 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scribble-supervised Cell Segmentation Using Multiscale Contrastive Regularization
Jun 25, 2023
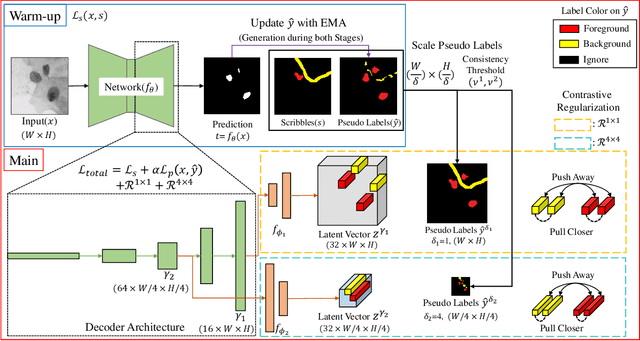
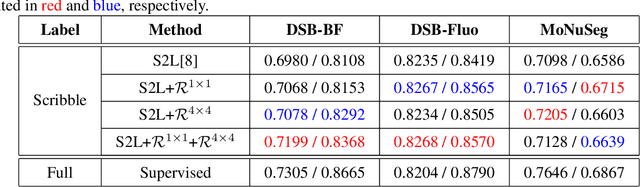

Current state-of-the-art supervised deep learning-based segmentation approaches have demonstrated superior performance in medical image segmentation tasks. However, such supervised approaches require fully annotated pixel-level ground-truth labels, which are labor-intensive and time-consuming to acquire. Recently, Scribble2Label (S2L) demonstrated that using only a handful of scribbles with self-supervised learning can generate accurate segmentation results without full annotation. However, owing to the relatively small size of scribbles, the model is prone to overfit and the results may be biased to the selection of scribbles. In this work, we address this issue by employing a novel multiscale contrastive regularization term for S2L. The main idea is to extract features from intermediate layers of the neural network for contrastive loss so that structures at various scales can be effectively separated. To verify the efficacy of our method, we conducted ablation studies on well-known datasets, such as Data Science Bowl 2018 and MoNuSeg. The results show that the proposed multiscale contrastive loss is effective in improving the performance of S2L, which is comparable to that of the supervised learning segmentation method.
CDiffMR: Can We Replace the Gaussian Noise with K-Space Undersampling for Fast MRI?
Jun 25, 2023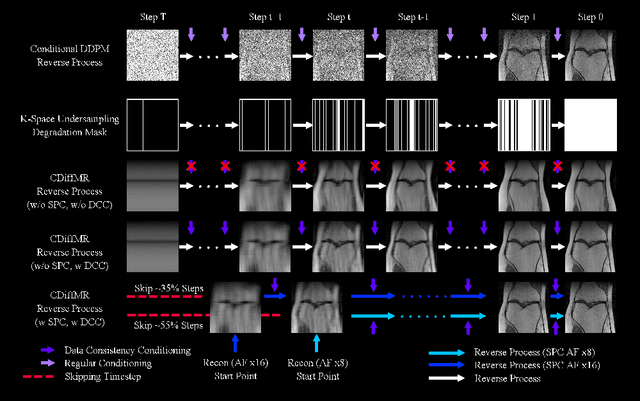

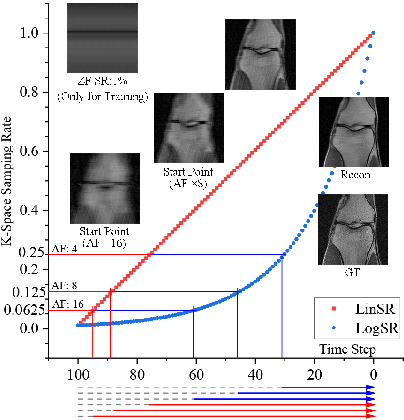
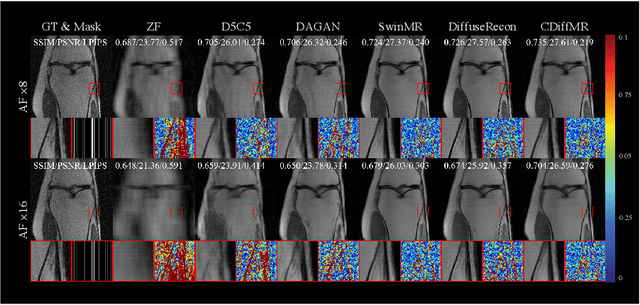
Deep learning has shown the capability to substantially accelerate MRI reconstruction while acquiring fewer measurements. Recently, diffusion models have gained burgeoning interests as a novel group of deep learning-based generative methods. These methods seek to sample data points that belong to a target distribution from a Gaussian distribution, which has been successfully extended to MRI reconstruction. In this work, we proposed a Cold Diffusion-based MRI reconstruction method called CDiffMR. Different from conventional diffusion models, the degradation operation of our CDiffMR is based on \textit{k}-space undersampling instead of adding Gaussian noise, and the restoration network is trained to harness a de-aliaseing function. We also design starting point and data consistency conditioning strategies to guide and accelerate the reverse process. More intriguingly, the pre-trained CDiffMR model can be reused for reconstruction tasks with different undersampling rates. We demonstrated, through extensive numerical and visual experiments, that the proposed CDiffMR can achieve comparable or even superior reconstruction results than state-of-the-art models. Compared to the diffusion model-based counterpart, CDiffMR reaches readily competing results using only $1.6 \sim 3.4\%$ for inference time. The code is publicly available at https://github.com/ayanglab/CDiffMR.
Online Self-Supervised Learning in Machine Learning Intrusion Detection for the Internet of Things
Jun 22, 2023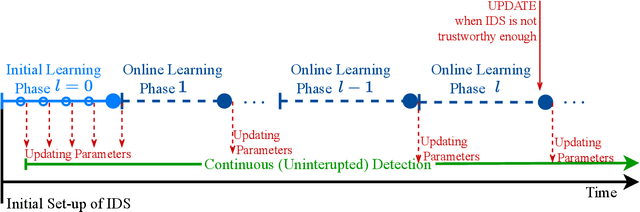

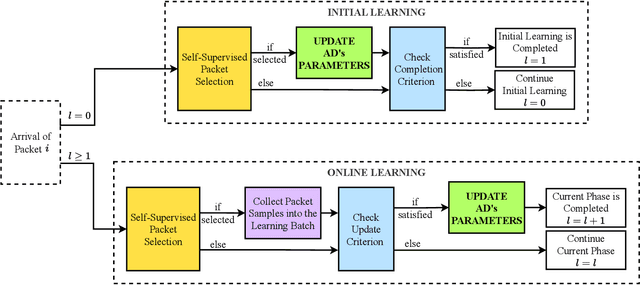
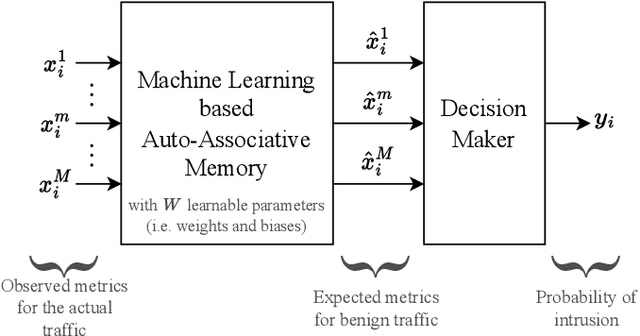
This paper proposes a novel Self-Supervised Intrusion Detection (SSID) framework, which enables a fully online Machine Learning (ML) based Intrusion Detection System (IDS) that requires no human intervention or prior off-line learning. The proposed framework analyzes and labels incoming traffic packets based only on the decisions of the IDS itself using an Auto-Associative Deep Random Neural Network, and on an online estimate of its statistically measured trustworthiness. The SSID framework enables IDS to adapt rapidly to time-varying characteristics of the network traffic, and eliminates the need for offline data collection. This approach avoids human errors in data labeling, and human labor and computational costs of model training and data collection. The approach is experimentally evaluated on public datasets and compared with well-known ML models, showing that this SSID framework is very useful and advantageous as an accurate and online learning ML-based IDS for IoT systems.
Sum-Rate Maximization of RSMA-based Aerial Communications with Energy Harvesting: A Reinforcement Learning Approach
Jun 22, 2023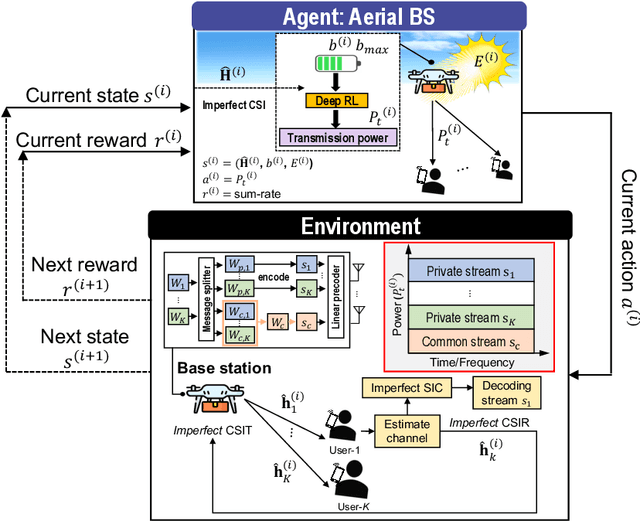
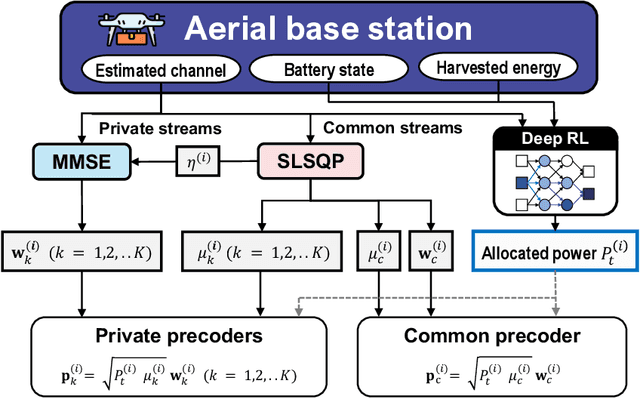
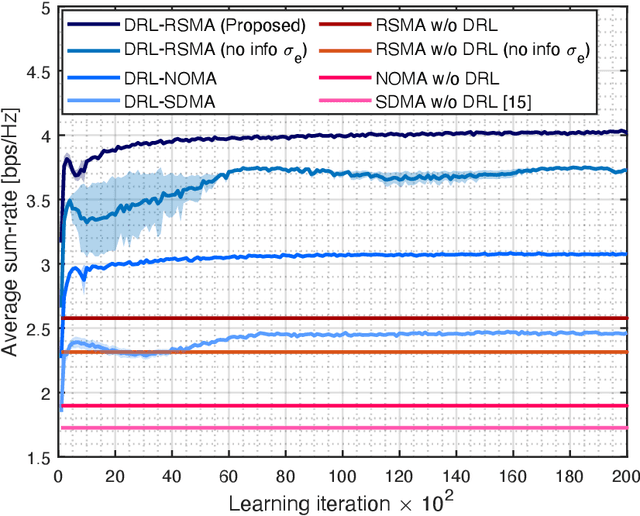
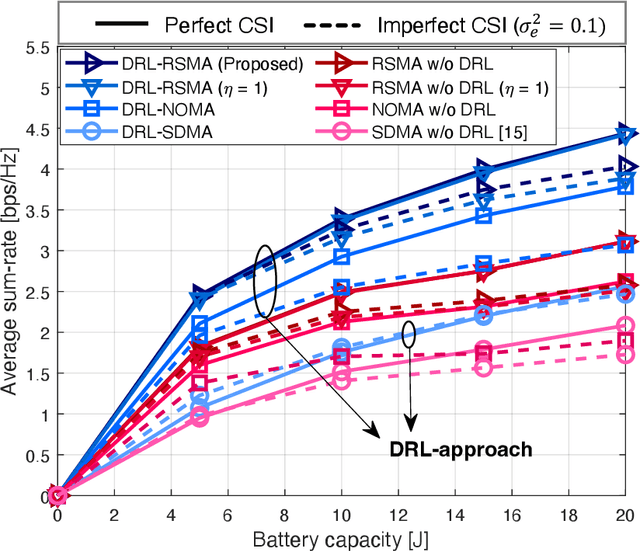
In this letter, we investigate a joint power and beamforming design problem for rate-splitting multiple access (RSMA)-based aerial communications with energy harvesting, where a self-sustainable aerial base station serves multiple users by utilizing the harvested energy. Considering maximizing the sum-rate from the long-term perspective, we utilize a deep reinforcement learning (DRL) approach, namely the soft actor-critic algorithm, to restrict the maximum transmission power at each time based on the stochastic property of the channel environment, harvested energy, and battery power information. Moreover, for designing precoders and power allocation among all the private/common streams of the RSMA, we employ sequential least squares programming (SLSQP) using the Han-Powell quasi-Newton method to maximize the sum-rate for the given transmission power via DRL. Numerical results show the superiority of the proposed scheme over several baseline methods in terms of the average sum-rate performance.
Irregular Change Detection in Sparse Bi-Temporal Point Clouds using Learned Place Recognition Descriptors and Point-to-Voxel Comparison
Jun 27, 2023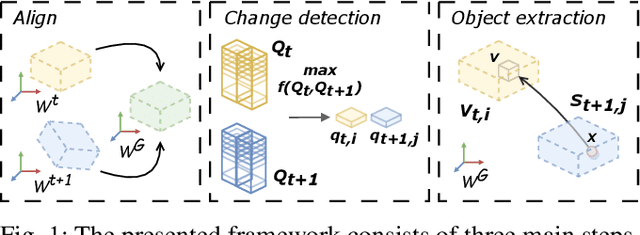
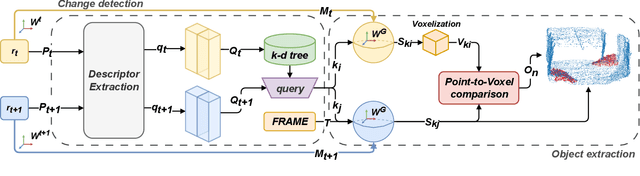
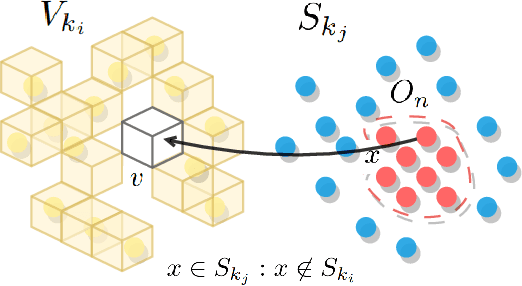
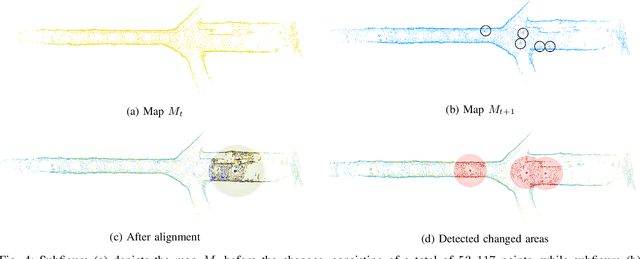
Change detection and irregular object extraction in 3D point clouds is a challenging task that is of high importance not only for autonomous navigation but also for updating existing digital twin models of various industrial environments. This article proposes an innovative approach for change detection in 3D point clouds using deep learned place recognition descriptors and irregular object extraction based on voxel-to-point comparison. The proposed method first aligns the bi-temporal point clouds using a map-merging algorithm in order to establish a common coordinate frame. Then, it utilizes deep learning techniques to extract robust and discriminative features from the 3D point cloud scans, which are used to detect changes between consecutive point cloud frames and therefore find the changed areas. Finally, the altered areas are sampled and compared between the two time instances to extract any obstructions that caused the area to change. The proposed method was successfully evaluated in real-world field experiments, where it was able to detect different types of changes in 3D point clouds, such as object or muck-pile addition and displacement, showcasing the effectiveness of the approach. The results of this study demonstrate important implications for various applications, including safety and security monitoring in construction sites, mapping and exploration and suggests potential future research directions in this field.
CrunchGPT: A chatGPT assisted framework for scientific machine learning
Jun 27, 2023
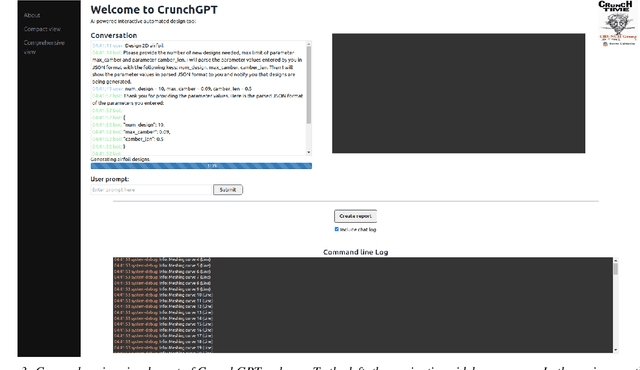
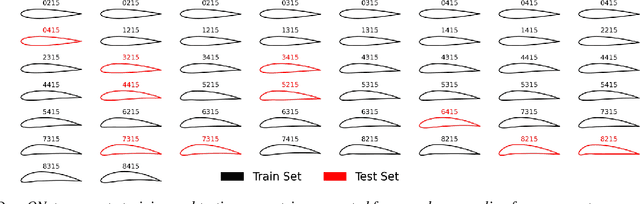
Scientific Machine Learning (SciML) has advanced recently across many different areas in computational science and engineering. The objective is to integrate data and physics seamlessly without the need of employing elaborate and computationally taxing data assimilation schemes. However, preprocessing, problem formulation, code generation, postprocessing and analysis are still time consuming and may prevent SciML from wide applicability in industrial applications and in digital twin frameworks. Here, we integrate the various stages of SciML under the umbrella of ChatGPT, to formulate CrunchGPT, which plays the role of a conductor orchestrating the entire workflow of SciML based on simple prompts by the user. Specifically, we present two examples that demonstrate the potential use of CrunchGPT in optimizing airfoils in aerodynamics, and in obtaining flow fields in various geometries in interactive mode, with emphasis on the validation stage. To demonstrate the flow of the CrunchGPT, and create an infrastructure that can facilitate a broader vision, we built a webapp based guided user interface, that includes options for a comprehensive summary report. The overall objective is to extend CrunchGPT to handle diverse problems in computational mechanics, design, optimization and controls, and general scientific computing tasks involved in SciML, hence using it as a research assistant tool but also as an educational tool. While here the examples focus in fluid mechanics, future versions will target solid mechanics and materials science, geophysics, systems biology and bioinformatics.
CARMA: Context-Aware Runtime Reconfiguration for Energy-Efficient Sensor Fusion
Jun 27, 2023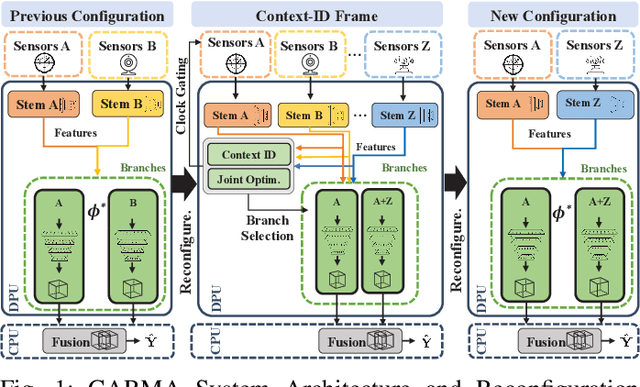
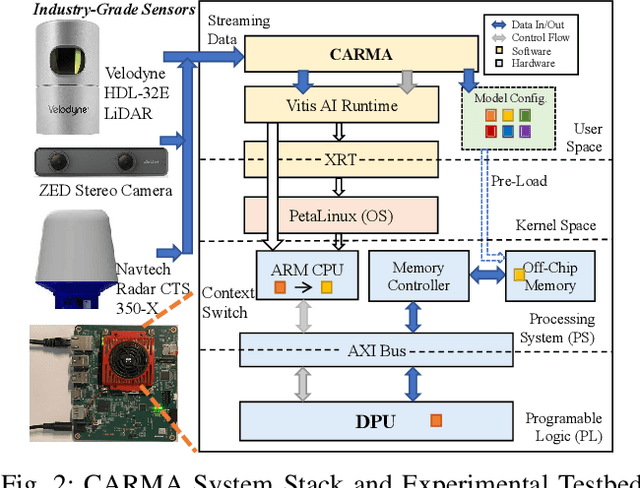
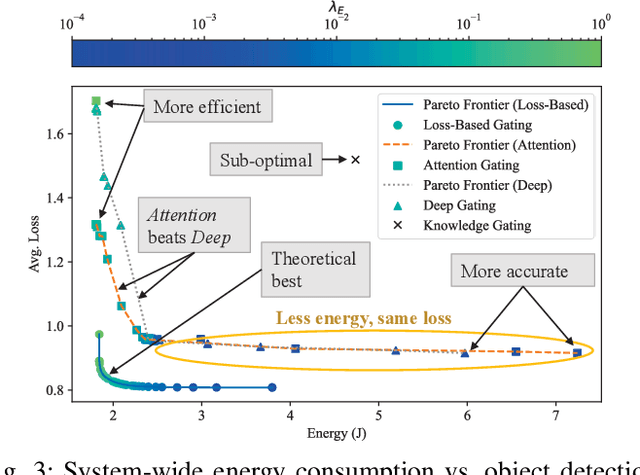
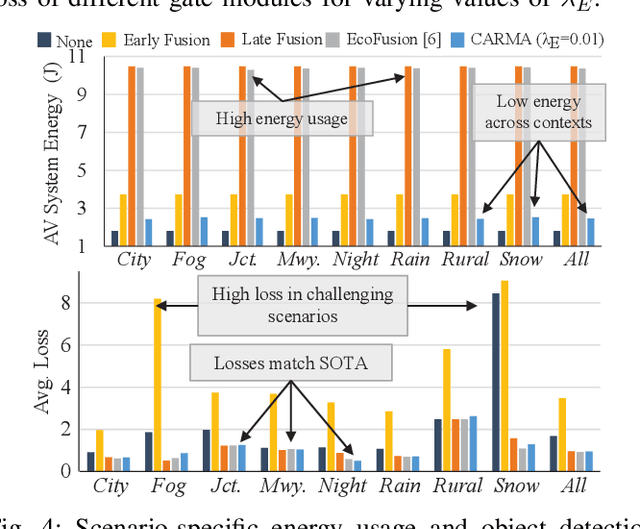
Autonomous systems (AS) are systems that can adapt and change their behavior in response to unanticipated events and include systems such as aerial drones, autonomous vehicles, and ground/aquatic robots. AS require a wide array of sensors, deep-learning models, and powerful hardware platforms to perceive and safely operate in real-time. However, in many contexts, some sensing modalities negatively impact perception while increasing the system's overall energy consumption. Since AS are often energy-constrained edge devices, energy-efficient sensor fusion methods have been proposed. However, existing methods either fail to adapt to changing scenario conditions or to optimize energy efficiency system-wide. We propose CARMA: a context-aware sensor fusion approach that uses context to dynamically reconfigure the computation flow on a Field-Programmable Gate Array (FPGA) at runtime. By clock-gating unused sensors and model sub-components, CARMA significantly reduces the energy used by a multi-sensory object detector without compromising performance. We use a Deep-learning Processor Unit (DPU) based reconfiguration approach to minimize the latency of model reconfiguration. We evaluate multiple context-identification strategies, propose a novel system-wide energy-performance joint optimization, and evaluate scenario-specific perception performance. Across challenging real-world sensing contexts, CARMA outperforms state-of-the-art methods with up to 1.3x speedup and 73% lower energy consumption.
TsSHAP: Robust model agnostic feature-based explainability for time series forecasting
Mar 22, 2023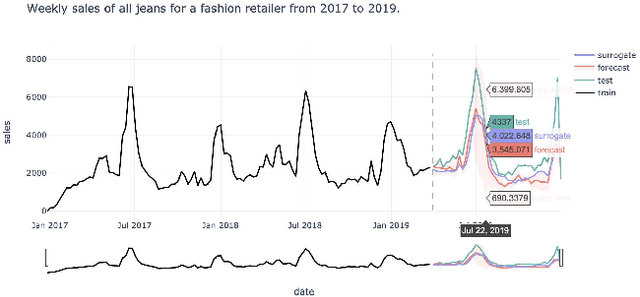

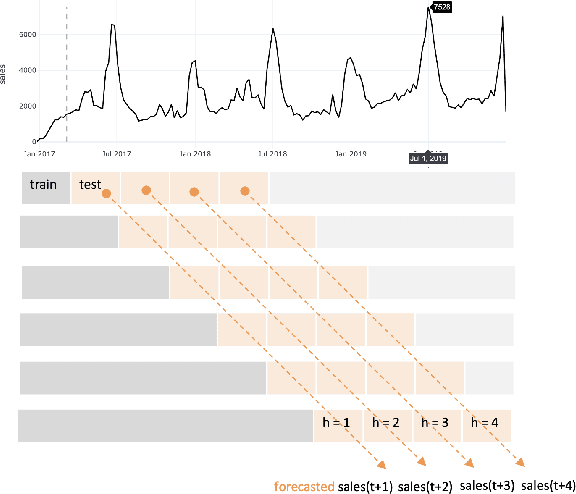
A trustworthy machine learning model should be accurate as well as explainable. Understanding why a model makes a certain decision defines the notion of explainability. While various flavors of explainability have been well-studied in supervised learning paradigms like classification and regression, literature on explainability for time series forecasting is relatively scarce. In this paper, we propose a feature-based explainability algorithm, TsSHAP, that can explain the forecast of any black-box forecasting model. The method is agnostic of the forecasting model and can provide explanations for a forecast in terms of interpretable features defined by the user a prior. The explanations are in terms of the SHAP values obtained by applying the TreeSHAP algorithm on a surrogate model that learns a mapping between the interpretable feature space and the forecast of the black-box model. Moreover, we formalize the notion of local, semi-local, and global explanations in the context of time series forecasting, which can be useful in several scenarios. We validate the efficacy and robustness of TsSHAP through extensive experiments on multiple datasets.
Efficient Heuristics for Multi-Robot Path Planning in Crowded Environments
Jun 26, 2023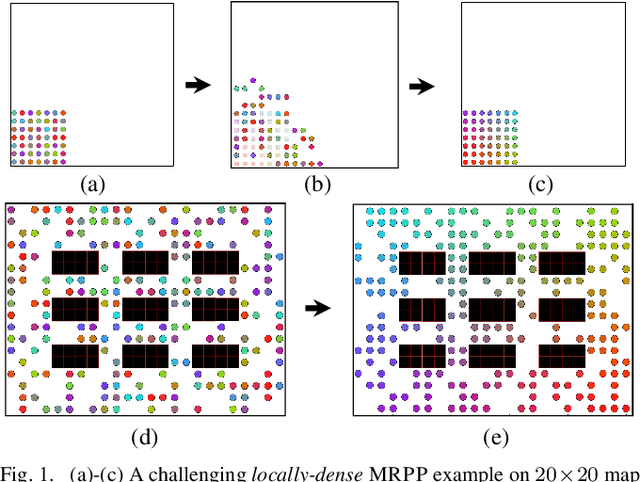
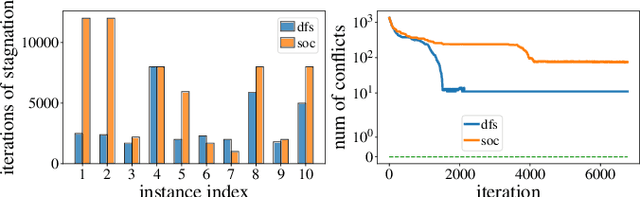
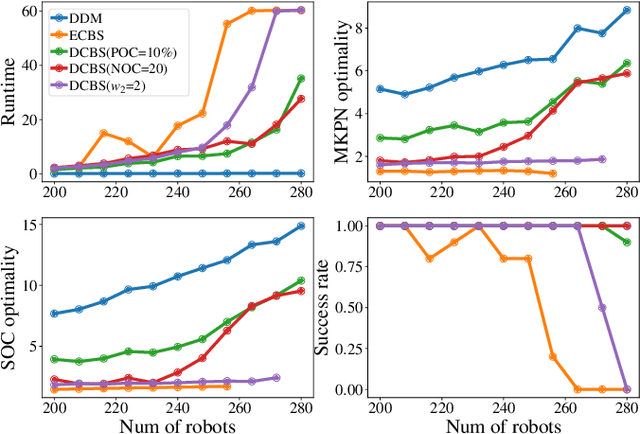
Optimal Multi-Robot Path Planning (MRPP) has garnered significant attention due to its many applications in domains including warehouse automation, transportation, and swarm robotics. Current MRPP solvers can be divided into reduction-based, search-based, and rule-based categories, each with their strengths and limitations. Regardless of the methodology, however, the issue of handling dense MRPP instances remains a significant challenge, where existing approaches generally demonstrate a dichotomy regarding solution optimality and efficiency. This study seeks to bridge the gap in optimal MRPP resolution for dense, highly-entangled scenarios, with potential applications to high-density storage systems and traffic congestion control. Toward that goal, we analyze the behaviors of SOTA MRPP algorithms in dense settings and develop two hybrid algorithms leveraging the strengths of existing SOTA algorithms: DCBS (database-accelerated enhanced conflict-based search) and SCBS (sparsified enhanced conflict-based search). Experimental validations demonstrate that DCBS and SCBS deliver a significant reduction in computational time compared to existing bounded-suboptimal methods and improve solution quality compared to existing rule-based methods, achieving a desirable balance between computational efficiency and solution optimality. As a result, DCBS and SCBS are particularly suitable for quickly computing good-quality solutions for multi-robot routing in dense settings
Subjective assessment of the impact of a content adaptive optimiser for compressing 4K HDR content with AV1
Jun 26, 2023

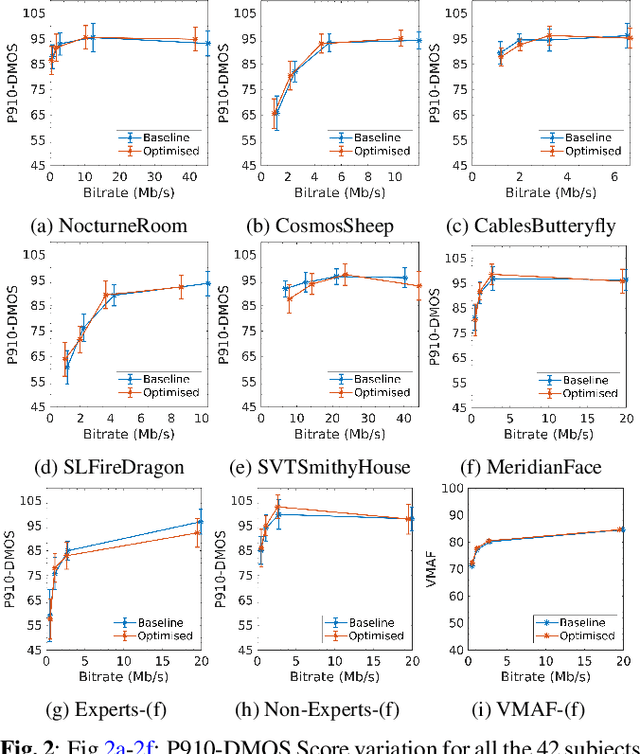
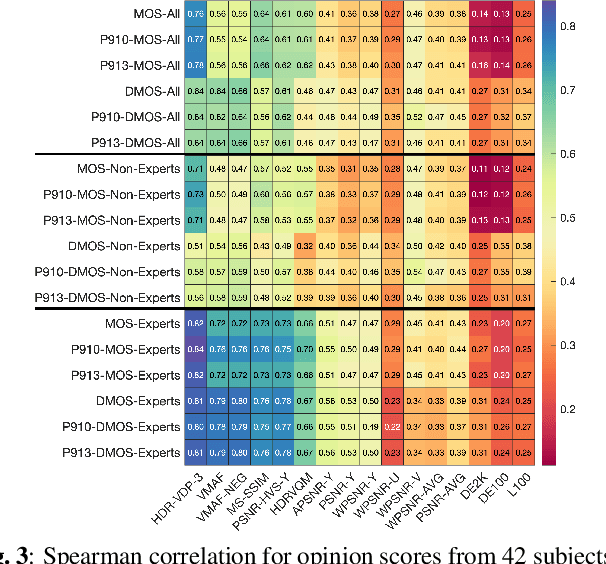
Since 2015 video dimensionality has expanded to higher spatial and temporal resolutions and a wider colour gamut. This High Dynamic Range (HDR) content has gained traction in the consumer space as it delivers an enhanced quality of experience. At the same time, the complexity of codecs is growing. This has driven the development of tools for content-adaptive optimisation that achieve optimal rate-distortion performance for HDR video at 4K resolution. While improvements of just a few percentage points in BD-Rate (1-5\%) are significant for the streaming media industry, the impact on subjective quality has been less studied especially for HDR/AV1. In this paper, we conduct a subjective quality assessment (42 subjects) of 4K HDR content with a per-clip optimisation strategy. We correlate these subjective scores with existing popular objective metrics used in standard development and show that some perceptual metrics correlate surprisingly well even though they are not tuned for HDR. We find that the DSQCS protocol is too insensitive to categorically compare the methods but the data allows us to make recommendations about the use of experts vs non-experts in HDR studies, and explain the subjective impact of film grain in HDR content under compression.