 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TsSHAP: Robust model agnostic feature-based explainability for time series forecasting
Mar 22, 2023
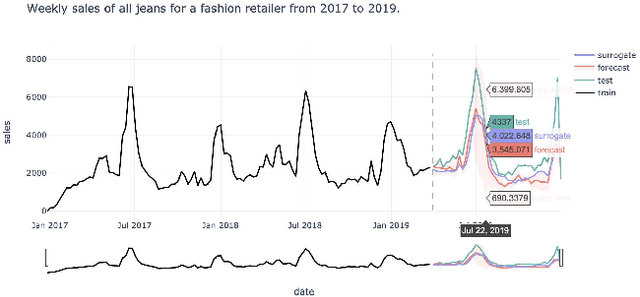

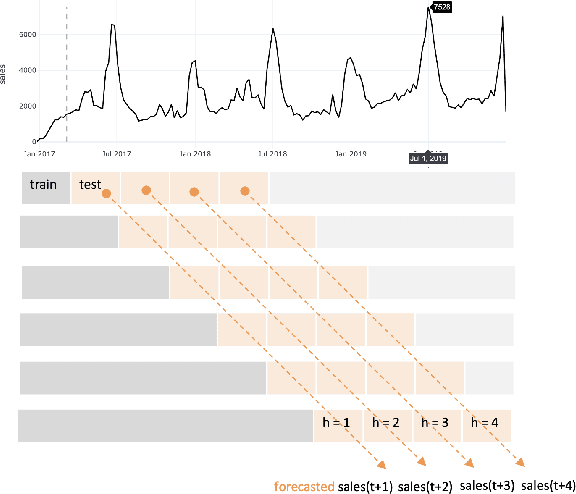
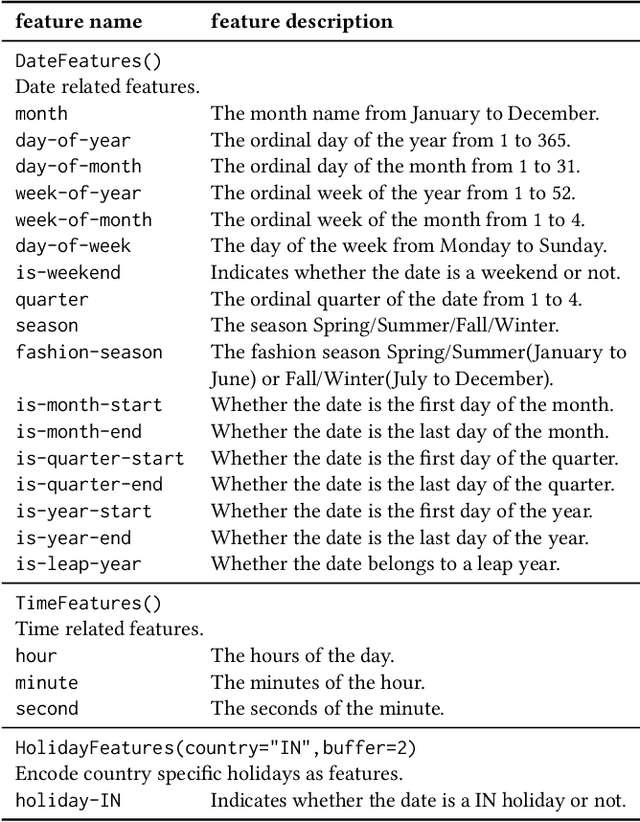
A trustworthy machine learning model should be accurate as well as explainable. Understanding why a model makes a certain decision defines the notion of explainability. While various flavors of explainability have been well-studied in supervised learning paradigms like classification and regression, literature on explainability for time series forecasting is relatively scarce. In this paper, we propose a feature-based explainability algorithm, TsSHAP, that can explain the forecast of any black-box forecasting model. The method is agnostic of the forecasting model and can provide explanations for a forecast in terms of interpretable features defined by the user a prior. The explanations are in terms of the SHAP values obtained by applying the TreeSHAP algorithm on a surrogate model that learns a mapping between the interpretable feature space and the forecast of the black-box model. Moreover, we formalize the notion of local, semi-local, and global explanations in the context of time series forecasting, which can be useful in several scenarios. We validate the efficacy and robustness of TsSHAP through extensive experiments on multiple datasets.
Stable Yaw Estimation of Boats from the Viewpoint of UAVs and USVs
Jun 24, 2023
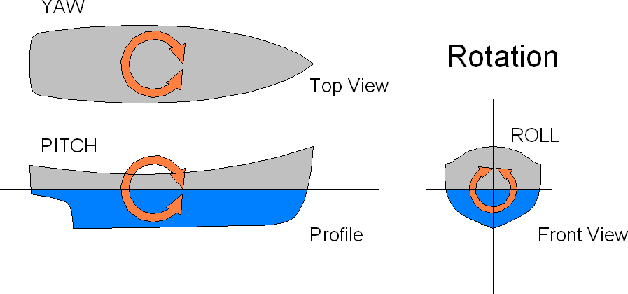
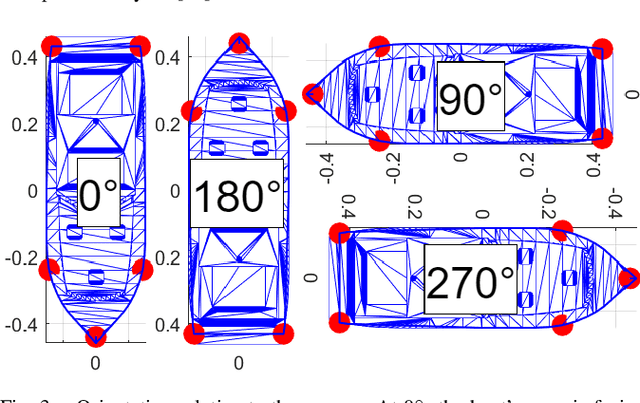

Yaw estimation of boats from the viewpoint of unmanned aerial vehicles (UAVs) and unmanned surface vehicles (USVs) or boats is a crucial task in various applications such as 3D scene rendering, trajectory prediction, and navigation. However, the lack of literature on yaw estimation of objects from the viewpoint of UAVs has motivated us to address this domain. In this paper, we propose a method based on HyperPosePDF for predicting the orientation of boats in the 6D space. For that, we use existing datasets, such as PASCAL3D+ and our own datasets, SeaDronesSee-3D and BOArienT, which we annotated manually. We extend HyperPosePDF to work in video-based scenarios, such that it yields robust orientation predictions across time. Naively applying HyperPosePDF on video data yields single-point predictions, resulting in far-off predictions and often incorrect symmetric orientations due to unseen or visually different data. To alleviate this issue, we propose aggregating the probability distributions of pose predictions, resulting in significantly improved performance, as shown in our experimental evaluation. Our proposed method could significantly benefit downstream tasks in marine robotics.
Real-Time Decentralized Navigation of Nonholonomic Agents Using Shifted Yielding Areas
Mar 16, 2023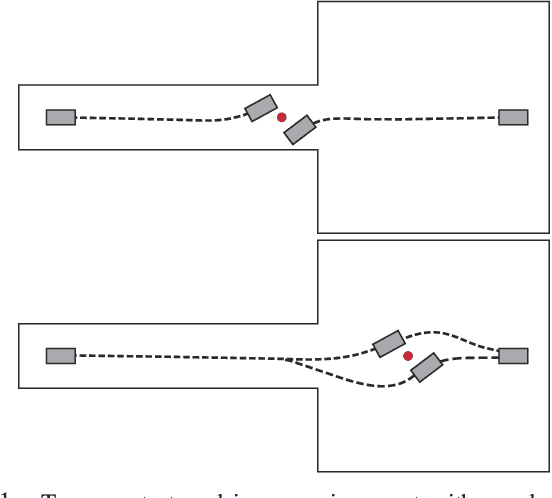
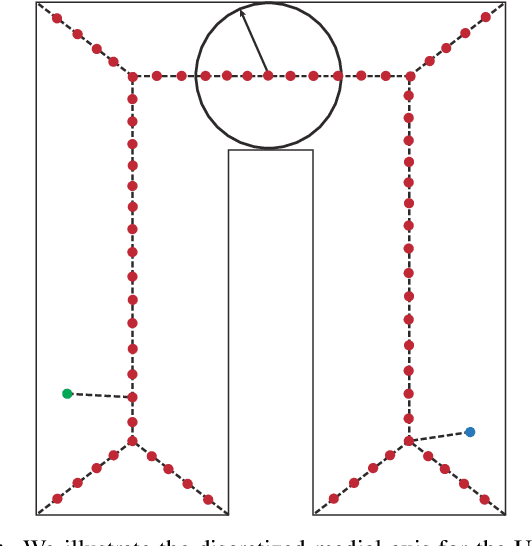
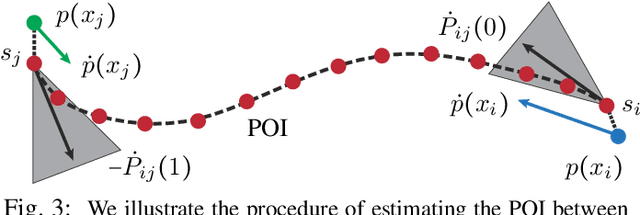
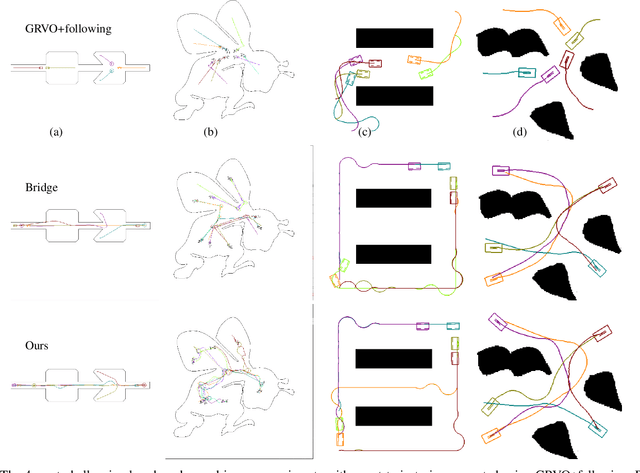
We present a lightweight, decentralized algorithm for navigating multiple nonholonomic agents through challenging environments with narrow passages. Our key idea is to allow agents to yield to each other in large open areas instead of narrow passages, to increase the success rate of conventional decentralized algorithms. At pre-processing time, our method computes a medial axis for the freespace. A reference trajectory is then computed and projected onto the medial axis for each agent. During run time, when an agent senses other agents moving in the opposite direction, our algorithm uses the medial axis to estimate a Point of Impact (POI) as well as the available area around the POI. If the area around the POI is not large enough for yielding behaviors to be successful, we shift the POI to nearby large areas by modulating the agent's reference trajectory and traveling speed. We evaluate our method on a row of 4 environments with up to 15 robots, and we find our method incurs a marginal computational overhead of 10-30 ms on average, achieving real-time performance. Afterward, our planned reference trajectories can be tracked using local navigation algorithms to achieve up to a $100\%$ higher success rate over local navigation algorithms alone.
More efficient manual review of automatically transcribed tabular data
Jun 28, 2023
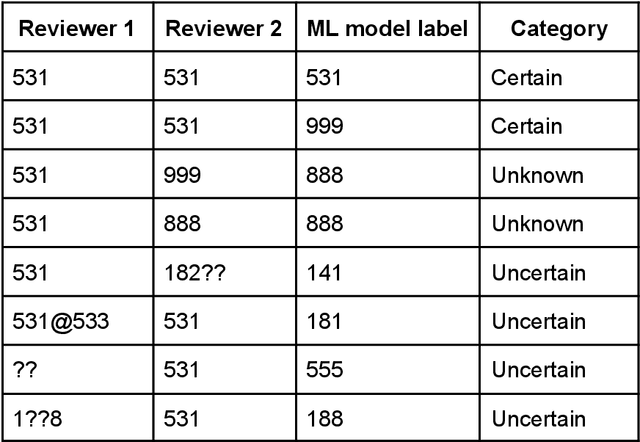
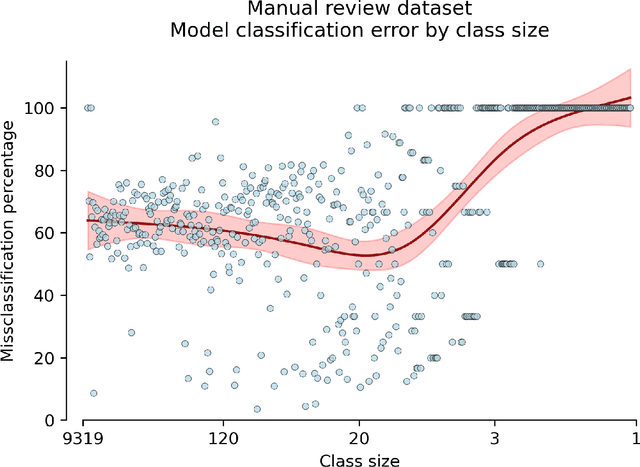
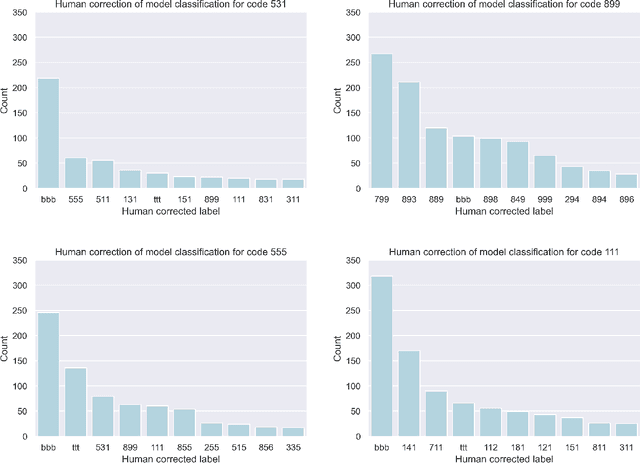
Machine learning methods have proven useful in transcribing historical data. However, results from even highly accurate methods require manual verification and correction. Such manual review can be time-consuming and expensive, therefore the objective of this paper was to make it more efficient. Previously, we used machine learning to transcribe 2.3 million handwritten occupation codes from the Norwegian 1950 census with high accuracy (97%). We manually reviewed the 90,000 (3%) codes with the lowest model confidence. We allocated those 90,000 codes to human reviewers, who used our annotation tool to review the codes. To assess reviewer agreement, some codes were assigned to multiple reviewers. We then analyzed the review results to understand the relationship between accuracy improvements and effort. Additionally, we interviewed the reviewers to improve the workflow. The reviewers corrected 62.8% of the labels and agreed with the model label in 31.9% of cases. About 0.2% of the images could not be assigned a label, while for 5.1% the reviewers were uncertain, or they assigned an invalid label. 9,000 images were independently reviewed by multiple reviewers, resulting in an agreement of 86.43% and disagreement of 8.96%. We learned that our automatic transcription is biased towards the most frequent codes, with a higher degree of misclassification for the lowest frequency codes. Our interview findings show that the reviewers did internal quality control and found our custom tool well-suited. So, only one reviewer is needed, but they should report uncertainty.
Real-World Performance of Autonomously Reporting Normal Chest Radiographs in NHS Trusts Using a Deep-Learning Algorithm on the GP Pathway
Jun 28, 2023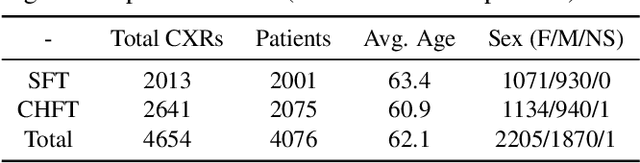
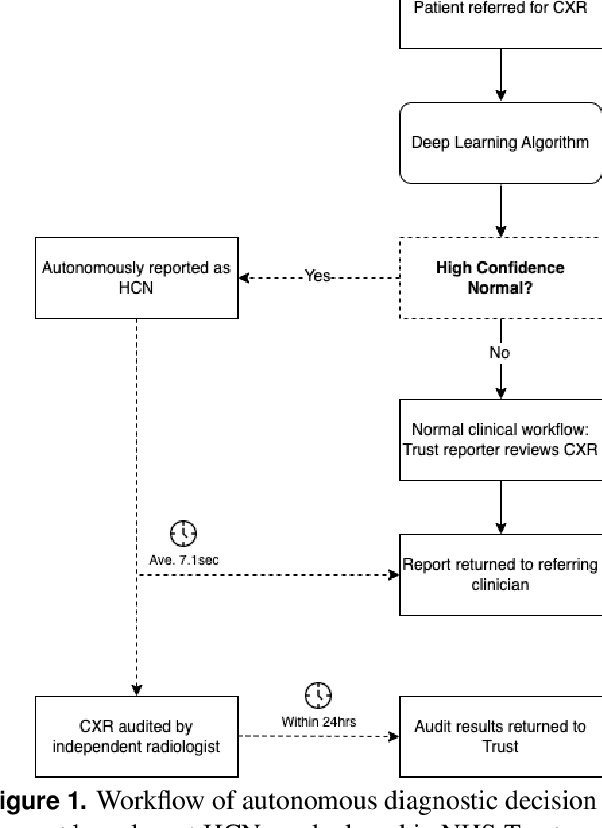
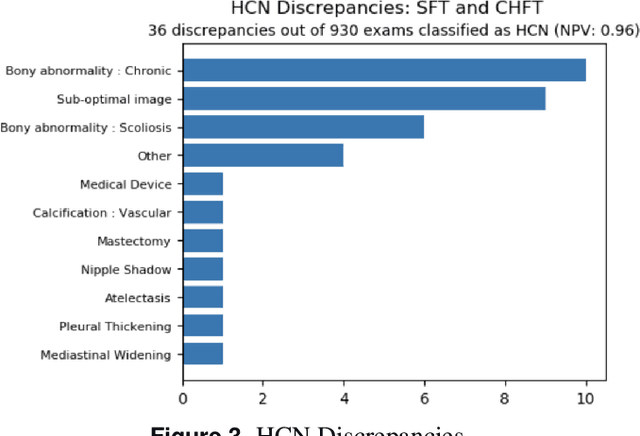
AIM To analyse the performance of a deep-learning (DL) algorithm currently deployed as diagnostic decision support software in two NHS Trusts used to identify normal chest x-rays in active clinical pathways. MATERIALS AND METHODS A DL algorithm has been deployed in Somerset NHS Foundation Trust (SFT) since December 2022, and at Calderdale & Huddersfield NHS Foundation Trust (CHFT) since March 2023. The algorithm was developed and trained prior to deployment, and is used to assign abnormality scores to each GP-requested chest x-ray (CXR). The algorithm classifies a subset of examinations with the lowest abnormality scores as High Confidence Normal (HCN), and displays this result to the Trust. This two-site study includes 4,654 CXR continuous examinations processed by the algorithm over a six-week period. RESULTS When classifying 20.0% of assessed examinations (930) as HCN, the model classified exams with a negative predictive value (NPV) of 0.96. There were 0.77% of examinations (36) classified incorrectly as HCN, with none of the abnormalities considered clinically significant by auditing radiologists. The DL software maintained fast levels of service to clinicians, with results returned to Trusts in a mean time of 7.1 seconds. CONCLUSION The DL algorithm performs with a low rate of error and is highly effective as an automated diagnostic decision support tool, used to autonomously report a subset of CXRs as normal with high confidence. Removing 20% of all CXRs reduces workload for reporters and allows radiology departments to focus resources elsewhere.
Fast Recognition of birds in offshore wind farms based on an improved deep learning model
Jun 28, 2023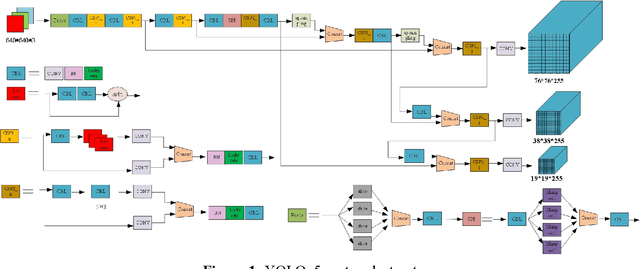
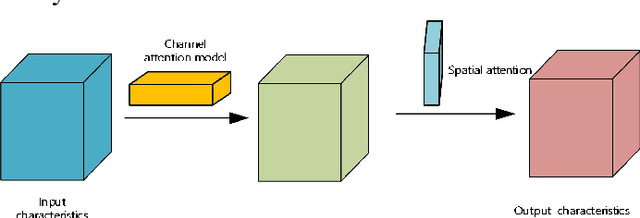

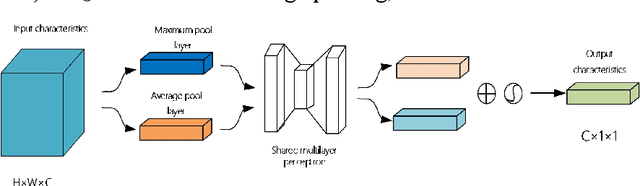
The safety of wind turbines is a prerequisite for the stable operation of offshore wind farms. However, bird damage poses a direct threat to the safe operation of wind turbines and wind turbine blades. In addition, millions of birds are killed by wind turbines every year. In order to protect the ecological environment and maintain the safe operation of offshore wind turbines, and to address the problem of the low detection capability of current target detection algorithms in low-light environments such as at night, this paper proposes a method to improve the network performance by integrating the CBAM attention mechanism and the RetinexNet network into YOLOv5. First, the training set images are fed into the YOLOv5 network with integrated CBAM attention module for training, and the optimal weight model is stored. Then, low-light images are enhanced and denoised using Decom-Net and Enhance-Net, and the accuracy is tested on the optimal weight model. In addition, the k-means++ clustering algorithm is used to optimise the anchor box selection method, which solves the problem of unstable initial centroids and achieves better clustering results. Experimental results show that the accuracy of this model in bird detection tasks can reach 87.40%, an increase of 21.25%. The model can detect birds near wind turbines in real time and shows strong stability in night, rainy and shaky conditions, proving that the model can ensure the safe and stable operation of wind turbines.
Separable Physics-Informed Neural Networks
Jun 28, 2023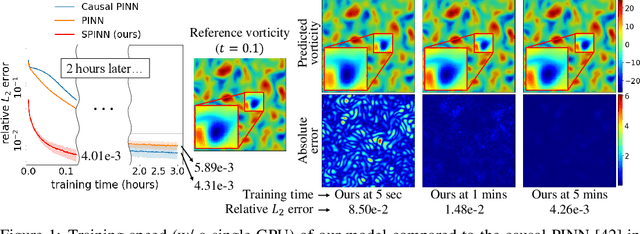

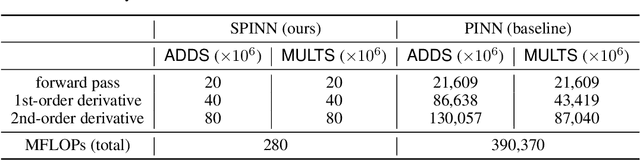
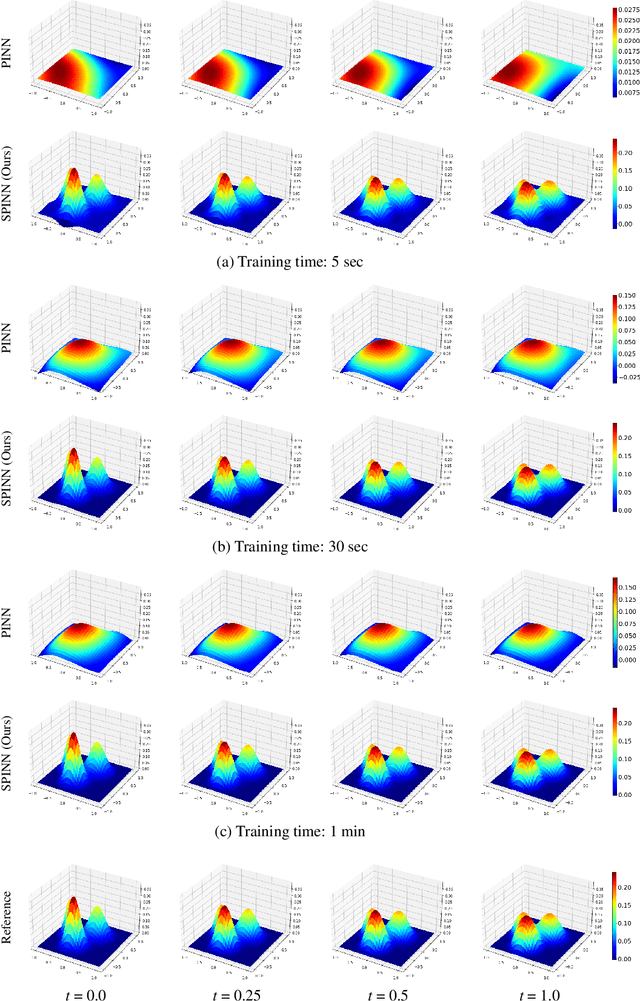
Physics-informed neural networks (PINNs) have recently emerged as promising data-driven PDE solvers showing encouraging results on various PDEs. However, there is a fundamental limitation of training PINNs to solve multi-dimensional PDEs and approximate highly complex solution functions. The number of training points (collocation points) required on these challenging PDEs grows substantially, but it is severely limited due to the expensive computational costs and heavy memory overhead. To overcome this issue, we propose a network architecture and training algorithm for PINNs. The proposed method, separable PINN (SPINN), operates on a per-axis basis to significantly reduce the number of network propagations in multi-dimensional PDEs unlike point-wise processing in conventional PINNs. We also propose using forward-mode automatic differentiation to reduce the computational cost of computing PDE residuals, enabling a large number of collocation points (>10^7) on a single commodity GPU. The experimental results show drastically reduced computational costs (62x in wall-clock time, 1,394x in FLOPs given the same number of collocation points) in multi-dimensional PDEs while achieving better accuracy. Furthermore, we present that SPINN can solve a chaotic (2+1)-d Navier-Stokes equation significantly faster than the best-performing prior method (9 minutes vs 10 hours in a single GPU), maintaining accuracy. Finally, we showcase that SPINN can accurately obtain the solution of a highly nonlinear and multi-dimensional PDE, a (3+1)-d Navier-Stokes equation.
A two-way translation system of Chinese sign language based on computer vision
Jun 03, 2023

As the main means of communication for deaf people, sign language has a special grammatical order, so it is meaningful and valuable to develop a real-time translation system for sign language. In the research process, we added a TSM module to the lightweight neural network model for the large Chinese continuous sign language dataset . It effectively improves the network performance with high accuracy and fast recognition speed. At the same time, we improve the Bert-Base-Chinese model to divide Chinese sentences into words and mapping the natural word order to the statute sign language order, and finally use the corresponding word videos in the isolated sign language dataset to generate the sentence video, so as to achieve the function of text-to-sign language translation. In the last of our research we built a system with sign language recognition and translation functions, and conducted performance tests on the complete dataset. The sign language video recognition accuracy reached about 99.3% with a time of about 0.05 seconds, and the sign language generation video time was about 1.3 seconds. The sign language system has good performance performance and is feasible.
Ultra-Precise Synchronization for TDoA-based Localization Using Signals of Opportunity
Jun 08, 2023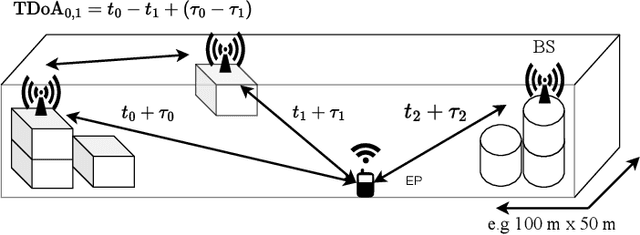
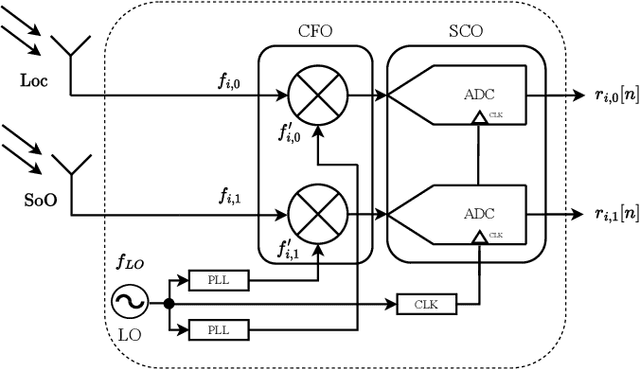
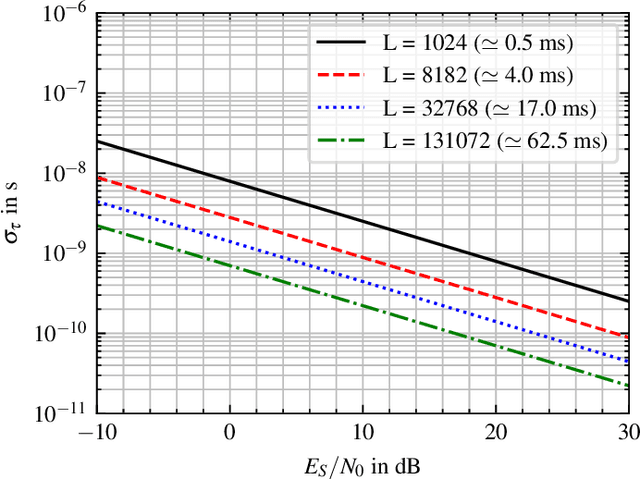
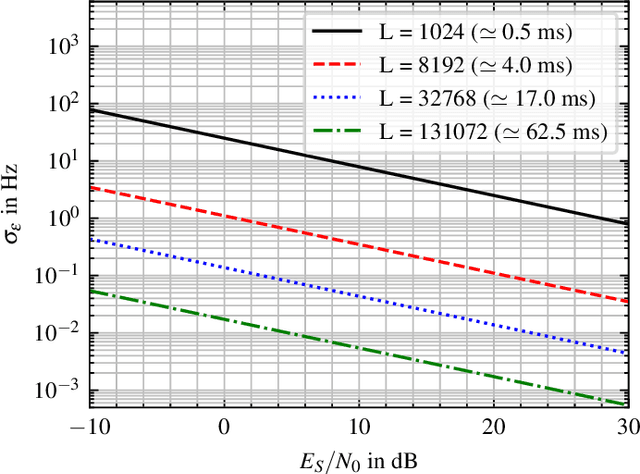
Precise localization is one key element of the Internet of Things (IoT). Especially concepts for position estimation when Global Navigation Satellite Systems (GNSS) are unavailable have moved into the focus. One crucial component for localization systems in general and precise runtime-based positioning, in particular, is the necessity of ultra-precise clock synchronization between the receiving base stations. Our work presents a software-based approach for the wireless synchronization of spatially separated base stations using a low-cost off-the-shelf frontend architecture. The proposed system estimates the time synchronization, sampling clock offset, and carrier frequency offset using broadcast signals as Signals of Opportunity. In this paper, we derive the theoretical lower bound for the estimation variance according to the Modified Cramer-Rao Bound. We show that a theoretical time synchronization accuracy in the range of ps and a frequency synchronization precision in the range of milli-Hertz is achievable. An algorithm is presented that estimates the desired parameter based on evaluating the Cross-Correlation Function between base stations. Initial measurements are conducted in a real-world environment. It is shown that the presented estimator nearly reaches the theoretical bound within a time and frequency synchronization accuracy of down to 200 ps and 6 mHz, respectively.
Towards Real-Time Single-Channel Speech Separation in Noisy and Reverberant Environments
Mar 14, 2023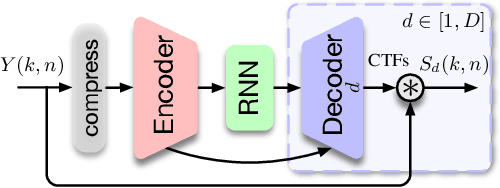
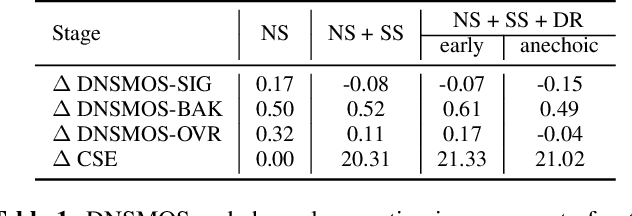
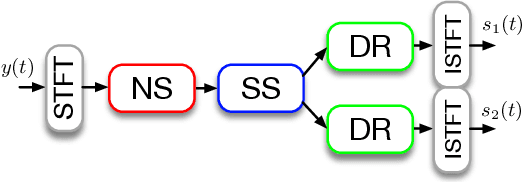
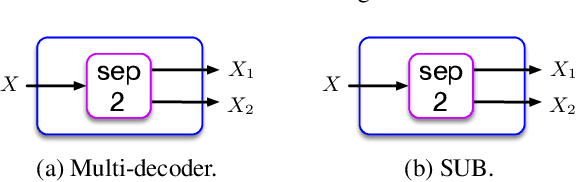
Real-time single-channel speech separation aims to unmix an audio stream captured from a single microphone that contains multiple people talking at once, environmental noise, and reverberation into multiple de-reverberated and noise-free speech tracks, each track containing only one talker. While large state-of-the-art DNNs can achieve excellent separation from anechoic mixtures of speech, the main challenge is to create compact and causal models that can separate reverberant mixtures at inference time. In this paper, we explore low-complexity, resource-efficient, causal DNN architectures for real-time separation of two or more simultaneous speakers. A cascade of three neural network modules are trained to sequentially perform noise-suppression, separation, and de-reverberation. For comparison, a larger end-to-end model is trained to output two anechoic speech signals directly from noisy reverberant speech mixtures. We propose an efficient single-decoder architecture with subtractive separation for real-time recursive speech separation for two or more speakers. Evaluation on real monophonic recordings of speech mixtures, according to speech separation measures like SI-SDR, perceptual measures like DNS-MOS, and a novel proposed channel separation metric, show that these compact causal models can separate speech mixtures with low latency, and perform on par with large offline state-of-the-art models like SepFormer.