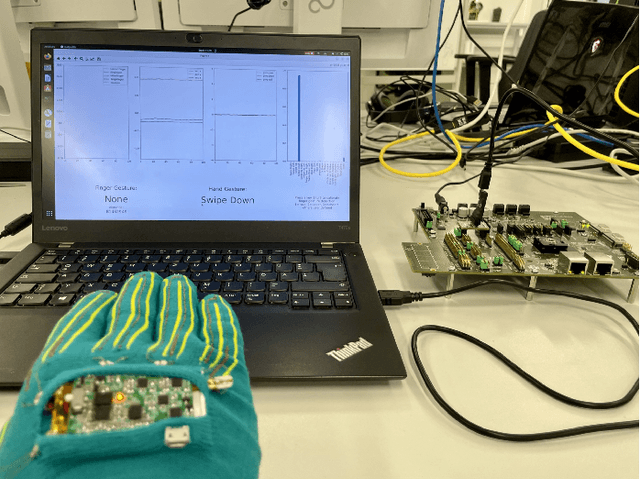
In the past few years, more and more AI applications have been applied to edge devices. However, models trained by data scientists with machine learning frameworks, such as PyTorch or TensorFlow, can not be seamlessly executed on edge. In this paper, we develop an end-to-end code generator parsing a pre-trained model to C source libraries for the backend using MicroTVM, a machine learning compiler framework extension addressing inference on bare metal devices. An analysis shows that specific compute-intensive operators can be easily offloaded to the dedicated accelerator with a Universal Modular Accelerator (UMA) interface, while others are processed in the CPU cores. By using the automatically generated ahead-of-time C runtime, we conduct a hand gesture recognition experiment on an ARM Cortex M4F core.
Sequential Manipulation Planning for Over-actuated UAMs
Jun 25, 2023
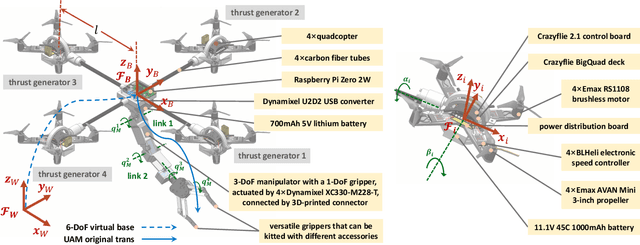
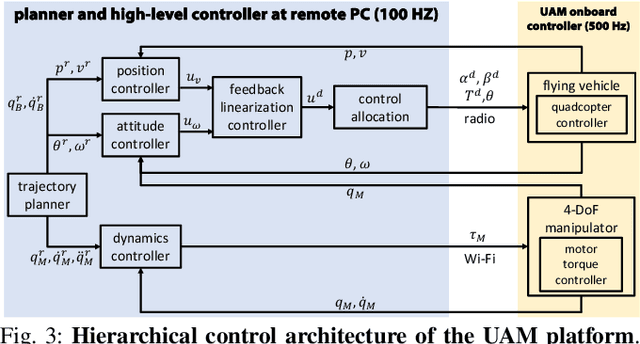
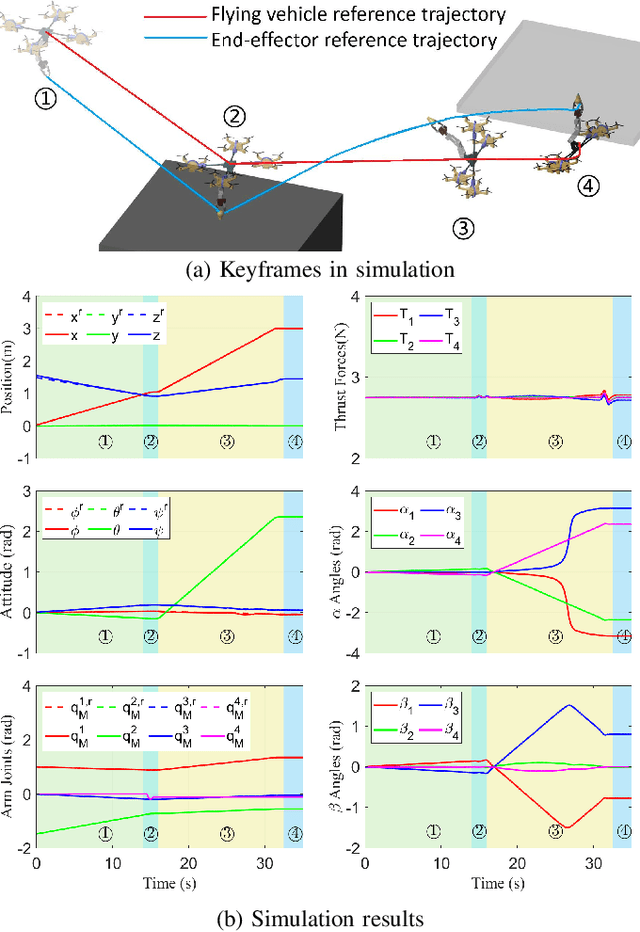
We investigate the sequential manipulation planning problem for unmanned aerial manipulators (UAMs). Unlike prior UAM work that primarily focuses on one-step manipulation tasks, sequential manipulations require coordinated motions of the floating base, the manipulator, and the object being manipulated, entailing a unified kinematics and dynamics model for motion planning under designated constraints. By leveraging a virtual kinematic chain (VKC)-based motion planning framework that consolidates components' kinematics into one chain, the sequential manipulation task of a UAM can be planned as a whole with more coordinated motions. Integrating the kinematics and dynamics models with a hierarchical control framework, we demonstrate, for the first time, an over-actuated UAM achieves a series of new sequential manipulation capabilities in both simulation and experiment.
Multi-Architecture Multi-Expert Diffusion Models
Jun 08, 2023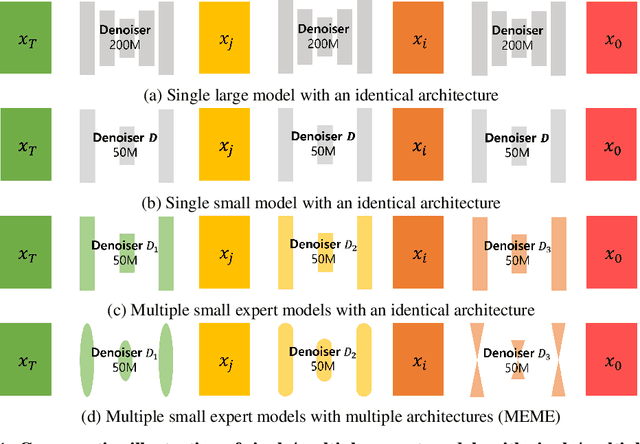
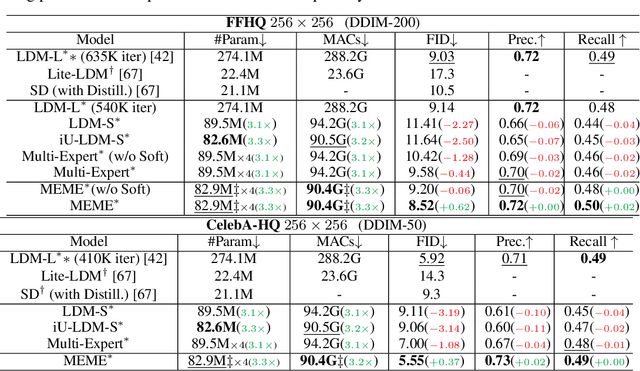
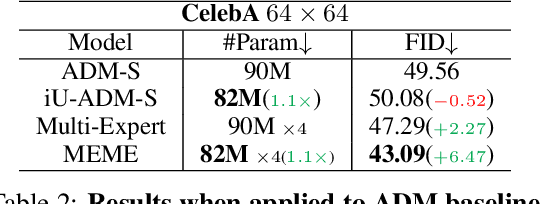
Diffusion models have achieved impressive results in generating diverse and realistic data by employing multi-step denoising processes. However, the need for accommodating significant variations in input noise at each time-step has led to diffusion models requiring a large number of parameters for their denoisers. We have observed that diffusion models effectively act as filters for different frequency ranges at each time-step noise. While some previous works have introduced multi-expert strategies, assigning denoisers to different noise intervals, they overlook the importance of specialized operations for high and low frequencies. For instance, self-attention operations are effective at handling low-frequency components (low-pass filters), while convolutions excel at capturing high-frequency features (high-pass filters). In other words, existing diffusion models employ denoisers with the same architecture, without considering the optimal operations for each time-step noise. To address this limitation, we propose a novel approach called Multi-architecturE Multi-Expert (MEME), which consists of multiple experts with specialized architectures tailored to the operations required at each time-step interval. Through extensive experiments, we demonstrate that MEME outperforms large competitors in terms of both generation performance and computational efficiency.