 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learned spatial data partitioning
Jun 19, 2023
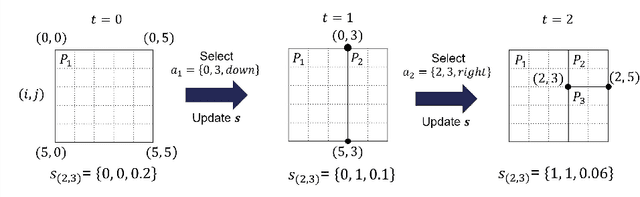
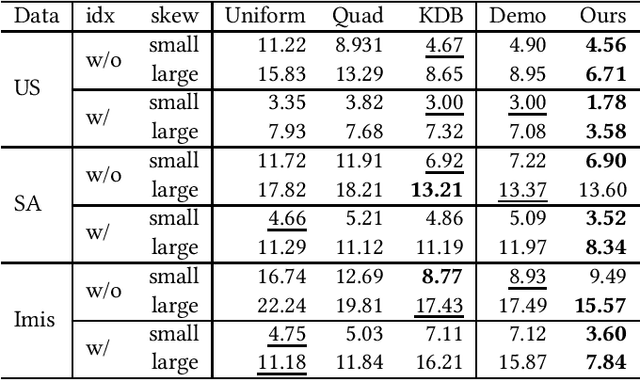
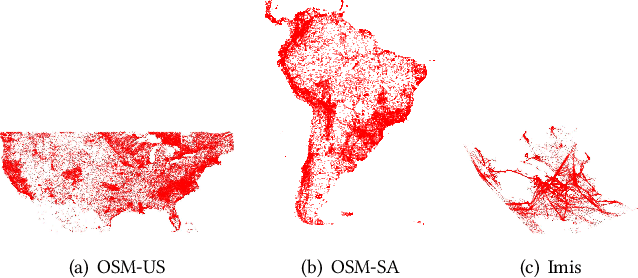
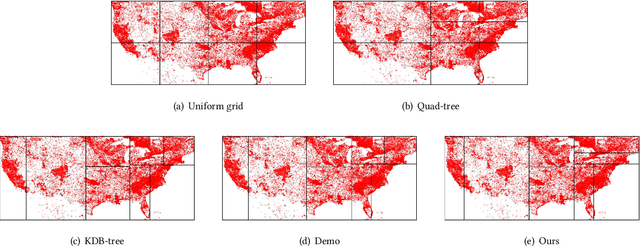
Due to the significant increase in the size of spatial data, it is essential to use distributed parallel processing systems to efficiently analyze spatial data. In this paper, we first study learned spatial data partitioning, which effectively assigns groups of big spatial data to computers based on locations of data by using machine learning techniques. We formalize spatial data partitioning in the context of reinforcement learning and develop a novel deep reinforcement learning algorithm. Our learning algorithm leverages features of spatial data partitioning and prunes ineffective learning processes to find optimal partitions efficiently. Our experimental study, which uses Apache Sedona and real-world spatial data, demonstrates that our method efficiently finds partitions for accelerating distance join queries and reduces the workload run time by up to 59.4%.
Binary domain generalization for sparsifying binary neural networks
Jun 23, 2023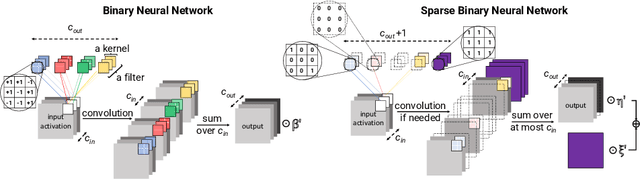

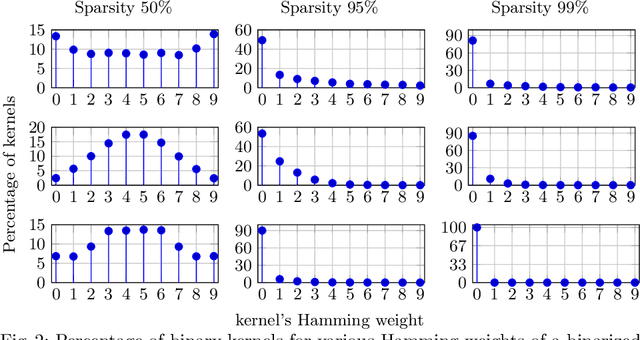
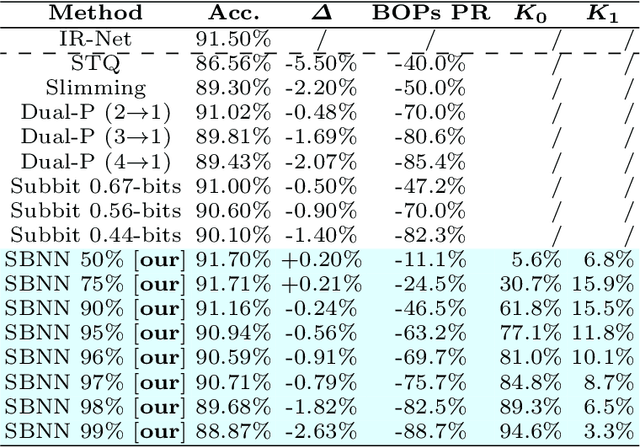
Binary neural networks (BNNs) are an attractive solution for developing and deploying deep neural network (DNN)-based applications in resource constrained devices. Despite their success, BNNs still suffer from a fixed and limited compression factor that may be explained by the fact that existing pruning methods for full-precision DNNs cannot be directly applied to BNNs. In fact, weight pruning of BNNs leads to performance degradation, which suggests that the standard binarization domain of BNNs is not well adapted for the task. This work proposes a novel more general binary domain that extends the standard binary one that is more robust to pruning techniques, thus guaranteeing improved compression and avoiding severe performance losses. We demonstrate a closed-form solution for quantizing the weights of a full-precision network into the proposed binary domain. Finally, we show the flexibility of our method, which can be combined with other pruning strategies. Experiments over CIFAR-10 and CIFAR-100 demonstrate that the novel approach is able to generate efficient sparse networks with reduced memory usage and run-time latency, while maintaining performance.
Multi-perspective Information Fusion Res2Net with RandomSpecmix for Fake Speech Detection
Jun 27, 2023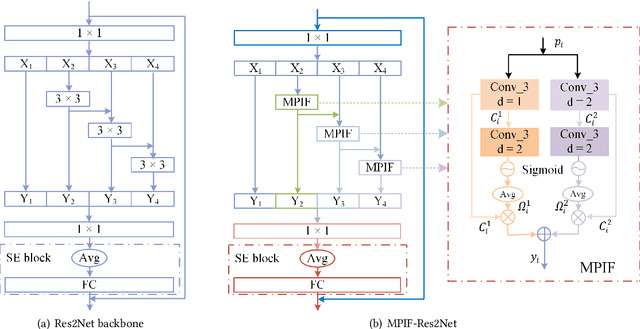

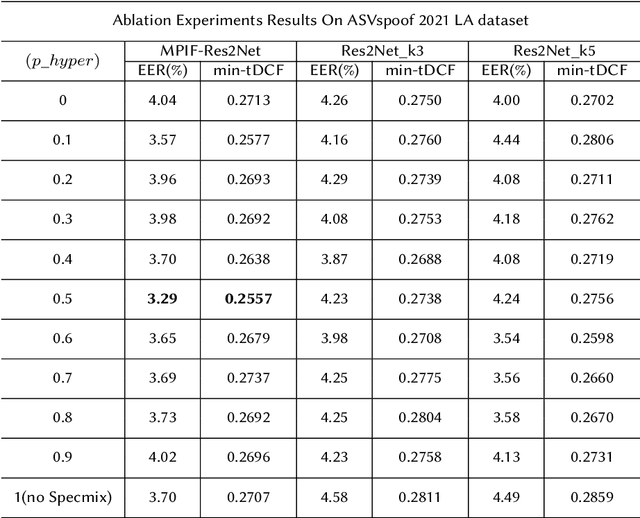
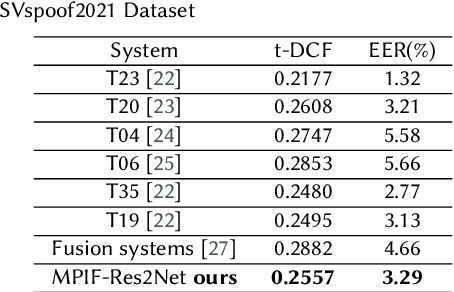
In this paper, we propose the multi-perspective information fusion (MPIF) Res2Net with random Specmix for fake speech detection (FSD). The main purpose of this system is to improve the model's ability to learn precise forgery information for FSD task in low-quality scenarios. The task of random Specmix, a data augmentation, is to improve the generalization ability of the model and enhance the model's ability to locate discriminative information. Specmix cuts and pastes the frequency dimension information of the spectrogram in the same batch of samples without introducing other data, which helps the model to locate the really useful information. At the same time, we randomly select samples for augmentation to reduce the impact of data augmentation directly changing all the data. Once the purpose of helping the model to locate information is achieved, it is also important to reduce unnecessary information. The role of MPIF-Res2Net is to reduce redundant interference information. Deceptive information from a single perspective is always similar, so the model learning this similar information will produce redundant spoofing clues and interfere with truly discriminative information. The proposed MPIF-Res2Net fuses information from different perspectives, making the information learned by the model more diverse, thereby reducing the redundancy caused by similar information and avoiding interference with the learning of discriminative information. The results on the ASVspoof 2021 LA dataset demonstrate the effectiveness of our proposed method, achieving EER and min-tDCF of 3.29% and 0.2557, respectively.
DCP-NAS: Discrepant Child-Parent Neural Architecture Search for 1-bit CNNs
Jun 27, 2023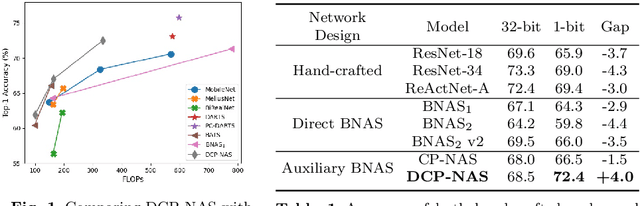
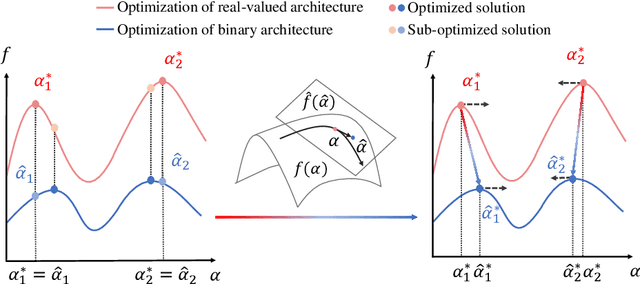

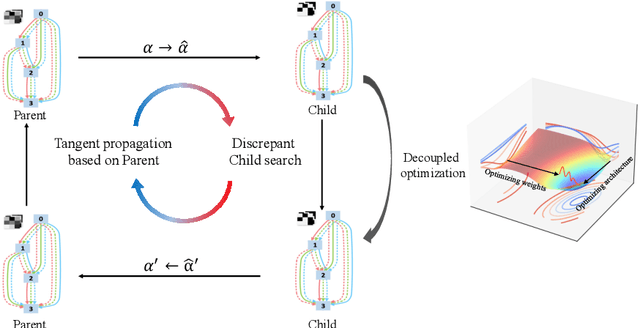
Neural architecture search (NAS) proves to be among the effective approaches for many tasks by generating an application-adaptive neural architecture, which is still challenged by high computational cost and memory consumption. At the same time, 1-bit convolutional neural networks (CNNs) with binary weights and activations show their potential for resource-limited embedded devices. One natural approach is to use 1-bit CNNs to reduce the computation and memory cost of NAS by taking advantage of the strengths of each in a unified framework, while searching the 1-bit CNNs is more challenging due to the more complicated processes involved. In this paper, we introduce Discrepant Child-Parent Neural Architecture Search (DCP-NAS) to efficiently search 1-bit CNNs, based on a new framework of searching the 1-bit model (Child) under the supervision of a real-valued model (Parent). Particularly, we first utilize a Parent model to calculate a tangent direction, based on which the tangent propagation method is introduced to search the optimized 1-bit Child. We further observe a coupling relationship between the weights and architecture parameters existing in such differentiable frameworks. To address the issue, we propose a decoupled optimization method to search an optimized architecture. Extensive experiments demonstrate that our DCP-NAS achieves much better results than prior arts on both CIFAR-10 and ImageNet datasets. In particular, the backbones achieved by our DCP-NAS achieve strong generalization performance on person re-identification and object detection.
Evidential Detection and Tracking Collaboration: New Problem, Benchmark and Algorithm for Robust Anti-UAV System
Jun 27, 2023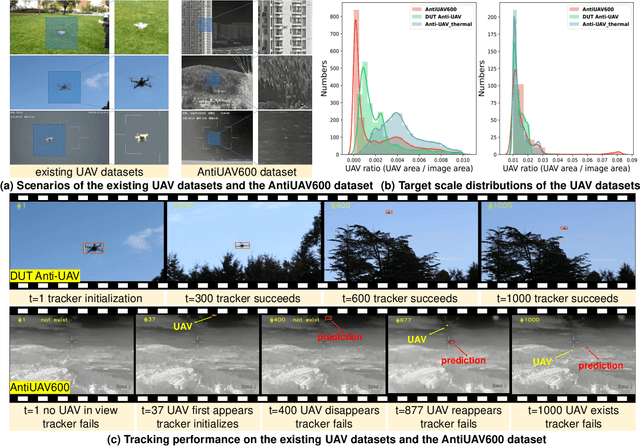
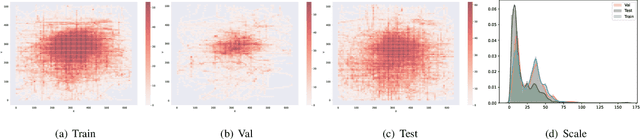
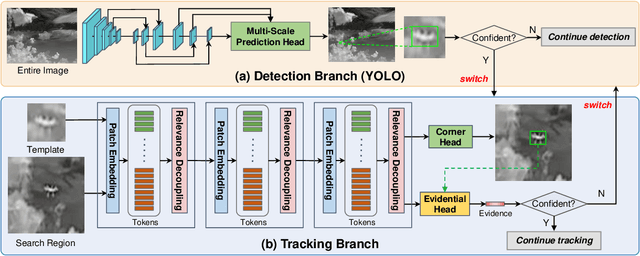
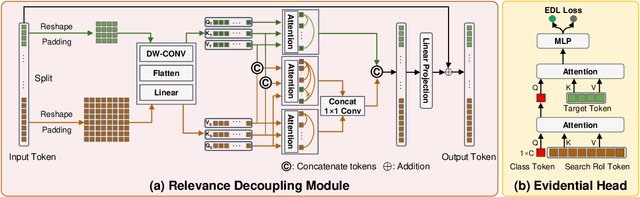
Unmanned Aerial Vehicles (UAVs) have been widely used in many areas, including transportation, surveillance, and military. However, their potential for safety and privacy violations is an increasing issue and highly limits their broader applications, underscoring the critical importance of UAV perception and defense (anti-UAV). Still, previous works have simplified such an anti-UAV task as a tracking problem, where the prior information of UAVs is always provided; such a scheme fails in real-world anti-UAV tasks (i.e. complex scenes, indeterminate-appear and -reappear UAVs, and real-time UAV surveillance). In this paper, we first formulate a new and practical anti-UAV problem featuring the UAVs perception in complex scenes without prior UAVs information. To benchmark such a challenging task, we propose the largest UAV dataset dubbed AntiUAV600 and a new evaluation metric. The AntiUAV600 comprises 600 video sequences of challenging scenes with random, fast, and small-scale UAVs, with over 723K thermal infrared frames densely annotated with bounding boxes. Finally, we develop a novel anti-UAV approach via an evidential collaboration of global UAVs detection and local UAVs tracking, which effectively tackles the proposed problem and can serve as a strong baseline for future research. Extensive experiments show our method outperforms SOTA approaches and validate the ability of AntiUAV600 to enhance UAV perception performance due to its large scale and complexity. Our dataset, pretrained models, and source codes will be released publically.
Resources and Evaluations for Multi-Distribution Dense Information Retrieval
Jun 21, 2023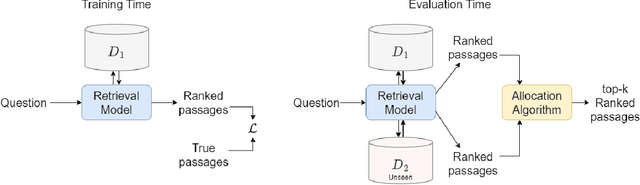

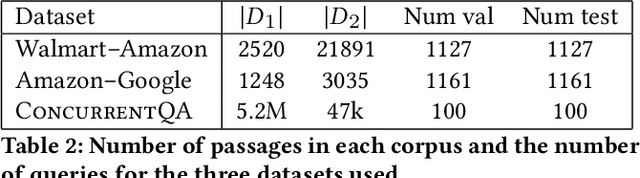
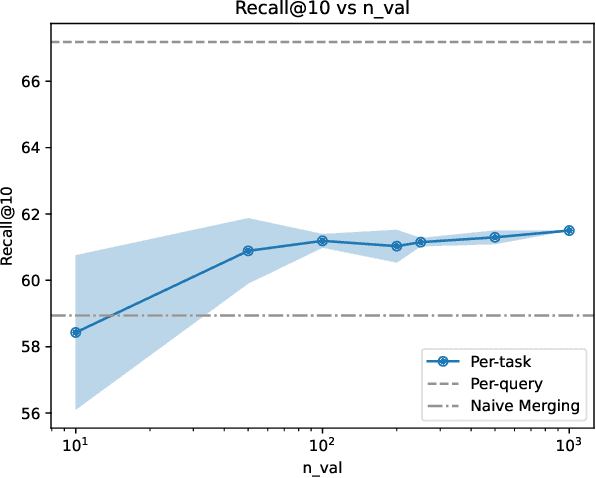
We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
Continuous-time convolutions model of event sequences
Feb 13, 2023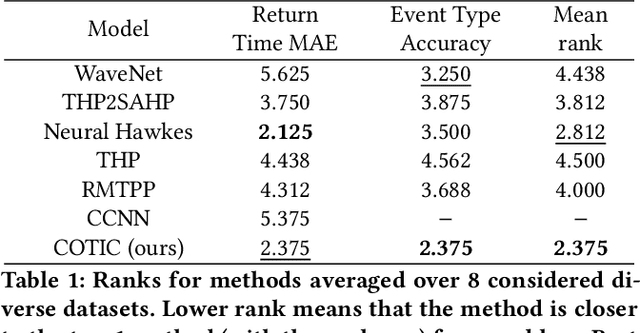
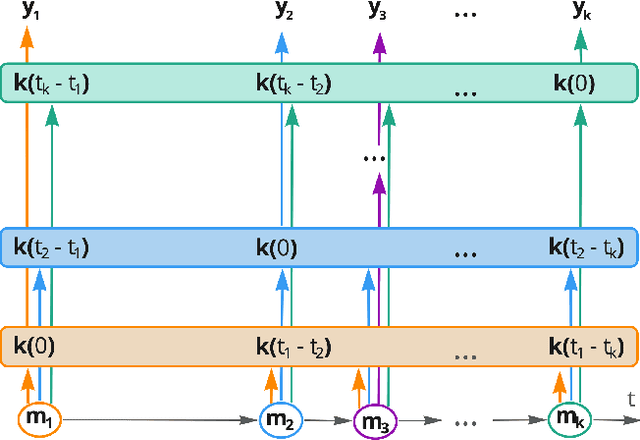
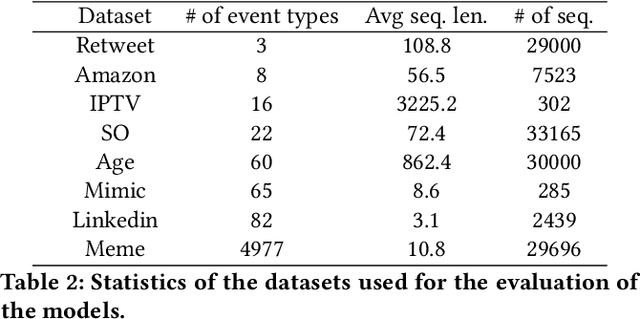
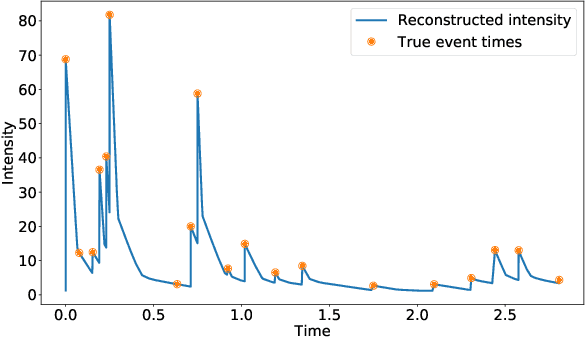
Massive samples of event sequences data occur in various domains, including e-commerce, healthcare, and finance. There are two main challenges regarding inference of such data: computational and methodological. The amount of available data and the length of event sequences per client are typically large, thus it requires long-term modelling. Moreover, this data is often sparse and non-uniform, making classic approaches for time series processing inapplicable. Existing solutions include recurrent and transformer architectures in such cases. To allow continuous time, the authors introduce specific parametric intensity functions defined at each moment on top of existing models. Due to the parametric nature, these intensities represent only a limited class of event sequences. We propose the COTIC method based on a continuous convolution neural network suitable for non-uniform occurrence of events in time. In COTIC, dilations and multi-layer architecture efficiently handle dependencies between events. Furthermore, the model provides general intensity dynamics in continuous time - including self-excitement encountered in practice. The COTIC model outperforms existing approaches on majority of the considered datasets, producing embeddings for an event sequence that can be used to solve downstream tasks - e.g. predicting next event type and return time. The code of the proposed method can be found in the GitHub repository (https://github.com/VladislavZh/COTIC).
Decision-Dependent Distributionally Robust Markov Decision Process Method in Dynamic Epidemic Control
Jun 24, 2023In this paper, we present a Distributionally Robust Markov Decision Process (DRMDP) approach for addressing the dynamic epidemic control problem. The Susceptible-Exposed-Infectious-Recovered (SEIR) model is widely used to represent the stochastic spread of infectious diseases, such as COVID-19. While Markov Decision Processes (MDP) offers a mathematical framework for identifying optimal actions, such as vaccination and transmission-reducing intervention, to combat disease spreading according to the SEIR model. However, uncertainties in these scenarios demand a more robust approach that is less reliant on error-prone assumptions. The primary objective of our study is to introduce a new DRMDP framework that allows for an ambiguous distribution of transition dynamics. Specifically, we consider the worst-case distribution of these transition probabilities within a decision-dependent ambiguity set. To overcome the computational complexities associated with policy determination, we propose an efficient Real-Time Dynamic Programming (RTDP) algorithm that is capable of computing optimal policies based on the reformulated DRMDP model in an accurate, timely, and scalable manner. Comparative analysis against the classic MDP model demonstrates that the DRMDP achieves a lower proportion of infections and susceptibilities at a reduced cost.
Learning Graph ARMA Processes from Time-Vertex Spectra
Feb 14, 2023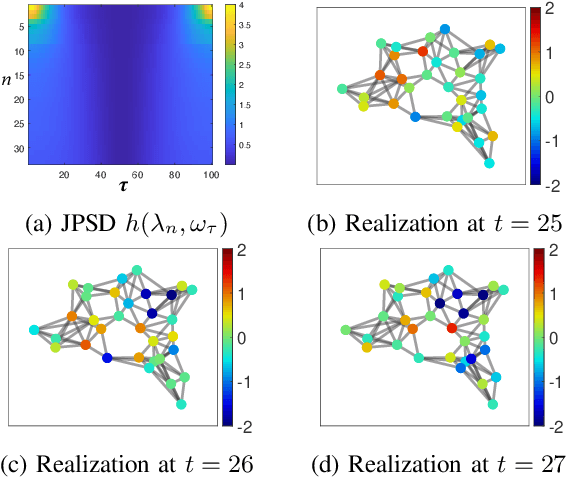
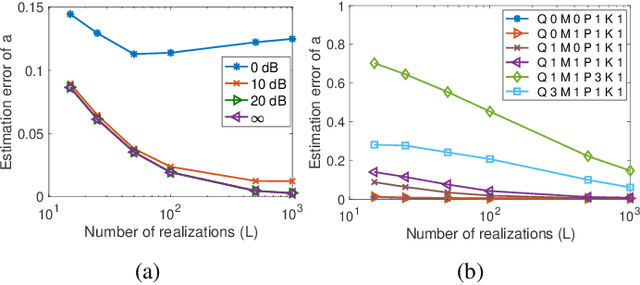
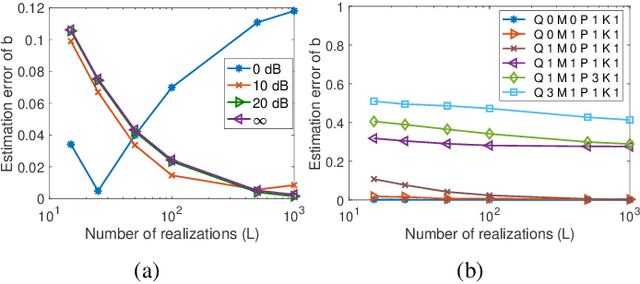
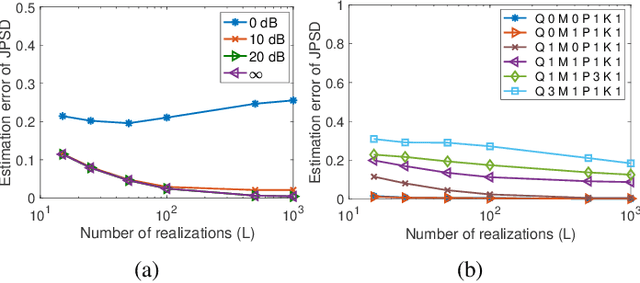
The modeling of time-varying graph signals as stationary time-vertex stochastic processes permits the inference of missing signal values by efficiently employing the correlation patterns of the process across different graph nodes and time instants. In this study, we first propose an algorithm for computing graph autoregressive moving average (graph ARMA) processes based on learning the joint time-vertex power spectral density of the process from its incomplete realizations. Our solution relies on first roughly estimating the joint spectrum of the process from partially observed realizations and then refining this estimate by projecting it onto the spectrum manifold of the ARMA process. We then present a theoretical analysis of the sample complexity of learning graph ARMA processes. Experimental results show that the proposed approach achieves improvement in the time-vertex signal estimation performance in comparison with reference approaches in the literature.
Understanding In-Context Learning via Supportive Pretraining Data
Jun 26, 2023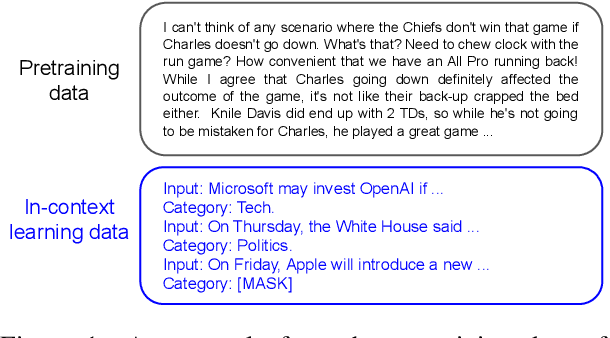
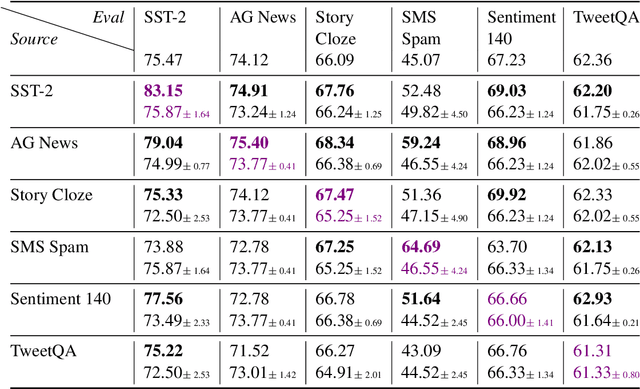

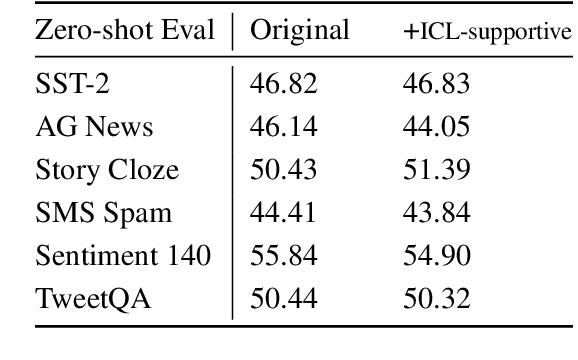
In-context learning (ICL) improves language models' performance on a variety of NLP tasks by simply demonstrating a handful of examples at inference time. It is not well understood why ICL ability emerges, as the model has never been specifically trained on such demonstrations. Unlike prior work that explores implicit mechanisms behind ICL, we study ICL via investigating the pretraining data. Specifically, we first adapt an iterative, gradient-based approach to find a small subset of pretraining data that supports ICL. We observe that a continued pretraining on this small subset significantly improves the model's ICL ability, by up to 18%. We then compare the supportive subset constrastively with random subsets of pretraining data and discover: (1) The supportive pretraining data to ICL do not have a higher domain relevance to downstream tasks. (2) The supportive pretraining data have a higher mass of rarely occurring, long-tail tokens. (3) The supportive pretraining data are challenging examples where the information gain from long-range context is below average, indicating learning to incorporate difficult long-range context encourages ICL. Our work takes a first step towards understanding ICL via analyzing instance-level pretraining data. Our insights have a potential to enhance the ICL ability of language models by actively guiding the construction of pretraining data in the future.