 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SysNoise: Exploring and Benchmarking Training-Deployment System Inconsistency
Jul 01, 2023
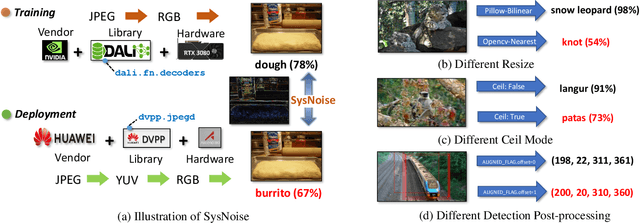

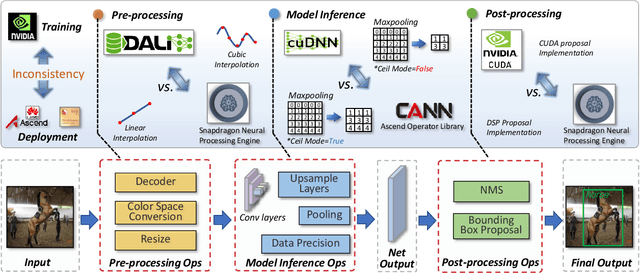
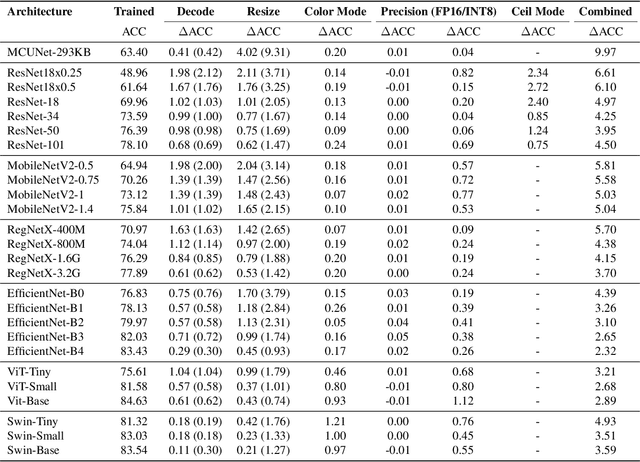
Extensive studies have shown that deep learning models are vulnerable to adversarial and natural noises, yet little is known about model robustness on noises caused by different system implementations. In this paper, we for the first time introduce SysNoise, a frequently occurred but often overlooked noise in the deep learning training-deployment cycle. In particular, SysNoise happens when the source training system switches to a disparate target system in deployments, where various tiny system mismatch adds up to a non-negligible difference. We first identify and classify SysNoise into three categories based on the inference stage; we then build a holistic benchmark to quantitatively measure the impact of SysNoise on 20+ models, comprehending image classification, object detection, instance segmentation and natural language processing tasks. Our extensive experiments revealed that SysNoise could bring certain impacts on model robustness across different tasks and common mitigations like data augmentation and adversarial training show limited effects on it. Together, our findings open a new research topic and we hope this work will raise research attention to deep learning deployment systems accounting for model performance. We have open-sourced the benchmark and framework at https://modeltc.github.io/systemnoise_web.
* Proceedings of Machine Learning and Systems. 2023 Mar 18
Power Beacon Energy Consumption Minimization in Wireless Powered Backscatter Communication Networks
Jun 09, 2023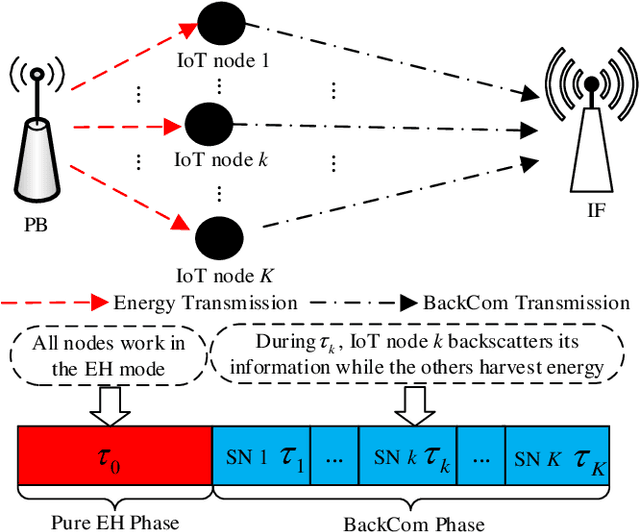

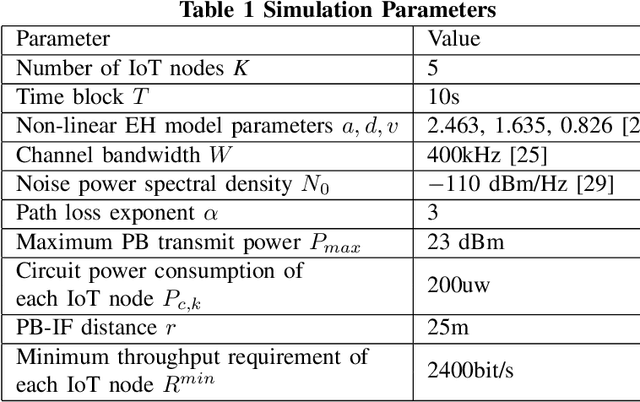
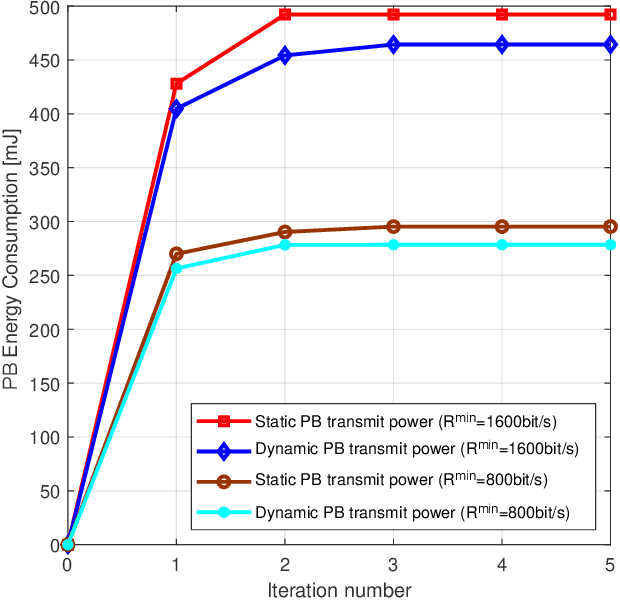
Internet-of-Things (IoT) networks are expected to support the wireless connection of massive energy limited IoT nodes. The emerging wireless powered backscatter communications (WPBC) enable IoT nodes to harvest energy from the incident radio frequency signals transmitted by a power beacon (PB) to support their circuit operation, but the energy consumption of the PB (a potentially high cost borne by the network operator) has not been sufficiently studied for WPBC. In this paper, we aim to minimize the energy consumption of the PB while satisfying the throughput requirement per IoT node by jointly optimizing the time division multiple access (TDMA) time slot duration and backscatter reflection coefficient of each IoT node and the PB transmit power per time slot. As the formulated joint optimization problem is non-convex, we transform it into a convex problem by using auxiliary variables, then employ the Lagrange dual method to obtain the optimal solutions. To reduce the implementation complexity required for adjusting the PB's transmit power every time slot, we keep the PB transmit power constant in each time block and solve the corresponding PB energy consumption minimization problem by using auxiliary variables, the block coordinated decent method and the successive convex approximation technique. Based on the above solutions, two iterative algorithms are proposed for the dynamic PB transmit power scheme and the static PB transmit power scheme. The simulation results show that the dynamic PB transmit power scheme and the static PB transmit power scheme both achieve a lower PB energy consumption than the benchmark schemes, and the former achieves the lowest PB energy consumption.
UW-ProCCaps: UnderWater Progressive Colourisation with Capsules
Jul 03, 2023Underwater images are fundamental for studying and understanding the status of marine life. We focus on reducing the memory space required for image storage while the memory space consumption in the collecting phase limits the time lasting of this phase leading to the need for more image collection campaigns. We present a novel machine-learning model that reconstructs the colours of underwater images from their luminescence channel, thus saving 2/3 of the available storage space. Our model specialises in underwater colour reconstruction and consists of an encoder-decoder architecture. The encoder is composed of a convolutional encoder and a parallel specialised classifier trained with webly-supervised data. The encoder and the decoder use layers of capsules to capture the features of the entities in the image. The colour reconstruction process recalls the progressive and the generative adversarial training procedures. The progressive training gives the ground for a generative adversarial routine focused on the refining of colours giving the image bright and saturated colours which bring the image back to life. We validate the model both qualitatively and quantitatively on four benchmark datasets. This is the first attempt at colour reconstruction in greyscale underwater images. Extensive results on four benchmark datasets demonstrate that our solution outperforms state-of-the-art (SOTA) solutions. We also demonstrate that the generated colourisation enhances the quality of images compared to enhancement models at the SOTA.
Towards Memory- and Time-Efficient Backpropagation for Training Spiking Neural Networks
Mar 07, 2023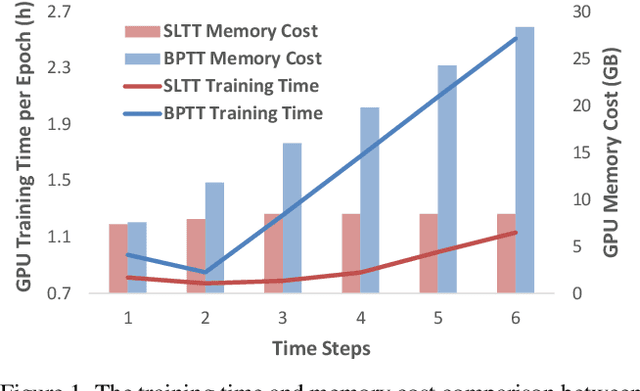
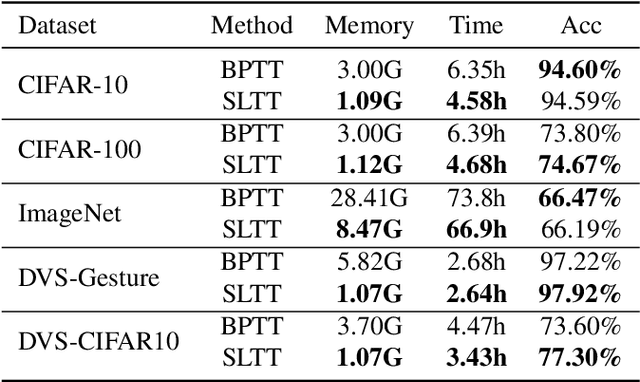
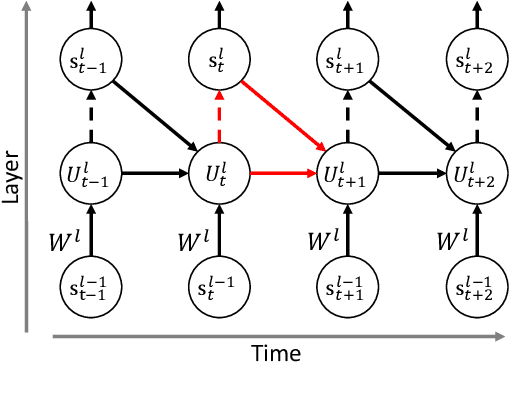
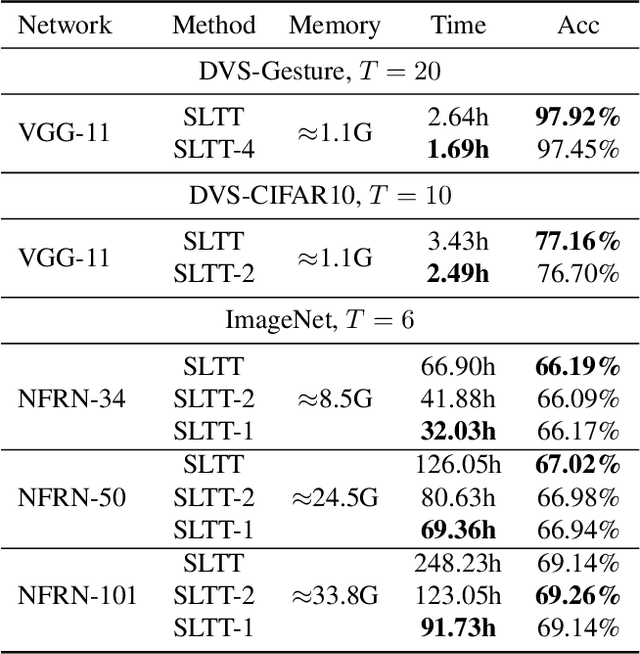
Spiking Neural Networks (SNNs) are promising energy-efficient models for neuromorphic computing. For training the non-differentiable SNN models, the backpropagation through time (BPTT) with surrogate gradients (SG) method has achieved high performance. However, this method suffers from considerable memory cost and training time during training. In this paper, we propose the Spatial Learning Through Time (SLTT) method that can achieve high performance while greatly improving training efficiency compared with BPTT. First, we show that the backpropagation of SNNs through the temporal domain contributes just a little to the final calculated gradients. Thus, we propose to ignore the unimportant routes in the computational graph during backpropagation. The proposed method reduces the number of scalar multiplications and achieves a small memory occupation that is independent of the total time steps. Furthermore, we propose a variant of SLTT, called SLTT-K, that allows backpropagation only at K time steps, then the required number of scalar multiplications is further reduced and is independent of the total time steps. Experiments on both static and neuromorphic datasets demonstrate superior training efficiency and performance of our SLTT. In particular, our method achieves state-of-the-art accuracy on ImageNet, while the memory cost and training time are reduced by more than 70% and 50%, respectively, compared with BPTT.
More Synergy, Less Redundancy: Exploiting Joint Mutual Information for Self-Supervised Learning
Jul 02, 2023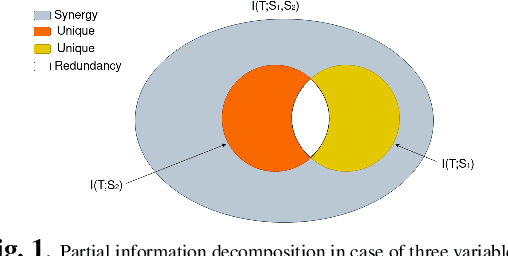
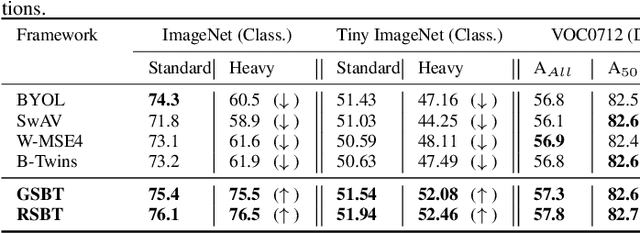
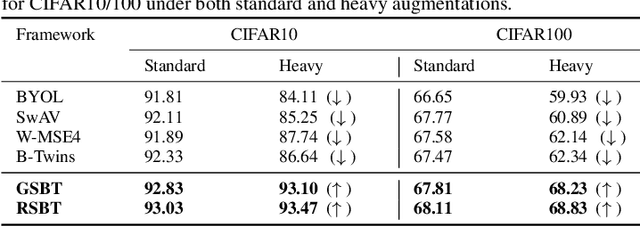
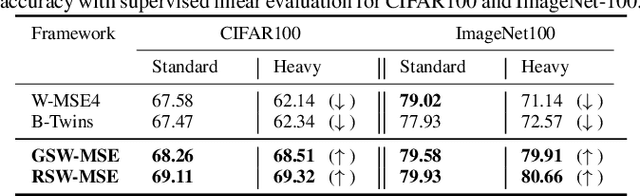
Self-supervised learning (SSL) is now a serious competitor for supervised learning, even though it does not require data annotation. Several baselines have attempted to make SSL models exploit information about data distribution, and less dependent on the augmentation effect. However, there is no clear consensus on whether maximizing or minimizing the mutual information between representations of augmentation views practically contribute to improvement or degradation in performance of SSL models. This paper is a fundamental work where, we investigate role of mutual information in SSL, and reformulate the problem of SSL in the context of a new perspective on mutual information. To this end, we consider joint mutual information from the perspective of partial information decomposition (PID) as a key step in \textbf{reliable multivariate information measurement}. PID enables us to decompose joint mutual information into three important components, namely, unique information, redundant information and synergistic information. Our framework aims for minimizing the redundant information between views and the desired target representation while maximizing the synergistic information at the same time. Our experiments lead to a re-calibration of two redundancy reduction baselines, and a proposal for a new SSL training protocol. Extensive experimental results on multiple datasets and two downstream tasks show the effectiveness of this framework.
STG4Traffic: A Survey and Benchmark of Spatial-Temporal Graph Neural Networks for Traffic Prediction
Jul 02, 2023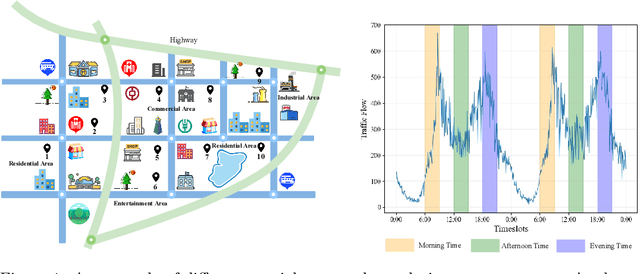


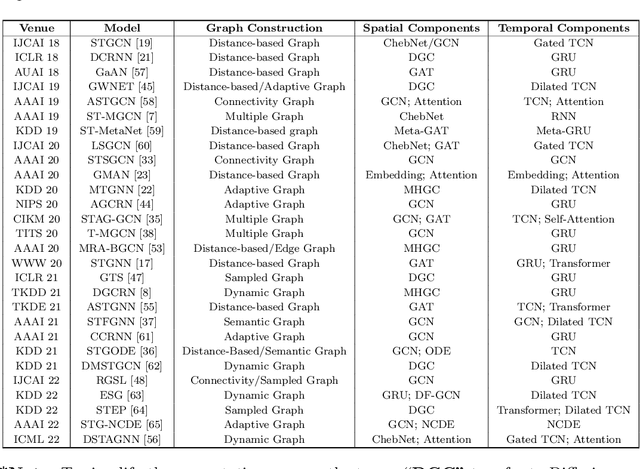
Traffic prediction has been an active research topic in the domain of spatial-temporal data mining. Accurate real-time traffic prediction is essential to improve the safety, stability, and versatility of smart city systems, i.e., traffic control and optimal routing. The complex and highly dynamic spatial-temporal dependencies make effective predictions still face many challenges. Recent studies have shown that spatial-temporal graph neural networks exhibit great potential applied to traffic prediction, which combines sequential models with graph convolutional networks to jointly model temporal and spatial correlations. However, a survey study of graph learning, spatial-temporal graph models for traffic, as well as a fair comparison of baseline models are pending and unavoidable issues. In this paper, we first provide a systematic review of graph learning strategies and commonly used graph convolution algorithms. Then we conduct a comprehensive analysis of the strengths and weaknesses of recently proposed spatial-temporal graph network models. Furthermore, we build a study called STG4Traffic using the deep learning framework PyTorch to establish a standardized and scalable benchmark on two types of traffic datasets. We can evaluate their performance by personalizing the model settings with uniform metrics. Finally, we point out some problems in the current study and discuss future directions. Source codes are available at https://github.com/trainingl/STG4Traffic.
Sentence-level Event Detection without Triggers via Prompt Learning and Machine Reading Comprehension
Jun 25, 2023The traditional way of sentence-level event detection involves two important subtasks: trigger identification and trigger classifications, where the identified event trigger words are used to classify event types from sentences. However, trigger classification highly depends on abundant annotated trigger words and the accuracy of trigger identification. In a real scenario, annotating trigger words is time-consuming and laborious. For this reason, we propose a trigger-free event detection model, which transforms event detection into a two-tower model based on machine reading comprehension and prompt learning. Compared to existing trigger-based and trigger-free methods, experimental studies on two event detection benchmark datasets (ACE2005 and MAVEN) have shown that the proposed approach can achieve competitive performance.
Characterizing the Emotion Carriers of COVID-19 Misinformation and Their Impact on Vaccination Outcomes in India and the United States
Jun 24, 2023
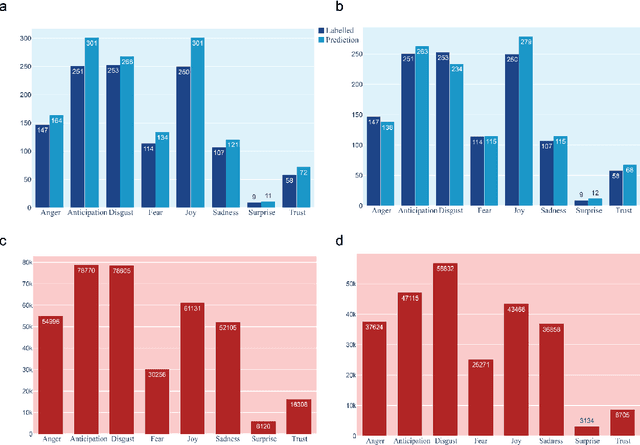
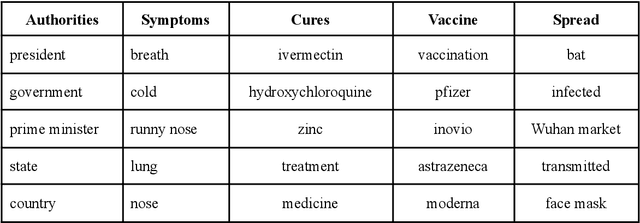
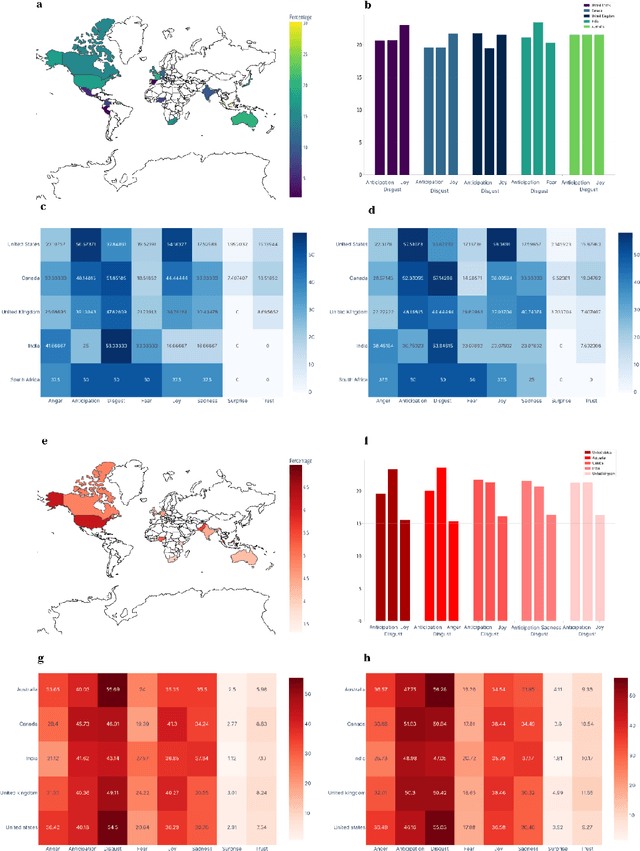
The COVID-19 Infodemic had an unprecedented impact on health behaviors and outcomes at a global scale. While many studies have focused on a qualitative and quantitative understanding of misinformation, including sentiment analysis, there is a gap in understanding the emotion-carriers of misinformation and their differences across geographies. In this study, we characterized emotion carriers and their impact on vaccination rates in India and the United States. A manually labelled dataset was created from 2.3 million tweets and collated with three publicly available datasets (CoAID, AntiVax, CMU) to train deep learning models for misinformation classification. Misinformation labelled tweets were further analyzed for behavioral aspects by leveraging Plutchik Transformers to determine the emotion for each tweet. Time series analysis was conducted to study the impact of misinformation on spatial and temporal characteristics. Further, categorical classification was performed using transformer models to assign categories for the misinformation tweets. Word2Vec+BiLSTM was the best model for misinformation classification, with an F1-score of 0.92. The US had the highest proportion of misinformation tweets (58.02%), followed by the UK (10.38%) and India (7.33%). Disgust, anticipation, and anger were associated with an increased prevalence of misinformation tweets. Disgust was the predominant emotion associated with misinformation tweets in the US, while anticipation was the predominant emotion in India. For India, the misinformation rate exhibited a lead relationship with vaccination, while in the US it lagged behind vaccination. Our study deciphered that emotions acted as differential carriers of misinformation across geography and time. These carriers can be monitored to develop strategic interventions for countering misinformation, leading to improved public health.
Embedding Theory of Reservoir Computing and Reducing Reservoir Network Using Time Delays
Mar 16, 2023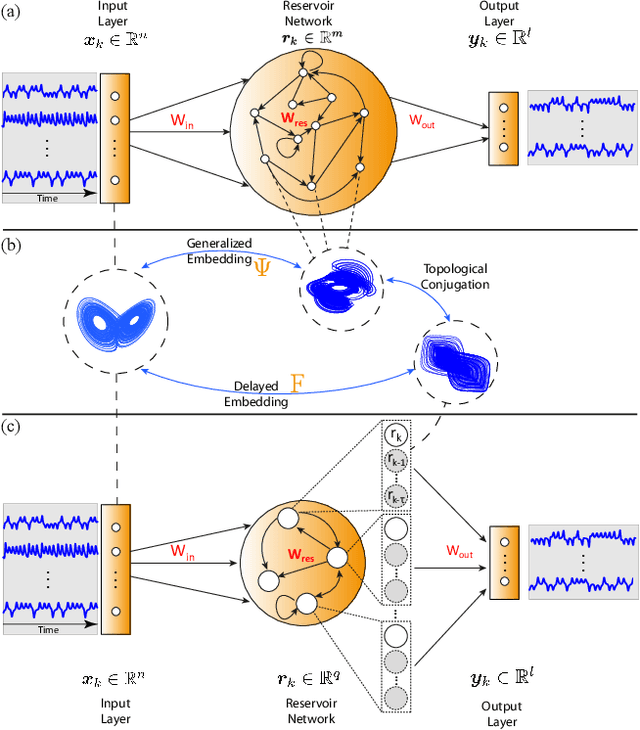
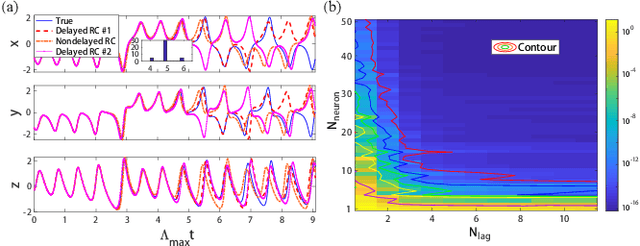
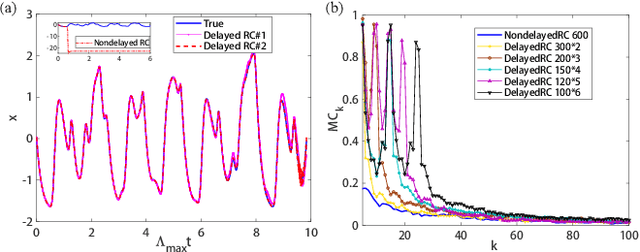
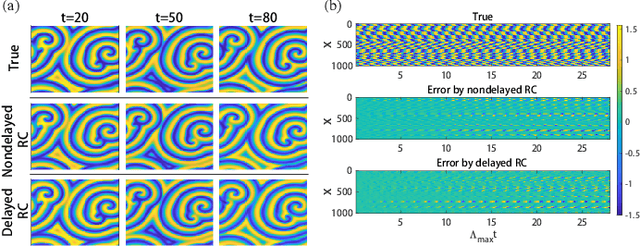
Reservoir computing (RC), a particular form of recurrent neural network, is under explosive development due to its exceptional efficacy and high performance in reconstruction or/and prediction of complex physical systems. However, the mechanism triggering such effective applications of RC is still unclear, awaiting deep and systematic exploration. Here, combining the delayed embedding theory with the generalized embedding theory, we rigorously prove that RC is essentially a high dimensional embedding of the original input nonlinear dynamical system. Thus, using this embedding property, we unify into a universal framework the standard RC and the time-delayed RC where we novelly introduce time delays only into the network's output layer, and we further find a trade-off relation between the time delays and the number of neurons in RC. Based on this finding, we significantly reduce the network size of RC for reconstructing and predicting some representative physical systems, and, more surprisingly, only using a single neuron reservoir with time delays is sometimes sufficient for achieving those tasks.
Cutting-Edge Techniques for Depth Map Super-Resolution
Jun 27, 2023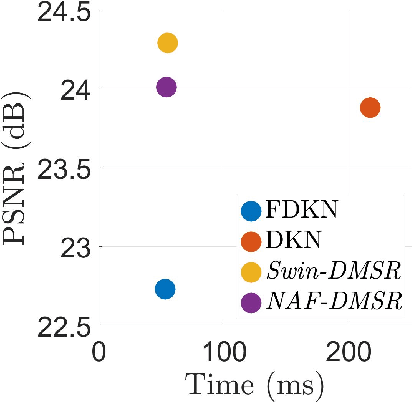

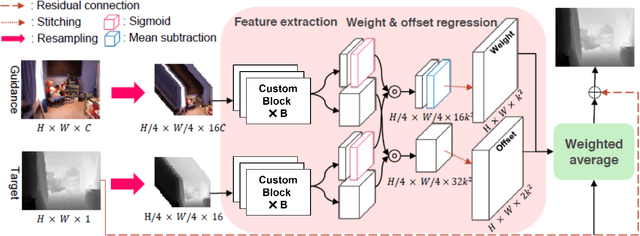
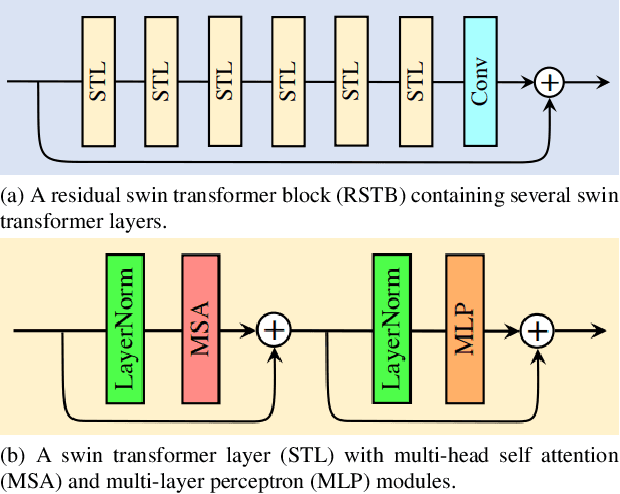
To overcome hardware limitations in commercially available depth sensors which result in low-resolution depth maps, depth map super-resolution (DMSR) is a practical and valuable computer vision task. DMSR requires upscaling a low-resolution (LR) depth map into a high-resolution (HR) space. Joint image filtering for DMSR has been applied using spatially-invariant and spatially-variant convolutional neural network (CNN) approaches. In this project, we propose a novel joint image filtering DMSR algorithm using a Swin transformer architecture. Furthermore, we introduce a Nonlinear Activation Free (NAF) network based on a conventional CNN model used in cutting-edge image restoration applications and compare the performance of the techniques. The proposed algorithms are validated through numerical studies and visual examples demonstrating improvements to state-of-the-art performance while maintaining competitive computation time for noisy depth map super-resolution.